









系列文章目录
前言
为什么学习爬虫?
爬虫技能,可为后续的大数据分析、挖掘、机器学习等提供重要的数据源;
一、环境准备
1、配置python环境(本文为python3.7)参考链接;
2、工具包:requests,re, time, random,tkinter;
二、基础知识
2.1.变量和字符串
2.1.1变量
a = 1 #将数值1赋值给变量a
2.1.2字符串运算
a = 'python'
b = 'is'
c = 'interesting!'
print(a + b + c)
print(a*3)
输出:
python is interesting!
python python python
2.1.3字符串切片和索引

a = 'python is interesting!'
print(a[0])
print(a[0:9])
print(a[-1])
print(a[-1:-4])
输出:
p
python is
!
ing
2.1.4字符串使用
1、split()方法
a = 'www.csdn.net'
print(a.split('.'))
输出:
['www', 'csdn', 'net']
2、replace()方法
a = 'We is the best'
b = a.replace('is','are')
print(b)
输出:
We are the best!
3、strip()方法
备注:strip()方法返回去除两侧(不包含内部)的空格字符串;
a = 'python is interesting! '
print(a.strip())
print(a.strip(!))
输出:
python is interesting!
4、format()方法
备注:字符串格式化符,在爬虫中,有些网页链接的部分参数是可变的,使用字符串格式化符可减少代码使用量;
a = '{} is my love'.format('python')
print(a)
输出:
python is my love
2.2函数与控制语句
2.2.1函数
函数定义:
def 函数名(参数1,参数2…): #注意中英文格式
return result
def hello():
print("hello world!!")
hello()
def cacluate(*args):
avg = sum(args) / len(args)
up_avg = []
for item in args:
if item > avg:
up_avg.append(item)
return avg,up_avg
a = cacluate(1,2,3,4,5,6,7)
print(a)
输出:
hello world!!
(4.0, [5, 6, 7])
2.2.2判断语句
在爬虫实战中,经常会使用判断语句,格式如下:
if condition:
do
else:
do
if conditon:
do
elif condition:
do
else:
do
举例:
def count_login():
password = input('password:')
if password == '12345':
print('输入成功!')
else:
print('错误,再输入')
count_login()
count_login()
输出:
password:123
错误,再输入
password:123456
错误,再输入
password:123456
错误,再输入
password:12345
输入成功!
2.2.3循环语句
python的循环语句包括for循环和while循环;
#for循环
for item in iterable:
do
#item表示元素,iterable是集合
for i in range(1,11):
print(i)
#其结果为依次输出1到10,切记11是不输出的,range为Python内置函数。
#while循环
while condition:
do
for循环举例1
for letter in 'Python':
if letter == 'o':
break #在语句块执行的过程中终止循环,并跳出整个循环;
print('当前字母 :%s' %letter)
for letter in 'Python':
if letter == 'o':
continue #在语句块执行过程中终止当前循环,跳出该次循环,执行下次循环;
print('当前字母 :%s' %letter)
# 输出 Python 的每个字母
for letter in 'Python':
if letter == 'o':
pass #pass是空语句,是为了保持程序结构的完整性;
print('这是 pass 语句')
print('当前字母 :%s'%letter)
print('Good bye!')
输出:
当前字母 :P
当前字母 :y
当前字母 :t
当前字母 :h
当前字母 :P
当前字母 :y
当前字母 :t
当前字母 :h
当前字母 :n
当前字母 :P
当前字母 :y
当前字母 :t
当前字母 :h
这是 pass 语句
当前字母 :o
当前字母 :n
Good bye!
