







PPT链接:
self-attention:https://speech.ee.ntu.edu.tw/~hylee/ml/ml2021-course-data/self_v7.pdf
Transformer:https://speech.ee.ntu.edu.tw/~hylee/ml/ml2021-course-data/seq2seq_v9.pdf
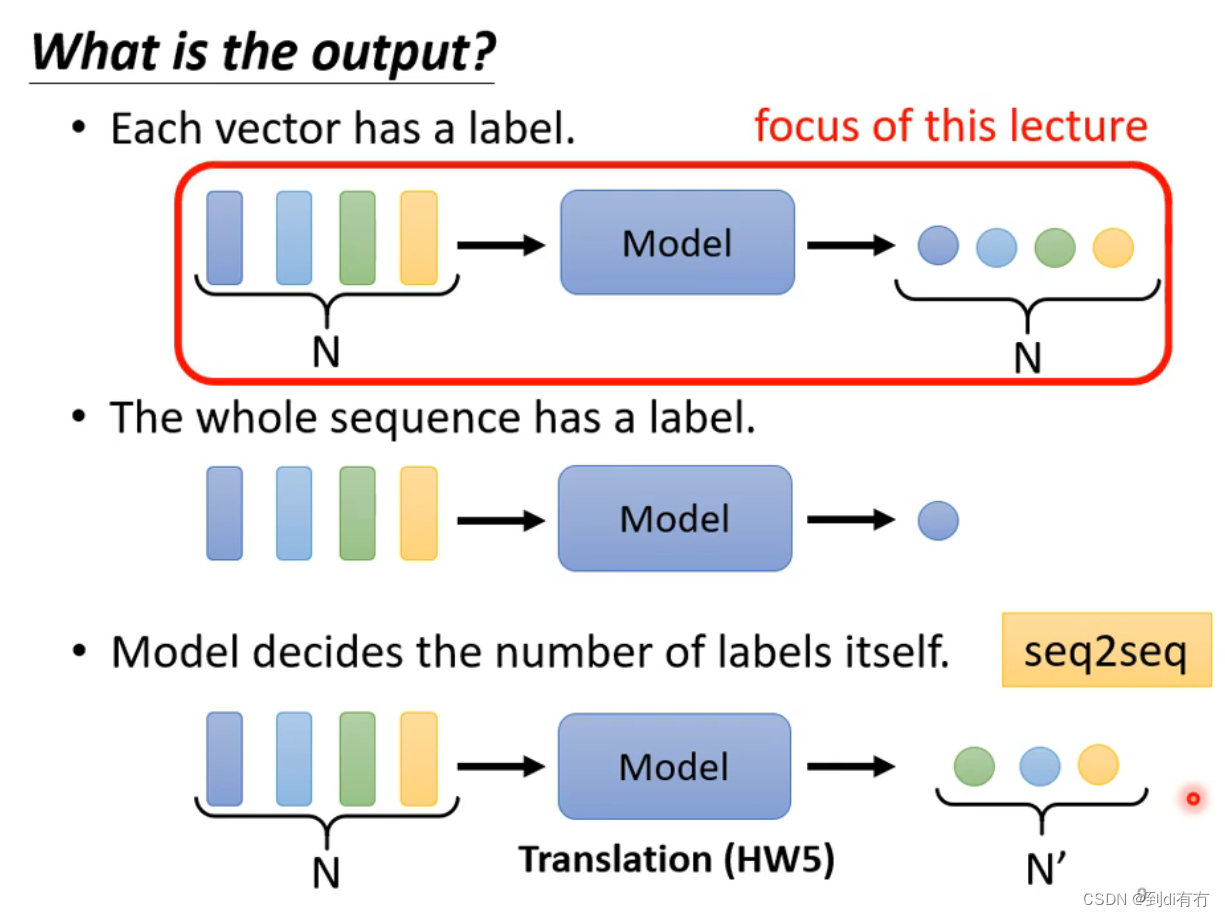
输出的类型分为三种,一种是有输入输出一样多,又称为sequenc labeling,例如词性标注;一种是有多个输入只有一个输出,例如情感分析;一种是有模型自己确认有几个输出,例如翻译,语音识别
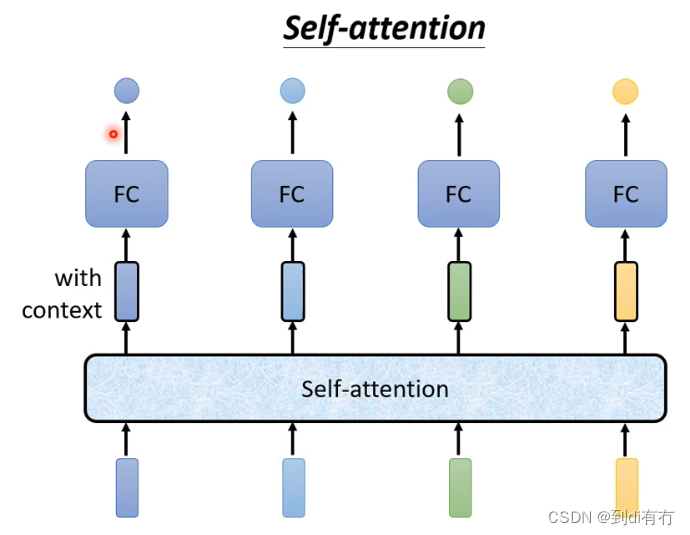
使用self-attention是模型在训练时考虑到整个输入序列的信息
