







1、引言
Redis是一个开源、高性能、内存键值存储系统,同时也提供了数据结构服务器的功能。它支持五种主要的数据类型:字符串(String)、哈希表(Hashes)、列表(Lists)、集合(Sets)和有序集合(Sorted Sets)。Redis因其数据全部存放在内存中,读写速度极快,特别适用于高并发场景下的缓存服务、实时排行榜、消息队列等应用场景。
Redis还具有持久化功能,可以将数据异步或同步地保存到磁盘,以确保在服务器重启后数据不丢失。同时,Redis支持多种客户端语言,如Java、Python、Node.js等,并且可以通过主从复制、哨兵模式、集群等方式实现高可用性和水平扩展。
1.1、主从复制的重要性及其在Redis中的角色
主从复制是Redis提供的一种数据备份与恢复机制,同时也是构建分布式系统的基石。在主从复制体系中,一个节点作为主节点(Master),其他节点则作为从节点(Slave)。主节点接收所有的写请求并执行,然后将写操作日志通过网络发送给从节点。从节点接收到这些日志后,会执行相同的命令,从而保证主从节点之间的数据一致性。
主从复制的重要性体现在以下几个方面:
- 数据冗余与备份:多个从节点可以保留主节点的完整数据副本,用于数据恢复或者故障转移。读写分离:主节点负责处理写请求,从节点负责处理读请求,这样可以减轻主节点的压力,提高系统整体性能。
- 高可用性:当主节点出现故障时,可以通过自动或手动方式提升一个从节点为新的主节点,保持服务的连续性。
1.2、Redis 7.0版本的更新概述
Redis 7.0版本带来了许多新特性和改进,以下是一些关键更新点:
- 多线程IO:Redis 7.0对IO密集型任务启用了多线程处理,提高了Redis处理网络I/O的能力,尤其在大规模高并发连接场景下显著提升性能。
- Time Series模块:增加了对时间序列数据的支持,适合存储和查询大量基于时间戳的数据
- SSL/TLS加密通信:增强了安全性,支持在客户端和服务端之间使用SSL/TLS协议进行加密通信
- Bloom Filter数据结构:引入了布隆过滤器(Bloom Filter)这一新的数据结构,用于近似判断某个元素是否存在于大规模集合中,有效节省存储空间。
- 增强的复制功能:可能包括部分重同步优化、更稳定的复制状态转换逻辑等,进一步提升主从复制的稳定性和效率。
Redis 7.0版本通常也会包含一系列性能优化措施以及对已知问题的修复,以持续提升Redis的整体性能和稳定性。
2、主从复制的基本原理
主从复制(Master-Slave Replication)是Redis中一种常见的数据备份和扩展读性能的技术。在这种配置中,一个Redis实例被配置为主服务器(Master),负责处理写操作并维护数据的一致性;而一个或多个Redis实例被配置为从服务器(Slave),它们复制主服务器的数据,并处理读操作。主从复制不仅提供了数据冗余,增强了数据的可靠性,还可以分担读操作的负载,从而提高整个系统的性能。
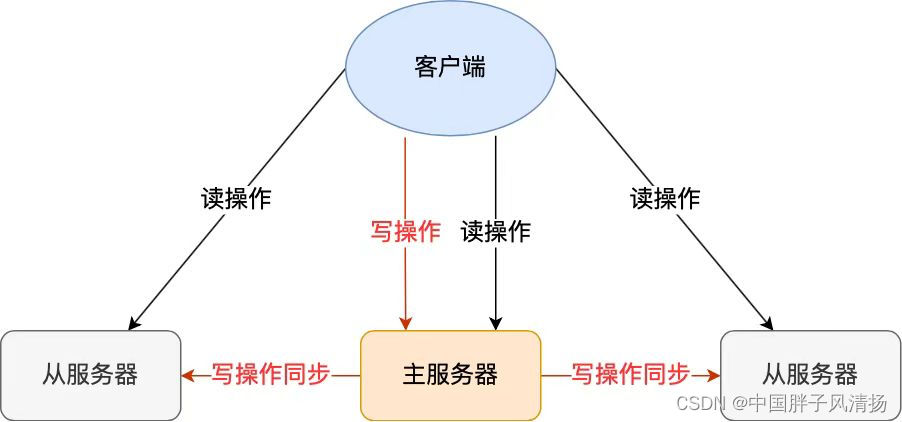
2.1、主从复制的工作流程
(1)主从复制的工作流程大致相同
- 连接建立:从服务器通过发送SYNC命令给主服务器,请求开始复制过程。
- 全量同步:主服务器接收到SYNC命令后,会执行BGSAVE命令生成一个RDB快照文件,并将这个文件发送给从服务器。同时,主服务器还会将所有在此期间接收到的写命令缓存起来。
- 从服务器加载RDB:从服务器接收到RDB快照文件后,会将其加载到内存中,从而拥有与主服务器相同的数据。
- 增量同步:在从服务器加载RDB期间以及之后,主服务器会将缓存的写命令发送给从服务器,从服务器执行这些命令以保持与主服务器的数据同步。
- 持续复制:一旦完成了全量同步和增量同步,主服务器会继续将后续接收到的写命令发送给从服务器,从服务器也会继续执行这些命令,保持与主服务器的数据一致。
(2)RDB和AOF对主从复制的影响
- RDB方式下,主节点定期保存快照,如果在主从复制过程中有新的RDB文件生成,主节点不会强制从节点重新做全量同步,除非从节点主动请求或者网络断开时间较长导致数据不一致。
