







前言:提倡先会使用,再研究底层的学习习惯
一:创建线程的四种方式
第一种:继承Thread类
前言:在多线程的场景下,一般有一个被操作的资源类,多个操作者
/**
* Thread中的常用方法
* 1,实例方法
* start():通知线程规划器此现场可以运行了。要注意调用start方法的顺序不代表线程启动的顺序,也就是cpu执行哪个线程的代码具有不确定性
* run():线程类调用start后执行的方法,如果在直接调用run而不是start方法,那么和普通方法一样,没有区别
* getName():获取线程名城
* isAlive():判断当前线程是否处于活动状态。活动状态就是已经启动尚未终止
* setPriority(int p):设置线程的优先级,默认情况下,线程的优先级是5。线程的优先级分为1~10等级,优先级高的线程容易被cpu执行
* getPriority():获取当前线程的优先级
* join():在线程a中调用线程b的join()方法,此时线程a进入阻塞状态
* 2,静态方法
* currentThread():当前正在执行线程对象的引用
* sleep(long millis):睡(不释放锁)
* yield():释放当前CPU的执行
*/
public class TestThread1 {
public static void main(String[] args) {
Source thread1 = new Source();
thread1.start();
}
}
/**
* 资源类
*/
class Source extends Thread {
@Override
public void run() {
System.out.println("操作资源");
}
}
第二种:实现Runnable接口
public class TestThread2 {
public static void main(String[] args) {
Source2 thread2 = new Source2();
new Thread(thread2).start();
}
}
/**
* 资源类
*/
class Source2 implements Runnable {
@Override
public void run() {
System.out.println("操作资源");
}
}
第三种:实现Callable接口
/**
* 使用callable接口实现的逻辑是
* new Thread(Runnable )
* Runnable的实现类有FutureTask
* FutureTask的构造参数有Callable
*/
public class TestThread3 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//创建资源类
Source3 source3 = new Source3();
//创建FutureTask把资源类穿进去
FutureTask futureTask = new FutureTask(source3);
//创建线程把FutureTask穿进去,就可以了
new Thread(futureTask).start();
Object o = futureTask.get();
System.out.println(o);
}
}
class Source3 implements Callable {
@Override
public Object call() throws Exception {
System.out.println("我进来了");
return "你想要返回的Object";
}
}
第四种:使用线程池创建
池化技术主要是节省资源,避免开启和关闭造成的资源浪费,线程池,数据库连接池亦如此
因为阿里规约不建议使用Executors去创建线程池,所以我们只列举demo,其实底层都是ThreadPoolExecutor
public static void main(String[] args) {
// 创建一个缓存池,根据cpu性能去调度最大限度的线程数
ExecutorService threadPool = Executors.newCachedThreadPool();
// 创建一个单利的线程
// ExecutorService threadPool = Executors.newSingleThreadExecutor();
// 创建一个固定大小的线程池
// ExecutorService threadPool = Executors.newFixedThreadPool(3);
// 创建一个任务调度线程池
// ExecutorService threadPool = Executors.newScheduledThreadPool(3);
try {
for (int i = 0; i < 100; i++) {
//在使用时有submit和execute两种方式,后面在详解
