






用requests模块进行网页爬虫,首先得下载requests包,这里以pycharm为例,如图1所示,进行安装。
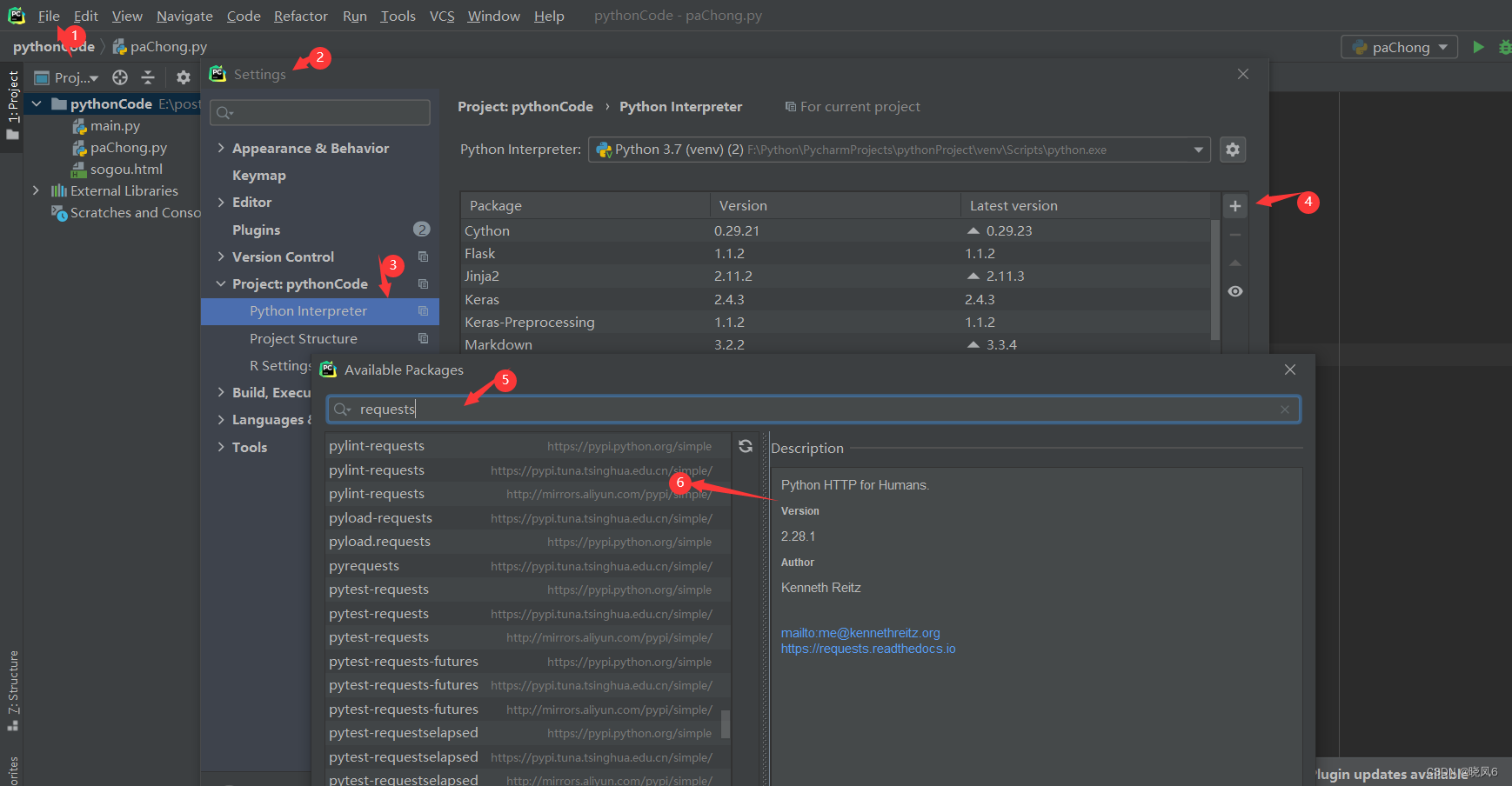
安装好requests后,开始编写代码,代码逻辑主要为以下三步骤:
(1)导入requests模块
(2)指定网页URL,这里以搜狗为例
(3)利用requests进行get请求,并用response接受返回的对象,注意,response是一个对象
(4)输出response的text内容
(5)对爬取到的数据进行存储
代码为:
import requests
if __name__ == "__main__":
url = 'http://www.sogou.com/'
# 发出get请求并接受返回的对象
response = requests.get(url=url)
print(response)
# 读取response中的对象的,即html元素
page_text = response.text
print(page_text)
# 建立html文件,进行持久化存储数据
with open('./sogou.html','w',encoding='utf-8') as fp:
fp.write(page_text)
print('爬取数据结束!!!')