- AOF模式下,虽然主节点主要依赖AOF日志进行持久化,但主从复制依然是基于命令传播的方式进行,即主节点将所有写命令发送给从节点。
- 若主节点重启并根据AOF文件恢复数据,已连接的从节点会继续同步主节点自上次中断以来的所有新命令。
2.2、数据同步策略
在Redis 7.0中,主从复制的数据同步策略得到了进一步的优化和增强。以下是几个关键的数据同步策略:
- 全量同步阶段:展示主服务器生成RDB快照,并将其发送给从服务器的过程。可以使用流程图,主服务器有一个箭头指向RDB快照文件,再有一个箭头指向从服务器。
- 增量同步阶段:展示主服务器将写命令发送给从服务器,从服务器执行这些命令的过程。可以使用流程图,主服务器有一个箭头指向写命令,再有一个箭头指向从服务器。
- 持续复制阶段:展示主服务器持续发送写命令给从服务器,从服务器持续接收并执行的过程。可以用一个简单的循环箭头来表示这一过程。
3、配置与实践
本次实践使用的环境是Docker,所以需要使用者有docker基础。
(1)拉取redis镜像
docker pull redis
(2)修改redis.conf配置文件
## 无论是Master还是Slave容器都要修改这些属性
daemonize yes
bind 0.0.0.0
protected-mode no
requirepass 123456
(3)启动容器
因为Docker容器是属于隔离的容器,所以一个镜像可以启动多个容器。
## 启动Master容器
docker run -d \
--name Master_Redis \
-p 8900:6379 \
-v /usr/tt/masterRedis/conf/redis.conf:/etc/redis/redis.conf \
-v /usr/tt/masterRedis/data:/data \
d1397258b2
## 启动Slave容器(使用的是与Master相同的镜像)
## Slave_1
docker run -d \
--name Slave_Redis_1 \
-p 8901:6379 \
-v /usr/tt/slaveRedis/conf/redis.conf:/etc/redis/redis.conf \
-v /usr/tt/slaveRedis/data:/data \
d1397258b2
--slaveof 192.168.240.3 8900 # 当前Redis是哪台Master的Slave机器,--slaveof Master地址 Master端口
## Slave_2
docker run -d \
--name Slave_Redis_2 \
-p 8902:6379 \
-v /usr/tt/slaveRedis/conf/redis.conf:/etc/redis/redis.conf \
-v /usr/tt/slaveRedis/data:/data \
d1397258b2
--slaveof 192.168.240.3 8900
(4)info replication查看配置信息
在Master机器上输入info replication后就会看到连接上的Slave信息:
role:master
connected_slaves:2 # slave机器连接数
slave0:ip=192.168.240.3,port=6379,state=online,offset=38730,lag=0 # slave_1
slave1:ip=192.168.240.3,port=6379,state=online,offset=38730,lag=0 # slave_2
master_failover_state:no-failover
master_replid:779eb999b0b80fbb5f12801e112db1a9b050fb6a
master_replid2:292fddd7005571cf21dff750302e6f666dbdb2ab
