







二叉树
三种深度遍历
递归
144.前序遍历
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
traversal(root,ans);
return ans;
}
private void traversal(TreeNode root,List<Integer> list){
if(root == null){
return;
}
list.add(root.val);
traversal(root.left,list);
traversal(root.right,list);
}
}
94.中序遍历
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
traversal(root,ans);
return ans;
}
private void traversal(TreeNode root,List<Integer> list){
if(root == null){
return;
}
traversal(root.left,list);
list.add(root.val);
traversal(root.right,list);
}
}
94.中序遍历
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
traversal(root,ans);
return ans;
}
private void traversal(TreeNode root,List<Integer> list){
if(root == null){
return;
}
traversal(root.left,list);
traversal(root.right,list);
list.add(root.val);
}
}
栈
144.前序遍历
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
Deque<TreeNode> stack = new ArrayDeque();
if(root == null){
return ans;
}
stack.push(root);
while(!stack.isEmpty()){
//前序遍历,要处理节点即访问到的节点
TreeNode t = stack.poll();
ans.add(t.val);
if(t.right != null){
stack.push(t.right);
}
if(t.left != null){
stack.push(t.left);
}
}
return ans;
}
}
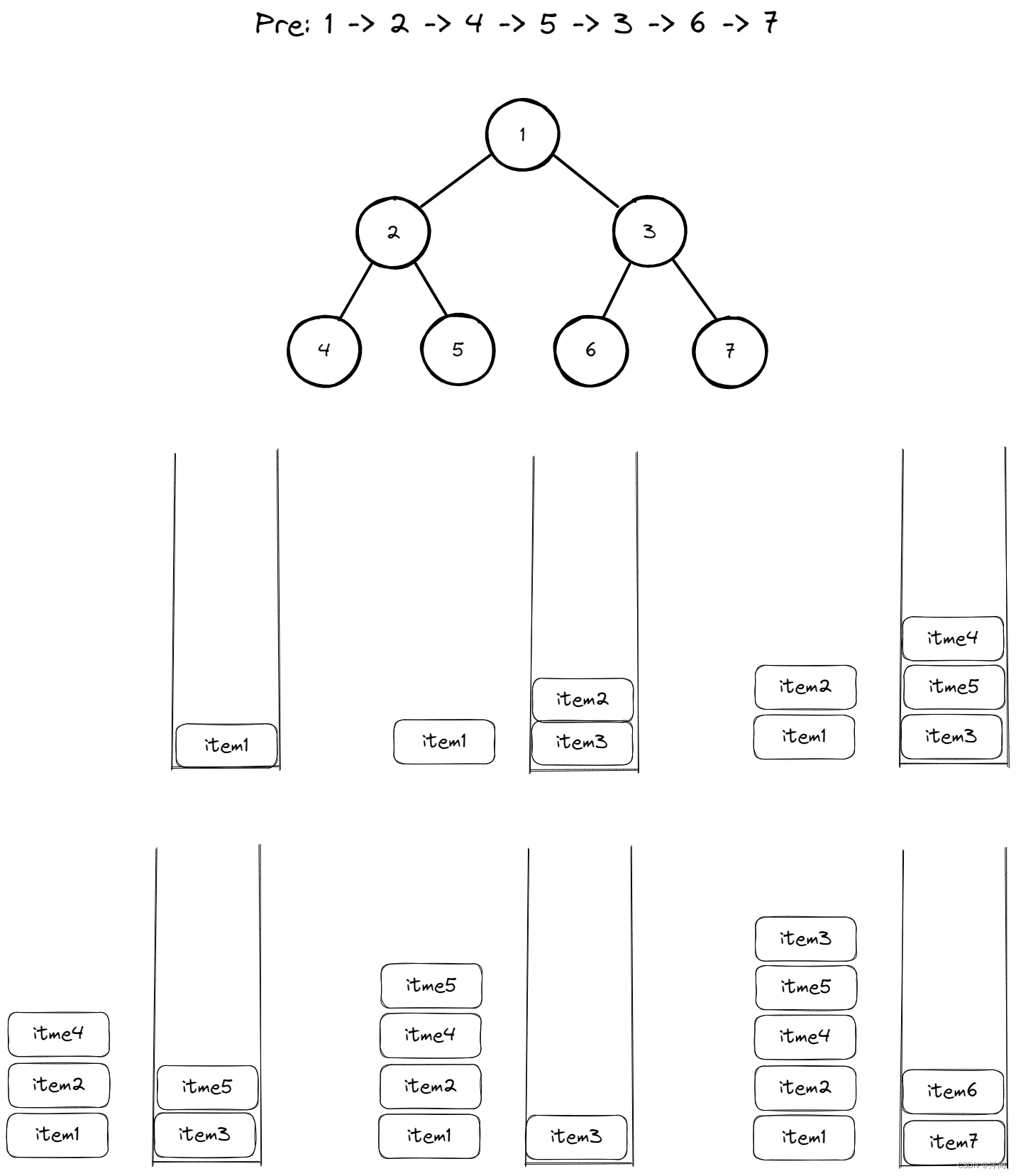
94.中序遍历
访问节点(遍历节点)和处理节点(将元素放进结果集)不一致的情况。
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
Deque<TreeNode> stack = new ArrayDeque();
TreeNode curl = root;
while(curl!= null || !stack.isEmpty() ){
//左,右子树不为空时,访问到最底层
if(curl != null){
// 将访问的节点放进栈
stack.push(curl);
curl = curl.left; //左
}else{
//1.没有左子树,输出本层中
//2.没有右子树,本层遍历完,输出上一层中
// 从栈里弹出的数据,就是要处理的数据
curl = stack.poll();
ans.add(curl.val); //中
//将指针移到右子树上
curl = curl.right; //右
}
}
return ans;
}
}
第二种写法
public static void inOrderIteration(TreeNode head) {
if (head == null) {
return;
}
TreeNode cur = head;
Stack<TreeNode> stack = new Stack<>();
while (!stack.isEmpty() || cur != null) {
while (cur != null) {
stack.push(cur);
cur = cur.left;
}
TreeNode node = stack.pop();
System.out.print(node.value + " ");
if (node.right != null) {
cur = node.right;
}
}
}
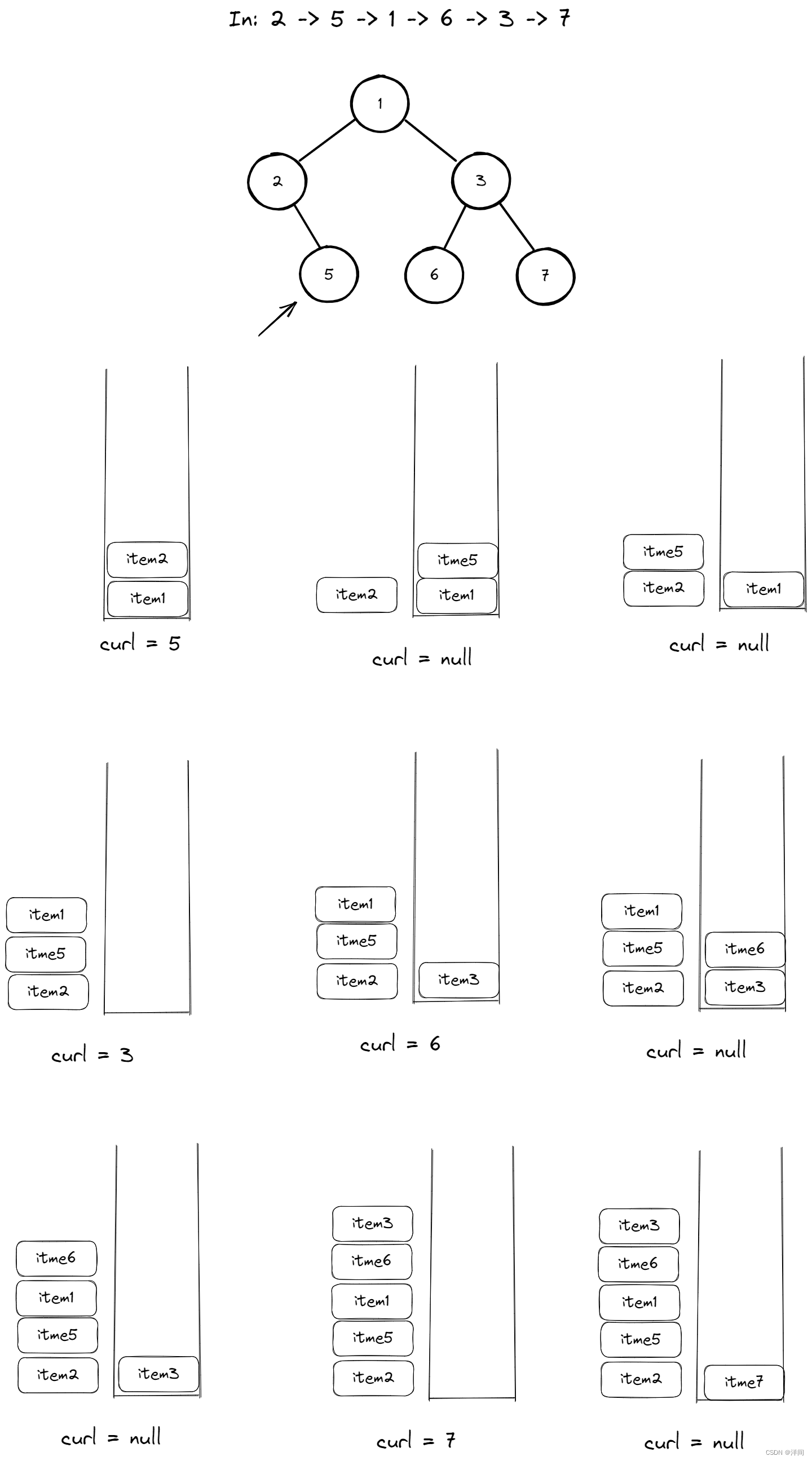
94.后序遍历
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
Deque<TreeNode> stack = new ArrayDeque();
TreeNode curl = root;
TreeNode pre = null;//标记以访问
while(curl != null || !stack.isEmpty()){
while(curl!= null){
stack.push(curl);
curl = curl.left;//极左
}
curl = stack.poll();//取出极左
//此节点不具有右节点,或此右节点是上次访问过的
if(curl.right == null || curl.right == pre){
ans.add(curl.val);
pre = curl;
curl = null; //key!
}else{ //此节点具有右节点,且此右节点不是上次访问过的
//重新把极左放进去
stack.push(curl);
curl = curl.right;//右
}
}
return ans;
}
}
第二种写法
public static void postOrderIteration2(TreeNode head) {
if (head == null) {
return;
}
TreeNode cur = head;
Stack<TreeNode> stack = new Stack<>();
stack.push(head);
while (!stack.isEmpty()) {
TreeNode peek = stack.peek();
if (peek.left != null && peek.left != cur && peek.right != cur) {
stack.push(peek.left);
} else if (peek.right != null && peek.right != cur) {
stack.push(peek.right);
} else {
System.out.print(stack.pop().val + " ");
cur = peek;
}
}
}
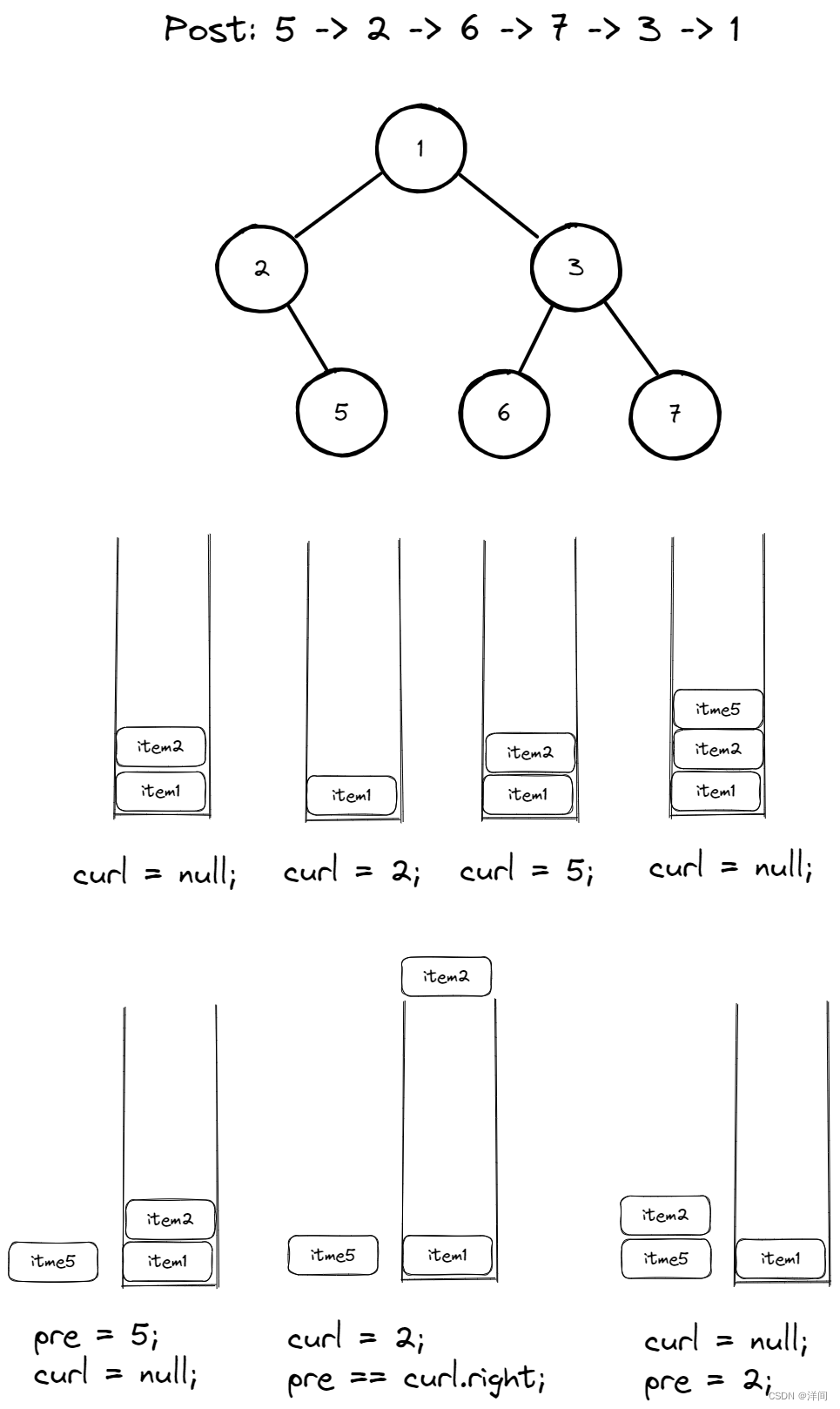
统一迭代法
中节点的左右子树都放入了栈里,访问过,但是还没有处理,加入空节点做为标记,标识不再遍历其子节点
144.前序遍历
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
//Deque<TreeNode> stack = new ArrayDeque(); //不允许插入null元素
Stack<TreeNode> stack = new Stack<>();
if(root != null) stack.push(root);
while(!stack.empty()){
TreeNode curl = stack.pop();// 将该节点弹出,查看节点是否需要访问
if(curl != null){ //前序反着放,右 左 中
if(curl.right != null){
stack.push(curl.right);
} //右
if(curl.left != null){
stack.push(curl.left);
} //左
// 中节点的左右子树都放入了栈里,访问过,但是还没有处理,加入空节点做为标记。
stack.push(curl);
stack.push(null); //中,key!