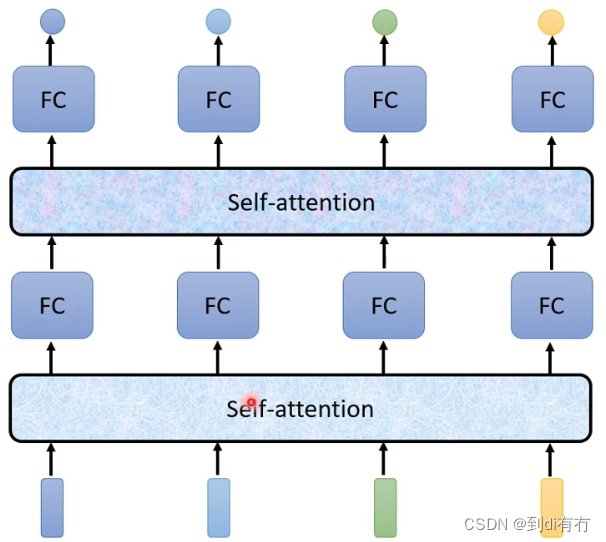
self-attention运作机制:self-attention会处理整个输入的序列,输入几个vector(最下方4个方格)同时就会输入几个vector(处理后带黑色边框的方格,此时新的vector是考虑整个序列信息得到的新vector),再把的到的新的vector输入到全连接神经网络,然后得到希望输出的东西,如此依赖全连接神经网络便是考虑了全局的信息,而不是部分或者某个窗口内的信息。self-attention可以用多次,即下发的网络结构
关于self-attention最出名文章即Attention is all you need,本篇文章中谷歌提出Tansformer架构,Tansformer中最重要的model即self-attention
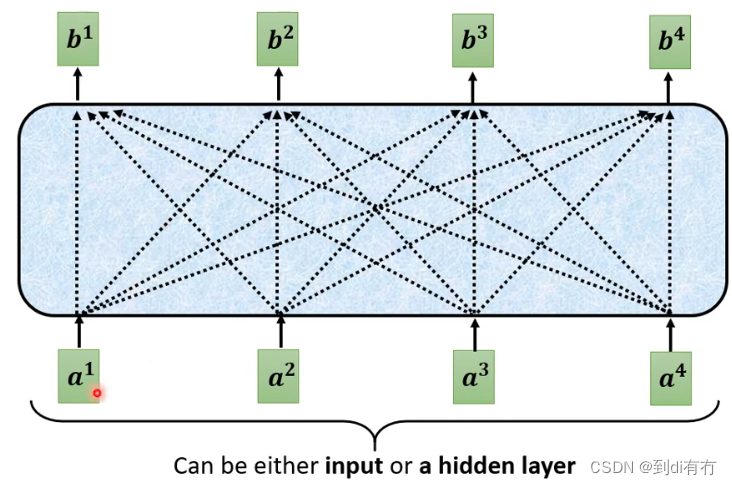
self-attention运作方式
