






1. 文章来源
ACM Transactions on Intelligent Systems and Technology
学术论文,已出版
2. 主要贡献
提出了引导截断梯度Shapley(GTG-Shapley)方法来解决这一挑战。它使用梯度更新来重建FL模型以进行SV计算,而不是使用不同组合的FL参与者反复训练。此外,我们设计了一种引导蒙特卡罗采样方法,结合轮内和轮间截断,以进一步减少所需的模型重建和评估次数。通过在不同的现实数据分布设置下进行大量实验,证明了GTG-Shapley可以在显著提高计算效率的同时,对实际Shapley值进行紧密逼近,特别是在非独立同分布设置下。
- 我们提出了一种有效的水平联邦学习的SV近似算法,GTG-Shapley,它通过梯度更新重建FL模型,从而显著降低了FL客户端贡献评估的计算成本。
- 我们进一步提出了一种引导蒙特卡罗采样技术,包括轮内和轮间截断,以进一步提高GTG-Shapley的效率。
- 在各种FL数据设置下进行了大量实验,包括i.i.d.和非i.i.d.数据分布,结果表明,GTG-Shapley不仅显著提高了计算效率,而且与实际的SV相比也达到了高精度。
3. 主要内容
3.1 背景介绍
奖励是基于各自的贡献评估,现有的方法可以分为四类:
- 自我报告[28、32]
- FL参与者的贡献是通过他们对敏感本地数据的自我报告信息来衡量的(例如,数据数量、质量、承诺的计算和通信资源)。
- 个体表现
- 效用博弈
- 基于SV的方法
- 随机抽样蒙特卡罗(MC)估计方法
- 使用组测试加速SV估计[9]
- TMC-Shapley
- 通过梯度Shapley技术进行FL参与者贡献评估[20、25、26]
3.2 引导截断梯度Shapley(GTG-Shapley)
SV近似方法应考虑以下方面:
(1)加速效用评估,
(2)不同FL训练轮次的重要性及其对SV的影响,以及
(3)减少不必要的评估。
目前没有任何一种方法涵盖了所有三个方面。在本文中,提出的GTG-Shapley方法填补了这一差距,并同时提高了效率和准确性。
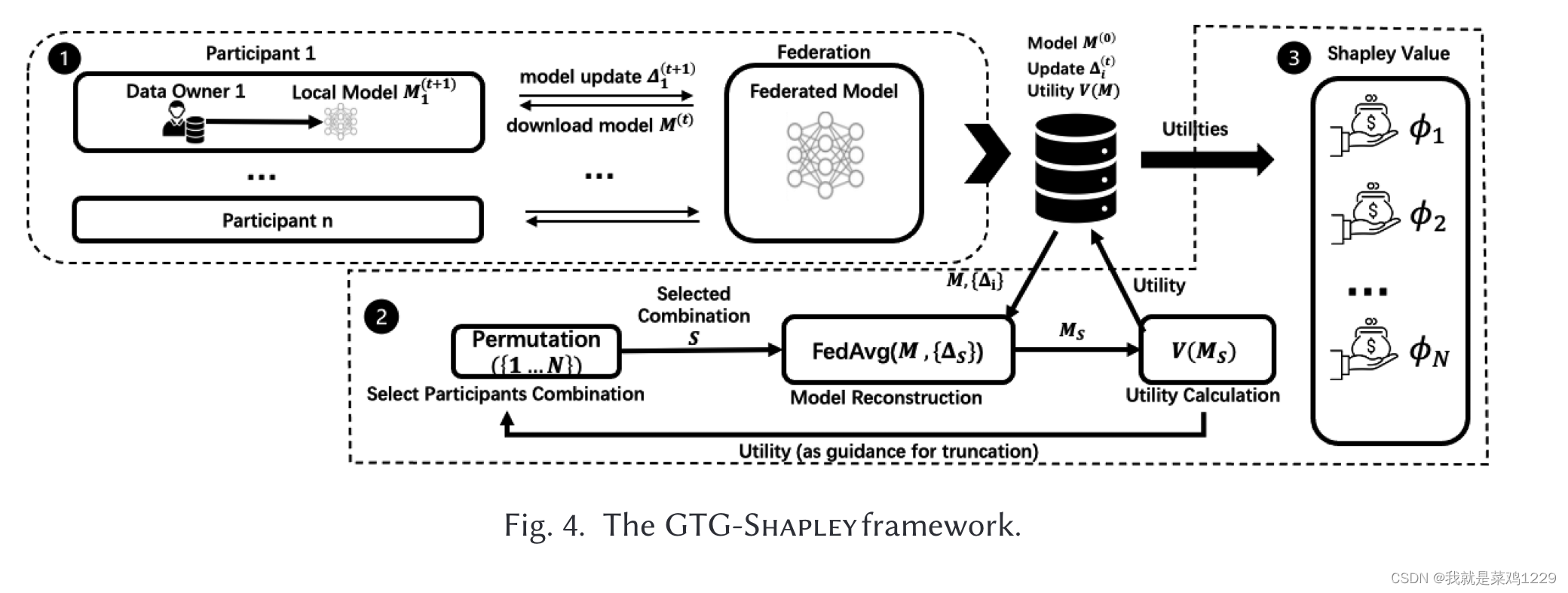
