







任务需求
在贝壳租房网站(这里我选择的城市是天津)爬取50页房源信息,包括房源编号、所在城市、所在区县、所在街道或地区、小区名称、面积、朝向、月租、计费方式、室、厅、卫、入住、租期、看房、所在楼层、总楼层、电梯、车位、用水、用电、燃气、采暖等信息。将信息写入CSV文件保存,以备后续任务使用。
对任务需求的分析
这是一个关于爬虫的任务,那么一些爬虫常用的模块(如requests, bs4等)是必不可少的。
需求中有提到“爬取50页数据”,看到这里很自然地就会想到使用循环来解决。打开贝壳租房网,翻页观察URL的变化并寻找规律,如下图所示:
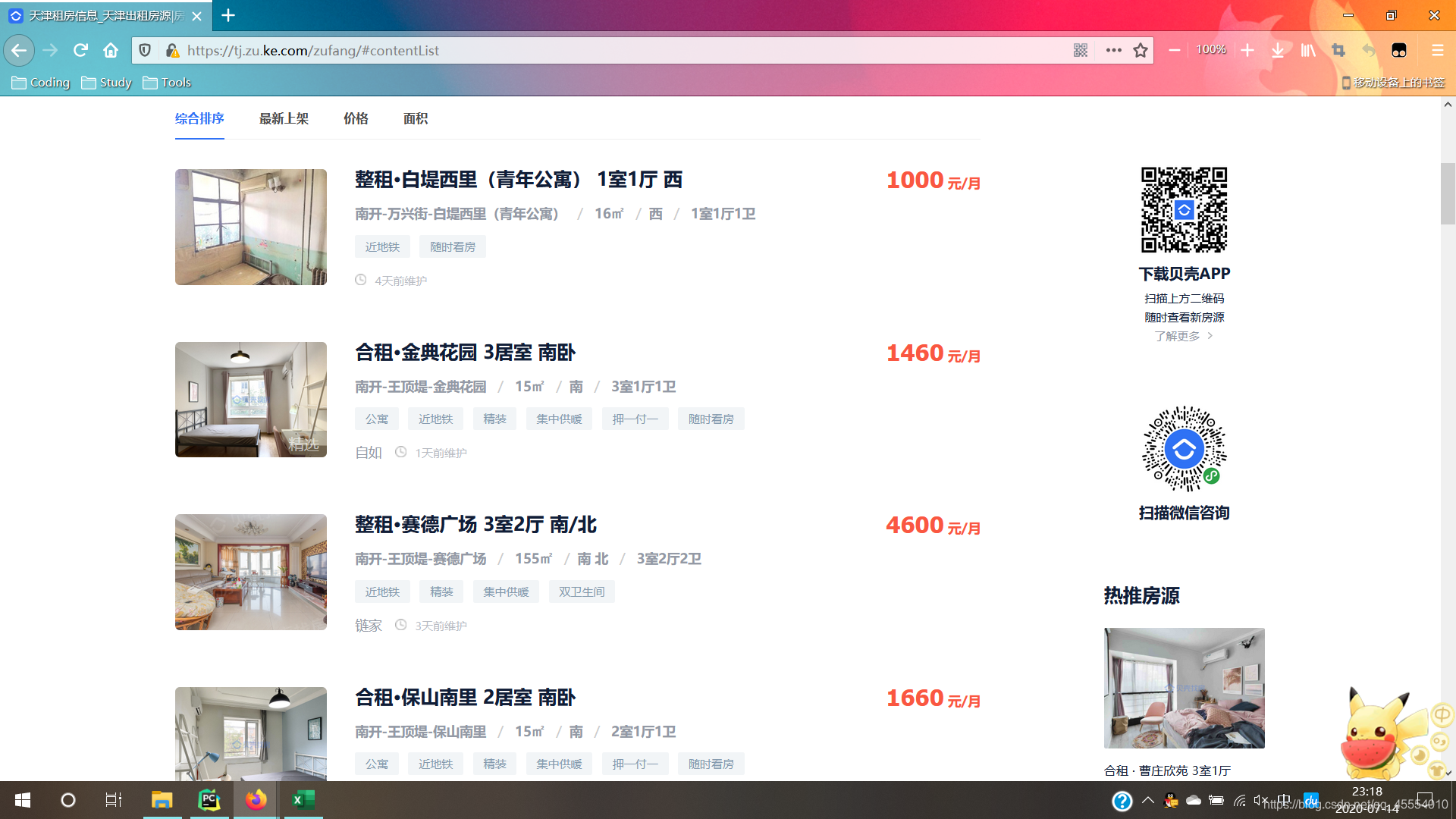
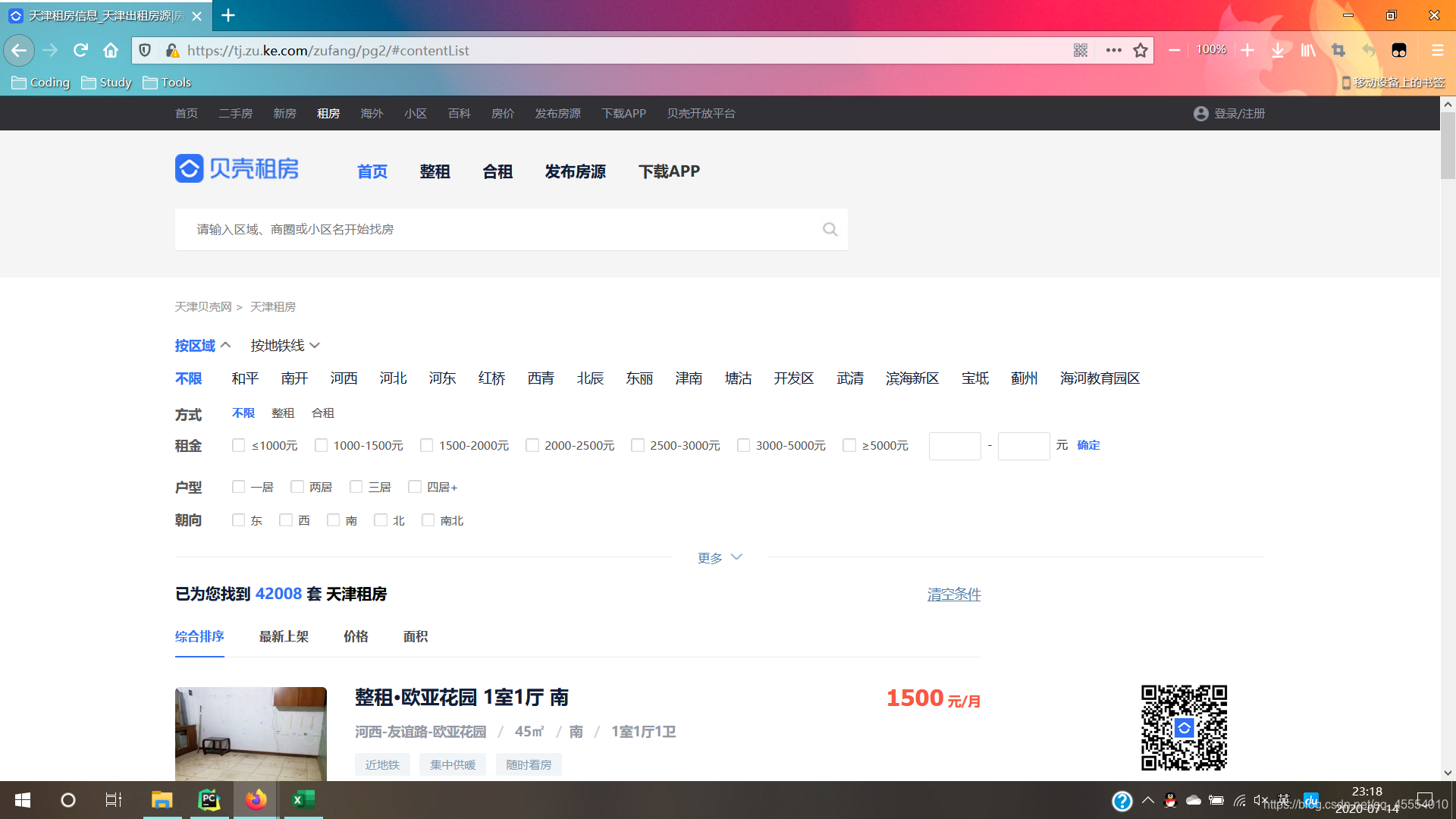
不难发现,URL的“模板”是https://tj.zu.ke.com/zufang/pg[对应的页码]/#contentList。那么,爬取50页数据就可以使用for循环来解决,循环变量的范围设置为range(1, 51),将其作为页码拼接到“模板”URL中,对这些URL分别发起请求爬取数据即可。
接下来的问题是,如何找到某一个房源的具体信息呢?
