






【MIT6.S081/6.828】手把手教你搭建开发环境-电子芯吧客(www.icxbk.com)
MIT6.s081 环境搭建 - silly19 - 博客园 (cnblogs.com)
配置环境
参考这两篇先把虚拟机环境搭建好了
然后看了第一章的xv6 book别人翻译的中文版,参考
FrankZn/xv6-riscv-book-Chinese (github.com)
看完之后尝试调试代码
主要参考[mit6.s081] 笔记 Lab1: Unix utilities | Unix 实用工具 - 掘金 (juejin.cn)
28天速通MIT 6.S081操作系统公开课 - 总结帖 - 知乎 (zhihu.com)
MIT6.s081 环境搭建 - silly19 - 博客园 (cnblogs.com)
SLEEP
我是在user里面添加了sleep.c文件
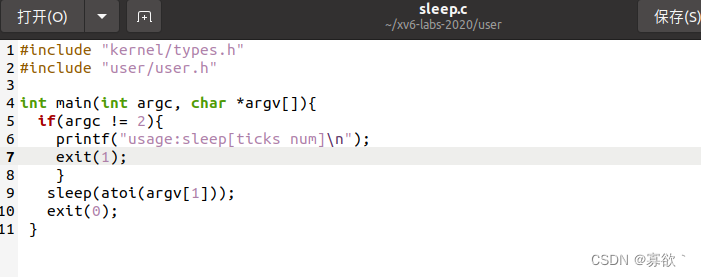
再Makefile像这样加了一句
再直接用文件对sleep进行测试 输入命令 ./grade-lab-util sleep

测试成功
PINGPONG
下载了vscode
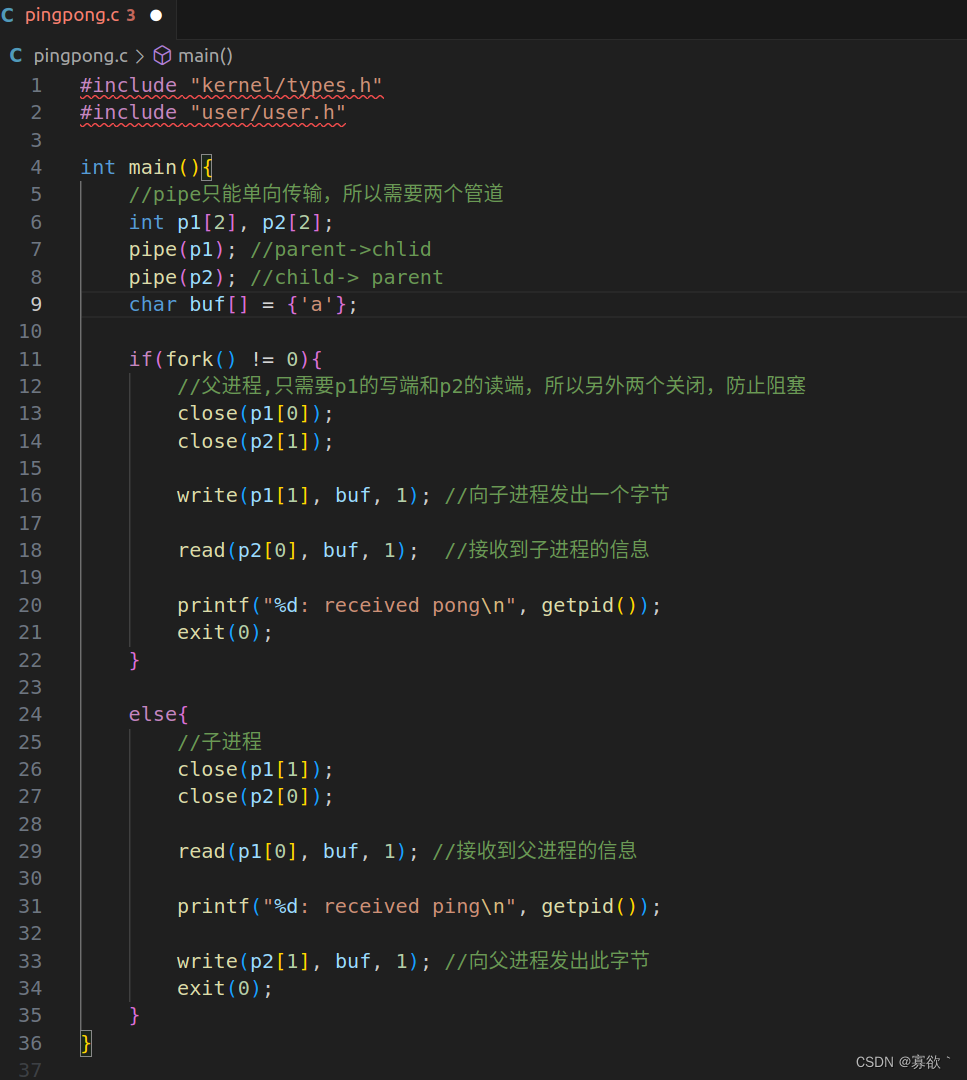
编写一个程序,使用 UNIX 系统调用在两个进程之间通过一对管道 "ping-pong "一个字节,每个方向一个管道。父进程应向子进程发送一个字节;子进程应打印"<pid>: received ping"(<pid>是其进程 ID),将管道上的字节写给父进程,然后退出;父进程应从子进程读取字节,打印"<pid>: received pong",然后退出。
因为开好管道之后,再fork,此时父子进程都有开好的管道,比较方便
read(文件描述符,内容,字节) 第二个参数是const void * buf,参数所指的内存地址

PRIMES
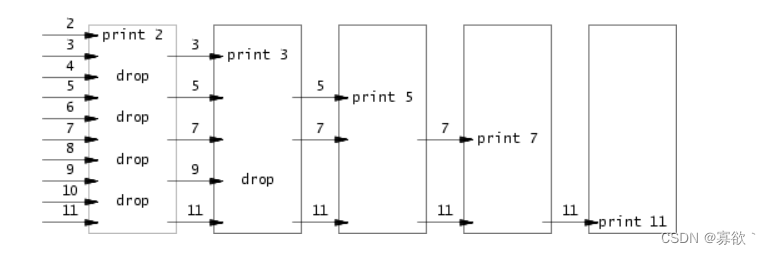
使用管道编写并发版本的质筛。
目标是使用管道和 fork 来建立管道。第一个进程将数字 2 到 35 送入管道。对于每一个质数,你将安排创建一个进程,通过管道从左邻右舍读取数据,并通过另一个管道向右邻右舍写入数据。由于 xv6 的文件描述符和进程数量有限,第一个进程可以在 35 处停止。
注意关闭进程不需要的文件描述符,否则程序会在第一个进程运行到 35 之前耗尽 xv6 的资源。
注意:一旦第一个进程运行到 35,它就应该等待整个流水线(包括所有子进程、孙进程等)结束。因此,主 primes 进程只有在打印完所有输出并退出所有其他 primes 进程后才能退出。
提示:当管道的写入端关闭时,read 返回 0。
最简单的方法是直接将 32 位(4 字节)的 int 写入管道,而不是使用格式化的 ASCII I/O。
用到了递归,数据读完了就跳出来。方法是从2开始,删除所有该数的倍数,删完之后向后传递剩下的数,递归。最后传递过去的就全是质数。

[MIT 6.S081] Lab 1: Xv6 and Unix utilities_mit 6.s081 lab1代码-CSDN博客
看了好久看不懂,只有这篇比较能看懂,直接抄的。
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/fs.h"
