






生成树不能解决单一vlan的负载均衡问题
堆叠:把相同类型交换机的备板联系起来
框式交换机特点:里面有许多板卡,板卡之间相互连接,有机的组成一个整体,进行工作
盒式交换机:每一个都有独立的引擎
堆叠的优势:可以将多个设备汇成一个设备,可以扩充该设备的接口
堆叠的解决方案:
堆叠的缺点:1.浪费转发性能;2.升级和割接时特别困难
注:聚合可以进行负载
典型园区组网之一:
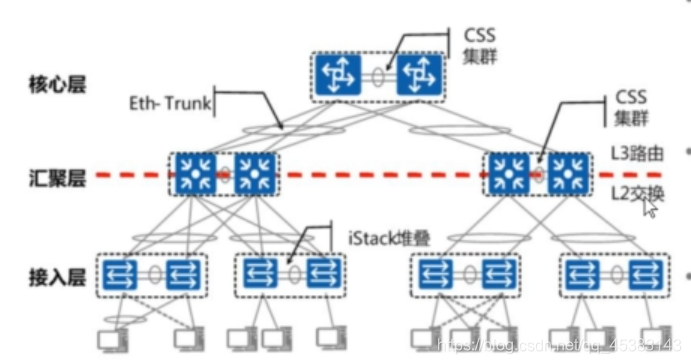
•优点:
简单:各层设备均使用堆叠技术,逻辑设备少,网络拓扑简单,二层天然无环,无需部署XSTP破坏协议
高效:各层设备之间使用Eth-Trunk链路聚合技术,负载分担,算法灵活,链路利用率高
可靠:堆叠技术通链路聚合技术结合使用,各层物理设备形成双规接入组网,提高整网可靠性
•缺点:
对设备性能要求高,盒式设备堆叠台数过多,可能导致堆叠的主控性能下降
如果采用业务口堆叠或集群,会占用业务端口数
堆叠切换速度较慢
操作系统的主要工作:将硬件资源转化为某种接口,提供给上层软件
资源池化意味着:硬件资源的重新分配
iStack基本概念:
角色:堆叠中所有的单台交换机都称为成员交换机,按照功能不同,可以分为三种角色
主交换机(master):负责管理整个堆叠,堆叠中只有一台主交换机
备交换机(standby):是主交换机的备份交换机。当主交换机故障时,备交换机会接替原主交换机的所有业务,堆叠中只有一台备交换机
从交换机(slave):主要用于业务转发,从交换机数量越多,堆叠系统的转发能力越强。除了主交换机和备交换机外,堆叠中其他的所有成员交换机都是从交换机
堆叠ID:即堆叠交换机的槽位号,用来标识和管理成员交换机,堆叠中所有成员交换机的堆叠ID都是唯一的
堆叠优先级:堆叠优先级是成员交换机的一个属性,主要用于角色选举过程中,确定成员交换机的角色,优先级值越大表示优先级越高,优先级越高当选为主交换机的可能性越大
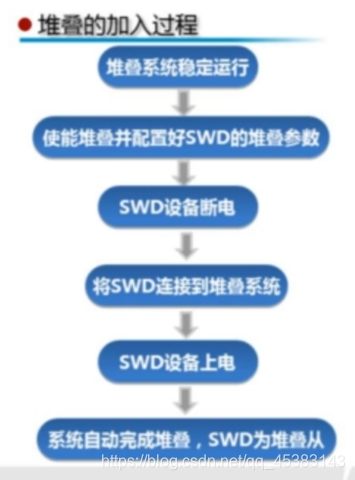
堆叠建立过程:使用堆叠并配置号堆叠参数–所有设备断电–连接堆叠线缆–所有设备上电–系统自动完成堆叠
系统自动完成堆叠分为三步:
1.主交换机选举:
运行状态比较,已运行的交换机比处于启动状态的交换机优先竞争为主交换机
堆叠优先级高的交换机优先竞争主交换机
堆叠优先级相同时,MAC地址小的交换机优先竞争为主交换机
2.拓扑收集和备交换机的选举:主交换机选举完成后,主交换机会手机所有成员交换机及的拓扑信息,根据拓扑信息计算出堆叠转发表项和破坏点信息下发给堆叠中的所有成员交换机,并向所有成员交换机分配堆叠ID。之后进行备交换机的选举,作为主交换机的备份交换机。当除主交换机外的其他交换机同时完成启动时:
堆叠优先级最高的设备成为备交换机
堆叠优先级相同时,MAC地址最小的成为备交换机
3.稳定运行
堆叠的来凝结方式:堆叠卡堆叠和业务口堆叠
堆叠卡堆叠:
交换机之间通过专用的堆叠插卡及专用的堆叠线缆连接
堆叠卡集成到了交换机后面板上,交换机通过继承的堆叠端口及专用的堆叠线缆连接