}else{// 只有遇到空节点的时候,才将下一个节点放进结果集
curl = stack.pop();
ans.add(curl.val);
}
}
return ans;
}
}
94.中序遍历
左中右,中即位正在访问的节点
那我们就将访问的节点放入栈中,把要处理的节点也放入栈中但是要做标记。
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
//Deque<TreeNode> stack = new ArrayDeque(); //不允许插入null元素
Stack<TreeNode> stack = new Stack<>(); //可以插入null元素
TreeNode curl = root;
if(root != null) stack.push(curl);
while(!stack.empty()){
curl = stack.pop();// 将该节点弹出,查看节点是否需要访问
if(curl != null){
//下面再将右中左节点添加到栈中
if(curl.right != null){
stack.push(curl.right);
}// 添加右节点(空节点不入栈)
stack.push(curl);// 添加中节点
// 中节点的左右子树都放入了栈里,访问过,但是还没有处理,加入空节点做为标记。
stack.push(null);//key flag;
if(curl.left != null){
stack.push(curl.left);
}// 添加左节点(空节点不入栈)
}else{// 只有遇到空节点的时候,才将下一个节点放进结果集
curl =stack.pop();// 重新取出栈中元素
ans.add(curl.val);// 加入到结果集
}
}
return ans;
}
}

145.后序遍历
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
//Deque<TreeNode> stack = new ArrayDeque(); //不允许插入null元素
Stack<TreeNode> stack = new Stack<>(); //可以插入null元素
if(root != null) stack.push(root);
while(!stack.empty()){
TreeNode curl = stack.pop();
if(curl != null){ //后序反着放,中 右 左
stack.push(curl);
stack.push(null); //中
if(curl.right != null){
stack.push(curl.right);
} //右
if(curl.left != null){
stack.push(curl.left);
} //左
}else{
curl = stack.pop();
ans.add(curl.val);
}
}
return ans;
}
}
层序遍历
102.二叉树的层序遍历
递归
class Solution {
public List<List<Integer>> result = new ArrayList<>();
public List<List<Integer>> levelOrder(TreeNode root) {
checkFunc1(root,0);
return result;
}
private void checkFunc1(TreeNode node, int deep){
if(node == null){
return;
}
deep++;
if(result.size()< deep){
List<Integer> sublist = new ArrayList<>();
result.add(sublist);
}
result.get(deep-1).add(node.val);
checkFunc1(node.left,deep);
checkFunc1(node.right,deep);
}
}
队列
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> result = new ArrayList<>();
Deque<TreeNode> que = new ArrayDeque();
if(root != null){
que.offer(root);
}
while(!que.isEmpty()){
List<Integer> sublist = new ArrayList<>();
int size = que.size();
for(int i = 0; i<size; i++){
TreeNode t = que.poll();
sublist.add(t.val);
if(t.left!=null) que.offer(t.left);
if(t.right!=null) que.offer(t.right);
}
result.add(sublist);
}
return result;
}
}
107.二叉树的层次遍历 II
自底向上输出,反转
class Solution {
public List<List<Integer>> levelOrderBottom(TreeNode root) {
List<List<Integer>> result = new ArrayList<>();
Deque<TreeNode> que = new ArrayDeque();
if(root != null){
que.offer(root);
}
while(!que.isEmpty()){
List<Integer> sublist = new ArrayList<>();
int size = que.size();
for(int i = 0; i<size; i++){
TreeNode t = que.poll();
sublist.add(t.val);
if(t.left!=null) que.offer(t.left);
if(t.right!=null) que.offer(t.right);
}
//result.addFirst(sublist); //LinkedList方法
result.add(0,sublist); //从头插
}
//或使用result.add(sublist)并反转
//Collections.reverse(result);
return result;
}
199.二叉树的右视图
层序遍历的时候,判断是否遍历到单层的最后面的元素,如果是,就放进result数组中,随后返回result就可以了。
class Solution {
public List<Integer> rightSideView(TreeNode root) {
List<Integer> result = new ArrayList<>();
Deque<TreeNode> que = new ArrayDeque<>();
if(root != null) que.offer(root);
while(!que.isEmpty()){
int size = que.size();
TreeNode t = que.peek();
while(size>0){
t = que.poll();
if(t.left != null) que.offer(t.left);
if(t.right != null) que.offer(t.right);
size--;
}
result.add(t.val);
}
return result;
}
}
637.二叉树的层平均值
每层遍历相加
class Solution {
public List<Double> averageOfLevels(TreeNode root) {
List<Double> result = new ArrayList<>();
Deque<TreeNode> que = new ArrayDeque<>();
if(root != null) que.offer(root);
while(!que.isEmpty()){
int size = que.size();
int i = size;
double sum = 0;
while(i>0){
TreeNode t = que.poll();
sum = sum+ t.val;
if(t.left != null) que.offer(t.left);
if(t.right != null) que.offer(t.right);
i--;
}
result.add(sum/size);
}
return result;
}
}
429.N叉树的层序遍历
Node有 int val 和List chirldren两个属性。
class Solution {
public List<List<Integer>> levelOrder(Node root) {
List<List<Integer>> result = new ArrayList<>();
Deque<Node> que = new ArrayDeque();
if(root != null) que.offer(root);
while(!que.isEmpty()){
List<Integer> sublist = new ArrayList<>();
int size = que.size();
for(int i = 0; i<size; i++){
Node t = que.poll();
sublist.add(t.val);
for(Node node : t.children){
que.offer(node);
}
}
result.add(sublist);
}
return result;
}
}
515.在每个树行中找最大值
class Solution {
public List<Integer> largestValues(TreeNode root) {
List<Integer> result = new ArrayList<>();
Deque<TreeNode> que = new ArrayDeque<>();
if(root != null) que.offer(root);
while(!que.isEmpty()){
int size = que.size();
int max = que.peek().val;
while(size>0){
TreeNode t = que.poll();
if(t.val > max) max = t.val;
//max = Math.max(max,node.val);
if(t.left != null) que.offer(t.left);
if(t.right != null) que.offer(t.right);
size--;
}
result.add(max);
}
return result;
}
}
116.填充每个节点的下一个右侧节点指针
借助队列层序遍历
class Solution {
public Node connect(Node root) {
Deque<Node> que = new LinkedList<>();
if(root != null) que.offer(root);
while(!que.isEmpty()){
int size = que.size();
for(int i = 0; i< size; i++){
Node t = que.poll();
if(i < size -1) t.next = que.peek();
if(t.left != null) que.offer(t.left);
if(t.right != null) que.offer(t.right);
}
}
return root;
}
}
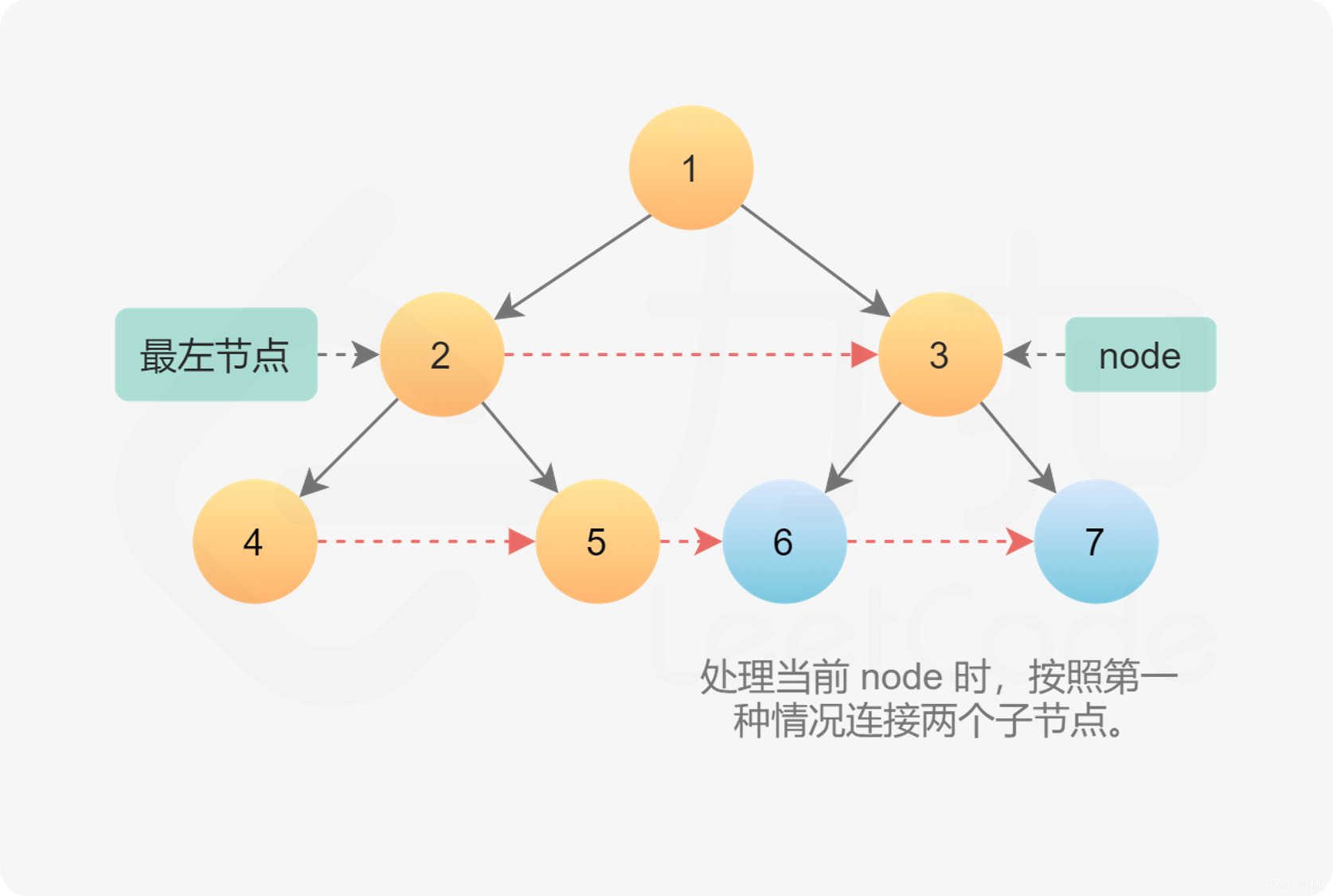
使用已建立的next 指针
class Solution {
public Node connect(Node root) {
if (root == null) {
return root;
}
// 从根节点开始
Node leftmost = root;
while (leftmost.left != null) {
// 遍历这一层节点组织成的链表,为下一层的节点更新 next 指针
Node head = leftmost;
while (head != null) {
// CONNECTION 1
head.left.next = head.right;
// CONNECTION 2
if (head.next != null) {
head.right.next = head.next.left;
}
// 指针向后移动
head = head.next;
}
// 去下一层的最左的节点
leftmost = leftmost.left;
}
return root;
}
}
117.填充每个节点的下一个右侧节点指针II
和上一题一模一样,借助队列层序遍历
class Solution {
public Node connect(Node root) {
Deque<Node> que = new LinkedList<>();
if(root != null) que.offer(root);
while(!que.isEmpty()){
int size = que.size();
for(int i = 0; i< size; i++){
Node t = que.poll();
if(i < size -1) t.next = que.peek();
if(t.left != null) que.offer(t.left);
if(t.right != null) que.offer(t.right);
}
}
return root;
}
}
104.二叉树的最大深度
层序遍历
class Solution {
public int maxDepth(TreeNode root) {
Deque<TreeNode> que = new LinkedList<>();
if(root != null) que.offer(root);
int result = 0;
while(!que.isEmpty()){
int size = que.size();
for(int i = 0; i< size; i++){
TreeNode t = que.poll();
if(t.left != null) que.offer(t.left);
if(t.right != null) que.offer(t.right);
}
result++;
}
return result;
}
}
递归法
前序遍历
class Solution {
int result = 0;//全局变量
public int maxDepth(TreeNode root) {
if(root == null){
return result;
}
treeDepth(root,1);
return result;
}
private void treeDepth(TreeNode node, int depth){
//先序遍历,判断此深度和最大深度哪个大并赋值
result = depth > result ? depth :result; //中
if(node.left != null) treeDepth(node.left,depth+1);//左
if(node.right != null) treeDepth(node.right,depth+1);//右
}
}
后序遍历
class Solution {
public int maxDepth(TreeNode root) {
return treeDepth(root);
}
private int treeDepth(TreeNode node){
if(node == null) return 0;
int left = treeDepth(node.left);//左
int right = treeDepth(node.right);//右
return 1 + Math.max(left,right);//中
}
}
559.n叉树的最大深度
层序遍历
class Solution {
public int maxDepth(Node root) {
Deque<Node> que = new LinkedList<>();
if(root != null) que.offer(root);
int result = 0;
while(!que.isEmpty()){
int size = que.size();
for(int i = 0; i< size; i++){
Node t = que.poll();
for(Node node:t.children){
if(node!=null) que.offer(node);
}
}
result++;
}
return result;
}
}
递归
class Solution {
public int maxDepth(Node root) {
return treeDepth(root);
}
public int treeDepth(Node node){
if(node == null) return 0;
int max = 0;
//子节点
for(Node children : node.children){
int depth = treeDepth(children);
max = depth > max ? depth : max;
}
//中节点
return max + 1;
}
}
111.二叉树的最小深度
层序遍历
1ms,最小深度还是层序快,到指定一层就停止,而深度要遍历完所有节点
class Solution {
public int minDepth(TreeNode root) {
Deque<TreeNode> que = new LinkedList<>();
if(root != null) que.offer(root);
int result = 0;
while(!que.isEmpty()){
int size = que.size();
result++;
for(int i = 0; i< size; i++){
TreeNode t = que.poll();
if(t.left == null & t.right == null){
return result;
}else{
if(t.left != null) que.offer(t.left);
if(t.right != null) que.offer(t.right);
}
}
}
return result;
}
}
深度遍历递归
7ms
后序遍历
class Solution {
public int minDepth(TreeNode root) {
return treeDepth(root);
}
public int treeDepth(TreeNode node){
if(node == null) return 0;
int left = treeDepth(node.left); //左
int right = treeDepth(node.right); //右
//中
//考虑根节点无左||右子树时,并不符合
//一个节点无左&&右节点时,才是叶子节点
if(node.left == null && node.right !=null ){
return right + 1;
}
if(node.right == null && node.left != null){
return left + 1;
}
//叶子节点,和有两个孩子的节点
return Math.min(left,right) +1;
}
}
先序遍历
int中最大的值可以用 Integer.MAX_VALUE; 表示
class Solution {
int result = 0;
public int minDepth(TreeNode root) {
if(root == null){
return result;
}
result = Integer.MAX_VALUE;
treeDepth(root,1);
return result;
}
public void treeDepth(TreeNode node, int depth){
if(node.left == null && node.right == null){
result = result > depth ? depth : result;
return;
}
if(node.left != null) treeDepth(node.left,depth+1);
