






摘要
目前的深度学习的视频去雨方法主要有两个缺点:
(1)大多数不足以模拟雨天视频中包含的雨层特征。
(2)当前的深度学习方法严重依赖于标记的训练数据,其雨层是合成的,导致与真实数据的偏差。
S2VD解决了这些问题:首先使用了一个动态降雨发生器(dynamical rain generator)来合成降雨层。而动态生成器(dynamical generator)由一个发射模型(emission model)和一个过渡模型(transition model)构成。分别同时编码雨纹的空间外观和时间动态,同时这两个模型均由深度神经网络(DNN)参数化。
介绍
雨纹,在过去几年中,已经探索了许多视觉特征,如光度外观、几何特征、色度一致性、局部结构相关性和多尺度卷积稀疏编码。与降雨条纹的这些确定性假设不同,Wei等人首先将其视为随机变量,并使用高斯混合模型(GMM)对其进行拟合。尽管这些传统方法在某些理想情况下被证明是有效的,但它们主要受到主观手动设计的先验知识和巨大计算负担的限制。
由于DNN强大的非线性拟合能力,基于DL的方法促进了视频去雨任务的显著改进。该方法的核心思想是以端到端的方式基于合成雨/清楚视频对直接训练由DNNs参数化的去雨器。这些方法大多利用不同的技术,例如超像素对齐、双水平流和自学习,从雨天视频中提取干净的背景。此外,Liu等人设计了一个循环网络,以联合执行雨水退化分类和雨水清除任务。
尽管基于DL的方法在去雨结果上取得了一定的改进,但是还有很大的空间去进一步增加在现实场景中的显示和泛化能力。一方面,这些方法大多致力于描述背景,而忽视了对雨层固有特征的建模。事实上,视频中的雨层是一个雨纹的图像序列,可以用时空过程来表示。具体而言,每个时间帧中随机散布的雨纹在空间维度上具有明显的视觉特性(如方向、尺度和厚度),不同时间帧中的雨层对应于沿时间维度的连续时间序列,显示了降雨动力学的因果特性(如速度和加速度)。因此,在视频数据中精心表示和利用雨层的这些固有物理特性有望促进雨水清除任务。
另一方面,众所周知,基于DL的方法的性能严重依赖于大量预先收集的训练数据,即雨/干净的视频对。事实上,由于在真实场景中获取此类视频对的人工成本很高,目前的大多数方法都必须使用合成视频对,这些合成视频对是基于真实感渲染技术或专业摄影和人类监督进行手动模拟的。下图显示了NTURain数据集中合成和真实降雨图像的几个典型帧,该数据集被广泛用作当前视频去噪方法的基准。其中(a1)-(c1):合成雨图像,(a2)(c2):真实雨图像。不难看出,合成和真实降雨图像中的降雨模式明显不同,真实图像包含更复杂和多样的降雨类型。

