






1.什么是众包场景
众包是数据交易广泛采用的方式之一,其直接交易原始数据本身。在众包场景下设计激励机制的核心问题之一是如何将任务分配给最合适的参与方以获得高质量的数据。该问题在很大程度上依赖于对参与方可靠性的准确建模。
现有的参与方可靠性建模存在以下两个缺陷:
1)忽略了任务的潜在集群结构,参与方在这些潜在集群上存在更细粒度的可靠性;
2)忽略了对数值任务下参与方可靠性建模研究。
众包是数据交易一种重要的方式,数据需求方可以通过众包从一个相对开放的大群体参与者中获取任务的信息或结果,例如图像标注,情感分析,回答难度较大的数据库查询。
许多众包平台,例如亚马逊机械土耳其(AMT)和CrowdFlower给数据需求方提供方便的接。
- 数据需求方发布不同类型的众包任务。
- 后众包平台会将任务分配给参与方,
- 在收到参与方提供的数据后给他们支付报酬。
- 平台将收集到的数据分析筛选后,将这些任务的最终结果交付给任务请求者。
2.研究的三个要点
- 如何准确估计参与方的可靠性?
- 概率模型
- 认为每个参与方的可靠性是一个常数,并且每个参与方的可靠性在所有任务中是一致的
- 这种假设不符合实际,因为参与方专业技能不同,其在不同任务上往往表现出不同的可靠性
- 混淆矩阵模型
- 假设每个参与方在具有相同答案的任务上表现出一致的可靠性,并模拟参与方在给定真值的情況下提供某个答案的概率
- 潜在领域模型
- 基于任务问题描述将任务分成不同的领域,并假设每个参与方在隶属于同一个领域的一组任务上具有一致的可靠性
- 概率模型
- 如何在线选取合适的任务分配给参与方?
- 循环轮换策略
- QASCA使用概率模型和混淆矩阵模型来建模参与方的可靠性,并依据可靠性计算期望收益,选取期望收益最大的任务分配给每个到达的参与方。
- DOCS根据任务描述将所有任务划分到不同的领域中,然后根据参与方在不同领域的可靠性进行任务分配。
- 如何根据参与方的回答推断任务的真值?
- 对分类任务进行多数表决,对数值任务进行平均/中位数计算(忽略了参与方可靠性的差异)
- 基于可靠性的真值推断方法,通过期望最大化策略来估计参与方的可靠性并推断任务的真值。即可靠性更高的参与方提供的答案质量更高。
3.系统概述
3.1 问题描述
该工作描述一个典型的众包系统,它由三部分组成:任务请求者、众包平台和动态的参与方集合。任务请求者在平台上发布任务,平台将这些任务分配给参与方,并在收到参与方的回答后进行真值推断,然后将最终结果发送给任务请求者。
- W = { w 1 , w 2 , . . . , w M } W=\{w_1,w_2,...,w_M\} W={w1,w2,...,wM}表示M个参与方集合
- 每个参与方 w ∈ W w\in W w∈W在时间窗口内随机到达平台,且每个参与方具有一个容量 w . τ w.\tau w.τ(可以完成的最大任务数)
- 该工作专注于数值任务并考虑两种类型的任务
- N N N个目标任务 T = { t 1 , t 2 , . . . , t N } T=\{t_1,t_2,...,t_N\} T={t1,t2,...,tN}由请求者发布,目标任务的真值是未知量,使用 d ^ t \hat{d}_t d^t来表示每个任务 t ∈ T t\in T t∈T的估计真值
- N ∗ N^* N∗个黄金任务 T ∗ = { t 1 ∗ , t 2 ∗ , . . . , t N ∗ } T^*=\{t^*_1,t^*_2,...,t^*_N\} T∗={t1∗,t2∗,...,tN∗},平台指导每个黄金任务 t ∗ ∈ T ∗ t^*\in T^* t∗∈T∗的真值 d t ∗ d_{t^*} dt∗
- N N N通常远大于 N ∗ N* N∗
