







小罗碎碎念
今天和大家分享的是一份国自然青年基金项目,直接费用为19万,于2022年12月结题。
项目的核心内容是设计和实现一个动态的、全程优化的智能连续决策模式。
研究团队基于贝叶斯理论,构建了非完整观测环境中的连续决策模型,并开发了多种深度强化学习算法。这些算法能够有效地处理慢性病治疗中的复杂决策问题,如药物剂量的调整和治疗方案的选择。此外,项目还引入了专家知识和注意力机制,以提高决策结果的可解释性,使医生能够更好地理解和信任系统的推荐。

在研究成果方面,项目团队在国内外知名学术期刊和会议上发表了多篇论文,其中包括SCI检索的国际A类期刊论文和CPCI/EI检索的国际会议论文。这些论文详细介绍了项目的研究方法、实验结果和应用前景,得到了学术界的广泛关注和认可。项目还积极开展国际合作与交流,邀请了多位境外知名学者进行合作,并资助团队成员参加国际学术会议,促进了学术思想的交流和融合。
在实际应用方面,项目的研究成果已经应用于多家医院的慢性病管理和药物推荐系统中。例如,在成都市慢性病专科医院和西区医院康复科,项目开发的“专家级机器医生”系统能够为全科医生提供个性化的诊疗建议,提升了医疗服务的质量和效率。此外,项目还培养了一批青年教师和研究生,为相关领域的人才培养和学科建设做出了贡献。
知识星球
如需获取推文中提及的各种资料,欢迎加入我的知识星球!
一、项目简介
研究内容与成果
长周期数据特征挖掘
- 提出多类型特征挖掘和融合方法,基于LSTM网络融合多种类型特征嵌入层,挖掘决策项目联系,发表于IJCNN。
- 结合域适应和深度图神经网络,学到具有网络可迁移性的低维特征表示,发表于AAAI,被引用26次。
- 提出用于序列生成的递归嵌套模型,增加模型深度,通过实验发现相关连接对模型有益,发表于AAAI。
马尔科夫过程模型构建和学习算法研究
- 提出基于电子健康记录的深度强化学习模型(EHRs - DQN),将其扩展到多智能体合作学习,优化慢性病治疗策略,发表于信息系统国际A类期刊,被引用17次。
- 提出基于分层深度强化学习的目标导向治疗决策方法(GORL),模拟临床医生指导学习过程,优化败血症治疗策略,已投稿国际B类期刊,二审中。