void find(char *dir, char *file) {
char buf[512] = {0}, *p;
int fd;
struct dirent de;
struct stat st;
// 打开目录
if ((fd = open(dir, 0)) < 0) {
fprintf(2, "find: cannot open %s\n", dir); //打不开目录
return;
}
// 判断路径长度
if (strlen(dir) + 1 + DIRSIZ + 1 > sizeof(buf)) {
fprintf(2, "find: path too long\n");
close(fd);
return;
}
strcpy(buf, dir);
p = buf + strlen(buf); //指针移到最后
*p++ = '/'; //加上/
// 遍历目录下文档
while (read(fd, &de, sizeof(de)) == sizeof(de)) { //用于从文件描述符 fd 所代表的文件中读取目录项(directory entry)。
//每次循环中,程序尝试读取一个目录项的数据,并将其存储在 de 变量中。返回读取的字节数等于目录项的大小,那么这个条件表达式的值就是 true,
// 跳过当前目录和上级目录
if (de.inum == 0 || strcmp(de.name, ".") == 0 || strcmp(de.name, "..") == 0) { //=0表示目录为空
continue;
}
// 得到完整路径,并添加字符串结束符
memmove(p, de.name, DIRSIZ);
p[DIRSIZ] = 0;
// 获取当前文档的状态
if (stat(buf, &st) < 0) {
fprintf(2, "find: cannot stat %s\n", buf);
continue;
}
// 是目录则递归遍历
if (st.type == T_DIR) {
find(buf, file);
} else if (strcmp(de.name, file) == 0) { //是文件则进行比较, 若与查找一致则输出
printf("%s\n", buf);
}
}
close(fd);
return;
}
int main(int argc, char *argv[]) {
struct stat st;
if (argc != 3) {
fprintf(2, "Usage: find dir file\n");//参数应为3个
exit(1);
}
// 获取查找目录的状态并判断是否为目录
if (stat(argv[1], &st) < 0) {
fprintf(2, "find: cannot stat %s\n", argv[1]);
exit(2);
}
if (st.type != T_DIR) {
fprintf(2, "find: '%s' is not a directory\n", argv[1]);
exit(3);
}
find(argv[1], argv[2]);
exit(0);
}

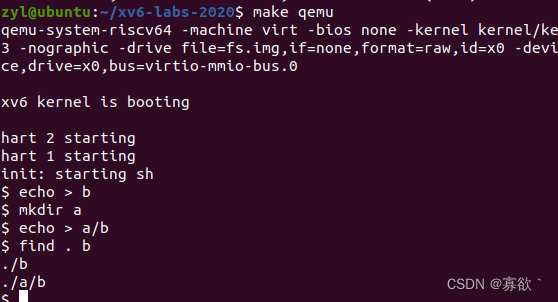
FIND