for循环举例2
for循环使用语法
for 变量 in 序列:
循环要执行的动作
range的三种用法
range(stop): 0 - stop-1
range(start,stop): start - stop-1
range(start,stop,step): start - stop-1 step(步长)
for item in range(5):
print(item)
print('\n')
for num in range(10,15):
print(num)
print('\n')
for a in range(20,30,2):
print(a)
输出:
0
1
2
3
4
10
11
12
13
14
20
22
24
26
28
while循环举例
while 条件():
条件满足时,做的事情1
条件满足时,做的事情2
i = 0
result = 0
while i <= 100:
result += i
i += 1
print('1+2+3+...+100的和为:%d' %result)
输出:
1+2+3+...+100的和为:5050
while嵌套
打印9*9乘法表
row = 1
while row <= 9:
col = 1
while col <= row:
print('%d * %d = %d\t' %(row,col,col * row),end='')
col += 1
print('')
row += 1
输出:
1 * 1 = 1
2 * 1 = 2 2 * 2 = 4
3 * 1 = 3 3 * 2 = 6 3 * 3 = 9
4 * 1 = 4 4 * 2 = 8 4 * 3 = 12 4 * 4 = 16
5 * 1 = 5 5 * 2 = 10 5 * 3 = 15 5 * 4 = 20 5 * 5 = 25
6 * 1 = 6 6 * 2 = 12 6 * 3 = 18 6 * 4 = 24 6 * 5 = 30 6 * 6 = 36
7 * 1 = 7 7 * 2 = 14 7 * 3 = 21 7 * 4 = 28 7 * 5 = 35 7 * 6 = 42 7 * 7 = 49
8 * 1 = 8 8 * 2 = 16 8 * 3 = 24 8 * 4 = 32 8 * 5 = 40 8 * 6 = 48 8 * 7 = 56 8 * 8 = 64
9 * 1 = 9 9 * 2 = 18 9 * 3 = 27 9 * 4 = 36 9 * 5 = 45 9 * 6 = 54 9 * 7 = 63 9 * 8 = 72 9 * 9 = 81
2.3python数据结构
2.3.1列表
在爬虫实战中,用的最多的就是列表数据结构,不论是构造出的多个URL,还是爬取到的数据,大多都为列表数据结构,列表的最显著特征如下:
- 列表中的每一个元素都是可变的;
- 列表的元素都是有序的,也就是说每个元素都有对应的位置(类似字符串的切片索引);
- 列表可以容纳所有的对象;
2.3.2字典
字典构造
user_info = {
'name':'xiaoming',
'age':'23',
'sex':'man'
2.3.3元组合集合
在爬虫中,元组和集合使用较少,元组类似于列表,但是元组的元素不能够修改,只能查看,格式如下:
tuple = (1,2,3)
集合的概念类似于数学中的集合,每个集合中的元素是无序的,不可重复的对象,有时可以通过集合把重复的数据去除
list = ['xiaoming','zhangyun','xiaoming']
set = set(list)
print(set)
输出:
{'xiaoming', 'zhangyun'}
2.4python面向对象
2.4.1定义类
类是用来描述具有相同的属性和方法的对象的集合,例如用python定义自行车类
class Bike:
compose = ['frame','wheel','pedal']
通过使用class定义一个自行车类,类中的变量compose称为类的变量,专业术语为类的属性;
my_bike = Bike()
you_bike = Bike()
print(my_bike.compose)
print(you_bike.compose) #类的属性都是一样
2.4.2定义类
对于同一款自行车,有些顾客会改造一下,加个篓子等;
class Bike:
compose = ['frame','wheel','pedal']
my_bike = Bike()
my_bike.other = 'basket'
print(my_bike.other) #实例属性
2.4.3类的继承
class Bike:
compose = ['frame','wheel','pedal']
def __init__(self):
self.other = 'basket' #定义实例的属性
def use(self,time):
print('you ride {}m'.format(time*100))
class Share_bike(Bike):
def cost(self,hour):
print('you spent {}'.format(hour*2))
bike = Share_bike()
print(bike.other)
bike.cost(2)
三、爬虫原理和网页结构
3.1.爬虫原理
3.1.1网络连接
我们向服务器发起一次Requests,相应的服务器会返回本机电脑相应的HTML文件作为Response.

