







文章目录
前言
关于学习elasticsearch的初期笔记,欢迎各位大佬指正!安装elasticsearch
下载安装了elasticsearch6.6.2版本的,解压之后如下所示:
进入bin,点击elasticsearch.bat,
然后闪退。。。。。。。。
然后又以命令行的形式再次进入那个elasticsearch.exe程序,然后报错。。。报的是:“此时不应有 \Java\jdk1.8.0_181\bin\java.exe”。。。
这个问题百度了个把小时,问题是说在jdk的javahome变量中不能有空格啥的,都是说要换一个jdk路径,还有说卸载重新装jdk的。。。我嫌弃太麻烦了。。。。不想换
最后终于找到了一篇博文,解决了!博文如下:
启动ElasticSearch闪退,并显示: “此时不应有 \Java\jdk1.8.0_181\bin\java.exe,,,”
也是修改javahome的路径,不过不用更改路径;
原有自己的路径是:
C:\Program Files (x86)\Java\jdk1.8.0_161
修改后,变成这样就可以了:
C:\Progra~2\Java\jdk1.8.0_161
这样就解决了!!!再点击就可以启动了,如下:
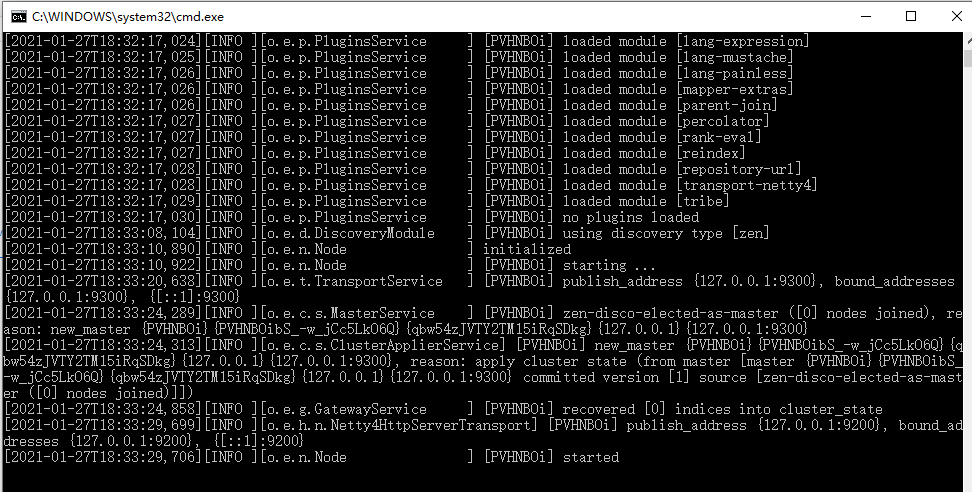
然后测试访问这个地址:
http://127.0.0.1:9200/
当出现一些json信息,我的是火狐,如下:
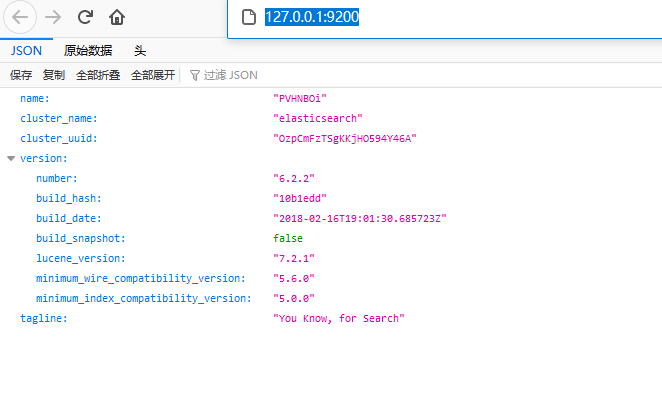
这就说明安装成功啦!
elasticsearch基础
定义
安装好之后,我觉得还是先了解下这个是什么东西才好。。。。根据官网定义如下:
Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene™ 基础之上。
Elasticsearch 也是使用 Java 编写的,它的内部使用
Lucene 做索引与搜索,但是它的目的是使全文检索变得简单, 通过隐藏 Lucene 的复杂性,取而代之的提供一套简单一致的
RESTful API。
然而,Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确的形容:
一个分布式的实时文档存储,每个字段 可以被索引与搜索
一个分布式实时分析搜索引擎
能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
注意下面的这些描述是很重要的!!!
一个分布式的实时文档存储,每个字段可以被索引与搜索
一个分布式的实时分析搜素引擎
能胜任上百个服务节点的扩展,并支持PB级别的结构化或者非结构化数据
基础
在百度关于这个elasticsearch资料的时候,我看到很多人都定义如下:
elasticsearch是一个面向文档型的数据库;
老实说,明明不是介绍说是一个搜索引擎吗,咋又是数据库了。。。。我疑惑了很久,然后注意到前面的定义!!!
一个分布式的实时文档存储,每个字段 可以被索引与搜索
也就是说同样可以存储数据,跟数据库没区别;然后以下是简易的一种对比:
在mysql这样的关系型数据库中,存储数据的格式如下:
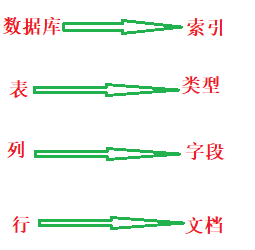
数据库 表 行 列
而在elasticsearch文档型数据库中,存储数据的格式如下:
索引 类型 文档 字段
上面是一一对应的,也就是说,一个索引对应着一个数据库,一个类型对应着一张表,一个文档对应着一行,一个字段对应着一列;画一张图看起来更加直观,如下;
这样解释其实还是感觉有点抽象,话不说多,直接看示例;在elasticsearch权威手册中,有一个例子是说索引员工文档,使用的restful实现跟elasticsearch交互的,如下:
ps:put是相当于add;
PUT /megacorp/employee/1
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
那么这个
PUT /megacorp/employee/1
包含了三部分信息,如下:
megacorp
索引名称
employee
类型名称
1
特定雇员的ID
那么我在mysql数据库中建库megacorp建表employee,插入跟上面一样的数据,然后查询如下:

然后再画一张图,表示其关系,如下:

这样就能够很清晰的看到了其和mysql的异同;
注意黄色框框的部分!
