





DeepCorr:使用深度学习对Tor进行强流量关联攻击
DeepCorr: Strong Flow Correlation Attacks on Tor Using Deep Learning
| 作者 | 机构 | |
|---|---|---|
| Milad Nasr | University of Massachusetts Amherst | milad@cs.umass.edu |
| Alireza Bahramali | University of Massachusetts Amherst | abahramali@cs.umass.edu |
| Amir Houmansadr | University of Massachusetts Amherst | amir@cs.umass.edu |
| 来源 | 级别 | 年份 |
|---|---|---|
| CCS | 信息安全顶会 | 2018 |
摘要
流量关联(
Flow correlation
\text{Flow correlation}
Flow correlation)是在
Tor
\text{Tor}
Tor上进行多种去匿名化攻击中使用的核心技术。尽管流量关联攻击在
Tor
\text{Tor}
Tor上的重要性不言而喻,现有的流量关联技术在大规模应用时被认为是无效且不可靠的,即它们带来高误报率或需要不切实际的长时间流量观测才能进行可靠的关联。在本文中,我们展示了一个不幸的事实:通过利用新兴的学习机制,流量关联攻击可以在
Tor
\text{Tor}
Tor流量上以前所未有的更高准确性进行。我们特别设计了一个系统,名为
DeepCorr
\text{DeepCorr}
DeepCorr,该系统在关联
Tor
\text{Tor}
Tor连接方面的性能超越了现有技术水平,提高了显著的幅度。
DeepCorr
\text{DeepCorr}
DeepCorr利用一种高级深度学习架构来学习一个专门针对
Tor
\text{Tor}
Tor复杂网络的流量关联函数,这与以往使用通用统计关联指标来关联
Tor
\text{Tor}
Tor流量的工作形成对比。我们展示了通过适度学习,DeepCorr能够以远高于现有算法的准确性关联Tor连接(从而破坏其匿名性),并且使用显著更短的流量观测长度。例如,仅通过收集每个目标
Tor
\text{Tor}
Tor流量的大约
900
900
900个数据包(大约
900KB
\text{900KB}
900KB的
Tor
\text{Tor}
Tor数据),
DeepCorr
\text{DeepCorr}
DeepCorr就能提供
96
%
96\%
96%的流量关联准确度,相比之下,使用相同设置的最先进系统
RAPTOR
\text{RAPTOR}
RAPTOR只有
4
%
4\%
4%的准确度。
我们希望我们的工作能展示出鉴于最近学习算法的进步,流量关联攻击对 Tor \text{Tor} Tor构成的威胁正在升级,这呼吁 Tor \text{Tor} Tor社区及时部署有效的对策。
CCS \text{CCS} CCS概念
• 信息系统 → 流量分析;• 安全与隐私 → 匿名性、伪名性和不可追踪性;保护隐私的协议;• 网络 → 网络隐私和匿名性;
关键词
流量分析; Tor \text{Tor} Tor;流量关联攻击;匿名通信
1 引言
Tor \text{Tor} Tor [16] 是最广泛使用的匿名系统,每天有超过 200 200 200万的日活跃用户 [74]。通过洋葱路由( onion-circuits \text{onion-circuits} onion-circuits)中继用户流量, Tor \text{Tor} Tor 提供匿名性,从而隐藏通信双方的 IP 地址之间的关联。 Tor \text{Tor} Tor 网络包括约 7 , 000 7,000 7,000个公共中继,每天传输数千兆字节的流量 [74]。 Tor \text{Tor} Tor 不仅被异见者、记者、告密者和企业广泛使用,也被普通公民用来实现匿名和抵抗封锁( blocking resistance \text{blocking resistance} blocking resistance)。
为了日常互联网活动(如网页浏览)的可用性, Tor \text{Tor} Tor 旨在提供低延迟通信。为了实现这一点, Tor \text{Tor} Tor 中继避免混淆流量特征,如数据包时序,因为这样做会减慢连接速度【注:请注意,一些 Tor \text{ Tor } Tor 桥(但不是公共中继)通过使用各种 Tor \text{ Tor } Tor 可插拔传输[61]来混淆它们与被审查客户端之间的 Tor \text{ Tor } Tor 流量的特征】。因此, Tor \text{Tor} Tor 因其易受流量关联攻击( flow correlation attacks \text{flow correlation attacks} flow correlation attacks)[14, 51, 68]而闻名,其中攻击者(adversary)试图通过比较出口和入口段的流量特征(尤其是它们的数据包时序和数据包大小)来连接 Tor \text{Tor} Tor 连接的出口和入口。
本文研究了针对 Tor \text{Tor} Tor 的流量关联攻击。流量关联是在广泛针对 Tor \text{Tor} Tor(及类似匿名系统)的攻击中使用的核心技术 [8, 20, 36, 38, 70, 72]。例如,在之前的攻击[83]中,一个控制/监听多个 Tor \text{Tor} Tor中继的攻击者试图通过应用流量关联技术来对 Tor \text{Tor} Tor连接进行去匿名化。 Tor \text{Tor} Tor 项目采用了“守卫”中继以限制此类攻击者在目标 Tor \text{Tor} Tor 连接的两端的定位机会。 Borisov \text{Borisov} Borisov 等人 [8] 展示了一种主动拒绝服务攻击,增加了攻击者观察目标用户 Tor \text{Tor} Tor 连接两端的机会(随后执行流量关联)。此外,也有针对 Tor \text{Tor} Tor 的各种路由攻击 [20, 38, 70, 72],旨在通过操纵路由决策来增加攻击者截获待关联流量的机会。
尽管流量关联在众多
Tor
\text{Tor}
Tor 攻击中扮演着关键角色,但长期以来,规模化地关联
Tor
\text{Tor}
Tor 连接一直被认为是低效的 [37, 55, 66]——但现在不再是这样了!尽管 Tor 中继不主动操纵数据包时序和大小以抵抗流量关联,但是Tor 网络自然地扰乱Tor 数据包,引起显著的网络抖动,使得流量关联成为 Tor 中的一个困难问题。具体来说,
Tor
\text{Tor}
Tor 连接经历的大网络抖动,比普通互联网连接要大得多。这种大的扰动是由
Tor
\text{Tor}
Tor 中继上的拥塞造成的,这是因为
Tor
\text{Tor}
Tor 的容量和来自客户端的带宽需求之间的不平衡。因此,现有的流量关联技术 [34, 45, 53, 72] 遭受高误报率和低准确率的困扰,除非它们应用在非常长的流量观察和/或不切实际的小目标流量集上。例如,最新的流量关联技术
RAPTOR
\text{RAPTOR}
RAPTOR [72] 在区分仅
50
50
50个目标连接的小集合上实现了良好的关联性能,甚至这还需要收集每个截获流量
5
5
5分钟、
100
MB
100 \text{ MB}
100 MB的流量。
在这项工作中,我们将
Tor
\text{Tor}
Tor上的“流量关联”攻击带入现实。我们开发了能够以远高于现有技术水平的准确度关联
Tor
\text{Tor}
Tor 流量的工具,应用于大型匿名集并使用非常短的
Tor
\text{Tor}
Tor 连接观数据。我们认为现有的流量关联技术 [13, 34, 45, 53, 68, 72] 在关联
Tor
\text{Tor}
Tor 流量方面效率低下,因为它们使用的是通用统计关联算法,无法捕捉
Tor
\text{Tor}
Tor 中的动态复杂噪声特性。与使用这种通用目的的统计关联算法相比,本文我们使用深度学习来学习一个专为
Tor
\text{Tor}
Tor 生态系统定制的关联函数。我们的流量关联系统,名为
DeepCorr
\text{DeepCorr}
DeepCorr,随后使用学到的关联函数来交叉关联(
cross-correlate
\text{cross-correlate}
cross-correlate)实时
Tor
\text{Tor}
Tor 流
量
【
1
】
量^{【1】}
量【1】。需要注意的是,与网站指纹攻击 [10, 27, 58, 75, 76] 不同,
DeepCorr
\text{DeepCorr}
DeepCorr 不需要学习任何目标目的地或目标电路;相反,
DeepCorr
\text{DeepCorr}
DeepCorr 学习的是一个可以用来链接任意电路上的流量,并指向任意目的地的关联函数。换句话说,即使连接目的地不是学习集的一部分,
DeepCorr
\text{DeepCorr}
DeepCorr 也能关联
Tor
\text{Tor}
Tor 连接的两端。此外,DeepCorr 甚至可以关联通过与学习过程中使用的电路不同的 Tor 电路发送的流量。这是可能的,因为
DeepCorr
\text{DeepCorr}
DeepCorr 的神经网络学习了
Tor
\text{Tor}
Tor 中的噪声的通用特征,而不考虑训练过程中使用的特定电路和终端主机。
我们通过在实时
Tor
\text{Tor}
Tor 网络上的大规模实验来展示
DeepCorr
\text{DeepCorr}
DeepCorr 的强大性能。我们在
Tor
\text{Tor}
Tor 上浏览了前
50
,
000
50,000
50,000个
Alexa
\text{Alexa}
Alexa 网站,并评估
DeepCorr
\text{DeepCorr}
DeepCorr 在关联记录的
Tor
\text{Tor}
Tor 连接的入口和出口段时的真阳率(
true positive
\text{true positive}
true positive)和假阳率(
false positive
\text{false positive}
false positive
)
【
2
】
)^{【2】}
)【2】。据我们所知,我们的数据集是已公开的最大的关联
Tor
\text{Tor}
Tor 流量数据集[注:https://people.cs.umass.edu/~amir/FlowCorrelation.html]。我们的实验表明,
DeepCorr
\text{DeepCorr}
DeepCorr 的关联准确度远高于现有的流量关联技术。例如,与最先进的流量关联算法 RAPTOR[72] 相比,DeepCorr 提供了96%的关联准确度【注:为了公平,在我们与
RAPTOR
\text{ RAPTOR }
RAPTOR 的比较中,我们采用了类似于
RAPTOR
\text{ RAPTOR }
RAPTOR 论文[72]中的准确性度量方式:每个流量仅与所有评估流量中的一个流量配对。对于我们剩余的实验,每个流量可以被宣称与任意数量的被截获流量相关,这是一个更现实(且更具挑战性)的设置】,而RAPTOR的准确度为4%(当两者都从每个截获的流中收集
900
900
900个数据包时)!以下是
DeepCorr
\text{DeepCorr}
DeepCorr 性能的亮点:
- 我们使用自己生成的 25 , 000 25,000 25,000个 Tor \text{Tor} Tor 流训练 DeepCorr \text{DeepCorr} DeepCorr。在单个 TITAN X \text{TITAN X} TITAN X GPU \text{GPU} GPU上训练 DeepCorr \text{DeepCorr} DeepCorr 大约需要一天,但我们显示攻击者需要大约每月重新训练一次 DeepCorr \text{DeepCorr} DeepCorr 以保持其关联性能。
- DeepCorr \text{DeepCorr} DeepCorr 可以用作通用关联函数: DeepCorr \text{DeepCorr} DeepCorr 的性能对于不同大小且包含通过不同电路路由的流的各种测试数据集是一致的。
- DeepCorr \text{DeepCorr} DeepCorr 大幅超过先前的流量关联算法。重要的是, DeepCorr \text{DeepCorr} DeepCorr 使得 Tor \text{Tor} Tor 流的关联只需比以前的工作所需的流量观察时间短得多。例如,仅用 300 300 300个数据包, DeepCorr \text{DeepCorr} DeepCorr 就实现了 0.8 0.8 0.8的真阳率,而先前的工作不到 0.05 0.05 0.05(固定的假阳率为 1 0 − 3 10^{-3} 10−3)。
- DeepCorr \text{DeepCorr} DeepCorr 的性能随着更长的流观察和更大的训练集迅速提高。
- DeepCorr \text{DeepCorr} DeepCorr 的关联时间比之前的工作快得多,达到相同的目标准确度。例如,当两者针对相同数据集目标95%的准确度时,每次 DeepCorr \text{DeepCorr} DeepCorr 关联只需 2 2 2毫秒,而 RAPTOR \text{RAPTOR} RAPTOR 需要超过 20 20 20毫秒。
鉴于新兴的深度学习算法,我们希望我们的研究能在社区中引起对
Tor
\text{Tor}
Tor 通信中大规模流量分析风险日益增加的关注。一种可能的对策是在所有 Tor 流量上部署流量混淆技术,例如
Tor
\text{Tor}
Tor 可插拔传输 [61] 所采用的技术。我们评估了
DeepCorr
\text{DeepCorr}
DeepCorr 在
Tor
\text{Tor}
Tor 当前部署的每种可插拔传输上的性能,显示出
meek
\text{meek}
meek 和
obfs4-iat0
\text{obfs4-iat0}
obfs4-iat0 对
DeepCorr
\text{DeepCorr}
DeepCorr 的流量关联提供很少的保护,而
obfs4-iat1
\text{obfs4-iat1}
obfs4-iat1 提供了更好的保护(注意,这些混淆机制目前没有被公共
Tor
\text{Tor}
Tor 中继部署,甚至
obfs4-iat1
\text{obfs4-iat1}
obfs4-iat1 也只由少部分
Tor
\text{Tor}
Tor 桥梁部署 [55])。这需要设计有效的流量混淆机制,由
Tor
\text{Tor}
Tor 中继部署,而不会对
Tor
\text{Tor}
Tor 通信造成大的带宽和性能开销。最后,请注意,虽然我们将
