







 本文介绍了一种使用Python和XPath的豆瓣图书爬虫实现方法,详细展示了如何抓取图书名称、链接、出版信息、评分、评价人数及简介,并提供了完整的代码示例。
本文介绍了一种使用Python和XPath的豆瓣图书爬虫实现方法,详细展示了如何抓取图书名称、链接、出版信息、评分、评价人数及简介,并提供了完整的代码示例。
实现目标
- 查询书名
- 查询详情页链接
- 评价人数
- 豆瓣评分
- 简介
- 出版信息
实现方式
- python3
- xpath
创作截图(部分)
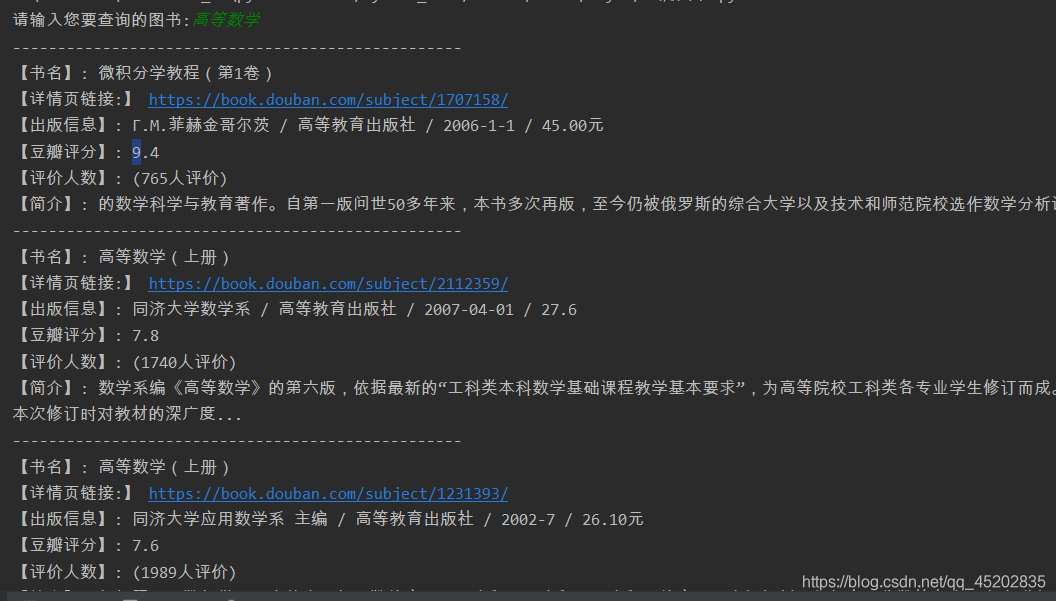
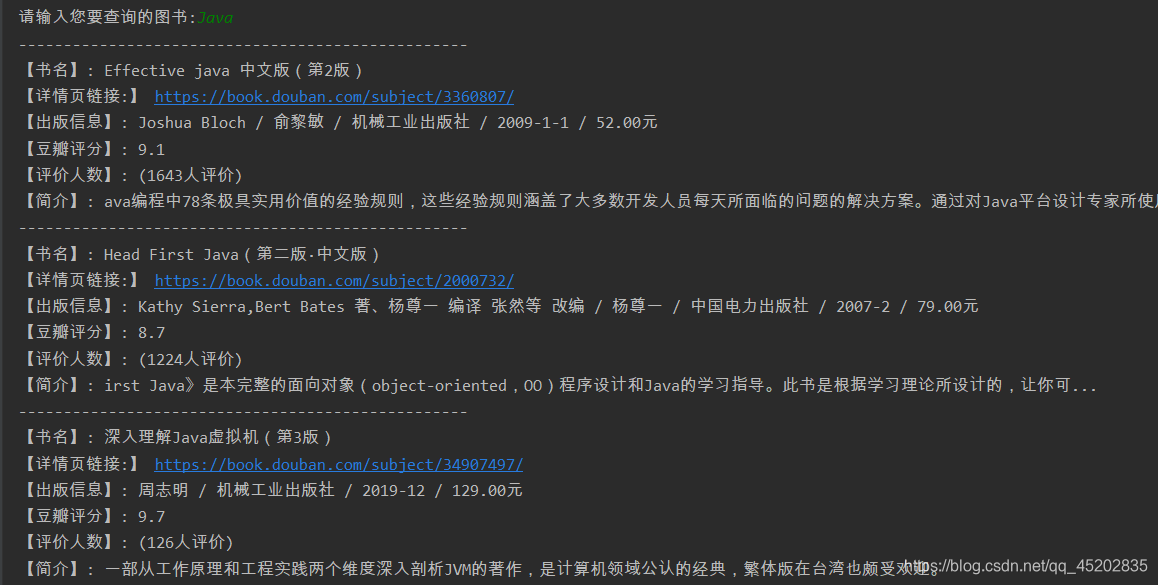
实现代码
import requests
from lxml import etree
def main():
# 豆瓣图书爬取信息的标签以及页数
url = 'https://book.douban.com/tag/%s?start={}&type=T' % name
# 请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'Upgrade-Insecure-Requests': '1',
}
for i in range(2):
# 发送请求
url = url.format(i)
response = requests.get(url, headers=headers).text
# xpath的解析
html = etree.HTML(response)
# 获取书籍详情页链接
base_url = html.xpath('//ul[@class="subject-list"]/li/div[@class="info"]/h2/a/@href')
# 获取书名
bookname = html.xpath('//ul[@class="subject-list"]/li/div[@class="info"]/h2/a/@title')
# 获取出版信息
pub = html.xpath('//ul[@class="subject-list"]/li/div[@class="info"]/div[@class="pub"]')
# 豆瓣评分
rating = html.xpath(
'//ul[@class="subject-list"]/li/div[@class="info"]/div[@class="star clearfix"]/span[@class="rating_nums"]')
# 评价人数
nums = html.xpath(
'//ul[@class="subject-list"]/li/div[@class="info"]/div[@class="star clearfix"]/span[@class="pl"]')
# 简介
page = html.xpath('//ul[@class="subject-list"]/li/div[@class="info"]/p/text()')
# 存储信息
for cnt in range(20):
book = {}
try:
book['【书名】:'] = bookname[cnt]
book['【详情页链接:】'] = base_url[cnt]
book['【出版信息】:'] = pub[cnt].text.strip()
book['【豆瓣评分】:'] = rating[cnt].text
book['【评价人数】:'] = nums[cnt].text.strip()
book['【简介】:'] = page[cnt][7:].strip()
booklist.append(book)
except Exception:
continue
def display():
print('-' * 50)
for book in booklist:
for k, v in book.items():
print(k, v)
print('-' * 50)
if __name__ == '__main__':
name = input("请输入您要查询的图书:")
booklist = []
main()
display()

















 1208
1208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









