







欢迎关注公众号 【11来了】 ,持续 MyBatis 源码系列内容!
在我后台回复 「资料」 可领取
编程高频电子书!
在我后台回复「面试」可领取硬核面试笔记!文章导读地址:点击查看文章导读!
感谢你的关注!
MyBatis 源码系列文章:
(一)MyBatis 源码如何学习?
(二)MyBatis 运行原理 - 读取 xml 配置文件
(三)MyBatis 运行原理 - MyBatis 的核心类 SqlSessionFactory 和 SqlSession
(四)MyBatis 运行原理 - MyBatis 中的代理模式
(五)MyBatis 运行原理 - 数据库操作最终由哪些类负责?
(六)MyBatis 运行原理 - 执行 Mapper 接口的方法时,MyBatis 怎么知道执行的哪个 SQL?
JVM 级别缓存能力设计:MyBatis 的一、二级缓存如何设计?
MyBatis 内部有一级缓存和二级缓存的功能,平常我们也知道他的概念:
- 一级缓存是 SqlSession 级别的
- 二级缓存是跨 SqlSession 级别的
但是,还有在实现的过程中还有一些更加细节的内容:缓存生命周期如何设计?什么样的情况下,缓存会失效?如何判断两个 SQL 之间的缓存是否相同?…
因此,接下来会介绍 MyBatis 内部的一、二级缓存如何设计,如何设计不同的类进行分工合作来完成这项缓存工作,这样在以后设计一些本地缓存,都可以借鉴对应的思想!
由于在执行 SQL 查询时,会先查询二级缓存,再查询一级缓存,因此会先介绍二级缓存的实现原理
背景知识
MyBatis 一级缓存默认开启,二级缓存默认关闭
MyBatis 开启二级缓存需要两个步骤:
步骤1:在 mybatis-config.xml 文件中增加配置 cacheEnabled
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>
<!--...-->
</configuration>
步骤2:在 UserMapper.xml 中增加缓存标签 <cache/>
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.github.yeecode.mybatisdemo.UserMapper">
<cache/>
<!--...-->
</mapper>
步骤3:在实体类 User 中添加序列化 Serializable
public class User implements Serializable {
// ...
}
CacheKey
MyBatis 内部缓存都是以 CacheKey 作为 key,因为获取 SQL 的缓存 需要多个条件 来作为唯一标识
如果仅仅使用 SQL 语句作为缓存的 key,会发生什么?
比如使用 SELECT * FROM user where id > ? 作为 key,那么当传入 id 不同,缓存也肯定不同,如果确定 id = 5,使用 SELECT * FROM user where id > 5 作为 key,会导致缓存的 key 粒度被 固定死 ,那么如果同一条 SQL 可能因为某些其他参数的不同导致查询的结果不同,这种场景就无法实现了
因此使用 CacheKey 可以根据传入条件的不同,来动态调整缓存的粒度
因此 MyBatis 包装了 CacheKey 来作为缓存的 key,内部包含了多个参数条件:包括 MappedStatement 的 id、分页参数、原始 SQL、入参等等 ,创建 CacheKey 的方法在 BaseExecutor 中:
// BaseExecutor # createCacheKey
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
CacheKey cacheKey = new CacheKey();
cacheKey.update(ms.getId());
cacheKey.update(rowBounds.getOffset());
cacheKey.update(rowBounds.getLimit());
cacheKey.update(boundSql.getSql());
// ...
