







第六章 数据库技术基础
6.1 基本概念
6.1.1 数据库与数据库管理系统
- 数据库系统基本概念
- 数据(data):描述事物的符号记录,有多种表现形式,如文字、图形、图像、声音和语言等。
- 信息(information):是现实世界事物的存在方式或状态的反映,具有可感知、可存储、可加工、可传递和可再生等特性。
- 数据是信息的符号表示,信息是具有特定释义和意义的数据。
- 数据库系统(Database System,DBS):是一个采用数据技术来存储数据,供多用户访问的计算机系统,由以下四部分组成:
- 数据库(Database,DB):存储在计算机内的、有组织的相关数据的集合。
- 硬件(hardware):构成计算机系统的各种设备,包括存储数据所需的外设。
- 软件(software):操作系统、数据库管理系统(Database Management System,DBMS)及应用程序。
- 人员:系统分析师和数据库设计人员、应用程序员、最终用户、数据库管理员(Database Administrator,DBA)。
- 数据库管理系统:由一组相互关联的数据的集合和一组用以访问这些数据的软件组成。
6.1.2 数据管理技术的发展
- 人工管理阶段
- 数据管理特点:数据量少;数据不保存;没有软件系统对数据进行管理。
- 缺点:应用程序之间依赖性太强,不独立;数据组和数据组之间可能有许多重复数据,造成数据冗余。
- 文件系统阶段
- 数据管理特点:数据可长期保留;数据不属于某个特定应用;文件组织形式多样化,有索引文件、连接文件和Hash文件等。
- 缺点:数据冗余(data redundancy);数据不一致(data inconsistency);数据孤立(data isolation)。
- 数据库系统阶段
- 数据管理特点:采用复杂的数据模型表示数据结构;有较高的数据独立性。
- 数据库的研究领域
- 数据库管理软件的研制;
- 数据库设计;
- 数据库理论:主要集中于关系的规范化理论、关系数据理论等。
6.1.3 DBMS的功能和特点
- DBMS的功能
- 数据定义:提供数据定义语言(Data Defined Language,DDL)
- 可以对数据库的结构描述,包括外模式、模式和内模式定义。
- 数据库的完整性定义。
- 安全保密定义,如口令、级别和存取权限等。
- 这些定义存储在数据字典中,是DBMS运行的基本依据。
- 数据库操作:提供数据操纵语言(Data Manipulation Language,DML)
- 实现对数据库中数据的基本操作,如检索、插入、修改和删除。
- 宿主型DML:将DML语句嵌入某种主语言(如C、Java、等)中使用。
- 自含型DML:指可单独使用DML语句,供用户交互使用。
- 数据库运行管理
- 多用户环境下的并发控制。
- 安全性检查和存取控制。
- 完整性检查和执行。
- 运行日志的组织管理。
- 事务管理和自动恢复。
- 数据组织、存储和管理
- 目标:提高存储空间的利用率。
- 对象:数据字典、用户数据和存取路径。
- 数据库的建立和维护
- 数据库的初始建立。
- 数据的转换。
- 数据库的转储和恢复。
- 数据库的重组和重构。
- 性能监测和分析。
- 其他功能