3.1.2爬虫
爬虫分类
- 通用网络爬虫:搜索引擎使用,遵守robots协议(君子协议)robots协议 :网站通过robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
- 聚焦网络爬虫 :自己写的爬虫程序。
爬虫的作用:
- 模拟电脑对服务器发起Requests请求;
- 接受服务器端的Response内容,并解析提取的信息。
但是互联网页错综复杂,一次的请求和回应不能够批量获取网页的数据,爬虫可实现多页面,跨页面;
3.1.3网页
任意打开个网页,https://www.fabiaoqing.com,右键选择"检查"或F12打开开发者选项,即可查看网页代码。

3.1.3 chrome浏览器中F12功能介绍
参考链接
在Chrome开发者工具中,调试使用较多的为元素(ELements)、控制台(Console)、源代码(Sources),网络(Network)等。
- 元素(Element):查看或修改HTML元素的属性、CSS属性、监听事件、断点等。
- 控制台(Console):控制台一般用于执行一次性代码,查看JavaScript对象,查看调试日志信息或异常信息。
- 源代码(Sources):用于查看页面的HTML文件源代码、JavaScript源代码、CSS源代码,此外最重要的是可以调试JavaScript源代码,可以给JS代码添加断点等。
- 网络(Network):网络页面主要用于查看header等与网络连接相关的信息。
- Resources:查看本地资源信息的(cookie,local storage,session,session storage)
其它选项:
- ALL:抓取所有的网络数据包。
- XHR:抓取异步加载的网络数据包。
- JS:抓取所有的JS文件。
- Headers:整个请求信息General、Response Headers、Request Headers、Query String、Form Data。
- Preview:对响应内容进行预览。
四、爬虫依赖
4.1.Python的第三方库
4.1.1第三方库概念
python之所以强大,一部分原因就是因为它拥有强大的第三方库,库就像部件一样,我们进行拼接即可使用,不用一个一个去造零部件;
4.1.2第三方库的安装
使用豆瓣源或其他国内源下载速度会更快!!!
其它源参考链接
pip install 库名称
pip --default-timeout=100 install pyside2 -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
pip --default-timeout=100 install 库名称 -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
如果由于网络问题引起的下载失败,可手动下载安装包,再进行安装;
4.1.3第三方库的使用
import 库名称
from bs4 import BeautifulSoup
4.2.爬虫的三大库
4.2.1 Requests库
Requests库:让HTTP服务人类,作用就是请求网站获取网页数据。
import requests
res = requests.get('https://www.fabiaoqing.com') #网站为表情包网址
print(res)
print(res.text)
#控制台返回结果为<Response [200]>,说明请求网址成功,若为404,400则请求网址失败。部分输出结果如下:

4.2.2 BeautufulSoup库
BeautifulSoup库是一个非常流行的Python库,通过它可以轻松解析Requests库请求的网页,并把网页源码解析为Soup文档,以便过滤提取数据;
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
res = requests.get('https://www.fabiaoqing.com',headers = headers) #网站为表情包网址
soup = BeautifulSoup(res.text,'html.parser')
print(soup.prettify())
4.2.3 Lxml库
Lxml库是基于libxm12这一个XML解析库的python封装,该模块使用C语言编写,解析速度比BeautifulSoup更快;
4.2.4 其它库
- time库是python中处理时间的标准库;
- os库提供通用的,基本操作系统交互功能,包含几百个函数,常用的有路径操作,进程管理,环境参数等;
- re正则解析库,主要用于字符串匹配,re比xpath快10倍,xpath比bs4快10倍!!
