







文件压缩
文件压缩概念及目的
概念:文件压缩是指在不丢失有用信息的前提下,缩减数据量以减少存储空间,提高其传输、存储和处理效率,或着按照一定的算法对文件中数据进行重新组织,减少数据的冗余和存储的空间的一种技术方法
目的:
- 紧缩数据存储容量,减少存储空间
- 可以提高数据传输的速度,减少带宽占用量,提高通讯效率
- 对数据的一种加密保护,增强数据在传输过程中的安全性
压缩分类:有损压缩、无损压缩
设计思路
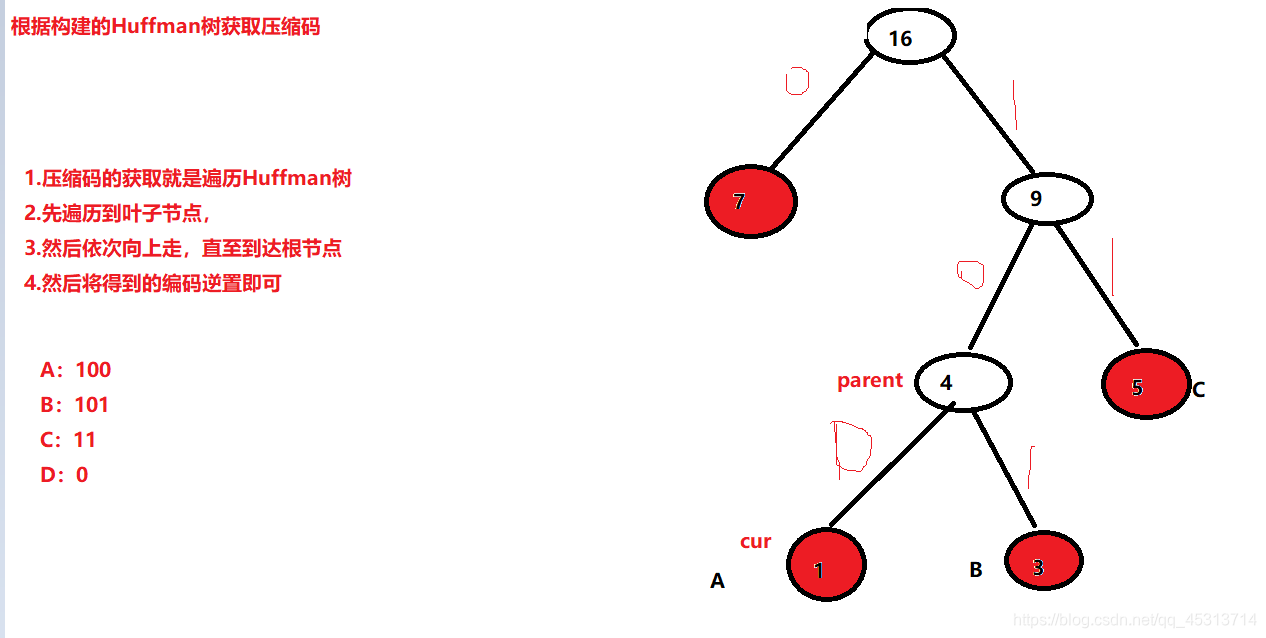
了解Huffman树
什么是Huffman树?
将带权路径长度最短的二叉树称为Huffman树。
如何构建?