- 目标是在面对粗粒度的任务描述和一些不诚实的参与方时,选取对最终数据质量增益最高的数值任务集合分配给到达的参与方并将最终推断真值发送给任务需求者

3.2 设计概览
为了实现上述目标,该工作将整个问题分为以下三个子问题:
- 参与方主题级可靠性估计
- 估计参与方的可靠性(即专业知识和诚实度)是准确推断真值和最优任务分配的基石
- 当参与方 w w w第一次到达平台时,类似于现有的工作,平台为他/她分配一组黄金任务。平台通过参与方 w w w的回答与黄金任务的真值之间的误差初始化 w w w的可靠性。考虑到任务之间存在潜在集群,即任务属于一些潜在主题,为了实现更细粒度的可靠性,平台应该挖掘数值任务的潜在主题集合 L \mathcal{L} L,然后估计每个参与方 w w w在每个主题 k ∈ L k \in \mathcal{L} k∈L的可靠性 σ w , k 2 \sigma^2_{w,k} σw,k2
- 在线任务分配
- 给定参与方的主题级可靠性和平台中任务的信息,平台需要选取合适的任务集合分配给每个到达的参与方 w w w,从而提高收集数据的质量
- 真值推断
- 给定参与方的主题级可靠性和目标任务的答案集 A \mathcal{A} A,平台需要估计每个任务 t t t的真值 d ^ t \hat{d}_t d^t以及该任务的潜在主题分布。
- 同时,平台将计算参与方回答与估计出的真值 d ^ t \hat{d}_t d^t的偏差,并根据偏差动态地调整参与方的可靠性,偏差越小,可靠性增加越多,从而激励更多的参与方贡献准确地数据。
3.3 工作流程设计
- 三大模块
- 高斯潜在主题估计模块(GLTE)
- 真值推断模块(TI)
- 在线任务分配模块(OTA)
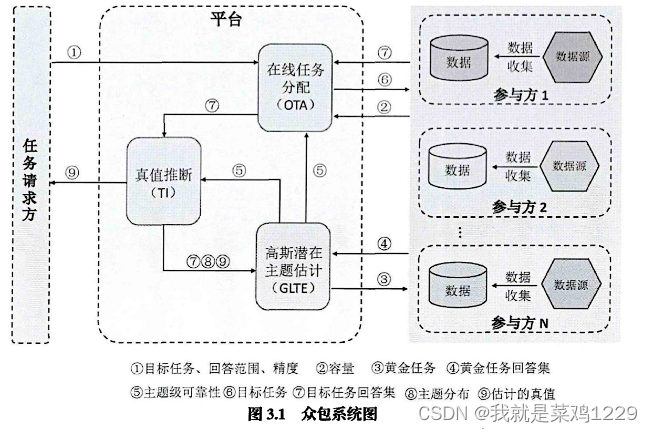
- 步骤(1)
- 每个任务请求者在平台上发布具有相同文本描述的数值任务,并且将数值任务的回答范围和可接受的精度一并发送到平台上。
- 步骤(2)-(5)
- 当参与方 w w w加入平台时,声明其容量 w . τ w.\tau w.τ,即其在一个时间窗口内可以执行的最大任务数,然后等待任务分配。
- GLTE模块将一小部分黄金任务分配给所有第一次达到的参与方并收集他们的答案。
- GLET模块将计算收集到的答案与真值之间的偏差,并根据偏差将任务划分为不同的潜在主题,而后初始化每个参与方 w w w的主题级可靠性 σ w , k 2 \sigma^2_{w,k} σw,k2并将其发送给OTA模块和TI模块。
- 在收到OTA模块发送回的目标任务答案和TI模块发送回的估计的目标任务真值和主题分布后,GLTE模块将动态更新每个参与方的主题级可靠性,然后将更新后的可靠性发送给OTA模块和TI模块。
- 步骤(6)-(7)
- OTA模块收集所有任务的答案集。对于每个参与方 w w w,OTA采用两种在线任务分配算法MRA-GLTM或MRAPC-GLTM来决定任务分配。
- MRA-GLTM中,该工作利用熵来衡量每个任务当前真值分布的模糊性,计算每个任务若分配给参与方后熵的减少情况,以最大化熵减少的原则选取任务分配给参与方。
- MRAPC-GLTM中,OTA模块首先基于MRA-GLTM分配任务给参与方。然后它计算每个任务若分配给参与方后潜在贡献情况,并以最大化贡献的原则选取任务分配给参与方。
- 步骤(8)-(9)
- 在获得目标任务的回答和参与方主题及可靠性后,TI模块估计目标任务的主题分布并进行真值推断。
- 考虑到一些参与方可能不诚实以及参与方可靠性的变化,TI模块将估计的真值和任务的主题分布发送给GLTE模块以更新参与方的可靠性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









