






一、canal总览
一、canal简介
主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
canal的工作原理:
1.canal模拟mysql sllave的交互协议,伪装自己为mysql salve;
2.mysql master收到dump请求,开始推送binary log给 slave(也就是canal);
3.canal解析binary log 对象(原始byte流),再发送到存储目的地,比如MySQL,Kafka,Elastic Search等等。
canal的数据同步可以增量/全量。基于binary log增量订阅和消费。

二、canal可以做什么?
(1)数据库镜像
(2)数据库实时备份
(3)索引构建和实时维护
(4)业务cache(缓存)刷新
(5)带业务逻辑的增量数据处理
对于我们项目中基本都会用到redis,es等中间件。
对于数据的增加及修改,删除等,都会通过在业务层直接硬编码直接删除或者修改缓存或者通过MQ中间件发送到中间件服务,再通过消费消息添加到redis或者es中。
有了canal后,我们直接可以通过微服务监控增量日志,直接发送到mq再进行操作。

三、为什么使用Canal?
(1). 更灵活的架构,多机房同步比较简单。
(2). 异构表之间也可以同步,同时可以控制不同步DDL以免出现数据丢失和不一致。
(3). Canal可以实现一个表一线程,多个表多线程的同步,速度更快。同时会压缩简化要传输的binlog,减少网络压力。
(4). 双A机房同步. 目前mysql的M-M部署结构,不支持解决数据的一致性问题,基于canal的双向复制+一致性算法,可一定程度上解决这个问题,实现双A机房;
四、canal-HA架构

五、mysql开启binlog
1、开启binlog
(1)MySQL的 my.cnf 中配置:
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复如果订阅的是mysql的从库,需求增加配置让从库日志也写到binlog里面
log_slave_updates=1
(2)可以通过在 mysql 终端中执行以下命令判断配置是否生效:
进入mysql:
mysql -hlocalhost -uroot -p[密码]
查看log日志是否开启命令:
show variables like 'log_bin';
查看当前二进制日志记录格式:
show variables like 'binlog_format';
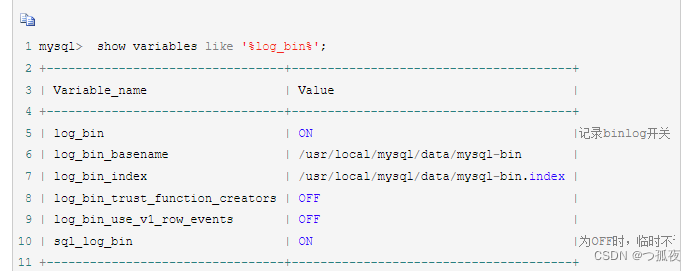

注意:
1. 以上截图是 ON 是开启状态 ,如果是OFF就是未开启,mysql数据库log-bin默认是不开启
