







上一篇我们介绍了索引的简介,这回我们看看怎么优化索引以及性能分析
索引优化分析
性能分析:Explain
使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MYSQL是如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈。
能干嘛?
- 表的读取顺序
- 哪些索引可以使用
- 哪些索引被实际使用
- 表之间的引用
- 每张表有多少行被物理查询
怎么玩?
EXPLAIN + SQL 语句
执行计划包含的信息

各个字段解释
id: select查询的序列号,包含一组数字,表示查询中执行select字句或操作表的顺序
id号每个号码,表示一趟独立的查询。一个sql的查询趟数越少越好
- id相同,执行顺序自上向下
- id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
- id相同不同,同时存在

select_type:查询的类型,主要是用于区别
普通查询、联合查询、子查询等的复杂查询

table:显示这一行的数据是关于哪张表的
partitions:代表分区表中的命中情况,非分区表,该项为null
possible_keys:显示可能应用在这张表中的索引,一个或多个。
查询涉及到的字段上若存在索引,则该索引被列出,但不一定被查询实际使用
key:实际使用的索引,如果为null,则没有使用索引
查询中若使用了覆盖索引,则该索引和查询的select字段重叠
ref:显示索引的那一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索隐裂上的值
filtered:这个字段表示存储引擎返回的数据再server层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比。
rows:rows列表示MYSQL认为它执行查询时必须查询的行数。越少越好
key_len:表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。
key_len字段能够帮你检查是否充分的利用上了索引。




尽量避免上图所示中的红色字段!!!
重要字段:id type key_len rows Extra
查询优化
批量数据脚本
1、建表
create table dept(
id int(11) not null auto_increment,
deptName varchar(30) default null,
address varchar(40) default null,
ceo int null,
constraint pk PRIMARY key(id)
)ENGINE=innodb auto_increment=1 default charset=utf8;
create table emp(
id int(11) not null auto_increment,
empno int not null,
name varchar(20) default null,
age int(3) default null,
deptId int(11) default null,
constraint pk PRIMARY key(id)
)engine=innodb auto_increment=1 default charset=utf8;2、设置参数log_bin_trust_function_creators
创建函数,假如报错:This function has none of DETERMINISTIC......
#由于开启过慢查询日志,因为我们开启了bin-log,我们就必须为我们的function指定一个参数。
show variables like 'log_bin_trust_function_creators';
set global log_bin_trust_function_creators=1;
#这样添加了参数以后,如果mysqld重启,上述参数又会小时,永久方法:
windows下my.ini[mysqld] 加上log_bin_trust_function_creators=1
linux 下 /etc/my.cnf 下 my.cnf[mysqld] 加上log_bin_trust_function_creators=1
3、创建函数,保证生成的数据不同
-- 随机生成字符串
delimiter $$
create function rand_string(n int) returns varchar(255)
begin
declare chars_str varchar(100) default
'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i <n do
set return_str = concat(return_str,substring(chars_str,FLOOR(1+RAND()*52),1));
set i = i+1;
end while;
return return_str;
end $$
-- 用于随机产生多少到多少的编号
delimiter $$
create function rand_num(from_num int,to_num int) returns int(11)
begin
declare i int DEFAULT 0;
set i = FLOOR(from_num+RAND()*(to_num-from_num+1));
RETURN i;
end $$4、创建存储过程
## 存储函数-插入emp表数据
delimiter $$
create procedure insert_emp(start int ,max_num int)
begin
declare i int default 0;
# set autocommit=0 把autocommit设置为0
set autocommit=0;
repeat
set i=i+1;
insert into emp(empno,NAME,age,deptid) values((start+i),rand_string(6),
rand_num(30,50),rand_num(1,10000));
until i =max_num
end repeat;
commit;
end $$
## 创建往dept表中插入数据的存储过程
delimiter $$
create procedure insert_dept(max_num int)
begin
declare i int default 0;
set autocommit = 0;
repeat
set i = i +1;
insert into dept(deptname,address,ceo) values(rand_string(8),rand_string(10),rand_num(1,500000));
until i =max_num
end repeat;
commit;
end $$5、执行存储过程,跑数据。
## 执行存储过程,往dept表添加1万条数据
CALL insert_dept(10000);
## 执行存储过程,往emp表添加50万条数据
CALL insert_emp(100000,500000)单表使用索引及常见索引失效
实战演练
1、单值索引
#没建索引
select SQL_NO_CACHE * FROM emp where emp.age = 30; #0.213s

#建索引后
create index idx_age on emp(age);
select SQL_NO_CACHE * FROM emp where emp.age = 30; #0.213s

2、复合索引
#先删除age索引
drop index idx_age on emp;
#没建索引前
explain select SQL_NO_CACHE * from emp where age = 30 and deptId = 4;

