







Redis 主从复制如何同步数据呢?
参考文章:https://blog.csdn.net/Seky_fei/article/details/106877329
https://zhuanlan.zhihu.com/p/55532249
https://cloud.tencent.com/developer/article/2063597
https://xie.infoq.cn/article/4cffee02a2a12c2450412fa21
在 Redis2.8 之后,进行主从同步使用 psync 命令,在 2.8 之前使用 sync 命令,sync 在断线情况下会进行全量复制,效率很低,因此使用 psync 命令进行改进,具备了 全量同步 和 部分同步 的功能
psync 命令格式如下:
# runid 为 master 的身份 id
# offset 是从节点同步命令的偏移量
psync [runid] [offset]
那么在从节点第一次同步主节点数据时,会向主节点发送 psync ? -1 命令,那么 master 收到命令后,匹配 runid,如果匹配成功,会使用 bgsave 生成 RDB 文件快照,并将 RDB 文件发送给 slave,slave 在收到 RDB 快照后将数据载入
如果从节点是断线之后重新连接上主节点,那么在同步数据时,会向主节点发送 psync runid offset ,那么 master 在收到命令之后,如果 runid 匹配成功,会判断 offset 这个偏移量与 master 本机的数据缓存的偏移量相差是否超过了 复制积压缓冲区 的大小,如果超过了,说明 slave 断线时间太长了,master 的 复制积压缓冲区 中的数据已经和 slave 的数据不连续了,因此进行全量复制;否则,就进行增量复制,将 slave 断线期间没有收到的数据给发送一下就可以了
主节点在接收到命令时,如何保存命令并将命令增量复制给从节点?
master 在接收命令时,将命令传递给 slave 的同时,也会将命令存放到 复制积压缓冲区,并且记录当前积压队列中存放命令的偏移量 offset,当 slave 重连时,master 会根据 slave 传的 offset 和自己最新命令的 offset 进行比较,如果相差的大小超过 复制积压缓冲区 的大小,就直接进行全量复制;否则,就增量复制
复制积压缓冲区 其实就是一个环形的循环队列,默认大小为 1MB,该缓冲区大小越大,允许 slave 断线的时间就越长
#设置复制积压缓冲区大小
repl-backlog-size 1mb
Redis 4.0 PSYNC2.0
在 Redis2.8 之后,使用 psync runid offset 来实现增量同步,但是如果发生了主从切换,那么新的 master 的 runid 和 offset 都会发生变化,因此还是需要全量复制
在 Redis4.0 的 PSYNC2.0 中优化了这个问题,即使发生了主从切换,如果条件允许,也可以进行增量同步
那么在 PSYNC2.0 中,舍弃了 runid 的概念,使用 replid 和 replid2 来代替,并且 replid2 和 second_replid_offset 是一对:
- 对 master 来说,
replid就是自己的复制 id,没有发生主从切换之前,replid2为空,发生主从切换之后,新的 master 的replid2是旧 master 的 replid - 对 slave 来说,
replid保存的是自己当前正在同步的 master 的replid,replid2保存的旧 master 的 replid
second_replid_offset 记录了上一次复制的主库的 offset
psync2.0中如何判断增量复制?