DeepCorr
\text{DeepCorr}
DeepCorr 呈现为针对
Tor
\text{Tor}
Tor 的流量关联攻击,但它也可以用于其他流量关联应用。为了证明这一点,我们还将
DeepCorr
\text{DeepCorr}
DeepCorr 应用于踏石检测问题 [6, 26, 80],显示
DeepCorr
\text{DeepCorr}
DeepCorr 在不可靠网络设置中显著优于以前的踏石检测算法。
组织结构:本文的其余部分组织如下。在第2节中,我们概述了“流量关联”的初步知识,并激励我们的工作(motivate
our work)。在第3节中,我们介绍了我们的流量关联系统,称为
DeepCorr
\text{DeepCorr}
DeepCorr。我们在第4节描述我们的实验设置,在第5节展示并讨论我们的实验结果。我们在第6节讨论并评估针对
DeepCorr
\text{DeepCorr}
DeepCorr的可能对策,并在第7节总结本文。
2 预备知识和动机
流量关联攻击,也称为确认攻击( c o n f i r m a t i o n a t t a c k s confirmation\ attacks confirmation attacks),用于在加密和其他内容混淆机制[14, 18, 26, 46, 53, 68, 81, 86]的存在下连接网络流。特别是,流量关联技术可以在匿名通信系统如 Tor \text{Tor} Tor [16] 和混合网络 mix networks \text{mix networks} mix networks [15, 64, 65]中,通过关联流量特征[4, 14, 51, 63, 68, 78, 79, 87]来破坏匿名性,连接匿名连接的出口和入口段。另外,流量关联技术可用于识别使用网络代理来隐藏身份的网络犯罪者,即所谓的跳板(踏石)攻击者[69, 84, 86]。
2.1 威胁模型
图1展示了流量关联场景的主要设置。

该设置包括一个计算机网络(例如 Tor \text{Tor} Tor的网络),有 M \text{M} M个入口流和 N \text{N} N个出口流。一些出口流是某些入口流的混淆版本;然而,由于使用了加密和类似的内容混淆技术如洋葱加密,这些流之间的关系无法通过分析数据包内容来检测。例如,在 Tor \text{Tor} Tor的情况下, F i F_i Fi和 F j F_j Fj是一个 Tor \text{Tor} Tor连接的入口和出口段(见图1),但是通过检查 F i F_i Fi和 F j F_j Fj的数据包内容无法检测到此类关联。我们称( F i F_i Fi, F j F_j Fj)为一对关联流。
在这种设置中,攻击者的目标是通过比较所有入口和出口流的流量特性,例如数据包时序和大小,来识别(部分或全部)关联流对,例如( F i F_i Fi, F j F_j Fj)。使用流量特性连接关联流对被称为流量关联。
流量关联的攻击者可以在各种网络位置截取网络流。特别是 Tor \text{Tor} Tor的攻击者,可以通过运行恶意 Tor \text{Tor} Tor中继[8, 36, 83]或控制/窃听互联网 ASes \text{ASes} ASes或 IXPs \text{IXPs} IXPs[39, 70, 72]来截取 Tor \text{Tor} Tor流。我们将在第2.3节中进一步阐述这一点。
请注意,本文我们只研究被动流量关联攻击;因此,如第2.5节所介绍的,也被称为流水印的主动流量关联技术,不在本文的讨论范围内。此外,流量关联与网站指纹攻击不同,如第2.5节所讨论的。
2.2 现有流量关联技术
如前所述,流量关联技术使用流量特征,特别是数据包时间、数据包大小及其变体(例如,流量速率、数据包间延迟等),来关联和链接网络流(回忆一下,由于内容混淆,例如洋葱加密,在这种设置中不能使用数据包内容来链接流)。例如,Paxson和Zhang的早期工作[86]将数据包到达( packet arrivals \text{packet arrivals} packet arrivals)建模为一系列的ON和OFF模式,他们使用这些模式来关联网络流,而Blum等人[7]关联了一段时间内网络数据包的聚合大小。现有的流量关联技术主要使用标准的统计关联度量来关联流的时间和大小向量。下面,我们概述了以前流量关联算法使用的主要类型的统计关联度量。
互信息( Mutual Information \text{Mutual Information} Mutual Information)互信息度量指标衡量两个随机变量的依赖性。因此,它可以用来量化流特征间的关联,例如,出口 Tor \text{Tor} Tor流的流量特征取决于其对应的入口流的特征。互信息技术已被Chothia等人[13]和Zhu等人[88]用来链接流。然而,这个度量需要一个长的特征向量(例如,长流)才能做出可靠的决策,因为它需要重建并比较目标流的流量特征的经验分布。
皮尔逊相关系数 ( Pearson Correlation \text{Pearson Correlation} Pearson Correlation)皮尔逊相关系数是一个经典的统计度量,用于衡量随机变量之间的线性关系。与互信息度量不同,皮尔逊相关度量不需要建立它所关联的变量的经验分布,因此可以应用于较短的数据长度。皮尔逊相关度量已被多个流量关联系统[45, 68]使用。
余弦相似度( Cosine Similarity \text{Cosine Similarity} Cosine Similarity)余弦相似度度量指标衡量两个随机变量的角度相似性。类似于皮尔逊系数,它可以直接应用于两个随机变量的样本向量。这个度量已被不同的时间和大小关联系统[34, 53]用来链接网络流。
斯皮尔曼相关系数( Spearman Correlation \text{Spearman Correlation} Spearman Correlation)斯皮尔曼等级相关度量指标衡量两个变量的排名之间的统计依赖性。该度量可以定义为排名变量之间的皮尔逊相关。RAPTOR的最近工作[72]使用了这个度量来关联 Tor \text{Tor} Tor流。
2.3 Tor \text{Tor} Tor上的流量关联攻击
流量关联是针对 Tor \text{Tor} Tor(及其他匿名系统)研究的广泛攻击中的核心技术。为了执行流量关联,攻击者需要观察(即截取)进入和离开 Tor \text{Tor} Tor网络的部分流量。如果攻击者能同时截取 Tor \text{Tor} Tor连接的入口和出口段,则可以对特定的 Tor \text{Tor} Tor连接进行去匿名化(通过对这些流量段执行流量关联算法)。因此,攻击者通过尝试截取更大比例的 Tor \text{Tor} Tor入口和出口流量,可以增加其去匿名化 Tor \text{Tor} Tor连接的机会。
攻击者可以采取两种主要方法来增加其截取
Tor
\text{Tor}
Tor连接比例。首先,通过运行大量Tor中继并记录它们转发的Tor连接的流量特征。各种研究表明,具有此类恶意中继访问权限的攻击者可以通过多种方式增加截获
Tor
\text{Tor}
Tor连接两端的机会[3, 8, 28, 49, 83]。例如,
Borisov
\text{Borisov }
Borisov 等人[8]演示了一种主动拒绝服务攻击,以增加截取目标客户
Tor
\text{Tor}
Tor流量的入口和出口段的机会。
Tor
\text{Tor}
Tor项目采用了
Tor
\text{Tor}
Tor守护中继的概念[21],以减少通过控制恶意中继执行流量关联的机会,这种攻击被称为前驱攻击(
predecessor attack
\text{predecessor attack}
predecessor attack)[83]。
另外,攻击者可以通过控制/窃听自治系统( ASes \text{ASes} ASes)或互联网交换点( IXPs \text{IXPs} IXPs),并记录它们过境的 Tor \text{Tor} Tor连接的流量特征,来增加执行流量关联的机会。几项研究[22, 52, 72]表明,特定的 ASes \text{ASes} ASes和 IXPs \text{IXPs} IXPs截获了 Tor \text{Tor} Tor流量的重要部分,因此能够在大规模集上执行 Tor \text{Tor} Tor的流量关联。其他研究[20, 38, 39, 70, 72]显示,一个 AS \text{AS} AS级别的攻击者可以通过执行各种路由操作,将更大比例的 Tor \text{Tor} Tor连接重路由通过其敌对的 ASes \text{ASes} ASes和 IXPs \text{IXPs} IXPs,进一步增加流量关联的机会。例如, Starov \text{Starov} Starov等人[70]最近表明,大约 40 % 40\% 40%的 Tor \text{Tor} Tor电路易受单个恶意 AS \text{AS} AS的流量关联攻击,而 Sun \text{Sun} Sun等人[72]表明, BGP \text{BGP} BGP中的变动以及对 BGP \text{BGP} BGP更新的主动操作可以增强一个敌对 AS \text{AS} AS在 Tor \text{Tor} Tor连接上的可见性。这导致了各种对 Tor \text{Tor} Tor的关于部署面向 AS \text{AS} AS的路径选择机制的方案( proposals \text{proposals} proposals)[2, 20, 54]。
2.4 本文的贡献
尽管流量关联是对
Tor
\text{Tor}
Tor的多种攻击的核心[3, 8, 20, 22, 28, 38, 39, 49, 52, 54, 70, 72, 72, 83],现有的流量关联算法被认为在可靠和大规模地链接Tor连接方面是无效的[7, 55, 66]。这是由于Tor的极其充满噪声的网络在Tor流量上施加了巨大的扰动,因此使得关联相关的入口和出口Tor流量的流量特征变得难以可靠地获得。特别是,
Tor
\text{Tor}
Tor网络在
Tor
\text{Tor}
Tor流量上施加了大的网络抖动,这是由于
Tor
\text{Tor}
Tor中继的拥堵造成的,许多
Tor
\text{Tor}
Tor数据包由于不可靠的网络条件被分片和重新打包。因此,现有的流量关联技术提供了差的关联表现——除非应用于非常大的流量观测以及不切实际的小目标流量集【注:请注意,像 [68] 这样的主动攻击超出了我们的讨论范围,如第
2.5
\text{ 2.5 }
2.5 节所述,因为这类攻击很容易被检测到,因此攻击者无法在大规模和长时间内部署而不被发现】。例如,
Sun
\text{Sun}
Sun等人[72]的最新关联技术需要观测每个目标流量
100
MB
100\text{ MB}
100 MB的流量约
5
5
5分钟,才能执行可靠的流量关联。这样长时间的流量观测不仅因
Tor
\text{Tor}
Tor连接的短暂性质(例如,网页浏览会话)而不切实际,而且如果在大规模集上应用,还会带来无法承受的存储要求(例如,一个恶意的
Tor
\text{Tor}
Tor中继很可能截获成千上万的并发流量)。此外,现有技术若不应用于一个不切实际的小疑似流量集,将遭受高误报率的关联,例如
Sun
\text{Sun}
Sun等人[72]在仅
50
50
50个目标流量集之间进行关联。
我们的方法:我们认为现有流量关联技术无效的主要原因是 Tor 网络扰动的强度和不可预测性。我们认为,之前的流量关联技术在关联
Tor
\text{Tor}
Tor流量方面是低效的,因为它们使用的是通用的统计关联算法,这些算法无法捕捉
Tor
\text{Tor}
Tor中动态复杂的噪声特性。与使用这种通用的统计关联指标不同,在本文中,我们使用深度学习来学习一个针对
Tor
\text{Tor}
Tor生态系统定制的关联函数。我们设计了一个流量关联系统,名为
DeepCorr
\text{DeepCorr}
DeepCorr,它学习
Tor
\text{Tor}
Tor的一个流量关联函数,并使用学到的函数来交叉关联实时
Tor
\text{Tor}
Tor连接。值得注意的是,与网站指纹攻击[10, 27, 58, 75, 76]不同,
DeepCorr
\text{DeepCorr}
DeepCorr不需要学习任何目标目的地或目标电路;相反,
DeepCorr
\text{DeepCorr}
DeepCorr学习的是一个关联函数,可以用来连接任意电路上的流量,并且指向任意目的地。换句话说,即使连接目的地未包含在学习集内,
DeepCorr
\text{DeepCorr}
DeepCorr也能关联
Tor
\text{Tor}
Tor连接的两端。此外,即使流量通过与训练过程中使用的电路不同的
Tor
\text{Tor}
Tor电路发送,
DeepCorr
\text{DeepCorr}
DeepCorr也能进行关联。
我们通过在实时 Tor \text{Tor} Tor网络上进行大规模实验,展示了 DeepCorr \text{DeepCorr} DeepCorr的强大关联性能,并将其与以前的流量关联技术进行比较。我们希望我们的研究能在社区中引起对于 Tor \text{Tor} Tor上大规模流量分析风险增加的关注,这些风险是在新兴学习算法的光环下形成的。我们讨论了潜在的对策,并评估 DeepCorr \text{DeepCorr} DeepCorr相对于现有对策的性能。
2.5 我们不涉及的相关主题
主动流量关联(水印) 网络流量水印是上述流量关联技术的一个主动变体。与被动流量关联方案类似,流量水印的目的是利用流量特征(例如数据包大小和时序),这些特征能够持续内容的混淆(
persist content obfuscation
\text{persist content obfuscation}
persist content obfuscation),从而链接网络流。与此相反,流量水印系统需要操纵它们截获的流的流量特征,以便能够进行流量关联。特别是,许多流量水印系统 [29-31, 33, 62, 79, 85] 通过略微延迟网络数据包来扰乱被截获流的数据包时序,以此调制一个人造模式进入流中,称为水印。例如,
RAINBOW
\text{RAINBOW}
RAINBOW [33] 操纵网络数据包之间的时延,以嵌入一个水印信号。一些方案 [32, 44, 62, 79, 85],称为基于间隔的水印,通过将数据包延迟到秘密时间间隔中来工作。
虽然被动流量关联攻击(本文研究的)在信息理论上是无法检测的,但是一个利用水印的攻击者可能由于应用与正常流量不同的流量扰动来暴露自己。一些主动关联技术 [12, 68] 甚至不追求隐形,因此它们可以被轻易地检测和禁用,使它们不适用于大规模流量关联。此外,尽管被动流量关联算法可以离线计算,但流量水印需要由有资源的攻击者执行,这些攻击者能够对实时的 Tor \text{Tor} Tor 连接应用流量操纵。在本文中,我们只关注被动流量关联技术。
