









文本挖掘技术研究_笔记
数据挖掘(DM,Data Mining):是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中采掘出隐含的、先前未知的、对决策有潜在价值的知识和规则的过程。
文本挖掘(TM,Text Mining):是以计算语言学、 统计数理分析为理论基础,结合机器学习和信息检索技术,从文本数据中发现和提取独立于用户信息需求的文档集中的隐含知识。它是一个从文本信息描述到选取提取模式,最终形成用户可理解的信息知识的过程。
文本挖掘种类:
1.基于单文档的数据挖掘
不涉及其他文档,主要使用文本摘要、信息提取(名字提取、短语提取、关系提取)等挖掘技术。
2.基于文档集的数据挖掘
对大规模的文档数据进行模式抽取(文本分类、文本聚类、个性化文本过滤、文档作者归属、因素分析)等
文本挖掘研究方向:
1.网络浏览:分析用户网络行为,帮助用户更好的寻找有用信息。
2.文本检索:研究对整个文档文本信息的表示、存储、组织和访问,根据用户的检索要求,从数据库中检索相关的信息资料。
3.文本自动分类:按照预先定义的主题类别,为文档集合中的每一个文档确定一个类别,方便用户查阅文档,限制搜索范围。(基于归纳学习的决策树、基于向量空间模型的K-最近邻、基于概率模型的Bayes分类器、神经网络、基于统计学习理论的支持向量机)
4.文本自动聚类:无教师机器学习,没有预先定义好的主题类别,将文档集合分成若干个簇,要求同一个簇内文档内容的相似度尽可能大,而不同簇间的相似度尽可能小。
5.文档总结:从文档中抽取关键信息,用简洁的形式,对文档内容进行摘要和解释,用户不需阅读全文就可了解文档或文档集合的总体内容。
文本挖掘研究过程:
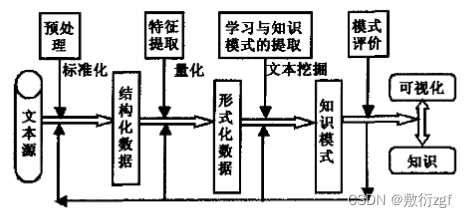
1.文本预处理:对文本数据进行数据挖掘中相应的标准化预处理,以及对文本数据的信息预处理。
2.文本的表示:常用模型(布尔逻辑模型、向量空间模型VSM、潜在语义索引LSI、概率模型)
3.特征集约减:构造特征评估函数
有效特征集具有完全性和区分性
4.文本挖掘的方法:
(1)文本分类:监督式机器学习
(2)文本聚类:无监督式机器学习



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