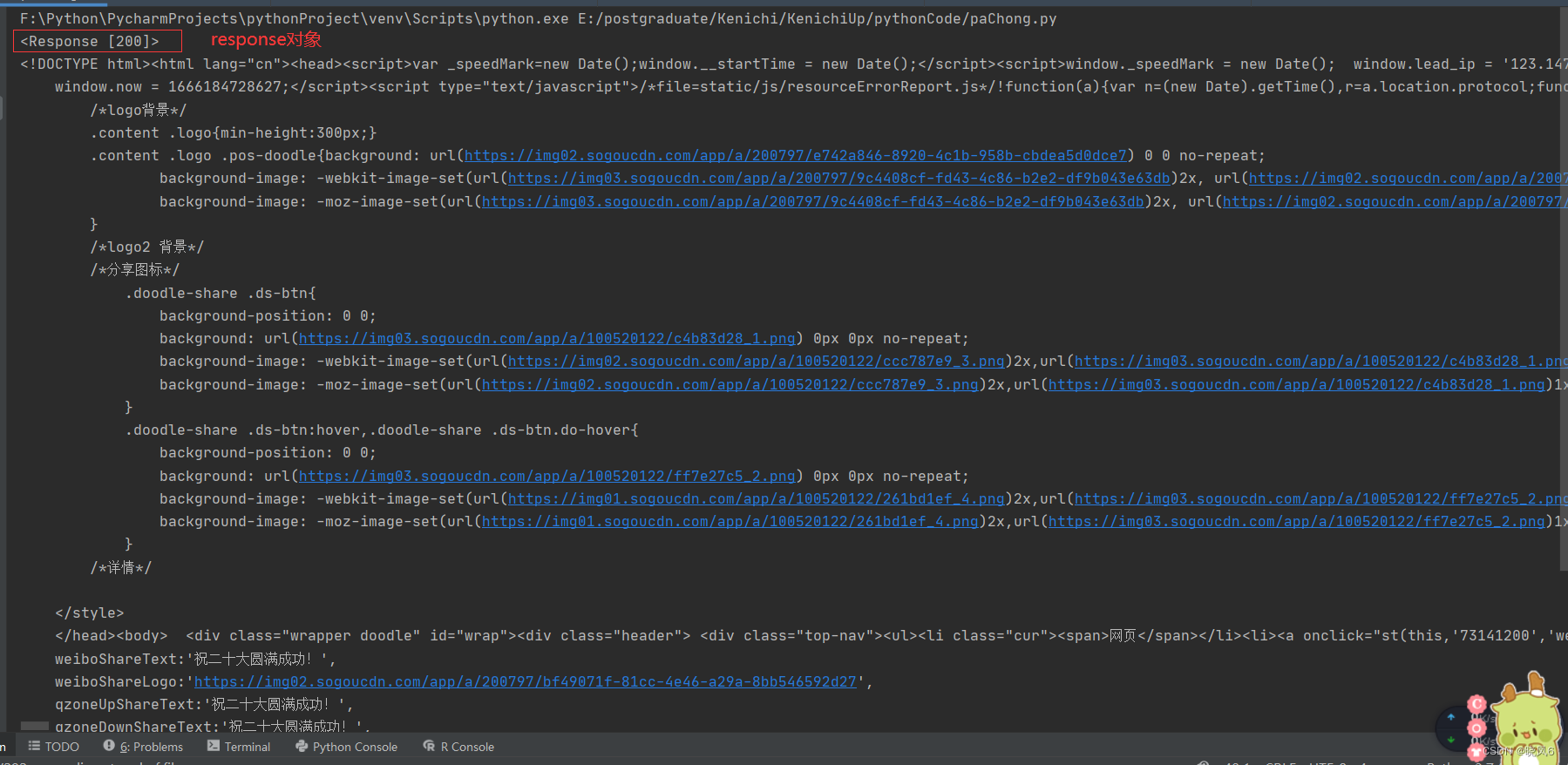
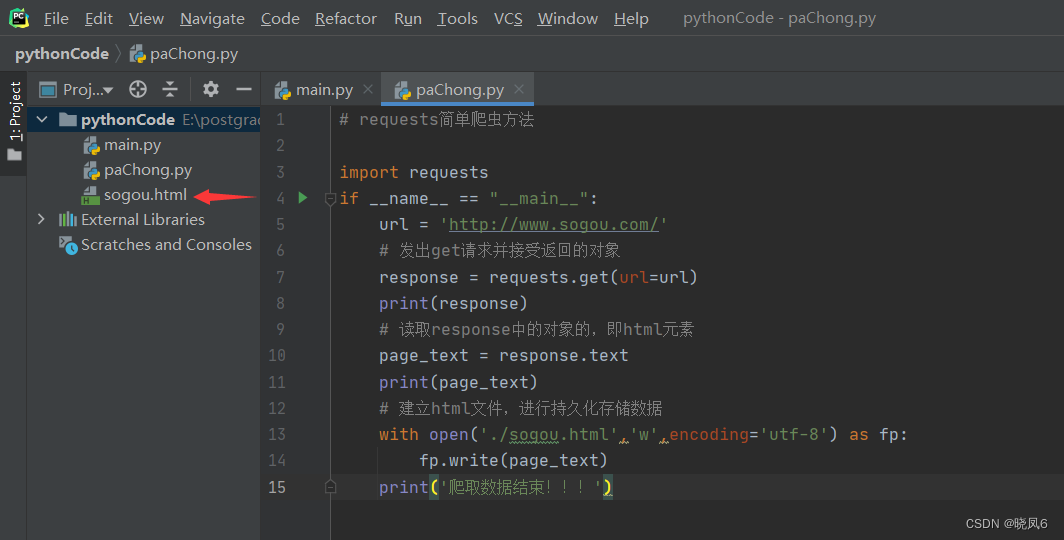
最终的结果如图2、3所示。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