4.3 爬虫模块参数
4.3.1 requests.get()
地址和请求头参数–url和header
res = requests.get(url,headers=headers) #向网站发起请求,并获取响应对象
- url :需要抓取的URL地址
- headers : 请求头
- timeout : 超时时间,超过时间会抛出异常
响应对象(res)属性
- encoding :响应字符编码 res.encoding = ‘utf-8’
- text :字符串 网站源码
- content :字节流 字符串网站源码
- status_code :HTTP响应码
- url :实际数据的URL地址
import requests
url = 'http://www.baidu.com/' # 爬取百度网页
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 \
(KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1'}
res = requests.get(url, headers=headers)
print(res.encoding) # 查看网站的编码格式 ISO-8859-1
# text属性获取响应内容(字符串)网站源码
res = requests.get(url,headers=headers)
res.encoding = 'utf-8'
html = res.text
# content属性获取响应内容(字节串 bytes)网站源码
res = requests.get(url,headers=headers)
html = res.content.decode('utf-8')
print(res.status_code) # 查看响应码 200
print(res.url) # 查看访问的URL地址 https://www.baidu.com/
4.3.1 request.urlopen()
from urllib import request
request.urlopen() 向网站发起请求并获取响应对象
参数:
- URL:需要爬取的URL地址
- timeout: 设置等待超时时间,指定时间内未得到响应抛出超时异常
响应对象(response)方法
- string = response.read().decode(‘utf-8’) 获取响应对象内容(网页源代码),返回内容为字节串bytes类型,顺便需要decode转换成string。
- url = response.geturl() 返回实际数据的URL地址
- code = response.getcode() 返回HTTP响应码
from urllib import request
url = 'http://www.baidu.com/'
# 向百度发请求,得到响应对象
response = request.urlopen(url)
# 返回网页源代码
print(response.read().decode('utf-8'))
# 返回http响应码
print(response.getcode()) # 200
# 返回实际数据URL地址
print(response.geturl()) # http://www.baidu.com/
五、正则表达式
5.1.正则表达式常用符号
5.1.1 常用符号

5.1.2 常用校验数字的正则表达式
1、数字:^[0-9]*$
2、n位的数字:^\d{n}$
3、至少n位的数字:^\d{n,}$
4、m-n位的数字:^\d{m,n}$
5、零和非零开头的数字:^(0|[1-9][0-9]*)$
6、非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$
7、带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})?$
8、正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$
9、有两位小数的正实数:^[0-9]+(.[0-9]{2})?$
10、有1~3位小数的正实数:^[0-9]+(.[0-9]{1,3})?$
11、非零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
12、非零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$
13、非负整数:^\d+$ 或 ^[1-9]\d*|0$
14、非正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$
15、非负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
16、非正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$
17、正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
18、负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
19、浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
5.1.3 常用校验字符的正则表达式
1、汉字:^[\u4e00-\u9fa5]{0,}$
2、英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
3、长度为3-20的所有字符:^.{3,20}$
3、由26个英文字母组成的字符串:^[A-Za-z]+$
5、由26个大写英文字母组成的字符串:^[A-Z]+$
6、由26个小写英文字母组成的字符串:^[a-z]+$
7、由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
8、由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$
9、中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$
10、中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
11、可以输入含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+
12、禁止输入含有~的字符:[^~\x22]+
5.1.4 常用特殊需求的正则表达式
1、Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
2、域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?