- DBMS与其他软件系统的通信功能。
- DBMS与其他DBMS或文件系统的数据转换功能。
- DBMS的特点
- 数据结构化且统一管理:真正实现了数据的共享。
- 有较高的数据独立性。指数据与程序独立,数据的独立性包括物理独立性和逻辑独立性。
- 数据控制功能
- 数据的安全性(security):防止不合法的使用所造成的数据泄露、更改或破坏。
- 数据的完整性(integrality):防止合法用户使用数据库时向数据库加入不符合语义的数据。
- 并发控制(concurrency control):协调并发事务的执行,保证数据库的完整性不受破坏,避免用户得到不正确的数据。
- 故障恢复(recovery from failure):通过建立冗余(redundancy)数据进行恢复。
- DBMS的分类
- 关系数据库系统(Relation Database Systems,RDBS),如MySQL、Oracle、Microsoft SQL Server。
- 面向对象的数据库系统(Object-Oriented Database Systems,OODBS),能表达数据间的嵌套、递归关系,有封装性和继承性。
- 对象关系数据库系统(Object-Oriented Relation Database Systems,OORDBS),在RDBS上提供了元组、数组、集合等。
6.1.4 数据库系统的体系结构
- 集中式数据库系统
- 不但数据是集中的,数据的管理也是集中的。
- 客户端/服务器(C/S)体系结构
- 客户端主要负责数据表示服务,服务器主要负责数据库服务。
- 采用C/S结构后,数据库系统功能分为前端和后端。
- 前端主要包括图形用户界面、表格生成和报表处理工具。
- 后端负责存取结构、查询计算和优化、并发控制以及故障恢复等。
- 前端与后端通过SQL或应用程序来接口。
- ODBC(开放数据库互连)和JDBC(Java程序数据库连接)标准定义了应用程序和数据库服务器通信的方法。
- 数据库服务器分类
- 事务服务器/查询服务器。客户端发出请求;服务端响应请求,并将执行结果返回给客户端。
- 数据服务器。使得客户端可以与服务器交互。
- 并行数据库系统
- 并行数据库系统是多个物理上连在一起的CPU。
- 分为共享内存式多处理器和无共享式并行体系结构。
- 分布式数据库系统
- 分布式数据库系统是多个地理上分开的CPU。
- 分为物理上分布、逻辑上集中的分布式结构和物理上分布、逻辑上分布的分布式结构。
6.1.5 数据库系统的三级模式结构
- 数据抽象
- 视图层(view level):描述整个数据库的某个部分。
- 逻辑层(logical level):描述数据库中存储什么数据以及这些数据间存在什么关系。
- 物理层(physical level):描述数据在存储器上如何存储的。
- 数据库的三级模式结构
- 数据库的体系结构基本上都采用"三级模式和两级映像"。
- 数据库有"型"和"值"的概念,"型"是对某一数据的结构和属性的说明,"值"是型的一个具体赋值。
- 模式
- 概念模式/模式
- 描述数据库中全部数据的逻辑结构和特征,只涉及型的描述,不涉及具体的值。
- 概念模式反映的是数据库的结构及其联系,所以是相对稳定的。