threadPool.execute(() -> System.out.println(Thread.currentThread().getName() + " ok"));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
//用完后记得关闭,但是在线上跑项目的时候不需要关闭
threadPool.shutdown();
}
}
重点:
public ThreadPoolExecutor(int corePoolSize, //核心线程数量
int maximumPoolSize, //最大线程数量
long keepAliveTime, //存活时间(超时了没人调用就会释放)
TimeUnit unit, //超时单位
BlockingQueue<Runnable> workQueue, //阻塞队列
ThreadFactory threadFactory, //线程工厂(一半不动)
RejectedExecutionHandler handler) //拒绝策略
/**
* 四种拒绝策略
* 1.AbortPolicy 抛出异常
* 2.CallerRunsPolicy 哪来的回哪去,哪个线程让你进来的,你就回去,比如main线程
* 3.DiscardPolicy 队列满了就丢掉任务,不抛出异常,不执行
* 4.DiscardOldestPolicy 队列满了尝试和最早的线程竞争 不抛出异常
**/
public class MyThreadPool {
public static void main(String[] args) {
// max的设置可以考虑两点 : CPU核心数和IO密集
// cpu最大核心数
// Runtime.getRuntime().availableProcessors();
// 根据具体的任务情况可以使用IO密集型,比如有15个大型任务,就可以设置为15
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(
2, //核心数量2个-->银行开放两个核心窗口
5, //最大数量5个-->银行一共有窗口
3, //开启最大线程数以后,线程执行完了,等待3s,没有任务进来 就关闭最大数量,保留核心数量-->银行的3个非核心窗口3s没有任务执行,就关闭
TimeUnit.SECONDS, //超时单位 秒
new LinkedBlockingQueue<>(3), //阻塞队列长度 3个-->银行等待区大小
Executors.defaultThreadFactory(), //默认的线程工厂
new ThreadPoolExecutor.DiscardOldestPolicy() //抛出异常的拒绝策略,一共四种
);
try {
//线程池最大承载数量为 max+Queue
//当任务为6( >5 但是 <=8 )时,开放最大线程数量,当任务数 >=9时,启动拒绝策略
for (int i = 1; i <= 15; i++) {
//执行任务
threadPool.execute(() -> System.out.println(Thread.currentThread().getName()));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
threadPool.shutdown();
}
}
}
二:锁
第一种:synchronized
/**
* synchronized 他是java的关键字
* 到底锁的是什么?
*
* http://openjdk.java.net/
* http://hg.openjdk.java.net/
*/
public class TestSync {
/**
* java对象的结构
* 对象头(12字节 96位):对象的布局、.class文件 、GC状态、同步状态和标识哈希代码的基本信息
* mark word(64bit 8字节) : hashCode 锁状态 GC 状态 年代划分 synchronized 主要是针对mark word
* klass pointer(32bit 4个字节): 指向类模板的指针 案例来说站8个字节的 进行了指针压缩 优化内存 JVM 关闭指针压缩 -XX:+UseCompressedOops,禁止指针压缩:-XX:-UseCompressedOops
* 实例数据
* 对齐填充 (alignment/padding gap) 因为cpu设定一次可以读 64字节来操作 8的倍数 要不在多核的cpu会数据丢失
*
* 对象的状态 无锁 偏向锁 轻量级锁 重量级锁 GC标记 biased_lock:1 lock:2
*
* 锁升级过程(锁的膨胀过程)
* 无锁 -- > 偏向锁 --- > 轻量级锁 ------> 重量级锁
* 偏向锁 当有一个线程1获取到锁了 把当前线程的id 给对象头加一个标记
* 此时这个对象就是 偏向对象
* 当线程2来了 也要获取锁对象
* 先判断对象是否是偏向对象
* 如果这个对象是 偏向对象??