网站指纹识别 网站指纹识别攻击 [10, 24, 25, 27, 40, 47, 57, 58, 75-77] 使用与流量关联技术不同的威胁模型。在网站指纹识别中,攻击者截获目标客户端的入口 Tor \text{Tor} Tor 流量(例如,通过窃听 Tor \text{Tor} Tor 客户端及其守卫中继之间的链接 ) 【 4 】 )^{【4】} )【4】,并将截获的入口 Tor \text{Tor} Tor 连接与一组目标网站的流量指纹(通常是小规模的)进行比较。这与流量关联攻击不同,在流量关联攻击中,攻击者截获匿名连接的两端,使得攻击者能够对任意发送者和接收者进行去匿名化。现有的网站指纹识别系统利用标准的机器学习算法,如 SVM \text{SVM} SVM 和 kNN \text{kNN} kNN,来分类和识别目标网站,而近期的工作 [67] 探讨了使用深度学习进行网站指纹识别。相反,如第 2.2 节概述的,之前的被动流量关联技术使用统计相关性指标来链接网络流中的流量特征。我们认为网站指纹识别与我们的工作正交,因为它基于不同的威胁模型和技术。
3 引入 DeepCorr
在本节中,我们将介绍我们的流量关联系统,名为 DeepCorr \text{DeepCorr} DeepCorr,它使用深度学习算法来学习关联函数。
3.1 特征及其表示
与早先概述的现有流量关联技术类似,我们的流量关联系统使用网络流的时间和大小来交叉关联它们。深度学习算法相对于传统学习技术的一个主要优势[23]是可以直接使用原始数据特征,而不是工程化的流量特征 (如由
SVM
\text{SVM}
SVM和
kNN
\text{kNN}
kNN-基础的网站指纹技术使用的特征[10, 24, 25, 27, 47, 57, 58, 75, 76])。这是因为深度学习能够从原始输入特征[23] 中提取复杂而有效的特征。因此,
DeepCorr
\text{DeepCorr}
DeepCorr接受原始流特征作为输入,并使用它们来衍生复杂特征,这些特征被其关联函数所使用。
我们用以下数组表示一个双向网络流
i
i
i:
F
i
=
[
T
i
u
;
S
i
u
;
T
i
d
;
S
i
d
]
\text{F}_i = [T^u_i; S^u_i; T^d_i; S^d_i]
Fi=[Tiu;Siu;Tid;Sid]
其中
T
T
T是流
i
i
i的数据包间延迟(
IPD
\text{IPD}
IPD)向量,
S
S
S是第
i
i
i 个数据包大小的向量,上标
u
u
u 和
d
d
d 代表双向流
i
i
i 的“上行”和“下行”侧(例如,
T
i
u
T^u_i
Tiu是
i
i
i 的上行
IPDs
\text{IPDs}
IPDs 向量)。同时,请注意,我们只使用每个向量的前
l
l
l 个元素,例如,只有前
l
l
l 个上行
IPDs
\text{IPDs}
IPDs。如果向量的元素少于
l
l
l ,我们通过添加零将其补充到
l
l
l。在学习过程中,我们将使用流表示(
flow representation
\text{flow representation}
flow representation)
F
i
\text{F}_i
Fi。
假设我们的目标是关联两个流
i
i
i和
j
j
j(比如说
i
i
i 被一个恶意的
Tor
\text{Tor}
Tor守卫中继截获,
j
j
j 被一个同伙出口中继截获)。我们用以下两维数组表示这对流,由8行组成:
F
i
,
j
=
[
T
i
u
;
T
j
u
;
T
i
d
;
T
j
d
;
S
i
u
;
S
j
u
;
S
i
d
;
S
j
d
]
\text{F}_{i,j} = [T^u_i; T^u_j; T^d_i; T^d_j; S^u_i; S^u_j; S^d_i; S^d_j]
Fi,j=[Tiu;Tju;Tid;Tjd;Siu;Sju;Sid;Sjd]
其中数组的行来自流的表示
F
i
\text{F}_i
Fi和
F
j
\text{F}_j
Fj。
3.2 网络架构
我们使用卷积神经网络( CNN \text{CNN} CNN)[23]来学习 Tor \text{Tor} Tor噪音网络( noisy network \text{noisy network} noisy network)的关联函数。我们使用 CNN \text{CNN} CNN,因为网络流特征可以被建模为时间序列,而且 CNN \text{CNN} CNN在时间序列上表现良好[23]。此外, CNN \text{CNN} CNN对数据流中模式的位置具有不变性[23],这使它们非常适合寻找可能偏移的流量模式。【注:请注意,我们的工作是第一次使用学习机制进行流量关联。在我们寻找有效的流量关联学习机制过程中,我们尝试了多种算法,包括全连接神经网络、循环神经网络( RNN \text{RNN} RNN)和支持向量机( SVM \text{SVM} SVM)。然而,相比我们调研的所有其他算法,卷积神经网络( CNN \text{CNN} CNN)提供了最佳的流量关联性能,这从直觉上讲是因为 CNN \text{CNN} CNN在处理更长数据长度时表现更好。例如,我们使用全连接网络只达到了 0.4 0.4 0.4的准确率。】
图2显示了 DeepCorr \text{DeepCorr} DeepCorr 的 CNN \text{CNN} CNN 网络结构。
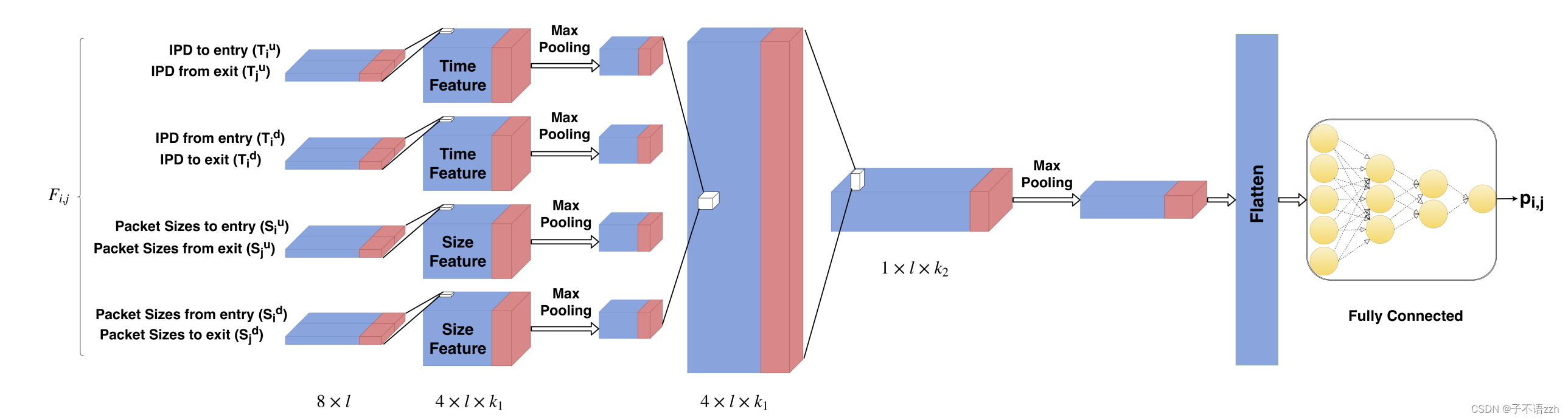
网络从左侧输入流对 F i , j \text{F}_{i,j} Fi,j(在左侧)。 DeepCorr \text{DeepCorr} DeepCorr的架构由两层卷积和三层全连接神经网络组成。第一层卷积层有 k 1 k_1 k1个核,每个大小为 ( 2 , w 1 ) (2,w_1) (2,w1),其中 k 1 k_1 k1和 w 1 w_1 w1是超参数,我们使用 ( 2 , 1 ) (2, 1) (2,1)的步长。使用第一层卷积层的直觉是捕捉输入矩阵 F i , j \text{F}_{i,j} Fi,j中相邻行之间的关联,这些行应该对于关联的 Tor \text{Tor} Tor流是相关的,例如, T i u T^u_i Tiu和 T j u T^u_j Tju之间。
DeepCorr \text{DeepCorr} DeepCorr的第二层卷积层旨在从所有时间和大小特征的组合中捕捉流量特征。在这一层, DeepCorr \text{DeepCorr} DeepCorr使用 k 2 k_2 k2个核,每个大小为 ( 4 , w 2 ) (4,w_2) (4,w2),其中 k 2 k_2 k2和 w 2 w_2 w2也是我们的超参数,它使用 ( 4 , 1 ) (4, 1) (4,1)的步长。
层卷积层的输出被平铺并输入到一个三层全连接网络。
DeepCorr
\text{DeepCorr}
DeepCorr在每一层卷积之后使用最大池化以确保排列不变性并避免过拟合[23]。最终,网络的输出是:
p
i
,
j
=
Ψ
(
F
i
,
j
)
p_{i,j} = \Psi(\text{F}_{i,j})
pi,j=Ψ(Fi,j)
用来决定输入流对 F i , j \text{F}_{i,j} Fi,j是否相关。为了规范化网络输出,我们应用一个 sigmoid \text{sigmoid} sigmoid函数[23]将输出缩放到零和一之间。因此, p i , j p_{i,j} pi,j显示流 i i i 和 j j j 关联的概率(相关),例如,是同一个 Tor \text{Tor} Tor连接的入口和出口段。
DeepCorr \text{DeepCorr} DeepCorr声明流 i i i 和 j j j 是相关的,如果 p i , j > η p_{i,j} > \eta pi,j>η,其中 η \eta η 是我们在实验中讨论的检测阈值。参数 ( w 1 , w 2 , k 1 , k 2 ) (w_1,w_2, k_1, k_2) (w1,w2,k1,k2)是我们系统的超参数;我们将通过实验调整它们的值。
3.3 训练
为了训练我们的网络,我们使用我们在 Tor \text{Tor} Tor上创建的一大组流对。这包括一大组关联的流对和一大组非关联的流对。一个关联的流对 F i , j \text{F}_{i,j} Fi,j包括一个 Tor \text{Tor} Tor连接的两个段(例如, i i i 和 j j j 是 Tor \text{Tor} Tor连接的入口和出口段)。我们用 y i , j = 1 y_{i,j} = 1 yi,j=1 标记一个关联对。另一方面,每个非关联流对(即负样本)由两个不属于同一个 Tor \text{Tor} Tor 连接的任意 Tor \text{Tor} Tor 流组成。我们用 y i , j = 0 y_{i,j} = 0 yi,j=0 标记这样的非关联对。对于每个捕获的 Tor \text{Tor} Tor 入口流 i i i ,我们通过形成 F i , j \text{F}_{i,j} Fi,j 对,其中 j j j 是任意 Tor \text{Tor} Tor连接的出口段,创建 N neg N_{\text{neg}} Nneg负样本。 N neg N_{\text{neg}} Nneg是一个超参数,其值将通过实验获得。
最后,我们使用如下交叉熵函数定义
DeepCorr
\text{DeepCorr}
DeepCorr的损失函数:
L
=
−
1
∣
F
∣
∑
F
i
,
j
∈
F
y
i
,
j
log
Ψ
(
F
i
,
j
)
+
(
1
−
y
i
,
j
)
log
(
1
−
Ψ
(
F
i
,
j
)
)
(1)
\mathcal{L} = -\frac{1}{|\mathcal{F}|} \sum_{\text{F}_{i,j} \in \mathcal{F}} y_{i,j} \log \Psi(\text{F}_{i,j}) + (1 - y_{i,j}) \log(1 - \Psi(\text{F}_{i,j})) \tag{1}
L=−∣F∣1Fi,j∈F∑yi,jlogΨ(Fi,j)+(1−yi,j)log(1−Ψ(Fi,j))(1)
其中
F
\mathcal{F}
F是我们的训练数据集,由所有关联和非关联流对组成。我们使用
Adam
\text{Adam}
Adam优化器[43]来最小化实验中的损失函数。
Adam
\text{Adam}
Adam优化器的学习率是我们系统的另一个超参数。
4 实验设置
在本节中,我们将讨论我们的数据收集及其伦理问题、我们的超参数选择以及我们的评估指标。
4.1 数据集和收集
图 3 显示了我们 Tor \text{Tor} Tor实验的实验设置。
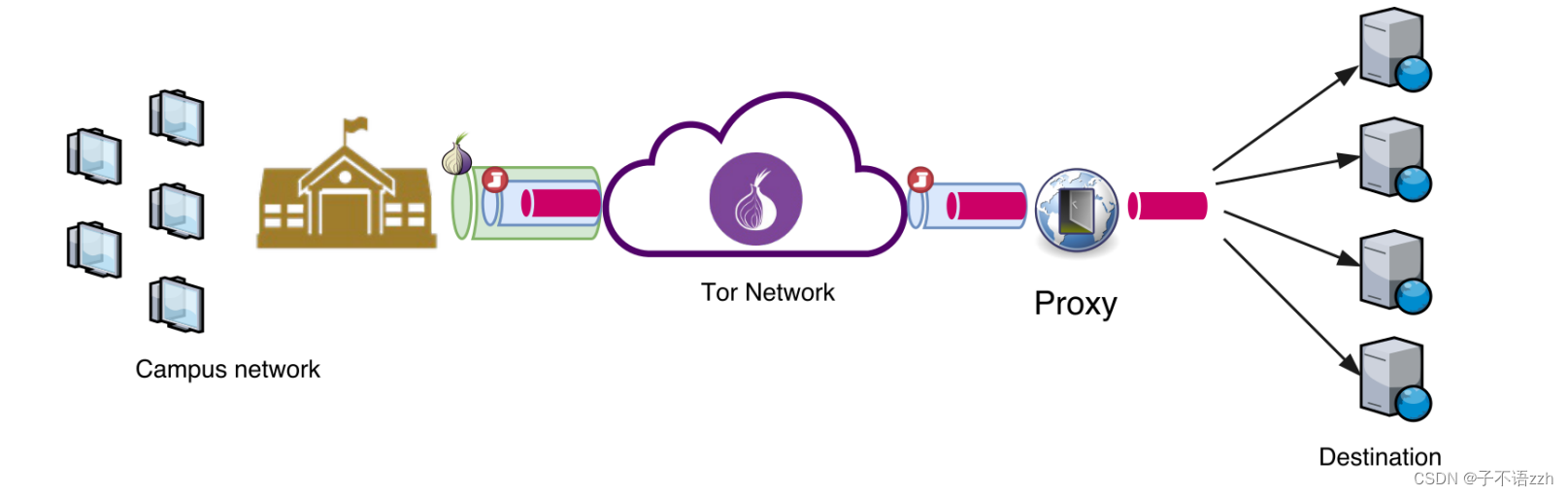
我们使用了多个在独立虚拟机内运行的 Tor \text{Tor} Tor客户端来生成和收集 Tor \text{Tor} Tor流量。我们利用每个 Tor \text{Tor} Tor客户端通过 Tor \text{Tor} Tor浏览前 50 , 000 50,000 50,000个 Alexa \text{Alexa} Alexa网站,并捕获了这些连接进入和退出 Tor \text{Tor} Tor网络的流量(我们使用一半的连接进行训练,另一半进行测试)。因此,进入的流量是 Tor \text{Tor} Tor单元格式( Tor cell format \text{Tor cell format} Tor cell format)的,而退出 Tor \text{Tor} Tor的流量则是常规的 HTTP/HTTPS \text{HTTP/HTTPS} HTTP/HTTPS格式。我们使用了 1 , 000 1,000 1,000个随机的 Tor \text{Tor} Tor电路( Tor circuits \text{Tor circuits} Tor circuits)来浏览网站,即每个电路大约浏览 50 50 50个网站。我们在形成 Tor \text{Tor} Tor电路时使用了不同的守卫节点;我们能够通过禁用 Vanilla Tor \text{Vanilla Tor} Vanilla Tor的强制守卫中继重用选项来交替我们的守卫节点。我们还使用了常规的 Firefox \text{Firefox} Firefox浏览器,而不是 Tor \text{Tor} Tor的浏览器,以便能够强制选择电路。我们使用的 Tor \text{Tor} Tor版本为 0.3.0.9 0.3.0.9 0.3.0.9,由一个 Python \text{Python} Python脚本自动化。
请注意,我们没有为实验的目的设置自己的 Tor \text{Tor} Tor中继,我们仅在所有实验中使用了公共的 Tor \text{Tor} Tor中继。我们使用 tcpdump 【 4 】 \text{tcpdump}^{【4】} tcpdump【4】在我们的 Tor \text{Tor} Tor客户端上捕获了入口 Tor \text{Tor} Tor流量。为了捕获出口 Tor \text{Tor} Tor流量(即,从出口中继到网站的流量),我们使我们的出口 Tor \text{Tor} Tor流量通过我们自己的 SOCKS \text{SOCKS} SOCKS代理服务器(如图3所示)隧道,并在我们自己的 SOCKS \text{SOCKS} SOCKS代理服务器上使用 tcpdump \text{tcpdump} tcpdump收集了出口 Tor \text{Tor} Tor流量。请注意,使用这种数据收集代理可能会在收集的流量上增加额外的延迟,因此 DeepCorr \text{DeepCorr} DeepCorr在实践中的表现比我们通过实验报告的要好。我们还通过 Tor \text{Tor} Tor可插拔传输收集了 500 500 500 个网站,以评估它们作为对抗 DeepCorr \text{DeepCorr} DeepCorr的对策的效果。我们分两步收集了 Tor \text{Tor} Tor流量:首先,我们在两周内收集了流量,然后在隔了三个月后,我们又收集了一个月的 Tor \text{Tor} Tor流量(以展示时间对训练的影响)。我们已将我们的数据集公开。据我们所知,这是最大的相关 Tor \text{Tor} Tor流量数据集,我们希望它对研究社区有用。
请注意,虽然我们只收集网页流量,但这不是 DeepCorr \text{DeepCorr} DeepCorr的限制,它可以用来关联任意的 Tor \text{Tor} Tor流量。
4.2 数据收集的伦理问题