- 概念模式的一个值称为模式的一个实例,同一个模式可以有很多实例。
- 实例反映的是数据库某一时刻的状态,所以是相对变动的。
- 概念模式不涉及存储结构、访问技术等细节。只有这样,概念模式才算做到了"物理数据独立性"。
- 外模式/用户模式/子模式
- 是用户与数据库系统的接口,是用户用到的那部分数据的描述。
- 有了外模式后,程序员不必关心概念模式,只与外模式发生联系,按外模式的结构存储和操纵数据。
- 内模式/存储模式
- 是数据物理结构和存储方式的描述,是数据在数据库内部的表示方式。
- 定义所有的内部记录类型、索引和文件的组织方式,以及数据控制方面的细节。
- 两级映像
- 作用:保证了数据库中的数据具有较高的逻辑独立性和物理独立性。
- 模式/内模式映像:实现了概念模式到内模式之间的相互转换。
- 外模式/模式映像:实现了外模式到概念模式之间的相互转换。
- 数据的独立性
- 物理独立性:指当数据库的内模式发生改变时,数据的逻辑结构不变。需要修改概念模式/内模式之间的映像。
- 逻辑独立性:指当数据的逻辑结构发生变化后,用户程序可以不修改。需要修改外模式/概念模式之间的映像。
6.2 数据模型
6.2.1 数据模型的基本概念
模型:对现实世界特征的模拟和抽象。
数据模型:对现实世界数据特征的抽象。
- 概念数据模型/信息模型
- 是按用户的观点对数据和信息建模,是用户和数据库设计人员交流的语言。
- 用于数据库设计。
- 这类模型中最著名的是实体联系模型,简称E-R模型。
- 基本数据模型
- 是按计算机系统的观点对数据建模,是现实世界数据特征的抽象。
- 用于DBMS的实现。
- 目前最常用的基本结构模型:
- 层次模型(hierarchical model),非关系模型。
- 网状模型(network model),非关系模型。
- 关系模型(relational model):采用二维表格结构表示实体集及其之间的联系,“关系模式"对应"类”,“关系"对应"变量”。
- 面向对象数据模型(object oriented model)。
6.2.2 数据模型的三要素
数据模型是用来描述数据的一组概念和定义。
- 数据结构
- 是所研究的对象类型的集合。
- 是对系统静态特性的描述。
- 数据操作
- 对数据库中各种对象(型)和实例(值)允许执行的操作的集合,包括操作及操作规则。
- 操作:检索、插入、删除、修改。
- 操作规则:优先级别等。
- 是对系统动态特性的描述。
- 数据的约束条件
- 是一组完整性规则的集合。
- 对于具体的应用数据必须遵循特定的语义约束条件,以保证数据的正确、有效和相容。
6.2.3 E-R模型
- E-R方法
-
E-R方法直接从现实世界中抽离出实体和实体间的联系,然后用非常直观的E-R来表示数据模型。
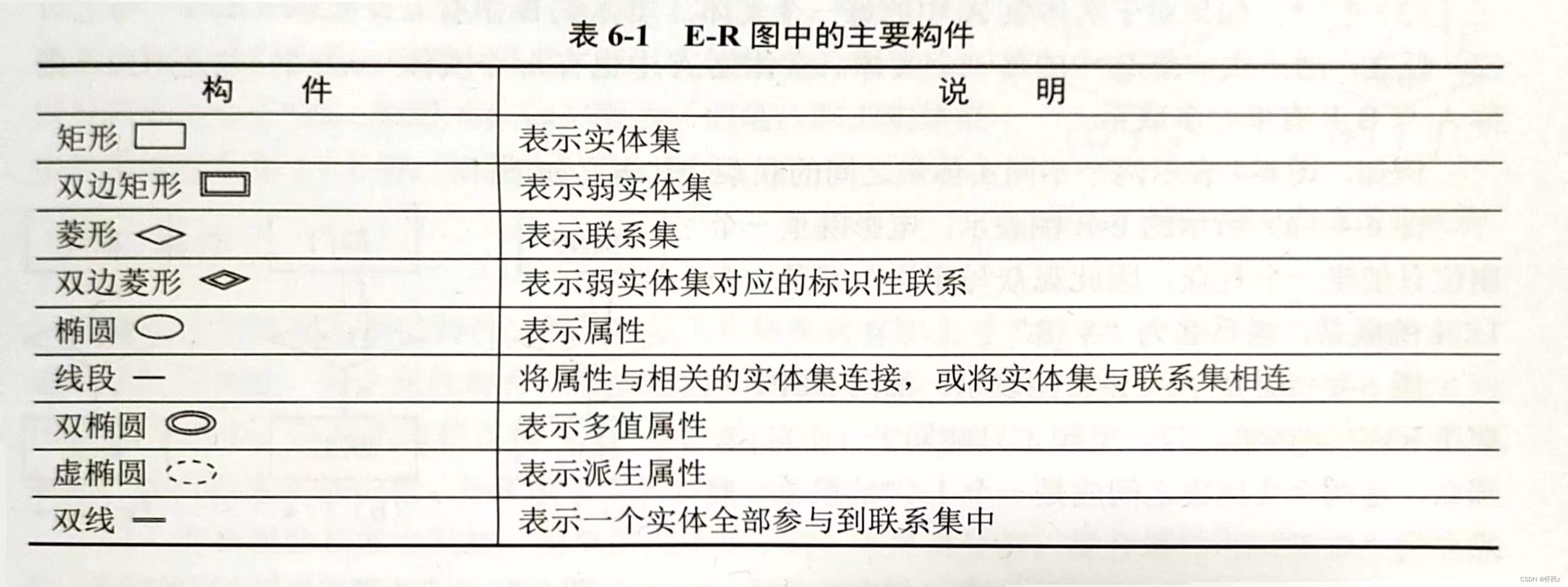
-
在E-R图中,实体集中作为主码(主键)的一部分属性名下面要加下画线注明。
-
在实体集与联系的线段上要标注联系的类型(1:1、1:
*或*:*)。
- 实体
- 实体在E-R图中用矩形表示,通常在矩形框内写明实体名。
- 实体是现实世界中可以区别于其他对象的"事件"或"物体"。
- 每个实体由一组特性(属性)来表示,其中的某一部分属性可以唯一标识实体。