2. canal需要的log日志格式为 ROW格式
2、授权账号权限
授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant:
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
二、单机部署
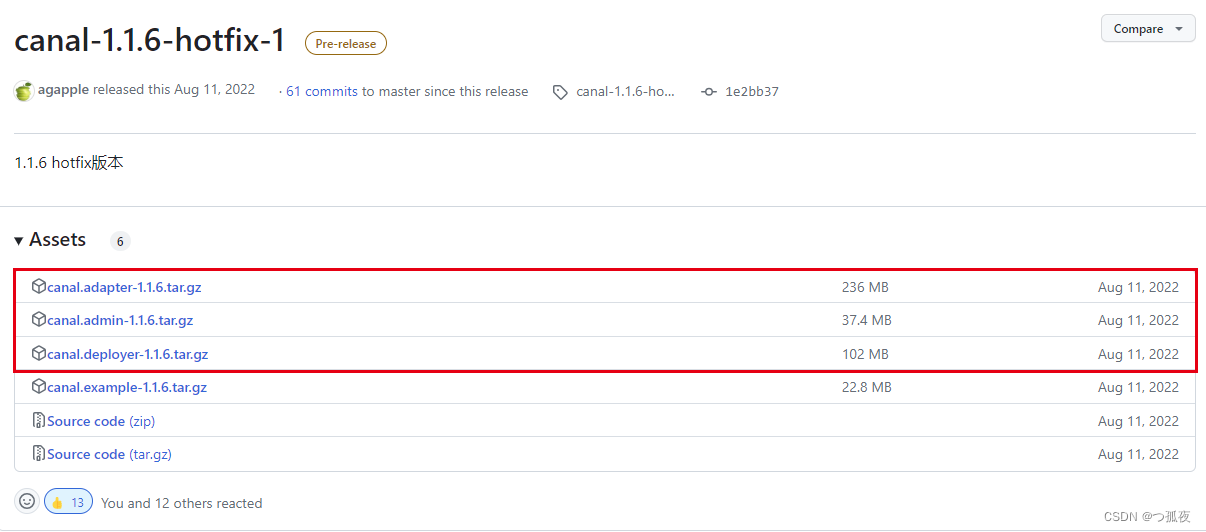
一、canal下载
下载地址:
https://github.com/alibaba/canal/releases/tag/canal-1.1.6-hotfix-1
二.can-admin部署
1. 解压到admin文件夹
tar -zxvf canal-admin-1.1.6.tar.gz -C admin
2. 修改配置文件
vim conf/application.yml
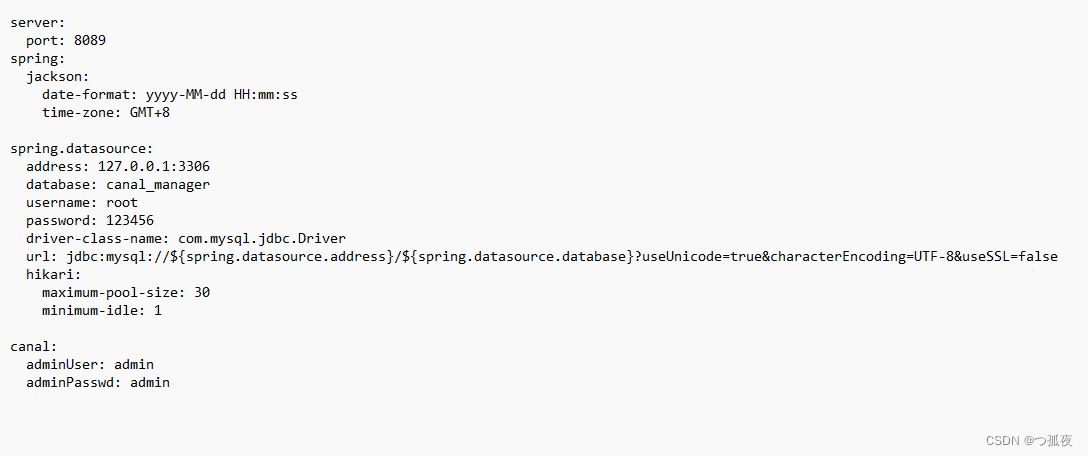
注意:(1)准备一个mysql数据库,执行admin下的canal_manager.sql为管理库
(2) 配置address、username、password为管理库地址、账号、密码 即可
3. 启动admin服务
./bin/startup.sh
4.启动成功管理界面
初始账号/密码:admin/123456

以上界面代表admin部署成功,
三、canal-deployer部署
1. 解压到adeployer文件夹
tar -zxvf canal-deployer-1.1.6.tar.gz -C deployer
2. 修改配置文件
删除原有canal.properties文件,修改canal_local.properties文件名为canal.properties
vim conf/canal.properties

注意:(1)修改manager为admin地址,账号密码默认即可
3. 启动adeployer服务
./bin/startup.sh
启动成功日志不报错即可。
4.启动成功界面
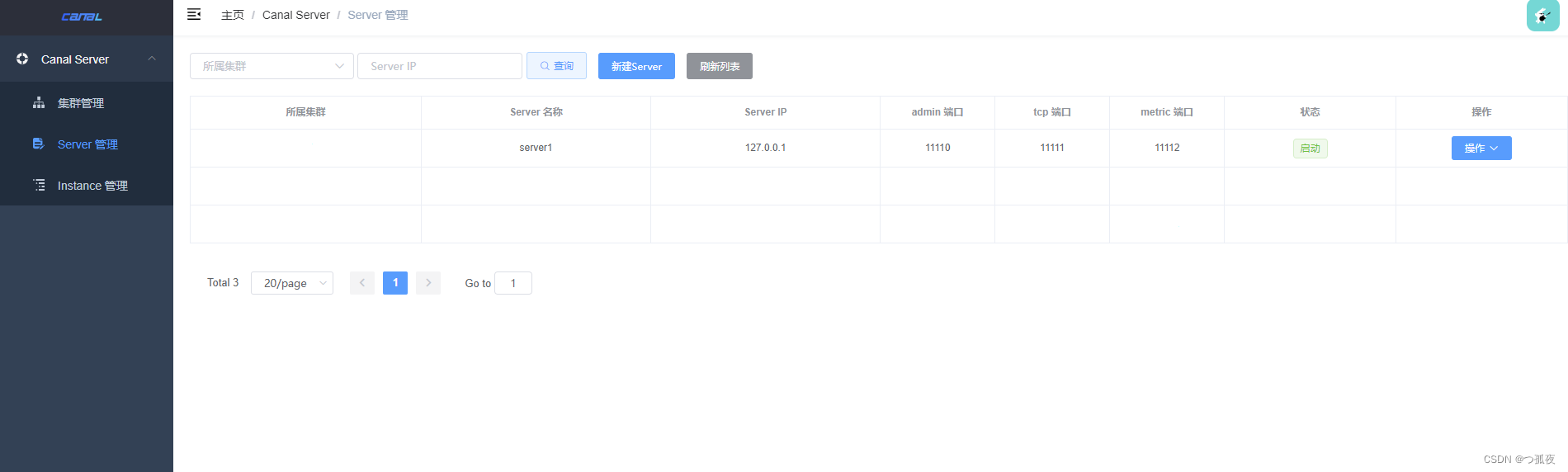
启动成功后即可在admin管理界面查看到server为启动状态
4.配置Instance实例

注意:Instance实例只需修改slaveId、address、username、password等数据库连接信息,多个实例的slaveId不能重复,且不能和mysql的slaveId重复
1.如果需要指定同步的binlog日志,配置:
canal.instance.master.journal.name 日志名称
canal.instance.master.position 日志偏移量
2.如果需要指定同步时间戳
canal.instance.master.timestamp 时间戳