3、 InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
4、手机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
5、电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$
6、国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}
7、身份证号(15位、18位数字):^\d{15}|\d{18}$
8、短身份证号码(数字、字母x结尾):^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$
9、帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
10、密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$
11、强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
12、日期格式:^\d{4}-\d{1,2}-\d{1,2}
13、一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$
14 、一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
15、钱的输入格式:
- 有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$
- 这表示任意一个不以0开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式:^(0|[1-9][0-9]*)$
- 一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9]*)$
- 这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧.下面我们要加的是说明可能的小数部分:^[0-9]+(.[0-9]+)?$
- 5.必须说明的是,小数点后面至少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$
- 6.这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$
- 这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$
- 1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$
- 备注:这就是最终结果了,别忘了"+"可以用"*"替代如果你觉得空字符串也可
- 以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里
16、xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$
17、中文字符的正则表达式:[\u4e00-\u9fa5]
18、双字节字符:[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))
19、空白行的正则表达式:\n\s*\r (可以用来删除空白行)
20、HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? /> (网上流传的版本太糟糕,上面这个也仅仅能部分,对于复杂的嵌套标记依旧无能为力)
21、首尾空白字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式)
22、 腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)
23、中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)
24、IP地址:\d+\.\d+\.\d+\.\d+ (提取IP地址时有用)
25、 IP地址:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))
5.2 re模块及其方法
5.2.1 re.search()函数
re模块的search()函数匹配并提取第一个符合规律的内容,返回一个正则表达式对象,search()函数语法为:
re.match(pattern, string, flags=0)
- pattern为匹配的正则表达式。
- string为要匹配的字符串。
- flags为标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等;
举例:
import re
a = 'one1two2three3'
infos = re.search('\d+',a) #匹配一个数字字符一次或无限次
print(infos.group()) #group方法获取信息
可以看出,search()函数返回的是正则表达式对象,通过正则表达式匹配到了"1"这个字符串,可以通过上面的代码返回匹配到的字符串。
5.2.2 re.sub()函数
re模块提供了sub()函数用于替换字符串中的匹配项,sub()函数语法为:
re.sub(pattern, repl, string, count=0, flags=0)
- pattern为匹配的正则表达式。
- repl为替换的字符串。
- string为要被查找替换的原始字符串。
- counts为模式匹配后替换的最大次数,默认0表示替换所有的匹配。
- flags为标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等;
5.2.3 re.findall()函数
findall()函数匹配所有符合规律的内容,并以列表的形式返回结果,例如上文中的’one1two2three3’,通过search()函数只能匹配到第一个符合规律的结果,通过findall可以返回字符串所有的数字。
import re
a = 'one1two2three3'
infos = re.findall('\d+',a)
print(infos)
输出结果对比:
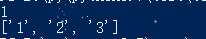
5.2.4 re.split函数
将一个字符串按照正则表达式匹配的结果进行分割,返回list对象
import re
l = re.split(r'[a-z]{5}','123hello456world789')
print(l)#获得列表对象['123','456','789']
#只分割1次
l = re.split(r'[a-z]{5}','123hello456world789',1)
print(l)#获得列表对象['123', '456world789']
- maxsplit = 0 :最大分割数,剩余的部分作为最后一个元素,默认全部分割;
5.2.5 re.match函数
从被搜索的字符串的起始位置匹配正则表达式,返回match对象
import re
m = re.match(r'[a-z]{5}','hello123')
print(m[0])#结果将匹配出‘hello’
5.2.6 re.finditer函数
搜索字符串,匹配结果返回为一个迭代对象,迭代元素都是match对象
import re
i = re.finditer(r'[a-z]{5}','hello123world')
for m in i:
print(m[0])#打印结果为‘hello’,‘world’
5.2.7 re模块修饰符
re模块中包含一些可选标志修饰符来控制匹配模式

在爬虫中,re.S是最常用的修饰符,它能够换行匹配
5.3 面向对象调用
pat = re.compile(r'[a-z]{5}')
该函数可以将正则表达式的表示编译成正则表达式对象pat,pat对象可以直接调用re的6个主要功能函数,这种面向对象调用的好处是经过一次编译可以多次对同一个字符串进行多次匹配或提取。
pat.search('hello123world')
举例:
import re
str1 = '123hello456world789'
str2 = '111hello222kitty333'
pattern = r'[a-z]{5}'
pat = re.compile(pattern)
matc1 = pat.search(str1)
matc2 = pat.search(str2)
list1 = pat.findall(str1)
list2 = pat.findall(str2)
iter1 = pat.finditer(str1)
iter2 = pat.finditer(str2)
...