1.由给定的n个权值构建n棵只含有根节点的二叉树森林集合。
2.重复以下步骤,直至二叉树森林中只含有一颗树为止。
2.1.在集合中选取两个权值最小的二叉树,作为左右子树构造一棵新的二叉树,同时将这两棵树的根节点权值变为左右子树权值之和。
2.2.将2.1中选取的两个权值最小二叉树从集合中删除
2.3.同时将这两个二叉树生成新二叉树放置在集合中,
选取的数据结构
构建Huffman选取的数据结构
因为生成的Huffman树默认权值是从顶层到底层权值是依次递减的。所以我们这里采用优先级队列来实现它,但由于其默认采用的大堆存储方法,所以我们此时必须利用仿函数来采取自定义比较方式:
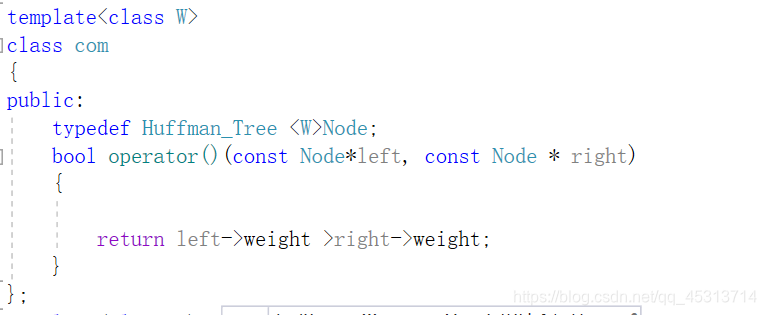
保存字符及对应的编码
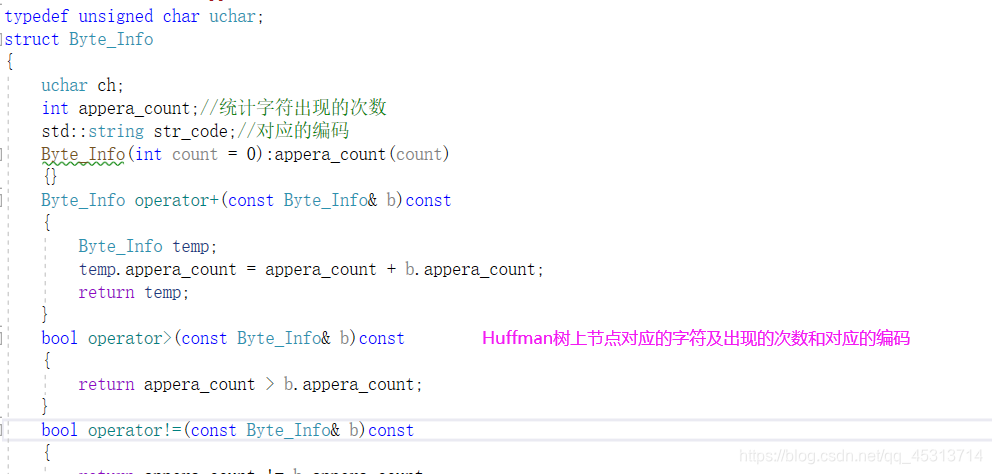
文件压缩的类及对应方法
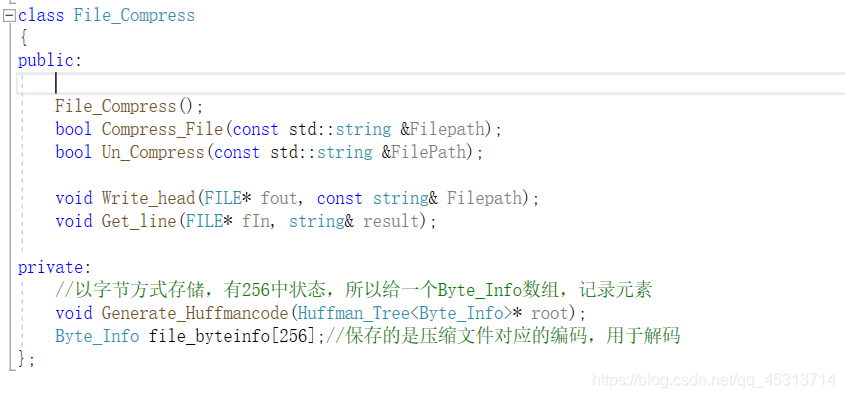
构建Huffman树以及对应编码规则
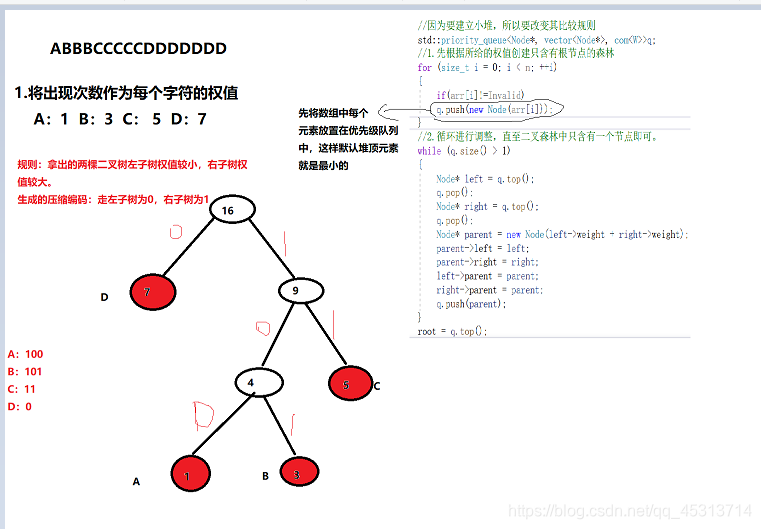
获取每个字符对应的压缩码
void File_Compress::Generate_Huffmancode(Huffman_Tree<Byte_Info>* root)
{
if (nullptr == root)
{
return;
}
if (root->left == nullptr && root->right == nullptr)
{
Huffman_Tree<Byte_Info>*cur = root;
Huffman_Tree<Byte_Info>* parent = root->parent;
std::string &str_code = file_byteinfo[cur->weight.ch].str_code;
while (parent)
{
if (cur == parent->left)
{
str_code += '0';
}
else
{
str_code += '1';
}
cur = parent;
parent = cur->parent;
}
reverse(str_code.begin(), str_code.end());
