






1.环境搭建
# --------------------------------dos命令--------------------------------------
1.启动/停止服务
命令提示符-->以管理员权限运行
(服务名字,以计算机--->管理--->服务--->mysql*** 为准)
net satrt mysql
net stop mysql
2.查看mysql版本
mysql --version
3.连接数据库
mysql -h localhost -P 3306 -u root -p
mysql 主机 ip 端口 端口号 用户 用户名 密码
2.数据库操作
# 显示当前连接下的所有数据库
show databases;
# 选择数据库来使用
use empty;
# 查看当前使用的数据库
select database();
# 创建一个数据库
create database first1;
# 删除一个数据库
drop database first1;
练习用表
create empty1;
use empty1;
create table Naruto(
n_id int primary key,
n_name varchar(20),
n_title varchar(30),
d_time date
);
insert into Naruto values(1,"千手柱间","忍者之神","2050-05-04"),
(2,"千手扉间",null,"2060-05-04"),(3,"猿飞佐助","忍界博士","2090-05-04"),
(4,"波风水门","黄色闪光","2060-05-04"),(5,"千手纲手","蛞蝓公主","2180-05-04"),
(6,"旗木卡卡西","拷贝忍者","2150-05-04"),(7,"漩涡鸣人",null,"2250-05-04");
insert into naruto values(8,"猿飞木叶丸",null,"2310-05-04");
insert into naruto values(9,"漩涡博人",null,"2380-05-04");

# constraint `约束名` foreign key(`字段名`) references `table`(`column`)
create table skills(
`sk_id` int ,
`ninjutsu` int,
`body_art` int,
`magic` int,
`magic_arts` int,
constraint `refer_naruto` foreign key(`sk_id`) REFERENCES `Naruto`(`n_id`)
);
# 查看已有的约束名字,Key name就是约束名
show index in skills;
# ninjutsu【忍术】--body_art【体术】--magic【幻术】--magic_arts【仙术】
insert into skills values(1,99,99,null,99),(2,99,89,78,56),
(3,87,68,78,48),(4,92,87,63,79),(5,85,91,null,51),
(6,83,83,92,45),(7,86,93,23,92);

3.表的操作
# 1.查看数据下的表
show tables;
show tables from empty;
# 2.查看表结构
desc course;
# 3.改表名
alter table skills rename to skill;
# 4.创建表
int 4个字节
bigint 8个字节
char 固定字符串
varchar 可变字符串
date YYYY-MM-DD
time HH:mm:ss
# 5.删除表
drop table skills;
# drop无法rollback,delete可以
4.字段的操作
# 1.增加字段
alter table skills add `bigskill` varchar(20);
# 2.修改字段名
alter table skills change `bigskill` `big_skill` varchar(30);
# 3.删除字段名
alter table skills drop big_skill;
5.记录的操作
# 1.增加记录(字段和值一一对应)
# a.插入一整行数据;
insert into naruto values(8,"猿飞木叶丸",null,"2300-05-04");
# b.按特定字段插入一行数据;
insert into naruto(n_id,n_name) values(9,"漩涡博人");
# c.插入多行数据;
insert into tablename values(....),(....),(...);
# 2.删除记录
delete from naruto where n_id=8;
6.约束
# 约束 ?
# 外键必须在主键的范围内,否则会报错
insert into skills values(8,80,70,60,30);
primary key #主键
foreign key #外键
not null #非空
unique #唯一
default #默认值
auto_increment #自增
7.条件查询
# 条件查询 ?
# 1.查询整个表
select * from skills;
# 2.查询某个字段
select sk_id as "火影编号",ninjutsu as "忍术评分" from skills;
# 3.关系运算和逻辑运算
# 关系:> < = != >= <=
# 逻辑:not and or
select * from skills where ninjutsu>80 and magic_arts>50;
# 4.在某个区间(全闭区间)
select * from skills where ninjutsu between 80 and 100;
# 5.in的用法(任选一个匹配即可)
select * from skills where ninjutsu in(99,92,90);
# 6.distinct去掉重复的记录
# a.两个字段都重复才会去掉
select distinct ninjutsu,sk_id from skills;
# b.返回不重复字段的条数
select count(distinct sk_id) from skills;
8.其他查询
# 1.模糊查询
# 通配符"_"匹配一个字符 通配符"%"匹配多个字符
select * from naruto where n_name like "千手__";
select * from naruto where d_time like "20%";
# 2.空值查询
select * from naruto where n_title is null;
select * from naruto where n_title is not null;
# 3.排序显示
# descending 降序
# ascending 升序
select * from naruto order by n_id desc;
select * from skills order by ninjutsu asc;
# 4.聚合函数
count()、max()、min()、sum()、avg()
select
count(sk_id) as "火影数量",max(ninjutsu) as "忍术最高",
min(ninjutsu) as "忍术最低",avg(ninjutsu) as "忍术平均"
from skills;
9.分组查询
# 1.分组查询 ?
# where是针对【记录】的过滤,having是针对【组】的过滤
# 一旦分组,select后面只出现分组字段和聚合函数
select sk_id as "火影编号",max(ninjutsu) as "忍术最高分" from skills
where ninjutsu>=80 group by sk_id ;
# 2.记录的显示 ?
# limit 0,3 第一行编号为0,显示包括第一行之后的三行
select * from skills where magic_arts<=60 limit 0,3;
# 3.编写顺序 ?
select * from table where 字段 group by 字段 having 字段 order by 字段
# 4.执行顺序 ?
from 有积运算先算
join 确定积运算类型
on 积运算的过滤条件
where 对分组之前表的过滤
group by 分组
having 分组之后再进行过滤
select 选择字段
distinct 去掉重复的行
order by 按字段来排序
limit 限制输出的行数
10.数据更新
#update 表名 set 表达式 条件;
update skills set ninjutsu=ninjutsu-1000 where sk_id=6;
update skills set ninjutsu=ninjutsu+1000 where sk_id=6;
11.嵌套查询
# 忍术和体术都大于80的火影编号、名字、称号 ?
select sk_id from skills where ninjutsu>=80 and magic_arts>=60;# (1,4,7)
select n_id,n_name,n_title from naruto where n_id in(1,4,7);# 查询对应编号的姓名
# 合并
select n_id,n_name,n_title from naruto where n_id in(
select sk_id from skills where ninjutsu>=80 and magic_arts>=60
);
12.积运算