四、canal-adapter部署
1. 解压到adapter文件夹
tar -zxvf canal-adapter-1.1.6.tar.gz -C adapter
2. 修改配置文件
删除原有canal.properties文件,修改canal_local.properties文件名为canal.properties
vim conf/canal.properties
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_nullcanal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ
flatMessage: true
batchSize: 500 #每次获取的数据大小,单位为 k
syncBatchSize: 1000 #每次同步的批数量
retries: 5 #重试次数,-1为无限次
timeout: 60000 #超时时间
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer
canal.tcp.server.host: #对应单机模式下的canal
# canal.tcp.zookeeper.hosts: # 对应集群模式下的zk地址, 如果配置了
canal.tcp.batch.size: 500 #每次获取的数据大小,单位为 k
#canal.tcp.username:
#canal.tcp.password:
srcDataSources:
defaultDS:
url: jdbc:mysql://localhost:3306/mysql?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password: 123456
canalAdapters:
- instance: test # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: logger
- name: es7 # es6 or es7
key: exampleKey # 配置key
hosts: http://localhost:9200 # 集群地址,逗号隔开
mode: rest # rest or transport
# security.auth: test:123456 # only used for rest mode
cluster.name: es7
3.配置查询sql
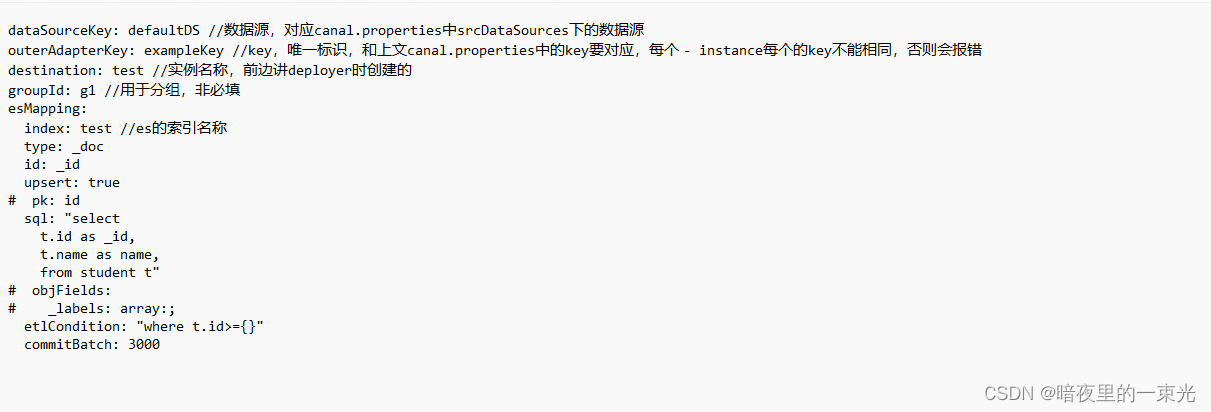
4. 启动adapter服务
./bin/startup.sh
启动成功日志不报错即可。
以上即是单机模式下canal的配置部署了,一定要熟练掌握!