if(node.right != null) treeDepth(node.right,depth+1);
}
}
226.翻转二叉树
听说 Homebrew的作者Max Howell,就是因为没在白板上写出翻转二叉树,最后被Google拒绝了。
所以拿下这题能进谷歌吗😍
广度优先遍历
class Solution {
public TreeNode invertTree(TreeNode root) {
Deque<TreeNode> que = new LinkedList<>();
if(root != null) que.offer(root);
while(!que.isEmpty()){
int size = que.size();
for(int i = 0; i< size; i++){
TreeNode node = que.poll();
//两边交换
TreeNode t = node.left;
node.left = node.right;
node.right = t;
if(node.left != null) que.offer(node.left);
if(node.right != null) que.offer(node.right);
}
}
return root;
}
}
深度优先
递归
前序遍历
//DFS递归
class Solution {
/**
* 前后序遍历都可以
* 中序不行,因为先左孩子交换孩子,再根交换孩子(做完后,右孩子已经变成了原来的左孩子),再右孩子交换孩子(此时其实是对原来的左孩子做交换)
*/
public TreeNode invertTree(TreeNode root) {
if (root == null) {
return null;
}
invertTree(root.left);
invertTree(root.right);
swapChildren(root);
return root;
}
private void swapChildren(TreeNode root) {
TreeNode tmp = root.left;
root.left = root.right;
root.right = tmp;
}
}
中序遍历
代码虽然可以,但这毕竟不是真正的递归中序遍历了。看上去遍历两次left
//DFS递归
class Solution {
/**
* 前后序遍历都可以
* 中序不行,因为先左孩子交换孩子,再根交换孩子(做完后,右孩子已经变成了原来的左孩子),再右孩子交换孩子(此时其实是对原来的左孩子做交换)
*/
public TreeNode invertTree(TreeNode root) {
if (root == null) {
return null;
}
invertTree(root.left);
swapChildren(root);
invertTree(root.left);
return root;
}
private void swapChildren(TreeNode root) {
TreeNode tmp = root.left;
root.left = root.right;
root.right = tmp;
}
}
统一迭代法
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
Stack<TreeNode> stack = new Stack<>(); //可以插入null元素
TreeNode curl = root;
if(root != null) stack.push(curl);
while(!stack.empty()){
curl = stack.pop();// 将该节点弹出,查看节点是否需要访问
if(curl != null){
//下面再将右中左节点添加到栈中
if(curl.right != null){
stack.push(curl.right);
}// 添加右节点(空节点不入栈)
stack.push(curl);// 添加中节点
// 中节点的左右子树都放入了栈里,访问过,但是还没有处理,加入空节点做为标记。
stack.push(null);//key flag;
if(curl.left != null){
stack.push(curl.left);
}// 添加左节点(空节点不入栈)
}else{// 只有遇到空节点的时候,才将下一个节点放进结果集
curl =stack.pop();// 重新取出栈中元素
swapChildren(curl);
}
}
return root;
}
private void swapChildren(TreeNode root) {
TreeNode tmp = root.left;
root.left = root.right;
root.right = tmp;
}
}
101. 对称二叉树相似题型
101. 对称二叉树
层序遍历
层序遍历经过我的初步验证后失败,因为一层中分不清左子树右子树关系,如果放在栈中两两消除,非镜像也能消除,比如下面情况。
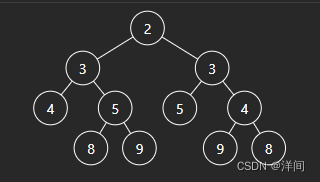
通过LInkedLIst存空值,并每次放入对称节点解决。
递归法
深度优先
class Solution {
public boolean isSymmetric(TreeNode root) {
if(root == null) return true;
return compare(root.left,root.right);
}
private boolean compare(TreeNode left, TreeNode right){
//节点有空时的情况
if(left == null && right == null){
return true;
}else if(left == null || right == null){
return false;
}//数值不同的情况
else if(left.val != right.val){
return false;
}
//此时,left/right都不为空且数值相等
//比较外侧数值,即 左子树的左 与 右子树的右
//boolean b1 = compare(left.left,right.right);
//比较内侧数值,即 左子树的右 与 右子树的左
//boolean b2 = compare(left.right,right.left);
//相当于提前判断b1,省去一部分递归
return compare(left.left,right.right) && compare(left.right,right.left);
}
}
迭代法
广度优先
初始化时我们把根节点入队两次。每次提取两个结点并比较它们的值(队列中每两个连续的结点应该是相等的,而且它们的子树互为镜像),然后将两个结点的左右子结点按相反的顺序插入队列中。当队列为空时,或者我们检测到树不对称(即从队列中取出两个不相等的连续结点)时,该算法结束。
注意:应该使用LinkedList而不是ArrayDeque,因为它无法插入null值。
class Solution {
public boolean isSymmetric(TreeNode root) {
if(root == null) return true;
//需要使用LinkedList,因为会添加空节点
//用栈其实也一样,因为相邻的两个两个取值,而且放的统一是内/外侧,所以从头取从尾取一样
Deque<TreeNode> que = new LinkedList<>();
que.offer(root.left);
que.offer(root.right);
while(!que.isEmpty()){
TreeNode leftNode = que.poll();
TreeNode rightNode = que.poll();
if(leftNode == null && rightNode == null){
continue;
}
if(leftNode == null || rightNode == null || leftNode.val != rightNode.val){
return false;
}
que.offer(leftNode.left);
que.offer(rightNode.right);
que.offer(leftNode.right);
que.offer(rightNode.left);
//如果是双端队列,可以换个顺序放,一样
//que.offerFirst(leftNode.left);
//que.offerFirst(leftNode.right);
//que.offerLast(rightNode.right);
//que.offerLast(rightNode.left);
}
return true;
}
}
100. Same Tree
允许添加空值,一次放入两个树的相同节点,每次取两个看是否相同
广度优先
class Solution {
public boolean isSameTree(TreeNode p, TreeNode q) {
Deque<TreeNode> que = new LinkedList<>();
que.offer(p);
que.offer(q);
while(!que.isEmpty()){
TreeNode node1 = que.poll();
TreeNode node2 = que.poll();
if( node1 == null && node2 == null){
continue;
}
if( node1 == null || node2 == null){
return false;
}
if( node1.val != node2.val){
return false;
}
// p与q都不为空且数值相等
que.offer(node1.left);
que.offer(node2.left);
que.offer(node1.right);
que.offer(node2.right);
}
return true;
}
}
深度优先
使用栈
把队列换成栈就行了
class Solution {
public boolean isSameTree(TreeNode p, TreeNode q) {
Deque<TreeNode> stack = new LinkedList<>();
stack.push(p);
stack.push(q);
while(!stack.isEmpty()){
TreeNode node1 = stack.poll();
TreeNode node2 = stack.poll();
if( node1 == null && node2 == null){
continue;
}
if( node1 == null || node2 == null){
return false;
}
if( node1.val != node2.val){
return false;
}
stack.push(node1.right);
stack.push(node2.right);
stack.push(node1.left);
stack.push(node2.left);
}
return true;
}
}
递归
class Solution {
public boolean isSameTree(TreeNode p, TreeNode q) {
if( p == null && q == null){
return true;
}
if( p == null || q == null || p.val != q.val){
return false;
}
return isSameTree(p.left,q.left) && isSameTree(p.right,q.right);
}
}
572. Subtree of Another Tree
暴力遍历
利用栈或队列 20ms(5%)
利用Same Tree,让每个节点都进行对比
class Solution {
public boolean isSubtree(TreeNode root, TreeNode subRoot) {
Deque<TreeNode> stack = new LinkedList<>();
stack.push(root);
//广度遍历不可行,深度遍历,利用栈
while(!stack.isEmpty()){
TreeNode t = stack.poll();
boolean flag = isSameTree(t,subRoot);
if(flag){
return true;
}
if(t.left != null) stack.push(t.left);
if(t.right != null) stack.push(t.right);
}
return false;
}
private boolean isSameTree(TreeNode p, TreeNode q) {
Deque<TreeNode> stack = new LinkedList<>();
stack.push(p);
stack.push(q);
while(!stack.isEmpty()){
TreeNode node1 = stack.poll();
TreeNode node2 = stack.poll();
if( node1 == null && node2 == null){
continue;
}
if( node1 == null || node2 == null){
return false;
}
if( node1.val != node2.val){
return false;
}
stack.push(node1.right);
stack.push(node2.right);
stack.push(node1.left);
stack.push(node2.left);
}
return true;
}
}
递归 3ms(82%),挺快的
class Solution {
public boolean isSubtree(TreeNode s, TreeNode t) {
return dfs(s, t);
}
//跟主函数分出来写,清晰点
public boolean dfs(TreeNode s, TreeNode t) {
if (s == null) {
return false;
}
// boolean b1 = isSameTree(s,t)//中
// boolean b2 = dfs(s.left,t);//左
// boolean b3 = dfs(s.right,t);//右
// return b1 | b2 | b3;
return isSameTree(s, t) || dfs(s.left,t) || dfs(s.right, t);
}
public boolean isSameTree(TreeNode p, TreeNode q) {
if( p == null && q == null){
return true;
}
if( p == null || q == null || p.val != q.val){
return false;
}
return isSameTree(p.left,q.left) && isSameTree(p.right,q.right);
}
}
时间复杂度:O(s*t)
空间复杂度:O(max{ds,dt}),ds为s的深度。
深度优先搜索序列上做串匹配
当我们使用固定遍历方式时,会生成树的序列,暴力遍历时把每个节点都进行重新匹配,相当于两次循环
可以使用KMP算法进行串匹配,极大的降低时间复杂度。
官方
class Solution {
List<Integer> sOrder = new ArrayList<Integer>();
List<Integer> tOrder = new ArrayList<Integer>();
int maxElement, lNull, rNull;
public boolean isSubtree(TreeNode s, TreeNode t) {
maxElement = Integer.MIN_VALUE;
getMaxElement(s);
getMaxElement(t);
lNull = maxElement + 1;
rNull = maxElement + 2;
getDfsOrder(s, sOrder);
getDfsOrder(t, tOrder);
return kmp();
}
//根据树的值范围,确定左右null值的选择
public void getMaxElement(TreeNode t) {
if (t == null) {
return;
}
maxElement = Math.max(maxElement, t.val);
getMaxElement(t.left);
getMaxElement(t.right);
}
//将树序列化
public void getDfsOrder(TreeNode t, List<Integer> tar) {
if (t == null) {
return;
}
tar.add(t.val);
if (t.left != null) {
getDfsOrder(t.left, tar);
} else {
tar.add(lNull);
}
if (t.right != null) {
getDfsOrder(t.right, tar);
} else {
tar.add(rNull);
}
}
//序列化后的树匹配,KMP算法
public boolean kmp() {
int sLen = sOrder.size(), tLen = tOrder.size();
int[] fail = new int[tOrder.size()];
Arrays.fill(fail, -1);
for (int i = 1, j = -1; i < tLen; ++i) {
while (j != -1 && !(tOrder.get(i).equals(tOrder.get(j + 1)))) {
j = fail[j];
}
if (tOrder.get(i).equals(tOrder.get(j + 1))) {
++j;
}
fail[i] = j;
}
for (int i = 0, j = -1; i < sLen; ++i) {
while (j != -1 && !(sOrder.get(i).equals(tOrder.get(j + 1)))) {
j = fail[j];
}
if (sOrder.get(i).equals(tOrder.get(j + 1))) {
++j;
}
if (j == tLen - 1) {
return true;
}
}
return false;
}
}
添加空值
我的第一版 5ms(9.19%)
其实不用根据树范围选取空值,因为序列化后的树,可以被序列唯一确定,所以只需要添加null值标识空就可。
class Solution {
public boolean isSubtree(TreeNode root, TreeNode subRoot) {
List<Integer> rootOrder = preorderTraversal(root);
List<Integer> subOrder = preorderTraversal(subRoot);
return KMP(rootOrder,subOrder);
}
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
Deque<TreeNode> stack = new LinkedList();
if(root == null){
return ans;
}
stack.push(root);
while(!stack.isEmpty()){
//前序遍历,要处理节点即访问到的节点
TreeNode t = stack.poll();
if(t != null){
ans.add(t.val);
stack.push(t.right);
stack.push(t.left);
}else{
ans.add(null);
}
}
return ans;
}
public boolean KMP(List<Integer> haystack, List<Integer>needle) {
int m = haystack.size();
int n = needle.size();
if(n == 0){
return false;
}
//初始化
int[] next = new int[n];
