







滚动到最底下显示全部200本书
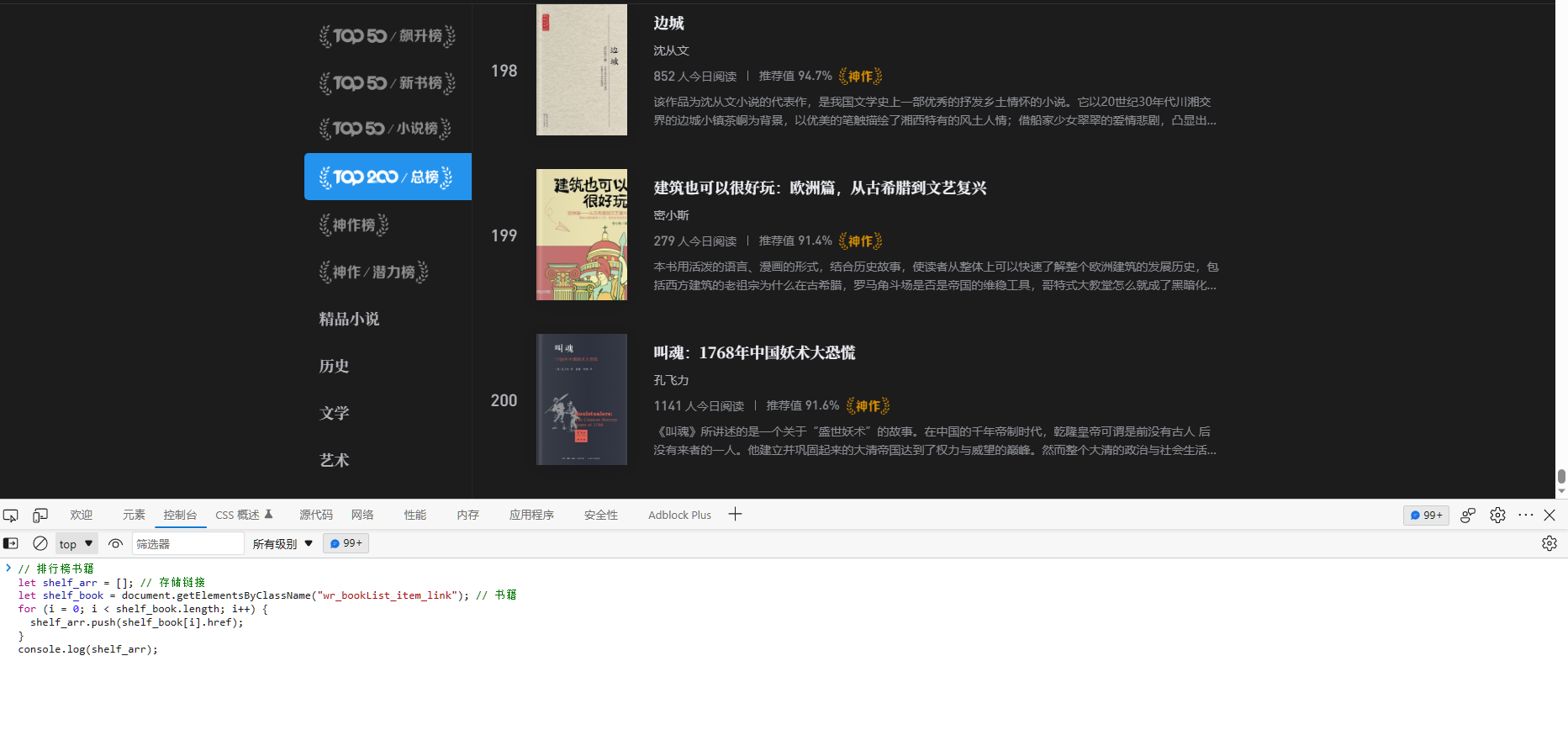
// 排行榜书籍
let shelf_arr = []; // 存储链接
let shelf_book = document.getElementsByClassName("wr_bookList_item_link"); // 书籍
for (i = 0; i < shelf_book.length; i++) {
shelf_arr.push(shelf_book[i].href);
}
console.log(shelf_arr);