在前面定义的时候有提到,elasticsearch是
一个面向文档的数据库
在这里我个人认为就有体现面向文档数据库这个概念;理由如下:当我们在mysql中描述存储信息中,能够反映其信息的往往就是一行数据,比如这一行信息,就表明了这个员工如下信息:

这是一个25岁,名叫John Smith的喜欢攀岩的男生;
而在elasticsearch中,根据前面的对比,也就是一行表示一个文档,那么同样是一个文档表示了这个信息,如下:
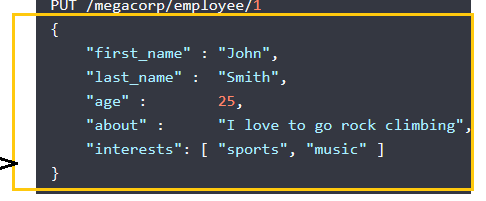
这是一个25岁,名叫John Smith的喜欢攀岩的男生;
这只是一个角度来理解这个elasticsearch的数据库功能,它的功能肯定不止这些;
参考资料:
Elasticsearch: 权威指南
安装Kibana
安装
Kibana 是在ElasticSearch 有了相当多的数据之后,进行分析这些数据用的工具;
我的理解就是,相当于数据库mysql的一些图形化界面使用工具,例如navicat等等,作用是差不多的;具体这个Kibana的用法,有几篇博文很好,如下:
Kibana详细入门教程
大家百度自行下载,我的是跟elasticsearch一样的6.2.2版本,然后跟elasticsearch一样的打开解压的并文件夹下的带bat后缀的,
打开之后稍等一会,就是如下所示:
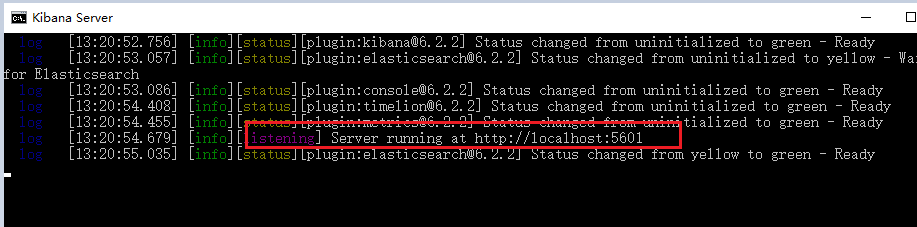
红色标出来的是访问的端口;
安装好之后,在浏览器访问如下端口;
http://localhost:5601/app/kibana#/home?_g=()
那么显示为这样:
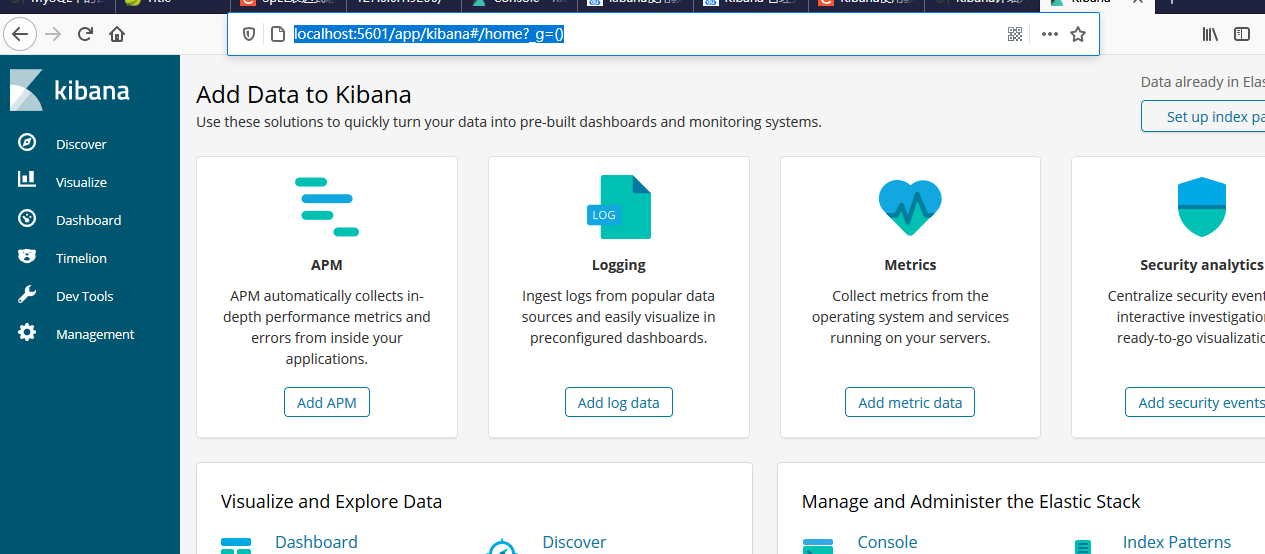
就说明ok了!
至于左边的各个意思的话,如下截图可知:

查看服务状态
点击左边的Dev Tools开发者命令视图,输入:
GET /_cat/health?v
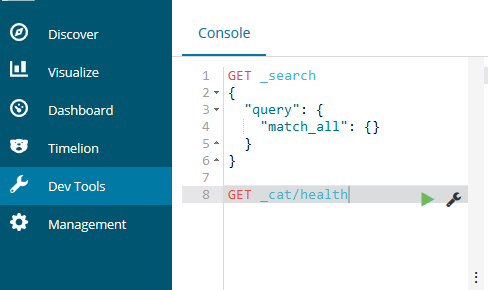
点击工具图形的绿色按钮,显示为如下:

绿色按钮没有变红色,即是健康状态
Kibana索引管理
在基础中有提到,索引相当于mysql中的数据库;
这里使用索引进行管理是使用elasticsearch交互的restful风格方式;至于restful风格是啥的话,简单来说在http协议中,表单提交的方式有post,put,get,delete等等,常用的是get和post;至于更加详细的restful风格,请参考菜鸟教程如下:
在elasticsearch中,表示如下;
PUT 表示增加
GET 表示获取
DELETE 表示删除
POST表示更新
注意,在http协议中,put也可用于更新,post也可用于增加。。。。就很迷糊,这里不展开。
增加索引(数据库)
鉴于之前的基础可知,增加索引就是相当于增加一个数据库;
在Kibana界面中,点击Dev Tools,输入以下语句:
PUT /HelloKibana?pretty
添加 名为HelloKibana的索引pretty解释:
在任意的查询字符串中增加pretty参数,会让Elasticsearch美化输出(pretty-print)JSON响应以便更加容易阅读。
然后就是这个结果:
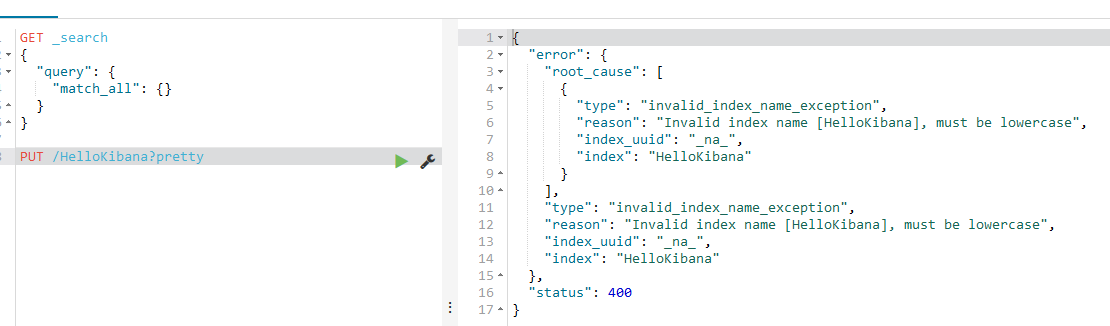
在学习的路途上艰辛啊。。。。查看了一下右边的报错原因:
“root_cause”: [
{
“type”: “invalid_index_name_exception”,
“reason”: “Invalid index name [HelloKibana], must be lowercase”,
“index_uuid”: “na”,
“index”: “HelloKibana”
}
然后改成小写,如下:
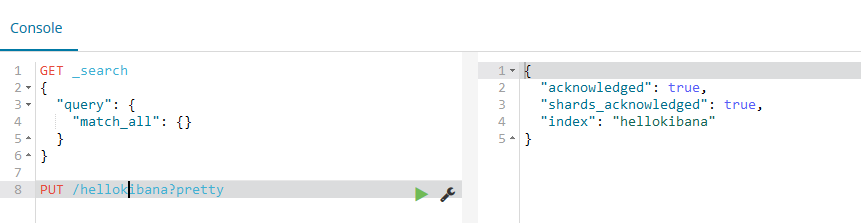
这样就创建索引成功!