}
Generate_Huffmancode(root->left);
Generate_Huffmancode(root->right);
}
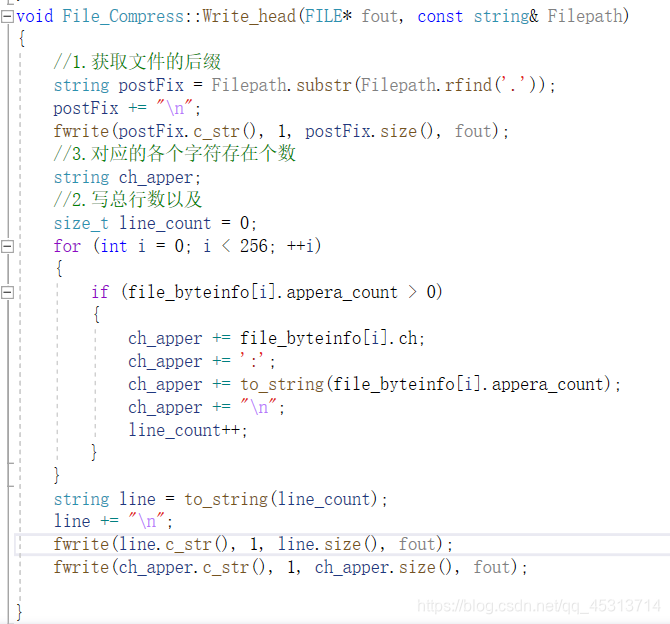
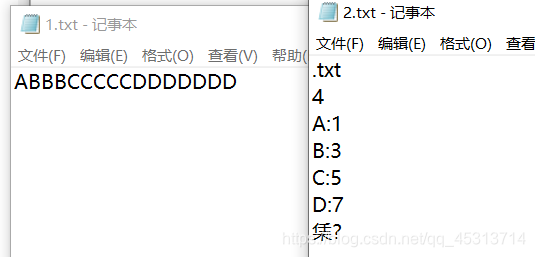
书写压缩文件
1.将文件的类型写出来
2.将文件对应的字符类的个数写出来
3.将每个字符对应的个数写出来
4,用得到的编码替换字符

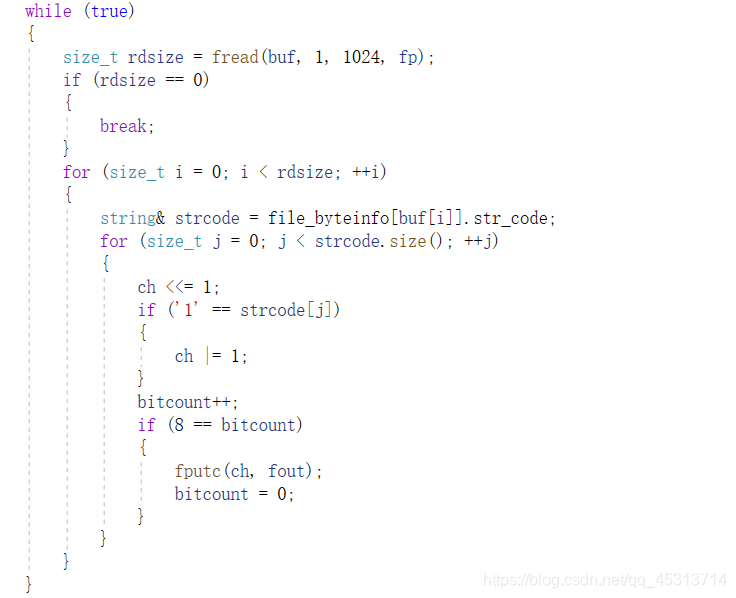

解码
思路:
1.根据压缩保存的文件类型先来获取到文件类型,创建文件
2.读取第二行存储的行的大小,字符的种类个数
3.根据里面的权值来重建Huffman树
4.读取压缩数据,结合Huffman树进行解压缩。
bool File_Compress::Un_Compress(const std::string& FilePath)
{
//1.从压缩文件中读取我们解压缩所要用到的信息。
FILE* Fin = fopen(FilePath.c_str(), "rb");
if (Fin == nullptr)
{
std::cout << "open error" << std::endl;
}
//读取文件后缀
string PostFix;
Get_line(Fin, PostFix);
//读取频次信息总行数
string strcontent;
Get_line(Fin, strcontent);
size_t linecount = atoi(strcontent.c_str());
strcontent = "";
for (size_t i = 0; i < linecount; ++i)
{
Get_line(Fin, strcontent);
//证明其读到一个换行符
if ("" == strcontent)
{
strcontent += "\n";
Get_line(Fin, strcontent);
}
//file_byteinfo[strcontent[0]].ch = strcontent[0];