- 实体集是具有相同属性的实体集合。
- 联系
-
联系在E-R图中用菱形表示,通常在菱形框内写明联系名,并用无向边分别与有关实体连接,同时在无向边旁标注上联系的类型。
-
实体的联系分为实体内部的联系和实体与实体之间的联系。
-
实体内部的联系反映数据在同一记录内部各字段之间的联系。
-
两个不同实体之间的联系可分为三类:
- 1:1。对于实体集A中的每一个实体,实体集B中至多有一个实体与之对应,反之亦然。则称A与B具有一对一联系。
- 1:
*:对于实体集A中的每一个实体,实体集B中有n(n≥0)个实体与之对应,反之,对于实体集B中的每一个实体,实体集A中至多只有一个实体与之对应,则称A与B具有一对多联系。 *:*:对于实体集A中的每一个实体,实体集B中有n(n≥0)个实体与之对应,反之,对于实体集B中的每一个实体,实体集A中也有m(m≥0)个实体与之对应,则称A与B具有多对多联系。
-
两个以上不同实体集之间的联系:(1:1:1)、(1:1:
*)、(1:*:*)、(*:*:*)。注意:三个实体集之间的多对多的联系和三个实体集两两之间的多对多的联系的语义是不同的。
-
同一实体集内的二元联系:(1:1)、(1:
*)、(*:*)。
- 属性
- 属性是实体某方面的特性。
- 每个属性都有其取值范围。
- 在同一实体集中,每个实体的属性及其域是相同的,但可能取不同的值。
- E-R模型中的属性有如下分类:
-
简单属性和复合属性。
简单属性是原子的、不可再分的。
复合属性可细分为更小的部分(即划分为别的属性)。例如地址可进一步划分为省、市、街道。
-
单值属性和多值属性。
单值属性:属性对于一个特定的实体只有单独的一个值,例如身份证号。
多值属性,属性对于一个特定的实体可能对应一组值,例如职工的亲属的姓名。
-
NULL属性:当实体在某个属性上没有值或属性值未知时,使用NULL值,表示无意义或不知道。
-
派生属性:可以从其他属性得来,如年龄可以由当前时间和出生日期得到。
-
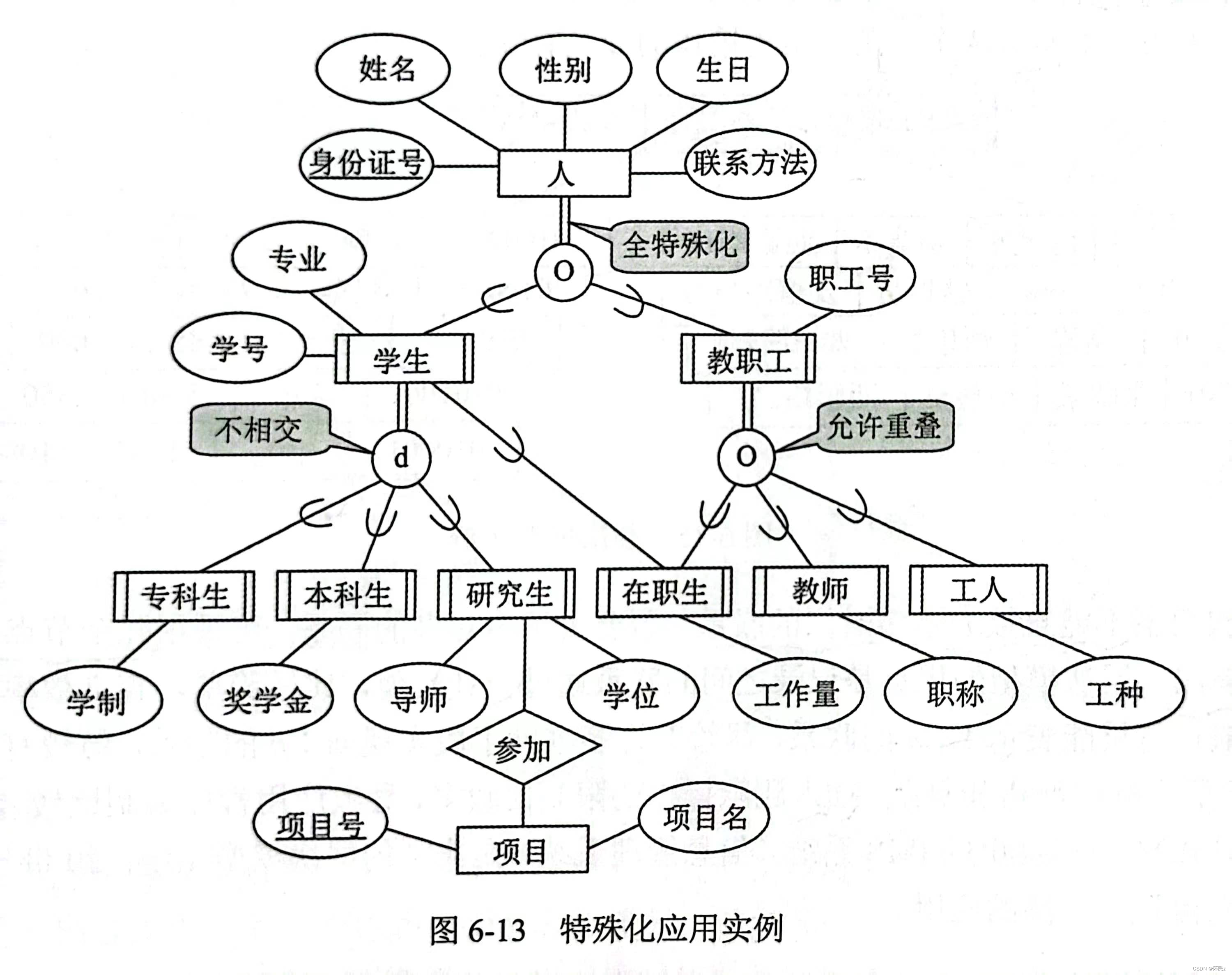
- 扩充的E-R模型
-
弱实体:一种特殊的依赖关系,即一个实体的存在必须以另一个实体为前提,将这类实体称为弱实体。
例如企业职工的家属,家属总是属于某职工的,当某职工离职时,会将其连同其家属一起从职工关系中删除。
-
特殊化:某些实体一方面具有一些共性,另一方面还有各自的特殊性,则一个实体集可按照某些特征区分为几个子实体。
-
设有实体集E,如果S是E的某些真子集的集合,记为S={Si|Si⊂ E, i=1.2,…,n},则称
S是E的一个特殊化。
E是S1、S2、…、Sn的超类。
S1、S2、…、Sn称为E的子类。子类继承超类的所有属性和联系,且还有自己特殊的属性和联系。
如果S1 ∪ S2 ∪ … ∪ Sn = E,则称S是E的全特殊化,否则是E的部分特殊化。
如果Si ∩ Sj = Ø,i ≠ j,则S是不相交特殊化,否则是重叠特殊化。
-
在扩充的E-R模型中,子类继承超类的所有属性和联系,但是子类还有自己特殊的属性和联系。
不相交/disjoint;重叠/overlap。

-
特殊化应用示例:
-
6.2.4 基本的数据模型
- 层次模型(Hierarchical Model)