5.4 match对象介绍
search(),match(),finditer()在re库中都会返回match对象
match对象的属性实例:
import re
pat = re.compile(r'[a-z]{5}')
match = pat.search('123hello456world789')
print(match.string)#待匹配的文本
#结果:123hello456world789
print(match.re)#匹配时使用的pattern对象,也就是编译后的正则表达式
#结果:re.compile('[a-z]{5}')
print(match.pos)#正则表达式搜索文本的开始位置
#结果:0
print(match.endpos)#正则表达式搜索文本的结束位置
#结果:19
match对象的方法实例:
import re
pat = re.compile(r'[a-z]{5}')
match = pat.search('123hello456world789')
print(match.group())#获得匹配到的字符串
#结果:hello
print(match.start())#匹配到的字符串在文本中的开始位置
#结果:3
print(match.end())#匹配到的字符串在文本中的结束位置
#结果:8
print(match.span())#以元祖类型返回start()和end()
#结果:(3, 8)
5.5 re库的最小匹配和贪婪匹配
re库默认为贪婪匹配,即匹配最多的值
实例:
import re
#默认为贪婪匹配,匹配最多的值 m = re.search(r'\d+','123456') print(m[0])
#输出结果为:123456
如果在实际应用中,只需要匹配到"1",需要用到操作符"?"
import re
#使用操作符'?'使用最小匹配
m = re.search(r'\d+?','123456')
print(m[0])
#输出结果为:1
''''
?操作符可以跟在4个元字符的后面,这样就是非贪婪匹配了
* *?
* +?
? ??
{m,n} {m,n}?
'''
六、Lxml库和Xpath
6.1.Lxml库安装与使用
6.1.1 Lxml安装
pip install lxml
6.1.2 Lxml库的使用
- 修正HTML代码
- 读取HTML文件
- 解析HTML文件
6.2.Xpath语法
6.2.1 节点关系
- 父节点
- 子节点
- 同胞节点
- 先辈节点
- 后代节点
6.2.2 节点选择
Xpath使用路径表达式在XML文档中选取节点,节点是通过沿着路径或step来选取的;

6.2.3 获取方式
在爬虫实战中,Xpath路径可以通过Chrome复制得到:

6.2.4 解析
XPath即为XML路径语言,它是一种用来确定XML文档中某部分位置的语言,同样适用于HTML文档的检索,我们来利用xpath对HTML代码进行检索试试,以下是HTML示例代码。
<ul class="book_list">
<li>
<title class="book_001">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>69.99</price>
</li>
<li>
<title class="book_002">Spider</title>
<author>Forever</author>
<year>2019</year>
<price>49.99</price>
</li>
</ul>
匹配演示:
//li #查找所有的li节点
//li/title[]@class="book_001" #查找li节点下的title子节点中,class属性为“book_001”的节点
//li//title/@class #查找li节点下所有title节点的,class属性的值
注:
只要涉及到条件,加[];
只要涉及到属性,加@;
获取节点
//:从所有节点中查找(包括子节点和后代节点)
@:获取属性值
//div[@class="movie"] #属性作为条件
//div/a/@src #直接获取属性值
七、爬虫案例
7.1.案例一
7.1.1 根据关键词搜索下载表情包
#导入程序所需要的库,Requests库用于请求网页获取网页数据。BeautifulSoup用于解析网页数据。time库的sleep()方法可以让程序暂停
import os
import re
import time
import requests
from bs4 import BeautifulSoup
# 发送请求 获取网页源码
def askPage(httpUrl): #定义获取网页url的函数
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
} #通过Vhrome浏览器的开发者工具,复制user-Agent,用于伪装为浏览器,便于爬虫的稳定性
res = requests.get(url=httpUrl, headers=headers) #向网站发起请求,并获取响应对象
htmlCode = res.text #保存响应对象
return htmlCode
# 获取表情包页码总数
def getPageNum(soup): #定义获取网页页码函数
dict = soup.find_all('a', attrs={'class': 'item', 'href': True, 'title': False}) #在所有源码中查找满足匹配规则的源码
# 获取倒数第二个a标签内的内容
lastPageNum = int(dict[-2].text.strip())
return lastPageNum
# 格式化表情包名称
def formatImgName(str):
# 截取 - 之前的名称
flag = str.find('-')
str = str[0:flag - 1]
# 去掉名称中的\n / \ : * ? " < > | ! \f \r
res = re.sub(r'[\f\t\r\n?!<>:"*/|\\]', '', str)
# 当名称大于等于30时 去前30个
if (len(res) >= 30):
res = res[0:31]
return res
# 获取指定网页所有的表情包
def getImgInfo(soup):
# 返回的图片信息列表
imgInfoList = []
# 获得指定的img标签 列表
imgList = soup.find_all('img', attrs={'class': 'ui image bqppsearch lazy', 'src': True, 'title': True})
for item in imgList:
imgInfo = {}
imgInfo['name'] = formatImgName(item.get('alt'))
imgInfo['href'] = item.get('data-original')