业务口堆叠:交换机之间通过与逻辑堆叠端口绑定的物理成员端口相连接不需要专用的堆叠插卡。如下图所示:

堆叠成员加入:先陪自豪新加入的设备的参数–断电–加入堆叠系统–加电–系统自动完成堆叠
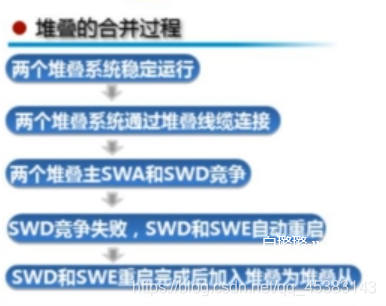
堆叠合并:
堆叠成员退出:

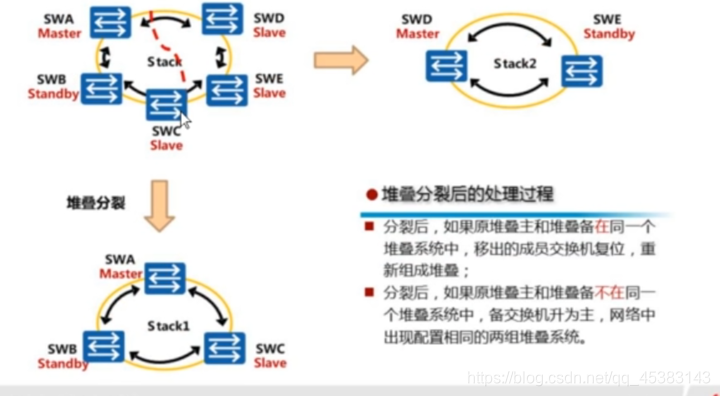
堆叠分裂:
多主检测–直连检测方式
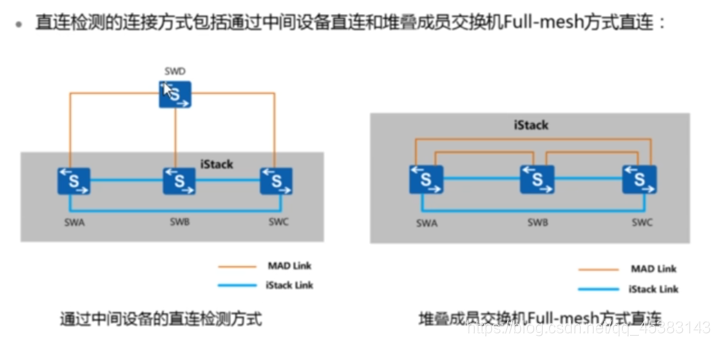
•于堆叠系统中所有成员交换机都使用同-一个IP地址和MAC地址(堆叠系统MAC) , 一个堆叠分裂后,可能产生多个具有相同IP地址和MAC地址的堆叠系统。为防止堆叠分裂后, 产生多个具有相同IP地址和MAC地址的堆叠系统,引起网络故障,必须进行IP地址和MAC地址的冲突检查。多主检测MAD ( Multi- Active Detection) , 是一种检测和处理堆叠分裂的协议。链路故障导致堆叠系统分裂后, MAD可以实现堆叠分裂的检测、冲突处理和故障恢复,降低堆叠分裂对业务的影响。
•MAD检测方式有两种:直连检测方式和代理检测方式。在同-一个堆叠系统中,两种检测方式互斥,不可以同时配置。
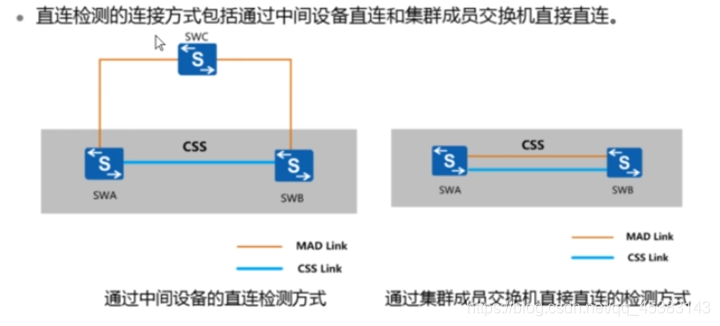
•直连检测方式是指堆叠成员交换机间通过普通线缆直连的专用链路进行多主检测。在直连检测方式中,堆叠系统正常运行时,不发送MAD报文;堆叠系统分裂后,分裂后的两台交换机以1s为周期通过检测链路发送MAD报文以进行多主冲突处理。
•通过中间设备直连:堆叠系统的所有成员交换机之间至少有一条检测链 路与中间设备相连。
•Full-mesh方式直连 :堆叠系统的各成员交换机之间通过检测链路建立Full-mesh全连接,即每两台成员交换机之间至少有一条检测链路。
•通过中间设备直连可以实现通过中间设备缩短堆叠成员交换机之间的检测链路长度, 适用于成员交换机相距较远的场景。与通过中间设备直连相比, Full-mesh方式直连可以避免由中间设备故障导致的MAD检测失败,但是每两台成员交换机之间都建立全连接会占用较多的接口, 所以该方式适用于成员交换机数目较少的场景。
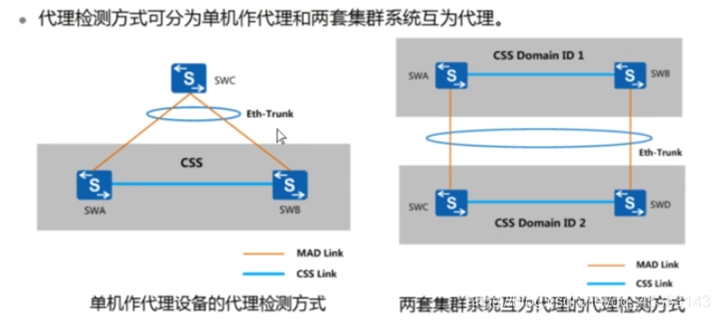
多主检测–代理检测方式:
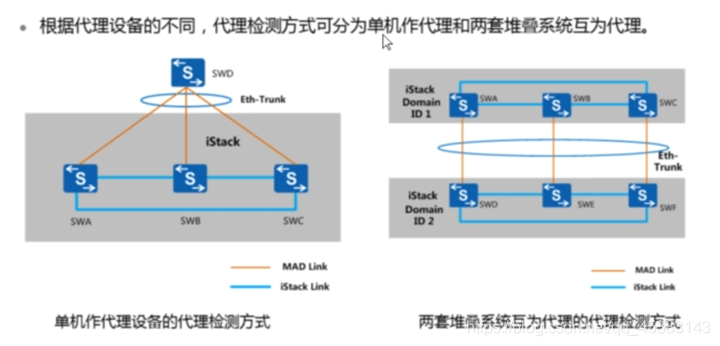
在代理检测方式中,堆叠系统正常运行时,堆叠成员交换机以30s为周期通过检测链路发送MAD报文。堆叠成员交换机对在正常工作状态下收到的MAD报文不做任何处理;堆叠分裂后,分裂后的两台交换机以1s为周期通过检测链路发送MAD报文以进行多主冲突处理。
•MAD冲突处理
•堆叠分裂后, MAD冲突处理机制会使分裂后的堆叠系统处于Detect状态或Recovery状态。Detect状态表示堆叠正常工作状态, Recovery状态表示堆叠禁用状态。