self-attention的输入是一串的vector,这些vector可能是整个网络的输入,也可能是某个隐藏层的输出,每个b向量都是考虑所有的a向量而生成的

如何产生b1向量:(其他同理)
第一步:找出这些序列中(a1-a4)跟a1相关的向量,每个向量跟a1的关联程度使用数值α表示
如何决定两个向量的相关性呢,以a1与a4举例,通常使用一个函数直接计算出两个对应的α,有多种方法:

法1(上图左):常见的方法是dot product(点积),两个向量分别乘以两个不同的矩阵(Wq,Wk),得到两个新的向量(q,k),再将q和k做点积便得到alpha。法2(上图右):在得到q与w后将两个向量串起来,通过激活函数,再通过一个转换得到α。后续讨论中均使用上图左方法
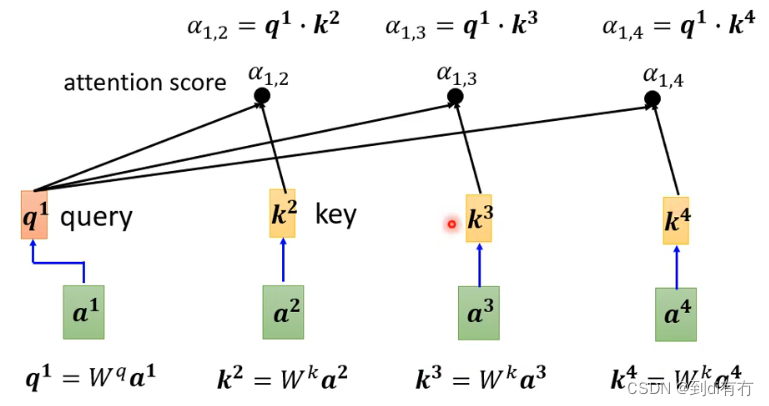