next[0] = -1;
//开始构造
for(int i = 1,j = -1; i < n; i++){
Integer before = needle.get(j+1);
Integer after = needle.get(i);
//匹配失败,调整j位置
while(j >= 0 && !(before == after) && (before == null || after == null || ! before.equals(after))){
j = next[j];
before = needle.get(j+1);
}
//匹配成功
if((before == after) || before.equals(after)){
j++;
}
next[i] = j;
}
// 因为next数组里记录的起始位置为-1,注意i就从0开始
for(int i = 0, j = -1; i< m ;i++){
Integer before = needle.get(j+1);
Integer after = haystack.get(i);
//匹配失败,调整j位置
while(j >= 0 && !(before == after) && (before == null || after == null || ! before.equals(after))){
j = next[j];
before = needle.get(j+1);
}
//匹配成功,before==after判断的是空值
if((before == after) || before.equals(after)){
j++;
}
//判断是否满足全匹配
if(j == n-1){
return true;//模式串出现的第一个位置 (从0开始)
}
}
return false;
}
}
优化版
第一版序列化较慢,使用递归函数快了2ms,使用Objects.equals()优化判断条件。 3ms(82.6%)
class Solution {
public boolean isSubtree(TreeNode root, TreeNode subRoot) {
List<Integer> rootOrder = new ArrayList<>();
List<Integer> subOrder = new ArrayList<>();
getDfsOrder(root, rootOrder);
getDfsOrder(subRoot, subOrder);
return KMP(rootOrder,subOrder);
}
public void getDfsOrder(TreeNode node, List<Integer> dfsorder) {
if (node == null) return;
dfsorder.add(node.val);
if (node.left == null) {
dfsorder.add(null);
} else {
getDfsOrder(node.left, dfsorder);
}
if (node.right == null) {
dfsorder.add(null);
} else {
getDfsOrder(node.right, dfsorder);
}
}
public boolean KMP(List<Integer> haystack, List<Integer>needle) {
int m = haystack.size();
int n = needle.size();
if(n == 0){
return false;
}
//初始化
int[] next = new int[n];
next[0] = -1;
//开始构造
for(int i = 1,j = -1; i < n; i++){
//匹配失败,调整j位置
while(j >= 0 && !(Objects.equals(needle.get(i),needle.get(j+1)))){
j = next[j];
}
//匹配成功
if(Objects.equals(needle.get(i),needle.get(j+1))){
j++;
}
next[i] = j;
}
// 因为next数组里记录的起始位置为-1,注意i就从0开始
for(int i = 0, j = -1; i< m ;i++){
//匹配失败,调整j位置
while(j >= 0 && !(Objects.equals(haystack.get(i),needle.get(j+1)))){
j = next[j];
}
//匹配成功
if(Objects.equals(haystack.get(i),needle.get(j+1))){
j++;
}
//判断是否满足全匹配
if(j == n-1){
return true;//模式串出现的第一个位置 (从0开始)
}
}
return false;
}
}
时间复杂度:O(s+t)
空间复杂度:O(s+t)
树哈希

官方代码
class Solution {
static final int MAX_N = 1005;
static final int MOD = 1000000007;
boolean[] vis = new boolean[MAX_N];
int[] p = new int[MAX_N];
int tot;
Map<TreeNode, int[]> hS = new HashMap<TreeNode, int[]>();
Map<TreeNode, int[]> hT = new HashMap<TreeNode, int[]>();
public boolean isSubtree(TreeNode s, TreeNode t) {
getPrime();
dfs(s, hS);
dfs(t, hT);
int tHash = hT.get(t)[0];
for (Map.Entry<TreeNode, int[]> entry : hS.entrySet()) {
if (entry.getValue()[0] == tHash) {
return true;
}
}
return false;
}
public void getPrime() {
vis[0] = vis[1] = true;
tot = 0;
for (int i = 2; i < MAX_N; ++i) {
if (!vis[i]) {
p[++tot] = i;
}
for (int j = 1; j <= tot && i * p[j] < MAX_N; ++j) {
vis[i * p[j]] = true;
if (i % p[j] == 0) {
break;
}
}
}
}
public void dfs(TreeNode o, Map<TreeNode, int[]> h) {
h.put(o, new int[]{o.val, 1});
if (o.left == null && o.right == null) {
return;
}
if (o.left != null) {
dfs(o.left, h);
int[] val = h.get(o);
val[1] += h.get(o.left)[1];
val[0] = (int) ((val[0] + (31L * h.get(o.left)[0] * p[h.get(o.left)[1]]) % MOD) % MOD);
}
if (o.right != null) {
dfs(o.right, h);
int[] val = h.get(o);
val[1] += h.get(o.right)[1];
val[0] = (int) ((val[0] + (179L * h.get(o.right)[0] * p[h.get(o.right)[1]]) % MOD) % MOD);
}
}
}
我的代码
感觉第三种解法存在问题,MAX_N规定了生成1005范围内的素数(共168个素数),所以p[169-1004]都为0并不是素数。
所以在节点个数大于169时p[sl]为0失去了hash的意义,而在节点个数大于1005时甚至会产生越界报错。
题目说了最多有2000个节点,所以应该生成2000个素数,大约在18000的范围内可以查找到2000个素数,所以MAX_N应该等于18000。 如果不想生成太多的素数,可以根据生成总数让素数在节点里循环,所以代码应该改为
val[0] = (int)(val[0] + 179L * right[0] * prime[right[1]%n]);
全部代码如下
class Solution {
//节点,(hash值,第几个素数)
Map<TreeNode, int[]> hS = new HashMap<TreeNode, int[]>();
Map<TreeNode, int[]> hT = new HashMap<TreeNode, int[]>();
//2000个节点,最多两千个数字,n/ln(n) = 264
int maxn = 2000;
int[] prime = new int[maxn]; //素数密度:n以内的素数大约是 n/ln(n)
boolean[] vis = new boolean[maxn]; //true为合数,默认false为素数
int n;//总数
public boolean isSubtree(TreeNode s, TreeNode t) {
//生成素树表
gener_prime();
//得到树hash
dfs(s, hS);
dfs(t, hT);
int tHash = hT.get(t)[0];
for (Map.Entry<TreeNode, int[]> entry : hS.entrySet()) {
//判定树1的子树是否存在hash相等树2的hash
if (entry.getValue()[0] == tHash) {
return true;
}
}
return false;
}
//欧拉筛
private void gener_prime(){
vis[0] = vis[1] = true;
for(int i =2; i< maxn; i++){
if(!vis[i]){
prime[++n] = i;
}
for(int j = 1; j<= n && i* prime[j] < maxn ;j++){
vis[i*prime[j]] = true;
if(i % prime[j] == 0) break;
}
}
}
private void dfs(TreeNode node, Map<TreeNode,int[]> h){
//前序遍历
//中
int[] val = new int[]{node.val,1};
h.put(node,val);//初始化
//左
if(node.left != null){
dfs(node.left,h);
int[] left = h.get(node.left);
val[1] = val[1] + left[1];
val[0] = (int)(val[0] + 31L * left[0] * prime[left[1]%n]);
}
//右
if(node.right != null){
dfs(node.right,h);
int[] right = h.get(node.right);
val[1] = val[1]+ right[1];
val[0] = (int)(val[0] + 179L * right[0] * prime[right[1]%n]);
}
}
}
生成素数表,判断素数的方法
1.逐一试除
从 2 ~ n^(1/2),一个一个试
bool is_prime(int x){
for(int i = 2; i*i<x; i++){
if(x%i==0) return false;
}
return ture;
}
2.埃式筛法
把所有素数的倍数筛去,O(nloglogn),问题是一个合数可能被多次筛选
从i*i 开始是因为它之前的合数 i * (2 ,3,…, i-1)已经被2 ,3,…, i-1算合数时筛选过了
int maxn = 1000000;//范围
boolean[] vis = new int[maxn]; //记录划掉的
int[] prime = new int[maxn/10]; //素数密度:n以内的素数大约是 n/ln(n)
int n;//总数
void gener_prime(){
vis[0] = vis[1] = true;
//0与1默认false,即为合数
for(i = 2; i < maxn; i++){
if(vis[i] == 0){
prime[n++] = i;
}
// 2*2 = 4, 2*3 = 6, 2*4 = 8
// 3*3 = 9, 3*4 = 12, 3*5 =15
for (int j = i*i; j <= maxn; j += i) {
visit[j] = 1;
}
}
}
bool is_prime(int x){
return !vis[x];
}
3.欧拉筛法
所有合数只被自己的 最小质因数 prime[j] * 最大真因数 i 筛一次,O(n),牛
(比如 18 = 2 * 9,prime[j]是最小质因数,i在其中充当倍数的作用)
如果此数的质因子在
n = p1× p2 × p3
int maxn = 1000000;//范围
boolean[] vis = new int[maxn]; //记录划掉的
int[] prime = new int[maxn/10]; //素数密度:n以内的素数大约是 n/ln(n)
int n;//总数
void gener_prime(){
vis[0] = vis[1] = true;
for(int i = 2; i<maxn; i++){
//从2开始往后遍历
if(vis[i] == 0){ //没被划拉过,是素数
prime[n++] = i;//添加到素数表里,目前n个
}
for(int j = 0; j < n && i*prime[j]<maxn; j++){//与素数表里每个数都相乘,得到合数
vis[i * prime[j]] == true;//划掉
if(i % prime[j] == 0) break;//关键点
}
}
}
bool is_prime(int x){
return !vis[x];
}

222.完全二叉树的节点个数
普通二叉树遍历
递归
class Solution {
public int countNodes(TreeNode root) {
if(root == null) return 0;
return 1 + countNodes(root.left) + countNodes(root.right);
}
}
层序遍历
class Solution {
public int countNodes(TreeNode root) {
int result = 0;
Deque<TreeNode> que = new ArrayDeque();
if(root != null){
que.offer(root);
}
while(!que.isEmpty()){
int size = que.size();
for(int i = 0; i<size; i++){
TreeNode t = que.poll();
result++;
if(t.left!=null) que.offer(t.left);
if(t.right!=null) que.offer(t.right);
}
}
return result;
}
}
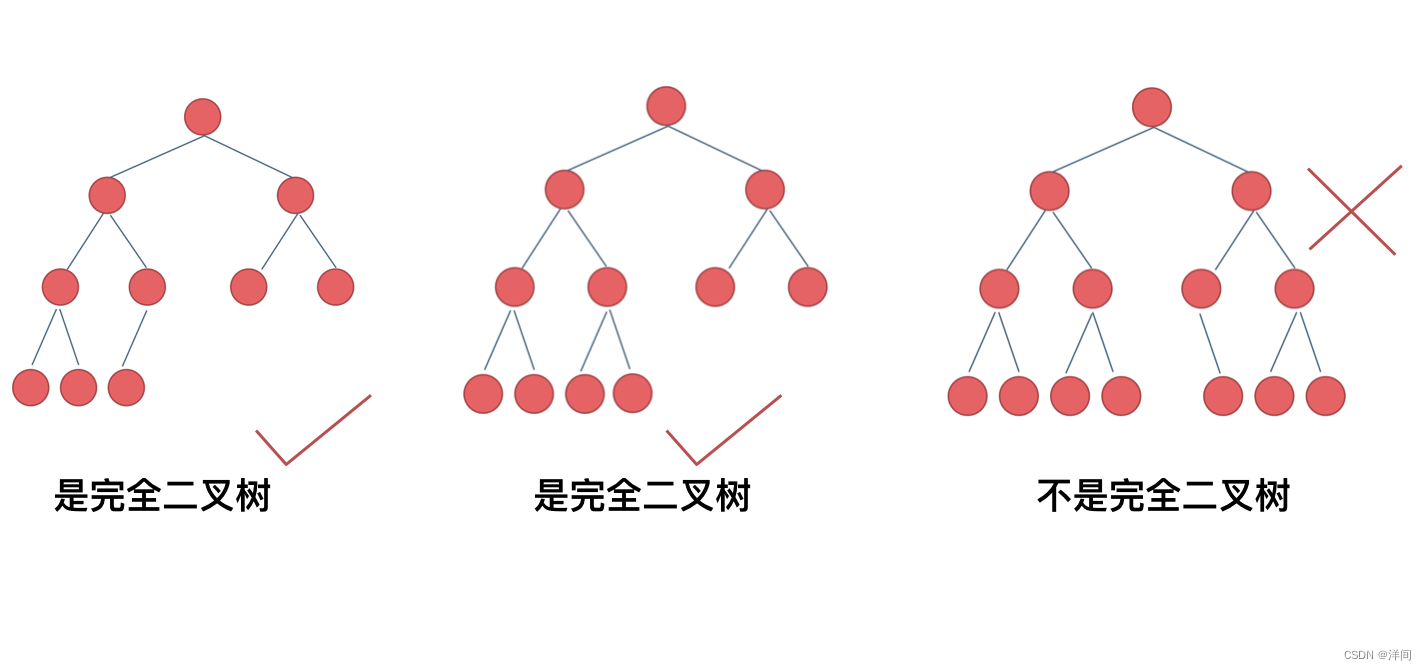
完全二叉树性质
在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1~ 2^(h-1) 个节点。
完全二叉树只有两种情况,情况一:就是满二叉树,情况二:最后一层叶子节点没有满。
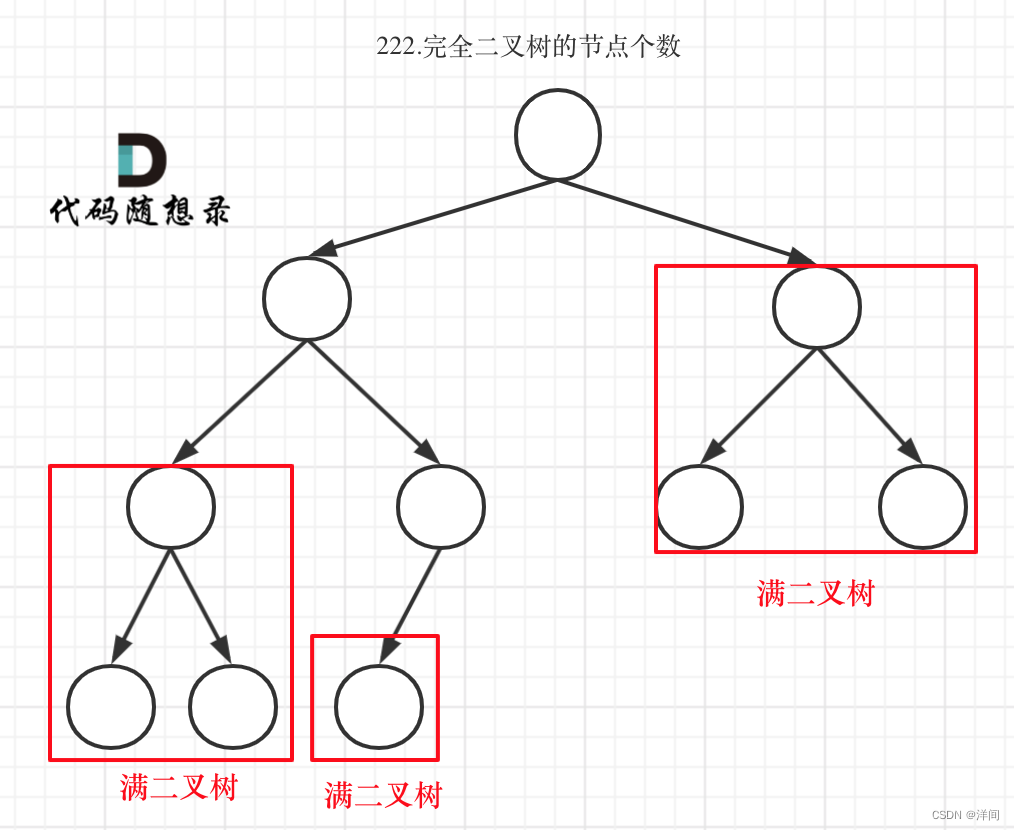
对于情况一,可以直接用 2^树深度 - 1 来计算,注意这里根节点深度为1。
对于情况二,分别递归左孩子,和右孩子,递归到某一深度一定会有左孩子或者右孩子为满二叉树,然后依然可以按照情况1来计算。
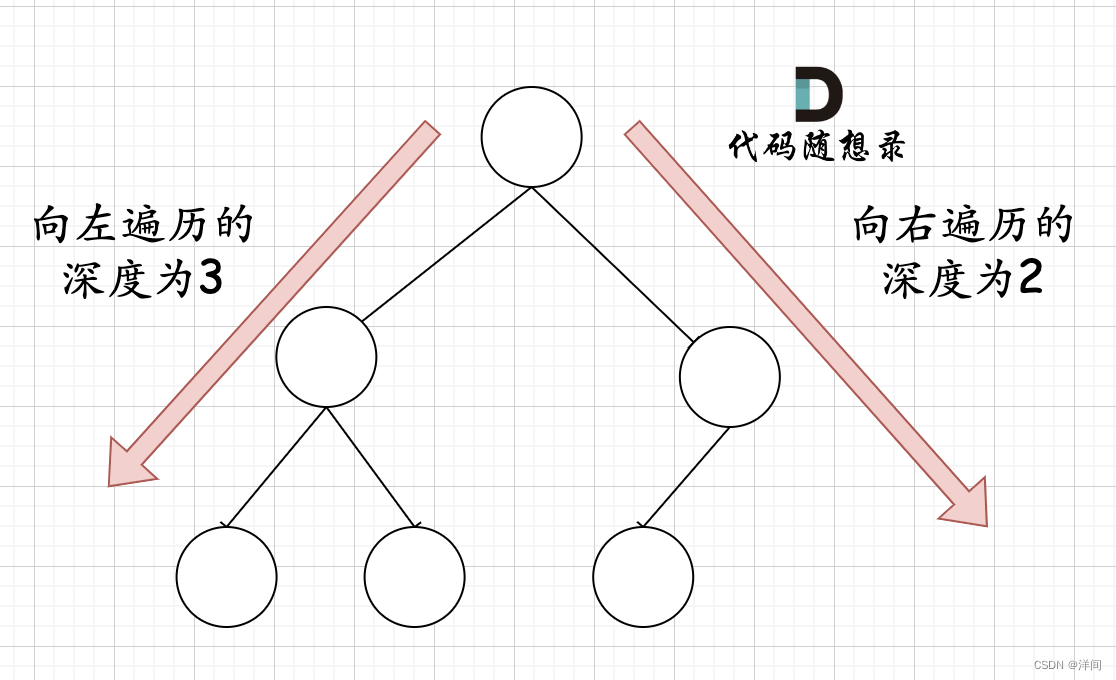
可以看出如果整个树不是满二叉树,就递归其左右孩子,直到遇到满二叉树为止,用公式计算这个子树(满二叉树)的节点数量。
在完全二叉树中,如果递归向左遍历的深度等于递归向右遍历的深度,那说明就是满二叉树。
class Solution {
public int countNodes(TreeNode root) {
if(root == null) return 0;
//判断此子树是不是满二叉树
TreeNode left = root.left;
TreeNode right = root.right;
int leftDepth = 0;
int rightDepth = 0;
while(left != null){
left = left.left;
leftDepth++;
}
while(right != null){
right = right.right;
rightDepth++;
}
//如果是,直接得出节点数
if(leftDepth == rightDepth){
//2<<leftDepth相当于2^(leftdepth+1),而leftDepth就是depth-1
//所以2<<leftDepth = 2^depth
//返回满足满二叉树的子树节点数量
return (2<<leftDepth)-1;
}
//如果不是,遍历子节点再计算
int leftNum = countNodes(root.left); //左子树,直到找到满二叉树(或叶子节点)
int rightNum = countNodes(root.right);//右,同理
return 1+ leftNum + rightNum;//中
}
}
- 时间复杂度:O(log n × log n)
- 空间复杂度:O(log n)
110.平衡二叉树
平衡二叉树:一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 。
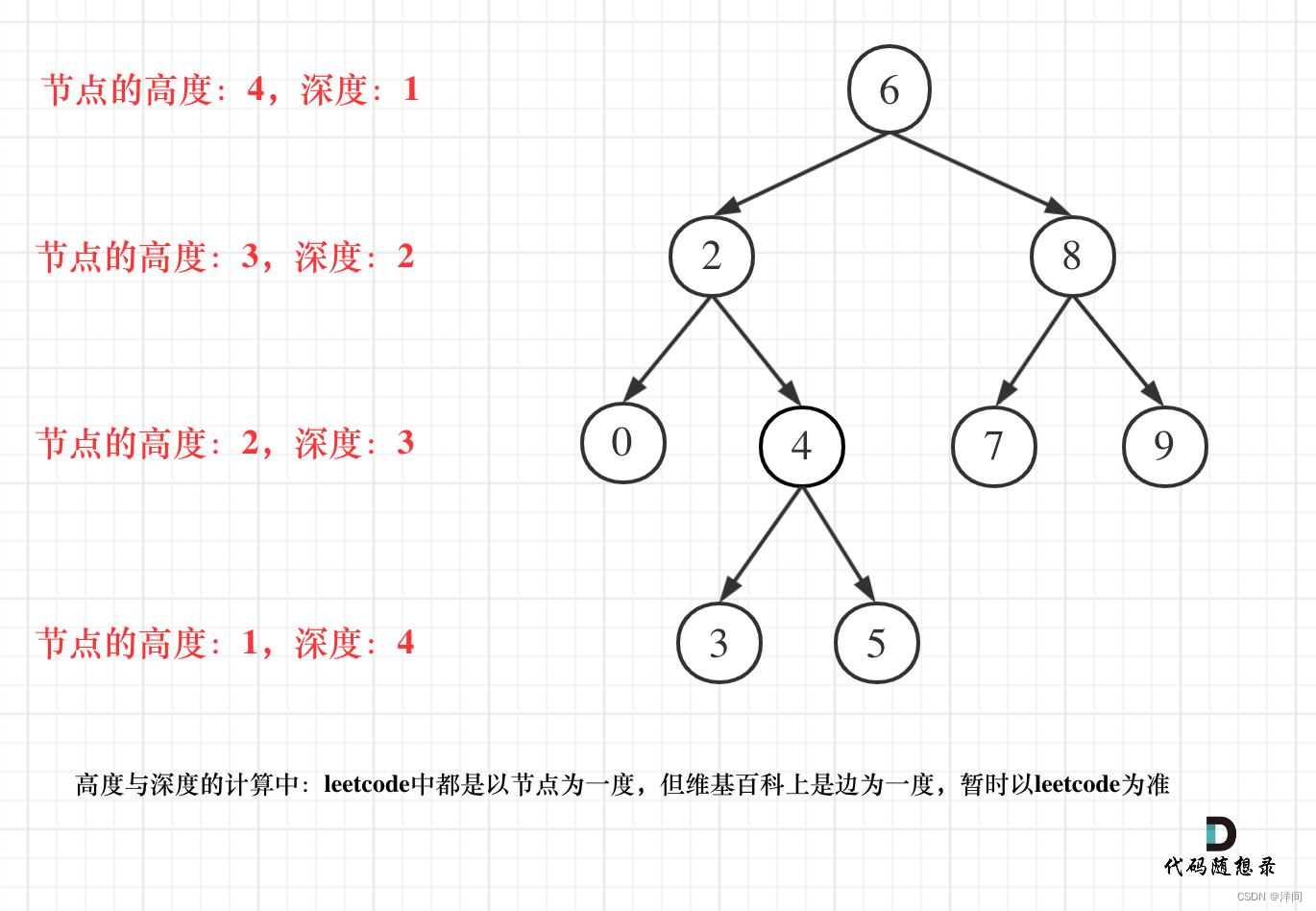
前序遍历和层序遍历可以用来求深度,但不能求得节点高度是多少,本题要得到子树节点的高度,所以采用后序遍历比较好。
递归
后序遍历
因为depth>=0,所以用-1来进行标识左右子树高度差大于-1,并向上传导,求左右子树深度并对比,时间复杂度O(n)
class Solution {
public boolean isBalanced(TreeNode root) {
return treeDepth(root) > -1;
}
private int treeDepth(TreeNode node){
//空节点高度为0
if(node == null){
return 0;
}
//左节点高度
int left = treeDepth(node.left);
if(left == -1){
return -1;
}
//右节点高度
int right = treeDepth(node.right);
if(right == -1){
return -1;
}
//左右差大于1则标记不符
int subValue = left > right ? left - right: right - left;
if(subValue >1){
return -1;
}
//中节点高度
return 1 + Math.max(left,right);
}
}
先序遍历
自顶向下的递归,每个节点都求下左右子树高度O(n^ 2)
class Solution {
public boolean isBalanced(TreeNode root) {
if (root == null) {
return true;
} else {
return Math.abs(height(root.left) - height(root.right)) <= 1 //中
&& isBalanced(root.left) //左
&& isBalanced(root.right); //右
}
}
public int height(TreeNode root) {
if (root == null) {
return 0;
} else {
return Math.max(height(root.left), height(root.right)) + 1;
}
}
}
时间复杂度O(n^2)
迭代
下面两个迭代方法的时间复杂度为O(n^2),不建议迭代!!