* 判断线程1 是否存活
* 如果不存活 需要使用CAS 把之前的线程id 替换成我自己的 (因为之前的线程不会去处理锁的状态 )
* 替换成功 就加锁成功 此时锁还是偏向锁
* 如果线程1存活 搞一个竞争
* 锁就会有 偏向锁 ---- > 轻量级锁 自旋 循环+CAS
*
* 当自选次数超过10次 或者有大量的线程竞争
* 锁就会有 轻量级锁 ---- 重量级锁 (由操作系统控制了 两个队列 一个竞争队列 一个等待队列 )
* 此时 用户态-->内核态 (对外提供了接口 程序表 线程数 操作系统的调度器) 开销非常大
*
* 锁升级是可逆的 批量撤销
*
* Lock
*
* jvm 规范 有很多实现 hospot j9
*
* @param args
*/
public static void main(String[] args) {
SxtSync sxtSync = new SxtSync();
// 可以锁对象 也可以类的模板 .class
System.out.println(ClassLayout.parseInstance(sxtSync).toPrintable());
synchronized (sxtSync){
System.out.println(ClassLayout.parseInstance(sxtSync).toPrintable());
}
}
}
第二种:lock
lock锁是JDK1.5以后加进来的新API,先看这几个lock锁的关系图,我们关心常用的lock列举学习

第一种:可重入锁—ReentrantLock
/**
* ReentrantLock:可重入锁
* 使用方法
* 在try->catch->finally里面使用
**/
public class MyReentrantLock {
static int count = 0;
public static void main(String[] args) {
Lock lock = new ReentrantLock();
for (int i = 0; i <= 100; i++) {
new Thread(() -> {
// 操作资源的时候加锁
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + "-->" + count++);
} catch (Exception e) {
e.printStackTrace();
} finally {
// 资源操作完成后释放锁
lock.unlock();
}
}, String.valueOf(i)).start();
}
}
}
第二种:读写锁之可重入读写锁—ReentrantReadWriteLock
/**
* ReentrantReadWriteLock:读写锁,细粒度解决资源存储读取问题
* 使用方法:
* 在对资源读取时加读锁 readWriteLock.readLock().lock()
* 在对资源赋值时加写锁 readWriteLock.writeLock().lock()
* 注意解锁
**/
public class MyReadWriteLock {
public static void main(String[] args) {
Source source = new Source();
// 五个线程去放值
for (int i = 1; i <= 5; i++) {
final int temp = i;
new Thread(() -> source.put(temp + "", temp), String.valueOf(i)).start();
}
// 五个线程去读取
for (int i = 1; i <= 5; i++) {
final int temp = i;
new Thread(() -> source.get(temp + ""), String.valueOf(i)).start();
}
}
}
class Source {
Map<String, Object> map = new HashMap<>();
ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock();
void put(String k, Object v) {
// 写入加上写锁
readWriteLock.writeLock().lock();
try {
System.out.println(Thread.currentThread().getName() + "开始写入");
map.put(k, v);
System.out.println(Thread.currentThread().getName() + "写入OK");
} catch (Exception e) {
e.printStackTrace();
} finally {
// 记得释放锁
readWriteLock.writeLock().unlock();
}
}
Object get(String k) {
Object o = null;
// 读取加上读锁
readWriteLock.readLock().lock();
try {
System.out.println(Thread.currentThread().getName() + "开始读取");
o = map.get(k);
System.out.println(Thread.currentThread().getName() + "读取OK");
} catch (Exception e) {
e.printStackTrace();
} finally {
// 记得释放锁
readWriteLock.readLock().unlock();
}
return o;
}
}
分析Lock锁底层源码:
锁的基本实现原理是
● 有一个表示(锁)状态的变量(例如 0表示没有现成获取锁,1表示已经有线程占有锁),该变量必须声明为volatile修饰的
● 一个队列,队列中的节点表示未能获取锁而阻塞的线程。
关于上述两个锁的运用,底层都是同样的实现原理,如图:

总结synchronized与Lock的区别
● Lock的加锁和解锁都是由java代码配合native方法(调用操作系统的相关方法)实现的,而synchronize的加锁和解锁的过程是由JVM管理的
● 当一个线程使用synchronize获取锁时,若锁被其他线程占用着,那么当前只能被阻塞,直到成功获取锁。而Lock则提供超时锁和可中断等更加灵活的方式,在未能获取锁的 条件下提供一种退出的机制。