•MAD冲突处理机制如下: MAD分裂检测机制会检测到网络中存在多个处于Detect状态的堆叠系统,这些堆叠系统之间相互竞争,竞争成功的堆叠系统保持Detect状态,竞争失败的堆叠系统会转入Recovery状态;并且在Recovery状态堆叠系统的所有成员交换机上,关闭除保留端口以外的其它所有物理端口,以保证该堆叠系统不再转发业务报文。
•MAD故障恢复
•通过修复故障链路, 分裂后的堆叠系统重新合并为-一个堆叠系统。重新合并的方式有以下两种:o堆叠链路修复后,处于Recovery状态的堆叠系统重新启动,与Detect状态的堆叠系统合并,同时将被关闭的业务端口恢复Up,整个堆叠系统恢复。
•如果故障链路修复前, 承载业务的Detect状态的堆叠系统也出现了故障。此时,可以先将Detect状态的堆叠系统从网络中移除,再通过命令行启用Recovery状态的堆叠系统,接替原来的业务,然后再修复原Detect状态堆叠系统的故障及链路故障。故障修复后,重新合并堆叠系统。
堆叠配置:

CSS:(集群技术)将两个设备的资源合二为一。即接口资源,内存资源,引擎资源,备板资源合二为一
完美重启技术:当设备重启的时候,不重置路由表
CSS:将两台支持集群特性的交换机组合在一起,从逻辑上组合成为一台交换机设备
CSS特征:
交换机多虚一:堆叠交换机对外表现为一台逻辑交换机,控制平面合一,统一管理
转发平面合一:堆叠内物理设备转发平面合一,珠海那发信息共享并实时同步
跨设备链路聚合:跨堆叠内物理设备的链路被聚合成一个Eth-Trunk端口,和下游设备实现互联
CSS和istck的区别:一般框式交换机堆叠称为CSS,盒式交换机堆叠称为istck,但最终实现的功能是一样的
实现的功能:
1.高可靠性:集群系统两台成员交换机之间冗余备份,同时利用链路聚合功能实现跨设备的链路冗余备份
2.强大的网络扩展能力:通过组建集群增加交换机,从而轻松的扩展端口数,带宽和处理能力
3.简化配置和管理:集群建立后,两台物理设备虚拟成为一台设备,用户只需要登录一台成员交换机即可对集群系统所有成员交换机进行统一配置和管理
CSS基本概念:
主交换机:负责管理整个集群,集群中只有一台主交换机
备交换机:是主交换机的备份交换机。当主交换机故障时,备交换机会接替原主交换机的所有业务,集群中只有一台备交换机
集群ID:CSS ID。用来标识和管理成员交换机。集群中成员交换机的集群ID是唯一的
集群优先级:priority。是成员交换机的一个属性,主要用于角色选举过程中确定成员交换机的角色,优先级值越大优先级越高,优先级越高当选主交换机的可能性越大。
CSS集群建立:
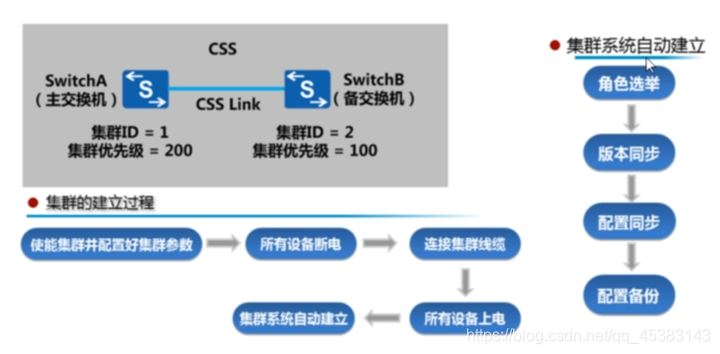
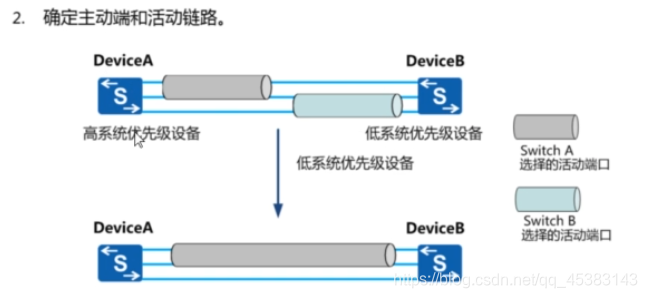
集群建立时,成员交换机间相互发送集群竞争报文,通过竞争,一台成为主交换机,负责管理整个集//群系统,另一台则成为备交换机。
•角色选举
1.最先完成启动,并进入单框集群运行状态的交换机成为主交换机。