其核心思想是机会性地消除子模型再训练和截断不必要的模型评估,以减少计算成本,同时保持估计SV的准确性。
在GTG-Shapley下,参与者加入一个联邦并像他们在水平FL场景中通常做的那样训练FL模型。然而,在每轮训练期间,FL服务器会存储每个参与者的梯度更新。GTG-Shapley利用这些信息来评估不同FL子模型的性能,这些模型是根据SV估计的不同反事实排列而产生的。在子模型评估期间,GTG-Shapley战略性地生成排列序列以实现快速收敛,根据其预期的边际增益评估评估子模型的必要性,并动态消除那些不重要的子模型。
3.2.1 消除子模型重训练
GTG-Shapley利用梯度更新(Δ)作为数据集的替代来评估FL参与者的贡献。
V
(
S
)
=
V
(
M
S
)
=
V
(
M
+
∑
i
∈
S
∣
D
i
∣
∣
D
S
∣
Δ
i
)
V(S)= V(M_S)= V {(M + \sum_{i \in S}\frac{ |D_i|}{|D_S|}} \Delta_i)
V(S)=V(MS)=V(M+∑i∈S∣DS∣∣Di∣Δi)
这样,当计算SV需要评估S的效用时,子模型MS的重新训练过程被基于先前的梯度更新和当前FL模型的子模型重建过程所替代。因此,应用SV在FL中的主要瓶颈被解决,SV的计算可以完全在FL服务器上执行,从而不会为参与者增加额外的计算成本。
3.2.2 模型评估的引导截断
随着子模型重新训练效率的提高。估计SV所需的大部分时间被模型重建和性能评估步骤所消耗(如图2(a)所示)。对于参数数量庞大的模型和具有大型测试数据集的联邦系统,模型评估严重拖慢了SV的估计速度。
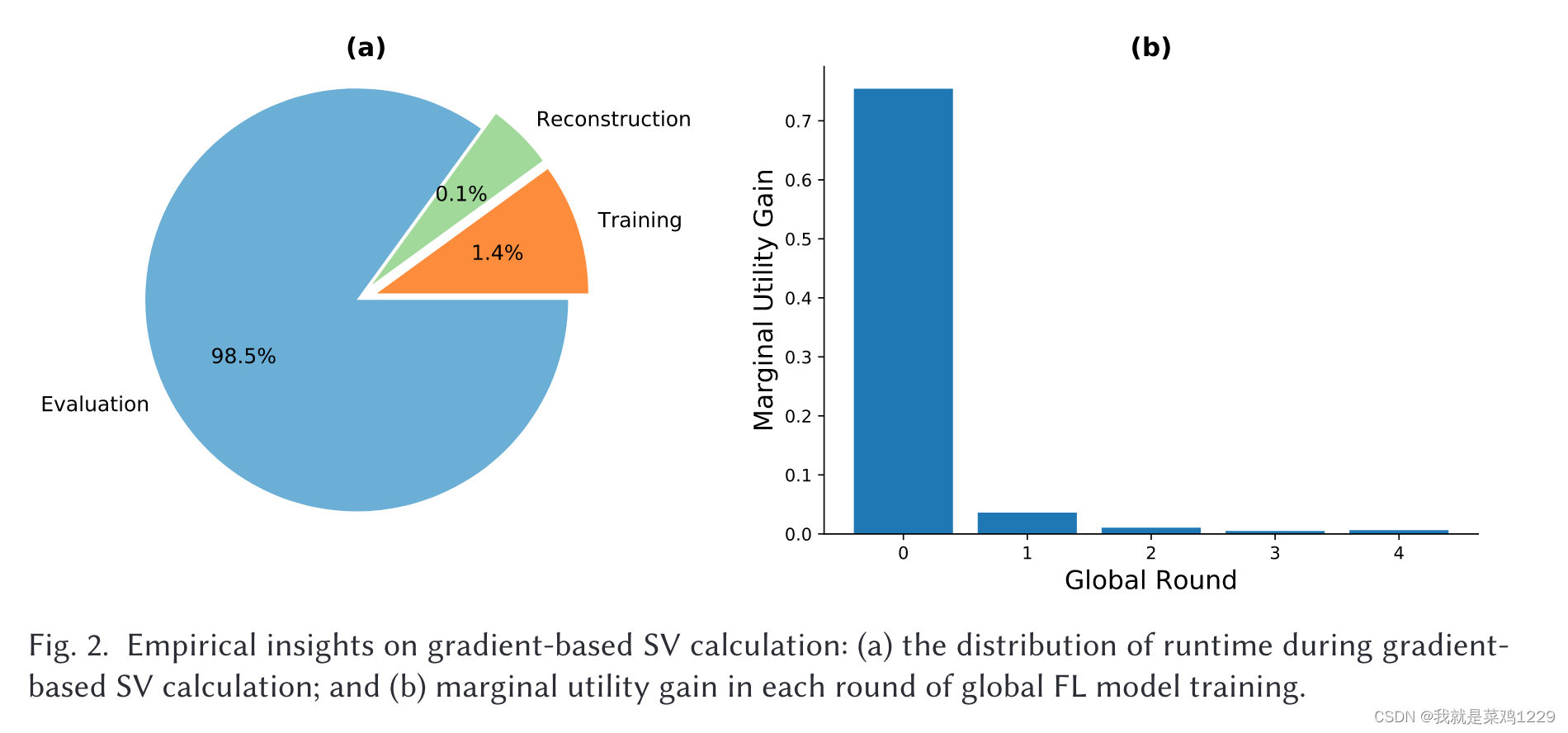
应该想办法减少模型的评估时间。
根据不同轮次之间效用的分布见解(图2(b)),可以根据方程(4)丢弃边际效用收益较低的SV计算轮次,而不会显著影响SV的估计。
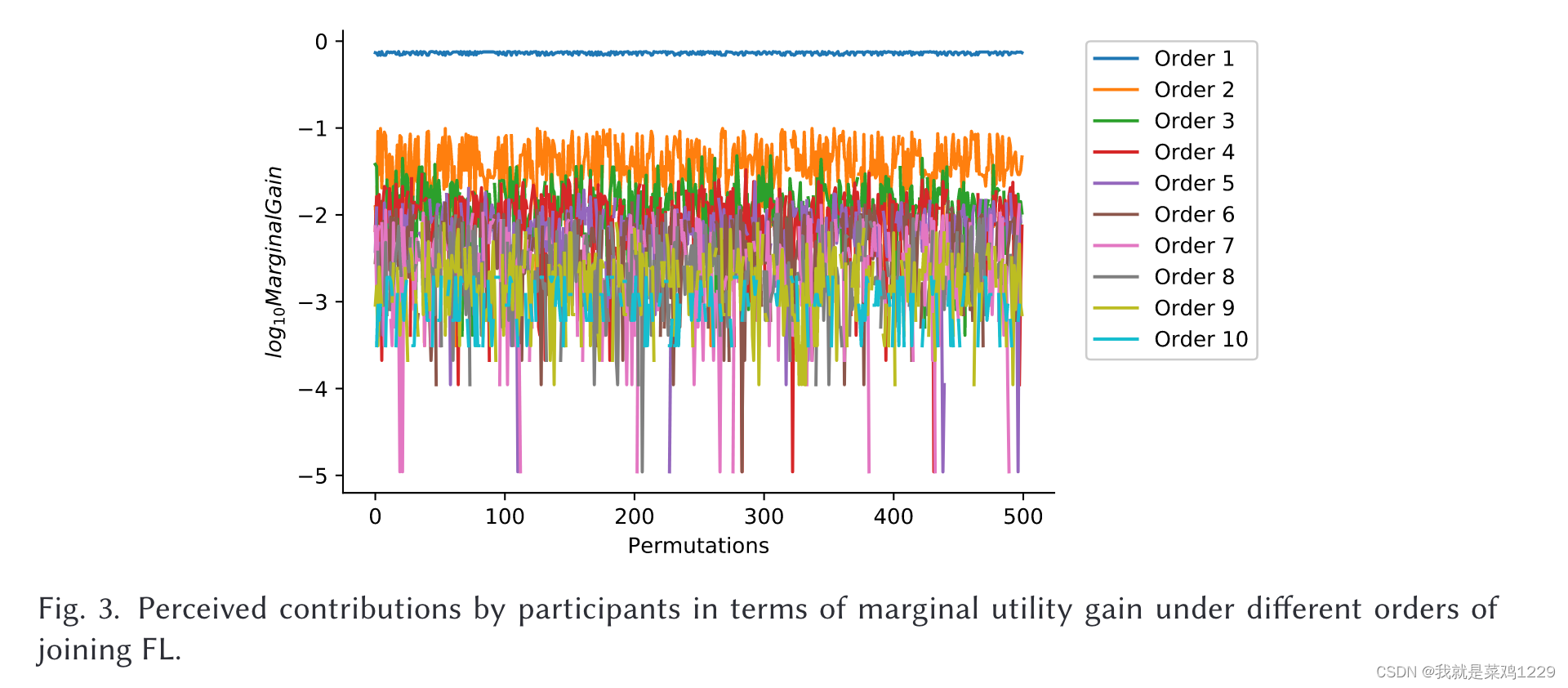
从图3可以看出,在排列中的位置不同时,对于边际的贡献大小差别很大。
所以本文提出了一个引导采样策略,以在多个排列中公平分配FL参与者的不同位置。
3.2.3 GTG-SHAPLEY Algorithm

- 输入