从节点向主节点发送同步请求,那么主节点需要判断两个东西:
-
从节点的 offset 是否在
复制积压缓冲区中 -
判断复制历史是否一样
判断复制历史首先 master 要判断 replid 是否一致,也就是从节点的 replid 和 master 的 replid2 相同,如果一致(表明新的主节点和从节点之前都是复制的同一个主节点),再来判断这个 offset 是否在上一次的 second_replid_offset,如果也在的话,就可以进行增量同步
下边这个例子说明一下为什么 offset 要在上一次的 second_replid_offset 中:
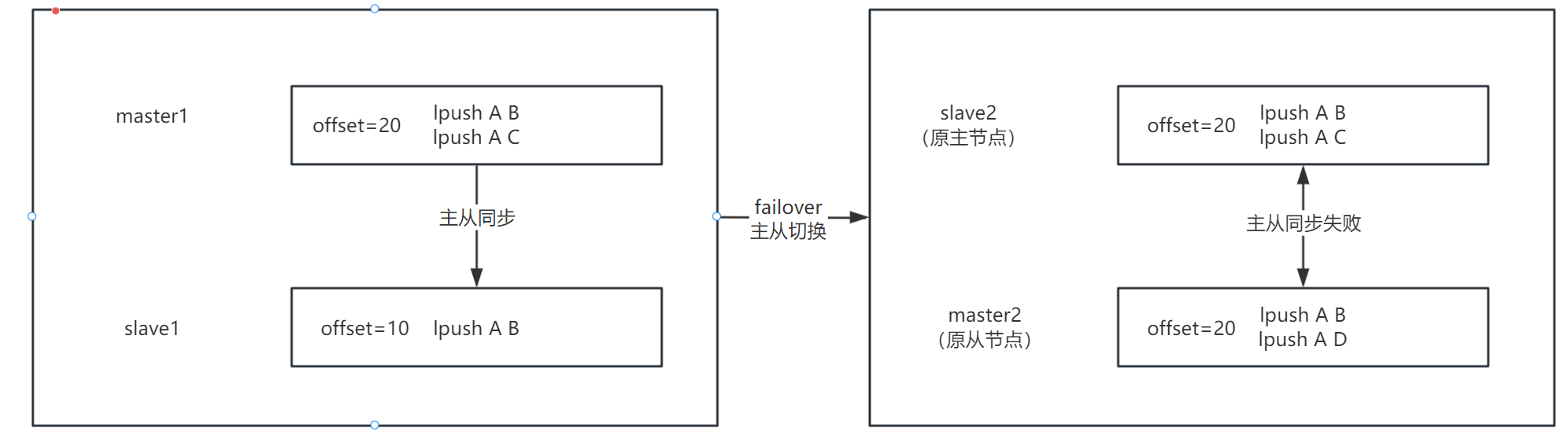
比如一主一从机器来说,master1 和 slave1,master1 中写入两条数据:
# master1
lpush A B
lpush A C
我们假设一条数据偏移量为 10,那么在 master1 中插入两条数据,master1 的 offset = 20,此时 master1 和 slave1 主从复制,slave1 在复制完第一条数据之后,也就是 lpush A B 之后,failover 后 slave1 变为新的 master,我们先称原 slave1 为 master2,原 master1 为 slave2
那么 master2 又会接收新的请求,假如在 master2 中写入如下数据:
# master2
lpush A D
那么此时 master2 中也有两条数据了,如上图,在发生主从切换之后,master2 和 slave2 的 offset 都是 20,是相同的,但是他们两个能进行增量复制吗?
肯定不可以,虽然他们的 offset 是相同的,但是他的复制上下文已经变了,原来的 slave 进行主从复制是基于
lpush A B
lpush A C
这个上下文来进行复制的,那么在主从切换之后,新的主库写入了新的数据,新主库的上下文已经变为了:
lpush A B
lpush A D
和原来主库的上下文都不同了,那么只单纯比较 offset 是没有意义的,所以需要拿 offset 和 second_replid_offset 进行比较
PSYNC-AOF【扩展内容】
百度智能云提出了 - PSYNC-AOF 方案
在 Redis 的主从复制中存在的问题,首先就是内存,Redis 的数据都存储在内存中,Backlog(复制积压缓冲区) 也在内存中,那么内存容量是有限的,当主从连接断开重连后,从库在主库的 Backlog 中查找数据,因为 Backlog 容量是有限的,所以查找数据也有限,那么如果主从断连时间过长的话,就在 Backlog 中找不到对应的数据,就需要进行全量复制了
那么 PSYNC-AOF 方案中,将 AOF 的内容和 Backlog 内容保持一致,主从断连后,从库去主库的 Backlog 中查找数据,那么如果没有找到的话,尝试从 AOF 里找,那么通过 RDB 文件作为基准,AOF 作为增量,就可以实现一个更大的 复制积压缓冲区 ,从而可以应对更长的网络延迟以及网络断开。
总结:总之,主从复制的痛点在于如果主从连接断开时间过长,或者发生主从切换,会导致全量复制,全量复制很伤,所以优化主从数据同步的目的就是尽可能地避免全量复制
















 560
560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