获取索引(数据库)
如图所示:
输入:GET /hellokibana?pretty
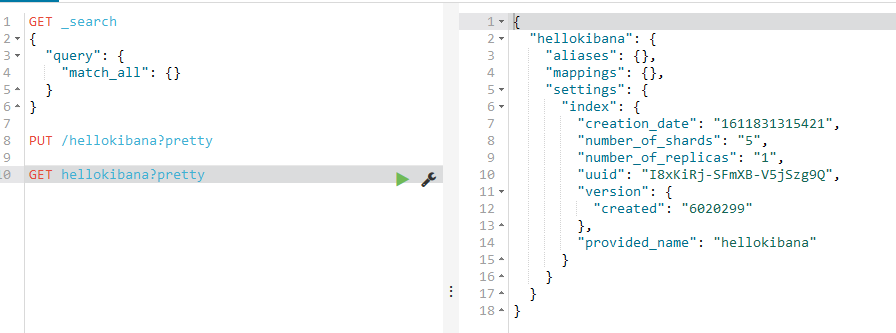
当然也可以使用
GET /_cat/indices?v
注意:这个v是打印出表头信息
如下,使用这个语句为:
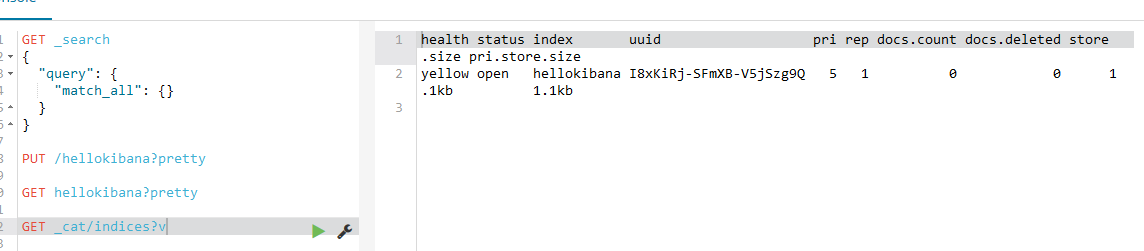
这个语句的意思是查询索引信息
那么查询具体的索引信息语句,如下:
GET _cat/indices/这里是索引名
删除索引(数据库)
也是一样的,区别是提交的方法不一样,如下删除数据:
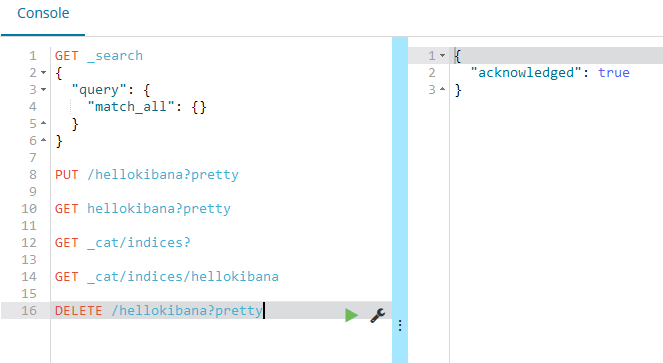
这个acknowledged返回true,就是删除成功;这个acknowledged是承认的意思;
也可以查看一下是否删除成功,运行
GET _cat/indices?v 查询语句后,如下:
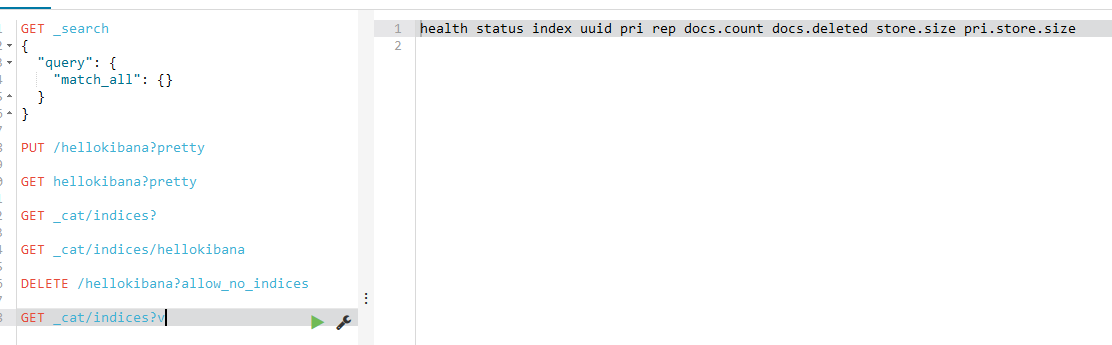
一片空白。。。说明已经删了。
更多相关crul命令
上面使用的命令是属于crul命令;出入量其全名是来自于client客户端这个单词,加上url。。。。加起来就是curl单词了,所以就是客户端的url工具意思了;
更多的命令,参考博客,如下:
Kibana安装中文分词器
分词器指的是搜索关键字的时候,将关键字拆分几个字进行搜索。
其实有默认的分词器,例如在Console中输入语句:
GET _analyze
{
“text”:“我爱打篮球”
}
如图所示:
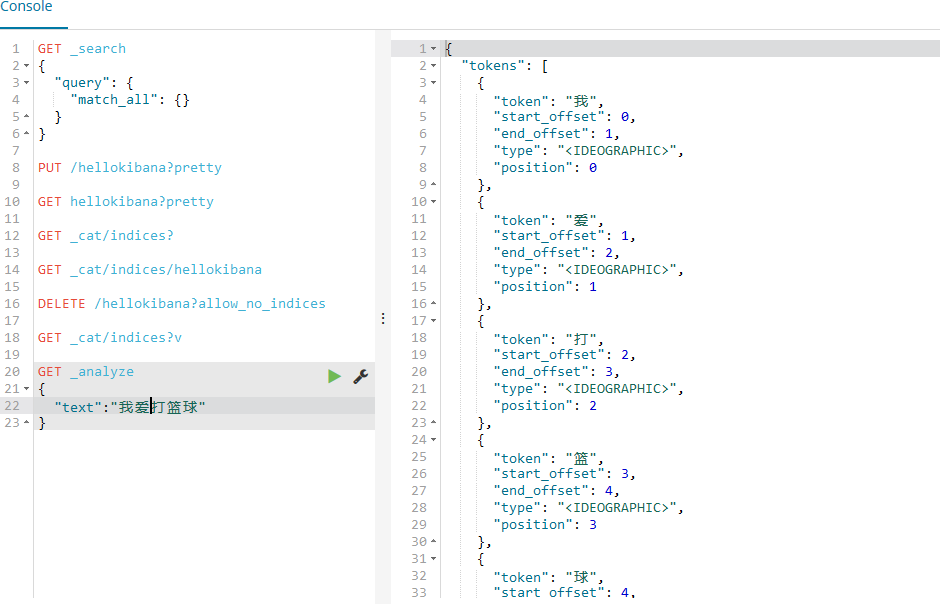
这个就。。。单纯的分为了一个字这样。。。。这样就不符合语义。。。所以才需要一个插件也是中文分词器;这个插件需要下载安装;
可以使用Node.js进行安装,Node.js如何安装,请看博文:
ElasticSearch学习笔记(三)-可视化界面Kibana及ES中文分词配置
我这里是采用了直接下载了这个6.6.2版本的分词器插件,如下:
然后打开elasticsearch解压目录下的bin文件夹,输入以下语句:
elasticsearch-plugin install
file:\\D:\elasticsearch\esdownload\elasticsearch-6.2.2\elasticsearch-analysis-ik-6.2.2.zip
以上file后面是我下载的位于elasticsearch解压目录下的地址;也就是在bin目录下,输入:
elasticsearch-plugin install +file:\\插件文件(目录+文件名)
然后这样就是安装成功,如下:

注意点:
这个下载的插件压缩包一定要在elasticsearch的解压目录下,要是在其它目录,就安装不了,会报错,如下:
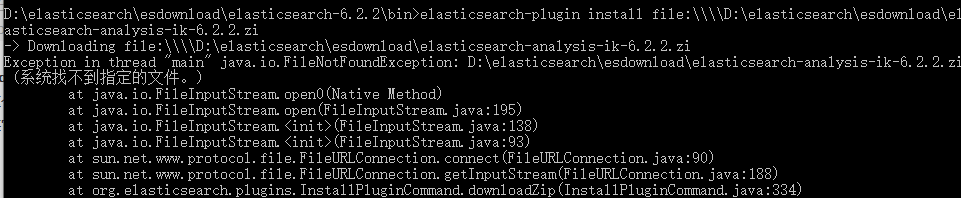
安装成功之后,就要检验是否生效,那就得重启kibana和elasticsearch;关闭两个的bat文件,再打开;
打开之后,再次在浏览器输入:
http://127.0.0.1:5601/app/kibana#/dev_tools/console?_g=()
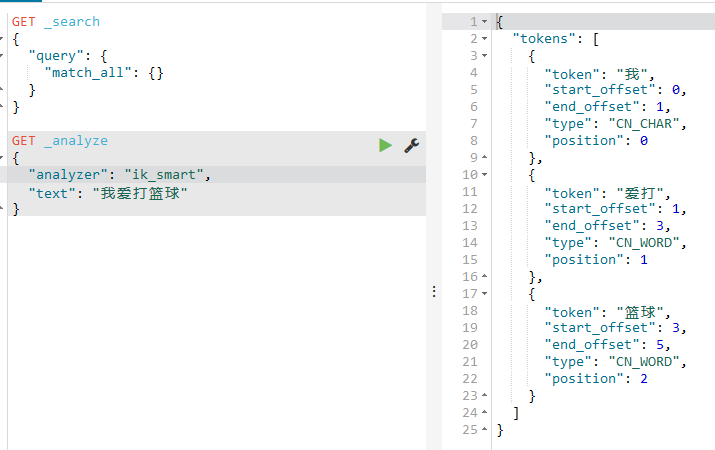
然后输入以下语句,关键词还是我爱打篮球,如下:
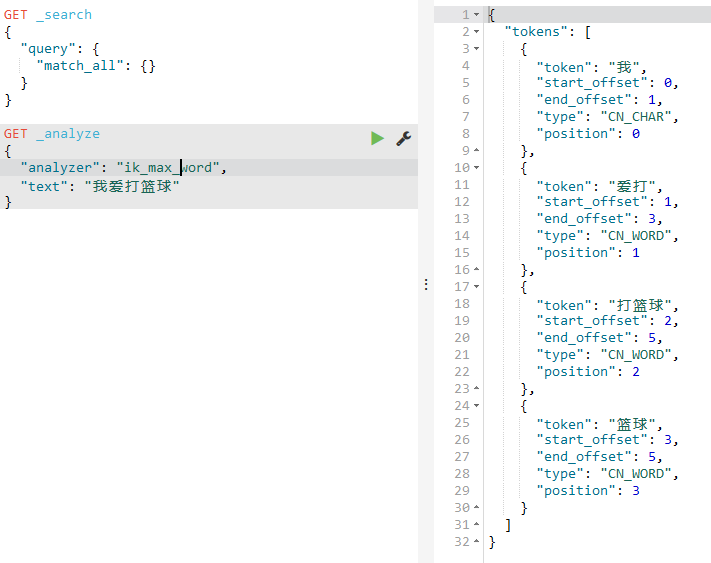
跟原来的相比,这个分词器就符合咱们的语义了,就很nice!