- 上一轮的联邦模型 M ( t ) M^{(t)} M(t)
- 这一轮的联邦模型 M ( t + 1 ) M^{(t+1)} M(t+1)
- 衡量函数 V V V
- 各个参与方的梯度更新 { Δ i , . . . , Δ n } \{\Delta_i,...,\Delta_n\} {Δi,...,Δn}
- 输出
- 第 ( t + 1 ) (t+1) (t+1)轮的夏普利值, ϕ i t + 1 \phi^{t+1}_i ϕit+1
- 过程
- 初始化各方夏普利值为0
- k=0, v 0 v_0 v0的上一轮的模型的表现情况, v N v_N vN是这一轮利用各方梯度更新之后的模型表现
- 轮间截断: 如果最终模型与初始模型的性能提升不超过预定义的阈值εb,则忽略该轮SV计算,并返回所有参与者的贡献为0。
- 循环SV计算: 在满足收敛标准之前,重复以下步骤
- 增加轮数
- 指导采样生成 π k \pi^k πk
- 保存初始评估值到 v 0 k v^k_0 v0k,重点
- 轮内截断
- 对于每个参与者,根据剩余边际增益是否小于预定义的截断阈值εi,决定是否继续评估子模型。
- 构建子模型的参与者集合C,从 π k \pi^k πk中取前j位
- 重建子模型
- 评估子模型的性能 v j k v^k_j vjk
- 根据子模型的性能差异,更新每个参与者的贡献值。
3.2.4 联邦学习参与方的贡献度衡量

- 初始化SVs变量 ϕ i \phi_i ϕi为0,其中i为每个参与者的编号。
- 通过T个轮次进行迭代,其中T是FL训练的总轮次。 对于每个轮次t,
- 首先在客户端运行。 并行地对每个参与者i执行以下操作:
- 参与者i使用当前FL模型M(t)在本地进行更新,生成梯度更新Δ(t+1)i。 在所有参与者完成更新后,
- 进入服务器端运行。 服务器收集所有参与者上传的梯度更新
- 使用FedAvg算法来更新全局FL模型M(t+1)。
- 使用GTG-Shapley方法对当前轮次的FL模型M(t)和更新后的FL模型M(t+1)进行评估,以计算每个参与者的贡献。
- 计算得到的 S V s { ϕ ( t + 1 ) i } SVs \{\phi(t+1)i\} SVs{ϕ(t+1)i}被累加到对应的φi中。