为了确保我们没有使 Tor \text{Tor} Tor 的网络超载,我们在数据收集期间最多同时运行了 10 10 10 个 Tor \text{Tor} Tor 连接。同时,我们交替使用不同的守卫节点来避免过载任何特定的电路或中继。我们没有通过 Tor \text{Tor} Tor 浏览任何非法内容,并且我们的客户端每次连接之间都有闲置时间。如上所述,我们在我们自己的 Tor \text{Tor} Tor客户端以及我们自己的 SOCKS \text{SOCKS} SOCKS代理服务器上收集了我们的入口和出口 Tor \text{Tor} Tor 流量;因此,我们没有收集其他 Tor \text{Tor} Tor 用户的任何流量。在我们的 Tor \text{Tor} Tor 可插拔传输实验中,与我们的裸 Tor \text{Tor} Tor 实验相比,我们收集了一组更少的流量;我们这样做是因为 Tor \text{Tor} Tor桥非常稀少和昂贵,因此我们避免了对桥的过载。
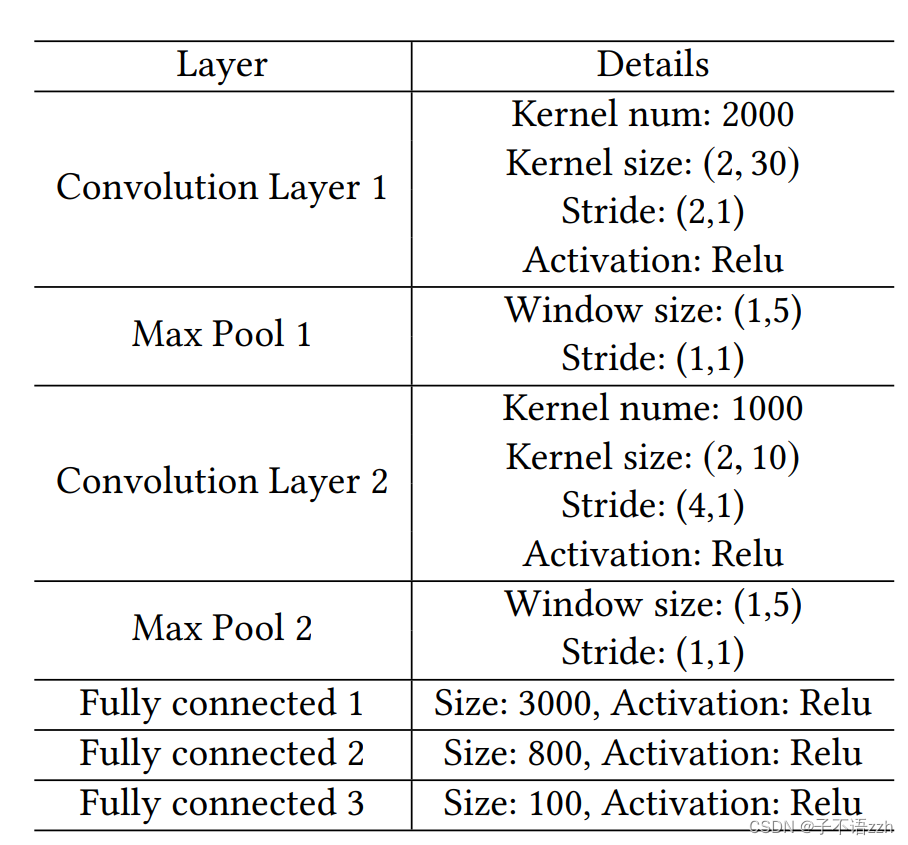
4.3 选择超参数
我们使用
Tensorflow
\text{Tensorflow}
Tensorflow[1]来实现
DeepCorr
\text{DeepCorr}
DeepCorr的神经网络。我们尝试了我们系统的不同超参数的多个值,以优化流量关联性能。为了优化每个参数,我们的网络大约需要一天时间才能收敛(我们使用了一块
Nvidia
\text{Nvidia}
Nvidia
TITAN
\text{TITAN}
TITAN
X
\text{X}
X
GPU
\text{GPU}
GPU)。
对于学习率,我们尝试了
{
0.001
,
0.0001
,
0.0005
,
0.00005
}
\{0.001, 0.0001, 0.0005, 0.00005\}
{0.001,0.0001,0.0005,0.00005} ,并且我们发现学习率为
0.0001
0.0001
0.0001时性能最佳。至于负样本的数量,
N
neg
\text{N}_{\text{neg}}
Nneg,我们尝试了
{
9
,
49
,
99
,
199
,
299
}
\{9, 49, 99, 199, 299\}
{9,49,99,199,299} ,
199
199
199给出了最好的结果。对于卷积层的窗口大小,
w
1
w_1
w1和
w
2
w_2
w2,我们尝试了
{
5
,
10
,
20
,
30
}
\{5, 10, 20, 30\}
{5,10,20,30} 。我们的最佳结果是
w
1
=
30
w_1 = 30
w1=30 和
w
2
=
10
w_2 = 10
w2=10。我们还尝试了
{
2
,
5
,
10
}
\{2, 5, 10\}
{2,5,10} 作为最大池化的大小,最大池化为
5
5
5 时性能最佳。最后,对于内核的数量,
k
1
k_1
k1,
k
2
k_2
k2,我们尝试了
{
500
,
1000
,
2000
,
3000
}
\{500, 1000, 2000, 3000\}
{500,1000,2000,3000} ,
k
1
=
2000
k_1 = 2000
k1=2000 和
k
2
=
1000
k_2 = 1000
k2=1000 结果最佳。我们在表1中呈现了这些参数和系统的其他参数的值。
4.4 评估指标
与以往的研究类似,我们使用真阳性( t r u e p o s i t i v e true\ positive true positive TP \text{TP} TP)和假阳性( f a l s e p o s i t i v e false\ positive false positive FP \text{FP} FP)错误率作为评估流量关联技术性能的主要指标。 TP \text{TP} TP率衡量正确被 DeepCorr \text{DeepCorr} DeepCorr 声明为关联的相关流对的比例(即流对 ( i , j ) (i,j) (i,j),其中 i i i和 j j j是同一个 Tor \text{Tor} Tor连接的段,且我们有 p i , j > η p_{i,j} > \eta pi,j>η)。另一方面, FP \text{FP} FP 率衡量被 DeepCorr \text{DeepCorr} DeepCorr 错误地识别为关联的非相关流对的比例(例如,当 i i i和 j j j是两个无关 Tor \text{Tor} Tor连接的段,但 p i , j > η p_{i,j} > \eta pi,j>η时)。为了评估 FP \text{FP} FP, DeepCorr \text{DeepCorr} DeepCorr将每个收集的入口流与每个收集的出口流相关联,因此,我们在每个实验中进行约 ( 25 , 000 − 1 ) 2 (25,000 - 1)^2 (25,000−1)2次错误关联(我们的测试数据集中有 25 , 000 25,000 25,000个 Tor \text{Tor} Tor 连接)。
需要注意的是,检测阈值 η \eta η 在 FP \text{FP} FP 率和 TP \text{TP} TP 率之间进行权衡;因此,我们利用 ROC \text{ROC} ROC 曲线与其他算法比较 DeepCorr \text{DeepCorr} DeepCorr 的性能。
最后,在与 RAPTOR \text{RAPTOR} RAPTOR [72]的比较中,我们还使用了准确度指标(所有关联中真阳性和真阴性关联的总和),该指标在 RAPTOR \text{RAPTOR} RAPTOR论文中被使用。为了进行公平比较,我们根据 RAPTOR \text{RAPTOR} RAPTOR 的方法导出准确度指标:每个流只能被声明与所有评估流中的单个流相关,例如,导致最大关联度量 p i , j p_{i,j} pi,j的流。对于我们其余的实验,每个流可以被声明与任意数量的截获流相关(即任何满足 p i , j > η p_{i,j} > \eta pi,j>η的对),这是一个更现实(也更具挑战性)的设置。
5 实验结果
在本节中,我们将展示和讨论我们的实验结果。
5.1 对性能的初步观察
正如实验设置部分所述,我们通过 Tor \text{Tor} Tor 浏览前 50 , 000 个 50,000个 50,000个 Alexa \text{Alexa} Alexa 网站,并收集其流入和流出的流量段。我们使用收集的迹线( traces \text{traces} traces)的一半来训练 DeepCorr \text{DeepCorr} DeepCorr(如前所述)。然后,我们使用另一半收集的来测试 DeepCorr \text{DeepCorr} DeepCorr。因此,我们向 DeepCorr \text{DeepCorr} DeepCorr 提供大约 25 , 000 25,000 25,000 对相关流对,以及 25 , 000 × 24 , 999 ≈ 6.2 × 1 0 8 25,000 \times 24,999 \approx 6.2 \times 10^8 25,000×24,999≈6.2×108对非相关流量对进行训练。我们仅使用每个流的前 l = 300 l=300 l=300 个数据包(对于更短的流,我们通过添加零将其填充到 300 300 300个数据包)。图4展示了 DeepCorr \text{DeepCorr} DeepCorr在不同 threshold \text{threshold} threshold η \eta η 值下的真阳性和假阳性错误率。
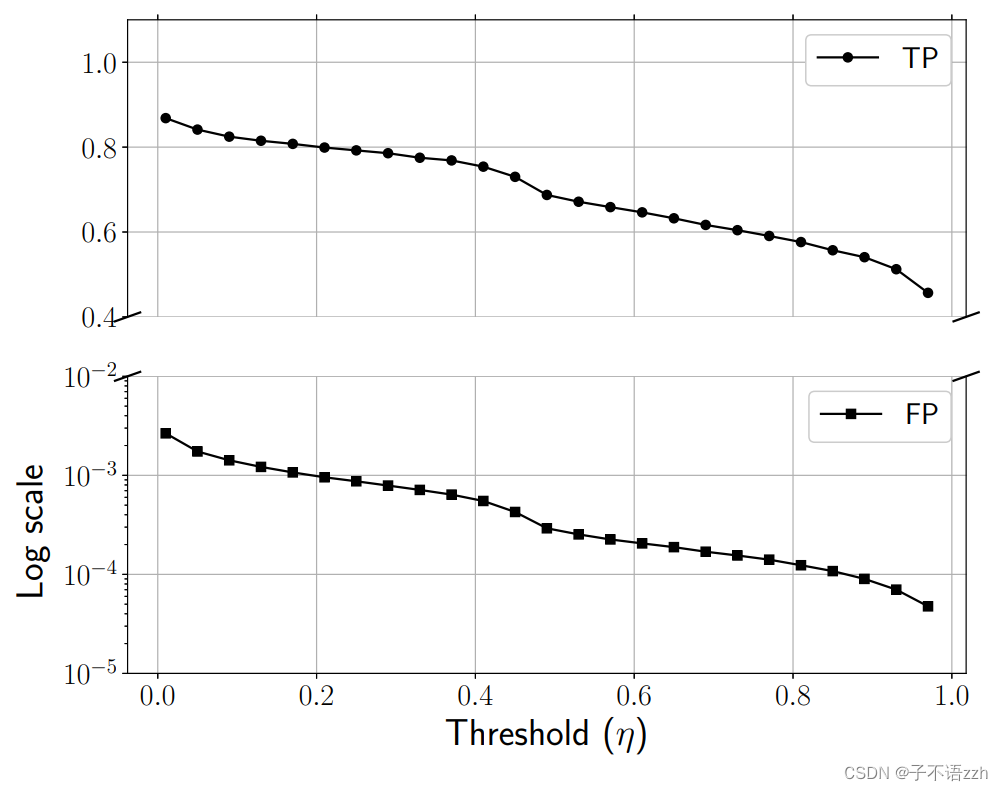
如预期, η \eta η 在 TP \text{TP} TP和 FP \text{FP} FP错误率之间进行权衡。该图表显示 DeepCorr \text{DeepCorr} DeepCorr在仅使用每个流量的 300 300 300 个数据包的情况下,具有很好的性能。例如,对于一个 FP \text{FP} FP为 1 0 − 3 10^{-3} 10−3的情况, DeepCorr \text{DeepCorr} DeepCorr的 TP \text{TP} TP 接近 0.8 0.8 0.8 。如下所示,这比以前的工作的性能明显更好。
关于假阳性错误率的实用性 请注意,对于实际环境中恶意
AS/IXP
\text{AS/IXP}
AS/IXP拦截数千个
Tor
\text{Tor}
Tor连接的情况,
1
0
−
3
10^{-3}
10−3的
FP
\text{FP}
FP 可能看起来太大。首先,这里呈现的结果是基于仅有
300
300
300个数据包的
Tor
\text{Tor}
Tor流,以展示
DeepCorr
\text{DeepCorr}
DeepCorr在短流上的独特性能(以前的工作从未进行过这么短的
Tor
\text{Tor}
Tor流实验并获得可接受的准确度)。如后所示,增加流量长度迅速提高了 DeepCorr 的流量关联性能,例如,从图8可以看出,
450
450
450个数据包的流长度比
300
300
300个数据包的流长度将
FP
\text{FP}
FP 提高了近两个数量级(固定
TP
\text{TP}
TP为
0.8
0.8
0.8)。
这也从图11和图12中可以看出。其次,流量关联攻击者可以部署多阶段攻击以优化准确度和流量收集。例如,他可以在所有拦截的 Tor \text{Tor} Tor 流的前 300 300 300 个数据包上应用 DeepCorr \text{DeepCorr} DeepCorr,然后收集第一阶段攻击检测到的流对的更多数据包。然后,他重新应用 DeepCorr \text{DeepCorr} DeepCorr在这些流对的更长观察结果上。第三,攻击者可以执行标准的预过滤机制以进一步降低 FP \text{FP} FP ,例如,他可以忽略所有开始时间明显不同的流对。在我们的实验中,所有的流都有相同的开始时间。
5.2 DeepCorr \text{DeepCorr} DeepCorr可以关联任意电路和目的地
正如之前讨论的, DeepCorr \text{DeepCorr} DeepCorr学习了一个 Tor \text{Tor} Tor的流量关联函数,可以用来关联任意电路和任意目的地的 Tor \text{Tor} Tor流量,不管在训练过程中使用的电路和目的地是什么。为了证明这一点,我们比较了 DeepCorr \text{DeepCorr} DeepCorr 在两个实验中的表现,每个实验包括 2 , 000 2,000 2,000 个 Tor \text{Tor} Tor连接,因此有 2 , 000 2,000 2,000对关联的组合和 2 , 000 × 1 , 999 2,000×1,999 2,000×1,999 对非关联的流量组合。在第一个实验中, DeepCorr \text{DeepCorr} DeepCorr测试的流量使用的电路和目的地与训练期间使用的相同。在第二个实验中, DeepCorr \text{DeepCorr} DeepCorr测试的流量(1)使用的电路与训练期间使用的完全不同,(2)目标网站与训练期间使用的不同,并且(3)是在学习流量后一周收集的。图5比较了两个实验的 DeepCorr \text{DeepCorr} DeepCorr的 ROC \text{ROC} ROC 曲线。
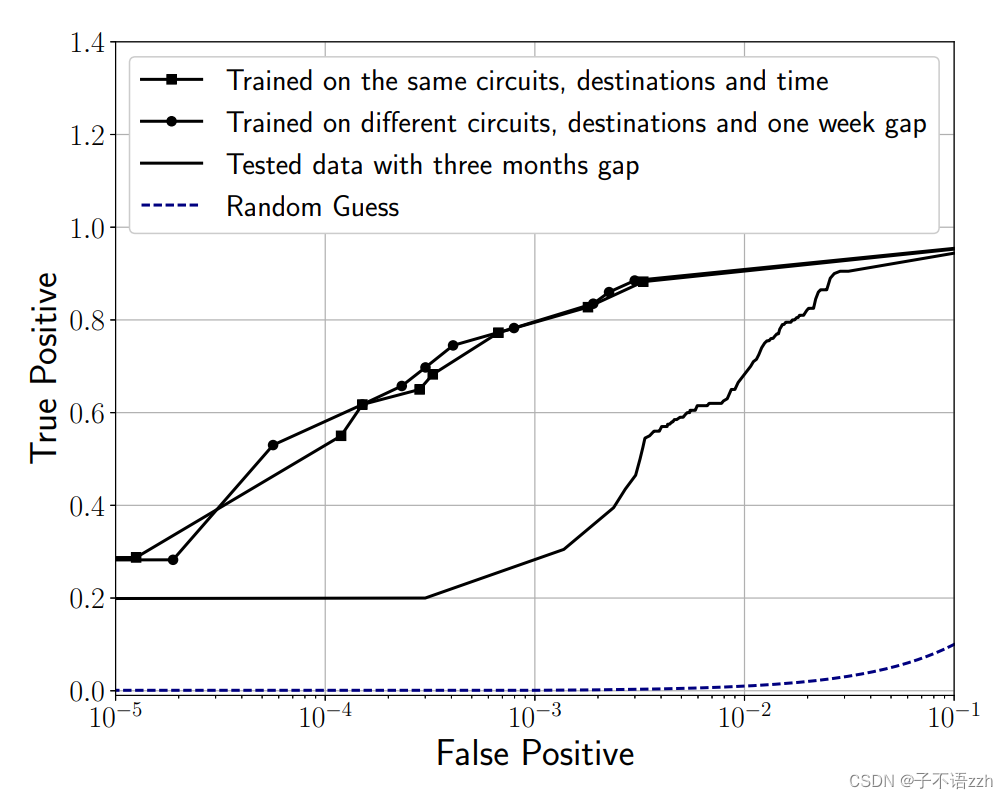
如图所示, DeepCorr \text{DeepCorr} DeepCorr 在两个实验中表现相似,证明了 DeepCorr \text{DeepCorr} DeepCorr 学到的关联函数可以用来关联任意电路和任意目的地的 Tor \text{Tor} Tor 流量。图中的第三条线显示了训练集三个月大时的结果,表现有所下降,下文将进一步讨论。
5.3 DeepCorr \text{DeepCorr} DeepCorr不需要频繁重新训练
由于 Tor \text{Tor} Tor流量的特性随时间变化,任何基于学习的算法偶尔需要重新训练以保持其流量关联性能。我们进行了两个实验来评估 DeepCorr \text{DeepCorr} DeepCorr需要多久重新训练一次。在我们的第一个实验中,我们评估了我们的预训练模型在连续 30 30 30 天收集的 Tor \text{Tor} Tor 流量上的表现。图6展示了每天对于关联和非关联流量组合的关联函数输出。
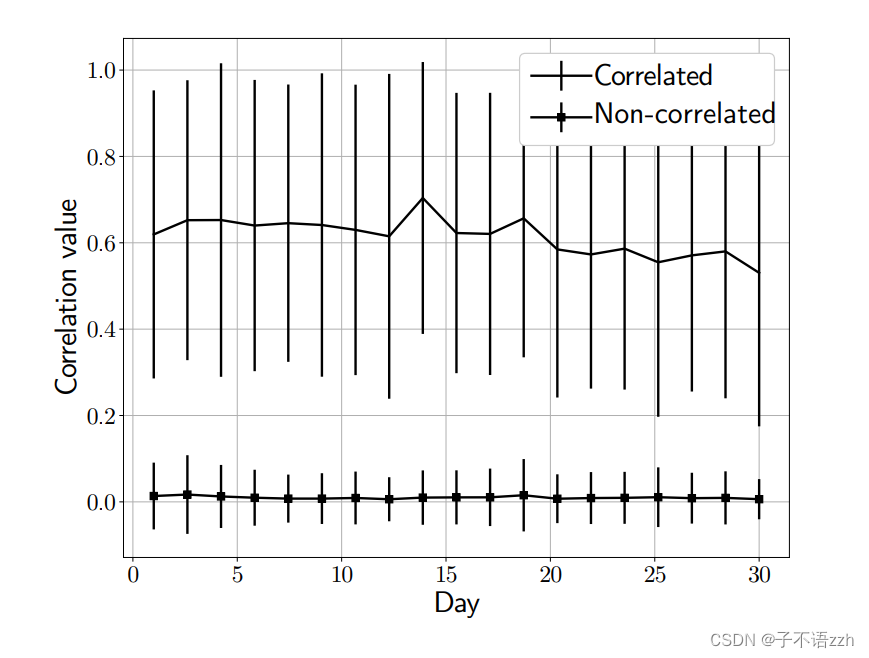
正如我们所见,非关联流量的关联值没有显著变化,然而,关联流量的关联值在大约三周后开始轻微下降。这表明一个攻击者只需要每三周或甚至每个月重新训练一次他的 DeepCorr \text{DeepCorr} DeepCorr。
作为一个极端情况,我们还评估了 DeepCorr \text{DeepCorr} DeepCorr使用三个月前训练的模型的表现。图5比较了三种情况的结果:训练和测试之间有三个月的间隔,一周的间隔,和没有间隔。我们看到,训练和测试之间有三个月间隔时 DeepCorr \text{DeepCorr} DeepCorr的准确性显著下降——有趣的是,即使这种因为缺乏重新训练而显著下降的 DeepCorr \text{DeepCorr} DeepCorr的表现仍然优于图10中比较的所有先前技术。
5.4 DeepCorr \text{DeepCorr} DeepCorr的性能不随测试流量关联数量而降低
我们还展示了 DeepCorr \text{DeepCorr} DeepCorr 的流量关联性能并不依赖于被关联的流的数量,即测试数据集的大小。图 7 展示了不同数量的流的数据集上的真阳性( TP \text{TP} TP)和假阳性( FP \text{FP} FP)结果(针对一个特定阈值)。
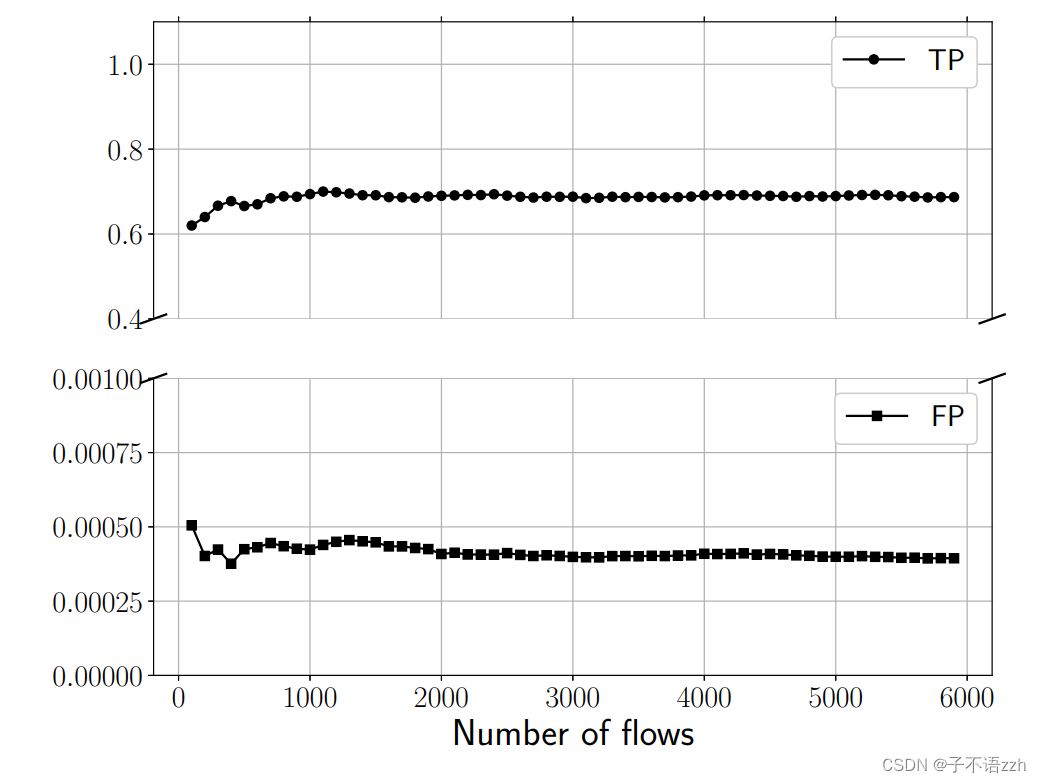
如结果所示,不同数量的流的结果是一致的。这表明如果 DeepCorr \text{DeepCorr} DeepCorr被应用于更大的截取流的数据集上,例如由一个大型恶意 IXP \text{IXP} IXP收集的流,其流量关联性能将与我们实验中得到的相似。
5.5 DeepCorr \text{DeepCorr} DeepCorr的性能随流量关联长度快速提升
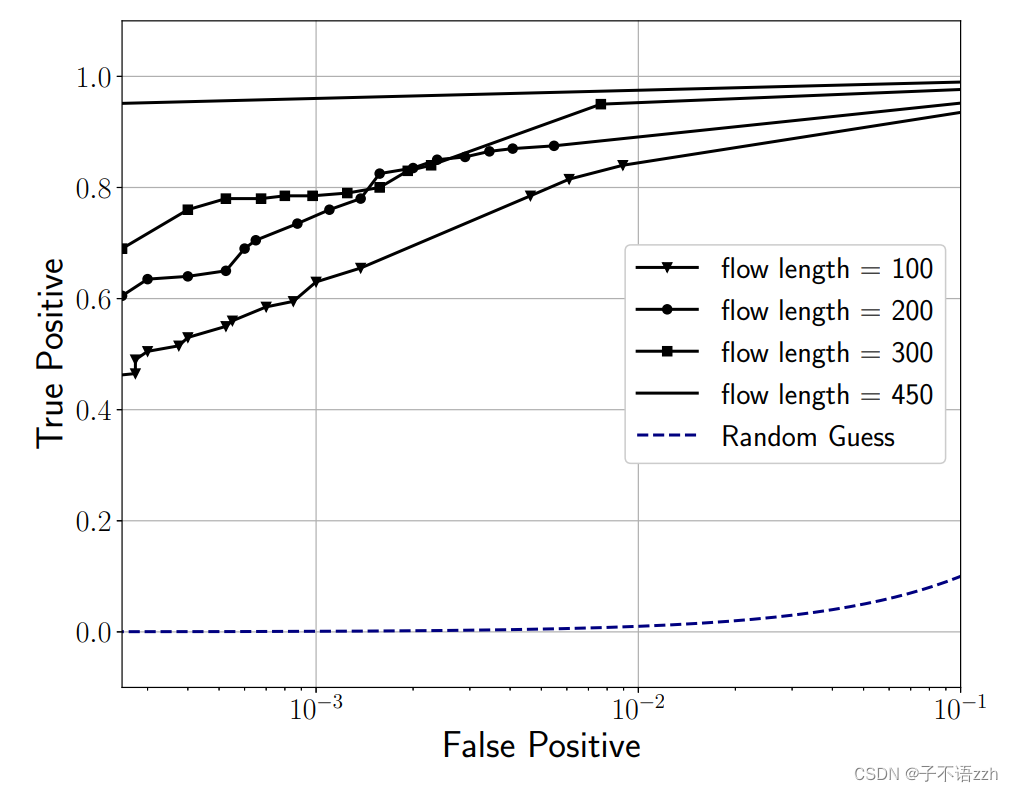
在之前的所有结果中,我们使用的流长度为 l = 300 l = 300 l=300个数据包。可以预料,增加用于训练和测试的流的长度应该会提高 DeepCorr \text{DeepCorr} DeepCorr的性能。图 8 比较了不同长度的流的 DeepCorr \text{DeepCorr} DeepCorr性能,显示了 DeepCorr \text{DeepCorr} DeepCorr在更长的流观测下性能显著提高。
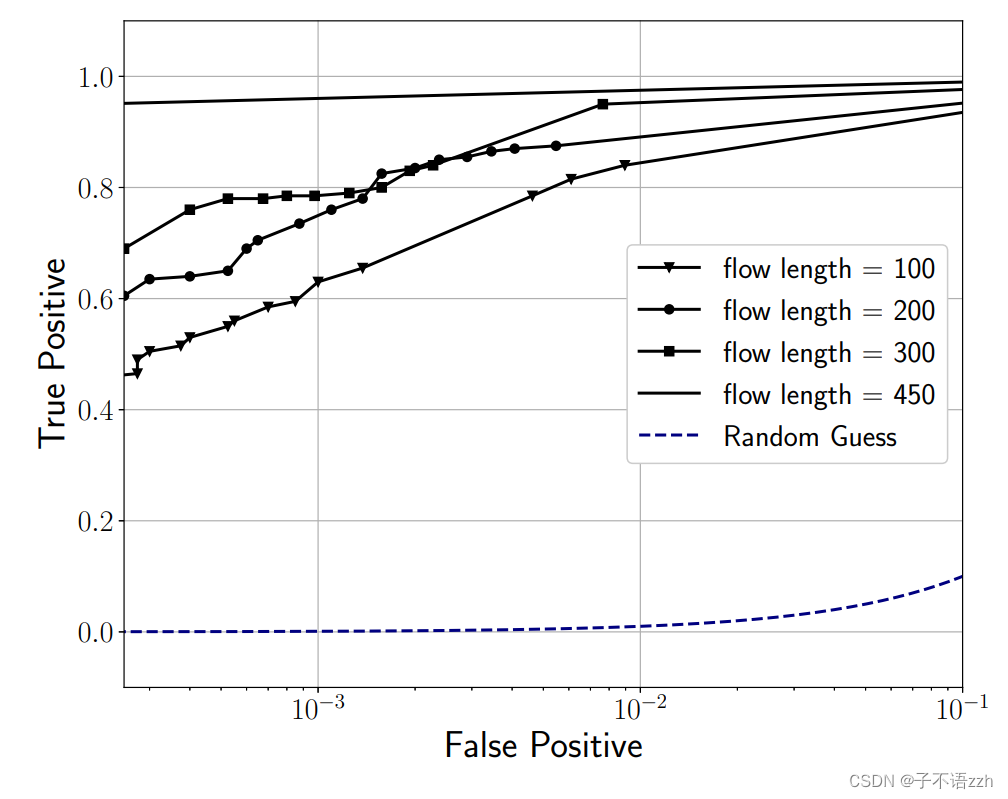