● 一个锁内部可以有多个Condition实例,即有多路条件队列,而synchronize只有一路条件队列;同样Condition也提供灵活的阻塞方式,在未获得通知之前可以通过中断线程以及设置等待时限等方式退出条件队列。
● synchronize对线程的同步仅提供独占模式,而Lock即可以提供独占模式,也可以提供共享模式
三:JUC的常用辅助类
第一个:CountDownLatch
/**
* countDownLatch是一个计数器(减法计数器),线程完成一个记录一个,计数器递减,只用一次
* 常用方法有:
* countDown():计数器-1
* await():等待计数器为0时,往下执行 --- 注意这个方法是阻塞式的
* await(long,TimeUnit):等待一定的时间后count值还没变为0的话就会继续往下执行
* getCount():获得计数器数量
**/
public class MyCountDownLatch {
public static void main(String[] args) throws InterruptedException {
CountDownLatch downLatch = new CountDownLatch(10);
for (int i = 0; i < 10; i++) {
new Thread(() -> {
//计数器-1
downLatch.countDown();
System.out.println(Thread.currentThread().getName() + "--" + downLatch.getCount());
}, String.valueOf(i)).start();
}
//等待计数器为0
downLatch.await();
// downLatch.await(1, TimeUnit.SECONDS); 等待1s后count值还不为0时往下执行
System.out.println("结束了");
}
}
第二个:CyclicBarrier
/**
* CyclicBarrier:是一个计数器(加法计数器)屏障,线程完成一个记录一个,计数器递减,只能用一次
* 常用方法:
* CyclicBarrier(int parties) --- 定义参与线程的个数
* CyclicBarrier(int parties,Runnable r) --- 在最后一个线程到达后,由最后一个进入屏障的线程执行任务
* await():等待所有的线程到达屏障后往下执行
**/
public class MyCyclicBarrier {
public static void main(String[] args) {
CyclicBarrier cyclicBarrier = new CyclicBarrier(10, () -> System.out.println("全部到达,最后一个线程" + Thread.currentThread().getName() + "执行了这个任务"));
for (int i = 1; i <= 10; i++) {
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "到达屏障");
try {
//到达屏障一次
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}, "Thread--" + i).start();
}
}
}
第三个:Semaphore
/**
* Semaphore:一个计数信号量,可以用在抢车位---可以限流
* 常用方法:
* Semaphore(int p) --- 创建给定数量p个的许可证和非公平锁设置。
* Semaphore(int p,boolean f) --- 创建一给定数量p个的许可证和公平锁设置
* acquire():从该信号量获取许可证,阻止其他线程获取,直到释放
* release():释放许可证,将其返回到信号量
**/
public class MySemaphore {
public static void main(String[] args) {
// 这是设定2个许可证,假设是2个车位
Semaphore semaphore = new Semaphore(2);
for (int i = 1; i <= 6; i++) {
// 这里假设有6个车要进来停车
new Thread(() -> {
try {
// 拿到一个许可证
semaphore.acquire();
System.out.println(Thread.currentThread().getName() + "进入了车位");
// 停车三秒
TimeUnit.SECONDS.sleep(3);
System.out.println(Thread.currentThread().getName() + "离开了车位");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 释放车位
try {
TimeUnit.SECONDS.sleep(1);
System.out.println("-------------------------");
} catch (InterruptedException e) {
e.printStackTrace();
}
//释放许可证
semaphore.release();
}
}, String.valueOf(i)).start();
}
}
}
辅助类总结
CountDownLatch 是一次性的,CyclicBarrier 是可循环利用的
CountDownLatch 参与的线程的职责是不一样的,有的在倒计时,有的在等待倒计时结束。CyclicBarrier 参与的线程职责是一样的。
四:Queue(FIFO=first input first output)
首先来看Queue在java中的结构关系图

一:BlockingQueue的四组Api
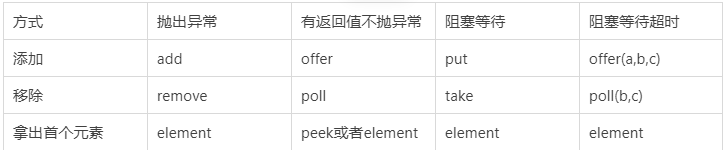
/**
* 抛出异常 add --- remove
*/
public static void test1() {
//定义一个长度为3的阻塞队列
BlockingQueue blockingQueue = new ArrayBlockingQueue<>(3);
//添加成功返回true
blockingQueue.add("a");
blockingQueue.add("b");
blockingQueue.add("c");
//超过长度抛出异常
// blockingQueue.add("d");