后序遍历
通过栈模拟的后序遍历找每一个节点的高度(其实是通过求传入节点为根节点的最大深度来求的高度)
通过栈模拟的后序遍历找每一个节点的高度(其实是通过求传入节点为根节点的最大深度来求的高度)
class Solution {
/**
* 迭代法,效率较低,计算高度时会重复遍历
* 时间复杂度:O(n^2)
*/
public boolean isBalanced(TreeNode root) {
if (root == null) {
return true;
}
Stack<TreeNode> stack = new Stack<>();
TreeNode pre = null;
while (root!= null || !stack.isEmpty()) {
while (root != null) {
stack.push(root);
root = root.left;
}//左
TreeNode inNode = stack.peek();
// 右结点为null或已经遍历过
if (inNode.right == null || inNode.right == pre) {
// 比较左右子树的高度差,输出,中
if (Math.abs(getHeight(inNode.left) - getHeight(inNode.right)) > 1) {
return false;
}
stack.pop();
pre = inNode;
root = null;// 当前结点下,没有要遍历的结点了
} else {
root = inNode.right;// 右结点还没遍历,遍历右结点
}
}
return true;
}
/**
* 层序遍历,求结点的高度
*/
public int getHeight(TreeNode root) {
if (root == null) {
return 0;
}
Deque<TreeNode> deque = new LinkedList<>();
deque.offer(root);
int depth = 0;
while (!deque.isEmpty()) {
int size = deque.size();
depth++;
for (int i = 0; i < size; i++) {
TreeNode poll = deque.poll();
if (poll.left != null) {
deque.offer(poll.left);
}
if (poll.right != null) {
deque.offer(poll.right);
}
}
}
return depth;
}
}
前序遍历
/**
* 前序遍历,访问所有节点
*/
public boolean isBalanced(TreeNode root) {
if (root == null) {
return true;
}
Deque<TreeNode> stack = new LinkedList<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode node = stack.poll();//中
if(Math.abs(getHeight(node.left) - getHeight(node.right)) >1){
return false;
}
if(node.right != null) stack.push(node.right);//右
if(node.left != null) stack.push(node.left);//左
}
return true;
}
/**
* 层序遍历,求结点的高度
*/
public int getHeight(TreeNode root) {
if (root == null) {
return 0;
}
Deque<TreeNode> deque = new LinkedList<>();
deque.offer(root);
int depth = 0;
while (!deque.isEmpty()) {
int size = deque.size();
depth++;
for (int i = 0; i < size; i++) {
TreeNode poll = deque.poll();
if (poll.left != null) {
deque.offer(poll.left);
}
if (poll.right != null) {
deque.offer(poll.right);
}
}
}
return depth;
}
257. 二叉树的所有路径
借用Map存储每个节点的路线字符串
时间复杂度O(n),不过涉及Map操作
迭代的先序遍历(10ms)
class Solution {
public List<String> binaryTreePaths(TreeNode root) {
return pathFinder(root);
}
private List<String> pathFinder(TreeNode root){
if(root == null){
return null;
}
List<String> result = new ArrayList<>();
Deque<TreeNode> stack = new LinkedList<>();
Map<TreeNode,String> map = new HashMap<>();
stack.push(root);
map.put(root,String.valueOf(root.val));
while(!stack.isEmpty()){
TreeNode node = stack.poll();
String value = map.get(node);
//叶子节点
if(node.right == null && node.left == null){
result.add(value);
}
//右
if(node.right != null){
stack.push(node.right);
String right = value+"->"+ String.valueOf(node.right.val);
map.put(node.right,right);
}
//左
if(node.left != null){
stack.push(node.left);
String left = value+"->"+ String.valueOf(node.left.val);
map.put(node.left,left);
}
}
return result;
}
}
递归的先序遍历(7ms)
class Solution {
public List<String> binaryTreePaths(TreeNode root) {
List<String> result = new ArrayList<>();
Map<TreeNode,String> map = new HashMap<>();
map.put(root,String.valueOf(root.val));
pathRecursive(root,result,map);
return result;
}
//先序遍历
private void pathRecursive(TreeNode node, List<String> result, Map<TreeNode,String> map){
if(node == null){
return;
}
String value = map.get(node);
//叶子节点
if(node.right == null && node.left == null){
result.add(value);
}
//左
if(node.left != null){
String leftString = value+"->"+ String.valueOf(node.left.val);
map.put(node.left,leftString);
pathRecursive(node.left,result,map);
}
//右
if(node.right != null){
String rightString = value+"->"+ String.valueOf(node.right.val);
map.put(node.right,rightString);
pathRecursive(node.right,result,map);
}
}
}
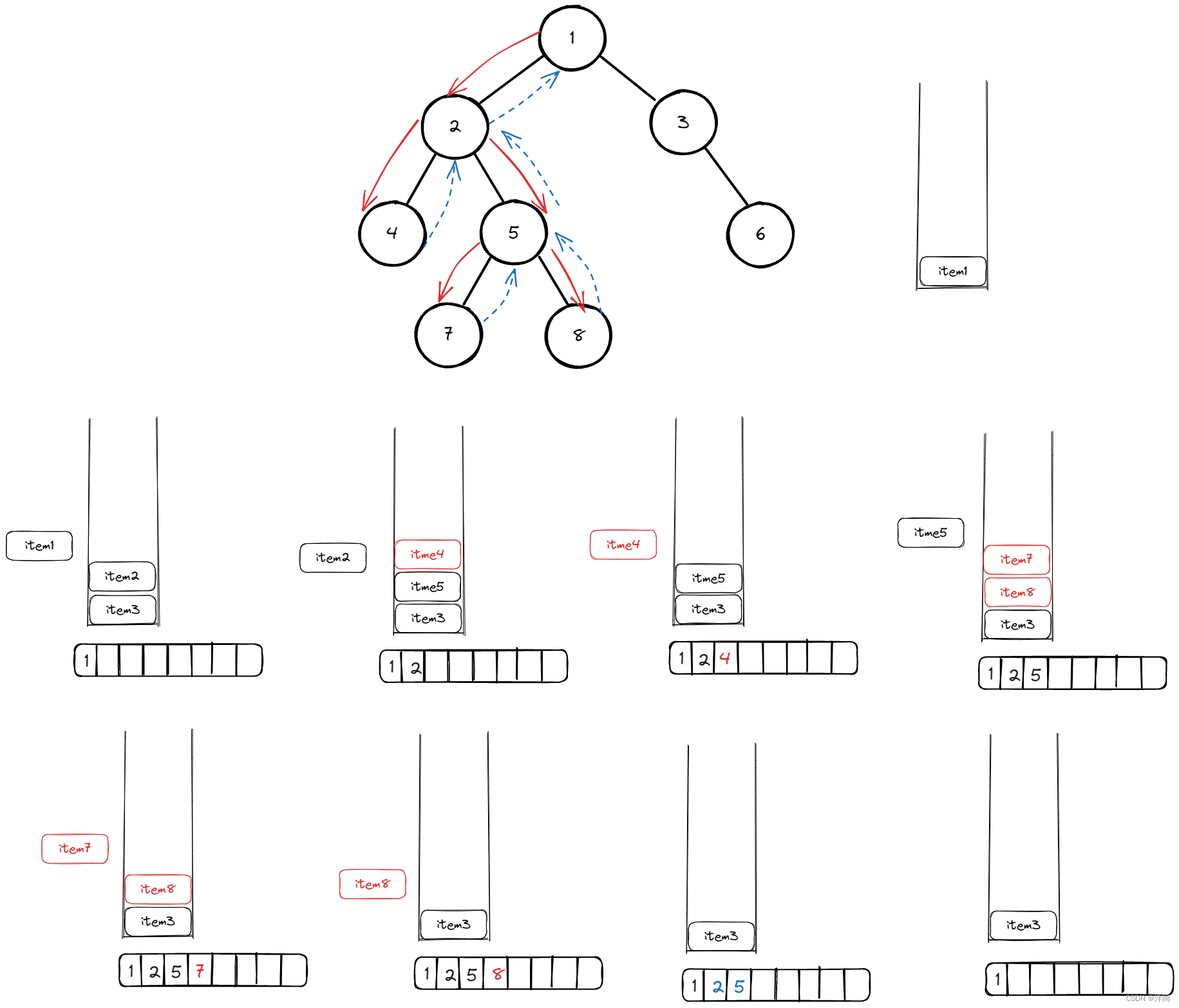
回溯+递归
数组存储路径(1ms)
相当于用一个数组,存储遍历过的节点,关键是在什么时候需要去除数组里的节点
在每次递归遍历时,将之前的元素记录一下就可以,但是在每次出递归时结果中也需要移除元素,因为当前元素被添加了进去
class Solution {
public List<String> binaryTreePaths(TreeNode root) {
List<String> result = new ArrayList<>();
List<Integer> path = new ArrayList<>();
if(root == null){
return null;
}
pathRecursive(root,result,path);
return result;
}
//先序遍历
private void pathRecursive(TreeNode node, List<String> result,List<Integer> path){
path.add(node.val);//中
//叶子节点
if(node.right == null && node.left == null){
//遍历path,转化为String
StringBuilder builder = new StringBuilder();
for(int i = 0 ; i<path.size() - 1; i++){
builder.append(path.get(i));
builder.append("->");
}
builder.append(path.get(path.size()-1));
result.add(builder.toString());
//return加不加都行,进入循环下面两个条件就不符
return;
}
//左
if(node.left != null){
pathRecursive(node.left,result,path);
path.remove(path.size()-1);
}
//右
if(node.right != null){
pathRecursive(node.right,result,path);
path.remove(path.size()-1);
}
}
}
String存储当前路径(1~8ms)
Java中String是不变的,所以即使path传入子函数中,当path想改变内容其指针也改变,所以上层函数path仍不变。可利用java特性(或者c++传入参数的复制,形式参数而不是&地址的拷贝)存储当前路径。
初版(8ms)
class Solution {
public List<String> binaryTreePaths(TreeNode root) {
List<String> result = new ArrayList<>();
String path = new String();
if(root == null){
return null;
}
pathRecursive(root,result,path);
return result;
}
//先序遍历
private void pathRecursive(TreeNode node, List<String> result,String path){
path = path + node.val; //中
//StringBuilder pathSB = new StringBuilder(path);
//叶子节点
if(node.right == null && node.left == null){
result.add(path);
return;
}
//或者path = path + "->";
//左
if(node.left != null) pathRecursive(node.left,result,path+"->");
//右
if(node.right != null) pathRecursive(node.right,result,path+"->");
}
}
代码优化版(1ms)
使用StringBuilder替换了String拼接,没想到时间差距挺大将近十倍,所以Java有字符串拼接操作一定要用StringBuilder
class Solution {
public List<String> binaryTreePaths(TreeNode root) {
List<String> result = new ArrayList<>();
if(root == null) return null;
pathRecursive(root,result,"");
return result;
}
//先序遍历
private void pathRecursive(TreeNode node, List<String> result,String path){
StringBuilder pathSB = new StringBuilder(path);
pathSB.append(String.valueOf(node.val));
//叶子节点
if(node.right == null && node.left == null){
result.add(pathSB.toString());
}else{
pathSB.append("->");
if(node.left != null) pathRecursive(node.left,result,pathSB.toString()); //左
if(node.right != null) pathRecursive(node.right,result,pathSB.toString()); //右
}
}
}
利用Stack存储遍历路径
迭代的先序遍历(2ms)
基本跟利用Map的迭代思路相同,同时使用一个Object栈来存储此节点路径而不是map,同理也可用队列层序遍历
class Solution {
public List<String> binaryTreePaths(TreeNode root) {
List<String> result = new ArrayList<>();
if (root == null) return result;
Deque<Object> stack = new LinkedList<>();
// 节点和路径同时入栈
stack.push(root);
//stack.push(String.valueOf(root.val))
stack.push(root.val + "");
while (!stack.isEmpty()) {
// 节点和路径同时出栈
String path = (String) stack.poll();
TreeNode node = (TreeNode) stack.poll();
// 若找到叶子节点
if (node.left == null && node.right == null) {
result.add(path);
}
//右子节点不为空
if (node.right != null) {
stack.push(node.right);
stack.push(new StringBuilder(path).append("->").append(node.right.val).toString());
}
//左子节点不为空
if (node.left != null) {
stack.push(node.left);
stack.push(new StringBuilder(path).append("->").append(node.right.val).toString());
}
}
return result;
}
}
404.左叶子之和
迭代
前序遍历(1ms)
其实任何一种遍历都可以,只要每个节点都判断 其左子节点 是否为叶子节点
class Solution {
public int sumOfLeftLeaves(TreeNode root) {
int sum = 0;
Deque<TreeNode> stack = new LinkedList<>();
if(root != null) stack.push(root);
while(!stack.isEmpty()){
TreeNode node = stack.poll();
//右节点
if(node.right != null) stack.push(node.right);
//左节点
if(node.left != null){
//如果是叶子节点
if(node.left.right == null && node.left.left == null){
sum = sum + node.left.val;
}else{
stack.push(node.left);
}
}
}
return sum;
}
}
递归
后序遍历
递归的遍历顺序为后序遍历(左右中),是因为要通过递归函数的返回值来累加求取左叶子数值之和。
class Solution {
public int sumOfLeftLeaves(TreeNode root) {
if (root == null) return 0;
int leftValue = sumOfLeftLeaves(root.left); // 左
//左子节点是叶子节点,则leftValue = 0,可以覆盖
if (root.left != null && root.left.left == null && root.left.right == null) {
leftValue = root.left.val;
}
int rightValue = sumOfLeftLeaves(root.right); // 右
int sum = leftValue + rightValue; // 中
return sum;
}
}
513.找树左下角的值
递归
需要类里的两个全局变量,bottomDepth用来记录最大深度,result记录最大深度最左节点的数值。最大深度时记录第一个值即可(遍历保证先左子节点)
我的
class Solution {
int bottomDepth = 0;
int result = 0;
public int findBottomLeftValue(TreeNode root) {
findValue(root,1);
return result;
}
//递归遍历
public void findValue(TreeNode node, int depth){
if(node == null) return;
//左,其实什么顺序都可
findValue(node.left,depth+1);
//右
findValue(node.right,depth+1);
//叶子节点,在最后一层左边,且层数大
//中,depth>bottomDepth保证,记录在最后一层的第一个节点
//而前序、中序、后续遍历都保证,先访问左子节点,再访问右子节点
if(node.left == null && node.right== null
&& depth > bottomDepth){
result = node.val;
bottomDepth = depth;
}
}
官方
可以每个深度遍历时都存储resullt,最后返回时就是最深的最左边,此时不用判断是否为叶子节点
class Solution {
int bottomDepth = 0;
int result = 0;
public int findBottomLeftValue(TreeNode root) {
findValue(root,1);
return result;
}
//递归遍历
public void findValue(TreeNode node, int depth){
if(node == null) return;
//左,其实什么顺序都可
findValue(node.left,depth+1);
//右
findValue(node.right,depth+1);
//中,depth>bottomDepth保证,记录在最后一层的第一个节点
//而前序、中序、后续遍历都保证,先访问左子节点,再访问右子节点
if(depth > bottomDepth){
result = node.val;
bottomDepth = depth;
}
}
}
层序遍历
最容易想到的就是层序遍历,如果从左到右遍历,只需要记录最后一行第一个节点的数值就可以了。
从左到右遍历
class Solution {
public int findBottomLeftValue(TreeNode root) {
int result = 0;
Deque<TreeNode> que = new ArrayDeque<>();//ArrayDeque快一点,在没有null值时好用
if(root != null){
que.offer(root);
}
//最底层的最左孩子,所以使用层序遍历
while(!que.isEmpty()){
int size = que.size();
result = que.peek().val;// 记录最后一行第一个元素
for(int i = 0 ; i< size; i++){
TreeNode node = que.poll();
if(node.left != null) que.offer(node.left);
if(node.right != null) que.offer(node.right);
}
}
return result;
}
}
从右到左遍历
从右到左遍历的话,只需要记录最后一个节点即可
class Solution {
public int findBottomLeftValue(TreeNode root) {
int result = 0;
Queue<TreeNode> que = new ArrayDeque<TreeNode>();
que.offer(root);
while (!que.isEmpty()) {
TreeNode node = queue.poll();
if (node.right != null) {
que.offer(node.right);
}
if (node.left != null) {
que.offer(node.left);
}
result = node.val;
}
return result;
}
}
112. 路径总和
递归
List存储路径
借用所有路径的方法,存储所有遍历节点,到叶子节点则遍历其路径求和,看是否符合(1ms)
class Solution {
public boolean hasPathSum(TreeNode root, int targetSum) {
return dfs(root, new ArrayList<>(),targetSum);
}
public boolean dfs(TreeNode node,List<Integer> path, int targetSum){
if(node == null) return false;
path.add(node.val);
//叶子节点
if(node.right == null && node.left == null){
int sum = 0;
for(Integer num : path){
sum += num;
}
if(sum == targetSum){
return true;
}else{
return false;
}
}
boolean flag = false;
if(node.left != null){
flag = dfs(node.left,path,targetSum);
if(flag == true){
return true;
}
path.remove(path.size()-1);
}
if(node.right != null){
flag = dfs(node.right,path,targetSum);//递归,判断
if(flag == true){
return true;
}
path.remove(path.size()-1);//回溯,把此遍历过的节点去除
}
return false;
}
}
int存储当前状态
其实不需要存储路径,只需要存储遍历到当前节点的结果值,如果是叶子节点,则判断一路上之和是否满足targerSum,可以直接在targetSum上作为变化的参数,叶子结点的tagetSum == 0 则说明满足,一路返回即可。
第一版
class Solution {
public boolean hasPathSum(TreeNode root, int targetSum) {
return dfs(root, targetSum);
}
public boolean dfs(TreeNode node,int targetSum){
if(node == null) return false;
//targetSum -= node.val;
//叶子节点
if(node.right == null && node.left == null){
if(targetSum == node.val){
return true;
}else{
return false;
}
}
boolean flag = false;
if(node.left != null){
flag = dfs(node.left,targetSum-node.val);//java隐藏回溯
if(flag == true) return true;
}
if(node.right != null){
flag = dfs(node.right,targetSum-node.val);//隐藏回溯
if(flag == true) return true;
}
return false;
}
}
优化版
优化了很多不必要的if判断
class Solution {
public boolean hasPathSum(TreeNode root, int targetSum) {
return dfs(root, targetSum);
}
public boolean dfs(TreeNode node,int targetSum){
if(node == null) return false;
if(node.right == null && node.left == null) return targetSum == node.val;//叶子节点
//不判断空值,通过||优化返回值
return dfs(node.left,target - node.val)|| dfs(node.right,targetSum - node.val);
}
}
迭代
利用栈/队列
利用Object栈/队列多存一个当前节点的累计值,任何方法遍历都可以。(2ms)
class Solution {
public boolean hasPathSum(TreeNode root, int targetSum) {
Deque<Object> stack = new LinkedList<>();
if(root != null){
stack.push(root);
stack.push(root.val);
}
while(!stack.isEmpty()){
int num = (int)stack.poll();
TreeNode node = (TreeNode)stack.poll();
if(node.right == null && node.left == null && num == targetSum){
return true;
}
if(node.right != null){
stack.push(node.right);
stack.push(num + node.right.val);
}
if(node.left != null){
stack.push(node.left);
stack.push(num + node.left.val);
}
}
return false;
}
}
113. 路径总和ii
递归(List存储访问路径)
我的(2ms,14%)
利用path存储已经访问过的路径,注意path对象会随着遍历改变,如果想将当前路径添加到result中,需要新建对象复制当前path路线。(2ms)
class Solution {
List<List<Integer>> result = new ArrayList<>();
public List<List<Integer>> pathSum(TreeNode root, int targetSum) {
dfs(root,new ArrayList<>(),targetSum);
return result;
}
public void dfs(TreeNode node,List<Integer> path, int targetSum){
if(node == null) return;
path.add(node.val);
//叶子节点
if(node.right == null && node.left == null){
int sum = 0;
for(Integer num : path){
sum += num;
}
if(sum == targetSum){
//不能添加path,是个对象(指针),会随着遍历变化!!
