







解决报错OverflowError: Python int too large to convert to C long.
问题描述
问题代码如下:
TEXT = torchtext.data.Field(sequential=True)
LABEL = torchtext.data.Field(sequential=False, dtype=torch.long, use_vocab=False)
#使用TabularDataset方法生成数据集
# 读取文件生成数据集
fields = [('label', LABEL), ('comment', TEXT)]
train, valid, test = TabularDataset.splits(
path='/root/For+Detecting+sentiment+polarity/lstm/', format='csv',
train='train_data.csv',
validation="valid_data.csv",
test='test_data.csv',
skip_header=True, fields=fields)
运行时出现报错:
OverflowError: Python int too large to convert to C long.
问题分析:
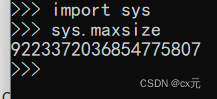
根据提示可知,是发生了溢出错误,即问题数字超过了系统支持的最大数值表示sys.maxsize:
但是更换数据集之后还是一样的报错,所以猜想可能是torchtext版本问题。
解决方法:
搜索了很多解决方法,发现,其实有可能是torchtext的版本问题。
最开始报错时使用的torchtext版本好像是0.4.0,降低版本改成0.2.3就不会报错了。
但是版本为0.2.3时torchtext.data.Field不支持dyte参数。
去官网查了一下pytorch和torchtext的对应版本,我的pytorch是1.9,解释器python3.8,对应的torchtext版本为0.10.0,于是又把torchtext更新为0.10.0,此时不会再报错,但是会发现0.10.0版本的torchtext没有Field,其实是放在了别的package里,把所有的torchtext.data改为torchtext.legacy.data就可以了。代码更新如下:
TEXT = torchtext.legacy.data.Field(sequential=True)
LABEL = torchtext.legacy.data.Field(sequential=False, dtype=torch.long, use_vocab=False)
#使用TabularDataset方法生成数据集
# 读取文件生成数据集
fields = [('label', LABEL), ('comment', TEXT)]
train, valid, test = TabularDataset.splits(
path='/root/For+Detecting+sentiment+polarity/lstm/', format='csv',
train='train_data.csv',
validation="valid_data.csv",
test='test_data.csv',
skip_header=True, fields=fields)
问题解决。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









