







 本文概述了知识追踪(KT)的任务定义和模型分类,重点介绍了概率模型(如BKT和DBKT)、逻辑模型(如LFA和KTM)以及基于深度学习的模型(如DKT、DKVMN和AKT)。KT旨在预测学生在学习过程中的知识状态演变,深度学习模型在处理复杂学习过程时表现出优越性能,但可解释性较弱。文章还探讨了KT模型的个性化建模、学习过程中的参与信息融合以及遗忘效应的考虑。
本文概述了知识追踪(KT)的任务定义和模型分类,重点介绍了概率模型(如BKT和DBKT)、逻辑模型(如LFA和KTM)以及基于深度学习的模型(如DKT、DKVMN和AKT)。KT旨在预测学生在学习过程中的知识状态演变,深度学习模型在处理复杂学习过程时表现出优越性能,但可解释性较弱。文章还探讨了KT模型的个性化建模、学习过程中的参与信息融合以及遗忘效应的考虑。
一,KT任务定义和KT模型的分类
KT任务定义: 给定在线学习系统中的学习交互序列,知识跟踪旨在监测学生在学习过程中的知识状态演变,并预测他们在未来练习中的表现(既要考虑学生成绩预测,也要考虑学生的知识状态)
KT模型:
1.概率模型
2.逻辑模型
3.基于深度学习的模型
变体:1.学习前的个性化建模 2.在学习过程中结合参与和利用辅助信息 3.考虑学习后的遗忘
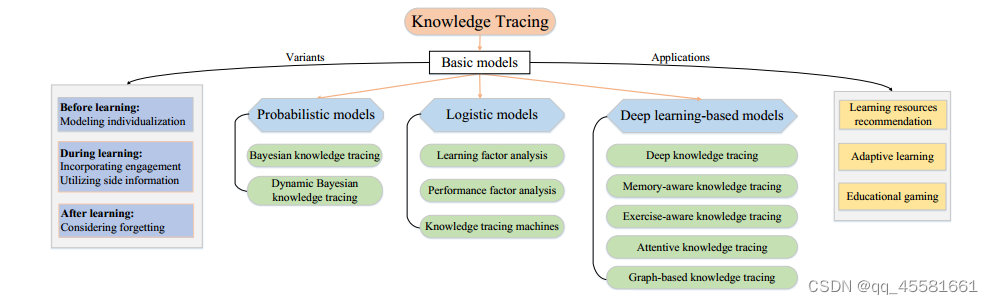
二,概率模型
1.原始贝叶斯知识追踪(BKT)
BKT是隐马尔可夫模型(含有转移概率和发射概率)
在BKT中,过渡概率有两个学习参数定义:P(T):从未学习状态过渡到学习状态的过程
P(F):遗忘先前掌握知识的概率
发射概率的两个性能参数决定:P(G):即学生在不精通的情况下猜对的概率
P(S):学生在掌握知识后犯的错误概率
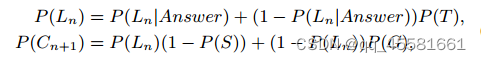
P(Ln)是在第n次学习交互中掌握KC的概率,P(Cn+1)是下一次学习交互中正确答案的概率。 P(Ln)是两个概率的和:(1)KC已经被掌握的概率;(2)知识状态转化为掌握状态的概率
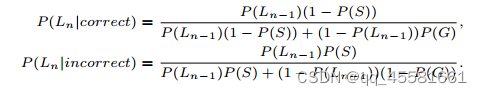
2.动态贝叶斯知识追踪(DBKT)(KC之间并不是完全独立的,而是层次性的、密切相关的)
三,逻辑模型
使用学生学习互动中的不同因素来计算学生和KC参数的估计,然后利用逻辑函数将该估计转换为掌握概率的预测
1.学习因素分析
初始知识状态:参数α估计每个学生的初始知识状态;
KCs的容易程度:参数β捕获不同KCs的容易程度;
KCs的学习率:参数γ表示KCs的学习率。
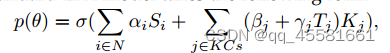
其中σ是sigmoid函数,Si是学生i的协变量,Tj表示KC j上相互作用次数的协变量,Kj是KC j的协变量,p(θ)是正确答案的概率估计。
2.性能因素分析
先前失败:参数f是学生KC的先前失败;
以前的成功:参数s表示学生的KC以前的成功;
KCs的容易程度:参数β表示不同KCs的容易程度,与LFA模型相同
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