2.当两台交换机同时启动时,集群优先级高的交换机成为主交换机。
3.当两台交换机同时启动,且集群优先级又相同时,MAC地址小的交换机成为主交换机。
4.当两台交换机同时启动,且集群优先级和MAC都相同时,集群ID小的交换机成为主交换机。
•版本同:集群具有自动加载系统软件的功能,待组成集群的成员交换机不需要具有相同的软件版本,只需要版本间兼容即可。当主交换机选举结束后,如果备交换机与主交换机的软件版本号不一致时,备交换机会自动从主交换机下载系统软件,然后使用新的系统软件重启,并重新加入集群。
•备份配置:交换机从非集群状态进入集群状态后,会自动将原有的非集群状态下的配置文件加上.bak的扩展名进行备份,以便去使能集群功能后,恢复原有配置。例如,原配置文件扩展名为.cfg,则备份配置文件扩展名为.cfg.bak。去使能交换机集群功能时,用户如果希望恢复交换机的原有配置,可以更改备份配置文件名并指定其为下一次启动的配置文件,然后重新启动交换机,恢复原有配置
CSS连接非让是:集群卡集群和业务口集群
集群卡集群:集群成员交换机之间通过主板上专用的集群卡及专用的集群线缆连接
业务口集群:集群成员交换机之间通过业务板上的普通业务接口连接,不需要专用的集群卡,。通istack,业务口集群一样涉及两种端口概念:物理成员端口和逻辑成员端口
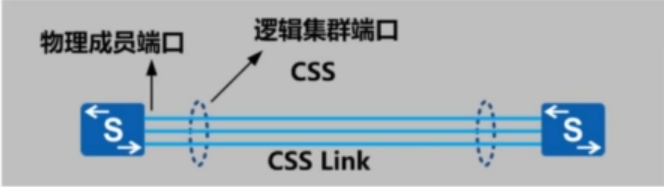
集群成员的加入与合并:
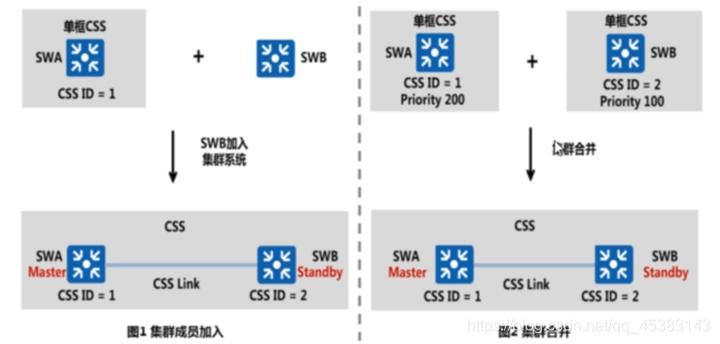
集群分裂:集群建立后,系统主用主控板和系统备用主控板定时发送心跳报文来维护集群系统的状态。集群线缆、集群卡、主控板等发生故障或者是其中一台交换机下电或重启将导致两台交换机之间失去通信。当两台交换机之间的心跳报文超时(超时时间为8秒)时,集群系统将分裂为两个单框集群系统,如图所示:
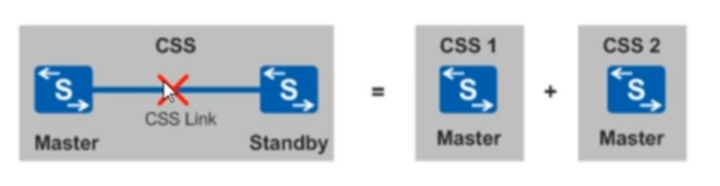
集群分裂后,由于成员交换机运行着相同的配置文件,就会产生两个具有相同IP和MAC的集群系统。为防止由此硬气的网络故障,必须进行IP和MAC的冲突检查
多主检测–直连检测方式
多主检测–代理检测方式
集群配置:

Eth-Trunk:
链路聚合最多能绑八个口
转发原理:
流的分配:hash算法
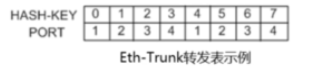
Eth-Trunk模块内部维护- 张转发表,这张表由以下两项组成。
HASH-KEY值: HASH-KEY值是根据数据包的MAC地址或IP地址等,经HASH算法计算得出
接口号: Eth-Trunk转发表表项分布和设备每个Eth-Trunk支持加入的成员接口数量相关,不同的HASH-KEY值对应不同的出接口。
流转发如何尽可能的达成均匀分布:1.流的划分足够细2.尽可能使用偶数链路
链路聚合:
1手工模式聚合链路(双方不进行协商,强行聚合)
2.LACP模式链路聚合(双方进行协商)
配置链路聚合:
解绑的时候在物理口上解绑