- 迭代完成后,返回每个参与者的贡献 S V s { ϕ 1 , . . . , ϕ n } SVs \{\phi_1,...,\phi_n\} SVs{ϕ1,...,ϕn}。
4. 实验
4.1 数据集
数据集使用的是MNIST数据集。
设计了涉及10个参与者的联邦5个学习场景。
- 相同分布和相同大小:我们随机采样了10,840张图像,并确保所有10个参与者对于每个数字都拥有相同数量的图像(即1,084张)。
- 不同分布和相同大小:每个参与者拥有相同数量的样本。然而,参与者1和2的数据集包含80%的数字’1’和’2’。其余数字均均匀分布在剩余20%的样本中。对其余参与者也采用类似的过程。
- 相同分布和不同大小:我们根据预定义的比例从整个训练集中随机采样,形成每个参与者的本地数据集,同时确保每个参与者对于每个数字都有相同数量的图像。比例为参与者1和2为10%,参与者3和4为15%,参与者5和6为20%,参与者7和8为25%,参与者9和10为30%。
- 噪声标签和相同大小:我们采用了相同分布和不同大小设置中的数据集。然后,我们在每个参与者的本地数据集中翻转预定义百分比的样本标签。设置为参与者1和2为0%,参与者3和4为5%,参与者5和6为10%,参与者7和8为15%,参与者9和10为20%。
- 噪声特征和相同大小:我们采用了相同分布和相同大小设置中的数据集。然后,我们在输入图像中添加不同百分比的高斯噪声。设置为参与者1和2为0%,参与者3和4为5%,参与者5和6为10%,参与者7和8为15%,参与者9和10为20%。
4.2 实验方法
对比方法。我们将GTG-Shapley与以下六种方法进行比较:
- 原始Shapley:该方法遵循原始SV计算的原则,根据方程(3)评估所有参与者的所有可能组合。每个子模型都从数据集重新训练。SV是基于模型性能计算的。
- TMC Shapley:在这种方法中,通过使用FL参与者的本地数据集和初始FL模型,训练FL参与者子集的模型,并执行蒙特卡洛估算来对SV进行随机采样排列和截断不必要的子模型训练和评估。
- GTB组测试:这种方法通过对FL更新的一些子集进行采样,并评估相应的训练子模型的性能。然后,它估计Shapley差异而不是SV。之后,通过解决可行性问题,从Shapley差异中推导出SV。