三、HA模式
单机模式多用于测试、练习等场景,在生产中多用HA模式保证高可用。基础的配置和搭建这里不再赘述,不懂得同学请先看单机部署。
首先准备3个服务器:
192.168.40.111
192.168.40.112
192.168.40.113
一、zookeeper部署
canal的HA 模式是以主从形式搭建,服务间调用时通过zookeeper获取地址,借助zookeepe做集群管理实现故障转移,当发生故障时集群间重新选主,集群节点推荐为3个。
1. 下载
https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.9.0/apache-zookeeper-3.9.0-bin.tar.gz
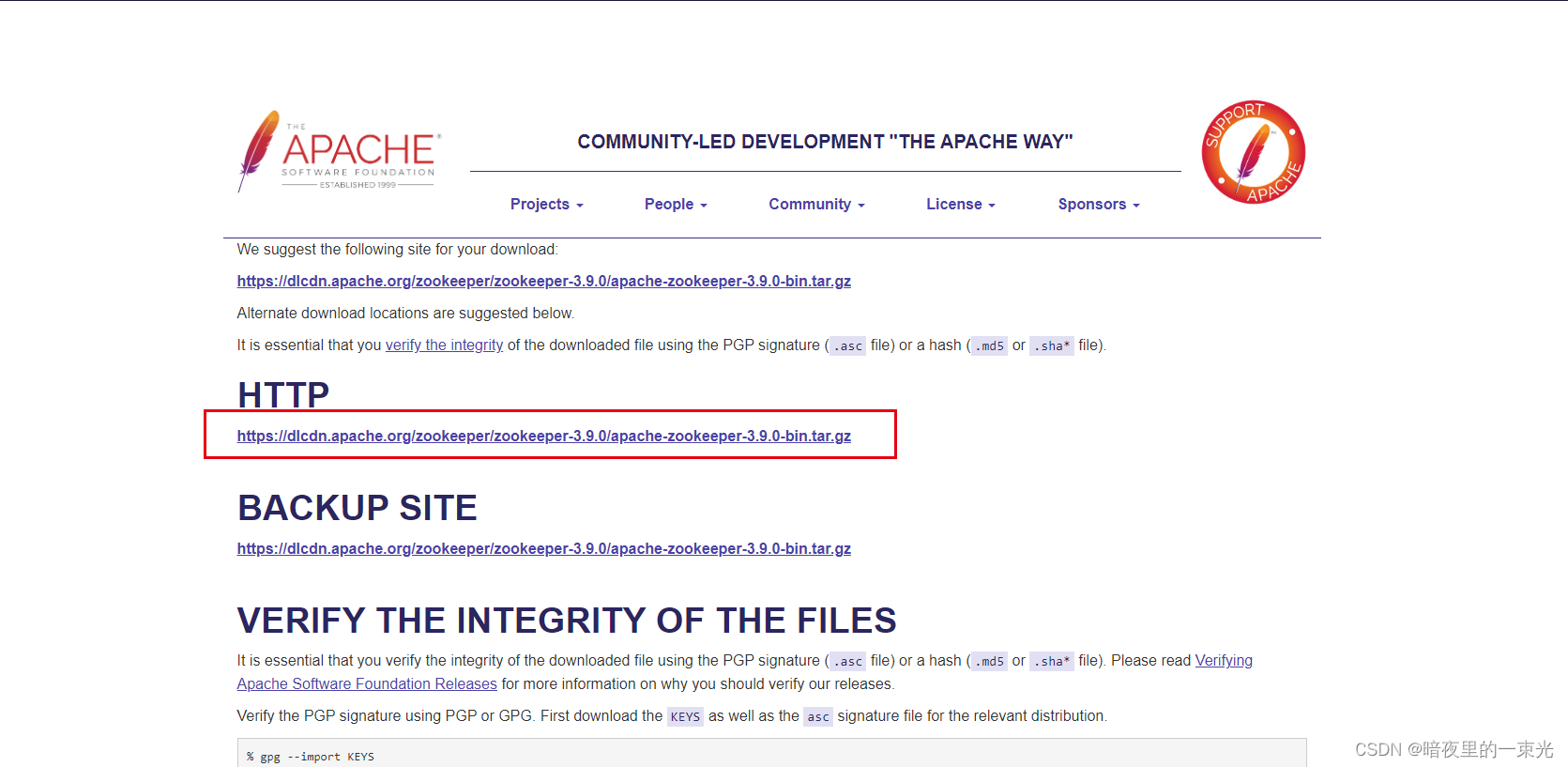
2. 解压
tar -zxvf apache-zookeeper-3.8.1-bin.tar -C zookeeper
3. 配置修改
1.添加配置文件
mv zoo_sample.cfg zoo.cfg
2. 创建data文件夹,修改dataDir路径:
mkdir zkData
3.修改配置文件
vim zoo.cfg
进入zoo.cfg文件:vim zoo.cfg
修改dataDir路径为
dataDir=/opt/zookeeper/zkData
添加集群信息:
server.1=192.168.40.111::3188:3288
server.2=192.168.40.112::3188:3288
server.3=192.168.40.113::3188:3288
4. 添加服务器ID
在每个zookeeper的 zkData目录下创建一个 myid 文件,内容分别是1、2、3 。这个文件就是记录每个服务器的ID。
4. 启动服务
./bin/zkServer.sh start|stop|status|restart
5.设置开机自启
1.配置 Zookeeper 启动脚本
vim /etc/init.d/zookeeper
#!/bin/bash
#chkconfig:2345 20 90
#description:Zookeeper Service Control Script
ZK_HOME='opt/zookeeper'
case $1 in
start)
echo "----------zookeeper启动----------"
$ZK_HOME/bin/zkServer.sh start
;;
stop)
echo "---------- zookeeper停止-----------"
$ZK_HOME/bin/zkServer.sh stop
;;
restart)
echo "---------- zookeeper 重启------------"
$ZK_HOME/bin/zkServer.sh restart
;;
status)
echo "---------- zookeeper 状态------------"
$ZK_HOME/bin/zkServer.sh status
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
2. 设置开机自启
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper
3.启动Zookeeper
service zookeeper start
4. 查看当前状态
service zookeeper status
二、admin添加集群
集群多个zookeeper中间用逗号隔开

三、canal-deployer部署
1. 修改配置文件
在单机版本的配置上添加以下配置:
canal.admin.register.cluster = zk //集群名称
canal.admin.register.name = server1 //server注册到集群的名称
canal.zkServers=192.168.40.111:2181,192.168.40.112:2181,192.168.40.113:2181 //zk地址