例如,对于目标 FP \text{FP} FP 为 1 0 − 3 10^{-3} 10−3,当 l = 100 l = 100 l=100个数据包的流量关联时, DeepCorr \text{DeepCorr} DeepCorr实现了 TP = 0.62 \text{TP} = 0.62 TP=0.62,而在包含 l = 450 l= 450 l=450个数据包的流量关联时,实现了 TP = 0.95 \text{TP} = 0.95 TP=0.95。
需要注意的是,截取的流的长度在 DeepCorr \text{DeepCorr} DeepCorr 的性能和攻击者的计算开销之间做了一个权衡。也就是说,虽然更长的流长提高了 DeepCorr \text{DeepCorr} DeepCorr 的流量关联性能,但更长的流也给流量关联攻击者带来了更高的存储和计算开销。更长的流长也会增加攻击者在实时检测关联流时的等待时间。
5.6 DeepCorr \text{DeepCorr} DeepCorr的性能随训练集大小提升
正如直觉所预料的, DeepCorr \text{DeepCorr} DeepCorr 的性能在使用更大的 Tor \text{Tor} Tor 流训练集时得到提高(即, DeepCorr \text{DeepCorr} DeepCorr 通过更多的训练样本学习到了更好的 Tor \text{Tor} Tor 流量关联函数)。图 9 比较了 DeepCorr \text{DeepCorr} DeepCorr 在不同数量的流训练下的 ROC \text{ROC} ROC 曲线(在所有实验中,我们用固定的 1000 1000 1000 个流进行测试)。
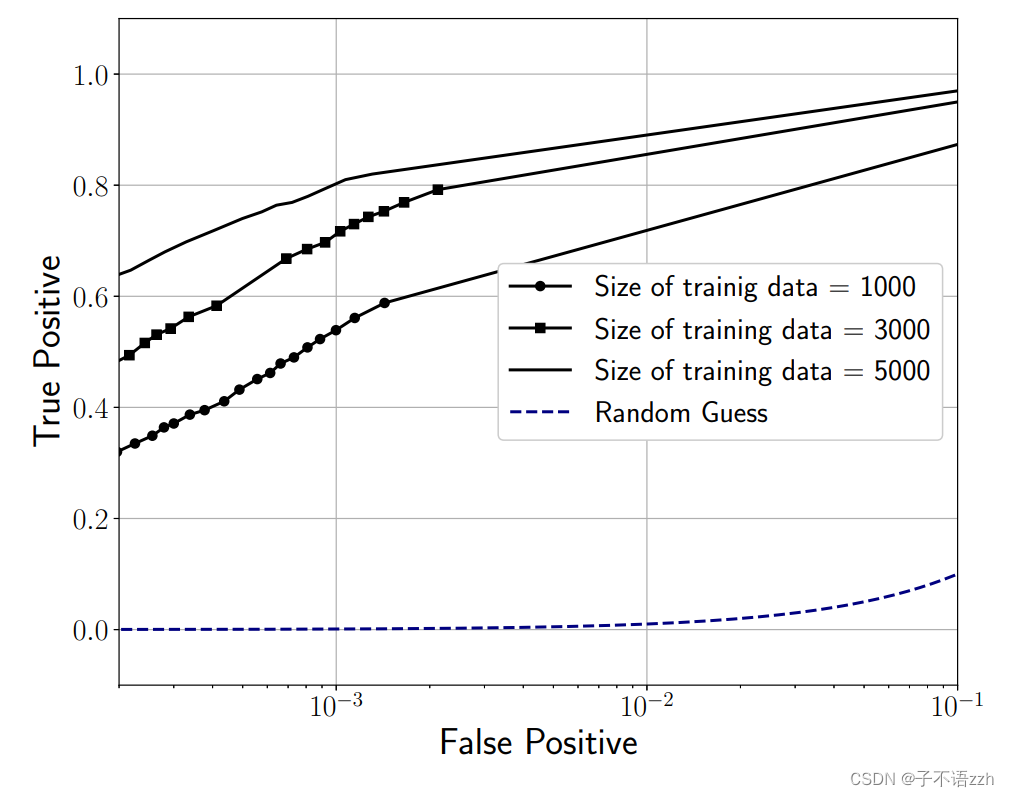
该图确认了增加训练集的大小提高了 DeepCorr \text{DeepCorr} DeepCorr 的性能。例如,对于目标 FP = 1 0 − 3 \text{FP} = 10^{-3} FP=10−3,使用 1000 1000 1000 个训练流结果为 TP = 0.56 \text{TP} = 0.56 TP=0.56,而使用 5000 5000 5000 个流训练则使 DeepCorr \text{DeepCorr} DeepCorr达到了 TP = 0.8 \text{TP} = 0.8 TP=0.8。这表明一个资源丰富的攻击者可以通过收集更多的 Tor \text{Tor} Tor 流用于训练,来提高其流量关联分类器的准确性。需要注意的是,更大的训练集会增加训练时间,然而如之前评估的那样,学习过程不需要频繁重复。
5.7 DeepCorr \text{DeepCorr} DeepCorr显著优于现有技术
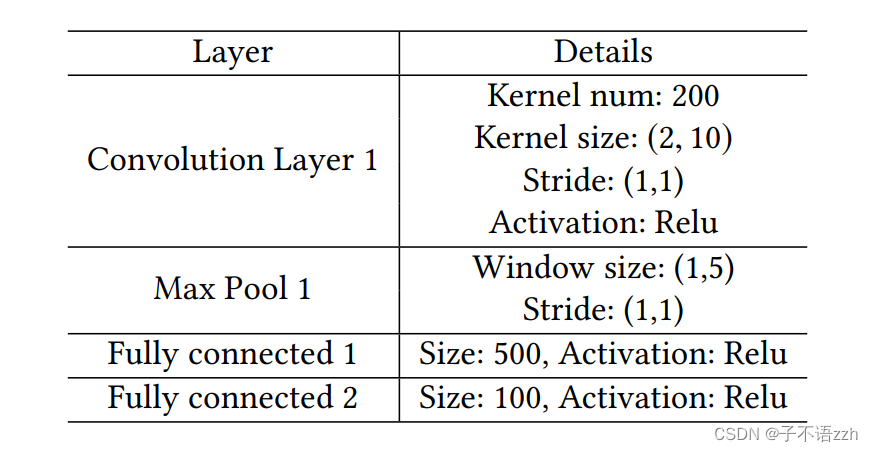
在2.2节中,我们回顾了在我们的工作之前引入的主要流量关联技术。我们进行实验比较 DeepCorr \text{DeepCorr} DeepCorr 与这些早期系统在关联 Tor \text{Tor} Tor流的性能。图10比较了 DeepCorr \text{DeepCorr} DeepCorr与其他系统的 ROC \text{ROC} ROC曲线,其中所有系统都在完全相同的 Tor \text{Tor} Tor流数据集上进行测试(每个流量最多 300 300 300 个数据包)。
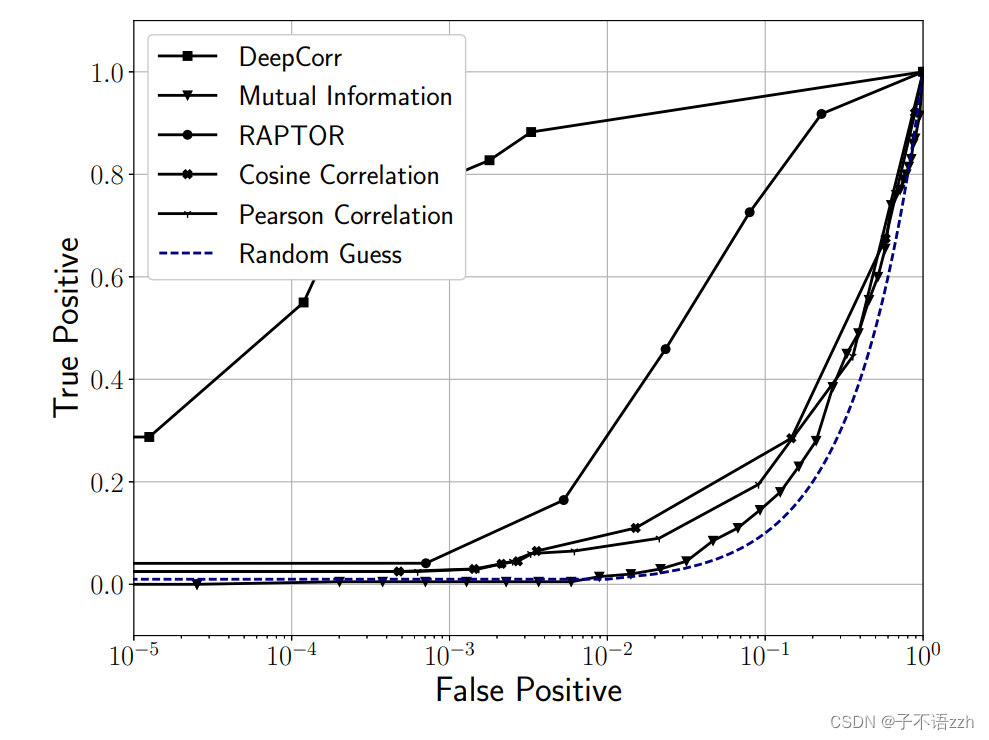
可以看到, DeepCorr \text{DeepCorr} DeepCorr 显著优于以前工作中使用的流量关联算法,我们看到 DeepCorr \text{DeepCorr} DeepCorr 的 ROC \text{ROC} ROC 曲线与其他系统之间有很大的差距。例如,对于目标 FP = 1 0 − 3 \text{FP} = 10^{-3} FP=10−3, DeepCorr \text{DeepCorr} DeepCorr达到了 TP = 0.8 \text{TP} = 0.8 TP=0.8,而以前的系统提供的 TP \text{TP} TP率不到 0.05 0.05 0.05!这一巨大的改进来自于 DeepCorr \text{DeepCorr} DeepCorr 学习了针对 Tor \text{Tor} Tor 的定制关联函数,而以前的系统使用通用的统计关联指标(如2.2节中介绍的)来链接 Tor \text{Tor} Tor 连接。
不用说,任何流量关联算法通过增加其截取用于关联的流的长度(等同于它从每个流收集的流量量)都会提高其性能;我们在5.5节为 DeepCorr \text{DeepCorr} DeepCorr 展示了这一点。为了提供合理的准确性,之前的工作在包含更多数据包(和更多数据)的流上进行了实验。例如,孙等人在只有 50 50 50 个流的设定场景中评估了最新技术 RAPTOR [72] \text{RAPTOR [72]} RAPTOR [72] ,每个流在 5 5 5 分钟内传输 100 MB 100\text{ MB} 100 MB 的数据。而在我们迄今为止介绍的实验中,每个流只有 300 300 300 个数据包,相当于只有约 300 KB 300 \text{ KB} 300 KB的 Tor \text{Tor} Tor流量(与 RAPTOR \text{RAPTOR} RAPTOR的 100 MB 100\text{ MB} 100 MB 相比!)。为了确保公平比较,我们在完全相同的设置下评估 DeepCorr \text{DeepCorr} DeepCorr 与 RAPTOR \text{RAPTOR} RAPTOR(例如,每个 100 MB 100\text{ MB} 100 MB的 50 50 50 个流,并且我们使用4.4节描述的准确性指标)。图11所示的结果表明 DeepCorr \text{DeepCorr} DeepCorr 的性能极为优越(我们的结果与孙等人报告的 RAPTOR \text{RAPTOR} RAPTOR 数字一致[72])。
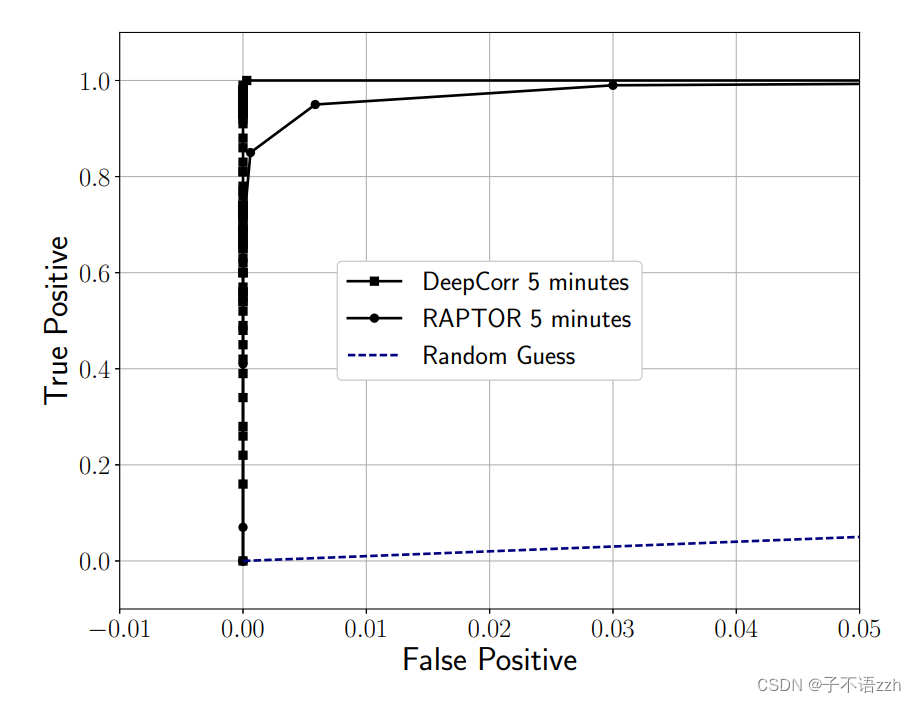
另一方面,我们展示了 DeepCorr \text{DeepCorr} DeepCorr 与 RAPTOR \text{RAPTOR} RAPTOR 在较短流观测之间的性能差距显著更大。为了展示这一点,我们根据它们从每个流截取的流量量比较了 DeepCorr \text{DeepCorr} DeepCorr 和 RAPTOR \text{RAPTOR} RAPTOR 。图12所示的结果表明, DeepCorr \text{DeepCorr} DeepCorr表现显著优越,尤其是在较短的流观测中。
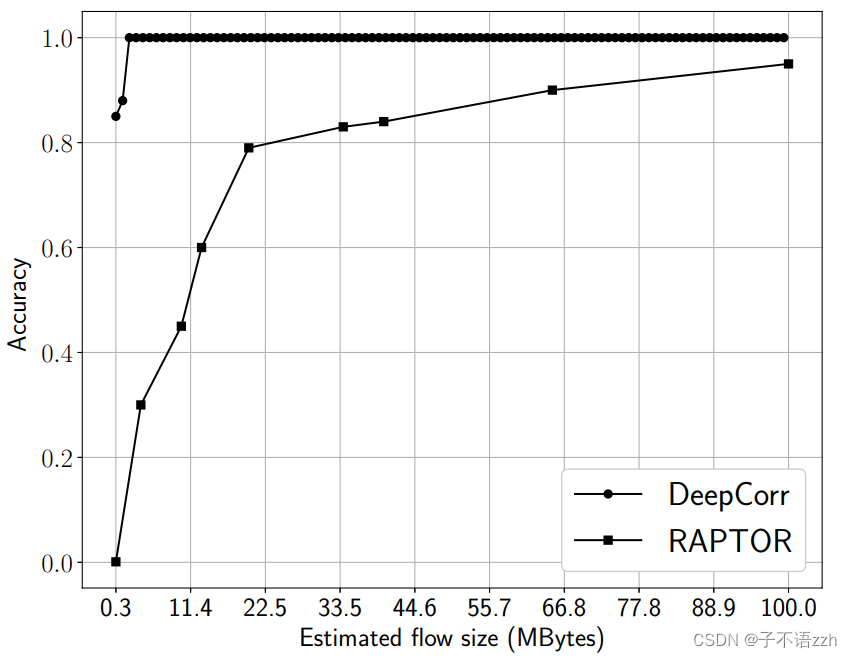
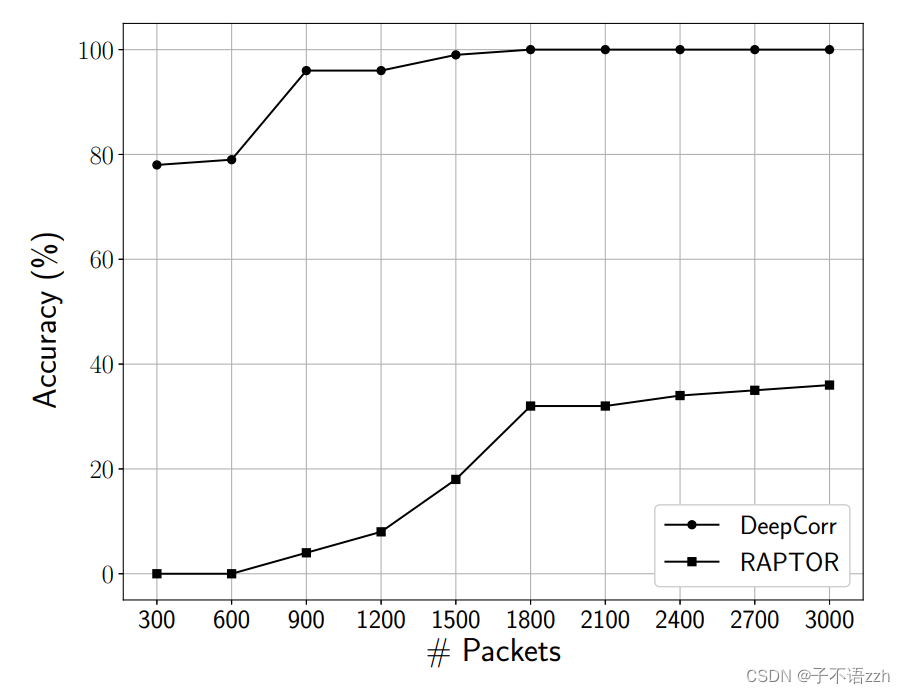
例如, RAPTOR \text{RAPTOR} RAPTOR 在从每个流接收 100 MB 100\text{ MB} 100 MB 后达到了 0.95 0.95 0.95的准确性,而 DeepCorr \text{DeepCorr} DeepCorr在接收约 3 MB 3\text{ MB} 3 MB的流量后达到了 1 1 1 的准确性。我们看到 DeepCorr \text{DeepCorr} DeepCorr 在较短的流观测上特别强大。我们通过比较 RAPTOR \text{RAPTOR} RAPTOR 和 DeepCorr \text{DeepCorr} DeepCorr 在少量观测数据包的情况下,放大了这种能力,这在图13中显示。我们看到 DeepCorr \text{DeepCorr} DeepCorr 仅用 900 900 900 个数据包就实现了约 0.96 0.96 0.96 的准确性,相比之下 RAPTOR \text{RAPTOR} RAPTOR 的准确性为 0.04 0.04 0.04 。
5.8 DeepCorr \text{DeepCorr} DeepCorr的计算复杂性
在表2中,我们展示了进行单次 DeepCorr \text{DeepCorr} DeepCorr 关联的时间与之前技术的比较(所有系统的被关联流都是 300 300 300 个数据包长)。
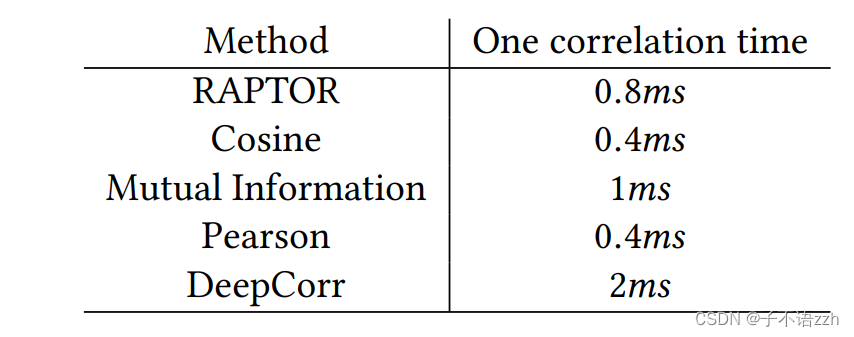
我们看到 DeepCorr \text{DeepCorr} DeepCorr 明显比之前的技术慢,例如,大约比 RAPTOR \text{RAPTOR} RAPTOR 慢两倍。然而,请注意,由于所有系统使用相同长度的流, DeepCorr \text{DeepCorr} DeepCorr 为相同的时间开销提供了极大更好的关联性能;例如,基于图10,我们看到当所有之前的系统提供的 TP \text{TP} TP 都小于 0.2 0.2 0.2 时, DeepCorr \text{DeepCorr} DeepCorr提供的 TP \text{TP} TP约为 0.9 0.9 0.9 。因此,当所有系统提供类似准确性时(例如,每个使用不同长度的输入流), DeepCorr \text{DeepCorr} DeepCorr将比所有系统更快地达到同样的准确性。例如,每次 RAPTOR \text{RAPTOR} RAPTOR 关联需要 20 ms 20 \text{ ms} 20 ms(在更长的流观测中)以达到与 DeepCorr \text{DeepCorr} DeepCorr相同的准确性,而 DeepCorr \text{DeepCorr} DeepCorr只需要 2 ms 2 \text{ ms} 2 ms——即, DeepCorr \text{DeepCorr} DeepCorr在相同准确性下快 10 10 10 倍。
与之前的关联技术相比, DeepCorr \text{DeepCorr} DeepCorr 是唯一有训练阶段的系统。我们使用标准的 Nvidia TITAN X GPU \text{Nvidia TITAN X GPU} Nvidia TITAN X GPU ( 1.5 GHz 1.5\text{GHz} 1.5GHz 时钟速度和 12 GB 12\text{ GB} 12 GB内存)( 4090 4090 4090大约是其性能 3 3 3倍?)训练 DeepCorr \text{DeepCorr} DeepCorr,训练了大约 25 , 000 25,000 25,000对相关流对和 25 , 000 × 24 , 999 ≈ 6.2 × 1 0 8 25,000 × 24,999 ≈ 6.2 × 10^8 25,000×24,999≈6.2×108个非相关流对,每个流包含 300 300 300 个数据包。在这种设置中, DeepCorr \text{DeepCorr} DeepCorr 的训练大约需要一天。回想一下,如5.3节所示, DeepCorr \text{DeepCorr} DeepCorr 不需要频繁重新训练,例如,每三周只需一次。此外,拥有比我们更好的 GPU \text{GPU} GPU 资源的富有资源的攻击者将能够缩短训练时间。
5.9 DeepCorr \text{DeepCorr} DeepCorr在非 Tor \text{Tor} Tor应用中同样有效
虽然我们将 DeepCorr \text{DeepCorr} DeepCorr 介绍为针对 Tor \text{Tor} Tor 的流量关联攻击,但它也可以用于其他流量关联应用。我们通过将 DeepCorr \text{DeepCorr} DeepCorr 应用于跳板攻击问题( stepping stone attacks \text{ stepping stone attacks } stepping stone attacks )[6, 26, 80]来证明这一点。在这种情况下,网络犯罪者通过一个被攻陷的机器(例如,跳板)代理其流量,以隐藏其身份。因此,网络管理员可以使用流量关联来匹配中继连接的入口和出口段,从而追踪到网络犯罪者。以前的工作为这一应用开发了各种流量关联技术[17, 33, 53, 59, 81]。
在我们的跳板 (踏石) 检测实验中,我们使用了2016年
CAIDA
\text{CAIDA}
CAIDA 匿名化数据追踪(迹线?)(
anonymized data traces
\text{ anonymized data traces}
anonymized data traces)[11]。与之前的工作[33, 34, 53]类似,我们通过拉普拉斯分布模拟了网络抖动,并通过伯努利分布模拟了不同率的数据包丢失。我们通过在跳板设置中学习
DeepCorr
\text{DeepCorr}
DeepCorr 来将
DeepCorr
\text{DeepCorr}
DeepCorr 应用于这个问题。由于这个场景中的噪声模型比
Tor
\text{Tor}
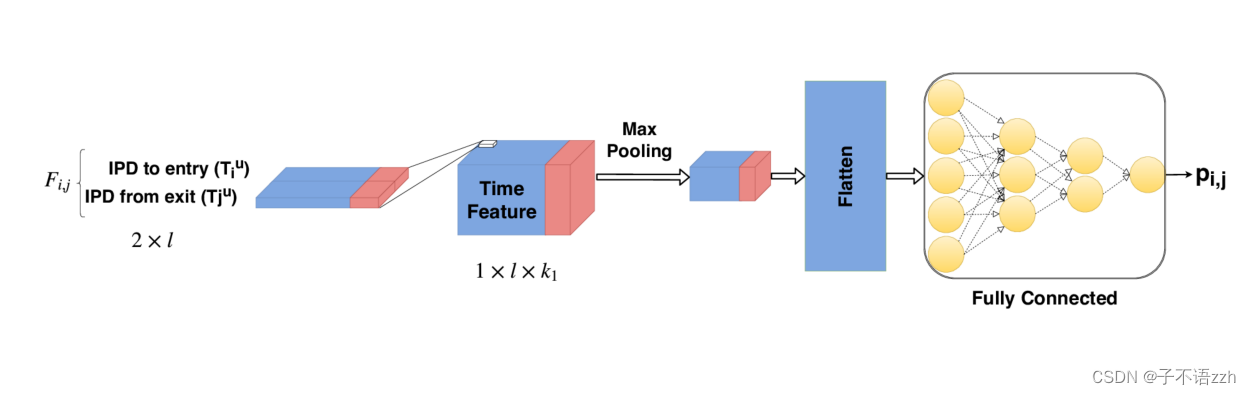
Tor 简单得多,我们为这个应用使用了一个更简单的神经网络模型。此外,我们只使用双向连接的一个方向进行公平比较,以前的系统都只使用单向流。图14和表3分别展示了我们定制的神经网络和我们选择的参数。
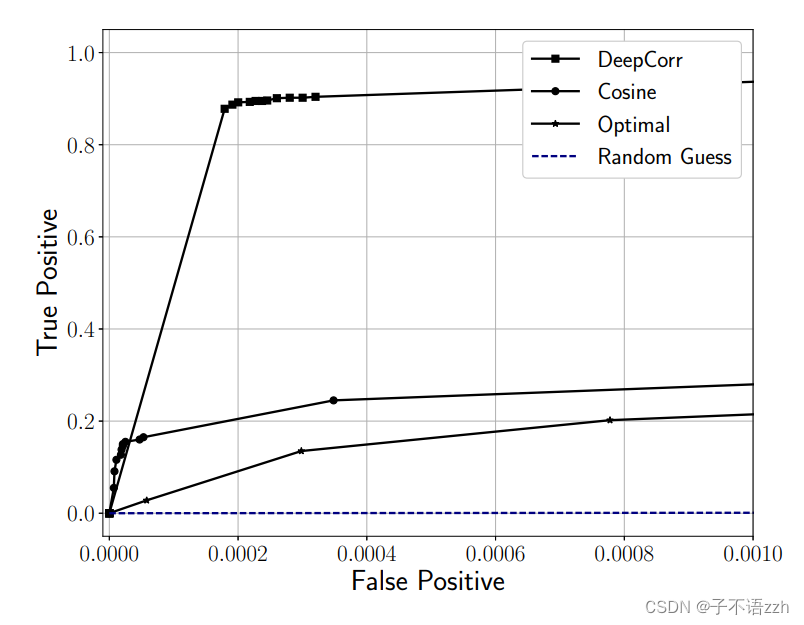
我们的评估显示,在网络条件稳定时, DeepCorr \text{DeepCorr} DeepCorr提供了与 Houmansadr \text{Houmansadr} Houmansadr等人[33, 34]的“最优”流量关联技术可比的( comparable \text{comparable} comparable)性能。然而,当网络条件变得嘈杂时, DeepCorr \text{DeepCorr} DeepCorr在检测跳板攻击方面提供了显著更强的性能。这在图15中显示,其中通信网络的网络抖动标准差为 0.005 0.005 0.005 秒,网络随机丢弃 1 % 1\% 1% 的数据包。
6 对策
虽然之前的工作研究了不同的对策以对抗流量关联和类似的流量分析攻击[2, 9, 19, 35, 41, 42, 50, 56, 61, 82],它们大多未被部署,可能是由于现有流量关联技术在大规模上的性能不佳[60, 66]。以下,我们讨论两种可能的对策。
6.1 模糊流量模式
针对流量关联(以及类似的网站指纹等流量分析攻击)的一种直观对策是模糊算法使用的流量特征。因此,已经提出了各种对策,通过填充或分割数据包来修改数据包大小,或通过延迟数据包来扰乱其时序特性,以击败流量关联。
Tor
\text{Tor}
Tor 项目特别部署了各种可插拔传输[61]以对抗国家封锁所有
Tor
\text{Tor}
Tor 流量的审查。这些可插拔传输中的一些只模糊数据包内容[56],一些模糊
Tor
\text{Tor}
Tor中继的IP地址[48],而一些模糊流量模式[50, 56]。需要注意的是,
Tor
\text{Tor}
Tor 的可插拔传输仅旨在抵抗审查,并且它们只模糊从受审查客户端到它的第一个