file_byteinfo[(uchar)strcontent[0]].appera_count = atoi(strcontent.c_str() + 2);
strcontent = "";
}
//2.恢复Huffman树
Huffman<Byte_Info> ht;
Byte_Info Invalid;
ht.Create_Huffman(file_byteinfo, 256, Invalid);
//3.读取压缩数据,结合Huffman树进行解压缩
string filename("3");
filename += PostFix;
FILE* fout = fopen(filename.c_str(), "wb");
uchar buf[1024];
uchar bitcount = 0;
Huffman_Tree <Byte_Info>* cur = ht.Getroot();
const int file_size = cur->weight.appera_count;
int compress_size = 0;
while (true)
{
size_t rdsize = fread(buf, 1, 1024, Fin);
if (0 == rdsize)
{
break;
}
for (int i = 0; i < rdsize; ++i)
{
uchar ch = buf[i];
bitcount = 0;
while (bitcount < 8)
{
if (ch & 0x80)
{
cur = cur->right;
}
else
{
cur = cur->left;
}
if (nullptr == cur->left && nullptr == cur->right)
{
fputc(cur->weight.ch, fout);
cur = ht.Getroot();
compress_size++;
//为了避免读取脏数据
if (compress_size == file_size)
{
break;
}
}
bitcount++;
ch <<= 1;
}
}
}
fclose(Fin);
fclose(fout);
return true;
}
效果图
文本文件:
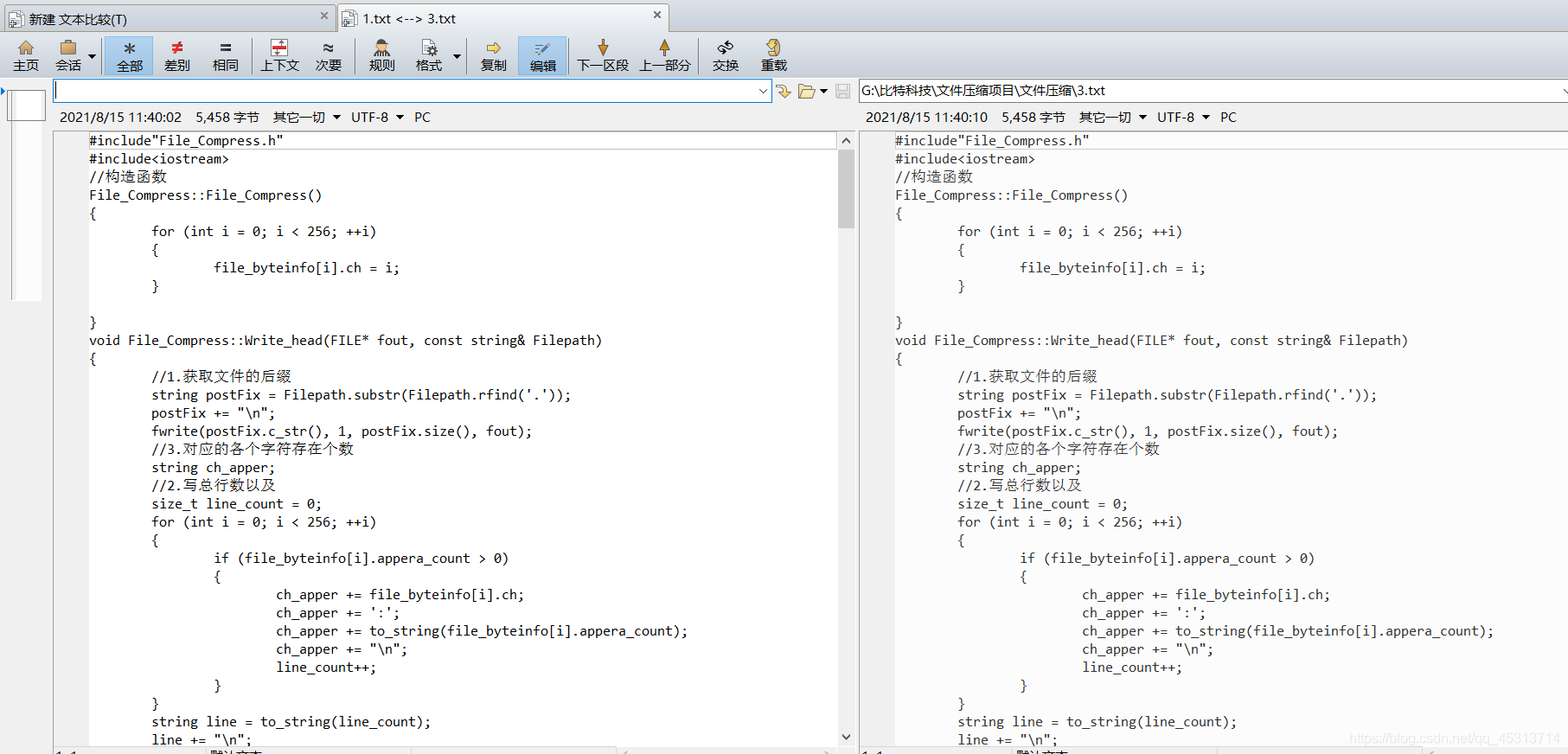