// cacheKey 还会关联上运行时参数值
return cacheKey;
}
在 update() 方法中就会去 关联 对应的一个个参数,接下来进入 update() 方法:
// CacheKey # update
public void update(Object object) {
int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object);
count++;
checksum += baseHashCode;
baseHashCode *= count;
hashcode = multiplier * hashcode + baseHashCode;
updateList.add(object);
}
在 update() 方法中,入参就是影响缓存唯一标识的变量,比如关联 MappedStatement 的 id ,会将该变量的 hashCode 也加入到当前 CacheKey 的 hashCode 中,并且通过 count、checksum、baseHashCode 来记录影响 CacheKey 的因素
如下,如果 CacheKey 相同,则说明是同一份缓存数据,这里重写了 equals() 方法,比较了 hashcode、checksum、count 等等多种变量,通过多种比较方式来避免 CacheKey 相等的误判
// CacheKey # equals
public boolean equals(Object object) {
if (this == object) {
return true;
}
if (!(object instanceof CacheKey)) {
return false;
}
final CacheKey cacheKey = (CacheKey) object;
if (hashcode != cacheKey.hashcode) {
return false;
}
if (checksum != cacheKey.checksum) {
return false;
}
if (count != cacheKey.count) {
return false;
}
for (int i = 0; i < updateList.size(); i++) {
Object thisObject = updateList.get(i);
Object thatObject = cacheKey.updateList.get(i);
if (!ArrayUtil.equals(thisObject, thatObject)) {
return false;
}
}
return true;
}
二级缓存能力
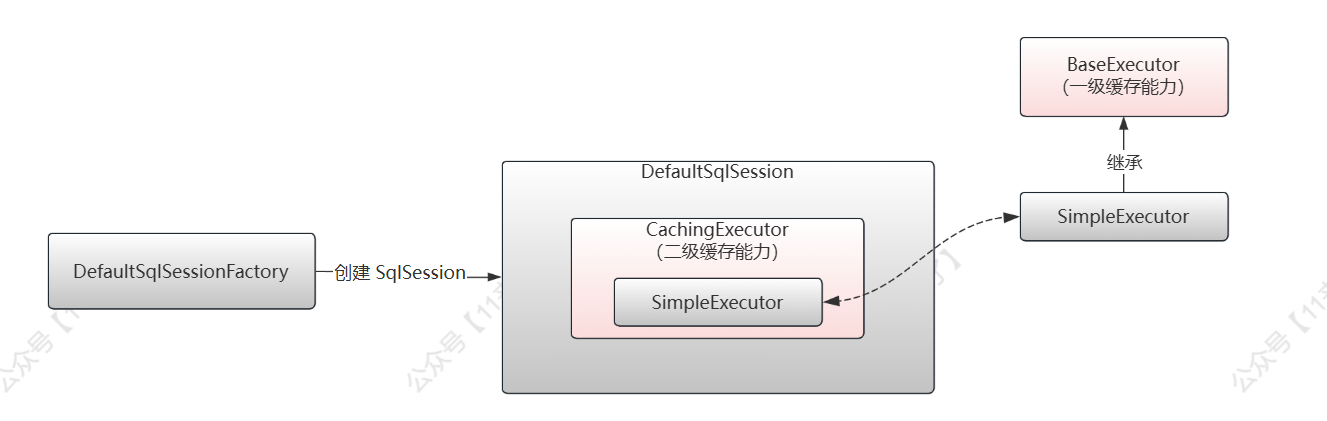
二级缓存的能力是通过 CachingExecutor 来提供的
在执行 UserMapper.xml 中的 SQL 时,会走到 DefaultSqlSession 中,之后又会将 SQL 的执行交给对应的 Executor 来完成,如下图:
// DefaultSqlSession # selectList
@Override
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
}
}
这里的 executor 就是 CachingExecutor ,CachingExecutor 就是普通 Executor的 装饰器 ,普通的 Executor 完成 SQL 的一些执行操作,而 CachingExecutor 在这个基础上,可以进行增强,这里增加了 二级缓存 的功能
// CachingExecutor # query
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameterObject);
// 1、获取 CacheKey
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
// 2、执行查询操作
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
// 3、从 MappedStatement 中获取 Cache 对象
Cache cache = ms.getCache();
if (cache != null) {
// 4、判断是否需要清空二级缓存的数据
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
// 5、通过 TransactionalCacheManager 去获取对应的二级缓存数据
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
// 6、利用提供查询能力的 Executor 去查询数据
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list);
}
return list;
}
}
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