Tor
\text{Tor}
Tor 中继(即
Tor
\text{Tor}
Tor 桥)的流量。因此,
Tor
\text{Tor}
Tor 的可插拔传输未被
Tor
\text{Tor}
Tor 的公共中继部署。
作为对 DeepCorr \text{DeepCorr} DeepCorr 的可能对策,我们建议所有 Tor \text{Tor} Tor 中继(包括守卫和中间中继)部署流量模糊技术。我们评估了几种 Tor \text{Tor} Tor 可插拔传输对 DeepCorr \text{DeepCorr} DeepCorr 性能的影响。目前, Tor \text{Tor} Tor 项目部署了三种插件: meek \text{meek} meek、 obfs3 \text{obfs3} obfs3 和 obs4 \text{obs4} obs4。我们在 meek \text{meek} meek 和 obfs4 \text{obfs4} obfs4 上评估了 DeepCorr \text{DeepCorr} DeepCorr ( obfs3 \text{obfs3} obfs3 是 obfs4 \text{obfs4} obfs4 的旧版本)。我们还评估了两种 obfs4 \text{obfs4} obfs4 模式:一种是 IAT \text{IAT} IAT 模式“开”[55],它模糊流量特征;另一种是 IAT \text{IAT} IAT 模式“关”,它不模糊流量特征。我们使用 DeepCorr \text{DeepCorr} DeepCorr 来学习并关联这些插件上的流量。然而,由于伦理原因,我们为这些实验收集的流量集比以前的实验少得多;这是因为 Tor \text{Tor} Tor 桥非常稀少和昂贵,我们因此避免过载桥【注:或者,我们可以为实验搭建自己的 Tor \text{Tor} Tor 桥接。我们决定使用真实世界的桥接,以便在我们的实验中加入实际的流量负载影响】。因此,我们的关联结果由于其小型训练数据集而非常乐观(例如,一个现实世界的攻击者将通过充分的训练实现更高的关联准确性)。我们在 obfs4 \text{obfs4} obfs4 上浏览了 500 500 500 个网站,无论 IAT \text{IAT} IAT 模式是否开启,以及在 meek \text{meek} meek 上。我们仅在每种传输上使用 400 400 400 个流(每个 300 300 300 个数据包)对 DeepCorr \text{DeepCorr} DeepCorr 进行训练(与我们之前的实验中的 25 , 000 25,000 25,000 个流相比),并在另外 100 100 100 个流上进行测试。表4总结了结果。
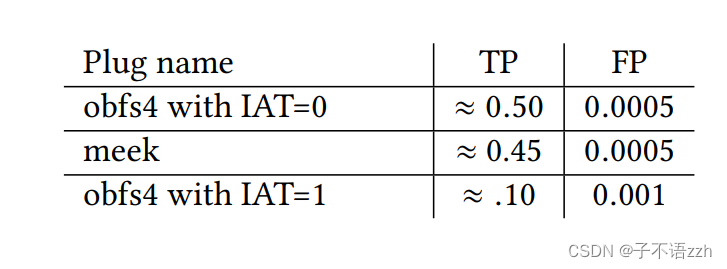
我们看到, meek \text{meek} meek 和 obfs4 \text{obfs4} obfs4 在 IAT=0 \text{IAT=0} IAT=0 时对 DeepCorr \text{DeepCorr} DeepCorr 没有提供保护;注意, 0.5 0.5 0.5 的 TP \text{TP} TP 与我们仅用 400 400 400 个流训练的裸 Tor \text{Tor} Tor 得到的结果相当(见图9),因此我们预期在更大的训练集上会得到类似裸 Tor \text{Tor} Tor 的关联结果。结果是直观的: meek \text{meek} meek 仅模糊了桥的 IP \text{IP} IP 并未部署流量模糊(除了添加自然网络噪音)。此外, obfs4 \text{obfs4} obfs4 在 IAT=0 \text{IAT=0} IAT=0 时仅模糊数据包内容,而不是流量特征。另一方面,我们看到在 obfs4 \text{obfs4} obfs4 与 IAT=1 \text{IAT=1} IAT=1 存在的情况下, DeepCorr \text{DeepCorr} DeepCorr 的性能显著降低(再次, DeepCorr \text{DeepCorr} DeepCorr 的准确性对于一个收集更多训练流的现实世界攻击者将会更高)。
我们的结果表明,(公共的) Tor \text{Tor} Tor 中继应部署像 obfs4 \text{obfs4} obfs4 与 IAT=1 \text{IAT=1} IAT=1 这样的流量模糊机制,以抵抗像 DeepCorr \text{DeepCorr} DeepCorr 这样的高级流量关联技术。然而,这不是一个简单的解决方案,因为这样的模糊机制会增加成本、增加开销(带宽和 CPU \text{CPU} CPU ),并减少服务质量。即使是大多数[55]运行 Obfsproxy Tor \text{Obfsproxy Tor} Obfsproxy Tor 桥的 obfs4 \text{obfs4} obfs4 也不进行流量模糊( IAT=0 \text{IAT=0} IAT=0 )。因此,为 Tor \text{Tor} Tor 设计一个在性能、成本和匿名性之间做出正确平衡的模糊机制仍是未来工作中的一个挑战性问题。
6.2 减少攻击者执行流量关联的机会
另一个针对 Tor 上流量关联的对策是减少攻击者截取许多 Tor 连接两端的机会(从而减少她执行流量关联的机会)。正如之前讨论的,最近的研究[22, 52, 72]表明,各种
ASes
\text{ASes}
ASes 和
IXPs
\text{IXPs}
IXPs 截取了
Tor
\text{Tor}
Tor 流量的显著部分,使它们处于执行流量关联攻击的理想位置。作为对策,几个提议建议
Tor
\text{Tor}
Tor 新的中继选择机制,以减少恶意
ASes
\text{ASes}
ASes 的截取机会[2, 5, 41, 54, 71, 73]。由于对性能、成本和隐私的负面影响,
Tor
\text{Tor}
Tor 尚未部署这些替代方案。我们认为,为
Tor
\text{Tor}
Tor 设计实用的
AS
\text{AS}
AS 智能中继(
AS-aware
\text{AS-aware}
AS-aware)选择机制是防御针对
Tor
\text{Tor}
Tor 的流量关联攻击的一个有希望的途径。
7 结论
我们设计了一个流量关联系统,称为 DeepCorr \text{DeepCorr} DeepCorr,在关联 Tor \text{Tor} Tor 连接方面大大优于现有最先进的系统。 DeepCorr \text{DeepCorr} DeepCorr 利用先进的深度学习架构学习了针对 Tor \text{Tor} Tor 复杂网络的流量关联函数(与之前工作使用的通用统计关联指标相反)。我们展示了通过充分学习, DeepCorr \text{DeepCorr} DeepCorr 可以关联 Tor \text{Tor} Tor 连接(因此打破其匿名性),其准确性显著强于现有算法,并且使用显著更短的流观测长度。我们希望我们的工作展示了由于先进学习算法的兴起,对 Tor \text{Tor} Tor 的流量关联攻击的威胁不断升级,并呼吁 Tor \text{Tor} Tor 社区部署有效的对策。
致谢
本工作得到了 NSF \text{NSF} NSF赠款 CNS-1525642 \text{CNS-1525642} CNS-1525642、 CNS-1553301 \text{CNS-1553301} CNS-1553301和 CNS-1564067 \text{CNS-1564067} CNS-1564067的支持。
参考文献
[1] Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, et al. 2016. TensorFlow: A System for Large-Scale Machine Learning. In OSDI, Vol. 16. 265–283.
[2] Masoud Akhoondi, Curtis Yu, and Harsha V Madhyastha. 2012. LASTor: A low-latency AS-aware Tor client. In Security and Privacy (SP), 2012 IEEE Symposium on. IEEE, 476–490.
[3] Axel Arnbak and Sharon Goldberg. 2014. Loopholes for Circumventing the Constitution: Unrestricted Bulk Surveillance on Americans by Collecting Network Traffic Abroad. Mich. Telecomm. & Tech. L. Rev. 21 (2014), 317.
[4] Adam Back, Ulf Möller, and Anton Stiglic. 2001. Traffic Analysis Attacks and Trade-Offs in Anonymity Providing Systems. In Information Hiding (Lecture Notes in Computer Science), Vol. 2137. Springer, 245–247.
[5] Armon Barton and Matthew Wright. 2016. DeNASA: Destination-naive as-awareness in anonymous communications. Proceedings on Privacy Enhancing Technologies 2016, 4 (2016), 356–372.
[6] Avrim Blum, Dawn Song, and Shobha Venkataraman. 2004. Detection of interactive stepping stones: Algorithms and confidence bounds. In International Workshop on Recent Advances in Intrusion Detection. Springer, 258–277.
[7] A. Blum, D. Song, and S. Venkataraman. 2004. Detection of Interactive Stepping Stones: Algorithms and Confidence Bounds. In RAID.
[8] Nikita Borisov, George Danezis, Prateek Mittal, and Parisa Tabriz. 2007. Denial of service or denial of security?. In Proceedings of the 14th ACM conference on Computer and communications security. ACM, 92–102.
[9] X. Cai, X. Zhang, B. Joshi, and R. Johnson. 2012. Touching from a Distance: Website Fingerprinting Attacks and Defenses. In CCS.
[10] Xiang Cai, Xin Cheng Zhang, Brijesh Joshi, and Rob Johnson. 2012. Touching from a distance: Website fingerprinting attacks and defenses. In Proceedings of the 2012 ACM conference on Computer and communications security. ACM, 605–616.
[11] Caida Trace [n. d.]. The CAIDA UCSD Anonymized Internet Traces 2016 - [2016]. http://www.caida.org/data/passive/passive_2016_dataset.xml.
[12] Sambuddho Chakravarty, Marco V Barbera, Georgios Portokalidis, Michalis Polychronakis, and Angelos D Keromytis. 2014. On the effectiveness of traffic analysis against anonymity networks using flow records. In International conference on passive and active network measurement. Springer, 247–257.
[13] Tom Chothia and Apratim Guha. 2011. A statistical test for information leaks using continuous mutual information. In Computer Security Foundations Symposium (CSF), 2011 IEEE 24th. IEEE, 177–190.
[14] George Danezis. 2004. The traffic analysis of continuous-time mixes. In International Workshop on Privacy Enhancing Technologies. Springer, 35–50.
[15] George Danezis, Roger Dingledine, and Nick Mathewson. 2003. Mixminion: Design of a type III anonymous remailer protocol. In Security and Privacy, 2003. Proceedings. 2003 Symposium on. IEEE, 2–15.
[16] Roger Dingledine, Nick Mathewson, and Paul Syverson. 2004. Tor: The Second-Generation Onion Router. In USENIX Security Symposium.
[17] D. Donoho, A. Flesia, U. Shankar, V. Paxson, J. Coit, and S. Staniford. 2002. Multi-scale Stepping-Stone Detection: Detecting Pairs of Jittered Interactive Streams by Exploiting Maximum Tolerable Delay. In RAID.
