







前言(逼逼赖赖)
哈哈哈,本来想细读yolo的代码然后弄懂结果的,但是由于我太拖拉了,这个我放弃!!!不不不,说的好听点叫做搁浅。
直接去找教程看图去
1、大佬直接开了个网页做教程⇨Ultralytics YOLO 文件
他真的,我哭死,但是水平不够看不太懂噢。所以装装样子得了。
2、讲得最清楚的还是阿里云论坛上的⇨阿里论坛
我想我会做个合格的cv圣手,结合上次云服务器上训练的结果进行分析!
这个是我这篇博文的主要参考
3、找到个解释参数很仔细的博主⇨YOLOv5训练结果分析
(超详细)YOLOv5训练出结果,如何分析结果的性能分析
—2024/5/31
更新一波识别到的标签的位置和类型。
—2024/7/9
一、混淆矩阵
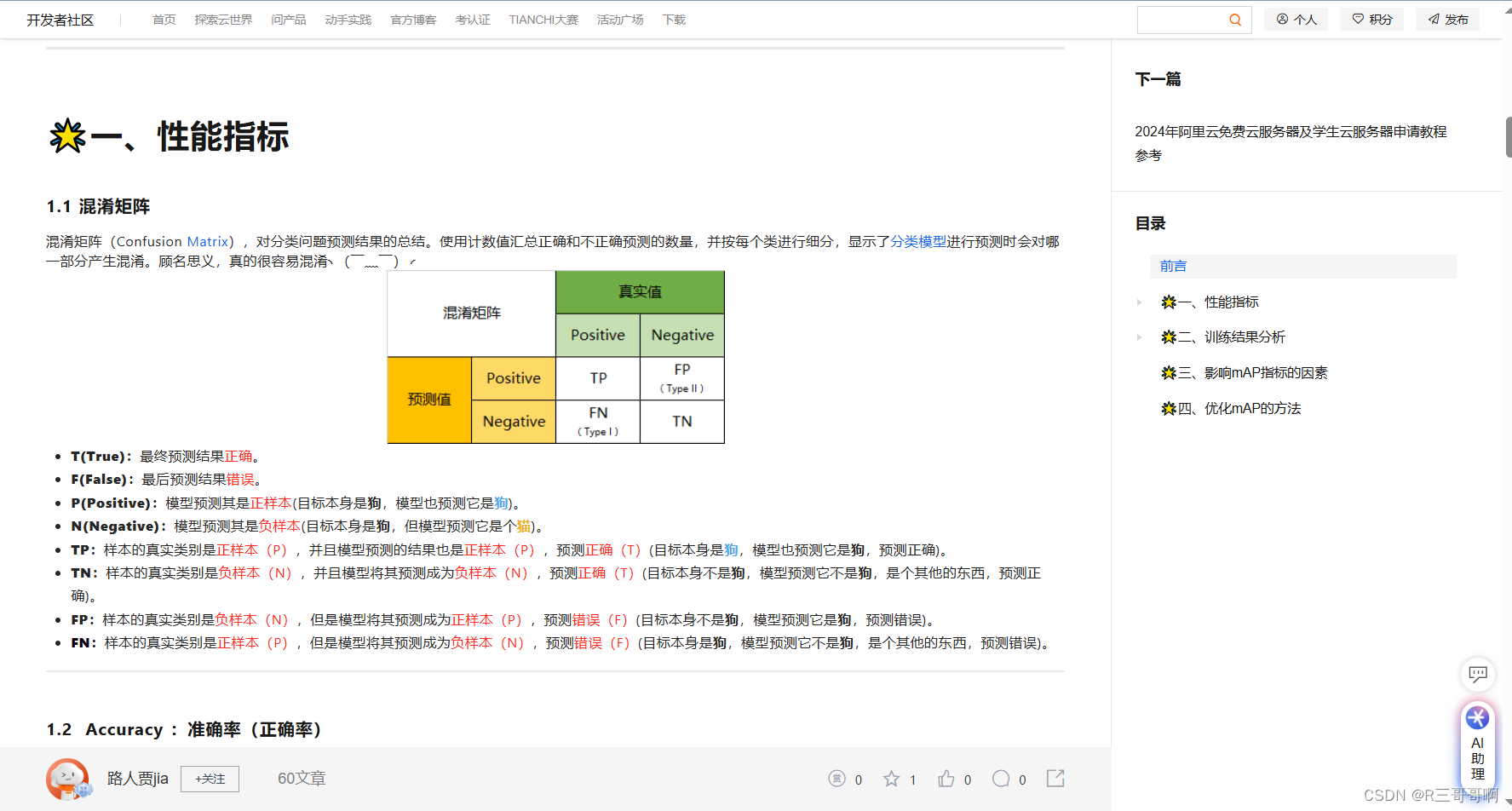
真的清楚好嘛,对应过来就是这个
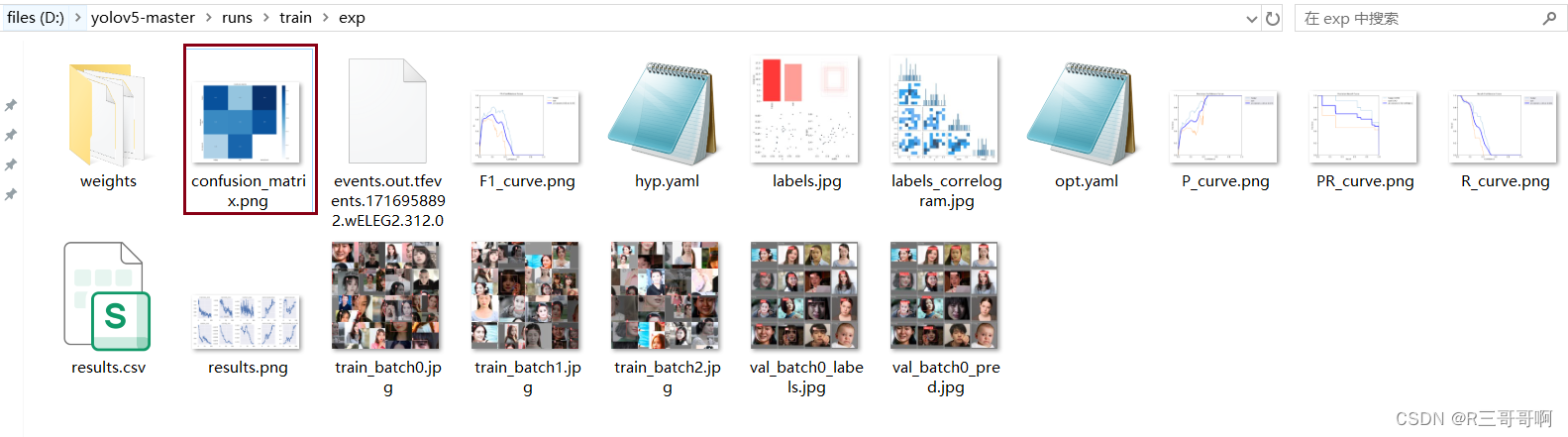
在YOLOv5的训练结果中,confusion_matrix.png文件是一个混淆矩阵的可视化图像,用于展示模型在不同类别上的分类效果。
混淆矩阵是一个n×n的矩阵,其中n为分类数目,矩阵的每一行代表一个真实类别,每一列代表一个预测类别,矩阵中的每一个元素表示真实类别为行对应的类别,而预测类别为列对应的类别的样本数。