在 步骤 1 会先获取 CacheKey,这个 CacheKey 就是缓存的 key ,因为在比较一个 SQL 是不是同一条 SQL 需要多个条件,将这些条件全部放入 CacheKey 中进行统一比较(详细内容在上边 CacheKey 中已经介绍)
可以发现在 步骤 3 中会从 MappedStatement 中获取一个 Cache 对象,这个 Cache 对象就是在构建 MappedStatement 时放入进去的(MappedStatement 是解析 xml 时创建的,因此说二级缓存的生命周期是 跨 SqlSession 的),也就是在 XMLMapperBuilder 的 cacheElement() 中去创建 Cache 对象并且在构建 MappedStatement 对象时,放入进去的(这里就不看详细代码了)
在 步骤 4 会去判断是否需要清空二级缓存的数据,清空的判断很简单,判断 flushCacheRequired 状态是否为 true,select 标签默认为 false,insert|update|delete 默认为 true,因此修改语句进入到这里都会去清空二级缓存:
// CachingExecutor # flushCacheIfRequired
private void flushCacheIfRequired(MappedStatement ms) {
Cache cache = ms.getCache();
if (cache != null && ms.isFlushCacheRequired()) {
tcm.clear(cache);
}
}
在 步骤 5 中会去 TransactionalCacheManager 中获取对应的二级缓存数据:
TransactionalCacheManager:二级缓存管理器TransactionalCache:在 TransactionalCacheManager 内部,用于存储二级缓存数据
这两个类之间的关系为:
public class TransactionalCacheManager {
private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<>();
}
在 TransactionalCacheManager 内部使用 MappedStatement 内部的 Cache 对象作为 key,value 为 TransactionalCache,在该 TransactionalCache 内部就包含了 MappedStatement 里的 Cache 对象,这里 TransactionalCache 也是作为了一个 装饰器类 ,对基本的 Cache 做一个增强,提供了一个事务的能力,会先将查询到的数据暂存起来,当事务提交之后,再把对应的数据放在二级缓存中(详细可以查看 TransactionalCache 内部源码)
如果缓存中没有获取到对应数据,就会在 步骤 6 中去通过内部的 Executor 去查询对应的数据(因为 CachingExecutor 是对其他 Executor 的装饰器,只提供二级缓存能力,真正查询数据的能力还是由其他 Executor 提供)
在默认情况下,在 步骤 6 中会进入到 BaseExecutor 中,去进行真正数据的查询
测试二级缓存
测试使用二级缓存,代码如下,创建两个 SqlSession,分别去执行查询,看代码是否走到缓存中:
// 创建 SqlSessionFactory
SqlSessionFactory sqlSessionFactory =
new SqlSessionFactoryBuilder().build(inputStream);
User userParam = new User();
userParam.setSchoolName("Sunny School");
// 创建 SqlSession
SqlSession session1 = sqlSessionFactory.openSession();
SqlSession session2 = sqlSessionFactory.openSession();
UserMapper userMapper1 = session1.getMapper(UserMapper.class);
UserMapper userMapper2 = session2.getMapper(UserMapper.class);
List<User> users = userMapper1.queryUserBySchoolName(userParam);
// 提交 SqlSession1 中的数据,此时 TransactionalCache 就会将数据真正放入二级缓存中
session1.commit();
List<User> users1 = userMapper2.queryUserBySchoolName(userParam);
上边代码中,需要调用 session1.commit() 去提交 SqlSession1 中的事务,之后第二次查询才可以获取到对应的二级缓存,如果去掉该行代码,就无法获取二级缓存了,这是为什么呢?