[18] David L Donoho, Ana Georgina Flesia, Umesh Shankar, Vern Paxson, Jason Coit, and Stuart Staniford. 2002. Multiscale stepping-stone detection: Detecting pairs of jittered interactive streams by exploiting maximum tolerable delay. In International Workshop on Recent Advances in Intrusion Detection. Springer, 17–35.
[19] K. Dyer, S. Coull, T. Ristenpart, and T. Shrimpton. 2013. Protocol Misidentification Made Easy with Format-Transforming Encryption. In CCS.
[20] M. Edman and P. Syverson. 2009. AS-awareness in Tor path selection. In CCS.
[21] T. Elahi, K. Bauer, M. AlSabah, R. Dingledine, and I. Goldberg. 2012. Changing of the Guards: Framework for Understanding and Improving Entry Guard Selection in Tor. In WPES.
[22] Nick Feamster and Roger Dingledine. 2004. Location Diversity in Anonymity Networks. In Workshop on Privacy in the Electronic Society. Washington, DC, USA.
[23] Ian Goodfellow, Yoshua Bengio, Aaron Courville, and Yoshua Bengio. 2016. Deep learning. Vol. 1. MIT press Cambridge.
[24] Jamie Hayes and George Danezis. 2016. k-fingerprinting: A Robust Scalable Website Fingerprinting Technique… In USENIX Security Symposium. 1187–1203.
[25] Gaofeng He, Ming Yang, Xiaodan Gu, Junzhou Luo, and Yuanyuan Ma. 2014. A novel active website fingerprinting attack against Tor anonymous system. In Computer Supported Cooperative Work in Design (CSCWD), Proceedings of the 2014 IEEE 18th International Conference on. IEEE, 112–117.
[26] Ting He and Lang Tong. 2007. Detecting encrypted stepping-stone connections. IEEE Transactions on Signal Processing 55, 5 (2007), 1612–1623.
[27] Dominik Herrmann, Rolf Wendolsky, and Hannes Federrath. 2009. Website fingerprinting: attacking popular privacy enhancing technologies with the multinomial naïve-bayes classifier. In Proceedings of the 2009 ACM workshop on Cloud computing security. ACM, 31–42.
[28] Nicholas Hopper, Eugene Y Vasserman, and Eric Chan-Tin. 2010. How much anonymity does network latency leak? ACM Transactions on Information and System Security (TISSEC) 13, 2 (2010), 13.
[29] A. Houmansadr and N. Borisov. 2011. SWIRL: A Scalable Watermark to Detect Correlated Network Flows. In NDSS.
[30] Amir Houmansadr and Nikita Borisov. 2011. Towards Improving Network Flow Watermarks using the Repeat-accumulate Codes. In ICASSP.
[31] Amir Houmansadr and Nikita Borisov. 2013. The need for flow fingerprints to link correlated network flows. In International Symposium on Privacy Enhancing Technologies Symposium. Springer, 205–224.
[32] Amir Houmansadr, Negar Kiyavash, and Nikita Borisov. 2009. Multi-Flow Attack Resistant Watermarks for Network Flows. In ICASSP.
[33] Amir Houmansadr, Negar Kiyavash, and Nikita Borisov. 2009. RAINBOW: A Robust And Invisible Non-Blind Watermark for Network Flows. In Network and Distributed System Security Symposium (NDSS).
[34] Amir Houmansadr, Negar Kiyavash, and Nikita Borisov. 2014. Non-blind watermarking of network flows. IEEE/ACM Transactions on Networking (TON) 22, 4 (2014), 1232–1244.
[35] A. Houmansadr, T. Riedl, N. Borisov, and A. Singer. 2013. I Want My Voice to Be Heard: IP over Voice-over-IP for Unobservable Censorship Circumvention. In NDSS.
[36] Rob Jansen, Marc Juarez, Rafa Gálvez, Tariq Elahi, and Claudia Diaz. 2018. Inside Job: Applying Traffic Analysis to Measure Tor from Within. In NDSS.
[37] Filip Jelic. 2016. Tor’s Biggest Threat – Correlation Attack. [Online]. Available: https://www.deepdotweb.com/2016/10/25/tors-biggest-threat-correlation-attack/.
[38] A. Johnson, C. Wacek, R. Jansen, M. Sherr, and P. Syverson. 2013. Users Get Routed: Traffic Correlation on Tor by Realistic Adversaries. In CCS.
[39] Aaron Johnson, Chris Wacek, Rob Jansen, Micah Sherr, and Paul Syverson. 2013. Users get routed: Traffic correlation on Tor by realistic adversaries. In Proceedings of the 2013 ACM SIGSAC conference on Computer & communications security. ACM, 337–348.
[40] Marc Juarez, Sadia Afroz, Gunes Acar, Claudia Diaz, and Rachel Greenstadt. 2014. A critical evaluation of website fingerprinting attacks. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security. ACM, 263–274.
[41] Joshua Juen, Aaron Johnson, Anupam Das, Nikita Borisov, and Matthew Caesar. 2015. Defending Tor from network adversaries: A case study of network path prediction. Proceedings on Privacy Enhancing Technologies 2015, 2 (2015), 171–187.
[42] G. Kadianakis. 2012. Packet Size Pluggable Transport and Traffic Morphing. Tor Tech Report 2012-03-004.
[43] Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
[44] Negar Kiyavash, Amir Houmansadr, and Nikita Borisov. 2008. Multi-Flow Attacks Against Network Flow Watermarking Schemes. In USENIX Security Symposium.
[45] Brian N Levine, Michael K Reiter, Chenxi Wang, and Matthew Wright. 2004. Timing attacks in low-latency mix systems. In International Conference on Financial Cryptography. Springer Berlin Heidelberg, 251–265.
[46] Zhen Ling, Junzhou Luo, Wei Yu, Xinwen Fu, Dong Xuan, and Weijia Jia. 2009. A new cell counter based attack against Tor. In Proceedings of the 16th ACM conference on Computer and communications security. ACM, 578–589.
[47] Liming Lu, Ee-Chien Chang, and Mun Choon Chan. 2010. Website fingerprinting and identification using ordered feature sequences. In European Symposium on Research in Computer Security. Springer, 199–214.
[48] meek [n. d.]. meek Pluggable Transport. [Online]. Available: https://trac.torproject.org/projects/tor/wiki/doc/meek.
[49] Prateek Mittal, Ahmed Khurshid, Joshua Juen, Matthew Caesar, and Nikita Borisov. 2011. Stealthy traffic analysis of low-latency anonymous communication using throughput fingerprinting. In Proceedings of the 18th ACM conference on Computer and communications security. ACM, 215–226.
[50] H. Moghaddam, B. Li, M. Derakhshani, and I. Goldberg. 2012. SkypeMorph: Protocol Obfuscation for Tor Bridges. In CCS.
[51] Steven J Murdoch and George Danezis. 2005. Low-cost traffic analysis of Tor. In 2005 IEEE Symposium on Security and Privacy. IEEE, 183–195.
[52] Steven J. Murdoch and Piotr Zieliński. 2007. Sampled Traffic Analysis by Internet Exchange-Level Adversaries. In Privacy Enhancing Technologies Symposium (Lecture Notes in Computer Science), Nikita Borisov and Philippe Golle (Eds.), Vol. 4776. Springer, Ottawa, Canada.
[53] Milad Nasr, Amir Houmansadr, and Arya Mazumdar. 2017. Compressive Traffic Analysis: A New Paradigm for Scalable Traffic Analysis. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2053–2069.