当然这里的:analyzer有两个值:
一个是ik_max_word:最大的化的中文分词器,也就是在符合一定语义下最细粒度的拆分;
一个是ik_smart :较为简易的分词器,粒度比起前面的而言要小;
试下第二个,如下结果:
至于更为详细的关于分词器,参考博文,如下:
es的分词器analyzer
Kibana类型管理(表)
其实说是文档管理也行,虽然文档是属于类型的一部分,但是归属类型也是为了实现文档管理;
前面我们学了建库(索引),接下来就是建表(类型)以及crud的操作了;
因为建类型也是为了实现建文档,索引直接一起操作了;
添加文档
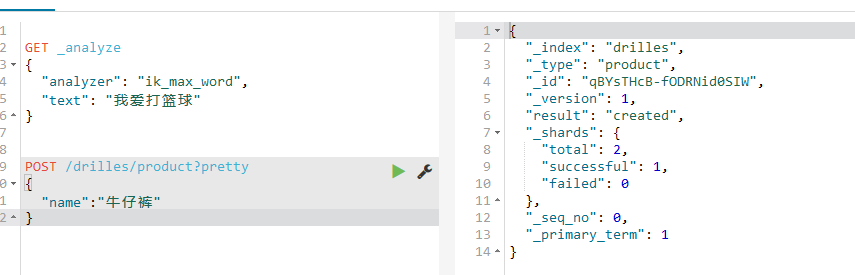
按照crul命令,挺简单的,添加语句:
POST /drilles/product?pretty
{
“name”:“牛仔裤”
}
添加成功会如下所示:
然后用PUT也可以实现添加,如下:
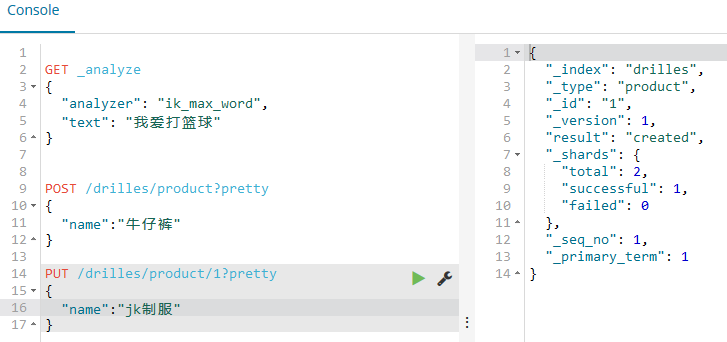
这里等会再讨论区别;
获取文档
获取就是GET
如下:
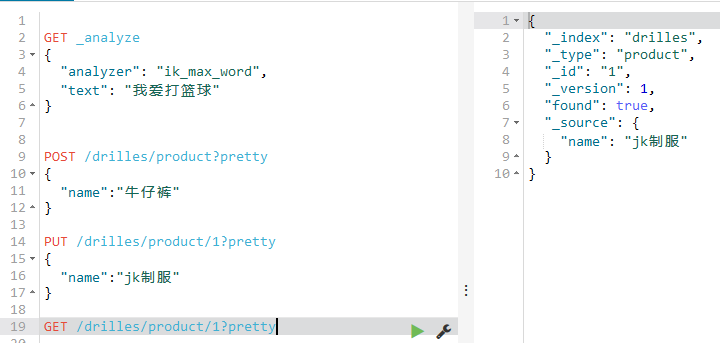
获取的右边,依次的含义如下:
_index 表示哪个索引
_type 表示哪个类型(表)
_id 主键
_version 版本
found 数据是否存在
_source: 数据内容
注意:
前面添加牛仔裤的时候,我是用POST的语句的时候,是没有指定id的,这样默认就是一个uuid,所以要获取那个牛仔裤,不指定id获取不到,我目前初学是不晓得怎么获取到的,要是不指定id获取,如下:
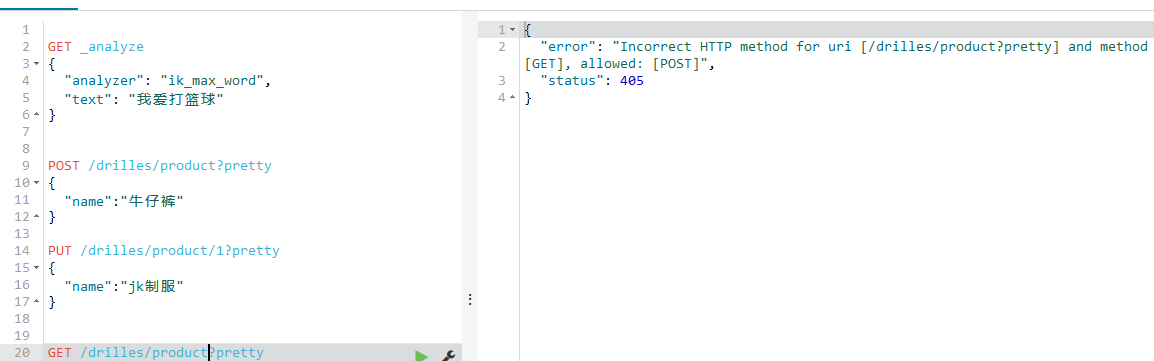
报错是说:应该使用POST,说我使用GET是不准确的请求方法
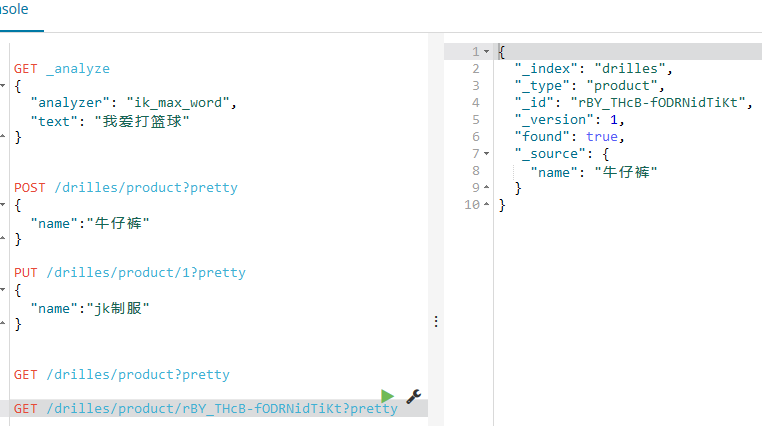
之后我重新创建了一个文档,也是使用POST方式,并且将右边的uuid复制下来,然后再次使用GET获取,并且指定id,这样就能获取了,如下:
修改文档
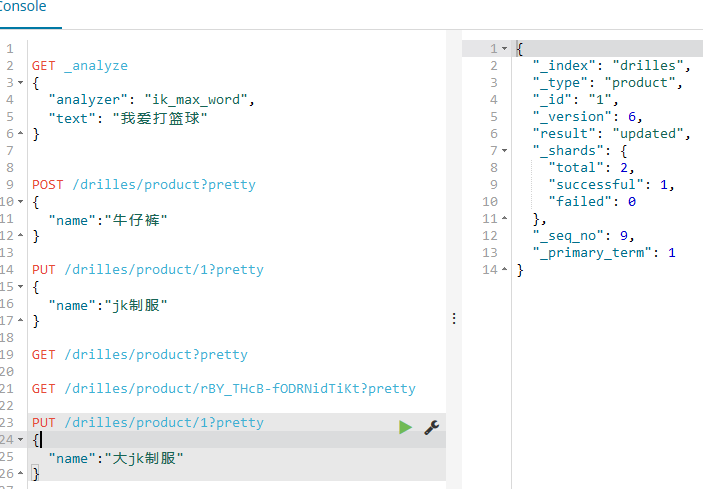
使用POST或者PUT都能够实现修改,这里以前面的jk制服为例,因为这个之前指定了id为1;
使用PUT
如下:
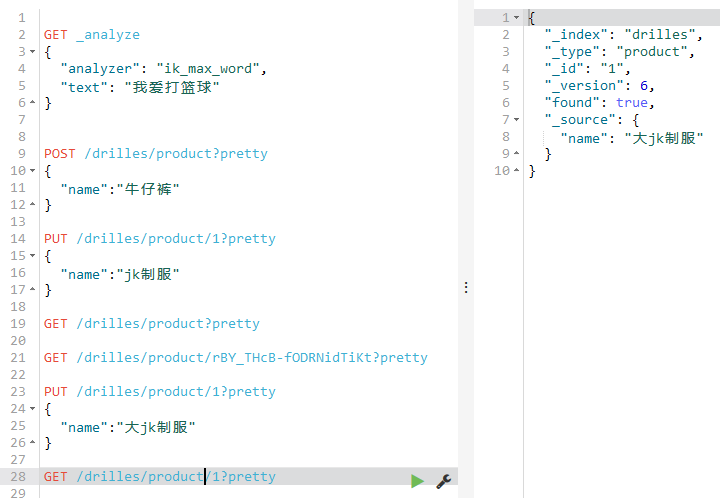
然后获取,看是否修改成功,如下:
使用POST
如下:
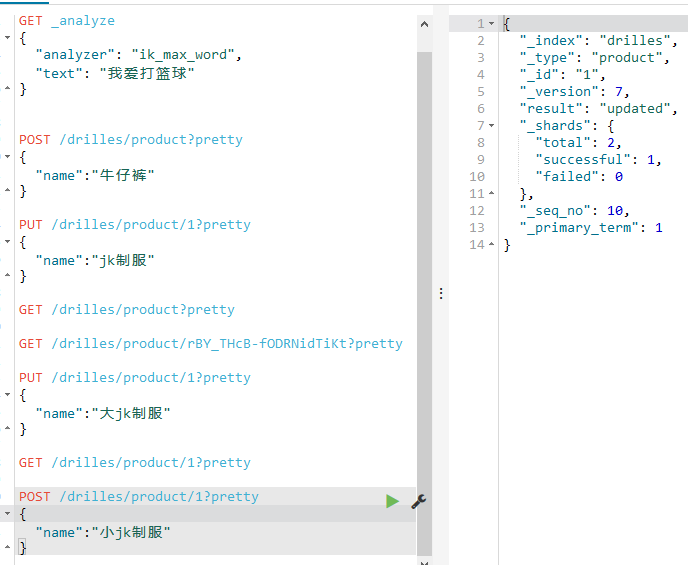
获取验证是否成功如下:
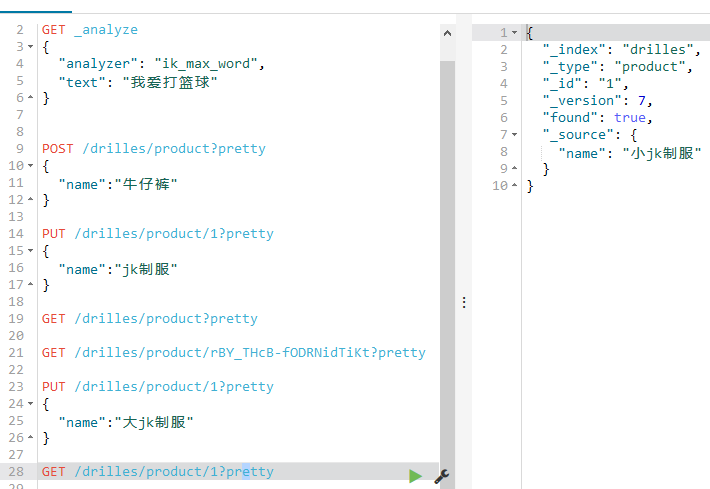
注意:
a.可以看到_version的值为7,也就是已经修改7次了,是第7个版本;
b.即使这个id为1的文档删除了,当我们再次指定id为1的文档数据的时候,这个_version也是会随着变化!
POST和PUT区别
前面有提到POST和PUT都能实现添加和修改操作,那么区别是啥?
需要了解的知识是:a.幂等是什么?
幂等(idempotent、idempotence)是一个数学与计算机学概念,常见于抽象代数中。
在编程中.一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。幂等函数,或幂等方法,是指可以使用相同参数重复执行,并能获得相同结果的函数。这些函数不会影响系统状态,也不用担心重复执行会对系统造成改变。
简而言之,就是多次重复操作之后,是否会影响系统的状态;
b.post不是幂等的;
put,get,delete是幂等的;但是需要注意的是只有get是安全的,毕竟只是获取资源,没有对资源进行更新啥的;put和delete虽然是幂等的,但是不是安全的;
理由:
第一点:
因为POST不是幂等的,而且是作用到集合资源上的;作用到集合资源上是指?
也就是不用加具体的id,也能够实现添加,添加的范围为:/索引/类型
如下:
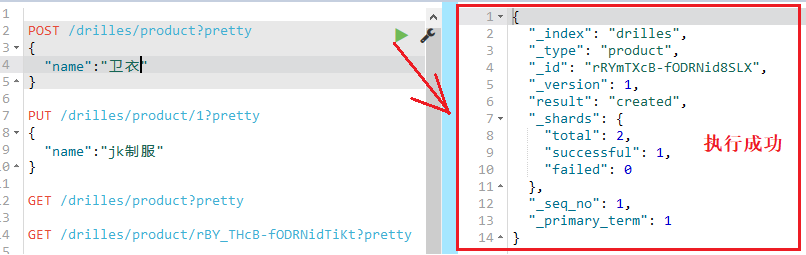
第二点:
PUT是幂等的,而且是作用到具体的资源上的;作用到具体的资源上是指?