因此,为了处理一般的视频去雨任务,建立一个合理的半监督学习框架,充分利用标记合成和未标记真实数据中的公共知识至关重要。为了解决这些问题,本文提出了一种半监督视频降额方法,其中采用动态降雨发生器模拟视频中雨层的生成过程,希望能够更好地同时从空间和时间维度获取内在知识。此外,在我们的模型中,真实的雨天视频被视为未标记数据,以获得更稳健的降额结果。
首先,我们提出了一种新的概率视频去雨方法,其中采用由过渡模型(Transition model)和发射模型(emission model)组成的动态降雨发生器(dynamical rain generator)来拟合视频中的降雨层。具体而言,过渡模型用于表示低维状态空间中的降雨动态,而发射模型则试图从状态空间生成图像空间中观察到的降雨条纹。为了提高这种动态降雨发生器的容量,过渡模型和排放模型均采用DNNs参数化。其次,通过构造带标记的合成数据和未标记的真实数据的不同先验格式,设计了一种半监督学习机制。具体而言,对于标记的合成数据,相应的地面实况无雨视频作为强约束包含在精细的先验分布中。
对于未标记的真实数据,我们引入了三维马尔可夫随机场(MRF)来建模底层背景的时间一致性和相关性。第三,设计了基于蒙特卡罗的EM算法来学习模型。在期望步骤中,由于使用DNN对生成器和去雨器进行参数化,潜在变量的后验值很难确定,因此采用朗之万动力学来逼近期望值。
半监督视频去雨模型
给定一个标记的数据集D={y,x}以及未标记的数据集U,其中y代表下雨的视频,x代表清晰的无雨视频。论文的目标是在此基础上构建一个半监督概率模型,然后设计一个EM算法来学习该模型。
设Y表示D或U中的任何雨视频,其中Yt是第t个图像帧。我们将下雨视频Y分解为三个部分,其中f(Y;W)、R和E分别是恢复的无雨背景、雨层和残差项,Eijt是位置(i,j,t)处的E元素。
假设残差项遵循方差为σ^2的零均值高斯分布。f(·;W),由DNNs参数化,表示将观测到的降雨视频映射到底层无雨背景的函数,在本文中称为“derainer”。接下来,我们考虑如何建模derainer参数W和雨层R。
背景层建模
众所周知,视频数据的一个一般先验知识是,无雨背景视频在空间和时间维度上具有很强的相关性和相似性。因此对于任意的下雨视频y、 我们通过以下MRF先验分布对此类知识进行编码:
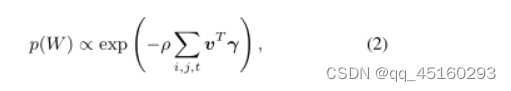
至于雨天视频Y∈ D、 已知的无雨背景X可以作为另一强先验信息进一步嵌入上述式子中。而derainer使用了一种简单的网络结构如下图所示:

在没有任何特殊设计的情况下,它只包含几个三维卷积层和剩余块。为了加快计算速度,在网络的头部和尾部分别添加了pixel-unshuffle 和 pixel-shuffle。
降雨层建模
直观地说,雨层是一个动态序列,因此论文中采用统计学中的时空过程来描述它。让我们使用Rt来表示雨层序列R的第t个图像帧,然后我们的动态降雨生成器可以公式化如下:

st表示第t帧中的隐藏状态变量,zt表示噪声向量。具体而言,等式(4)是具有参数α的过渡模型,期望描述降雨随时间的动态,等式(5)是具有将隐藏状态空间映射到降雨层空间的参数β的发射模型。注意,噪声向量彼此独立,每个zt对从st过渡到t的时间t影响降雨的随机因素(例如,风、摄像机运动等)进行编码st−1至st。
此外,可以将生成器扩展到用于多个雨水视频的高级版本。具体地,对于第i个雨视频Ri,将另一个向量m~N(0,I)引入来解释不同视频中降雨出现或模式的变化,因此等式(4)的过渡模型可以重新表示为:
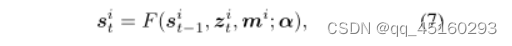
其中第i个rain视频的mi是固定的。为了便于记录,我们编写了等式。(7) 和(5)一起如下所示:
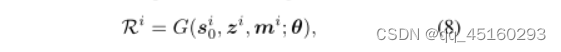
在实践中,我们使用公式(8)的扩展版本来同时拟合每个小批量视频数据中的雨层。
为了提高这种动态降雨发生器的容量,我们通过DNNs对过渡模型和发射模型进行参数化。我们使用下图中的两层多层感知器(MLP)作为过渡模型。