编写一个简单版本的 UNIX 查找程序:查找目录树中带有特定名称的所有文件。你的解决方案应放在 user/find.c 文件中。
还是参考上篇,写的真好,很清晰!
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/fs.h"
void find(char *dir, char *file) {
char buf[512] = {0}, *p; //buf存放目录字符串,p是指针
int fd;
struct dirent de;
struct stat st;
// 打开目录
if ((fd = open(dir, 0)) < 0) {
fprintf(2, "find: cannot open %s\n", dir); //打不开目录
return;
}
// 判断路径长度
if (strlen(dir) + 1 + DIRSIZ + 1 > sizeof(buf)) {
fprintf(2, "find: path too long\n");
close(fd);
return;
}
strcpy(buf, dir);
p = buf + strlen(buf); //指针移到最后
*p++ = '/'; //加上/
// 遍历目录下文档
while (read(fd, &de, sizeof(de)) == sizeof(de)) { //用于从文件描述符 fd 所代表的文件中读取目录项(directory entry)。
//每次循环中,程序尝试读取一个目录项的数据,并将其存储在 de 变量中。返回读取的字节数等于目录项的大小,那么这个条件表达式的值就是 true,
// 跳过当前目录和上级目录
if (de.inum == 0 || strcmp(de.name, ".") == 0 || strcmp(de.name, "..") == 0) { //=0表示目录为空
continue;
}
// 得到完整路径,并添加字符串结束符
memmove(p, de.name, DIRSIZ);
p[DIRSIZ] = 0;
// 获取当前文档的状态
if (stat(buf, &st) < 0) {
fprintf(2, "find: cannot stat %s\n", buf);
continue;
}
// 是目录则递归遍历
if (st.type == T_DIR) {
find(buf, file);
} else if (strcmp(de.name, file) == 0) { //是文件则进行比较, 若与查找一致则输出
printf("%s\n", buf);
}
}
close(fd);
return;
}
int main(int argc, char *argv[]) {
struct stat st;
if (argc != 3) {
fprintf(2, "Usage: find dir file\n");//参数应为3个
exit(1);
}
// 获取查找目录的状态并判断是否为目录
if (stat(argv[1], &st) < 0) {
fprintf(2, "find: cannot stat %s\n", argv[1]);
exit(2);
}
if (st.type != T_DIR) {