#建立索引后
create index idx_age_deptId on emp(age,deptId)
explain select SQL_NO_CACHE * from emp where age = 30 and deptId = 4;

现在测试创建三个字段的复合索引!!!
#先删除之前的索引
drop index idx_age_deptId on emp
explain select SQL_NO_CACHE * from emp where age = 30 and deptId = 4 and name = 'abcd';

#创建索引后
create index idx_age_deptId_name on emp(age,deptId,name)
explain select SQL_NO_CACHE * from emp where age = 30 and deptId = 4 and name = 'abcd';

#我们将where条件的deptID和age换个位置(会发现不影响索引)
explain select SQL_NO_CACHE * from emp where deptId = 4 and age = 30 and name = 'abcd';

会发现不影响索引:原因:mysql解析器会将sql在不影响最终结果的情况下,对sql进行优化操作。
#我们将where条件的deptID去掉(会发现去掉了deptID,只会按最左侧的索引查询 也就是age)
explain select SQL_NO_CACHE * from emp where age = 30 and name = 'abcd';

#我们将where条件的age去掉(会发现组合索引失效了)
explain select SQL_NO_CACHE * from emp where deptId = 4 and name = 'abcd';

接下来我们来探究一下为什么会这样???
复合索引的各个字段是按照层级来分类的。通俗点来讲就是先按age来建立平衡二叉树,等找到对应子节点后会按deptid建立平衡二叉树。。。依次类推。
所以:当age都没有了就不会走deptid的二叉树,没有了deptid但是有age,也就不能走name的二叉树了。。。

总结:如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。
索引失效
1、遵守最左前缀法则,如果不遵守会存在索引失效。案例如上所述。
2、不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
索引列有函数
create index idx_name on emp(name)
explain select SQL_NO_CACHE * from emp where emp.name like 'abc%';
explain select SQL_NO_CACHE * from emp where left(emp.name,3) = 'abc'; #创建索引后会失效
3、存储引擎不能使用索引中范围条件右边的列
create index idx_age_deptId_name on emp(age,deptId,name)
explain select SQL_NO_CACHE * from emp where age=30 and deptId>20 and emp.name= 'abc';
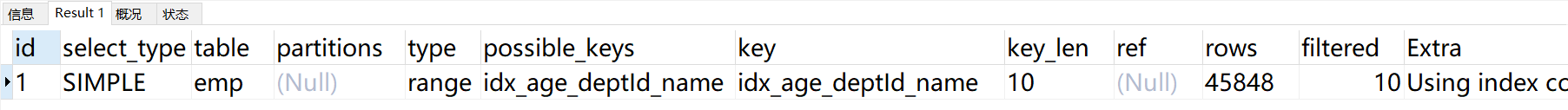
我们换一下name和deptId索引列的顺序。
drop index idx_age_deptId_name on emp
create index idx_age_deptId_name on emp(age,name,deptId)explain select SQL_NO_CACHE * from emp where age=30 and deptId>20 and emp.name= 'abc';
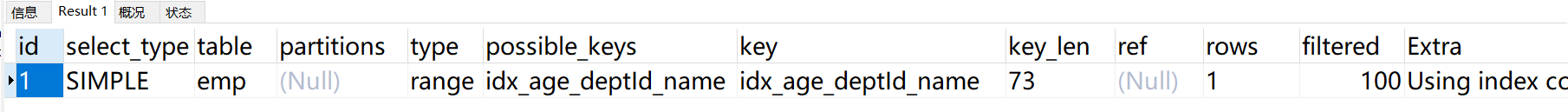
综上可以发现:存储引擎不能使用索引中范围条件右边的列
4、mysql在使用不等于(!= 或者 <>)的时候无法使用索引会导致全表扫描
create index idx_name on emp(name)
explain select SQL_NO_CACHE * from emp where name <>'abc';

5、is not null 也无法使用索引,但是is null 是可以使用索引的
explain select SQL_NO_CACHE * from emp where name is not null;

explain select SQL_NO_CACHE * from emp where name is null;

6.like 以通配符开头('%abc...') mysql索引失效会变成全表扫描

7、字符串不加单引号索引失效

总结:
假设index(a,b,c)