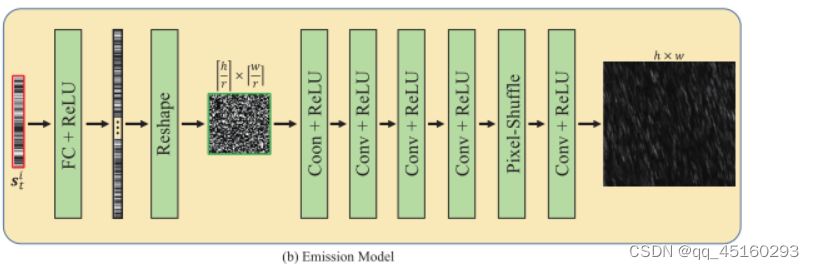
至于发射模型,论文设计了一个CNN架构,该架构将状态变量st作为输入并输出雨图像,如下所示,其主要灵感来自最近的一项工作,该工作使用CNN作为潜在变量模型来生成雨条纹。
Maximum A Posteriori Estimation(最大后验估计)
结合等式(1) -(6)获得了视频去雨的全概率模型。然后我们的目标转向最大化模型参数w和θ的后验值w.r.t
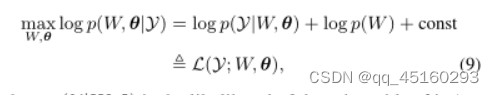
其中p(Y|W,θ)是下雨视频Y的可能性。根据等式。(1) 和(8)可以写成:
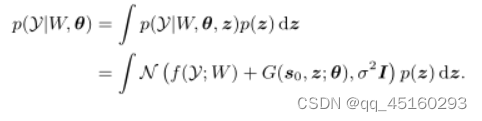
最后,我们在整个标记和未标记数据集上直接优化等式(9)的问题,即:
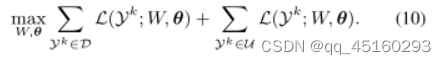
等式(10)是基于D和U中的大量数据样本,学习从下雨视频到干净视频的一般映射,这有望获得比在单个视频上实现的传统推理范式更有效、更稳健的去雨器。最值得注意的是,如果只考虑标记数据集,我们的方法自然退化为监督去雨模型。然而,涉及未标记的真实数据可以提高模型的泛化能力,从而可以应用于真实情况。
Inference and Learning Algorithm(推理和学习算法)
受时间交替反向传播技术的启发,设计了一种基于蒙特卡洛的EM算法来最大化L(Y;W,θ),其中期望步骤从后验分布p(z|Y)中采样潜变量z,最大化步骤基于推断的潜变量z更新模型参数W和θ。
E-step
假设(W^ old,θ^ old)和pold(z|Y)表示当前模型参数及其下的后验值,我们可以使用Langevin动力学从pold(z| Y)中采样z

τ指数是朗之万动力学的时间步长,δ表示步长,ξ(τ)是高斯白噪声,用于避免陷入局部模式。计算公式(11)的关键点是:∂/∂zlog(z|Y)=∂/∂z logpold(Y,z)和右项可以很容易地计算。在实践中,为了避免MCMC的高计算成本,在每次学习迭代中,等式(11)从z的先前更新结果开始。至于等式(8)中的初始状态向量s0和降雨变化向量m,因为它们也是我们模型中的潜变量,我们使用朗之万动力学将它们与z一起采样。
M-step
将E-Step中的采样潜变量表示为z,M-Step旨在最大化近似下界w.r.t w和θ,如下所示: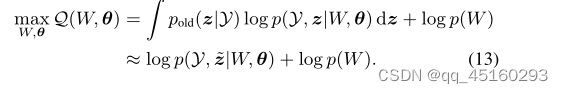
等价地,等式(13)可以进一步改写为以下最小化问题:
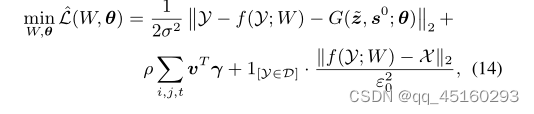
其中1[Y∈D] 当Y来自标记数据集D时等于1,否则为0。自然,我们可以基于反向传播(BP)算法通过梯度下降更新W和θ,如下所示:
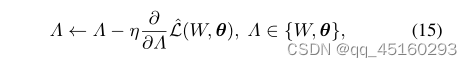
其中η表示步长。
仅使用等式(8)中定义的一个生成器很难在所有训练视频中拟合雨层。因此,论文中为每个小批量数据训练一个生成器。有了这种策略,我们的模型在所有实验中都表现良好。最小批量为12。算法1中给出了所提出算法的详细描述。















 584
584











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