[54] Rishab Nithyanand, Oleksii Starov, Adva Zair, Phillipa Gill, and Michael Schapira. 2016. Measuring and mitigating AS-level adversaries against Tor. In NDSS.
[55] obfs4 2016. Turning on timing obfuscation (iat-mode=1) for some default bridges. [Online]. Available: https://lists.torproject.org/pipermail/tor-project/2016-November/000776.html.
[56] obfsproxy [n. d.]. A Simple Obfuscating Proxy. [Online]. Available: https://www.torproject.org/projects/obfsproxy.html.en.
[57] Andriy Panchenko, Fabian Lanze, Andreas Zinnen, Martin Henze, Jan Pennekamp, Klaus Wehrle, and Thomas Engel. 2016. Website Fingerprinting at Internet Scale. In Proceedings of the 23rd Internet Society (ISOC) Network and Distributed System Security Symposium (NDSS 2016).
[58] Andriy Panchenko, Lukas Niessen, Andreas Zinnen, and Thomas Engel. 2011. Website fingerprinting in onion routing based anonymization networks. In Proceedings of the 10th annual ACM workshop on Privacy in the electronic society. ACM, 103–114.
[59] V. Paxson and S. Floyd. 1995. Wide-Area Traffic: The Failure of Poisson Modeling. IEEE/ACM Transactions on Networking 3, 3 (June 1995), 226–244.
[60] Mike Perry. 2017. A Critique of Website Traffic Fingerprinting Attacks. [Online]. Available: https://blog.torproject.org/critique-website-traffic-fingerprinting-attacks.
[61] PluggableTransports [n. d.]. Tor: Pluggable Transports. [Online]. Available: https://www.torproject.org/docs/pluggable-transports.html.en.
[62] Young June Pyun, Young Hee Park, Xinyuan Wang, Douglas S Reeves, and Peng Ning. 2007. Tracing traffic through intermediate hosts that repacketize flows. In INFOCOM 2007. 26th IEEE International Conference on Computer Communications. IEEE. IEEE, 634–642.
[63] Daniel Ramsbrock, Xinyuan Wang, and Xuxian Jiang. 2008. A first step towards live botmaster traceback. In Recent Advances in Intrusion Detection. Springer, 59–77.
[64] Michael K Reiter and Aviel D Rubin. 1998. Crowds: Anonymity for web transactions. ACM Transactions on Information and System Security (TISSEC) 1, 1 (1998), 66–92.
[65] Marc Rennhard and Bernhard Plattner. 2002. Introducing MorphMix: peer-to-peer based anonymous Internet usage with collusion
detection. In Proceedings of the 2002 ACM workshop on Privacy in the Electronic Society. ACM, 91–102.
[66] Fatemeh Rezaei and Amir Houmansadr. 2017. TagIt: Tagging Network Flows using Blind Fingerprints. In Privacy Enhancing Technologies (PETS).
[67] Vera Rimmer, Davy Preuveneers, Marc Juarez, Tom Van Goethem, and Wouter Joosen. 2018. Automated Website Fingerprinting through Deep Learning. In NDSS.
[68] Vitaly Shmatikov and Ming-Hsiu Wang. 2006. Timing analysis in low-latency mix networks: Attacks and defenses. In European Symposium on Research in Computer Security (ESORICS). Springer, 18–33.
[69] Stuart Staniford-Chen and L Todd Heberlein. 1995. Holding intruders accountable on the Internet. In Security and Privacy, 1995. Proceedings., 1995 IEEE Symposium on. IEEE, 39–49.
[70] Oleksii Starov, Rishab Nithyanand, Adva Zair, Phillipa Gill, and Michael Schapira. 2016. Measuring and mitigating AS-level adversaries against Tor. In NDSS.
[71] Yixin Sun, Anne Edmundson, Nick Feamster, Mung Chiang, and Prateek Mittal. 2017. Counter-RAPTOR: Safeguarding Tor Against Active Routing Attacks. In Security and Privacy (SP), 2017 IEEE Symposium on. IEEE, 977–992.
[72] Yixin Sun, Anne Edmundson, Laurent Vanbever, Oscar Li, Jennifer Rexford, Mung Chiang, and Prateek Mittal. 2015. RAPTOR: routing attacks on privacy in tor. In 24th USENIX Security Symposium (USENIX Security 15). 271–286.
[73] Henry Tan, Micah Sherr, and Wenchao Zhou. 2016. Data-plane defenses against routing attacks on Tor. Proceedings on Privacy Enhancing Technologies 2016, 4 (2016), 276–293.
[74] tor metrics [n. d.]. Tor Metrics. [Online]. Available: https://metrics.torproject.org.
[75] Tao Wang, Xiang Cai, Rishab Nithyanand, Rob Johnson, and Ian Goldberg. 2014. Effective attacks and provable defenses for website fingerprinting. In 23rd USENIX Security Symposium (USENIX Security 14). 143–157.
[76] Tao Wang and Ian Goldberg. 2013. Improved website fingerprinting on Tor. In Proceedings of the 12th ACM workshop on Workshop on privacy in the electronic society. ACM, 201–212.
[77] Tao Wang and Ian Goldberg. 2016. On realistically attacking Tor with website fingerprinting. Proceedings on Privacy Enhancing Technologies 2016, 4 (2016), 21–36.
[78] Xinyuan Wang, S. Chen, and S. Jajodia. 2005. Tracking Anonymous Peer-to-peer VoIP Calls on the Internet. In CCS.
[79] Xinyuan Wang, Shiping Chen, and Sushil Jajodia. 2007. Network flow watermarking attack on low-latency anonymous communication systems. In Security and Privacy, 2007. SP’07. IEEE Symposium on. IEEE, 116–130.
[80] Xinyuan Wang and Douglas S Reeves. 2003. Robust correlation of encrypted attack traffic through stepping stones by manipulation of interpacket delays. In Proceedings of the 10th ACM conference on Computer and communications security. ACM, 20–29.
[81] Xinyuan Wang, Douglas S Reeves, and S Felix Wu. 2002. Inter-packet delay based correlation for tracing encrypted connections through stepping stones. In Computer Security–ESORICS 2002. Springer, 244–263.
[82] C. Wright, S. Coull, and F. Monrose. 2009. Traffic Morphing: An Efficient Defense Against Statistical Traffic Analysis. In NDSS.
[83] Matthew K Wright, Micah Adler, Brian Neil Levine, and Clay Shields. 2002. An Analysis of the Degradation of Anonymous Protocols. In NDSS, Vol. 2. 39–50.
[84] Kunikazu Yoda and Hiroaki Etoh. 2000. Finding a connection chain for tracing intruders. In Computer Security-ESORICS 2000. Springer, 191–205.
[85] Wei Yu, Xinwen Fu, Steve Graham, Dong Xuan, and Wei Zhao. 2007. DSSS-based flow marking technique for invisible traceback. In Security and Privacy, 2007. SP’07. IEEE Symposium on. IEEE, 18–32.
[86] Yin Zhang and Vern Paxson. 2000. Detecting Stepping Stones… In USENIX Security Symposium, Vol. 171. 184.
[87] Ye Zhu and Riccardo Bettati. 2005. Unmixing Mix Traffic. In Privacy Enhancing Technologies Workshop, David Martin and George Danezis (Eds.). 110–127.
[88] Ye Zhu, Xinwen Fu, Bryan Graham, Riccardo Bettati, and Wei Zhao. 2004. On flow correlation attacks and countermeasures in mix networks. In International Workshop on Privacy Enhancing Technologies. Springer, 207–225.
注释
-
【1】交叉关联(cross-correlation)主要用于测量两个序列在变化时的相似性。这种技术尤其适用于发现两个时间序列之间的潜在关系,比如时间延迟或频率响应。下面我会用一些例子和图表来详细解释交叉关联是如何工作的。
-
基本原理
假设有两个时间序列 x ( t ) x(t) x(t) 和 y ( t ) y(t) y(t),交叉关联函数定义为它们之间在不同时间滞后 τ \tau τ 下的相关性:
R x y ( τ ) = ∑ t x ( t ) ⋅ y ( t + τ ) R_{xy}(\tau) = \sum_{t} x(t) \cdot y(t + \tau) Rxy(τ)=t∑x(t)⋅y(t+τ)这个公式表明,我们通过改变延迟 τ \tau τ,计算 x ( t ) x(t) x(t) 和 y ( t + τ ) y(t + \tau) y(t+τ) 的乘积之和。这种计算可以显示当一个信号相对于另一个信号移动时它们的相似程度。
-
图表解释
让我们用两个简单的信号来说明这一点:一个正弦波和一个延迟的正弦波。
- 信号 A: x ( t ) = sin ( t ) x(t) = \sin(t) x(t)=sin(t)
- 信号 B: y ( t ) = sin ( t + π 4 ) y(t) = \sin(t + \frac{\pi}{4}) y(t)=sin(t+4π)
信号 B 是信号 A 的延迟版本,我们可以通过交叉关联来发现这种延迟。
-
实例计算和图表
图像为这两个信号的图表以及它们的交叉关联函数。
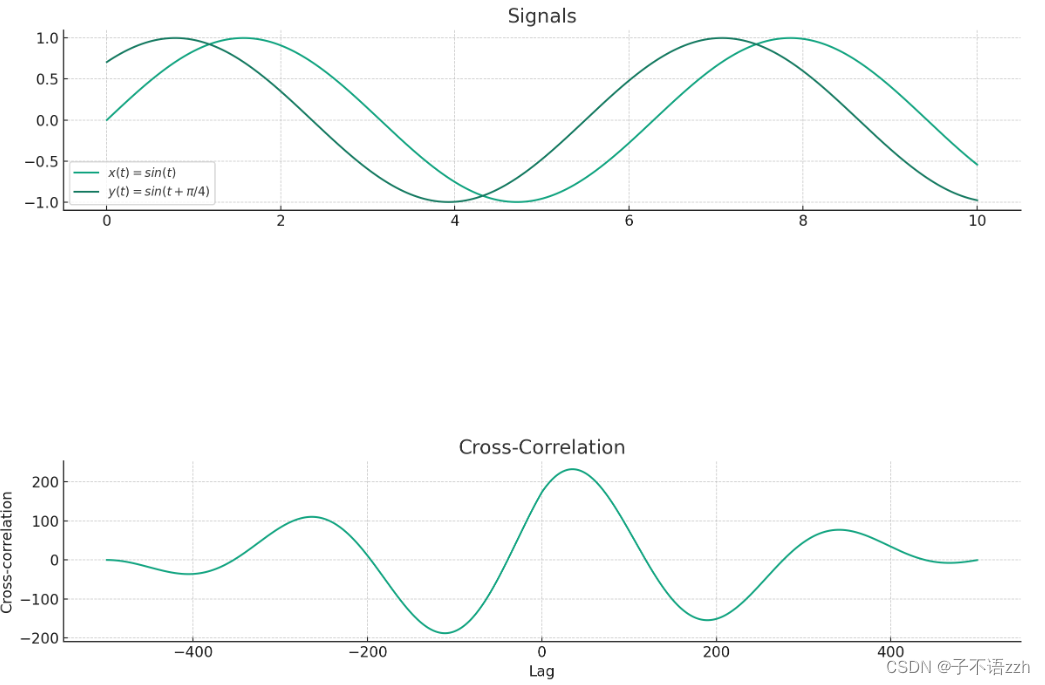
上图展示了两个信号和它们的交叉关联:
-
信号图:第一个子图显示了信号 x ( t ) = sin ( t ) x(t) = \sin(t) x(t)=sin(t) 和信号 y ( t ) = sin ( t + π 4 ) y(t) = \sin(t + \frac{\pi}{4}) y(t)=sin(t+4π)。可以看出信号 B 相对于信号 A 有一个时间的延迟。
-
交叉关联图:第三个子图显示了这两个信号之间的交叉关联。注意到,在某个特定的延迟(大约 25 25 25左右)时,交叉关联值达到峰值,这表明两个信号在该延迟时具有最大的相似性。这个延迟对应于信号 B 相对于信号 A 的实际时间延迟 π 4 \frac{\pi}{4} 4π。
通过这种方式,交叉关联帮助我们理解一个信号如何相对于另一个信号被延迟,这在信号处理、自动控制、地球物理学和其他许多领域都是非常有用的工具。
-
-
-
【2】在统计和机器学习中,“真正例”(True Positive, TP)和“假正例”(False Positive, FP)是两个常用的术语,用于评估分类模型的性能,特别是在二分类问题中。
-
真正例 (True Positive, TP):当模型预测的结果为正(如预测存在),并且实际情况也确实为正(如确实存在)时,这种情况被称为真正例。简而言之,真正例是模型正确地识别出正例的情况。
-
假正例 (False Positive, FP):当模型预测的结果为正(如预测存在),但实际情况是负(如实际不存在)时,这种情况被称为假正例。这也常被称为“误报”(false alarm),即模型错误地将某些负例识别为正例。
这两个指标通常与其他指标(如真负例、假负例)一起用于计算更复杂的性能指标,例如准确率、召回率、F1分数和ROC曲线等。这些指标帮助我们理解和评价模型在处理不同类别数据时的效能和偏差。
指标:评价标准解析
-
-
【3】Tor网络(The Onion Router)是一种为了保障用户隐私和安全而设计的匿名通信网络。在这个网络中,数据通过一系列的中继(relay)传输,每个中继只知道前一个和后一个中继的身份,而不知道其他任何信息。这种设计帮助用户隐藏了他们的身份和网络活动。
守卫中继(Guard Relay)
在Tor网络中,守卫中继是用户首次连接时接触的第一个中继。守卫中继的作用非常关键,因为它是用户入口到Tor网络的第一个节点。为了增加安全性,用户一旦选择了一个守卫中继,通常会在几个月内保持使用同一个守卫中继。这样做是为了减少被恶意守卫中继发现用户真实IP地址的风险。
守卫中继的选取基于其稳定性和带宽。Tor网络会选择那些长时间在线且有足够网络带宽的节点作为守卫中继,以保证网络连接的质量和安全。
桥(Bridge)
桥是Tor网络中的一种特殊中继,它不在公开的Tor目录中列出。桥主要用于帮助那些位于网络封锁区的用户访问Tor网络。由于桥的信息不公开,审查机构难以直接阻止所有桥的连接。
用户需要通过一些特定的途径获取桥的信息,例如通过电子邮件、网站或朋友。一旦获取了桥的信息,用户可以通过桥接入Tor网络,绕过本地的网络封锁。
区别
- 可见性:守卫中继在Tor网络的公开目录中可以找到,而桥则不会公开列出。
- 用途:守卫中继用于所有Tor用户的第一个连接点,而桥主要服务于那些无法直接访问Tor网络的用户。
- 选择机制:用户通常长时间使用同一个守卫中继以增加安全性,桥则可能经常更换以避开封锁。
图例说明
让我们设想一个简单的例子:
- 用户位于网络审查严格的国家。
- 桥允许用户绕过本地审查,进入Tor网络。
- 进入Tor网络后,数据首先经过守卫中继,然后通过几个中继节点,最后到达出口节点,从而访问互联网。
桥和中继都是第一个连接客户端的节点
守卫中继(Guard Relay)和桥接节点(Bridge Relay)都可以是Tor用户首次连接的节点,但它们的用途和情景有所不同:
-
守卫中继:这是大多数Tor用户在访问Tor网络时的第一个节点。守卫中继的目的是增加网络的稳定性和安全性。用户在一段时间内会使用同一个守卫节点,这有助于防止攻击者通过监控多个入口节点来分析流量。守卫节点是公开的,任何用户都可以从Tor的公开目录中找到并连接到这些节点。
-
桥接节点:桥节点主要服务于那些无法直接访问Tor网络的用户,比如那些生活在实行严格网络审查的国家的用户。桥不像普通的Tor节点那样在公开的目录中列出,因此,封锁者很难发现和封锁它们。用户通常需要通过一些私下的渠道获取桥的信息。
在Tor网络中,桥(Bridge Relay)和守卫中继(Guard Relay)的用途确实有所重叠,但在使用时,它们不会同时作为首个连接点。用户将会选择其中一种方式来开始他们的Tor连接,这取决于用户的网络环境和需求。
-
使用桥接节点:如果用户位于一个对Tor访问进行封锁或严重监控的国家,他们可能无法直接访问公开的守卫节点。在这种情况下,用户会首先连接到桥接节点。桥接节点在这里充当用户进入Tor网络的入口点,替代了守卫节点的功能。
-
使用守卫节点:对于大多数用户,特别是在Tor访问未受限制的国家,直接连接到守卫节点是常规的操作。在这种情况下,守卫节点作为首个节点,因为用户无需绕过任何封锁。
用户通常根据自己的具体情况选择使用桥接节点或守卫节点作为首个连接点。如果使用了桥接节点,就不需要再连接守卫节点,因为桥本身已经是一个特殊配置的守卫节点。同样,如果用户直接连接到守卫节点,那么他们就无需使用桥。这两者的选择取决于用户是否需要绕过网络封锁来访问Tor网络。
-
【4】tcpdump 是一个在 Unix 和类 Unix 操作系统上运行的网络数据包分析工具。它可以捕获网络上的数据包,并将其以人类可读的形式显示出来,或者保存到文件中供后续分析。tcpdump 是网络管理员和安全专家常用的工具之一,用于诊断网络问题、分析网络流量和检测网络攻击等。通过 tcpdump,用户可以实时查看网络上的数据包,并根据需要应用过滤器来仅捕获特定类型的数据包,以便更精确地分析网络流量。

















 545
545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