- 采用树型结构表示数据与数据间的关系。
- 每个结点表示一个记录类型(实体)。
- 记录之间的联系用结点之间的连线表示。
- 除根结点以外的其他结点有且仅有一个双亲结点。
- 上层和下一层类型的联系是1:n联系(包括1:1联系)。
- 层次模型不能直接表示多对多的联系。若要表示多对多的联系,可采用冗余结点法或虚拟结点分解法。
- 优点:记录之间的联系通过指针实现,比较简单,查询效率高。
- 缺点:只能表示1:n的联系;尽管有许多辅助手段实现m:n的联系,但较复杂不容易掌握;插入删除操作的应用程序编制较复杂。
- 网状模型(Network Model)
- 采用网络结构表示数据与数据间的关系。
- 每个节点表示一个记录类型(实体),每个记录类型可以包含若干个字段(实体的属性)。
- 节点间的连线表示记录类型之间一对多的联系。
- 允许一个以上的节点无双亲,一个节点可以有多于一个的双亲。
- 允许两个节点之间有多种联系(称之为复合联系)。
- 网状模型不能表示记录之间多对多的联系,需要引入联结记录来表示多对多联系。
- 网状模型与层次模型的区别:
- 网状模型中子女节点与双亲节点的联系不唯一,因此需要为每个联系命名。
- 网状模型允许复合链,即两个节点之间有两种以上的联系。
- 优点:更为直接地描述现实世界,具有良好的性能,存取效率高。
- 缺点:结构复杂,记录之间的联系是通过存取路径来实现的,增加了程序编写的负担。
- 关系模型(Relational Model)
- 采用表格结构表示实体集以及实体集之间的联系,其最大特色是描述的一致性。
- 一个"关系模式"相当于一个记录型,对应程序设计语言中"类型"定义的概念。
- 一个"关系"是一个实例,也是一张表,对应程序设计语言中"变量"的概念。
- 面向对象数据模型(Object Oriented Model)
- 对象和对象标识(OID)
- 对象:是现实世界中实体的模型化,与记录、元组的概念相似,但远比它们复杂。
- 对象标识:每个对象都有一个唯一的标识。对象标识不等于关系模式中的记录标识,OID是独立于值的,全系统唯一的。
- 封装(encapsulate)
- 每一个对象是状态(state)和行为(behavior)的封装。
- 对象的状态:是该对象属性的集合。
- 对象的行为:是在该对象状态上的操作的方法(程序代码)的集合。
- 被封装的状态和行为在对象外部是看不见的,只能通过显式定义的消息传递来访问。
- 对象的属性(object attribute)
- 对象的属性描述对象的状态、组成和特性,对象的某个属性可以是单值或值的集合。
- 对象的一个属性值本身在该属性看来也是一个对象。
- 类和类层次(class and class hierarchical)
- 类:所有具有相同属性和方法集的对象构成了一个对象类,任何一个对象是其对象类的实例(instance)。
- 类层次:所有的类构成了一个有根有向无环图,称为类层次(结构)。
- 继承(inherit)
- 一个类可以从直接/间接祖先(超类)继承(inherit)所有的方法和属性,该类称为子类。
- 类继承可分为单继承(即一个类只能有一个超类)和多重继承(即一个类可以有多个超类)。
6.3 数据存储和查询
数据库系统的功能部件通常可划分为存储管理器和查询处理器部件。