需要加上具体的id,才能够实现添加,添加的范围为:/索引/类型/id
如下:

结论如下:
a.基于restful设计的风格而言,设计的是POST为不安全且不是幂等的,所以才会让POST是作用到集体资源上也能够成功,因为这样就是随机创建了一个uuids为主键的文档信息,每一次都是随机创建一个id,这不就是印证了改变系统的状态了吗?;
b.然后PUT虽然是不安全的,但是幂等的,所以才需要作用到具体的资源,因为只有具体到某个资源,有其确定的id才能够让这个系统不改变;
c.因而言,还是得具体情况具体分析,我认为一般而言使用幂等PUT更新资源,不幂等POST添加资源;
参考博文:
ES 中的 POST 和 PUT 的区别
删除文档
删除文档,使用的也是一样的,只是提交的方式不一样而已,如下:
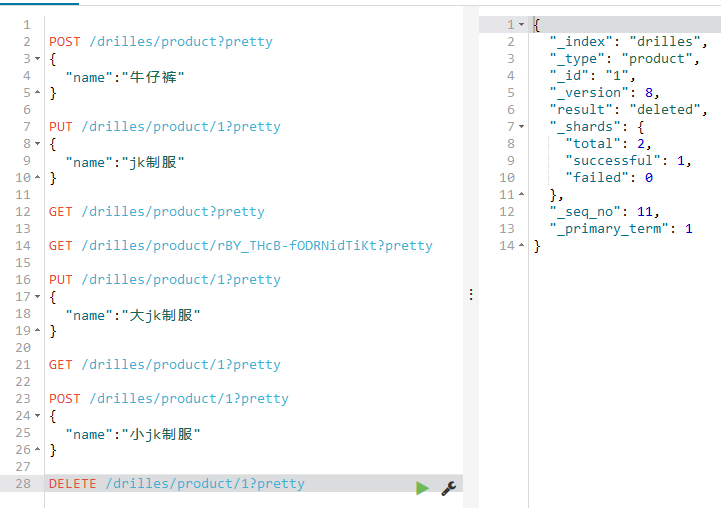
注意,可以看到上面的_version变为了8,这也验证了前面的注意点;
Kibana批量导入
Kibana实现批量导入,可以指定其字段的,也就是相当于mysql中的列属性;
导入两条数据,
如下:
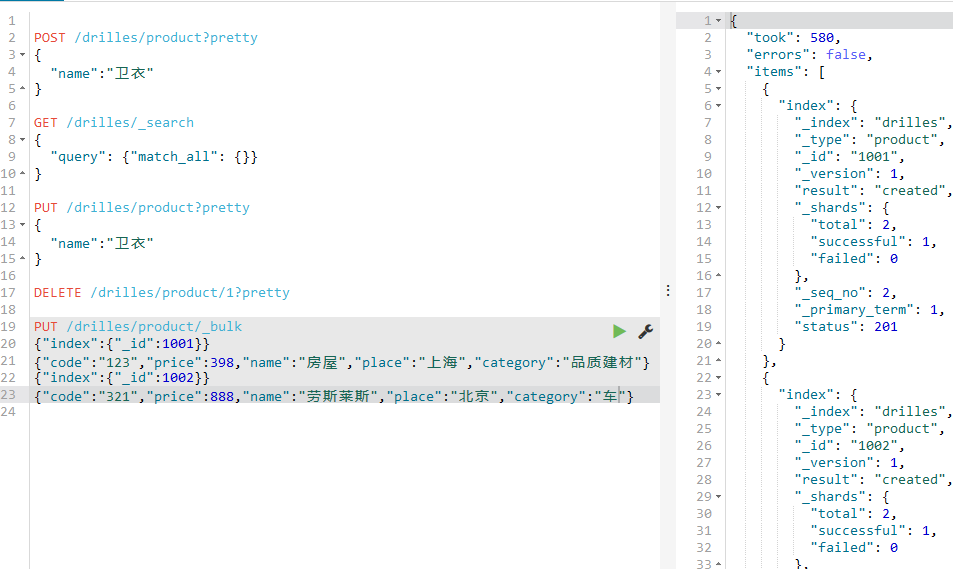
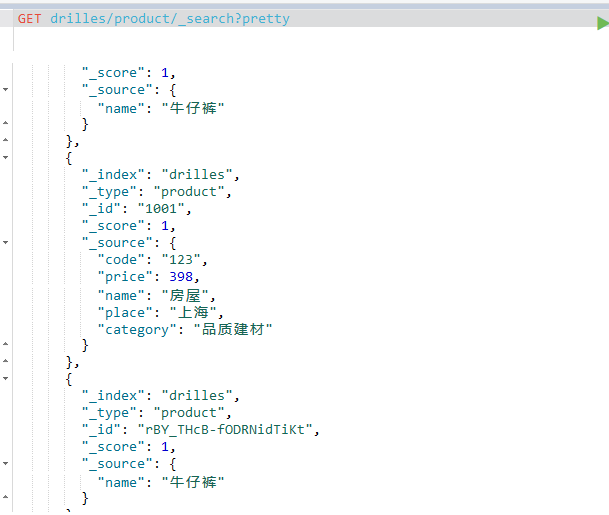
然后获取该索引的所有内容!这里插一句,前面的获取文档无法获取一个索引的内容,这里就学到了~~~~~
只需要在索引后面加上
_search 就能够实现查询到这个索引下的所有数据了,如图所示:
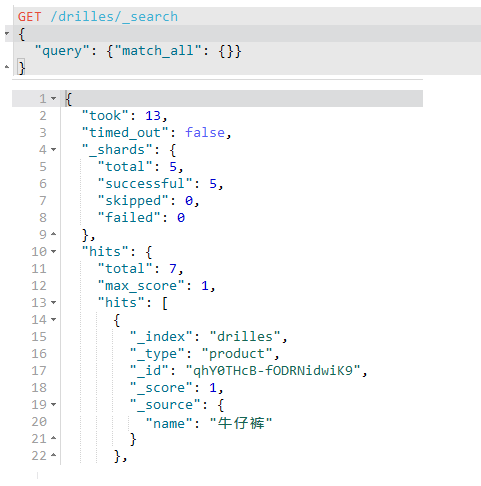
除此之外,还有一种写法,如下:
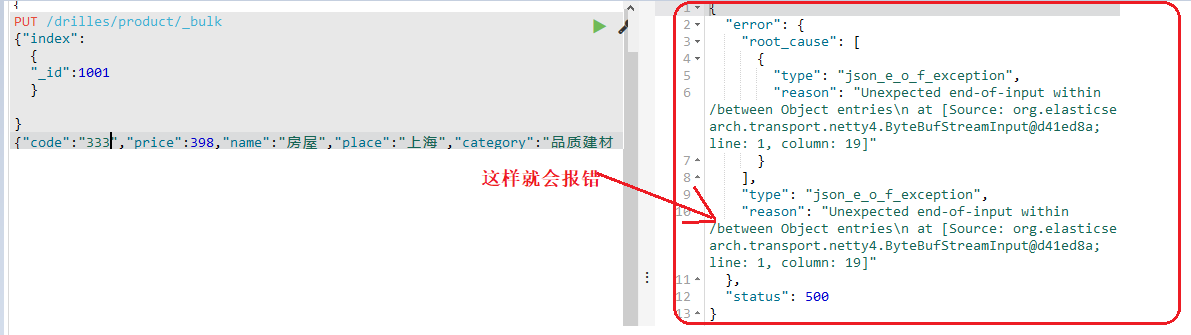
注意点:
a.使用POST或者PUT都可以,我这里应该用POST的,我没改了。。。b.可以使用json串代替斜线的内容,但是bulk不能代替,bulk单词的意思是大量,批量的;如下:
{“index”:{"_index":“drilles”,"_type":“product”,"_id":10001}}
curl批量导入
安装
上面那种批量导入的方法,要想导入大量的数据就很麻烦了。。。。所以使用curl工具就能够导入大量数据;
之前也有介绍,curl是一个可以模拟浏览器向服务器提交数据的命令行工具;首先得下载,
下载地址:
curl下载地址
然后一直往下滑,滑到如图所示位置:
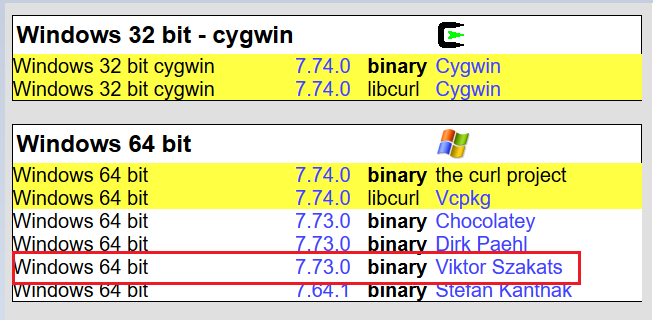
选择这个维克多版本的,网上说这个好用点;点击之后下载,下载完解压之后是这样的,如下所示:
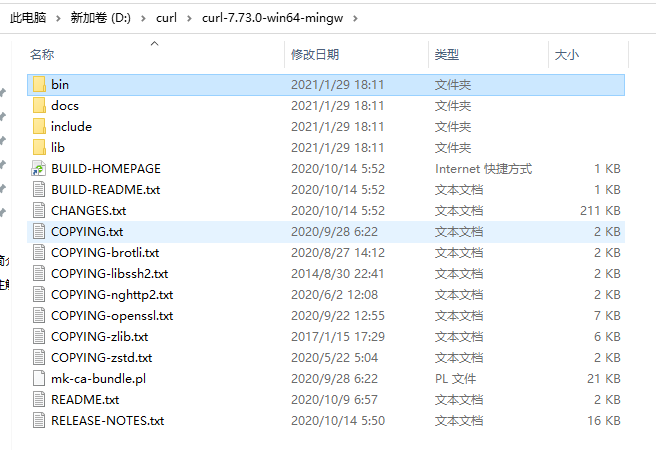
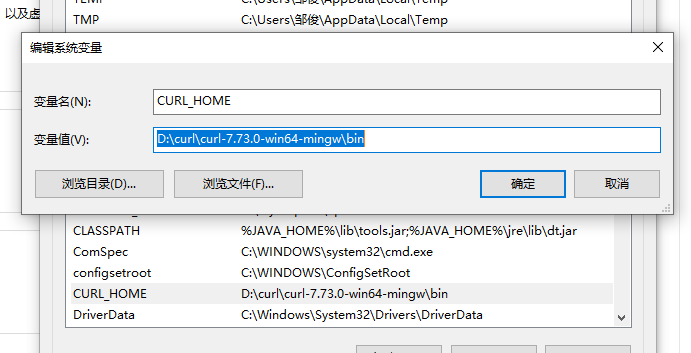
然后配置环境变量,这个跟配置jdk是一样的嘞。
先配置系统变量,如下:
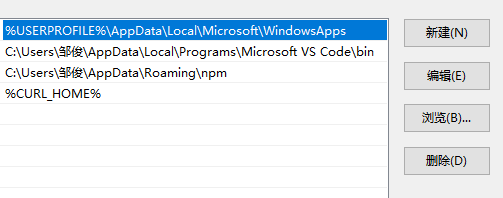
然后再配置用户变量,点击用户变量的Path,然后点击编辑
然后打开cmd,输入curl -help,显示为下面这样就是成功了:
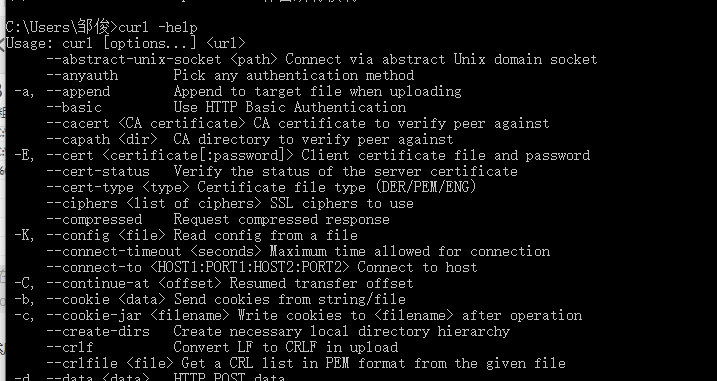
注意:
有个疑问,等下次空闲的时候重启电脑实验下。。。。