E-Trunk:是一种实现跨设备链路聚合的机制,基于LACP进行扩展,能实现多台设备间的链路聚合,从而把链路可靠性从单板级提高到了设备级
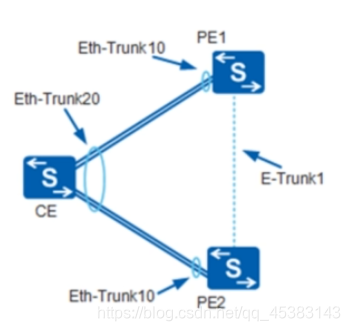
如图所示,CE 双归接入PE1和PE2,通过在PE节点部署E-Trunk,当CE至PE1的链路或PE1节点故障时,流量可以切换到PE2的链路,从而实现设备级保护
M-LAG:跨设备链路聚合组,是一种实现跨设备链路聚合的机制,将一台设备与另外两台设备进行跨设备链路聚合,从而把链路可靠性从单板级提高到了设备级,组成双活系统
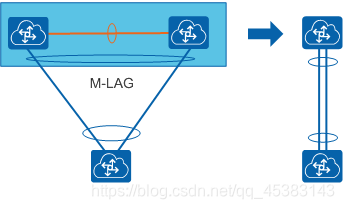
M-LAG基本概念
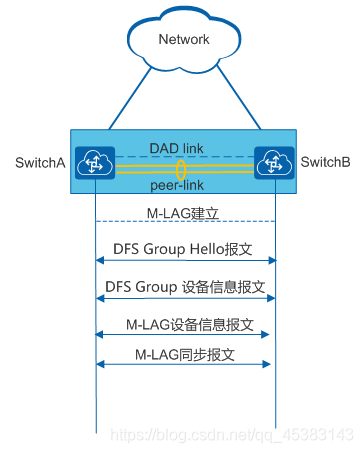
DFS Group :动态交换服务组DFS Group(Dynamic Fabric Service Group),主要用于部署M-LAG设备之间的配对,M-LAG双归设备之间的接口状态,表项等信息同步需要依赖DFS Group协议进行同步。
DFS主设备: 部署M-LAG且状态为主的设备,通常也称为M-LAG主设备。
DFS备设备: 部署M-LAG且状态为备的设备,通常也称为M-LAG备设备。
说明:
DFS Group的角色区分为主和备,正常情况下,主设备和备设备同时进行业务流量的转发,转发行为没有区别,仅在故障场景下,主备设备的行为会有差别。
双主检测链路: 双主检测链路,又称为心跳链路,是一条三层互通链路,用于M-LAG主备设备间发送双主检测报文。
说明:
正常情况下,双主检测链路不会参与M-LAG的任何转发行为,只在故障场景下,用于检查是否出现双主的情况。双主检测链路可以通过外部网络承载(比如,如果M-LAG上行接入IP网络,那么两台双归设备通过IP网络可以互通,那么互通的链路就可以作为双主检测链路)。也可以单独配置一条三层可达的链路来作为双主检测链路(比如通过管理口)。
peer-link接口: peer-link链路两端直连的接口均为peer-link接口。
peer-link链路: peer-link链路是一条直连链路且必须做链路聚合,用于交换协商报文及传输部分流量。接口配置为peer-link接口后,该接口上不能再配置其它业务。
为了增加peer-link链路的可靠性,推荐采用多条链路做链路聚合。
HB DFS主设备: 通过心跳链路来协商的状态为主的设备。
说明:
通过心跳链路报文来协商的设备HB DFS主备状态在正常情况下,对M-LAG的转发行为不会产生影响,仅用于二次故障恢复场景下,在原DFS主设备或备设备故障恢复且peer-link链路仍然故障时,触发HB DFS状态为备的设备上相应端口Error-Down,避免M-LAG设备在双主情况下出现的流量异常。
HB DFS备设备: 通过心跳链路来协商的状态为备的设备。
说明:
通过心跳链路报文来协商的设备HB DFS主备状态在正常情况下,对M-LAG的转发行为不会产生影响,仅用于二次故障恢复场景下,在原DFS主设备或备设备故障恢复且peer-link链路仍然故障时,触发HB DFS状态为备的设备上相应端口Error-Down,避免M-LAG设备在双主情况下出现的流量异常。