6.3.1 存储管理器
- 作用:与文件系统交互,将不同的DML语言翻译成底层文件系统命令,使原始数据通过文件系统存储在磁盘上。
- 存储管理器组件包括:
- 权限及完整性管理器。检查试图访问数据库的用户的权限,检测数据是否满足完整性约束。
- 事务管理器。保证一旦发生了故障,数据库的一致性状态,以及并发事务执行时不发生冲突。
- 文件管理器。管理磁盘空间的分配,管理用于表示磁盘所有信息的数据结构。
- 缓冲管理器。负责将数据从磁盘放入内存,并决定哪些数据应被缓冲放入内存。
6.3.2 查询处理器
- 查询处理器的组件包括:
- DDL解释器。解释DDL语句并将其放入数据字典中。
- DML编译器。将查询语言中的DML语句翻译为一个计算方案,包括一系列查询计算引擎能理解的命令。
6.4 数据仓库和数据挖掘基础知识
- 大量待处理的信息分为事务型处理和信息型处理两大类。
- 事务型处理:即业务操作处理,对信息进行查询和修改,目的是满足组织特定的日常管理需要。
- 信息型处理:对信息进行进一步的分析,为管理人员决策提供支持。
6.4.1 数据仓库
- 数据仓库的基本特性
- 面向主题的。数据仓库中的数据是面向主题进行组织的。在进行主题抽取时,必须按照决策分析对象进行。
- 数据是集成的。根据决策分析的要求,将分散于各处的原数据进行抽取、筛选、清理、综合等集成工作。
- 数据是相对稳定的。数据仓库中的数据主要供决策分析之用,涉及的数据操作主要是数据查询,一般不涉及修改。
- 数据是反映历史变化的:
- 数据仓库随时间变化不断增加新的数据内容。
- 数据仓库随时间变化不断删除旧的数据内容。
- 数据仓库中包含大量的综合数据,这些数据有很多信息与时间有关,需要随时间不断地进行重新综合。
- 数据仓库的数据模式
- 数据仓库的数据通常是多维数据,包括维属性、度量属性。包含多维数据的表称为事实表,事实表通常很大。
- 为了减少存储要求,维属性通常是一些短的标识,作为参照其他表的外码。
- 数据仓库的数据模式分类:
- 星型模式:一个事实表、多个维表以及从事实表到多维表的参照外码。
- 雪花模式:一个事实表、多个且多级维表以及从事实表到多维表的参照外码、维表到维表的参照外码。
- 事实星型模式:即不止一个事实表的星型模式。
- 数据仓库的体系结构
- 数据仓库通常采用三层体系结构:
- 底层的数据仓库服务器:一般是一个关系数据库系统。数据进行清洗、转换、集成后装入数据仓库。
- 中间层的OLAP服务器:提供对多维数据的存储和操作。
- 顶层的前端工具:查询和报表工具、分析工具、数据挖掘工具等。
- 从结构的角度看有三种数据仓库模型:
-
企业仓库:收集跨越整个企业的各个主题的所有信息。
数据通常来自多个操作型数据库和外部信息提供者,并且是跨越多个功能范围的。
企业仓库通常包含详细数据和汇总数据。
-
数据集市:包含对特定用户有用的、企业范围数据的一个子集。
它的范围限定于选定的主题。
包括在数据集市中的数据通常是汇总的。
根据数据来源的不同,分为独立的和依赖的两类。
在独立的数据集市中,数据来自一个或多个操作型数据库或外部信息提供者,或是一个特定部门或地区本地产生的数据。
在依赖的数据集市中,数据直接来自企业数据仓库。
-
虚拟仓库:是操作型数据库上视图的集合。