canal.instance.global.spring.xml = classpath:spring/default-instance.xml //集群固定配置
注意:每个server都要添加,然后重启
2. 重启deployer
./bin/restart.sh
重启完成后,在admin控制界面查看:

四、canal-adapter部署
1.修改配置文件
主要在canal.tcp.zookeeper.hosts中添加zookeeper的配置
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_nullcanal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ
flatMessage: true
batchSize: 500 #每次获取的数据大小,单位为 k
syncBatchSize: 1000 #每次同步的批数量
retries: 5 #重试次数,-1为无限次
timeout: 60000 #超时时间
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer
# canal.tcp.server.host: #对应单机模式下的canal
canal.tcp.zookeeper.hosts: 192.168.40.111:2181,192.168.40.112:2181,192.168.40.113:2181
canal.tcp.batch.size: 500 #每次获取的数据大小,单位为 k
#canal.tcp.username:
#canal.tcp.password:
srcDataSources:
defaultDS:
url: jdbc:mysql://localhost:3306/mysql?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password: 123456
canalAdapters:
- instance: test # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: logger
- name: es7 # es6 or es7
key: exampleKey # 配置key
hosts: http://localhost:9200 # 集群地址,逗号隔开
mode: rest # rest or transport
# security.auth: test:123456 # only used for rest mode
cluster.name: es7
2. 重启adapter服务
./bin/restart.sh
总结:以上就是HA模式全部搭建完成了,需要在ES创建索引才可以顺利同步。
四、 手动同步数据
一、 查看开关状态
curl http://127.0.0.1:8081/syncSwitch/canal-test
/**
* 获取实例开关状态 curl http://127.0.0.1:8081/syncSwitch/example
*
* @param destination 实例名称
* @return
*/
@GetMapping("/syncSwitch/{destination}")
public Map<String, String> etl(@PathVariable String destination)
二、同步开关
curl http://127.0.0.1:8081/syncSwitch/canal-test/off -X PUT
/**
* 实例同步开关 curl http://127.0.0.1:8081/syncSwitch/example/off -X PUT
*
* @param destination 实例名称
* @param status 开关状态: off on
* @return
*/