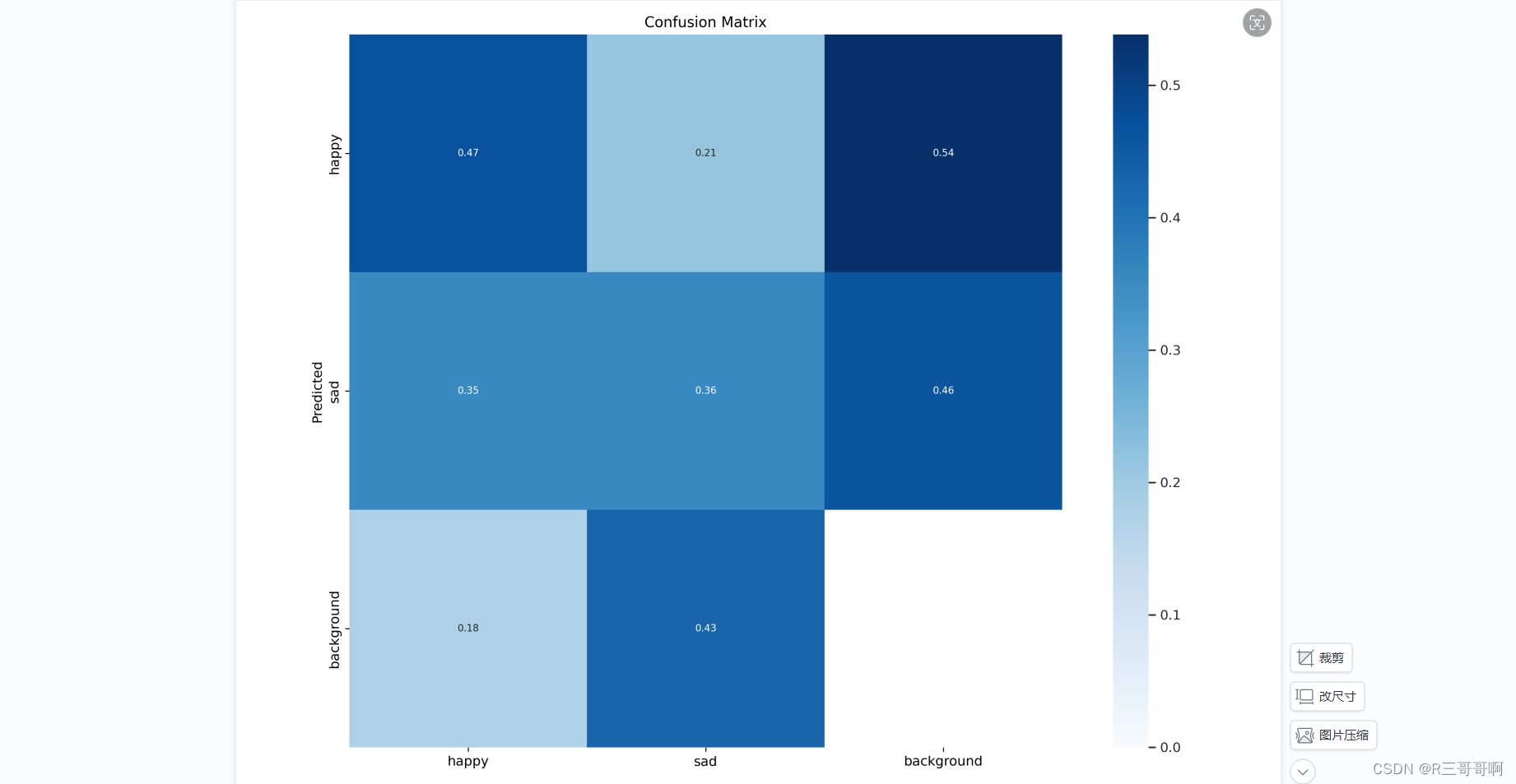
- 颜色深浅并不是衡量混淆矩阵结果好坏的标准,而是用来可视化展示各个类别之间的预测准确度的。一般来说,深色表示预测准确度高,浅色表示预测准确度低。
- 在深度学习中,当我们进行分类任务时,会将数据分为不同的类别。类别之间的预测精确度指的是模型在预测这些不同类别的数据时的准确程度。具体来说,对于每个类别,我们可以计算出模型预测为该类别的样本中确实属于该类别的比例,这就是该类别的预测精确度。
- 在目标检测任务中,通常会将图像中的物体分为不同的类别,比如人、车、动物等。而