一般性建议
- 对于单键索引,尽量选择针对当前query过滤性更好的索引。
- 在选择组合索引的时候,当前Query中过滤性最好的字段在字段顺序中,位置越靠前越好。
- 在选择组合索引的时候,尽量选择可以能够包含当前query中where字句中更多字段的索引。
- 在选择组合索引的时候,如果某个字段可能出现范围查询时,尽量把这个字段放在索引次序的最后面
- 书写sql语句时,尽量避免造成索引失效的情况。
关联查询优化
建表SQL
create table if not exists `class` (
id int(10) unsigned not null auto_increment,
card int(10) unsigned not null,
primary key(id)
);
create table if not exists book(
bookid int(10) unsigned not null auto_increment,
card int(10) unsigned not null,
primary key(bookid)
);
insert into class(card) values(FLOOR(1+(RAND()*20)));
insert into class(card) values(FLOOR(1+(RAND()*20)));
insert into class(card) values(FLOOR(1+(RAND()*20)));
insert into class(card) values(FLOOR(1+(RAND()*20)));
insert into class(card) values(FLOOR(1+(RAND()*20)));
insert into class(card) values(FLOOR(1+(RAND()*20)));
insert into class(card) values(FLOOR(1+(RAND()*20)));
insert into class(card) values(FLOOR(1+(RAND()*20)));
insert into class(card) values(FLOOR(1+(RAND()*20)));
insert into class(card) values(FLOOR(1+(RAND()*20)));
insert into class(card) values(FLOOR(1+(RAND()*20)));
insert into class(card) values(FLOOR(1+(RAND()*20)));
insert into class(card) values(FLOOR(1+(RAND()*20)));
insert into class(card) values(FLOOR(1+(RAND()*20)));
insert into class(card) values(FLOOR(1+(RAND()*20)));
insert into class(card) values(FLOOR(1+(RAND()*20)));
insert into class(card) values(FLOOR(1+(RAND()*20)));
insert into class(card) values(FLOOR(1+(RAND()*20)));
insert into class(card) values(FLOOR(1+(RAND()*20)));
insert into class(card) values(FLOOR(1+(RAND()*20)));
insert into book(card) values(FLOOR(1+(RAND()*20)));
insert into book(card) values(FLOOR(1+(RAND()*20)));
insert into book(card) values(FLOOR(1+(RAND()*20)));
insert into book(card) values(FLOOR(1+(RAND()*20)));
insert into book(card) values(FLOOR(1+(RAND()*20)));
insert into book(card) values(FLOOR(1+(RAND()*20)));
insert into book(card) values(FLOOR(1+(RAND()*20)));
insert into book(card) values(FLOOR(1+(RAND()*20)));
insert into book(card) values(FLOOR(1+(RAND()*20)));
insert into book(card) values(FLOOR(1+(RAND()*20)));
insert into book(card) values(FLOOR(1+(RAND()*20)));
insert into book(card) values(FLOOR(1+(RAND()*20)));
insert into book(card) values(FLOOR(1+(RAND()*20)));
insert into book(card) values(FLOOR(1+(RAND()*20)));
insert into book(card) values(FLOOR(1+(RAND()*20)));
insert into book(card) values(FLOOR(1+(RAND()*20)));
insert into book(card) values(FLOOR(1+(RAND()*20)));
insert into book(card) values(FLOOR(1+(RAND()*20)));
insert into book(card) values(FLOOR(1+(RAND()*20)));
insert into book(card) values(FLOOR(1+(RAND()*20)));案例
explain select * from class left join book on class.card = book.card;

#给book表添加索引优化
alter table book add index Y(`card`);
explain select * from class left join book on class.card = book.card;

#给class表添加索引优化
alter table class add index X(`card`);
explain select * from class left join book on class.card = book.card;

上述可以发现,class表还是全表扫描,使用了索引但是没有进行过滤。
left join 谁是主表谁就是驱动表,反之则是被驱动表。
换成inner join
#删除book表中的索引
drop index Y on book;
explain select * from class inner join book on class.card = book.card;

上述可发现:inner join 会将有索引的表作为被驱动表。
建议
1、保证被驱动表的join字段已经被索引
2、left join时,选择小表作为驱动表,大表作为被驱动表
3、inner join时,mysql会自己帮你吧小结果集的表选为驱动表。
4、子查询尽量不要放在被驱动表,有可能使用不到索引。
5、能够直接多表关联的尽量直接关联,不用子查询。
子查询优化
尽量不要使用not in 或者 not exists
用left outer join on xxx is null 替代
排序分组优化
去掉using filesort 请注意
- 无过滤不索引
- 顺序错,必排序
- 方向反,必排序
索引的选择
explain select SQL_NO_CACHE * FROM emp where age = 30 and empno <10 order by name;

综合上面内容,这个sql怎么建立索引呢?
mysql 会自己选择最优的索引!!!!
create index idx_age_name on emp(age,name);
create index idx_age_empno on emp(age,empno);


GROUP BY 关键字优化
group by 使用索引的原则几乎跟order by一致,唯一区别是group by 即使没有过滤条件用到索引,也可以直接使用索引。
覆盖索引
什么是覆盖索引?
简单说就是,select 到 from 之间查询的列 <= 使用的索引列 + 主键
驱动与被驱动表测试:mysql leftjoin 大表在外_小表驱动大表_weixin_39634876的博客-CSDN博客















 1878
1878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