在self-attention中,a1与a2,a3,a4分布计算相关性,把a1乘以wq得到q1(q有个名字叫query),a2乘以wk得到k2(k称之为key),然后q1与q2做内积得到α1,2,α1,2称为a1与a2的attention score,a3与a4同理得到a1,3和a1,4,
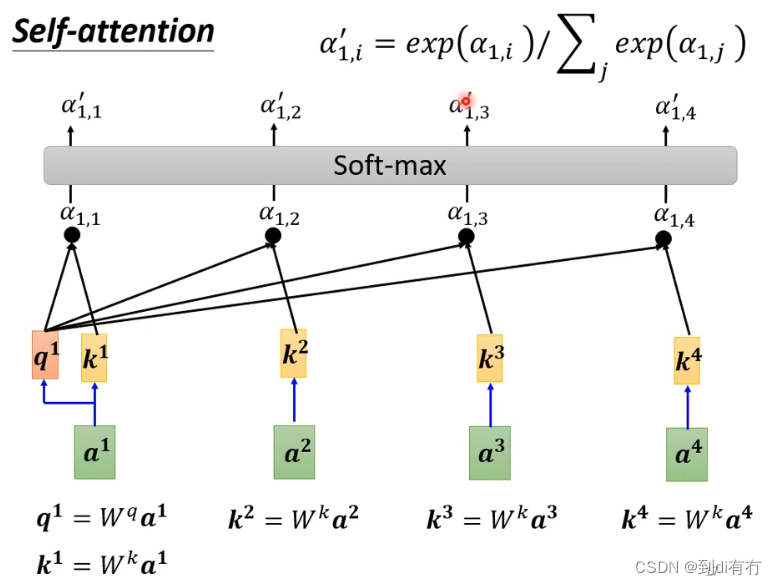
通常在实操中a1也会跟自己算关联性得到α1,1,得到每个关联性后做一个softmax。操作方式:α做一个exp(α1,i),再除以 所有exp(α1,i)加和 做一个归一化(normalized),得到最终输出(α`1,i)。【不一定用softmax,也可以relu,其他的激活函数都行,可以多多尝试】
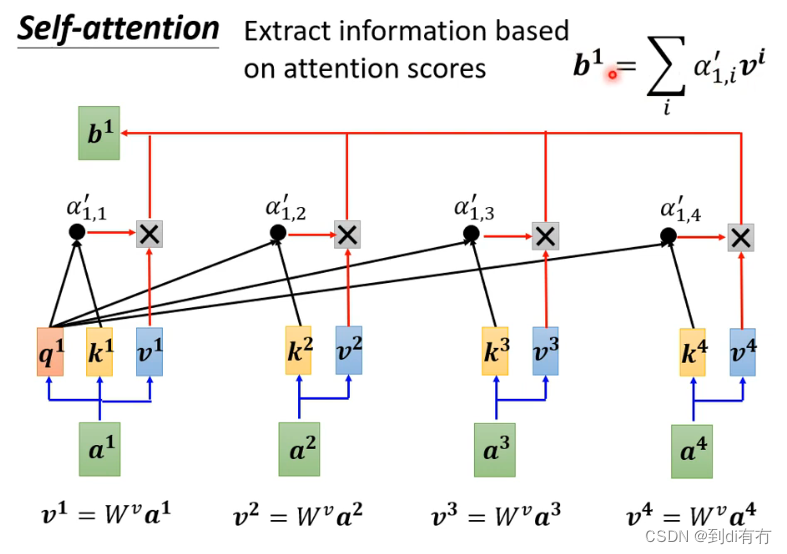
已经知道哪些向量和a1最相关,接下来要抽取相关的信息,抽取方式:将所有向量(a1-a4)乘以wv得到新的向量得到v1-v4,然后再将v1-v4分别乘以对应的α,然后再做一个加和。