







查询结果排序:select 字段1[,字段2,…] from 表名 order by 字段1[ 排序方向,字段2 排序方向,…];
多字段排序时,先按第一个字段排序,第一个字段值相同时再按第二个字段排序
指定排序方向:asc升序,desc降序(没有指定排序方向时,默认是asc升序)
-- 查询结果排序
-- 单字段排序:查询所有员工信息按sal降序显示
select *
from emp
order by sal desc; # 指定排序方向:asc升序,desc降序(没有指定排序方向时,默认是asc升序)
-- 多字段排序:查询所有员工信息按deptno升序、sal降序显示
select *
from emp
order by deptno asc, sal desc; # 先按deptno升序排序,再在相同deptno中按sal降序排序单字段排序
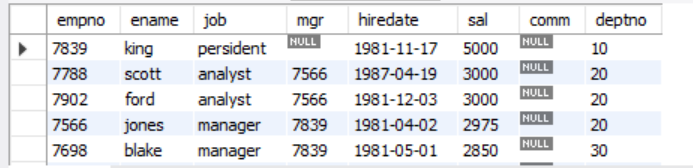 多字段排序
多字段排序
限制查询结果数量:select 字段1[,字段2,…] from 表名 limit [偏移量,] 行数;
limit接受一个或两个数字参数,参数必须是一个整数常量
第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目
如果只给定一个参数,表示返回最大的记录行数目
初始记录行的偏移量是0(而不是1)
-- 限制查询结果数量
-- 查询基本工资最高的前5位员工
select *
from emp
order by sal desc
limit 5; #表示取前5行,limit 0,5 省略了0
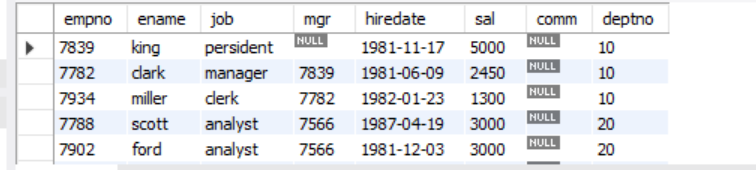
-- 查询基本工资第6到10名的员工
select *
from emp
order by sal desc
limit 5,5; # 第一个5表示偏移5行,第二个5表示取第6名到第10名共5行
-- 练习:查询最后入职的5位员工
select *
from emp
order by hiredate desc
limit 5;聚合函数

-- 聚合运算
-- 查询emp表中员工总数、最高工资、最低工资、平均工资及工资总和
select count(*) 员工总数,max(sal) 最高工资,min(sal) 最低工资,avg(sal) 平均工资,sum(sal) 工资总和
from emp; # 只有count能使用* 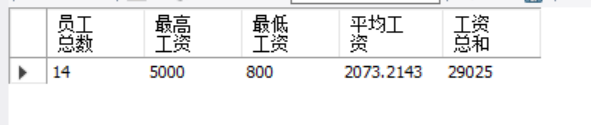
分组查询:select 字段1[,字段2,…] from 表名[ where 查询条件] group by 分组字段1[,分组字段2,…];
将查询结果按照一个或多个字段进行分组,字段值相同的为一组,对每个组进行聚合计算
-- 分组查询
-- 查询各部门的平均工资
select deptno,avg(sal) as 平均工资
from emp
group by deptno;
-- 查询各部门不同职位的平均工资
select deptno,job,avg(sal) as 平均工资
from emp
group by deptno,job
order by avg(sal) desc;分组后筛选:select 字段1[,字段2,…] from 表名[ where 查询条件][ group by 分组字段1[,分组字段2,…]] having 筛选条件;
where与having的区别:
where子句作用于表,having子句作用于组。
where条件查询的作用域是针对数据表进行筛选,而having条件查询则是对分组结果进行过滤。
where在分组和聚合计算之前筛选行,而having 在分组和聚合之后筛选分组的行,因此where子句不能包含聚合函数
-- 分组后筛选
-- 查询各部门clerk的平均工资
select deptno,job,avg(sal)
from emp
group by deptno,job
having job = 'clerk';
select deptno,job,avg(sal)
from emp
where job = 'clerk'
group by deptno,job;
-- 查询平均工资大于2000的部门
/*select deptno,avg(sal)
from emp
group by deptno
where avg(sal) >2000 -- 报错:where子句位于from之后
;*/
/*select deptno,avg(sal)
from emp
where avg(sal) >2000 -- 报错:where子句中不能使用聚合函数
group by deptno
;*/
select deptno,avg(sal)
from emp
group by deptno
having avg(sal) > 2000
;















 622
622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