result.add(new ArrayList<Integer>(path));
}
return;
}
if(node.left != null){
dfs(node.left,path,targetSum);
path.remove(path.size()-1);
}
if(node.right != null){
dfs(node.right,path,targetSum);//递归,判断
path.remove(path.size()-1);//回溯,把此遍历过的节点去除
}
}
}
优化(1ms,99%)
可利用targetSum随着遍历变化,而省去遍历path求和的时间
class Solution {
List<List<Integer>> result = new ArrayList<>();
public List<List<Integer>> pathSum(TreeNode root, int targetSum) {
if(root == null) return;
dfs(root,new ArrayList<Integer>(),targetSum);
return result;
}
public void dfs(TreeNode node,List<Integer> path, int targetSum){
path.add(node.val);
targetSum = targetSum - node.val;
//叶子节点
if(node.right == null && node.left == null){
if(targetSum == 0){
result.add(new ArrayList<Integer>(path));
}
return;
}
if(node.left != null){
dfs(node.left,path,targetSum);
path.remove(path.size()-1);
}
if(node.right != null){
dfs(node.right,path,targetSum);//递归,判断
path.remove(path.size()-1);//回溯,把此遍历过的节点去除
}
}
}
或者优化2
class Solution {
List<List<Integer>> result;
public List<List<Integer>> pathSum(TreeNode root, int targetSum) {
result = new ArrayList<>();
dfs(root,new ArrayList<Integer>(),targetSum);
return result;
}
public void dfs(TreeNode node,List<Integer> path, int targetSum){
if (root == null) return;
path.add(node.val);
targetSum -= node.val;
if(node.right == null && node.left == null && targetsum == 0){
result.add(new ArrayList<Integer>(path)); //叶子节点
}
dfs(node.left,path,targetSum);
dfs(node.right,path,targetSum);//递归,判断
//回溯,把此遍历过的节点去除
//此时回溯只用回溯一次,因为只有子节点都为null或遍历完毕时返回,此时去除当前节点
path.remove(path.size()-1);
}
}
迭代
层序遍历,用图存储父节点(3ms,6%)
维护图以及图的遍历更耗时
class Solution {
List<List<Integer>> result = new LinkedList<List<Integer>>();
Map<TreeNode, TreeNode> map = new HashMap<TreeNode, TreeNode>();
public List<List<Integer>> pathSum(TreeNode root, int targetSum) {
if (root == null) {
return result;
}
Queue<TreeNode> queueNode = new LinkedList<TreeNode>();
Queue<Integer> queueSum = new LinkedList<Integer>();
queueNode.offer(root);
queueSum.offer(0);
while (!queueNode.isEmpty()) {
TreeNode node = queueNode.poll();
int num = queueSum.poll() + node.val;
if (node.left == null && node.right == null) {
if (num == targetSum) {
getPath(node);
}
} else {
if (node.left != null) {
map.put(node.left, node);
queueNode.offer(node.left);
queueSum.offer(num);
}
if (node.right != null) {
map.put(node.right, node);
queueNode.offer(node.right);
queueSum.offer(num);
}
}
}
return result;
}
public void getPath(TreeNode node) {
List<Integer> temp = new LinkedList<Integer>();
while (node != null) {
temp.add(node.val);
node = map.get(node);
}
Collections.reverse(temp);//从底向上找的,所以反转
result.add(new LinkedList<Integer>(temp));
}
}
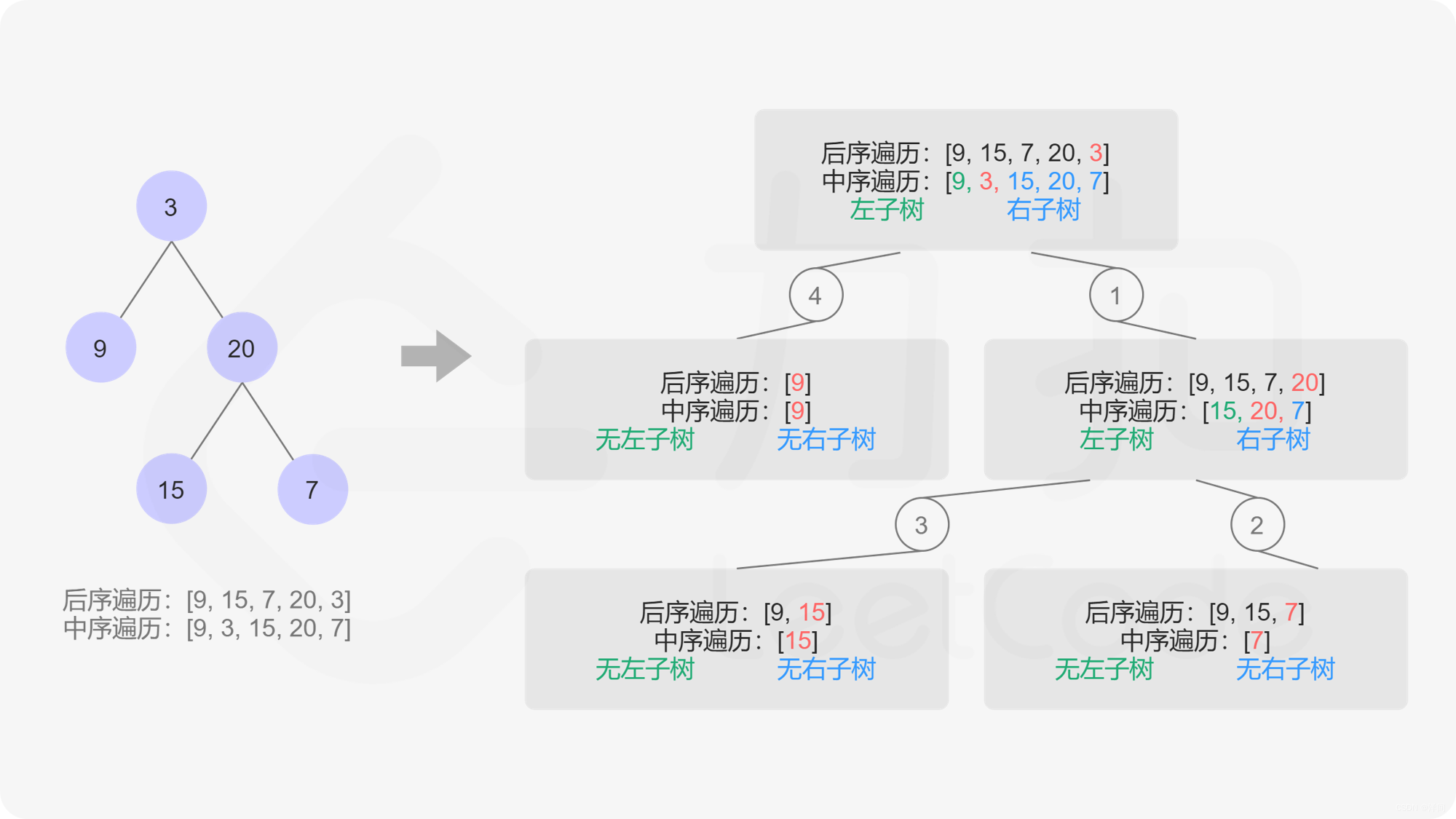
106.从中序与后序遍历序列构造二叉树
递归
使用Arrays静态方法copy数组
每次进入递归,使用Arrays分出中序、后续的左右子树(6ms,15.78%)
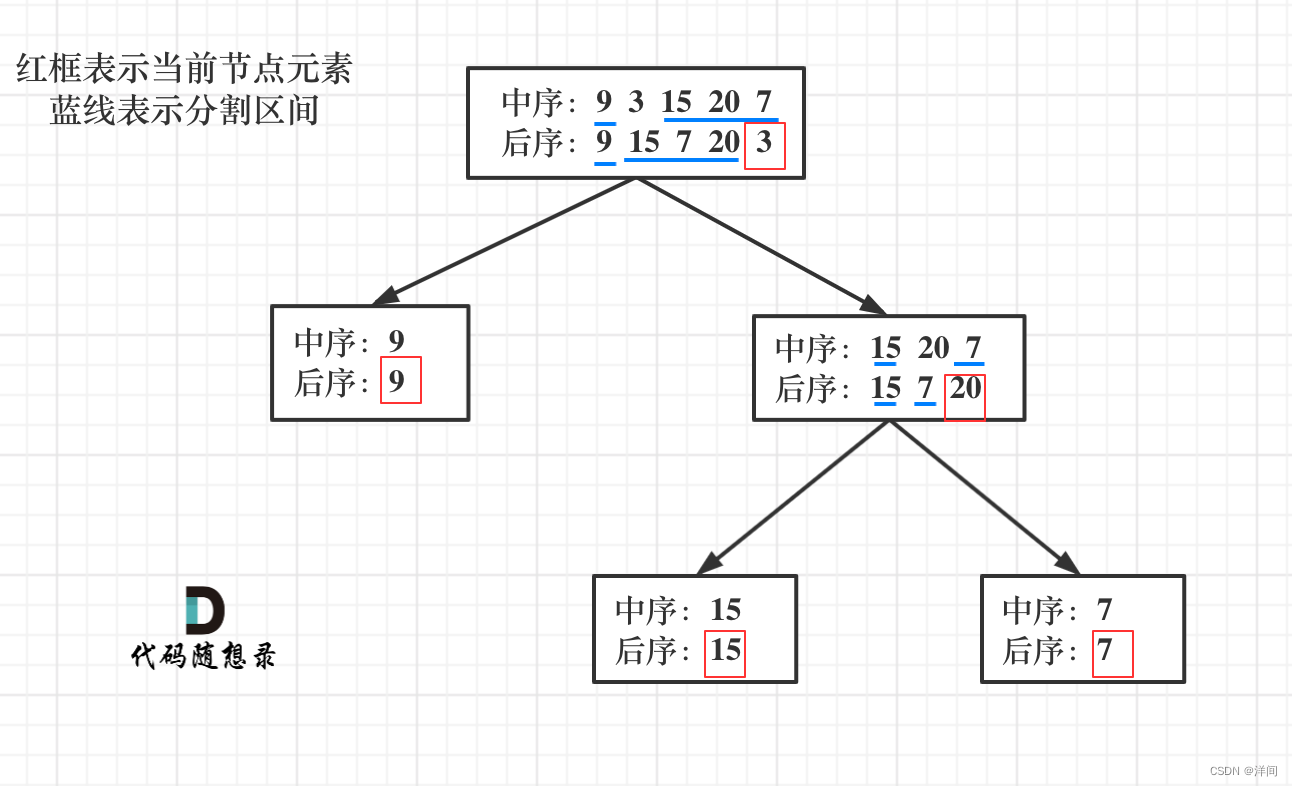
class Solution {
public TreeNode buildTree(int[] inorder, int[] postorder) {
return buildingTree(inorder,postorder);
}
public TreeNode buildingTree(int[] inorder, int[] postorder){
if(inorder.length == 0){
return null;
}
int middle = postorder[postorder.length - 1];
TreeNode node = new TreeNode(middle);
//叶子节点
if(inorder.length == 1){
return node;
}
//切割中序数组
int size = 0;
for(size = 0 ;size < inorder.length; size++){
if(inorder[size] == middle){
break;
}
}
//Arrays.copyOfRange(data,from,to);
//from - 要复制的范围的初始索引(包括)
//to - 要复制的范围的最终索引,不包括。 (此索引可能位于数组之外。)
int[] firstIn = Arrays.copyOfRange(inorder,0,size);
int[] secondIn = Arrays.copyOfRange(inorder,size+1,inorder.length);
//切割后序数组
int[] firstPost = Arrays.copyOfRange(postorder,0,size);
int[] secondPost = Arrays.copyOfRange(postorder,size,postorder.length-1);
node.left = buildingTree(firstIn,firstPost);
node.right = buildingTree(secondIn,secondPost);
return node;
}
}
使用下标操作原数组
不复制数组,复制数组耗费时间和空间,通过下标关系来判断操作范围(3ms,38.55%)
class Solution {
Map<Integer, Integer> idx_map = new HashMap<Integer, Integer>();
public TreeNode buildTree(int[] inorder, int[] postorder) {
return buildingTree(inorder,0,inorder.length,postorder,0,postorder.length);
}
public TreeNode buildingTree(int[] inorder,int inorderStart,int inorderEnd, int[] postorder,int postorderStart,int postorderEnd){
if(postorderStart == postorderEnd){
return null;
}
int middle = postorder[postorderEnd-1];
TreeNode node = new TreeNode(middle);
//叶子节点
//if(postorderEnd - postorderStart == 1) return node;
//切割中序数组
int size;
for(size = inorderStart ;size < inorderEnd; size++){
if(inorder[size] == middle){
break;
}
}
//切割中序数组
int leftInorderStart = inorderStart;
int leftInorderEnd = size;
int rightInorderStart = size+1;
int rightInorderEnd = inorderEnd;
//切割后序数组
int leftPostorderStart = postorderStart;
int leftPostorderEnd = postorderStart+(size-inorderStart);
int rightPostorderStart = leftPostorderEnd;//postorderStart+(size-inorderStart);
int rightPostorderEnd = postorderEnd-1;
node.left = buildingTree(inorder, leftInorderStart, leftInorderEnd,
postorder, leftPostorderStart, leftPostorderEnd);
node.right = buildingTree(inorder, rightInorderStart, rightInorderEnd,
postorder, rightPostorderStart, rightPostorderEnd);
return node;
}
}
时间复杂度:O(n2),每个节点遍历一次,同时每次找中节点最大遍历n次(没有右节点),所以O(n2)
使用Map优化时间复杂度
还可以使用map存储inorder节点,优化找中节点的遍历时间(1ms,99.34%)
我的
class Solution {
Map<Integer, Integer> idx_map = new HashMap<Integer, Integer>();
public TreeNode buildTree(int[] inorder, int[] postorder) {
// 建立(元素,下标)键值对的哈希表
int idx = 0;
for (Integer val : inorder) {
idx_map.put(val, idx++);
}
return buildingTree(inorder,0,inorder.length,postorder,0,postorder.length);
}
public TreeNode buildingTree(int[] inorder,int inorderStart,int inorderEnd, int[] postorder,int postorderStart,int postorderEnd){
.
.
.
//根据map找middle的位置
int size = idx_map.get(middle);
.
.
.
return node;
}
}
时间复杂度O(n)
LeetCode版本优化
时间复杂度O(n),1ms,99.34%,原理一样
class Solution {
Map<Integer, Integer> idx_map = new HashMap<Integer, Integer>();//存储中序遍历所有节点
int post_idx;//根节点位置
public TreeNode buildTree(int[] inorder, int[] postorder) {
// 建立中序遍历(元素,下标)键值对的哈希表
int idx = 0;
post_idx = postorder.length-1;
for (Integer val : inorder) {
idx_map.put(val, idx++);
}
return buildingTree(inorder,postorder,0,inorder.length);
}
public TreeNode buildingTree(int[] inorder,int[] postorder,int inorderStart,int inorderEnd){
if(inorderStart == inorderEnd){
return null;
}
int middle = postorder[post_idx];
TreeNode node = new TreeNode(middle);
//找到根节点在inorder里的位置
int size = idx_map.get(middle);
//更改根节点位置
post_idx--;
//构造右子树,左闭右开
node.right = buildingTree(inorder, postorder, size + 1, inorderEnd);
//构造左子树,左闭右开
node.left = buildingTree(inorder, postorder, inorderStart, size);
return node;
}
}
105.从前序与中序遍历序列构造二叉树
HashMap优化,递归
跟106一样,采用HashMap优化遍历,根节点位置作为全局变量优化代码。
class Solution {
Map<Integer,Integer> map = new HashMap<>();
int root_idx;
public TreeNode buildTree(int[] preorder, int[] inorder) {
int index = 0;
int root_idx = 0;
for(int t: inorder){
map.put(t,index++);
}
return buildingTree(preorder,inorder,0,inorder.length);
}
public TreeNode buildingTree(int[] preorder,int[] inorder, int inorderStart, int inorderEnd){
if(inorderStart == inorderEnd){
return null;
}
int middle = preorder[root_idx];
TreeNode node = new TreeNode(middle);
int index = map.get(middle);
root_idx++;
node.left = buildingTree(preorder,inorder,inorderStart,index);
node.right = buildingTree(preorder,inorder,index+1,inorderEnd);
return node;
}
}
遍历顺序如何确定二叉树
前序和中序可以唯一确定一棵二叉树。
后序和中序可以唯一确定一棵二叉树。
那么前序和后序可不可以唯一确定一棵二叉树呢?
