







1.length(null) 结果不是0是null,天真的我因为这个被坑苦了
还有SELECT if(length(null)<>12,'Y','N'), -- N if(length('')<>12,'Y','N') -- Y
这个也是个意想不到的错误
2.当一段sql报错,且不显示什么信息时,你就看看
表名.字段名,中间的.是不是写成了,
3.防止数据倾斜,这个真的太影响队列里的其他操作了,为避免数据倾斜,在2个地方需要额外注意,一个是表关联,一个是汇总数据。
在表关联时,可以
t1
left join
t2
on nvl(t1.line,concat('hive1',rand())) = nvl(t2.line,concat('hive1',rand()))
在汇总数据时
select
id,
sum(sum_num)
from
(
select
id,
cast((rand() * 100) * 100 as int) as idx,
sum(num) sum_num
from
table1
) a group by id
虽然多包一层,但可以避免数据倾斜
4.建表时,要加存储格式和压缩格式,要不然碰到大数据量运行,会吃光运行资源,而且存储资源也会占光
create table ta1 stored STORED AS ORC TBLPROPERTIES ('orc.compress' = 'SNAPPY')
select
...
from ta
5.去除字符串特殊字符。如:(空字符串、双引号、换行符、回车、tab键、‘null’、‘NULL’、‘N/A’、‘#N/A’、‘n/a’、‘#n/a’ )时,置为空
SELECT regexp_replace(line, '"|\\n|\\t|\\r|\\s+|null|NULL|N/A|#N/A|n/a|#n/a', '');
6.排序
row_number() over(partition by line1 order by line2 desc)
order by 后面跟的字段类型要格外注意,如果是数字类型倒没啥问题,但如果要是string类型,那么排的顺序会让人非常意外
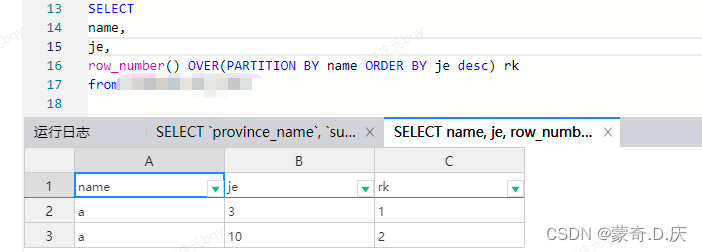
如上,按金额排序,按说je为10的排第一,但是因为该字段是string类型,所以排序出现问题
7.补充函数
问题:截取字段前6位,若小于10位,补’0’至10位
左补足函数:lpad
语法: lpad(string str, int len, string pad)
返回值: string
说明:将str进行用pad进行左补足到len位
举例:
hive> select lpad(‘abc’,10,’td’) from dual;
tdtdtdtabc
右补足函数:rpad
语法: rpad(string str, int len, string pad)
返回值: string
说明:将str进行用pad进行右补足到len位
举例:
hive> select rpad(‘abc’,10,’td’) from dual;
abctdtdtdt
8.解决json数组问题
某一字段为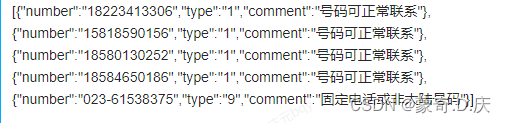
我想取出该字段中type和number对应的所有值
select get_json_object(sale_json,'$.type') as type
,get_json_object(sale_json,'$.number') as number
from table LATERAL VIEW explode(split(regexp_replace(regexp_replace(line_list , '\\[|\\]',''),'\\}\\,\\{','\\}\\;\\{'),'\\;')) sales as sale_json
9.yyyymmdd转换成yyyy-mm-dd格式
from_unixtime(unix_timestamp(line,'yyyyMMdd'),'yyyy-MM-dd')
10.当字段存在"、空字符串、回车、换行符或‘null’或’NULL’或’N/A’或’#N/A’或不可见字符串等异常值时,去掉特殊字符
regexp_replace(line, '"|\\n|\\t|\\r|^null$|^NULL$|^N/A$|^#N/A$|^n/a$|^#n/a$', '')
11.求最大或最小函数
least函数(返回最小值)
语法:least((表达式1,表达式2,…,表达式n),n>=2,此表达式的功能为返回表达式中最小值,如果表达式存在null则返回null
注意:所有表达式必须为同一类型或者能转换成同一类型。
select least(-1,0,3,8); -- -1
select least(-1,0,3,null); -- null
select least(-1,0,3,'abc'); -- null
select least('2021-12-01','2021-12-02','2021-12-03','2021-12-04'); -- 2021-12-01
greatest函数(返回最大值)
语法:greatest((表达式1,表达式2,…,表达式n),n>=2,此表达式的功能为返回表达式中最大值,如果表达式存在null则返回null
注意:所有表达式必须为同一类型或者能转换成同一类型。
select greatest(-1,0,3,8) --8
select greatest(-1,0,3,null) -- null
select greatest(-1,0,3,'abc') -- null
select greatest('2021-12-01','2021-12-02','2021-12-03','2021-12-04') -- 2021-12-04
if后接排序注意事项
背景:序号口径:is_delete = '0’的按照id分组,rq升序排序;is_delete = '1’序号为null
drop TABLE IF EXISTS test;
CREATE TABLE IF NOT EXISTS test(id STRING,rq STRING,is_delete STRING);
INSERT INTO TABLE test VALUES
('a','2023-05-01','0'),
('a','2023-05-02','0'),
('b','2023-05-01','1'),
('b','2023-05-02','1'),
('c','2023-05-01','0'),
('c','2023-05-02','1'),
('c','2023-05-03','0');
SELECT *
,if(is_delete='0', row_number()over(partition by id, if(is_delete='0',1,2) order by rq), null) serial_seq
,if(is_delete='0', row_number()over(partition by id order by rq), null) serial_seq_test
from test;
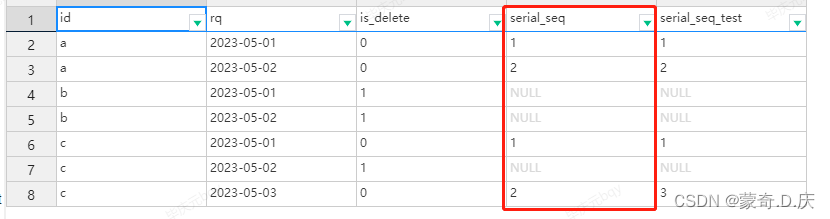
两种排序,只有圈出来的才符合规定
sort_array的应用