内连接:B
全外连接:A+B+C
左外连接:A+B
右外连接:B+C
select * from table1 inner join table2 on table1.key=table2.key; -- 内连接
select * from table1 left join table2 on table1.key=table2.key; -- 完整展示table1
select * from table1 right join table2 on table1.key=table2.key; -- 完整展示table2
select * from table1 left join table2 on table1.key=table2.key
union
select * from table2 left join table1 on table1.key=table2.key; -- 全外连接
select * from naruto left join skills on naruto.n_id=skills.sk_id;

13.函数
字符串函数
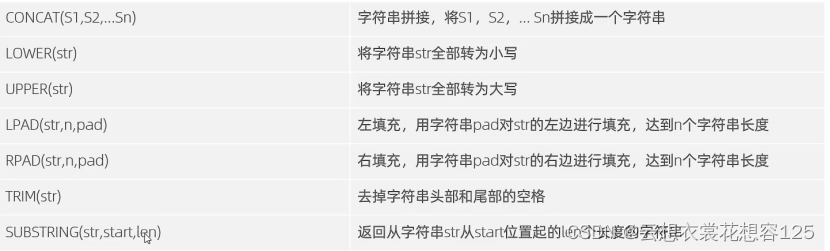
数值函数

日期函数

select date_add(now(),interval 10 day);
select date_add(now(),interval 10 month);
select date_add(now(),interval 10 year);
流程控制函数

select if(false,'成功','失败');
/*失败*/
select if(true,'成功','失败');
/*成功*/
select ifnull('Null','default');
/*Null*/
select ifnull(Null,'default');
/*default*/
select sk_id,
case when ninjutsu >= 95 then '忍术之神' when ninjutsu >= 90 then '忍术熟练' else '忍术菜鸟' end
from empty1.skills;
14.linux下的部署
# Linux centOS6.4 操作系统
# 1.下载安装用的Yum Repository
# wget是下载文件的工具
[root@localhost ~] wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm
# 2.yum安装--->安装MySQL服务器
[root@localhost ~] yum -y install mysql57-community-release-el7-10.noarch.rpm
[root@localhost ~] yum -y install mysql-community-server
# 3.启动MySQL
[root@localhost ~] systemctl start mysqld.service
# 4.查看MySQL运行状态
[root@localhost ~] systemctl status mysqld.service
# 5.找出root用户的密码
[root@localhost ~] grep "password" /var/log/mysqld.log
# 6.进入数据库
[root@locDalhost ~] mysql -u root -p
# 输入初始密码,此时不能做任何事情,因为MySQL默认必须修改密码之后才能操作数据库
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'new password';
1.网址:https://dev.mysql.com/downloads/repo/yum/

14.索引
"目的" 对复杂的查询操作语句进行优化,数据量越大,效果越好,"加速查找"
索引分类
1.普通索引index: 加速查找
2.唯一索引
主键索引:primary key :加速查找 + 约束(不为空且唯一)
唯一索引:unique:加速查找 + 约束 (唯一)
3.联合索引
-primary key(id,name):联合主键索引
-unique(id,name):联合唯一索引
-index(id,name):联合普通索引
4.全文索引fulltext
用于搜索很长一篇文章的时候,效果最好。
5.空间索引spatial
了解就好,几乎不用
1.创建索引
a.建表时创建
create table s1(
id int,
#id int index "不可以这样加索引"
name char(20),
age int,
email varchar(30)
#primary key(id) "可以在这加"
index(id) # "可以这样加"
);
b.建表后创建
create index name on s1(name); # 普通索引
create unique age on s1(age);# 唯一索引
alter table s1 add primary key(id); # 主键索引,并增加主键约束
create index name on s1(id,name); # 添加普通联合索引
2.删除索引
drop index id on s1;
drop index name on s1;# 删除普通索引
drop index age on s1; # 删除唯一索引
alter table s1 drop primary key; # 删除主键
写语句时需要注意的点
1."最左前缀匹配原则":按照从左到右的顺序匹配
create index ix_name_email on s1(name,email)
select * from s1 where name='egon'; # √
select * from s1 where name='egon' and email='asdf'; # √
select * from s1 where email='alex@oldboy.com'; # ×
mysql会一直向右匹配直到遇到范围查询(> < between like)就停止匹配,
比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,
d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2."="和"in"可以乱序
比如 a=1 and b=2 and c=3 建立(a,b,c)索引可以任意顺序
3.尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),
表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、
性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,
这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录
#4.索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’
就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,
但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。
所以语句应该写成create_time = unix_timestamp(’2014-05-29’);














 1998
1998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