M-LAG成员接口: M-LAG主备设备上连接用户侧主机(或交换设备)的Eth-Trunk接口。
为了增加可靠性,推荐链路聚合配置为LACP模式。
M-LAG成员接口角色也区分主和备,与对端同步成员口信息时,状态由Down先变为Up的M-LAG成员接口成为主M-LAG成员口,对端对应的M-LAG成员口为备。
说明:
仅在M-LAG接入组播场景下,M-LAG成员接口的主备角色存在转发行为差异。
建立:
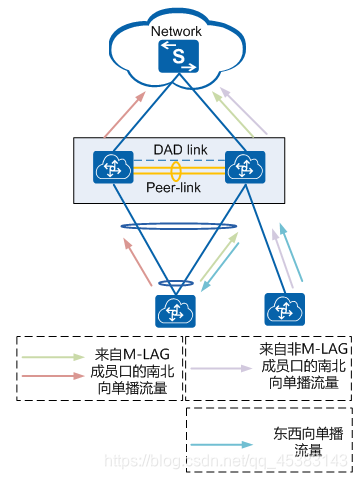
单播流量转发:本地直接查表直接走
对于南北向单播流量,在M-LAG接入侧,M-LAG的成员设备接收到接入设备通过链路捆绑负载分担发送的流量后,共同进行流量转发。到达M-LAG主备设备发往网络侧的流量则根据路由表转发流量
对于东西向单播流量,在全部组建M-LAG,没有孤立端口的场景下,二层流量通过M-LAG本地优先转发,三层流量通过双活网关转发,都不经过peer-Link链路,直接由M-LAG主备设备转发至对应成员口
组播流量转发:本地能转发,则本地转发;否则通过peer-link,走成员接口进行转发(本地能干本地干,本地干不了,交给成员干,通过peer-link交给成员)
M-LAG上行接入二层网络,那么二层网络必须要保证发往M-LAG的流量只有一份,否则会有成环的风险。假设右侧M-LAG上行接口被STP协议阻塞:
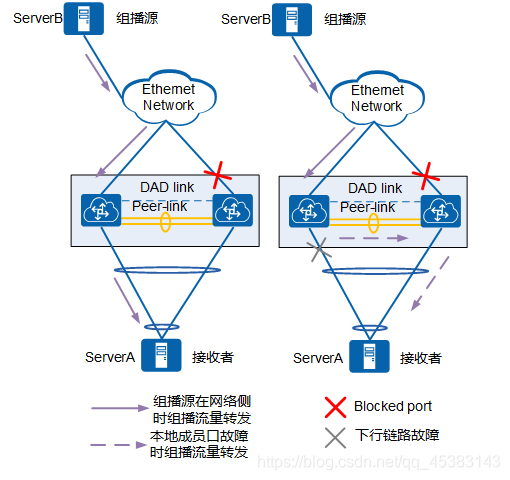
在ServerB作为组播源、ServerA作为组播组成员时,M-LAG主备都可以转发组播流量,在网络侧只引流一份流量的情况下,接收到流量的设备直接转发到本地的M-LAG成员口。如果本地M-LAG成员口故障,则组播流量如所示会从peer-link绕行,转发至M-LAG系统另一台设备的成员口进行转发。
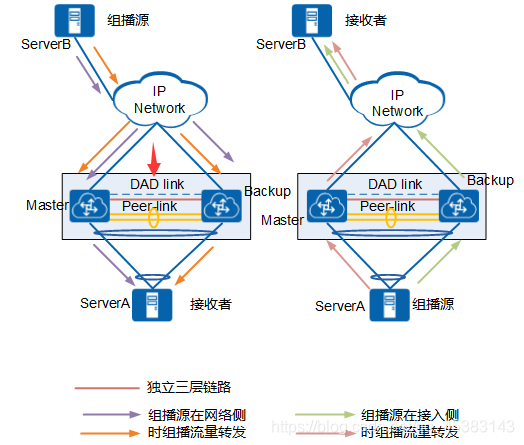
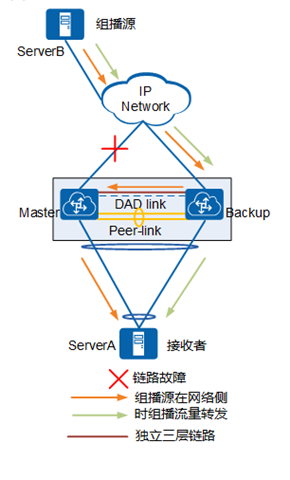
在ServerA作为组播源、ServerB作为组播组成员时,组播源的流量通过负载分担发送至M-LAG主备设备,由于右端M-LAG设备的上行接口被阻塞,那么右端设备的组播出接口指向peer-link链路。
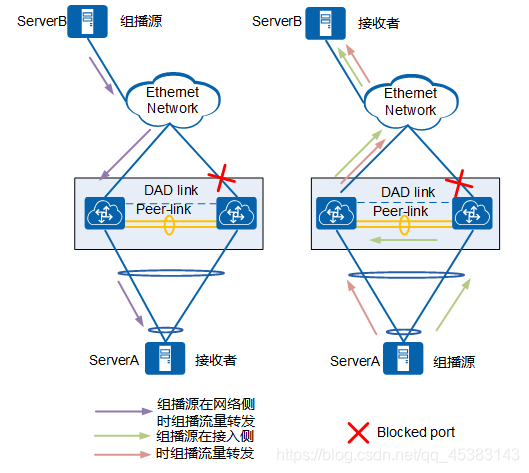
M-LAG接入二层网络组播流量成员口故障转发图:
在ServerA作为组播源、ServerB作为组播组成员时,组播源发出的流量负载分担到M-LAG系统主备设备,主备设备收到流量后在本地查找组播表将报文发送出去(未出现故障,不寻求成员帮助)
出现链路故障:
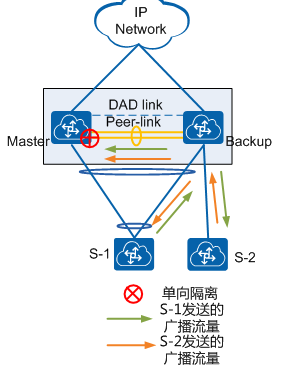
广播流量转发: 成员接口不能转发广播(防环)