- 提出基于电子病历的分类器链多病序贯诊断方法,解决疾病诊断顺序问题,已投稿国际B类期刊。
增强结果可解释性的研究
- 提出可解释条件扩充分类方法,利用条件生成对抗网平衡样本,提高不平衡电子病例死亡率预测模型性能和可解释性,发表于数据挖掘国际会议DMBD。
- 提出基于患者相似性的药物推荐模型,结合贝叶斯图模型和注意力机制等,使推荐结果具有可解释性,已投稿UTD期刊和A类期刊Information Systems,并在成都慢性病专科医院内部测试使用。
研究人员与合作交流
- 研究人员分工:负责人主导项目各环节,其他成员参与数据处理、模型实现与评估及部分论文撰写。
- 国际合作交流:邀请3人次海外学者交流,负责人及团队成员4人次参加国际会议作报告5次,负责人参与组织国际会议1次,合作撰写论文2篇(发表1篇,1篇在投)。
- 国内合作交流:与多所医院建立合作关系,取得初步成果;与腾讯、华为等企业保持合作,发表合作论文2篇。
项目成果总结
- 理论研究创新:在动态医疗长周期连续决策系统多方面取得突破,为医疗智能化决策开辟新思路。
- 论文发表:发表论文6篇,包括SCI检索国际A类期刊论文1篇,CPCI/EI检索国际会议论文4篇(A类2篇),国内学术期刊论文1篇。
- 人才培养:培养青年教师1名(晋升副教授),获相关称号;本科生2人参与发表论文;硕博研究生6人,发表或投稿论文6篇。
- 成果转化应用:为肿瘤医院研发组学分析方法,降低检测成本;方法应用于基层医院慢性病管理,提升医生水平,减轻医护负担;药物推荐系统成果应用于老年慢性病护理。
二、多类型特征挖掘和融合方法的整体框架
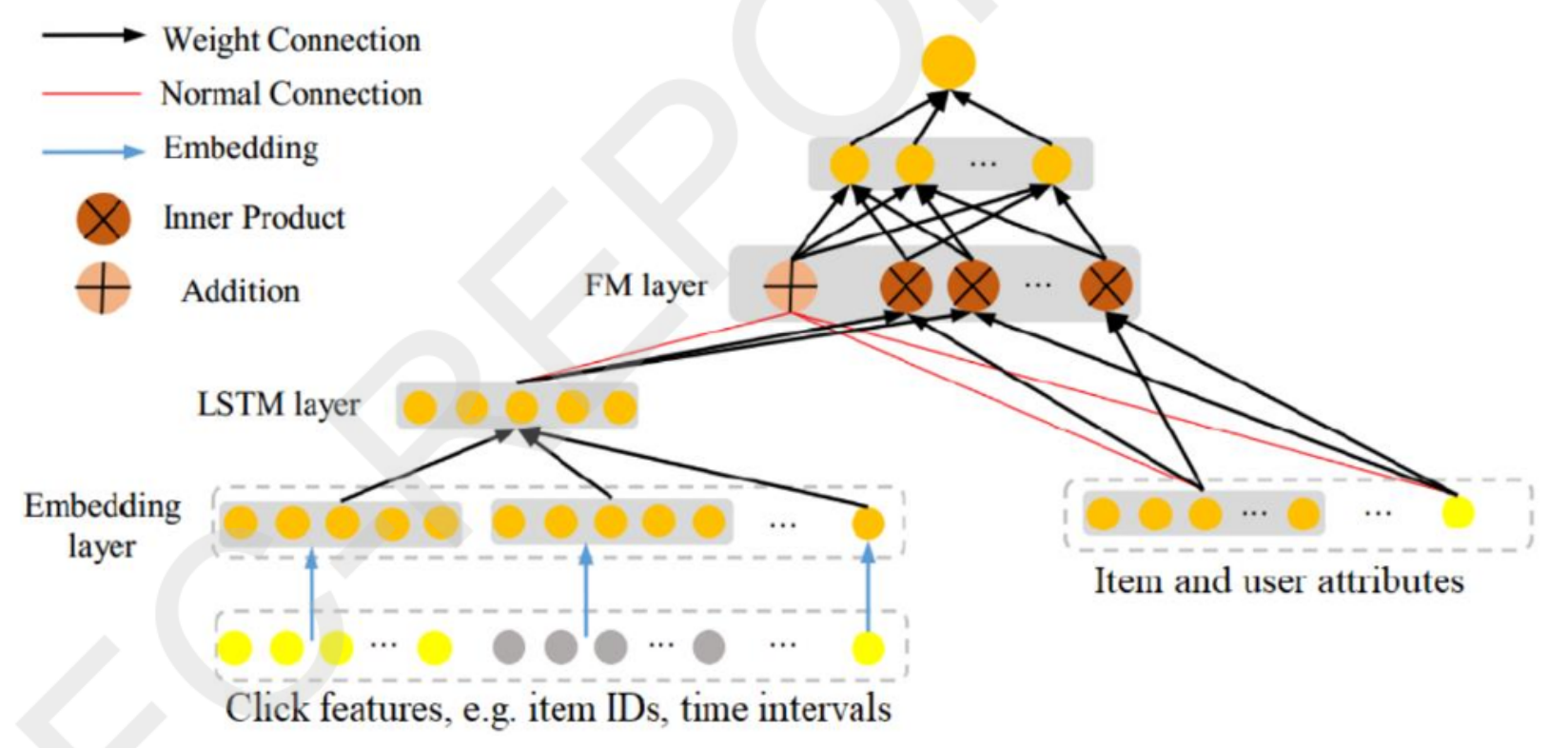
整体结构
框架主要由多个层次和不同类型的连接组成,从下往上依次为:
- Embedding layer(嵌入层):接收点击特征,例如物品ID、时间间隔等,这些特征用黄色和灰色的点表示。通过嵌入操作(蓝色箭头指向),将这些原始特征转换为更有意义的向量表示。
- LSTM layer(长短期记忆层):接收来自嵌入层的输出,用于处理序列数据,捕捉数据中的时序信息和长期依赖关系。