上边讲了,二级缓存数据是放在 TransactionalCache 中的,而 TransactionalCache 是一个装饰器,提供了增强的事务功能,当查询到数据之后,数据不会立即放入内部的 Cache 二级缓存中,而是先放入到 TransactionalCache 内部的 entriesToAddOnCommit 集合中,当事务提交之后,也就是调用 session1.commit() 之后,数据才会从这个临时集合放入到二级缓存中去
// TransactionalCache # commit 事务提交
public void commit() {
if (clearOnCommit) {
delegate.clear();
}
// 将数据放入到二级缓存
flushPendingEntries();
reset();
}
private void flushPendingEntries() {
// 遍历 entriesToAddOnCommit 的数据,放入到二级缓存中,delegate 就是【被装饰类】,即存放二级缓存的 Cache 对象
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValue());
}
for (Object entry : entriesMissedInCache) {
if (!entriesToAddOnCommit.containsKey(entry)) {
delegate.putObject(entry, null);
}
}
}
怎么判断到底是否走到了二级缓存呢?
二级缓存是 CachingExecutor 提供的能力,因此直接进入到 CachingExecutor 的 query() 方法,直接 debug 就可以看到,如下图,通过 tcm(TransactionalCacheManager) 获取的 list 就是二级缓存数据:
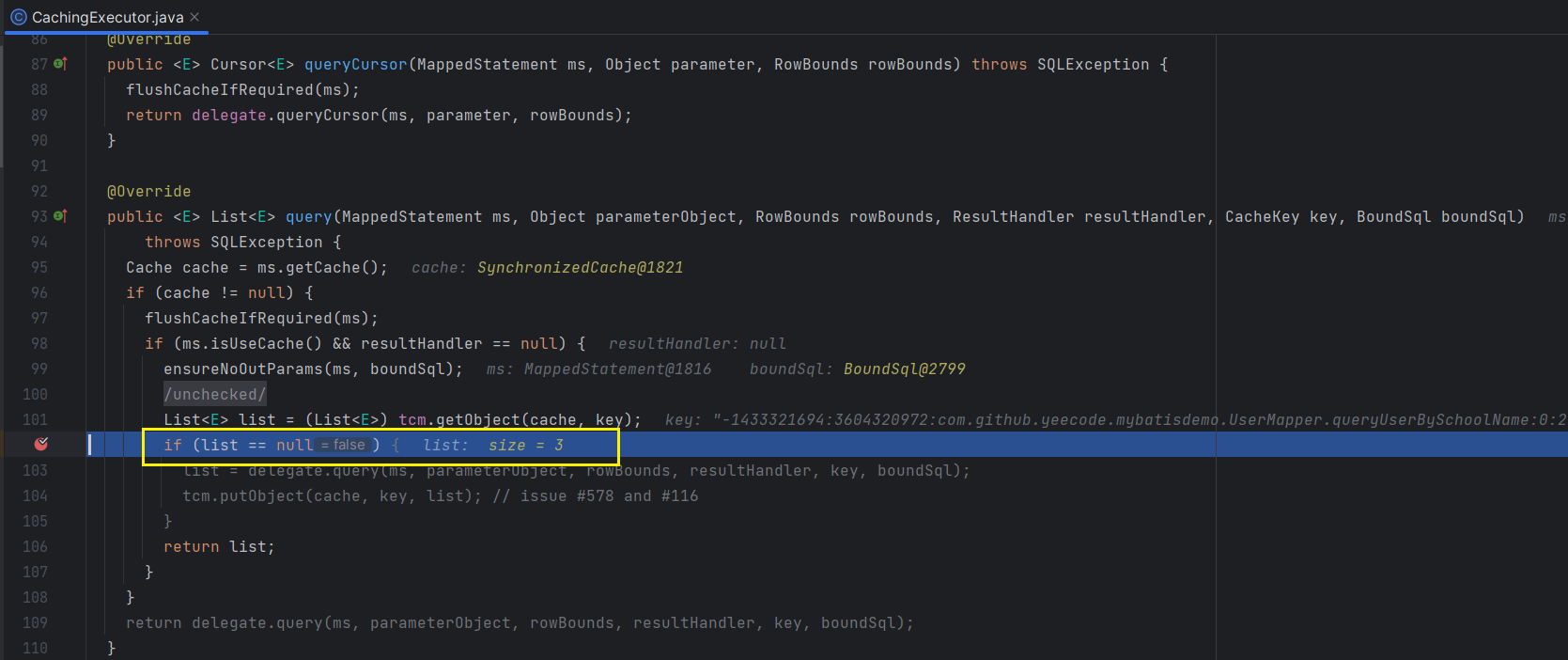
至此,二级缓存能力就已经介绍完毕了
一级缓存能力
一级缓存能力: 一级缓存是 SqlSession 级别的,在一个事务中,如果出现重复的查询结果,就直接使用一级缓存,不去重复的进行查询;并且当执行 嵌套查询时 ,如果一级缓存已经有嵌套查询的结果,也会直接从缓存获取
由于 一级缓存 能力是不可关闭的,因此一级缓存作为一个基础能力被封装在了 BaseExecutor 中,而不是作为一个增强功能放在装饰器类中了
在上边 CachingExecutor 的 query() 方法中,如果从二级缓存拿不到数据,就会走到 BaseExecutor 的 query() 方法中:
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLExcep
List<E> list;
try {
// 这个是嵌套查询的深度,可以暂且先不看
queryStack++;
// 1、从一级缓存获取数据
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 2、从数据库获取数据
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
return list;
}
在这里 BaseExecutor 维护了一个 PerpetualCache 缓存,命名为 localCache ,这个就是用于存放一级缓存数据的