M-LAG上行接入二层网络,那么二层网络必须要保证发往M-LAG的流量只有一份,否则会有成环的风险。此处以M-LAG主设备的转发为例,假设右侧M-LAG上行接口被STP协议阻塞,M-LAG主设备收到广播流量后向各个下一跳转发,当流量到达M-LAG备设备时,由于peer-link与M-LAG成员接口存在单向隔离机制,到达备设备的流量不会向S-1转发
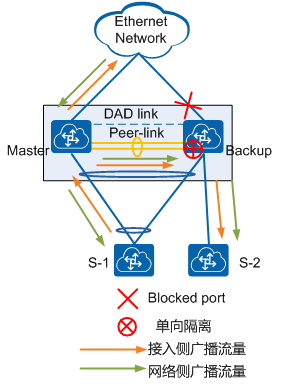
此处以M-LAG备设备的转发为例,M-LAG备设备收到广播流量后向各个下一跳转发,当流量到达M-LAG主设备时,由于peer-link与M-LAG成员接口存在单向隔离机制,到达主设备的流量不会向S-1转发
M-LAG故障场景流量转发:
本地不能转成员转:
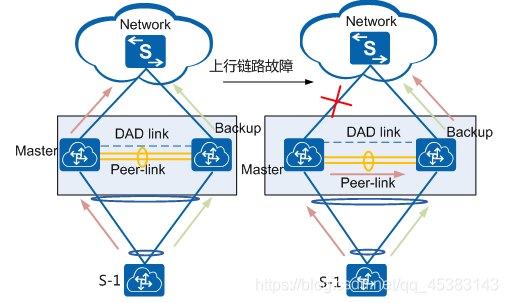
上行链路故障:
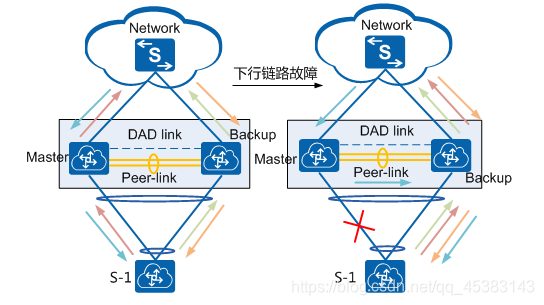
下行链路故障:
主设备故障:
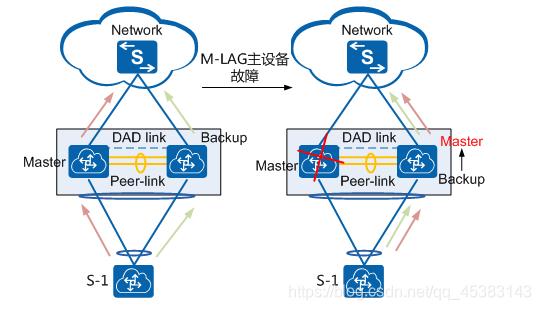
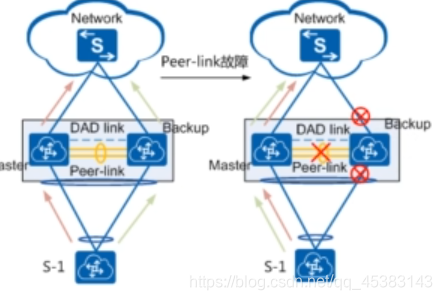
peer-link故障:故障后,阻塞备的所有接口
配置根桥和桥ID:采用根桥方式配置M-LAG时,必须将M-LAG主设备和备设备均作为STP网络中的根桥且配置相同的桥ID,将两台设备模拟成同一个根桥
配置同一个根桥:
•执行命令system-view,进入系统视图。
•执行命令stp [ instance instance-id ] root primary,配置当前设备为根桥设备。
缺省情况下,交换设备不作为任何生成树的根桥。配置后该设备优先级值自动为0,将不能更改设备优先级。
如果不指定instance,则配置设备在实例0上为根桥设备。
•执行命令stp bridge-address mac-address,配置设备参与生成树计算的桥MAC。
缺省情况下,当前设备参与生成树计算的桥MAC是设备的MAC地址。在配置M-LAG主备设备桥MAC时,建议选取两台设备中MAC地址较小的作为参与生成树计算的桥MAC。
•执行命令commit,提交配置。
执行命令system-view,进入系统视图。
执行命令dfs-group dfs-group-id,创建DFS Group并进入DFS-Group视图。
根据实际场景选择配置DFS Group绑定IP地址。
设备双归接入普通以太网络、VXLAN或IP网络时,配置DFS Group绑定IP地址。以下任选一种即可,不支持同时配置。
执行命令source ip ip-address [ peer peer-ip-address],配置DFS Group绑定IPv4地址和VPN实例。
执行命令source ipv6 ipv6-address [ peer peer-ipv6-address ],配置DFS Group绑定IPv6地址和VPN实例。
peer-link:
执行命令system-view,进入系统视图。