- FM layer(因子分解机层):包含多种操作,如内积(Inner Product,用棕色叉号表示)和加法(Addition,用橙色加号表示)。它接收来自LSTM层的输出以及物品和用户属性(Item and user attributes,用黄色点表示),通过这些操作来挖掘和融合不同类型的特征。
连接类型
- Weight Connection(权重连接):用黑色箭头表示,通常用于传递信息并在传递过程中可能涉及权重的调整,以反映不同连接的重要性。
- Normal Connection(普通连接):用红色箭头表示,可能是一种较为直接的信息传递方式,不涉及或较少涉及权重的调整。
- Embedding(嵌入):用蓝色箭头表示,特指从原始特征到嵌入层的转换过程,将原始特征映射到低维向量空间。
应用背景(其他领域扩展)
除了医疗领域,这种多类型特征挖掘和融合的方法在很多领域都有应用,特别是在推荐系统中。
通过综合考虑用户的点击行为、物品属性以及用户自身属性等多种信息,能够更全面地理解用户需求和物品特征,从而提高推荐的准确性和个性化程度。
例如,在电商平台中,可以根据用户的历史点击记录(如浏览过的商品、浏览时间等)、商品的属性(如类别、价格等)以及用户的个人信息(如年龄、性别等),利用这样的框架来挖掘潜在的特征和关系,为用户提供更符合其兴趣的商品推荐。
优势与意义
该框架的优势在于能够有效地整合多种类型的信息,避免了单一类型信息的局限性。
通过LSTM层处理时序信息,能够捕捉用户兴趣的动态变化;通过FM层的内积和加法操作,可以挖掘不同特征之间的交互关系,从而更好地理解数据的内在结构和模式。
这对于提升模型的性能和泛化能力具有重要意义,能够为用户提供更精准、更个性化的服务和体验。
三、融合电子健康记录建模和深度Q网络的连续决策框架
这一部分展示了“融合电子健康记录建模和深度Q网络的连续决策框架”,主要分为两个部分:EHRs建模和基于DQN的强化学习。
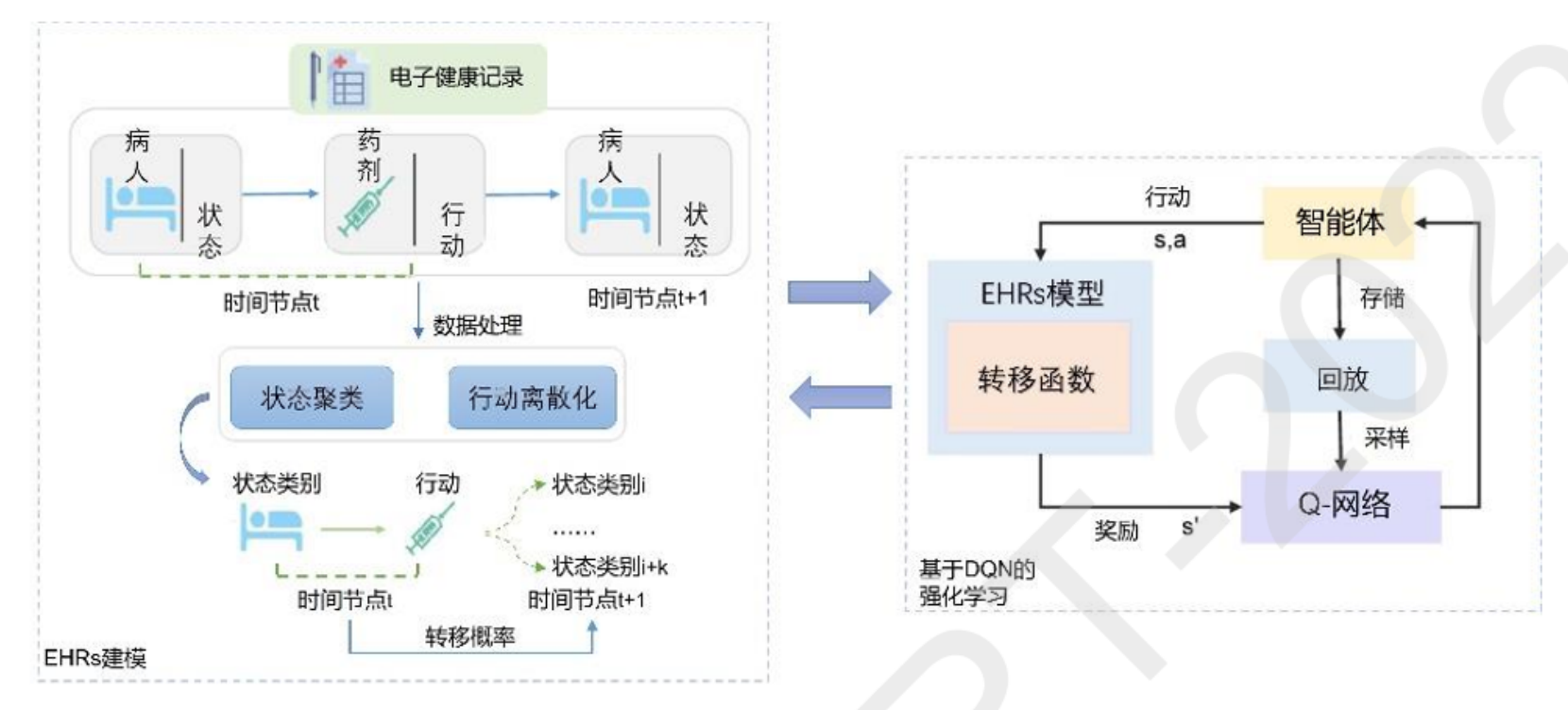
EHRs建模部分