- MR:在这种方法中,FL参与者子集的模型是根据它们的梯度更新每一轮重建的。每轮中计算每个参与者的SV。参与者的最终SV是所有轮次中该参与者的SV之和。
- Fed-SV:该方法通过基于组测试的估计来近似“联邦Shapley值”如组测试。不同之处在于(1)用于估计Shapley差异的子集性能是在由参与者模型参数重建的子模型上评估的,(2)SV每轮独立估算,然后后续进行汇总。
- TMR:在这种方法中,使用参与者的梯度更新独立计算每一轮的SV,并且有一个衰减参数λ,它既用作放大早期轮次的SV的权重,也用作截断因子来消除不必要的子模型重建。
4.3 实验表现的衡量指标
性能评估指标。对比方法的性能使用以下指标进行评估:
- 时间:计算SV所用的总时间用于评估每种方法的效率。为了以相同的视角展示不同的基线,我们对总经过时间应用log10(·)。
- 余弦距离:我们将由原始Shapley计算的SV结果表示为一个向量 ϕ ∗ = < ϕ ∗ 1 , . . . , ϕ ∗ n > \phi^∗=<\phi^*1,...,\phi^∗n> ϕ∗=<ϕ∗1,...,ϕ∗n>而由任何其他方法计算的估计结果表示为 ϕ = < ϕ 1 , . . . , ϕ n > \phi=<\phi^1,...,\phi^n> ϕ=<ϕ1,...,ϕn>。余弦距离定义为 1 − c o s ( ϕ ∗ , ϕ ) 1−cos(\phi^∗,\phi) 1−cos(ϕ∗,ϕ)。
- 欧氏距离:欧氏距离就是L2范数
- 最大差异:最大差异定义为 m a x i = 1 n ∣ ϕ i ∗ − ϕ i ∣ max^n_{i=1}|\phi^*_i - \phi_i| maxi=1n∣ϕi∗−ϕi∣所有四个指标的值越小,方法的性能就越好。
4.4 实验结果
- 相同分布和相同大小:
- GTG-Shapley明显优于其他方法,效率提高了7.4倍,而在准确性上与MR和TMR相似。
- 不同分布和相同大小:
- GTG-Shapley在效率和准确性方面都表现出色,是最佳选择,而TMC在准确性上与GTG-Shapley接近。
- 相同分布和不同大小:
- GTG-Shapley的效率和准确性仍然优于其他方法,尤其是在准确性上,与实际SV的差距保持在很小范围内。