可以看到的是,对于关联性最高的向量,假设是a2,则得到的α也更大,最终结果b1也就更加多的包含v2的信息
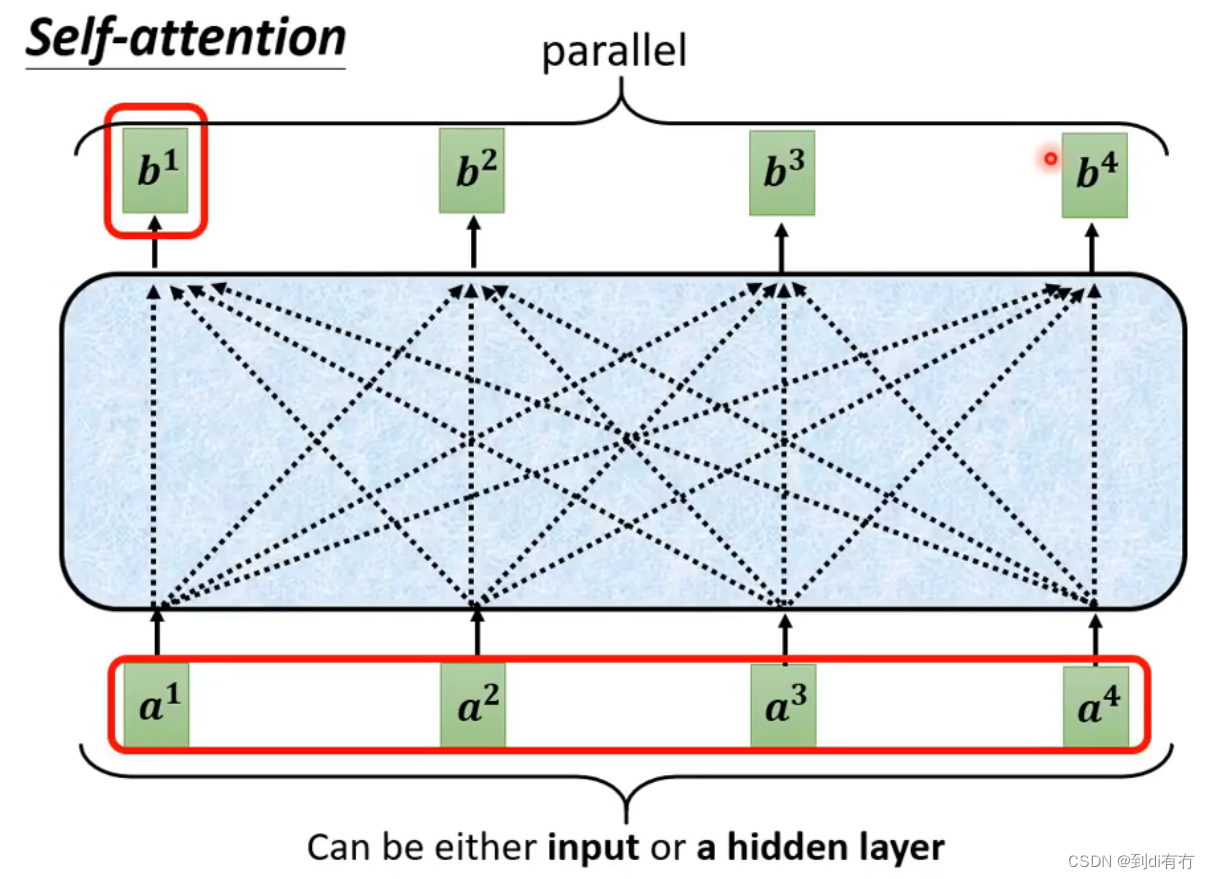
以同样的方式得到b2,b3,b4,在计算b1,b2,b3,b4时可以并行进行,不用一个个挨个算。

b2的计算方式,与b1同理
以上是self-attention的运作过程,接下来从矩阵乘法的角度再讲一次self-attention是怎么运作的
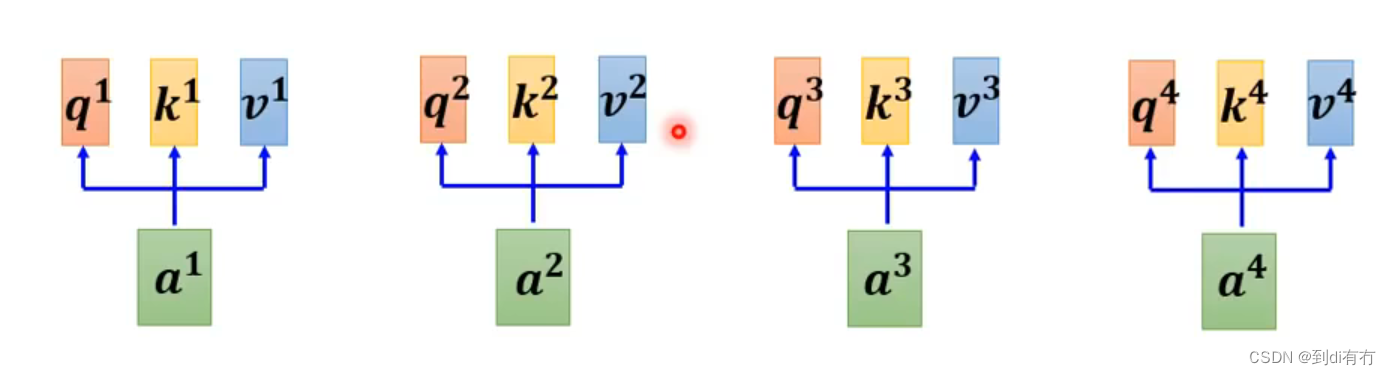
a1到a4每一个都要产生对应的q,k,v
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 166
166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