//拿到首个元素
System.out.println(blockingQueue.element());
//移除
System.out.println(blockingQueue.remove());
System.out.println(blockingQueue.remove());
System.out.println(blockingQueue.remove());
//取不到值抛出异常
// System.out.println(blockingQueue.remove());
}
/**
* 不抛异常有返回值 offer --- poll
*/
public static void test2() {
//定义一个长度为3的阻塞队列
BlockingQueue blockingQueue = new ArrayBlockingQueue<>(3);
//添加成功返回true
blockingQueue.offer("a");
blockingQueue.offer("b");
blockingQueue.offer("c");
//超多长度返回false
boolean d = blockingQueue.offer("d");
System.out.println(d);
//拿到首个元素
System.out.println(blockingQueue.element());
//移除
System.out.println(blockingQueue.poll());
System.out.println(blockingQueue.poll());
System.out.println(blockingQueue.poll());
//取不到返回null
System.out.println(blockingQueue.poll());
}
/**
* 阻塞等待 put --- take
*/
public static void test3() throws InterruptedException {
//定义一个长度为3的阻塞队列
BlockingQueue blockingQueue = new ArrayBlockingQueue<>(3);
//添加成功无返回值
blockingQueue.put("a");
blockingQueue.put("b");
blockingQueue.put("c");
//超多长度阻塞线程
//blockingQueue.put("d");
//拿到首个元素
System.out.println(blockingQueue.element());
//移除
System.out.println(blockingQueue.take());
System.out.println(blockingQueue.take());
System.out.println(blockingQueue.take());
//取不到阻塞线程
// System.out.println(blockingQueue.take());
}
/**
* 阻塞 等待超时后结束 offer(a,b,c) --- poll(b,c)
*/
public static void test4() throws InterruptedException {
//定义一个长度为3的阻塞队列
BlockingQueue blockingQueue = new ArrayBlockingQueue<>(3);
//添加成功返回true
blockingQueue.offer("a");
blockingQueue.offer("b");
blockingQueue.offer("c");
//超多长度阻塞线程 等待指定时间后往后执行
blockingQueue.offer("d", 2, TimeUnit.SECONDS);
//拿到首个元素
System.out.println(blockingQueue.peek());
//移除
System.out.println(blockingQueue.poll());
System.out.println(blockingQueue.poll());
System.out.println(blockingQueue.poll());
//取不到阻塞线程 等待指定时间后往后执行
System.out.println(blockingQueue.poll(2, TimeUnit.SECONDS));
}
二:SynchronousQueue同步队列
同步队列也是阻塞队列的一种,底层其实是Transferer,new SynchronousQueue()的时候传true就是TransferQueue (FIFO公平队列),传false或者不传就是TransferStack(非公平队列)
底层维护了一个QNode的节点(含尾指针,是单向连表),存储一个数据,运用CAS,来放(put) 和取(take)元素 这两个方法互相唤醒对方。
特点是只能存在一个元素,底层用park和unpark来阻塞和放行线程,可以用作生产者和消费者模式
/**
* 同步队列
*/
public static void test5() {
BlockingQueue<String> synchronousQueue = new SynchronousQueue<>(true);
//一个线程去循环放
new Thread(() -> {
for (int i = 0; i < 5; i++) {
final int temp = i;
try {
TimeUnit.SECONDS.sleep(2);
System.out.println(Thread.currentThread().getName() + " put " + temp);
synchronousQueue.put(temp + "");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "T1").start();
//五个线程去取
for (int i = 0; i < 5; i++) {
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + " take--->" + synchronousQueue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "T2").start();
}
}














 187
187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