@PutMapping("/syncSwitch/{destination}/{status}")
public Result etl(@PathVariable String destination, @PathVariable String status)
三、手动同步数据
1. 全量,不传参数
curl http://127.0.0.1:8081/etl/es7/test-user/test_user.yml -X POST
2. 指定参数
curl http://127.0.0.1:8081/etl/es7/test-user/test_user.yml -X POST -d "params=1273;1275"
/**
* ETL curl http://127.0.0.1:8081/etl/rdb/oracle1/mytest_user.yml -X POST
*
* @param type 类型 hbase, es
* @param key adapter key
* @param task 任务名对应配置文件名 mytest_user.yml
* @param params etl where条件参数, 为空全部导入,匹配etlCondition中的参数,使用;分号多个值
*/
@PostMapping("/etl/{type}/{key}/{task}")
public EtlResult etl(@PathVariable String type, @PathVariable String key, @PathVariable String task, @RequestParam(name = "params", required = false) String params)
五、常见问题
问题一、ERROR c.a.otter.canal.adapter.launcher.loader.AdapterProcessor - java.lang.ArrayIndexOutOfBoundsException: Index 164 out of bounds for length 163
答:上述问题由于adapter中多个instance的key一样导致,修改不同key值即可。
问题二、ERROR c.a.otter.canal.client.adapter.es7x.etl.ESEtlService - java.net.SocketTimeoutException: 30,000 milliseconds timeout on connection http-outgoing-0 [ACTIVE]
答:上述问题由于adapter中配置batchSize和syncBatchSize过大,ES同步超时导致,降低这两参数即可。
问题三、报错Elasticsearch exception [type=index_not_found_exception, reason=no such index [XXXX]]
答:该问题由于ES索引未创建导致
问题四、 ERROR c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Load canal adapter: es failed
答:该问题由于配置文件未在ES文件夹下读取对应配置文件报错。亲测放在ES7或者ES6文件夹下可以读取,子文件夹无法读取。
问题五、ERROR c.a.otter.canal.server.netty.handler.SessionHandler - something goes wrong with channel:[id: 0x58f255d8, /192.168.47.232:59420 :> /192.16
8.47.243:11111], exception=java.nio.channels.ClosedChannelException
答:由于clent长时间和server没有连接,导致通道断开,再次连接时会报该错,client需做好重试
