






Levenshtein Distance莱文斯坦距离
指的是两个字串之间,由一个转成另一个所需的最少编辑操作次数。允许的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
Levenshtein Distance莱文斯坦距离Java代码
public class LevenshteinDistanceUtil {
public static void main(String[] args) {
String a = "武汉市青山区棚改项目";
String b = "大武汉市棚改项目";
System.out.println("相似度:" + getSimilarityRatio(a, b));//相似度:0.6
}
/**
* 获取两字符串的相似度
*
* @param str
* @param target
* @return
*/
public static float getSimilarityRatio(String str, String target) {
int max = Math.max(str.length(), target.length());
System.out.println("两个字符串中最大长度:" + max);//两个字符串中最大长度:10
System.out.println("莱茵斯坦距离:" + compare(str, target));//莱茵斯坦距离:4
return 1 - (float) compare(str, target) / max;
}
/**
* 获取莱茵斯坦距离d[n,m]
*
* @param str
* @param target
* @return
*/
private static int compare(String str, String target) {
int d[][];// 矩阵
int n = str.length();
int m = target.length();
int i; // 遍历str的
int j; // 遍历target的
char ch1;// str的
char ch2;// target的
int temp;// 记录相同字符在某个矩阵位置值的增量,不是O就是1
if (n == 0) {
return m;
}
if (m == 0) {
return n;
}
d = new int[n + 1][m + 1];