不知道用curl --help命令之后显示的结果,是不是配置了环境变量的结果,因为我一开始配置好环境变量之后,点了确定再之后又删除了,可是还是能使用curl --help显示上述结果。。。。
参考文章:
curl命令下载安装并使用(Windows版本)
批量导入
准备一个json文件,这个大家自行准备了。。。。可以百度一个json文件,里面就是json数据;注意,这个json文件,必须要放到crul.exe同一文件夹下,如图所示:
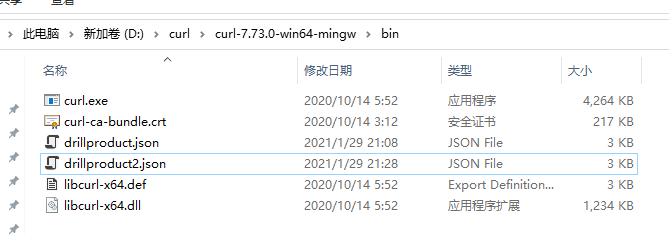
注意自己存放curl的解压目录所在位置!!!像我在d盘需要切换盘符
cd d: 切换盘符
打开cmd命令行,输入以下内容:
cd D:\curl\curl-7.73.0-win64-mingw\bin
d:
解释:
cd +curl.exe所在目录 后面加个d:是直接切换为路径,如下:
curl -H “Content-Type: application/json” -XPOST “localhost:9200/drilles2/product/_bulk” --data-binary “@drillproduct2.json”
解释:
-H 请求头
-X 请求方法
–data-binary 二进制文件
@+json文件名
点击回车,然后就报错。。。。。。。报错如下:
The bulk request must be terminated by a newline。。。。
百度了一下,是因为在我们提供的json文件中,必须要一空格一行结尾,如下:

增加空格后再度执行就成功了,如下:

然后可以在Kibana中查看导入的数据,如下:
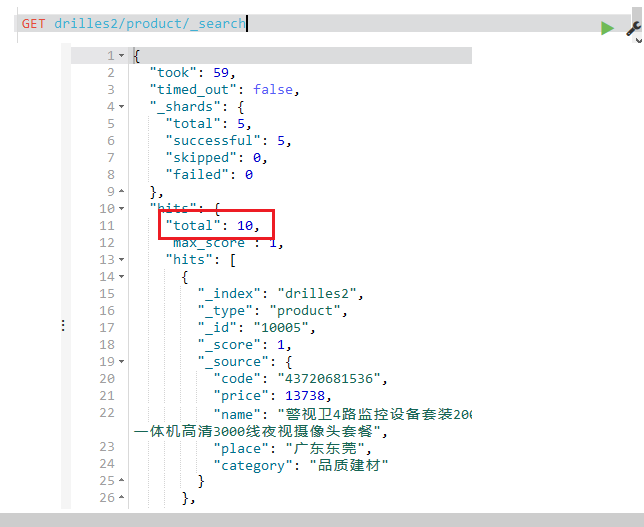
数据导入总数跟json中的对的上,说明导入没有少;导入成功
Kibana查询操作
前面我们批量导入了10条数据,还是稍微少了点。。。。所以我就自己又导入了10条数据,这样一共就是二十条数据了;
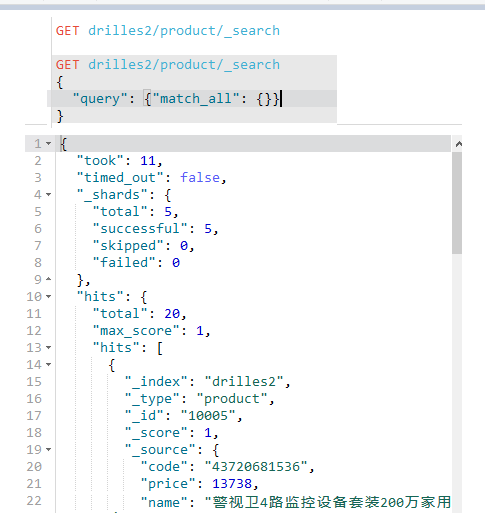
查询所有
之前有提到过查询所有的语句,如下:
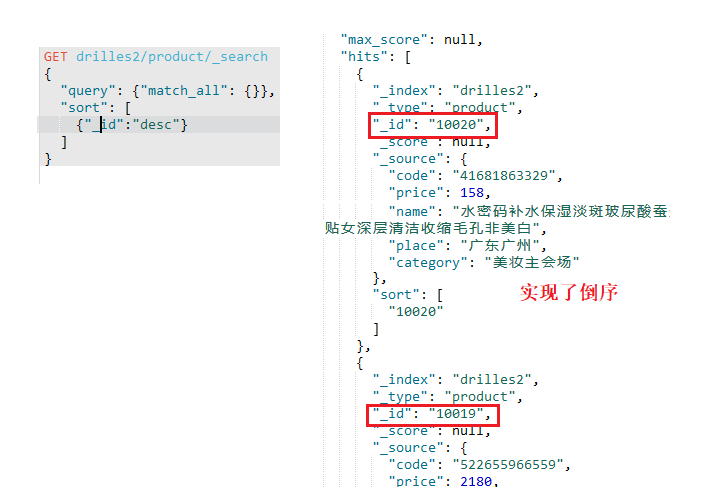
排序查询
跟mysql一样的,也有排序,如下:
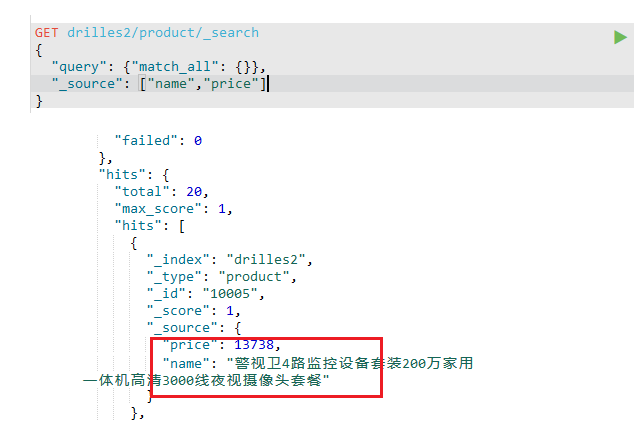
查询部分
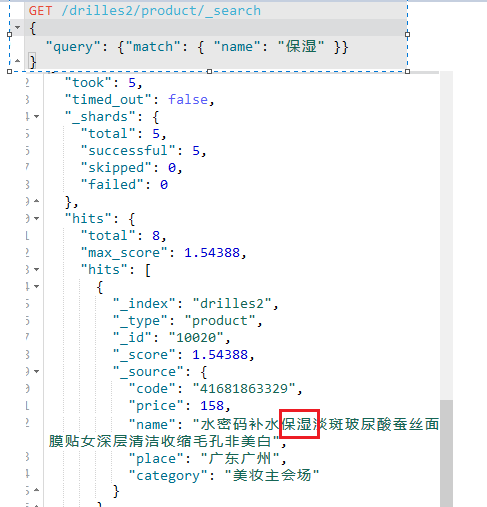
条件查询
在我的20条数据中,_id为10020的name如下:

按照条件匹配为保湿两个字,match英文单词的意思是匹配,如下:
还可以匹配多个字段,以及匹配跟mysql中模糊查询一样的效果,以下为引用博文elasticsearch中多条件查询(匹配某个字段值、匹配以某个字符开头)
GET /index-name/_search
{
"query" : {
"bool" : {
"must" : [
{
"match" : { //匹配某个字段值
"field-name" : "query-value" //"字段名":"字段值"
}
},
{
"prefix" : { //匹配前缀
"field-name" : { //字段名