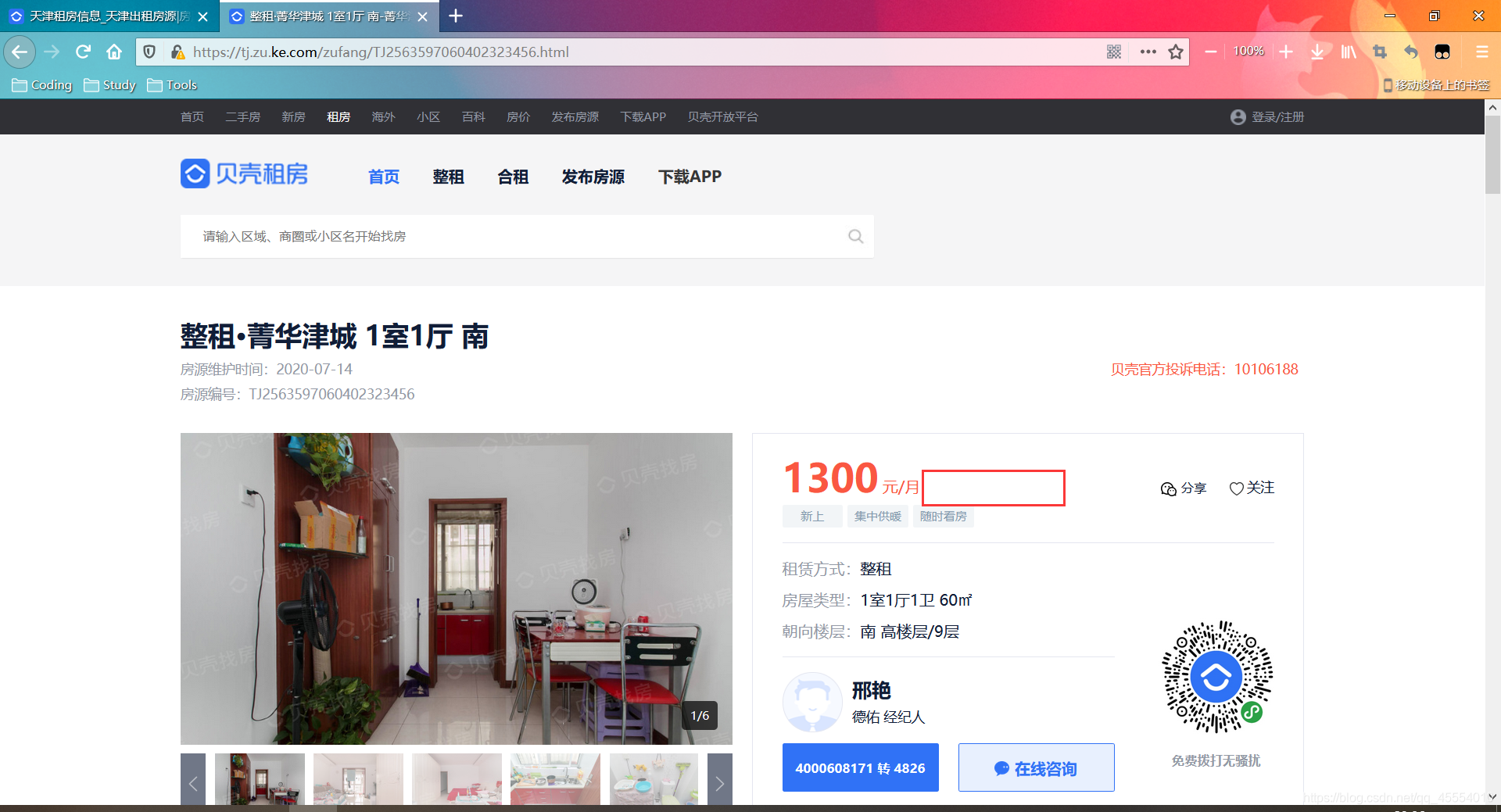
我们点击右键检查元素,进入网页的HTML源代码查看,会发现一个名为data-house_code的值。大胆猜测一下,它和房源具体信息页的URL存在一些关联。

点击房源进入详情页,我们发现URL中恰好包含前面看到的data-house_code值。事实上,这个值正是与房源一一对应的唯一编号。
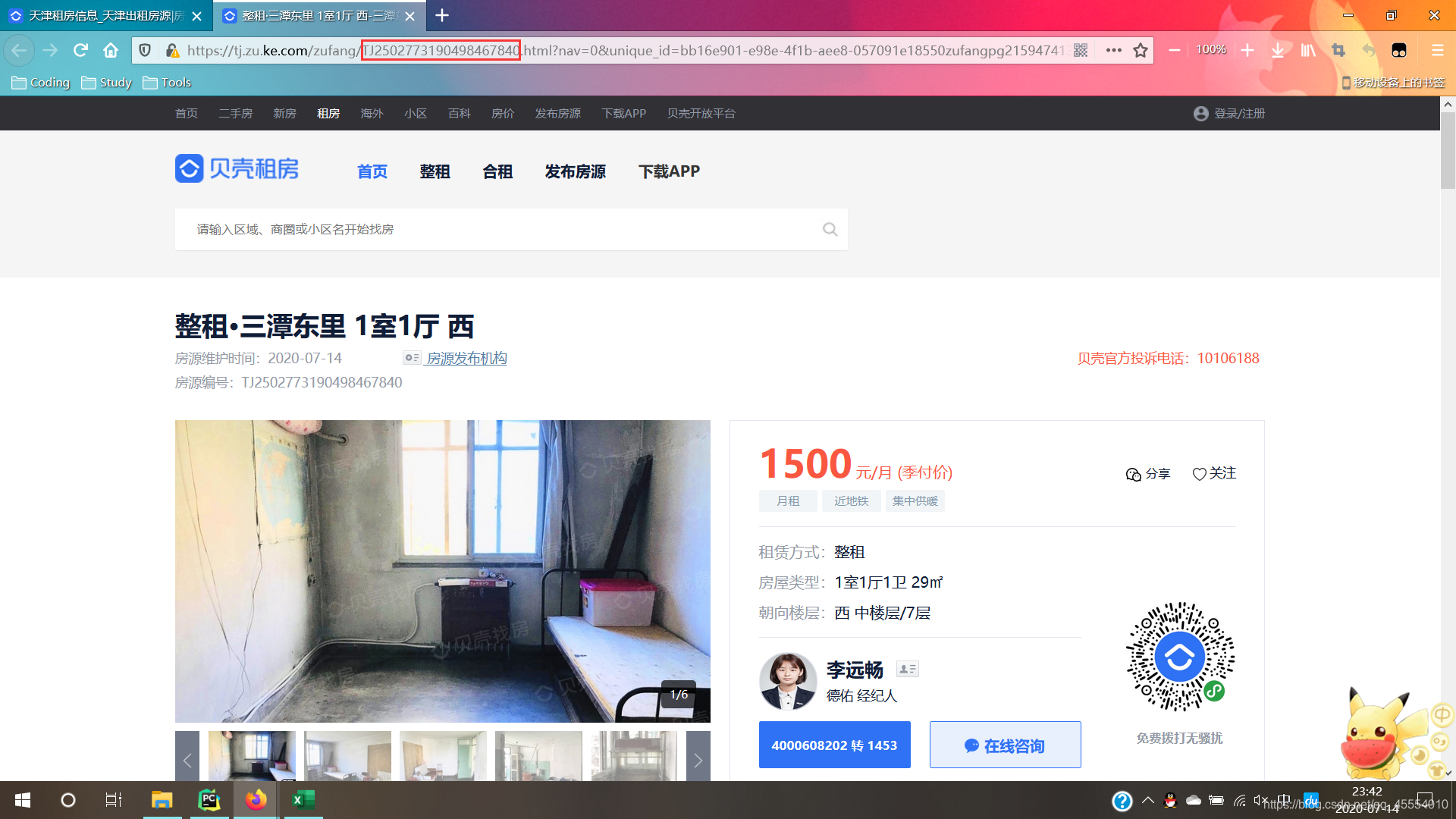
最后就是对HTML代码抽丝剥茧找出所需要的数据并写入CSV文件了。这里可以使用bs4来解析HTML源代码,也可以使用正则表达式或者XPath解析。我使用的是bs4和正则表达式结合解析HTML的方法。详细的实现过程可以参考下面的Python代码。
Python源代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import csv
import re
from bs4 import BeautifulSoup
import requests
head = ['房源编号', '所在城市', '所在区县', '所在街道或地区', '小区名称', '面积', '租赁方式', '朝向', '月租', '计费方式', '室', '厅',
'卫', '入住', '租期', '看房', '所在楼层', '总楼层', '电梯', '车位', '用水', '用电', '燃气', '采暖'] # 写入文件的标题行
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0'}
with open('TianjinRentHouseInfo.csv', 'w', newline='') as csv_out_file:
filewriter = csv.writer(csv_out_file)
filewriter.writerow(head)
for page in range(1, 51):
url = 'https://tj.zu.ke.com/zufang/pg' + str(page) + '/#contentList'
response = requests.get(url=url, headers=headers)
page_text = response.text
soup = BeautifulSoup(page_text, 'html.parser')
div_list = soup.find_all(class_='content__list--item')
codes = [] # 存储房源编号的列表
areas = [] # 存储房源地区的列表
for div in div_list:
code = re.search(r'data-house_code="(.*?)" ', str(div)).group()[17:-2]
codes.append(code)
p_list = soup.find_all(class_='content__list--item--des')
for p in p_list:
a_list = p.find_all('a')
area = []
for i in range(len(a_list)):
a_text = a_list[i].text
area.append(a_text)
areas.append(area)
for i in range(len(codes)):
info = [] # 存储房源信息的列表
info.extend([codes[i], '天津'] + areas[i])
url = 'https://tj.zu.ke.com/zufang/' + codes[i] + '.html'
response = requests.get(url=url, headers=headers)
page_text = response.text
soup = BeautifulSoup(page_text, 'html.parser')
ul_text = soup.find('ul', class_='content__aside__list').text
div_text = soup.find('div', class_='content__aside--title').text
S = re.search(r' (.*?)㎡', ul_text).group()[1:] # 面积
lease = re.search(r'租赁方式:(.*?)\n', ul_text).group()[5:-1] # 租赁方式
aspect = re.search(r'朝向楼层:(.*?) ', ul_text).group()[5:-1] # 朝向
price = re.search(r'([0-9]*?)元/月', div_text).group() # 月租
try:
charge_mode = re.search(r'\((.*?)\)', div_text).group()[1:-1] # 计费方式
except AttributeError:
charge_mode = 'None'
room = re.search(r'([0-9*?])室', ul_text).group() # 几室