有如上数据,现要求将同一xsf_code,xsf_name下的gmf_code、gmf_name分别做成一个数组,且gmf_code与gmf_name一一对应
即

SELECT
xsf_name,
xsf_code,
regexp_replace(zh,'[91[a-zA-Z0-9:]+]','') as gmf_name,
regexp_replace(zh,'[:([\\\u4e00-\\\u9fa5]+)\(\)]','') as gmf_code,
from
(
SELECT xsf_name
,xsf_code
,concat_ws(',',
sort_array(collect_set(concat_ws(':',
gmf_code,
name)))) as zh
FROM table
where length(regexp_replace(xsf_name,'\\d|\\.','')) <> 0
GROUP BY xsf_name
,xsf_code
)
;
regexp_extract
-- 根据主表【key】加工拓展【table_name表名】、【column_name字段名】、【统一字段名】和【二维表序号】:
-- 1)【table_name表名】加工规则:截取【key】第3个'.'前的内容记为【table_name表名】,
-- 2)【column_name字段名】加工规则如下:截取【key】第3个'.'后的内容记为【column_name字段名】
-- a.若【column_name字段名】包含'.':
-- ①【统一字段名】加工规则:截取处理后的【column_name字段名】中'.'后的字母
-- ②【二维表序号】加工规则:截取处理后的【column_name字段名】中'.'前的数字
-- b.【column_name字段名】不包含'.':将【column_name字段名】记为【统一字段名】,【二维表序号】置为空
求解
select *,
if(instr(COLUMN_NAME,'.') > 0,regexp_extract(COLUMN_NAME, '(.+?)\\.(.*+)',2),COLUMN_NAME) as TYZDM,
if(instr(COLUMN_NAME,'.') > 0,regexp_extract(COLUMN_NAME, '(.+?)\\.(.*+)',1),null) as EWBXH
from (select key,
regexp_extract(key, '(.+?\\..+?\\..+?)\\.(.*+)',1) as TABLE_NAME,
regexp_extract(key, '(.+?\\..+?\\..+?)\\.(.*+)',2) as COLUMN_NAME
from ta t
) a
呈现的效果如下

首先讲解下regexp_extract()这个函数
REGEXP_EXTRACT(VARCHAR str, VARCHAR pattern, INT index)
str,pattern,index分别为指定的字符串、匹配的字符串(通常以小括号区分开)、第几个被匹配的字符串
注:index的数字不能大于表达式中()的个数,否则会报错
其次’(.+?\…+?\…+?)\.(.*+)‘代表的意思
由需求可知,我们需要将key分为2部分,即截取【key】第3个’.‘前的内容记为【table_name表名】,截取【key】第3个’.‘后的内容记为【column_name字段名】
那么pattern得有2个小括号,且中间间隔的就是第3个’.’
(.+?\…+?\…+?)其实代表的就是a.b.c,.代表任意字符,+?代表最小匹配
\.代表字符.
算季度
SELECT concat(substr('202310',1,4),'0',floor(substr('202310',5,2)/3.1)+1)
字符串为数字+字母的组合
select 'asd123' rlike '^(?=.*[A-Za-z])(?=.*[0-9])[A-Za-z0-9]+$'















 1470
1470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