-
6.4.2 数据挖掘
- 数据挖掘(Data Mining,DM)
- 从大量的、不完全的、有噪声的、模糊的、随机的实际数据中提取-
- 隐含在其中的、人们不知道的、但又潜在有用的信息和知识的过程。
- 数据挖掘的分类
- 按所挖掘的数据库的种类分为:
- 关系型数据库的数据挖掘。
- 数据仓库的数据挖掘。
- 面向对象数据库的数据挖掘。
- 空间数据库的数据挖掘。
- 正文数据库和多媒体数据库的数据挖掘。
- 按所发现的知识类别可分为:
-
关联规则:关联规则是形如X→Y的蕴涵式,典型例子如"尿布和啤酒"。目的是为了挖掘出隐藏在数据间的相互关系。
Apriori算法。
-
特征描述。对目标类数据的一般特性或特征的汇总。
-
分类分析。从数据中选出已分类的训练集;在该训练集上运用分类,建立分类模型;对于没有分类的数据进行分类。
SVM是典型的分类算法。
决策树(ID3、C4.5)算法。
最近邻(KNN)。
贝叶斯。
人工神经网络。
-
聚类分析。指将物理或抽象对象的集合分组为由类似的对象组成的多个类的分析过程。
K-Means:基于对象之间的聚类进行聚类,需要输入聚类的个数,聚类结果与输入参数关系很大。
DBSCAN:基于密度进行聚类,需要确定阈值,聚类结果与输入参数关系很大。可处理不同大小和不同形状的簇。
EM(期望最大化)。
-
趋势和偏差分析。
-
- 按照所发现的知识抽象层次可分为
- 一般化知识。
- 初级知识。
- 多层次知识。
- 数据挖掘技术的三种基础技术:
- 海量数据搜集。
- 强大的多处理器计算机。
- 数据挖掘算法。
- 数据挖掘中常用的技术:
- 人工神经网络:仿照生理神经网络结构的非线性预测模型,通过学习进行模式识别。
- 决策树:代表着决策集的树形结构。
- 遗传算法:基于进化理论,并采用遗传结合、遗传变异,以及自然选择等设计方法的优化技术。
- 近邻算法:将数据集合中每一个记录进行分类的方法。
- 规则推导:从统计意义上对数据中的"如果-那么"规则进行寻找和推导。
- 数据挖掘与数据仓库的关系
- 成功的数据挖掘的关键之一在于通过访问正确、完整和集成的数据,这些正是数据仓库所能提供的。
- 数据仓库不仅是集成数据的一种方式,其联机分析处理功能OLAP为数据挖掘提供了一个极佳的操作平台。
- 数据挖掘技术的应用过程
- 确定挖掘对象:定义清晰的挖掘对象、认清数据挖掘的目标。
- 准备数据:搜索所有与业务对象有关的内部和外部数据,从中选择适合于数据挖掘应用的数据。
- 选择数据后,还需要对数据进行预处理。
- 对数据进行清洗、解决数据中的缺值、冗余、数据值的不一致性、数据定义的不一致性、过时数据等问题。
- 建立模型:将数据转换成一个分析模型,这个分析模型是针对挖掘算法建立的。
- 建立一个真正适合挖掘算法的分析模型,是数据挖掘的关键。
- 数据挖掘:除了完善与选择合适的算法需要人工干预,数据挖掘工作都由数据挖掘工具自动完成。
- 结果分析:对挖掘结果进行解释和评估。
- 知识应用:数据挖掘的结果经过业务决策人员的认可,才能实际应用。















 995
995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