背景(background)则是指图像中除了这些物体以外的部分,即不属于任何类别的区域。在混淆矩阵中,通常也会包括一个背景类别,用来表示模型正确地将背景区域分类为背景的情况。所以,背景类别在混淆矩阵中表示模型对图像中不包含目标的部分的分类情况。
简单来说,混淆矩阵是根据真实值和预测值划分的TP、FP、FN、TN,然后不同的颜色只是区分参数的程度,最终的结果还是取决于四个参数。
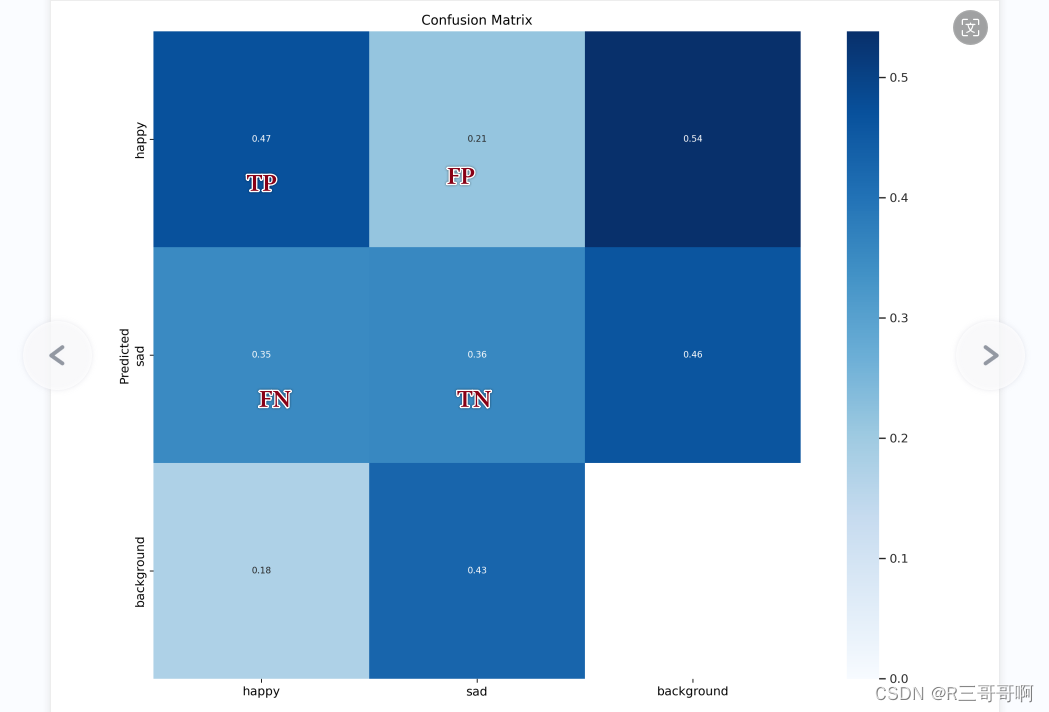
首先我承认我自己的模型训练的不好,其次我不太理解背景那一栏有什么用。
二、准确率