hall = re.search(r'([0-9*?])厅', ul_text).group() # 几厅
toilet = re.search(r'([0-9*?])卫', ul_text).group() # 几卫
info.extend([S, lease, aspect, price, charge_mode, room, hall, toilet])
div = soup.find('div', class_='content__article__info')
ul_list = div.find_all('ul')
ul_text = ''
for ul in ul_list:
ul_text += ul.text
check_in = re.search(r'入住:(.*?)\n', ul_text).group()[3:-1] # 入住
term = re.search(r'租期:(.*?)\n', ul_text).group()[3:-1] # 租期
see_house = re.search(r'看房:(.*?)\n', ul_text).group()[3:-1] # 看房
floor = re.search(r'楼层:(.*?)/', ul_text).group()[3:-1] # 所在楼层
total_floor = re.search(r'/(.*?)\n', ul_text).group()[1:-1] # 总楼层
lift = re.search(r'电梯:(.*?)\n', ul_text).group()[3:-1] # 电梯
stall = re.search(r'车位:(.*?)\n', ul_text).group()[3:-1] # 车位
water = re.search(r'用水:(.*?)\n', ul_text).group()[3:-1] # 用水
elec = re.search(r'用电:(.*?)\n', ul_text).group()[3:-1] # 用电
gas = re.search(r'燃气:(.*?)\n', ul_text).group()[3:-1] # 燃气
heating = re.search(r'采暖:(.*?)\n', ul_text).group()[3:-1] # 采暖
info.extend([check_in, term, see_house, floor, total_floor, lift, stall, water, elec, gas, heating])
print(info[0], '写入成功')
filewriter.writerow(info)
在写代码的过程中我遇到了一个问题,在用正则表达式匹配“计费方式”的时候,会有匹配不到结果而报AttributeError错误的情况出现。经过排查,我发现有的房源详情页并不存在“计费方式”的字样,自然无法匹配。可以使用try-except结构来解决这个问题,详情请参考上述代码第50-53行。
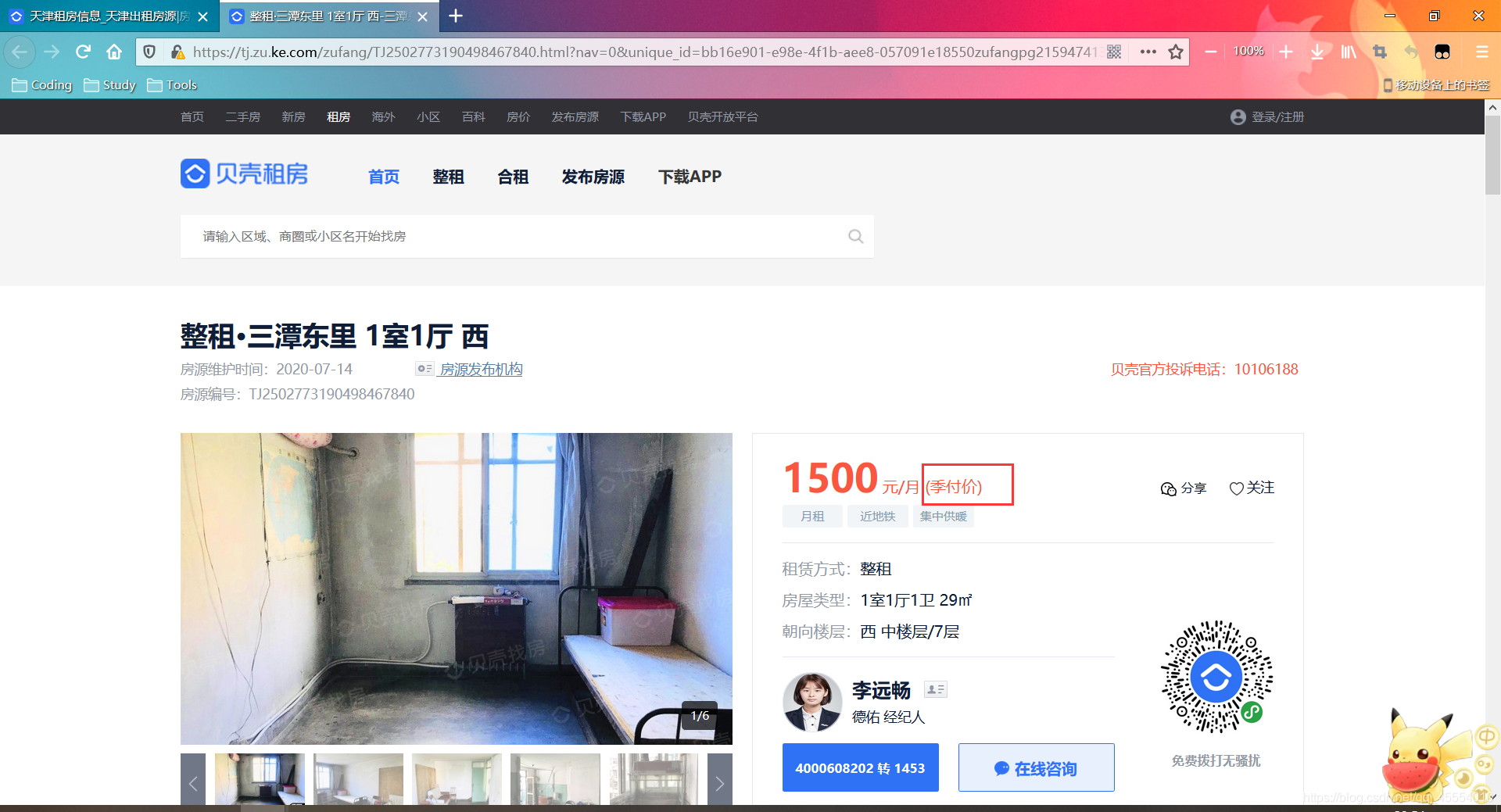
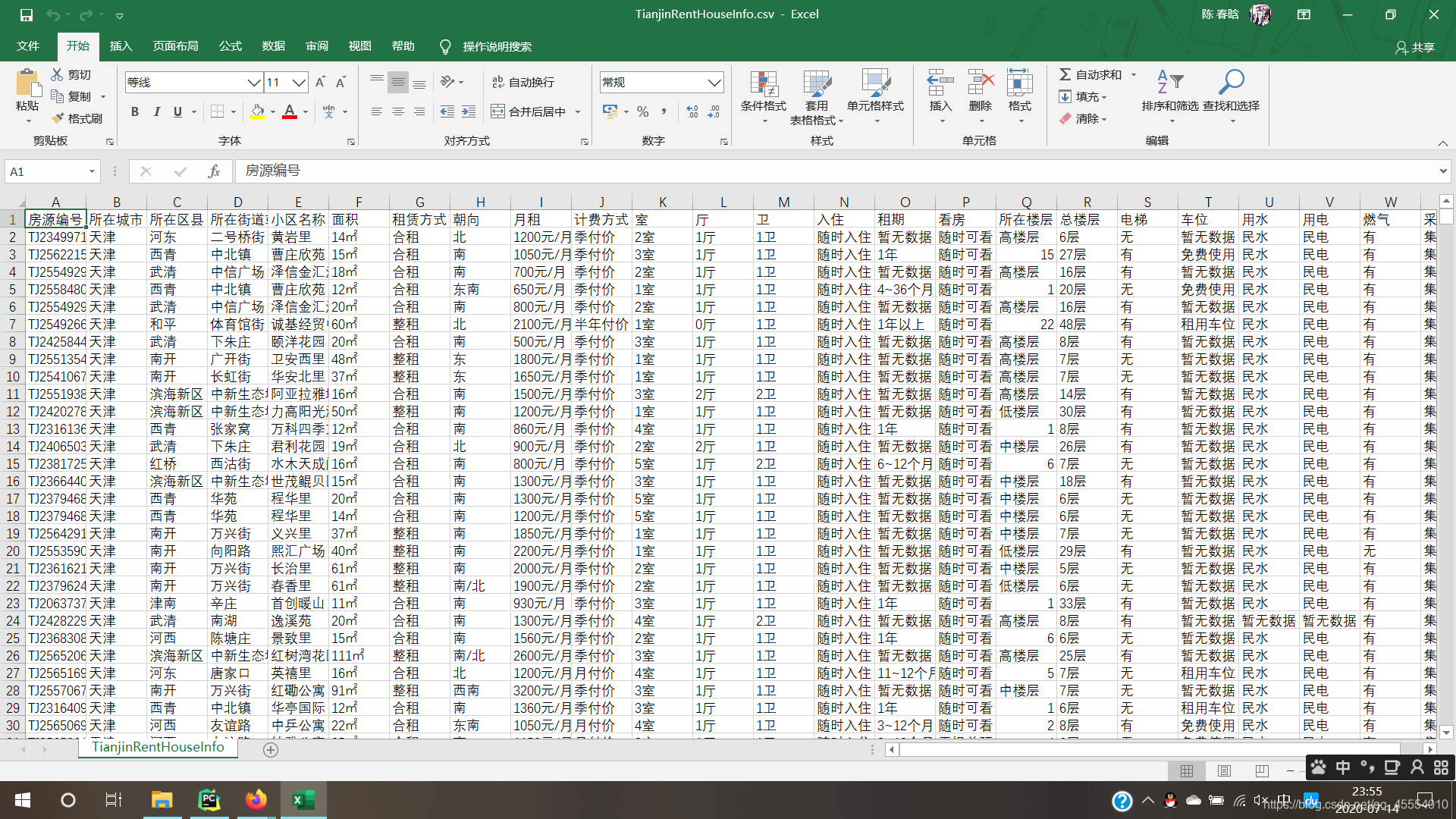
运行结果
运行后可得到一个CSV文件,其中共包含1503条房源数据。















 4724
4724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