- 有噪声标签和相同大小:
- GTG-Shapley在效率和准确性方面都优于其他方法,特别是在准确性上,它明显领先于其他基线。
- 有噪声特征和相同大小:
- GTG-Shapley在这种情况下也是最佳选择,表现出显著的效率和准确性优势。
4.5 消融实验
在本节中,我们实验分析了GTG-Shapley的主要组成部分的效果。实验设置与前文的实验评估部分相同。
我们将完整版本的GTG-Shapley与以下GTG-Shapley的变体进行比较:
GTG-Ti:该方法仅包含GTG-Shapley中的在轮内截断组件,省略了GTG-Shapley中的在轮间截断和引导抽样组件。
GTG-Tib:该方法包含GTG-Shapley中的在轮内和在轮间截断组件,但不包含引导抽样组件。
GTG-OTi:该方法用于分析计算SVs的频率的影响。GTG-OTi从一开始累积来自每个FL参与者的梯度,并在FL训练完成后仅执行一次基于梯度的SV估计。在计算SVs时进行在轮内截断。
4.5.1 SV 计算频率的影响
受到 MR 和 OR 不同计算频率设计的启发,我们研究了 SV 计算频率对 GTG-Shapley 在效率和准确性方面的影响。GTG-Ti 和 GTG-OTi 在 SV 计算频率方面基本相同。GTG-Ti 的频率最高(即每一轮),而 GTG-OTi 的频率最低(即总共仅一次)。
4.5.2 轮间截断的影响
专注于比较 GTG-Tid 和 GTG-Ti,以研究轮间截断的影响。两者之间唯一的区别在于 GTG-Tid 包括轮间截断,而 GTG-Ti 则不包括。GTG-Tid 比 GTG-Ti 效率提高了 17%(见图 12),在图 15 中可以高达 3 倍。效率的提升取决于 FL 模型的收敛速度。
4.5.3 导向采样的影响
所提出的导向采样技术的主要目的是通过参与者顺序来提高准确性,这允许不同的参与者在不同的排列抽样中占据重要位置,以减少 SV 估计中可能的偏差。通过导向采样,GTG-Shapley 在所有设置中都实现了最高的准确性,如图 11 至图 15 所示。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