如果一级缓存中没有数据,则会通过 queryFromDatabase() 方法去数据库查询,查询之后放入到一级缓存 localCache 中
一级缓存的生命周期是 SqlSession 级别的,在哪里可以体现呢?
在 DefaultSqlSessionFactory 的 openSession() 中去创建一个 SqlSession,此时还会去创建一个 Executor,这个 Executor 其实就是 SimpleExecutor,SimpleExecutor 继承自 BaseExecutor,而一级缓存就是在 BaseExecutor 中,因此BaseExecutor 内部的一级缓存生命周期是和 SqlSession 一致的,因此一级缓存是 SqlSession 级别的:
// DefaultSqlSessionFactory # openSession
public SqlSession openSession() {
return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false);
}
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
// 创建一个 Executor
final Executor executor = configuration.newExecutor(tx, execType);
return new DefaultSqlSession(configuration, executor, autoCommit);
}
至此,一级缓存能力也介绍完毕了
总结
最后在总结一下,MyBatis 设计了一级缓存、二级缓存,虽然二级缓存我们并不使用,但是可以了解他的一个设计原理,这里总结一下重点内容:
-
二级缓存:
-
二级缓存是跨 SqlSession 级别的,因此是在 MappedStatement 中存储,MappedStatement 是解析 xml 文件时构建的,因此生命周期和 MyBatis 是一直的,因此可以跨 SqlSession
-
二级缓存的能力支持是通过 CachingExecutor 来完成的,用到了 装饰器模式 ,BaseExecutor 提供一些公有的 一级缓存能力 ,BaseExecutor 作为抽象类,提供了一些模版方法供子类实现,这里 SimpleExecutor 继承 BaseExecutor 去实现自己的方法,而 CachingExecutor 又基于 SimpleExecutor 进行包装增强,在不影响原有功能的基础上提供了 二级缓存的能力
-
二级缓存数据最终存储在了 TransactionalCache 内部,TransactionalCache 又是基于 Cache 的一个装饰器,通过命名就可以看出,该类 TransactionalCache 增强的能力为事务能力,当事务提交之后,才将数据放入到二级缓存中
-
-
一级缓存:
- 一级缓存是 MyBatis 的基础能力,所以封装在了 BaseExecutor 中,所有执行器继承 BaseExecutor 之后都会具有一级缓存的能力
-
CacheKey:
- 缓存的 Key 通过 CacheKey 来包装,可以灵活控制缓存的粒度,将多个影响缓存 key 的因素全部放在 CacheKey 中去进行判断
















 823
823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