fprintf(2, "find: '%s' is not a directory\n", argv[1]);
exit(3);
}
find(argv[1], argv[2]);
exit(0);
}
XARGS
编写一个简单版本的 UNIX xargs 程序:从标准输入中读取行,并为每一行运行一个命令,同时将该行作为参数提供给命令。
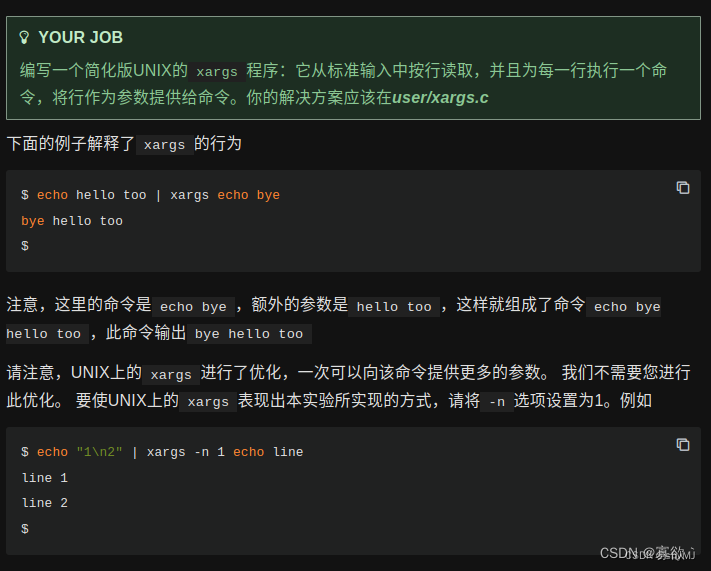
是这个意思,echo指令 管道输入 hello、too, 管道输出xargs(执行) echo bye。
首先echo 参数是bye,管道内的参数也输入进来,这一行的参数就是 bye、hello、too
这是我找到最简短的代码,在读取输入时不根据空格将参数进行划分, 直接作为 1 个参数
#include "kernel/types.h"
#include "user/user.h"
#include "kernel/param.h"
int main(int argc, char *argv[]){
char *p[MAXARG];
int i;
for(i=1; i < argc; i++)
p[i-1] = argv[i];//把argv参数都放进p,p是参数列表
p[argc-1] = malloc(512);//在最后一个参数后面分配空间
p[argc] = 0;//在空间后面+0,表示结束
while(gets(p[argc-1],512)){ //如果有管道,传递的参数也加入列表,gets函数一次读取一行,
// if(p[argc-1][0] == 0)break; //已读完
if(p[argc-1][strlen(p[argc-1])-1]=='\n'){//是最后一个字符
p[argc-1][strlen(p[argc-1])-1] = 0;//换成字符串结束符
} //该函数会将末尾换行保留,故需去掉换行符
if(fork()==0)
exec(argv[1],p); //argv[1]是echo
else
wait(0);
}
exit(0);
}
MIT 6.s081 实验解析——labs1_mit6.s081怎么编译代码-CSDN博客 是这位的!
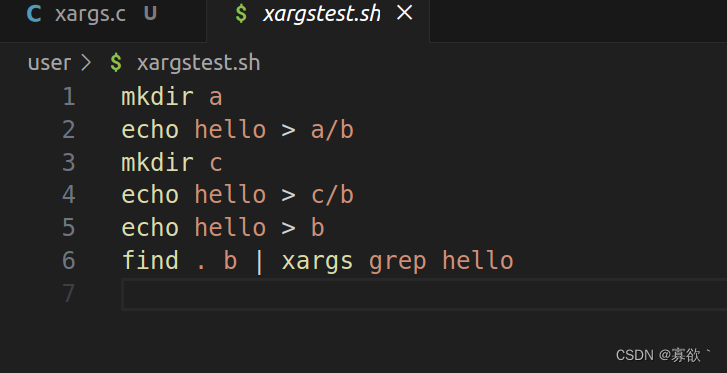
要测试您的 xargs 解决方案,请运行 shell 脚本 xargstest.sh。如果输出结果如下,则您的解决方案是正确的:
$ make qemu ... init: starting sh $ sh < xargstest.sh $ $ $ $ $ $ hello hello hello $ $
这里测试也是对了
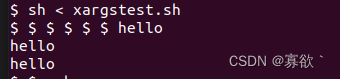 输出中有很多 $,这是因为 xv6 shell 没有意识到它是在处理来自文件而不是控制台的命令,因此会为文件中的每条命令打印一个 $。
输出中有很多 $,这是因为 xv6 shell 没有意识到它是在处理来自文件而不是控制台的命令,因此会为文件中的每条命令打印一个 $。
清理文件系统,用文件夹下用make clean,之后重新make、make qemu


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