成果
压缩率
文本类文件:.txt/.c/.cpp
83%
二进制类文件: png文件 .jpg文件
95% ~ 99% 平均98%
视频类文件:
93%~94% 多个文件测试下来平均为94%
一些问题
什么情况下压缩变大的可能比较大?
文件中出现的字节种类非常多,并且分布比较均匀的情况下,此时构建出来的Huffman树相当于是一个接近平衡的二叉树。
并且字节编码长度大于8的节点个数> 字节编码长度小于8的长度。此时压缩文件必定会比源文件大。
项目中遇到的一些问题
1.因为没有注意到边界值导致出现解析过多的问题。
因为是按位存储的,所以有时候会出现一个字节八位并未填充满的情况,此时再按照八字节去解析的话,解析最后一位时,很可能出现多解析的情况。
解决方案:利用构建出的Huffman树的根节点的权值来设立边界,因为根的权值就代表了总的节点个数,此时只需将解析出来的字符总数与根节点的权值做对比即可,满足就跳出循环。
2.中文字符解析所出现的越界问题。
初始时使用的是char作为保存每个节点的字符,char的表示大小为-128~127.
此时以char作为数组下标的话会出现越界问题。
解决方案:将char类型换为unsigned char
3.压缩文件的写入方式导致的数据丢失问题
以文本形式读取压缩文件时,此时文件读取函数再读取到-1(0xff)时,就认为其读取到了文件尾。就停止读取。
解决方案:
1、二进制文件是把内存中的数据按其在内存中的存储形式原样输出到磁盘上存放,也就是说存放的是数据的原形式。
2、文本文件是把数据的终端形式的二进制数据输出到磁盘上存放,也就是说存放的是数据的终端形式。
将其压缩文件(原为文本文件)转为二进制文件。来规避这个问题
feof()的原理:
feof()函数,并不是通过读取到文件的EOF来评判,这个文件是否为空。
一般EOF = -1
对feof()来说,它的工作原理是,站在光标所在位置,向后看看还有没有字符。如果有,返回0;如果没有,返回非0。它并不会读取相关信息,只是查看光标后是否还有内容。














 2223
2223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