问题六、ERROR com.alibaba.otter.canal.admin.handler.SessionHandler - something goes wrong with channel:[id: 0x5de58c89, /162.142.125.217:46792 => /115.182.116.18:11110], exception=java.io.IOException: Connection reset by peer
答:该问题大多由于数据库binlog和canal记录的binlog位置不同造成,也会因为canal服务器内存不够导致,建议先检查内存是否充足,然后单机清理meta.dat,HA模式清理zookeeper中记录的节点信息。
问题七、日期格式化
答:下载源码,修改ESSyncUtil中时间格式,重新打包替换adapter中的包即可
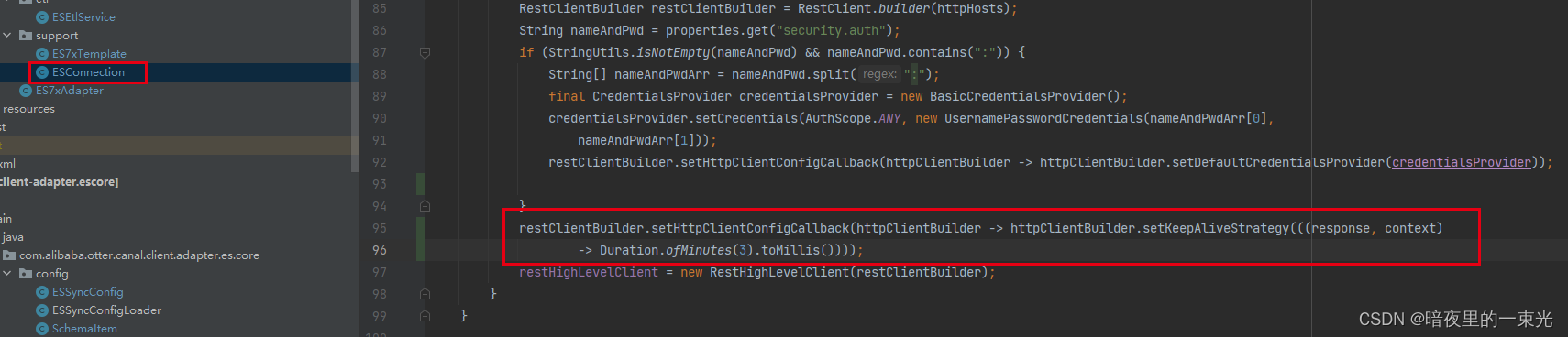
问题八、adapter和ES的链接中断问题,长时间无响应ES会断开连接,再次请求会抛出错误
答:在ESConnection中,修改restClientBuilder.setHttpClientConfigCallback(httpClientBuilder -> httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider)),添加定时发送心跳,如下图
问题九、java.io.IOException: ErrorPacket [errorNumber=1142, fieldCount=-1, message=SHOW command denied to user 'binlog'@'127.0.0.1' for table 'data_trace_zijinjiemi_zhuli', sqlState=42000, sqlStateMarker=#] 6 with command: show create table `cygg`.`data_trace_zijinjiemi_zhuli`
答:修改的库表已删除导致
问题十、Configuration property name ‘-index’ is not valid
答:看源码这个是因为yaml 不兼容以下环线开头的key,在es配置文件中_index _id都是以下划线开头的,所以报错。解决方式两种
1.升级springboot spring core等版本
2.修改源码的yaml配置类esmapping,去掉下划线开头的属性

问题十一、java.lang.RuntimeException: java.lang.NullPointerException
答:该问题大多是由于sql中未起别名,sql中字段和表都需要起别名
问题十二、()L java/nio/ByteBuffer
答:jdk版本过低,提升jdk为11即可
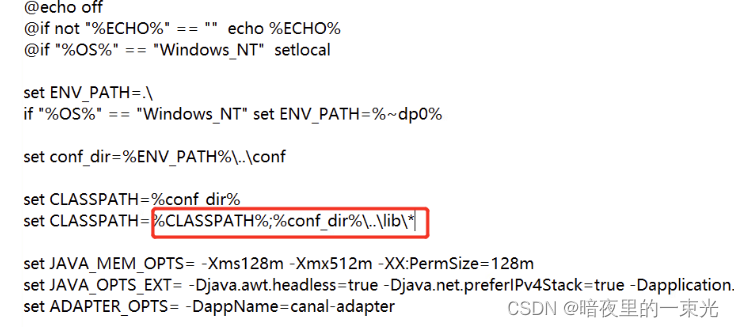
问题十三、config dir not found
答:在bin目录下startup.bat中,替换classpath的值,分号前后调换一下
问题十四、RuntimeException: java.lang.RuntimeException: No data source found: xxxx
答:dataSourceKey名称配置错误
问题十五、Unknown system variable 'query_cache_size'
答:替换mysql的驱动包为mysql8即可
问题十六、 javanio.Bytebuffer.clear()Ljava/nio/Bytebuffer
答:jdk8会报这个错,升级jdk版本,最低11即可
————————————————
版权声明:本文为CSDN博主「暗夜里的一束光」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
















 1076
1076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