权重

F1曲线

(跑题)突然发现博主csdn也有号~
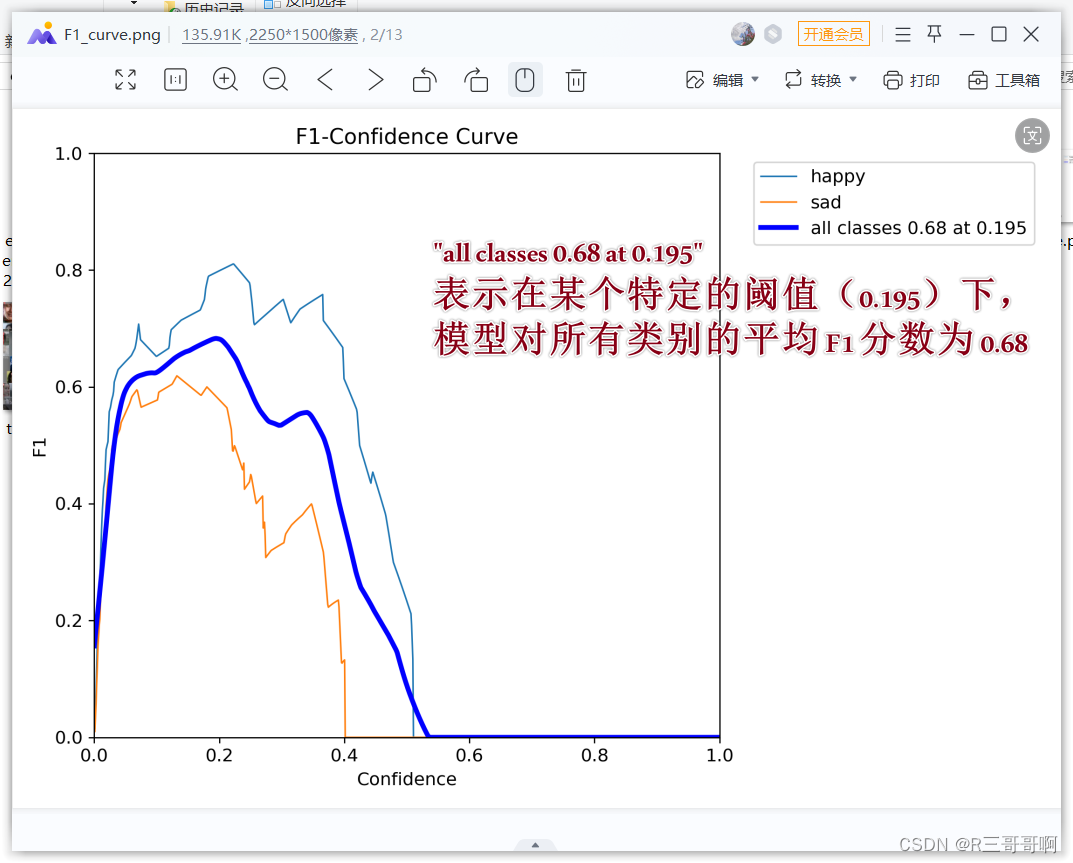 在特定阈值(0.195)下,模型对所有类别的平均 F1 分数为 0.68。这里的阈值是指在对数据进行分类时所使用的判别标准,而 F1 分数是用来评估模型在精确度和召回率之间的平衡表现的指标。所以这句话的含义是在特定条件下,模型对各个类别的分类性能都达到了相当高的水平,平均 F1 分数为 0.68。
在特定阈值(0.195)下,模型对所有类别的平均 F1 分数为 0.68。这里的阈值是指在对数据进行分类时所使用的判别标准,而 F1 分数是用来评估模型在精确度和召回率之间的平衡表现的指标。所以这句话的含义是在特定条件下,模型对各个类别的分类性能都达到了相当高的水平,平均 F1 分数为 0.68。
识别到的标签

下面的几句是我加上去的,目的是为了打印出来识别到的数据和查看它的类型。

这里补充一下,我这里是单纯运行detect.py程序的,然后这里打印了两次,是因为。
这段输出显示了YOLOv5模型在处理两张图片时的结果。每一行输出对应于模型处理的一张图片的检测结果和处理时间。
“image 1/2 D:\yolov5-master\data\images\bus.jpg: 640x480 4 persons, 1 bus, 13.0ms” 表示模型处理了名为 “bus.jpg” 的图片,该图片的尺寸是640x480像素,模型检测出了4个人和1辆公交车,处理时间为13.0毫秒。
“image 2/2 D:\yolov5-master\data\images\zidane.jpg: 384x640 2 persons, 2 ties, 15.0ms” 表示模型处理了名为 “zidane.jpg” 的图片,该图片的尺寸是384x640像素,模型检测出了2个人和2条领带,处理时间为15.0毫秒。
模型处理两张图片分别显示为 “1/2” 和 “2/2”,这个数字表示这是处理的第几张图片以及总共有多少张图片需要处理。因此,这里的 “image 2/2” 意味着这是模型处理的第二张图片,并且总共有两张图片需要处理。
总结来说,每一行 “image x/x” 的输出对应于模型处理的一张图片的检测结果和处理时间,而不是说某张图片被处理了两次。
【失败的思路】这个label会带着置信度,我之前尝试重写label的方法去剔除,但是失败了。于是我想换个思路,采用切片的方法打印出来。
我们不知道label的名称都是啥,切片怎么切嘛。失败,下一个

摔跤就学会走了。。。
我知道为什么我之前重写label会失败了,咱不是想要不对hide_labels和hide_conf的结果判断直接出name的数值判断吗,于是就是直接name[]了。这哪里对啊,一堆名字就是一堆变量,那需要names,加S啊,死多少次了都,不撞南墙不回头服了我了。
修改完就成功了~
撒花撒花~~~~~~
super_label = names[c]
print("super_label的数值是:",super_label)

总结
这篇文章依旧没有总结















 24万+
24万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