前序和后序不能唯一确定一棵二叉树!,因为没有中序遍历无法确定左右部分,也就是无法分割。
举一个例子:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-77ZZuO9Z-1685106833248)(D:\notebook\Working\algorithm\代码随想录.assets\20210203154720326.png)]](https://img-blog.csdnimg.cn/742cb9cc7e404f7398dadde0971d3fc8.png)
654.最大二叉树
递归构造二叉树
题目与根据两个遍历确定二叉树相似,只不过此根节点是自己找的最大值。
class Solution {
Map<Integer,Integer> map = new HashMap<>();
public TreeNode constructMaximumBinaryTree(int[] nums) {
return constructTree(nums,0,nums.length);
}
private TreeNode constructTree(int[] nums,int begin,int end){
if(begin == end) return null;
int max = nums[begin];
int index = begin;
//找到最大值和其索引
for(int i = begin + 1; i< end; i++){
if(max < nums[i]){
max = nums[i];
index = i;
}
}
TreeNode node = new TreeNode(max);
node.left = constructTree(nums,begin,index);
node.right = constructTree(nums,index+1,end);
return node;
}
}
时间复杂度:递归n层,在最坏的情况下(数组递增或递减),第i层需要遍历n-i个元素以找出最大值,所以时间复杂度O(n^2)
单调栈迭代
找出每一个元素左侧和右侧第一个比它大的元素所在的位置。这就是一个经典的单调栈问题了,可以参考 503. 下一个更大元素 II。如果左侧的元素较小,那么该元素就是左侧元素的右子节点;如果右侧的元素较小,那么该元素就是右侧元素的左子节点。没懂难顶
class Solution {
public TreeNode constructMaximumBinaryTree(int[] nums) {
int n = nums.length;
Deque<Integer> stack = new ArrayDeque<Integer>();
int[] left = new int[n];
int[] right = new int[n];
Arrays.fill(left, -1);
Arrays.fill(right, -1);
TreeNode[] tree = new TreeNode[n];
for (int i = 0; i < n; ++i) {
tree[i] = new TreeNode(nums[i]);
//此数如果大于栈里的数值,将栈里的值都取出来,并在前面right[index]中标记
while (!stack.isEmpty() && nums[i] > nums[stack.peek()]) {
right[stack.pop()] = i;
}
//如果栈不为空,说明此数小于栈里对应数值,并且栈里的数都在它左边,所以在left[i]中标记
if (!stack.isEmpty()) {
left[i] = stack.peek();
}//将此值放入栈,递减单调栈
stack.push(i);
}
TreeNode root = null;
for (int i = 0; i < n; ++i) {
if (left[i] == -1 && right[i] == -1) {
root = tree[i];
//元素右侧没有比它大的值,此时它一定为左边比它大的值的右子树
//2 1 3
//或者左侧的元素相对较小,(更大的元素nums[i]已经被构造过,或之后构造)那么该元素就是左侧元素的右子节点
} else if (right[i] == -1 || (left[i] != -1 && nums[left[i]] < nums[right[i]])) {
tree[left[i]].right = tree[i];
} else {
//右侧比他大的值左子树
tree[right[i]].left = tree[i];
}
}
return root;
}
}
备注提示
//[3,2,1,6,0,5],right[i]表示右侧第一个比nums[i]大的元素位置,left[i]表示第一个左侧比nums[i]大的元素位置
//tree = 3 stack = 0
//tree = 3,2 right = -1,-1,-1... left =-1,0 stack = 0 1
//tree = 3,2,1 right = -1,-1,-1... left =-1,0,1 stack = 0 1 2
//tree = 3,2,1,6 right = 3,3,3,-1,-1,-1 left =-1,0,1,-1 stack = 3
//tree = 3,2,1,6,0 right = 3,3,3,-1,-1,-1 left =-1,0,1,-1,3 stack = 3 4
//tree = 3,2,1,6,0,5 right = 3,3,3,-1,5,-1 left =-1,0,1,-1,3,3 stack = 3 5
//tree[3].left = tree[0];
//
//root = tree[2];
System.out.println("left:");
for(int i = 0; i<left.length;i++){
System.out.print(left[i]+" ");
}
System.out.println();
System.out.println("right:");
for(int i = 0; i<right.length;i++){
System.out.print(right[i]+" ");
}
617.合并二叉树
递归遍历(0ms,100%)
class Solution {
public TreeNode mergeTrees(TreeNode root1, TreeNode root2) {
return mergeTwo(root1,root2);
}
private TreeNode mergeTwo(TreeNode node1,TreeNode node2){
//双方为空,返回空,返回对方也行反正都是空,所以可以省略
//if(node1 == null & node2 == null) return null;
//一方为空,返回对方
if(node1 == null) return node2;
if(node2 == null) return node1;
//两个都不为空,值相加
node1.val = node1.val + node2.val;
node1.left = mergeTwo(node1.left,node2.left);
node1.right = mergeTwo(node1.right,node2.right);
return node1;
}
}
迭代遍历(1ms,13.95%)
维护队列稍慢
class Solution {
// 使用队列迭代
public TreeNode mergeTrees(TreeNode root1, TreeNode root2) {
if (root1 == null) return root2;
if (root2 ==null) return root1;
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root1);
queue.offer(root2);
while (!queue.isEmpty()) {
TreeNode node1 = queue.poll();
TreeNode node2 = queue.poll();
// 此时两个节点一定不为空,val相加
node1.val = node1.val + node2.val;
// 如果两棵树左节点都不为空,加入队列
if (node1.left != null && node2.left != null) {
queue.offer(node1.left);
queue.offer(node2.left);
}else if(node1.left == null){
// 若node1的左节点为空,直接赋值,空值一样赋,不用进入队列了
node1.left = node2.left;
}
// 如果两棵树右节点都不为空,加入队列
if (node1.right != null && node2.right != null) {
queue.offer(node1.right);
queue.offer(node2.right);
}else if(node1.right == null ){
// 若node1的右节点为空,直接赋值,空值一样赋
node1.right = node2.right;
}
//node1,node2的左右节点都为空,互相赋值null
}
return root1;
}
}
700.二叉搜索树中的搜索
递归遍历(0ms,100%)
class Solution {
public TreeNode searchBST(TreeNode root, int val) {
if(root == null) return null;
if(root.val == val) return root;
//if(root==null||root.val ==val) return root;
if(val < root.val){
return searchBST(root.left,val);
}
else{
return searchBST(root.right,val);
}
}
}
迭代遍历(0ms,100%)
class Solution {
public TreeNode searchBST(TreeNode root, int val) {
while(root != null){
if(root.val == val) return root;
root = root.val > val ? root.left : root.right;
}
return null;
}
}
98.验证二叉搜索树
中序遍历
二叉搜索树,左子树的每个值都小于当前节点,右子树的每个值都大于当前节点,所以可以采用中序遍历,每此遍历中值都大于上次遍历
递归版
把元素存储到数组中(2ms,19.69%)
时间复杂度:O(n)。维护和遍历数组较为浪费时间空间
class Solution {
List<Integer> list;
public boolean isValidBST(TreeNode root) {
list = new ArrayList<>();
judgeBSt(root);
for(int i = 0 ;i< list.size()-1;i++){
if(list.get(i+1)<=list.get(i)) return false;
}
return true;
}
private void judgeBSt(TreeNode node){
if(node == null) return;
//左
judgeBSt(node.left);
//中
list.add(node.val);
//右
judgeBSt(node.right);
}
}
存储上次值(0ms,100%)
pre存储上次遍历到的值,初始为null,在第一次遍历到左下角后会赋值。
class Solution {
Integer pre;
public boolean isValidBST(TreeNode root) {
return judgeBSt(root);
}
private boolean judgeBSt(TreeNode node){
if(node == null) return true;
//左
boolean left = judgeBSt(node.left);
if(!left) return false;
//中, pre赋值左下角
if(pre != null && pre >= node.val) return false;
pre = node.val;
//右
boolean right =judgeBSt(node.right);
return right;
}
}
迭代版
中序遍历,和递归一样(1ms,27.82%)
class Solution {
// 迭代
public boolean isValidBST(TreeNode root) {
if (root == null) {
return true;
}
Deque<TreeNode> stack = new LinkedList<>();
TreeNode pre = null;
while (root != null || !stack.isEmpty()) {
while (root != null) {
stack.push(root);
root = root.left;// 左
}
// 中,处理
TreeNode node = stack.poll();
if (pre != null && node.val <= pre.val) {
return false;
}
pre = node;
root = node.right;// 右
}
return true;
}
}
传入范围判断
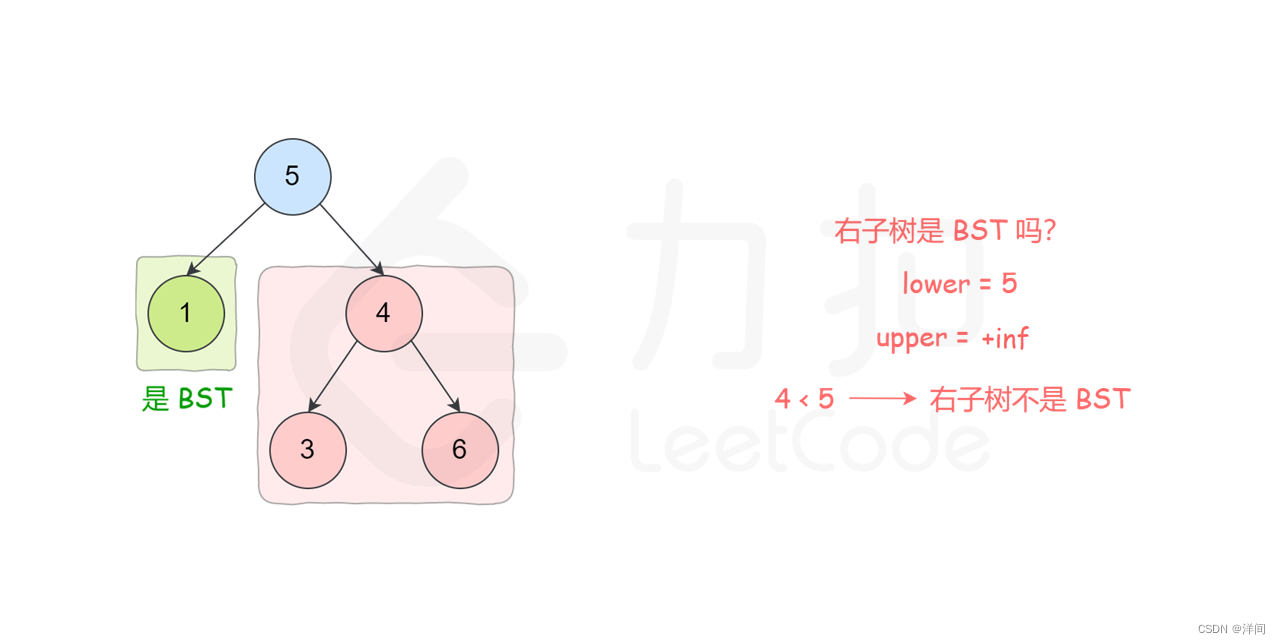
class Solution {
public boolean isValidBST(TreeNode root) {
return isValidBST(root, Long.MIN_VALUE, Long.MAX_VALUE);
}
public boolean isValidBST(TreeNode node, long lower, long upper) {
if (node == null) {
return true;
}
if (node.val <= lower || node.val >= upper) {
return false;
}
return isValidBST(node.left, lower, node.val) && isValidBST(node.right, node.val, upper);
}
}
530.二叉搜索树的最小绝对差
中序遍历递归
class Solution {
Integer min = Integer.MAX_VALUE;
TreeNode pre;
public int getMinimumDifference(TreeNode root) {
getDifference(root);
return min;
}
private void getDifference(TreeNode node){
if(node == null) return;
//左
getDifference(node.left);
//中
if(pre != null){
min = Math.min(min,node.val - pre.val);
}
pre = node;
//右
getDifference(node.right);
}
}
中序遍历迭代
class Solution {
public int getMinimumDifference(TreeNode root) {
Deque<TreeNode> stack = new LinkedList<>();
TreeNode pre = null;
int result = Integer.MAX_VALUE;
if(root != null) stack.push(root);
while(!stack.isEmpty()){
TreeNode curr = stack.poll();
if(curr != null){
if(curr.right != null) stack.push(curr.right);
stack.push(curr);
stack.push(null);
if(curr.left != null) stack.push(curr.left);
}else{
TreeNode temp = stack.poll();
if(pre != null)
result = Math.min(result, temp.val - pre.val);
pre = temp;
}
}
return result;
}
}
501.二叉搜索树中的众数
中序遍历递归
两个值存最多次数maxCount和当前次数count(0ms,100%)
class Solution {
int count;
int maxCount;
List<Integer> result;
Integer pre;
public int[] findMode(TreeNode root) {
count = 0;
maxCount = 0;
findTree(root);
int i = 0;
int[] ans = new int[result.size()];
for(int num : result){
ans[i++] = num;
}
//return result.stream().mapToInt(Integer::intValue).toArray();
return ans;
}
public void findTree(TreeNode node){
if(node == null) return;
findTree(node.left);
if(pre == null){
count = 1;
}else if(pre == node.val){
count++;
}else{
count = 1;
}
pre = node.val;
if(count > maxCount){
result = new ArrayList();
result.add(pre);
maxCount = count;
}else if(count == maxCount){
result.add(pre);
}
findTree(node.right);
}
}
同理可以使用迭代中序遍历
236. 二叉树的最近公共祖先
使用boolean数组记录p与q的遍历情况
代码优化过后,6ms,99.91%
class Solution {
TreeNode result;
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
findAncestor(root,p,q);
return result;
}
public boolean[] findAncestor(TreeNode root,TreeNode p, TreeNode q){
if(root == null){
return new boolean[]{false,false};
}
boolean[] ans = findAncestor(root.left,p,q);//左
//提前判断,如果满足则后续不用遍历,也可以不加此判断
if(ans[0] == true && ans[1] == true){
return ans;
}
boolean[] flag = findAncestor(root.right,p,q);//右
//左右合并后
//因为自己也算是自己的后代,再结合此节点判断,看是否符合
ans[0] = ans[0]||flag[0]||(root.val == p.val);//中
ans[1] = ans[1]||flag[1]||(root.val == q.val);
//满足,且是第一次满足,则记录
if(ans[0] == true && ans[1] == true && result == null){
result = root;
}
return ans;
}
}
返回目标节点情况
代码随想录
6ms,99.91%

class Solution {
TreeNode result;
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
return findAncestor(root,p,q);
}
public TreeNode findAncestor(TreeNode root,TreeNode p, TreeNode q){
if(root == null|| root == p || root == q){
return root;
}
TreeNode left = findAncestor(root.left,p,q);//左
TreeNode right = findAncestor(root.right,p,q);//右
//p and q will exist in the tree,and p != q
//使得向上传递的节点最后一定齐全
//所以如果右边一直为null,另一个值一定在左边的子孩子里,而不用遍历!!
//p与q都找到了
if(left != null && right != null){
return root;
//p或q找到一个
}else if(left != null && right == null){
return left;
}else if(left == null && right != null){
return right;
//p或q都没找到
}else{
return null;
}
//if (left != NULL && right != NULL) return root;
//if (left == NULL) return right;
}
}
leetcode官方
class Solution {
private TreeNode ans;
public Solution() {
this.ans = null;
}
private boolean dfs(TreeNode root, TreeNode p, TreeNode q) {
if (root == null) return false;
boolean lson = dfs(root.left, p, q);
boolean rson = dfs(root.right, p, q);
//只有当左右子树为真,或者本身符合一个值且子树符合一个值时,赋值,所以向上传递后不会满足
if ((lson && rson) || ((root.val == p.val || root.val == q.val) && (lson || rson))) {
ans = root;
}
//如果他的左子树,或者右子树,或者它本身符合一个值,则返回真
return lson || rson || (root.val == p.val || root.val == q.val);
}
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
this.dfs(root, p, q);
return this.ans;
}
}
存储父节点,向上遍历
先遍历一遍,存储每个节点的父节点。10ms,12.1%
class Solution {
Map<Integer, TreeNode> parent = new HashMap<Integer, TreeNode>();
Set<Integer> visited = new HashSet<Integer>();
//遍历存储父节点
public void dfs(TreeNode root) {
if (root.left != null) {
parent.put(root.left.val, root);
dfs(root.left);
}
if (root.right != null) {
parent.put(root.right.val, root);
dfs(root.right);
}
}
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
dfs(root);
while (p != null) {
//遍历p的所有祖先
visited.add(p.val);
p = parent.get(p.val);
}
while (q != null) {
//如果p的祖先中存在q,则返回q.
if (visited.contains(q.val)) {
return q;
}
//如果p的祖先中不存在q
//则查看q的祖先中,有没有p的祖先(先遇到p自身)
q = parent.get(q.val);
}
return null;
}
}
235. 二叉搜索树的最近公共祖先
递归版
按普通二叉树自底向上
class Solution {
TreeNode result;
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
return findAncestor(root,p,q);
}
public TreeNode findAncestor(TreeNode root,TreeNode p, TreeNode q){
if(root == null|| root == p || root == q){
return root;
}
TreeNode left = findAncestor(root.left,p,q);//左
TreeNode right = findAncestor(root.right,p,q);//右
//p and q will exist in the tree,and p != q
//使得向上传递的节点最后一定齐全
//所以如果右边一直为null,另一个值一定在左边的子孩子里,而不用遍历!!
if (left != null && right != null) return root;
if (left == null) return right;
return left;
}
}
按找二叉搜索树规则自顶向下
因为是有序树,所有 如果 中间节点是 q 和 p 的公共祖先,那么 中节点的数组 一定是在 [p, q]区间的。
那么只要从上到下去遍历,遇到 cur节点是数值在[p, q]区间中则一定可以说明该节点cur就是q 和 p的公共祖先。 那问题来了,一定是最近公共祖先吗?