执行命令interface eth-trunk trunk-id,进入Eth-Trunk接口视图。
执行命令trunkport interface-type { interface-number1 [ to interface-number2 ] } &<1-n>,增加成员接口。
批量增加成员接口时,若其中某个接口加入失败,则全部回退,此接口之前的接口也不会加入到Eth-trunk接口中。
执行命令mode lacp-static,配置Eth-Trunk的工作模式为静态LACP模式。
缺省情况下,Eth-Trunk的工作模式为手工负载分担模式。为了提高M-LAG的可靠性,必须配置为静态LACP模式。
执行命令undo stp enable,去使能接口的STP功能。
缺省情况下,接口的STP功能处于使能状态。
执行命令peer-link peer-link-id,配置接口为peer-link接口。
缺省情况下,接口不是peer-link接口。
•接口配置为peer-link接口后,缺省加入所有VLAN。
•接口配置为peer-link接口后,该接口上不能再配置其他业务。
•如果后续需要配置ERPS的控制VLAN、TRILL的Carrier VLAN或FCoE VLAN,需要执行步骤7将peer-link接口退出控制VLAN、Carrier VLAN或FCoE VLAN,否则无法配置。
•如果后续配置了网络侧的VLANIF且该VLANIF接口为双主检测链路,建议执行步骤7将peer-link接口退出相应的vlan,否则有可能会造成心跳检测失效等问题。
(可选)执行命令port vlan exclude { { vlan-id1 [ to vlan-id2 ] } &<1-10> },配置peer-link接口不允许通过的VLAN。
缺省情况下,未配置peer-link接口不允许通过的VLAN。
增强M-LAG三层转发:为提升M-LAG成员口故障时的收敛速度,可以使能M-LAG三层转发增强功能,形成下行出接口的主备备份路径,在M-LAG成员口故障时能够快速切换出接口为peer-link接口
•执行命令m-lag forward layer-3 enhanced enable(CE6881、CE6863和CE6820)或者m-lag forward layer-3 { ipv4 | ipv6 } enhanced enable(除CE6881、CE6863和CE6820),使能M-LAG三层转发增强功能。
缺省情况下,M-LAG三层转发增强功能未使能。
•在使能M-LAG三层转发增强功能后,对于报文出端口为M-LAG成员接口的所有ARP/ND表项会申请备份的FRR资源,出接口指向peer-link接口,形成主备路径转发。一旦FEI侧感知到M-LAG成员接口故障,设备双归接入变成单归,则将对应ARP/ND表项的下一跳由M-LAG成员接口切换为Peer-link接口,提升故障场景下的切换性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