master_repl_offset:38730
second_repl_offset:27657
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:27657
repl_backlog_histlen:11074
在Slave机器上输入info replication后就会看到连接的Master和当前的状态信息:
role:slave
master_host:192.168.240.3 # master主机的地址
master_port:8900 # master主机的端口
master_link_status:up # 当前master主机的状态
master_last_io_seconds_ago:9
master_sync_in_progress:0
slave_read_repl_offset:39038
slave_repl_offset:39038
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:779eb999b0b80fbb5f12801e112db1a9b050fb6a
master_replid2:292fddd7005571cf21dff750302e6f666dbdb2ab
master_repl_offset:39038
second_repl_offset:27657
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:9317
repl_backlog_histlen:2972
只要出现上面的信息,则表示Redis7.0版本的主从复制成功。
4、结论
Redis主从复制是一种有效的数据备份和扩展读性能的机制。它提供了数据冗余,增强了可靠性,并分担了读操作的负载。
4.1、主从复制在Redis中的重要性和价值
- 数据冗余和备份: 主从复制实现了数据的热备份,提供了数据层面上的冗余。即使主节点出现故障或进行维护时,从节点可以继续提供服务,保证了数据的高可用性。
- 故障恢复: 当主节点发生故障时,可以通过切换至从节点(通常通过哨兵模式自动完成)快速恢复服务,从而实现高可用架构设计,减少业务中断时间。
- 负载均衡与读写分离: 通过配置多个从节点,Redis可以支持读写分离,主节点处理所有写操作,而从节点用于处理只读请求,极大地提高了系统的并行处理能力和整体性能,特别是在读多写少的应用场景下。
- 水平扩展能力: 单一节点的资源有限,通过主从复制可以将数据分布到多个服务器上,从而实现水平扩展,满足更高的并发访问需求和更大的存储需求。
- 构建更高级集群架构的基础: 主从复制是搭建Redis Sentinel(哨兵)系统和Redis Cluster(集群)的基础,哨兵模式可以监控主从状态并自动故障转移,集群则能够进一步实现数据分片和分布式计算。
- 地理分布与容灾: 在多数据中心或多地域部署的情况下,通过设置跨地域的主从复制,可以在不同地理位置保存数据副本,增强系统的容灾能力。
4.2、Redis主从复制缺点
- 数据延迟:在高负载情况下,从节点与主节点之间的数据同步可能会有延迟,这可能导致从节点的数据不是最新的。这种延迟可能会影响一些需要实时数据一致性的应用。
- 故障转移不是自动的:在没有使用Redis Sentinel或Redis Cluster的情况下,如果主节点出现故障,需要手动进行故障转移,这可能会增加系统的恢复时间。
- 成本增加:为了保持数据的冗余和可靠性,需要维护多个从节点服务器,这可能会增加硬件和运维成本。
- 写扩展限制:所有的写操作仍然需要通过主节点进行,因此主从复制不会提高写操作的性能。在写操作非常频繁的场景下,这可能会成为性能瓶颈。
- 一致性问题:虽然主从复制可以提高系统的可用性,但在某些情况下,如网络分区或主节点宕机,可能会导致数据不一致的问题。
















 925
925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