复制object替换代码中的shelf_arr
import re
import requests
from bs4 import BeautifulSoup
# 爬取微信读书书架书籍字数,此处自行替换
shelf_arr = [
"https://weread.qq.com/web/bookDetail/cc932860813ab67c2g014597",
"https://weread.qq.com/web/bookDetail/ce032b305a9bc1ce0b0dd2a",
"https://weread.qq.com/web/bookDetail/a57325c05c8ed3a57224187",
] # 分组所有书籍
target_arr = [] # 书名+字数
for link in shelf_arr:
req = requests.get(url=link)
req.encoding = "utf-8"
html = req.text
soup = BeautifulSoup(req.text, features="html.parser")
book_titles = soup.find_all(
"h2", class_="bookInfo_right_header_title_text") # 书名
book_nums = soup.find_all("div", "introDialog_content_pub_line") # 字数
for book_title in book_titles:
book_title_handle = "书名: " + book_title.text.strip()
for book_num in book_nums:
book_num_handles = book_num.find_all("span")
for book_num_handle in book_num_handles:
book_num_handle = book_num_handle.text.strip()
# 判断字数
target_str = re.search(r",", book_num_handle)
if target_str != None:
book_num_handle = book_num_handle.replace(
book_num_handle, book_num_handle.replace(",", "")) # 去除逗号
target_arr.append(book_title_handle)
target_arr.append(book_num_handle)
# 判断字数
with open("./文本.txt", 'w', encoding='utf-8') as fw:
# 将列表转换为字符串,并使用 join() 方法连接起来
target_str = '\n'.join(target_arr)
# 将字符串写入文件
fw.write(target_str)
# 按照书籍字数从小到大排列
target_num = []
for i in range(len(target_arr)):
if i % 2 != 0:
target_num.append(int(target_arr[i]))
target_num.sort()
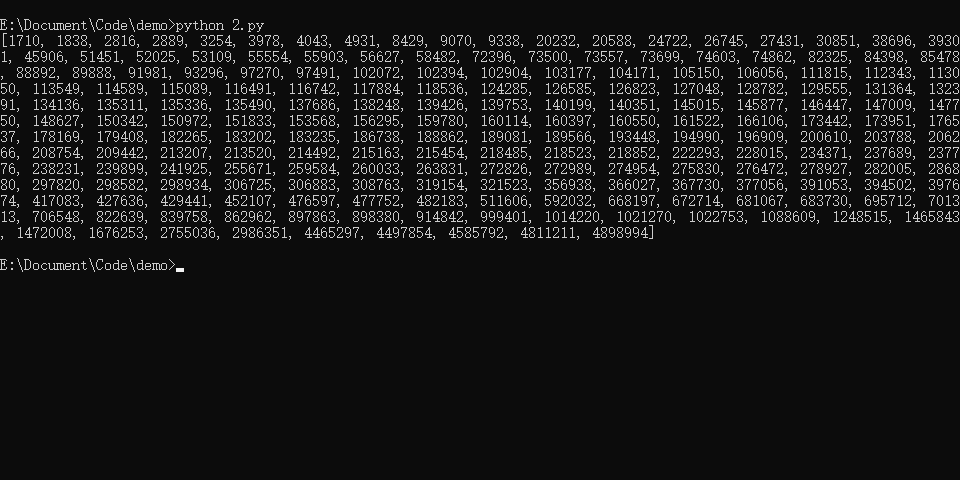
print(target_num)
字数从小到大输出结果如下
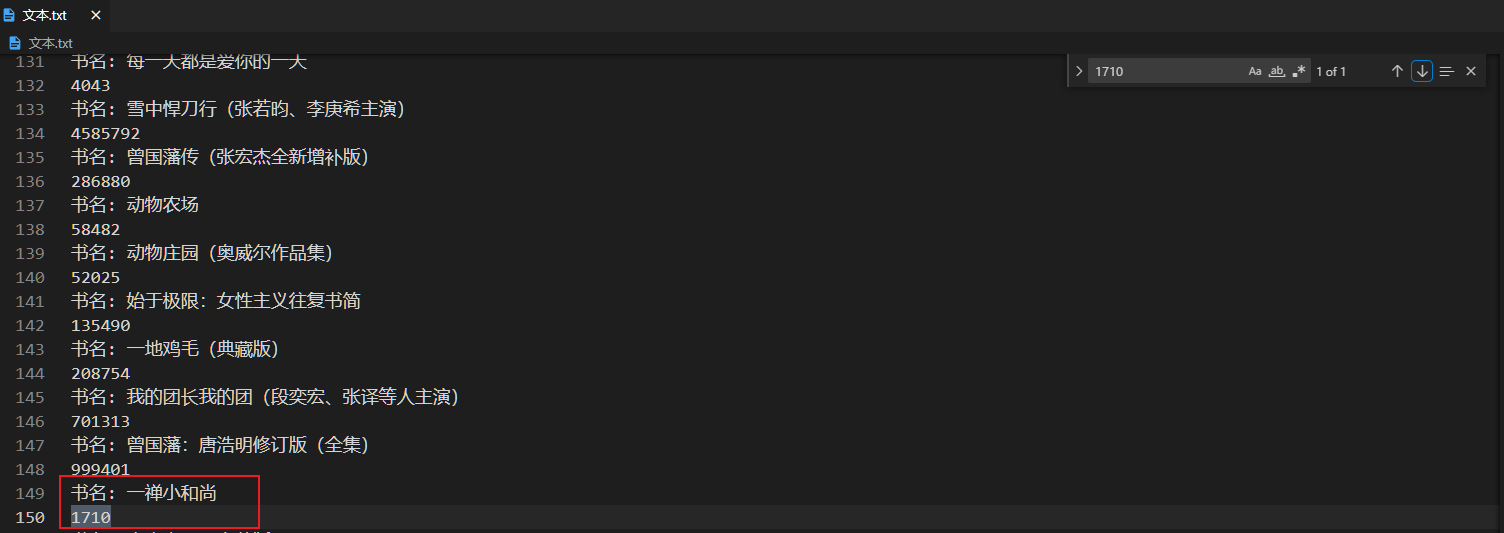
直接在文本.txt查找字数即可找到书名


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