// 初始化第一列
for (i = 0; i <= n; i++) {
d[i][0] = i;
}
// 初始化第一行
for (j = 0; j <= m; j++) {
d[0][j] = j;
}
// 遍历str
for (i = 1; i <= n; i++) {
ch1 = str.charAt(i - 1);
// 去匹配target
for (j = 1; j <= m; j++) {
ch2 = target.charAt(j - 1);
if (ch1 == ch2 || ch1 == ch2 + 32 || ch1 + 32 == ch2) {
temp = 0;
} else {
temp = 1;
}
// 左边+1,上边+1,左上角+temp取最小
d[i][j] = min(d[i - 1][j] + 1, d[i][j - 1] + 1, d[i - 1][j - 1] + temp);
}
}
return d[n][m];
}
/**
* 获取最小值
*
* @param one
* @param two
* @param three
* @return
*/
private static int min(int one, int two, int three) {
return (one = one < two ? one : two) < three ? one : three;
}
}
Levenshtein Distance莱文斯坦距离示例图解
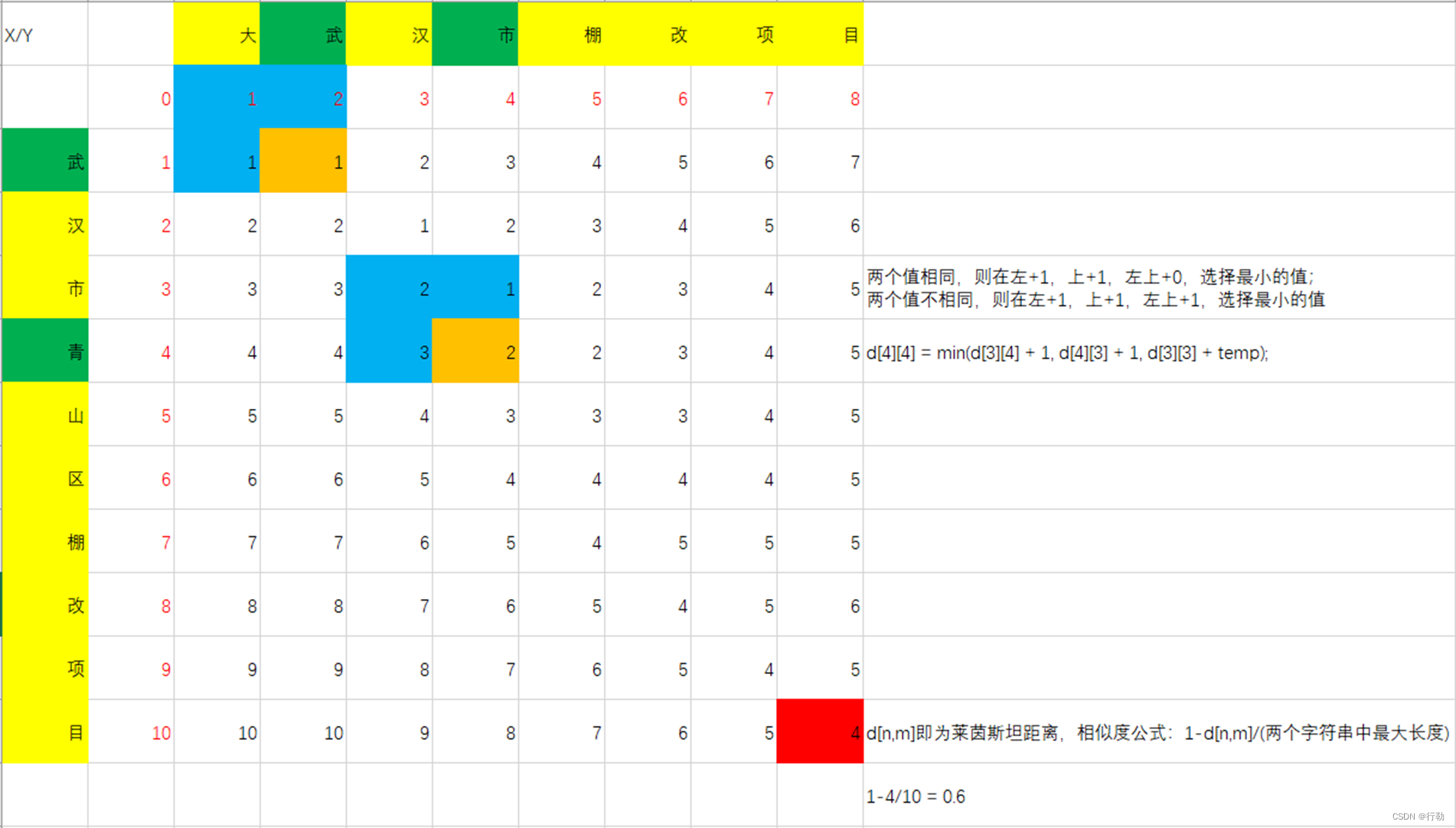
1.示例一
String a = “武汉市青山区棚改项目”;
String b = “大武汉市棚改项目”;
相似度为: 0.6
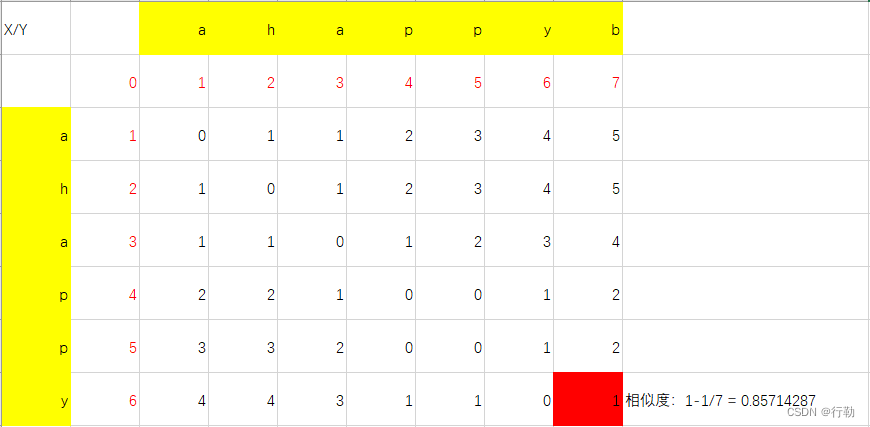
2.示例二
String a = “ahappy”;
String b = “ahappyb”;
相似度为: 0.85714287
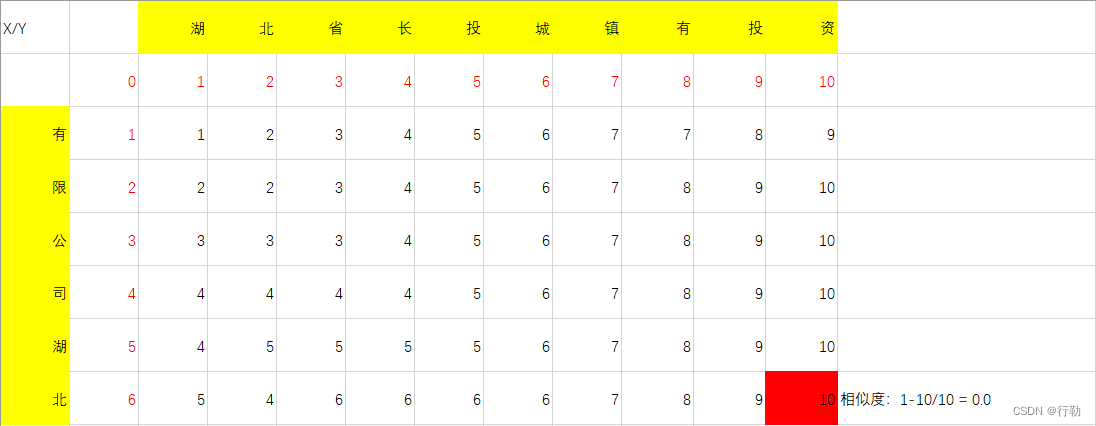
3.示例三
String a = “有限公司湖北”;
String b = “湖北省长投城镇有投资”;
相似度为: 0.0















 1448
1448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