此时节点5是不是最近公共祖先? 如果 从节点5继续向左遍历,那么将错过成为p的祖先, 如果从节点5继续向右遍历则错过成为q的祖先。
已知两节点在树里一定存在。所以自上向下遍历时,在两数左、右侧时是其公共祖先,而满足在两数之间时一定是其最低公共祖先,因为此时小的数在左子树,大的数在右子树,即使再向下走得到的数值也满足两数之间,其走的方向决定了不是另一数的祖先。
class Solution {
TreeNode result;
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if(p.val>q.val){
TreeNode temp = p;
p = q;
q = temp;
}
return findAncestor(root,p,q);
}
public TreeNode findAncestor(TreeNode root,TreeNode p, TreeNode q){
if(root == null){
return root;
}
//中
//节点大于最大值,则数字在节点左侧
if( q.val < root.val){
TreeNode left = findAncestor(root.left,p,q);
if(left != null){
return left;
}
//节点小于最小值,则数字在节点右侧
} else if( p.val > root.val ){
TreeNode right = findAncestor(root.right,p,q);
if(right != null){
return right;
}
}
//节点在两值中间,则符合公共祖先
return root;
}
}
优化版
class Solution {
TreeNode result;
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if(p.val>q.val){
TreeNode temp = p;
p = q;
q = temp;
}
return findAncestor(root,p,q);
}
public TreeNode findAncestor(TreeNode root,TreeNode p, TreeNode q){
//一定存在,不会找到null值
//节点大于最大值,则数字在节点左侧
if( q.val < root.val) return findAncestor(root.left,p,q);
//节点小于最小值,则数字在节点右侧
else if( p.val > root.val ) return findAncestor(root.right,p,q);
//节点在两值中间,则符合公共祖先
return root;
}
}
迭代版
递归版同理
找到第一个在两值间的节点
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
while (true) {
if (root.val > p.val && root.val > q.val) {
root = root.left;
} else if (root.val < p.val && root.val < q.val) {
root = root.right;
} else {
break;
}
}
return root;
}
}
两次遍历
找到到两个节点的两条路径,路径不同的分岔点即为公共祖先
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
List<TreeNode> path_p = getPath(root, p);
List<TreeNode> path_q = getPath(root, q);
TreeNode ancestor = null;
for (int i = 0; i < path_p.size() && i < path_q.size(); ++i) {
if (path_p.get(i) == path_q.get(i)) {
ancestor = path_p.get(i);
} else {
break;
}
}
return ancestor;
}
public List<TreeNode> getPath(TreeNode root, TreeNode target) {
List<TreeNode> path = new ArrayList<TreeNode>();
TreeNode node = root;
while (node != target) {
path.add(node);
if (target.val < node.val) {
node = node.left;
} else {
node = node.right;
}
}
path.add(node);
return path;
}
}
701.二叉搜索树中的插入操作
递归void遍历,全局pre节点
遍历,找到位置符合的null节点,通过记录的pre节点,判断值大小放到左/右节点(0ms,100%)
class Solution {
TreeNode pre = null;
public TreeNode insertIntoBST(TreeNode root, int val) {
if(root == null){
TreeNode t = new TreeNode(val);
return t;
}
insertTree(root,val);
return root;
}
public void insertTree(TreeNode node, int val){
if(node == null){
TreeNode t = new TreeNode(val);
if(pre.val>val){
pre.left = t;
}
else if(pre.val<val){
pre.right = t;
}
return;
}
pre = node;
if(node.val>val){
insertTree(node.left,val);
}
else if(node.val<val){
insertTree(node.right,val);
}
}
}
递归node遍历,返回插入节点
代码随随想录解法:上面的无返回值遍历还是麻烦一点的,通过递归函数的返回值完成父子节点的赋值是可以带来便利的。(0ms,100%)
class Solution {
public TreeNode insertIntoBST(TreeNode root, int val) {
return insertTree(root,val);
}
public TreeNode insertTree(TreeNode node, int val){
if(node == null){
TreeNode t = new TreeNode(val);
return t;
}
if(node.val>val) node.left = insertTree(node.left,val);
if(node.val<val) node.right = insertTree(node.right,val);
return node;
}
}
迭代法
和返回void的递归一样。(0ms,100%)
class Solution {
public TreeNode insertIntoBST(TreeNode root, int val) {
if (root == null) return new TreeNode(val);
TreeNode node = root;
TreeNode pre = null;
//找到合适null值
while (node != null) {
pre = node;
if (node.val > val) {
node = node.left;
} else if (node.val < val) {
node = node.right;
}
}
if (pre.val > val) {
pre.left = new TreeNode(val);
} else {
pre.right = new TreeNode(val);
}
return root;
}
}
450.删除二叉搜索树中的节点
我的迭代
1.找到需要删除的节点,存储其父节点(根节点的父节点dummyRoot)。
2.看此删除的节点是否存在右子树
-
如果存在
- 则在右子树中找到最小节点,即最左节点,使其成为替换节点(或左子树的最右节点)。
- 操作替换节点
- 最左节点不存在左孩子,把它的右孩子赋予其父节点的左节点,保存替换节点信息。
- 把待删除节点的左右孩子,赋予替换节点,右孩子可能为null(dummyNode.left)。
- 将被删除节点的父节点指向(判断左右)替换节点。
-
如果不存在
- 那么直接让此节点的左孩子,成为被替换节点即可。
- 将被删除节点的父节点指向(判断左右)替换节点
3.返回dummyRoot的孩子,因为root也可能被操作。
此方式改变的树的结构相对较小
class Solution {
public TreeNode deleteNode(TreeNode root, int key) {
return deleteTree(root,key);
}
//找到右子树的最左节点
//或者找到左子树的最右节点
//因为是叶子节点,不需要考虑后续结构
private TreeNode deleteTree(TreeNode root, int key){
TreeNode dummyRoot = new TreeNode(-1,root,null);
TreeNode pre = dummyRoot;
TreeNode node = root;
//找到需要删除的节点
while(node!=null){
if(node.val == key){
break;
}
pre = node;
if(node.val < key) node = node.right;//注意此时node变了,所以加else
else if(node.val > key) node = node.left;
}
if(node != null){
TreeNode leftest;
if(node.right == null){
leftest = node.left;
}else{
TreeNode dummyNode = new TreeNode(-1,node.right,null);
leftest = findLeftestAndDelete(dummyNode);
leftest = new TreeNode(leftest.val);
//节点左边无变化
leftest.left = node.left;
//节点右边可能删除node.right这个最左节点,从而切换为null或其右子树
leftest.right = dummyNode.left;
}
//判断此删除节点是上个节点的左子树还是右子树
if(pre.right == node){
//左子树,则替换左边
pre.right = leftest;
}else if(pre.left == node){
pre.left = leftest;
}
}
return dummyRoot.left;
}
private TreeNode findLeftestAndDelete(TreeNode node){
TreeNode pre = null;
TreeNode curl = node;
//找到节点最左节点
while(curl.left != null){
pre = curl;
curl = curl.left;
}
//删除此节点,把它的右孩子赋予其父节点的左节点。
pre.left = curl.right;
return curl;
}
}
代码随想录
递归1
直接将待删除左子树移到右子树最小值(最左节点)的左孩子上

通过递归返回值删除节点,有以下五种情况:
- 第一种情况:没找到删除的节点,遍历到空节点直接返回了
- 找到删除的节点
- 第二种情况:左右孩子都为空(叶子节点),直接删除节点, 返回NULL为根节点
- 第三种情况:删除节点的左孩子为空,右孩子不为空,删除节点,右孩子补位,返回右孩子为根节点
- 第四种情况:删除节点的右孩子为空,左孩子不为空,删除节点,左孩子补位,返回左孩子为根节点
- 第五种情况:左右孩子节点都不为空,则将删除节点的左子树头结点(左孩子)放到删除节点的右子树的最左面节点的左孩子上,返回删除节点右孩子为新的根节点。
class Solution {
public TreeNode deleteNode(TreeNode root, int key) {
// 第一种情况:没找到删除的节点,遍历到空节点直接返回了
if (root == null) return root;
//中,遍历
if (root.val == key) {
// 第二,三种情况:其左孩子为空,删除节点,右孩子补位 ,返回右孩子或null为根节点
if (root.left == null) {
return root.right;
// 第四种情况:其右孩子为空,左孩子不为空,删除节点,左孩子补位,返回左孩子为根节点
} else if (root.right == null) {
return root.left;
// 第五种情况:左右孩子节点都不为空,则将删除节点的左子树放到删除节点的右子树的最左面节点的左孩子的位置
// 并返回删除节点右孩子为新的根节点
} else {
TreeNode cur = root.right;
while (cur.left != null) {
cur = cur.left;
}
cur.left = root.left;
//跳过此root,将其右子树赋给它
root = root.right;
return root;
}
//返回值里
if (root.val > key) root.left = deleteNode(root.left, key);
if (root.val < key) root.right = deleteNode(root.right, key);
return root;
}
}
递归2
- 第一次是给目标节点赋值它的右子树最左面节点。
- 然后删除最左节点,因为其左子树为null所以第二次直接被null覆盖了。
class Solution {
public TreeNode deleteNode(TreeNode root, int key) {
if (root == null) return null;
if (root.val > key) {
root.left = deleteNode(root.left,key);
} else if (root.val < key) {
root.right = deleteNode(root.right,key);
//二叉树遍历到节点
} else {
if (root.left == null) return root.right;
if (root.right == null) return root.left;
TreeNode tmp = root.right;
while (tmp.left != null) {
tmp = tmp.left;
}
//tmp位置还会第二次删除为null,root值以改变直接返回即可
root.val = tmp.val;
root.right = deleteNode(root.right,tmp.val);
}
return root;
}
}
leetCode递归3
跟我的迭代思想一样,只用叶子节点替换
class Solution {
public TreeNode deleteNode(TreeNode root, int key) {
if (root == null) return null;
if (root.val > key) {
root.left = deleteNode(root.left,key);
} else if (root.val < key) {
root.right = deleteNode(root.right,key);
//二叉树遍历到节点
} else {
//当左右都为空时也符合
if (root.left == null) return root.right;
if (root.right == null) return root.left;
TreeNode tmp = root.right;
while (tmp.left != null) {
tmp = tmp.left;
}
//tmp位置还会第二次删除为null,root值以改变直接返回即可
root.right = deleteNode(root.right,tmp.val);
temp.right = root.right;
temp.left = root.left;
return temp;
}
return root;
}
}
迭代法
遍历到目标节点,记录父节点即可
class Solution {
// 将目标节点(删除节点)的左子树放到 目标节点的右子树的最左面节点的左孩子位置上
// 并返回目标节点右孩子为新的根节点
// 是动画里模拟的过程
private TreeNode deleteOneNode(TreeNode target) {
//空则直接返回,对应没找到的情况
if (target == null) return target;
//右子树为空,直接返回左子树或null,即跳过此target
if (target.right == null) return target.left;
//右子树不为空,找最左节点,有可能是自己
TreeNode cur = target.right;
while (cur.left!=null) {
cur = cur.left;
}
//右子树最左节点接上
cur.left = target.left;
//返回右子树,即跳过此target
return target.right;
}
public TreeNode deleteNode(TreeNode root, int key) {
if (root == null) return root;
TreeNode cur = root;
TreeNode pre = null; // 记录cur的父节点,用来删除cur
//找到目标节点
while (cur!=null) {
if (cur.val == key) break;
pre = cur;
if (cur.val > key) cur = cur.left;
else cur = cur.right;
}
//没找到
// if(cur == null){
// return root;
// }
if (pre == null) { // 如果搜索树只有头结点
return deleteOneNode(cur);
}
// pre 要知道是删左孩子还是右孩子
if (pre.left == cur) {
pre.left = deleteOneNode(cur);
}
if (pre.right == cur) {
pre.right = deleteOneNode(cur);
}
return root;
}
}
669. 修剪二叉搜索树⭐
代码随想录递归
对根结点 root 进行深度优先遍历。对于当前访问的结点,如果结点为空结点,直接返回空结点;
如果结点的值小于 low,那么说明该结点及它的左子树都不符合要求,我们返回对它的右结点进行修剪后的结果;
如果结点的值大于 high,那么说明该结点及它的右子树都不符合要求,我们返回对它的左子树进行修剪后的结果;
如果结点的值位于区间[low,high],我们将结点的左结点设为对它的左子树修剪后的结果,右结点设为对它的右子树进行修剪后的结果。
class Solution {
public TreeNode trimBST(TreeNode root, int low, int high) {
root = trimBSTSmall(root,low,high);
//root = trimBSTBig(root,low);
return root;
}
public TreeNode trimBSTSmall(TreeNode node,int low,int high){
if(node == null) return node;
//此节点小于最小值,判断它的右子树,则返回node.right,否则返回里面的节点
if(node.val <low){
//找到右子树里满足[low,high]的节点,也省略了node
TreeNode right = trimBSTSmall(node.right,low,high);
return right;
}
//此节点大于最大值,判断它的左子树,如果都符合,则返回node.left,否则返回里面的节点
if(node.val > high){
//遍历左子树
return trimBSTSmall(node.left,low,high);
}
//此节点位于最小值与最大值中间,遍历左右子树,
node.left = trimBSTSmall(node.left,low,high);
node.right = trimBSTSmall(node.right,low,high);
//返回符合的节点
return node;
}
}
迭代
先找到满足条件的root节点,设为node,然后修建root的左右子树。
先讨论左子树的修剪
- node的左节点为null,则不需要修剪左子树
- node的左节点非空
- 如果它的node.left小于low,则node.left以及node.left的左子树都不符合要求,我们将node.left设置为node.left的右子树,重新对node.left进行修剪。
- 如果node.left大于等于low,因为node>node.left且符合要求,所以node.left的右子树满足要求,需要对node.left的左子树进行修剪。所以令node = node.left,重新对node的左子树进行修剪。
class Solution {
public TreeNode trimBST(TreeNode root, int low, int high) {
//找到符合[low,high]的根节点。
while (root != null && (root.val < low || root.val > high)) {
if (root.val < low) {
root = root.right;
} else {
root = root.left;
}
}
if (root == null) {
return null;
}
//处理左孩子
for (TreeNode node = root; node.left != null; ) {
//左孩子<Low,则左子树都不符合,赋值为左孩子的右孩子,再次判断
if (node.left.val < low) {
node.left = node.left.right;
} else {
//左孩子大于low,判断左孩子的左孩子。
node = node.left;
}
}
//处理右孩子
for (TreeNode node = root; node.right != null; ) {
if (node.right.val > high) {
node.right = node.right.left;
} else {
node = node.right;
}
}
return root;
}
}
108.将有序数组转换为二叉搜索树
递归
平衡二叉搜索树,数组中间为根值,平均分左边构造左子树,右边构造右子树。
class Solution {
public TreeNode sortedArrayToBST(int[] nums) {
return construct(nums,0,nums.length);
}
public TreeNode construct(int[] nums,int begin,int end){
if(end == begin){
return null;
}
int mid = begin + (end - begin)/2;
TreeNode root = new TreeNode(nums[mid]);
root.left = construct(nums,begin,mid);
root.right = construct(nums,mid+1,end);
return root;
}
}
538.把二叉搜索树转换为累加树
两次递归
第一次递归求全部值的合sum。第二次递归重新把节点赋值,然后让sum减去此节点的值。
class Solution {
int total = 0;
public TreeNode convertBST(TreeNode root) {
total = findSum(root);
convertTree(root);
return root;
}
private void convertTree(TreeNode node){
if(node == null) return;
//左
convertTree(node.left);
//中
int temp = node.val;
node.val = total;
total = total - temp;
//右
convertTree(node.right);
}
private int findSum(TreeNode node){
if(node == null){
return 0;
}
int sum = findSum(node.right);
sum += findSum(node.left);
sum += node.val;
return sum;
}
}
反向遍历
从树中可以看出累加的顺序是右中左,所以我们需要反中序遍历这个二叉树,然后顺序累加就可以了,即从右中左开始累加。递归迭代都可。

class Solution {
int pre = 0;
public TreeNode convertBST(TreeNode root) {
convertTree(root);
return root;
}
private void convertTree(TreeNode node){
if(node == null) return;
//右
convertTree(node.right);
//中
node.val = pre + node.val;
pre = node.val;
//左
convertTree(node.left);
}
}















 344
344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