- 电子健康记录(EHRs):是整个框架的基础数据来源,包含了病人的状态、药剂使用以及病人后续状态等信息。
- 时间节点:在时间节点t,记录病人的当前状态和所采取的药剂行动;在时间节点t + 1,记录病人在采取行动后的新状态。
- 数据处理:包括状态聚类和行动离散化。状态聚类是将病人的各种状态归为不同的类别,行动离散化则是将药剂使用等行动进行离散处理,以便于后续的建模和分析。
- 转移概率:通过对不同时间节点上状态和行动的分析,计算出状态类别之间的转移概率,这对于理解病人状态的变化规律以及预测未来状态非常重要。
基于DQN的强化学习部分
- EHRs模型与转移函数:EHRs模型结合转移函数,用于模拟病人状态和行动之间的关系,为强化学习提供环境模型。
- 智能体:是决策的核心,根据当前状态(s)和采取的行动(a)与环境进行交互。
- 存储、回放和采样:智能体的交互经验(包括状态、行动、奖励和下一个状态)被存储起来,然后通过回放机制进行采样,用于训练Q - 网络。
- Q - 网络:通过学习大量的样本数据,不断优化其对状态 - 行动值(Q值)的估计,从而指导智能体做出更好的决策,以获得最大的奖励。
整体流程与应用
整个框架的流程是:首先从电子健康记录中提取病人状态和药剂行动等信息,经过数据处理后构建EHRs模型和计算转移概率;然后智能体在这个环境中根据当前状态采取行动,与环境交互产生经验数据,这些数据被存储、回放和采样后用于训练Q - 网络;Q - 网络不断优化,反过来又指导智能体做出更优的决策,形成一个闭环的连续决策过程。
这种融合电子健康记录建模和深度Q网络的连续决策框架在医疗领域具有重要应用价值。例如,可以用于优化慢性病的治疗决策,根据病人的历史健康记录和当前状态,智能地推荐最佳的治疗方案(如药剂的选择和使用时机等),提高治疗效果,同时也可以为医生提供决策支持,减少医疗决策的主观性和不确定性。
结束语
本期推文的内容就到这里啦,如果需要获取医学AI领域的最新发展动态,请关注小罗的推送!如需进一步深入研究,获取相关资料,欢迎加入我的知识星球!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