"value" : "/" //"value":"要匹配的前缀值",这里我匹配的是以/开头的
}
}
}
//,{}有其他的条件可继续往后加
]
}
}
}
如下实现匹配前缀:
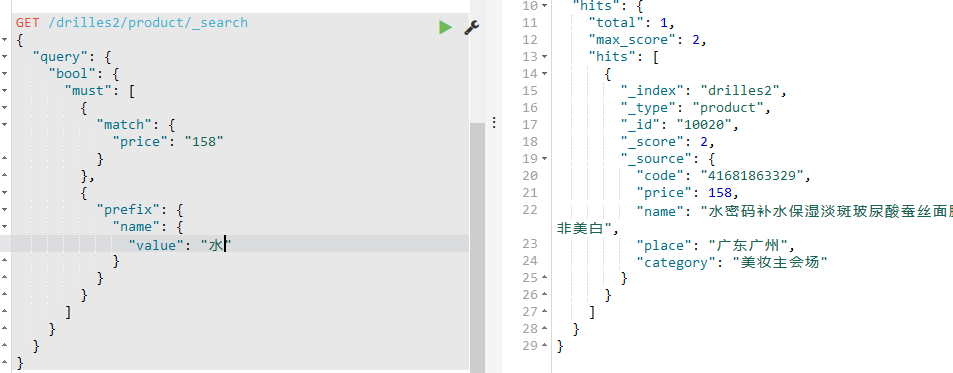
注意点:
前缀不是多个字符,是以什么开头的一个字符,比如这里的水,而不能是水密码,水密等等,多个字符会查询到null,如下:
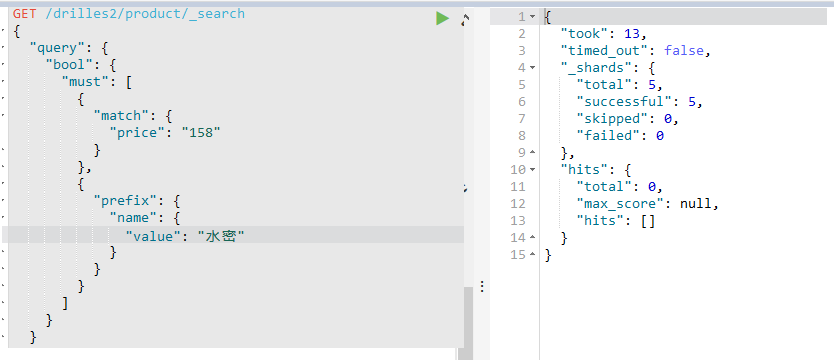
分页查询
跟关系型数据库一眼,有分页查询,如下:

值得注意的是:
from 指的是按照排序之后的第一位,从开始的
size 指的是查询几条数据,这个跟mysql中的limit是一样的效果;
聚合查询
在mysql中,使用sql语句,是有聚合函数需求的,比如查询数量;
举例如下:
查询产品中每个地方的数量,只显示3组分组数据;
如下:

上面的查询,相当于在mysql中的查询如下:
select count(*),place from product group by place limit 0,3
聚合函数的模板如下;
"aggregations" : {
"<aggregation_name>" : { <!--聚合的名字 -->
"<aggregation_type>" : { <!--聚合的类型 -->
<aggregation_body> <!--聚合体:对哪些字段进行聚合 -->
}
[,"meta" : { [<meta_data_body>] } ]? <!--元 -->
[,"aggregations" : { [<sub_aggregation>]+ } ]? <!--在聚合里面在定义子聚合 -->
}
[,"<aggregation_name_2>" : { ... } ]* <!--聚合的名字 -->
}
ps:aggs是aggregations的缩写
这里只简单的展示一种聚合函数,更多的聚合函数知识,参考文章如下:
Elasticsearch(8) — 聚合查询(Metric聚合)
注意点:
在聚合函数中,有注意到字段,不是使用的字段名place,而是使用的place.keyword,如下所示:
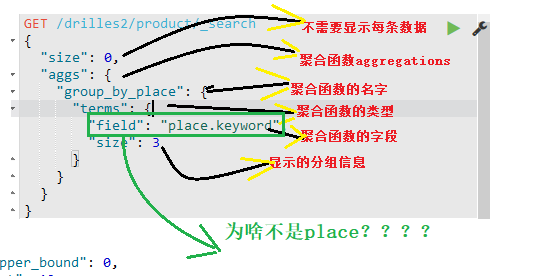
在elasticsearch中,2.x版本的话字符串数据类型只有string类型,到了5版本之后,取消了string类型,转而使用text和keyword类型;
区别如下:
a.text类型在存储数据的时候会默认进行分词,并生成索引。而keyword存储数据的时候,不会分词建立索引;
b.基于text类型会分词,所以当我们分组查询的时候。。。。那就是把一个词分开来分组了,这明显不符合;所以使用keyword这样不分词确定的一个词来进行聚合排序;
c.test类型的最大支持的字符长度无限制,适合大字段存储;keyword类型的最大支持的长度为——32766个UTF-8类型的字符,可以通过设置ignore_above指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果。














 7763
7763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









