






收到用户反馈DG上查不到最近一天的数据,怀疑同步有问题
一、检查备库同步情况 两个节点都未看到MRP0进程
SQL> select process,status,thread#,sequence# from v$managed_standby;
PROCESS STATUS THREAD# SEQUENCE#
------------------ ------------------------ ---------- ----------
ARCH CLOSING 6 174201
DGRD ALLOCATED 0 0
DGRD ALLOCATED 0 0
ARCH CLOSING 5 284619
ARCH CLOSING 5 280446
ARCH CLOSING 6 152822
RFS IDLE 0 0
RFS IDLE 0 0
RFS IDLE 0 0
RFS IDLE 6 0
二、查看alert日志发现如下报错 备库ASM 空间满
2023-02-28T16:47:29.089825+08:00
Errors in file /opt/oracle/diag/rdbms/node/NODE1/trace/NODE1_pr00_169293.trc:
ORA-01119: error in creating database file '+DATADG'
ORA-17502: ksfdcre:4 Failed to create file +DATADG
ORA-15041: diskgroup "DATADG" space exhausted
File #1071 added to control file as 'UNNAMED01071'.
Originally created as:
'+DATADG/NODE/DATAFILE/flxeaptbs2.3305.1129999631'
Recovery was unable to create the file as a new OMF file.
PR00 (PID:169293): MRP0: Background Media Recovery terminated with error 1274
2023-02-28T16:47:29.121223+08:00
Errors in file /opt/oracle/diag/rdbms/node/NODE1/trace/NODE1_pr00_169293.trc:
ORA-01274: cannot add data file that was originally created as '+DATADG/NODE/DATAFILE/flxeaptbs2.3305.1129999631'
2023-02-28T16:47:29.123758+08:00
.... (PID:9453): Managed Standby Recovery not using Real Time Apply
三、处理空间问题
查看发现过期备份未删除 已经累计29T了…
grid@NODE1:/home/grid>$ ./asmdu.sh +DATADG/NODE
+DATADG/NODE subdirectories size
Subdir Used MB Mirror MB
------ ------- ---------
BACKUPSET/ 30461584 60923168
CONTROLFILE/ 520 1560
DATAFILE/ 1549554 3099108
ONLINELOG/ 86856 173712
PARAMETERFILE/ 4 8
PASSWORD/ 0 0
TEMPFILE/ 646354 1292708
------ ------- ---------
Total 32744872 6549026
利用原本的删除脚本删除报错
sh clean.sh
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-03002: failure of delete command at 03/01/2023 14:02:41
RMAN-06091: no channel allocated for maintenance (of an appropriate type)
这也找到为什么会把空间撑爆的原因了…这个DB我们接手不久,都是前任DBA留的坑啊…
修改删除策略
run{
allocate channel c1 device type disk ;
allocate channel c2 device type disk ;
allocate channel c3 device type disk ;
allocate channel c4 device type disk ;
allocate channel c5 device type disk ;
allocate channel c6 device type disk ;
allocate channel c7 device type disk ;
allocate channel c8 device type disk ;
allocate channel c9 device type disk ;
allocate channel c10 device type disk ;
allocate channel for maintenance type disk;
crosscheck backup;
crosscheck archivelog all;
delete noprompt obsolete device type disk;
delete noprompt archivelog until time 'sysdate-7' device type disk;
delete noprompt expired backup;
release channel c1;
release channel c2;
release channel c3;
release channel c4;
release channel c5;
release channel c6;
release channel c7;
release channel c8;
release channel c9;
release channel c10;
}
再次执行脚本
sh.clean.sh
''''''
backup piece handle=+REDODG/NODE/AUTOBACKUP/2023_02_20/s_1129314781.5314.1129314783 RECID=47584 STAMP=1129314782
Deleted 4442 objects
''''''
删除成功
空间清理完成
grid@NODE1:/home/grid>$ ./asmdu.sh +DATADG/NODE
+DATADG/NODE subdirectories size
Subdir Used MB Mirror MB
------ ------- ---------
BACKUPSET/ 701954 1403908
CONTROLFILE/ 520 1560
DATAFILE/ 1549554 3099108
ONLINELOG/ 86856 173712
PARAMETERFILE/ 4 8
PASSWORD/ 0 0
TEMPFILE/ 646354 1292708
------ ------- ---------
Total 2985242 5971004
删除后仅剩不到700M…释放出29T空间
四、尝试重新开启MRP0进程
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE DISCONNECT;
Database altered.