imgInfoList.append(imgInfo)
return imgInfoList
# 下载表情包到本地
def downloadImg(imgUrl, imgName):
# 截取url的扩展名
extName = imgUrl[-4:]
res = requests.get(imgUrl)
imgName = imgName + extName
with open('./image/' + imgName, 'wb') as f:
f.write(res.content)
print(imgName + '下载成功')
# 爬虫主函数
def spider(baseUrl):
# 统计图片总个数
imgCount = 0
# 统计开始时间
startTime = time.time()
# 首页URL
mainHttpUrl = baseUrl + '1.html'
# 获取首页html代码
htmlCode = askPage(mainHttpUrl)
# 初始化 BeautifulSoup 获得首页的BeautifulSoup对象
soup = BeautifulSoup(htmlCode, 'html.parser')
# 获取指定表情包页码总数
lastPageNum = getPageNum(soup)
# 判断当前文件目录是否还有 image 文件夹
if ('image' not in os.listdir('./')):
os.mkdir('image')
print('成功创建文件夹 image')
# 循环遍历每一页
for index in range(1, lastPageNum + 1):
# 动态拼接URL
httpUrl = baseUrl + str(index) + '.html'
# 获取HTMl源码
htmlCode = askPage(httpUrl)
# 初始化 BeautifulSoup 获得每一页的BeautifulSoup对象
soup = BeautifulSoup(htmlCode, 'html.parser')
# 获取表情包链接
imgInfoList = getImgInfo(soup)
for img in imgInfoList:
imgCount = imgCount + 1
# 下载到本地
downloadImg(img.get('href'), str(imgCount) + '.' + img.get('name'))
# 统计结束时间
endTime = time.time()
runTime = round(endTime - startTime)
print('下载完成!!!')
print('共耗时 ' + str(runTime) + ' 秒。。。')
print('共下载 ' + str(imgCount) + ' 张表情包。。。')
if __name__ == '__main__':
keyword = input('请输入需要爬取表情包的关键词: ')
baseUrl = 'https://www.fabiaoqing.com/search/bqb/keyword/' + keyword + '/type/bq/page/'
spider(baseUrl)
7.2 案例二
7.2.1 高清壁纸下载
用户代理User-Agent
import random
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10",
"Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13",
"Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+",
"Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0",
"Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)",
"UCWEB7.0.2.37/28/999",
"NOKIA5700/ UCWEB7.0.2.37/28/999",
"Openwave/ UCWEB7.0.2.37/28/999",
"Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999",
# iPhone 6
"Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25",
# 新版移动ua
"Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Gecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"
]
# 随机获取一个请求头
def get_headers():
return {'User-Agent': random.choice(user_agent)
源码
import requests
from bs4 import BeautifulSoup
import os
import time
import random
import UserAgent
index = 'http://www.netbian.com' # 网站根地址
interval = 0.1 # 爬取图片的间隔时间
firstDir = r'E:\py\python3.7\test\test35' # 总路径
classificationDict = {} # 存放网站分类子页面的信息
# 获取页面筛选后的内容列表
def screen(url, select):
headers = UserAgent.get_headers() # 随机获取一个headers
html = requests.get(url = url, headers = headers)
html.encoding = 'gbk' # 网站的编码
html = html.text
soup = BeautifulSoup(html, 'lxml')
return soup.select(select)
# 获取页码
def screenPage(url, select):
html = requests.get(url = url, headers = UserAgent.get_headers())
html.encoding = 'gbk'
html = html.text
soup = BeautifulSoup(html, 'lxml')
return soup.select(select)[0].next_sibling.text
# 下载操作
def download(src, name, path):
if(isinstance(src, str)):
response = requests.get(src)
path = path + '/' + name + '.jpg'
while(os.path.exists(path)): # 若文件名重复
