






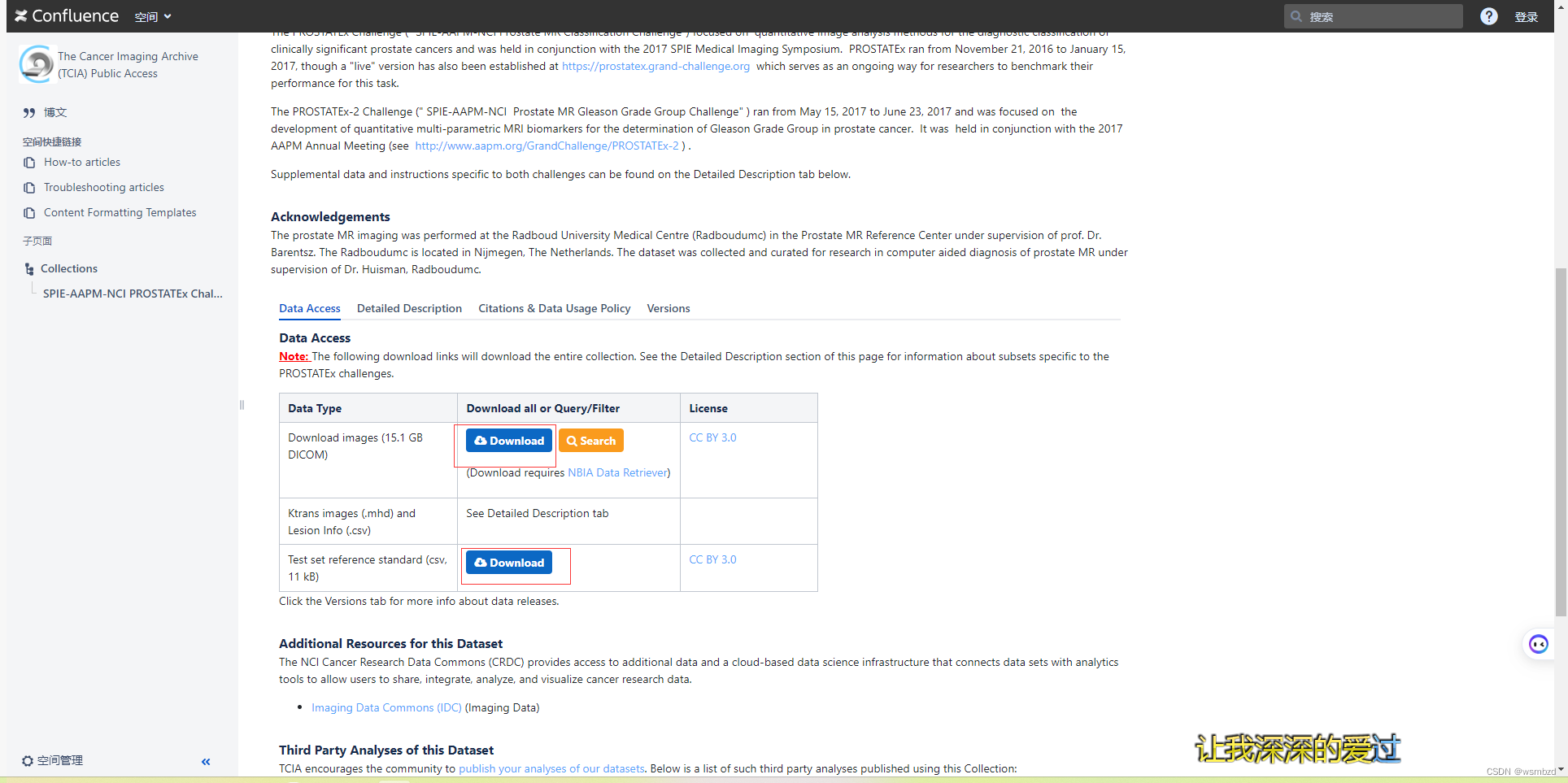
1. prostatex
下载地址:https://wiki.cancerimagingarchive.net/pages/viewpage.action?pageId=23691656
比赛:https://prostatex.grand-challenge.org/
这个下载的是一个tcia文件,参考这篇文章打开该文件
2. promise12
地址:https://zenodo.org/records/8026660
比赛:PROMISE12: Data from the MICCAI Grand Challenge: Prostate MR Image Segmentation 2012

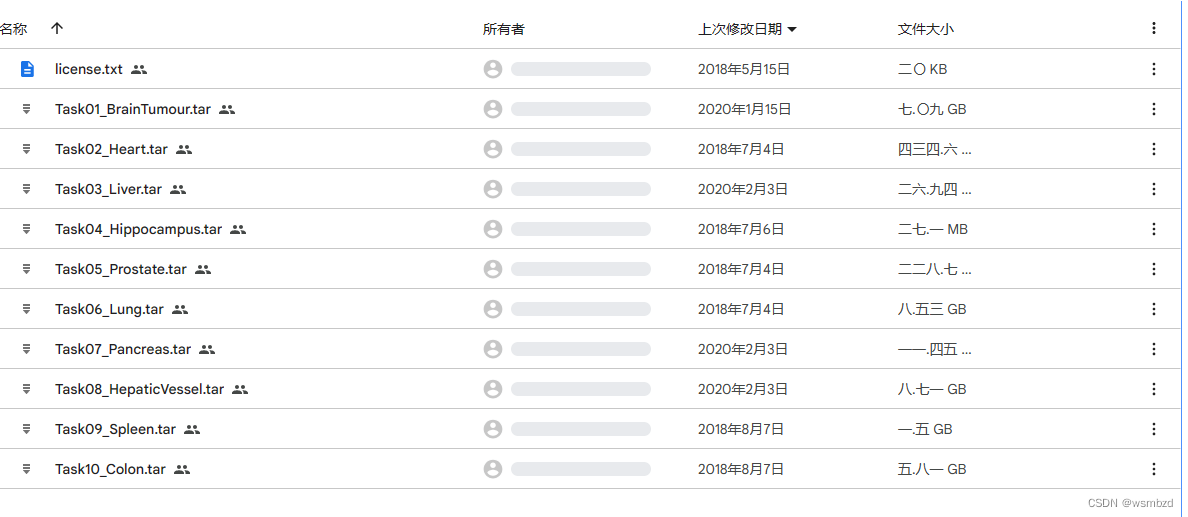
3. 不明
下载地址:https://drive.google.com/drive/folders/1HqEgzS8BV2c7xYNrZdEAnrHk7osJJ–2
比赛:不明















 1512
1512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