执行成功 再次检查
SQL> select process,status,thread#,sequence# from v$managed_standby;
PROCESS STATUS THREAD# SEQUENCE#
------------------ ------------------------ ---------- ----------
ARCH CLOSING 6 174201
DGRD ALLOCATED 0 0
DGRD ALLOCATED 0 0
ARCH CLOSING 5 284619
ARCH CLOSING 5 280446
ARCH CLOSING 6 152822
RFS IDLE 0 0
RFS IDLE 0 0
RFS IDLE 0 0
RFS IDLE 6 0
发现MRP0进程仍然没有启动
再次查看alert日志发现如下报错
Errors in file /opt/oracle/diag/rdbms/node/NODE1/trace/NODE1_mrp0_138218.trc:
ORA-01111: name for data file 1071 is unknown - rename to correct file
ORA-01110: data file 1071: '/opt/oracle/products/19.3.0/dbs/UNNAMED01071'
ORA-01157: cannot identify/lock data file 1071 - see DBWR trace file
ORA-01111: name for data file 1071 is unknown - rename to correct file
ORA-01110: data file 1071: '/opt/oracle/products/19.3.0/dbs/UNNAMED01071'
2023-03-01T14:29:23.252555+08:00
Background Media Recovery process shutdown (NODE1)
原因 : 备库ASM空间不足时如主库新增数据文件 备库会把数据文件传入到dbs目录下
五、解决方案
这个问题MOS上有标准解决步骤,我们正常按照步骤处理就行
How to resolve ORA-01111 ORA-01110 ORA-01157 in a physical standby database (Doc ID 1416554.1)
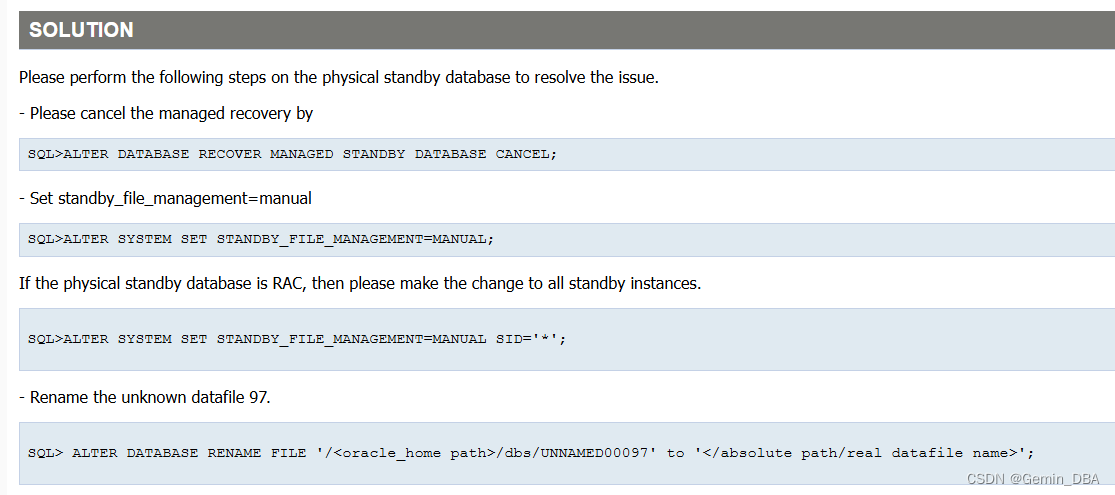
执行方案
SQL> ALTER SYSTEM SET STANDBY_FILE_MANAGEMENT=MANUAL SID='*';
Database altered.