path = path.split(".")[0] + str(random.randint(2, 17)) + '.' + path.split(".")[1]
with open(path,'wb') as pic:
for chunk in response.iter_content(128):
pic.write(chunk)
# 定位到 1920 1080 分辨率图片
def handleImgs(links, path):
for link in links:
href = link.get('href')
if(href == 'http://pic.netbian.com/'): # 过滤图片广告
continue
# 第一次跳转
if('http://' in href): # 有极个别图片不提供正确的相对地址
url = href
else:
url = index + href
select = 'div#main div.endpage div.pic div.pic-down a'
link = screen(url, select)
if(link == []):
print(url + ' 无此图片,爬取失败')
continue
href = link[0].get('href')
# 第二次跳转
url = index + href
# 获取到图片了
select = 'div#main table a img'
link = screen(url, select)
if(link == []):
print(url + " 该图片需要登录才能爬取,爬取失败")
continue
name = link[0].get('alt').replace('\t', '').replace('|', '').replace(':', '').replace('\\', '').replace('/', '').replace('*', '').replace('?', '').replace('"', '').replace('<', '').replace('>', '')
print(name) # 输出下载图片的文件名
src = link[0].get('src')
if(requests.get(src).status_code == 404):
print(url + ' 该图片下载链接404,爬取失败')
print()
continue
print()
download(src, name, path)
time.sleep(interval)
# 选择下载分类子页面
def select_classification(choice):
print('---------------------------')
print('--------------' + choice + '-------------')
print('---------------------------')
secondUrl = classificationDict[choice]['url']
secondDir = classificationDict[choice]['path']
if(not os.path.exists(secondDir)):
os.mkdir(secondDir) # 创建分类目录
select = '#main > div.page > span.slh'
pageIndex = screenPage(secondUrl, select)
lastPagenum = int(pageIndex) # 获取最后一页的页码
for i in range(0, lastPagenum):
if i == 0:
url = secondUrl
else:
url = secondUrl + 'index_%d.htm' %(i+1)
print('--------------' + choice + ': ' + str(i+1) + '-------------')
path = secondDir + '/' + str(i+1)
if(not os.path.exists(path)):
os.mkdir(path) # 创建分类目录下页码目录
select = 'div#main div.list ul li a'
links = screen(url, select)
handleImgs(links, path)
# ui界面,用户选择下载分类
def ui():
print('--------------netbian-------------')
print('全部', end=' ')
for c in classificationDict.keys():
print(c, end=' ')
print()
choice = input('请输入分类名:')
if(choice == '全部'):
for c in classificationDict.keys():
select_classification(c)
elif(choice not in classificationDict.keys()):
print("输入错误,请重新输入!")
print('----')
ui()
else:
select_classification(choice)
# 将分类子页面信息存放在字典中
def init_classification():
url = index
select = '#header > div.head > ul > li:nth-child(1) > div > a'
classifications = screen(url, select)
for c in classifications:
href = c.get('href') # 获取的是相对地址
text = c.string # 获取分类名
if(text == '4k壁纸'): # 4k壁纸,因权限问题无法爬取,直接跳过
continue
secondDir = firstDir + '/' + text # 分类目录
url = index + href # 分类子页面url
global classificationDict
classificationDict[text] = {
'path': secondDir,
'url': url
}
def main():
if(not os.path.exists(firstDir)):
os.mkdir(firstDir) # 创建总目录
init_classification()
ui()
if __name__ == '__main__':
main()
总结
分享:
我相信自己我坚信我的理想信念,即使现在每天都不是很容易,自己和别人差距很大,但是我不会放弃,即使百分之一的可能超越别人,我也会努力一点点拉进距离。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