SQL> show parameter db_create_file_dest
NAME TYPE VALUE
------------------------------------ ---------------------- ------------------------------
db_create_file_dest string +DATADG
-- 当前环境已经配置了OMF
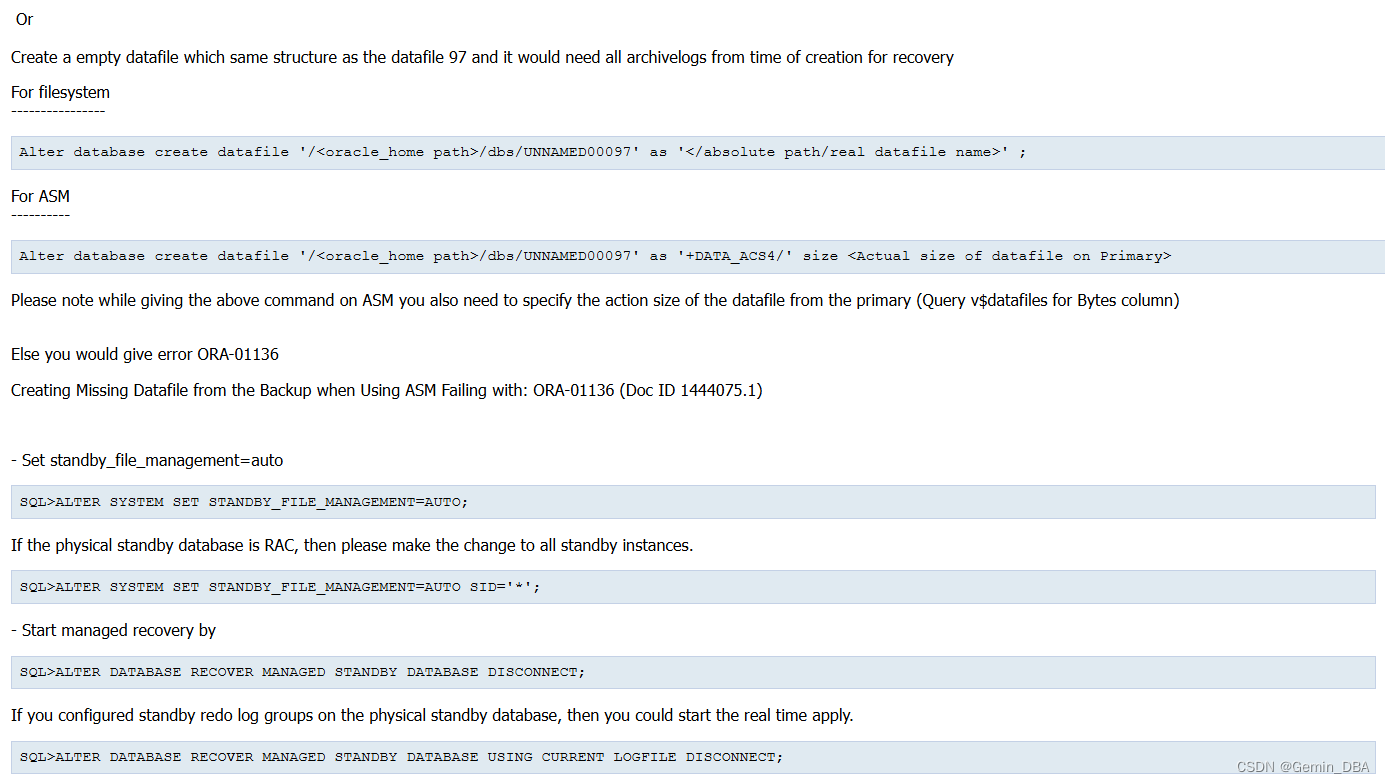
SQL> alter database create datafile '/opt/oracle/products/19.3.0/dbs/UNNAMED01071' as '+DATADG' size 31G;
Database altered.
SQL> ALTER SYSTEM SET STANDBY_FILE_MANAGEMENT=AUTO SID='*';
Database altered.
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE DISCONNECT;
Database altered.
再次检查MRP0进程
SQL> select process,status,thread#,sequence# from v$managed_standby;
PROCESS STATUS THREAD# SEQUENCE#
------------------ ------------------------ ---------- ----------
ARCH CLOSING 6 174201
DGRD ALLOCATED 0 0
DGRD ALLOCATED 0 0
ARCH CLOSING 5 284619
ARCH CLOSING 5 280446
ARCH CLOSING 6 152822
RFS IDLE 0 0
RFS IDLE 0 0
RFS IDLE 0 0
RFS IDLE 6 0
MRP0 APPLYING_LOG 6 174558
备库已恢复正常同步,日志已应用















 810
810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









