







Spring Cloud 综述
1 Spring Cloud 是什么
百度百科: Spring Cloud是一系列框架的有序集合。它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用 Spring Boot的开发风格做到一键启动和部署。Spring Cloud并没有重复制造轮子,它只是将目前各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过Spring Boot风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。
官方介绍:
2 Spring Cloud 解决什么问题
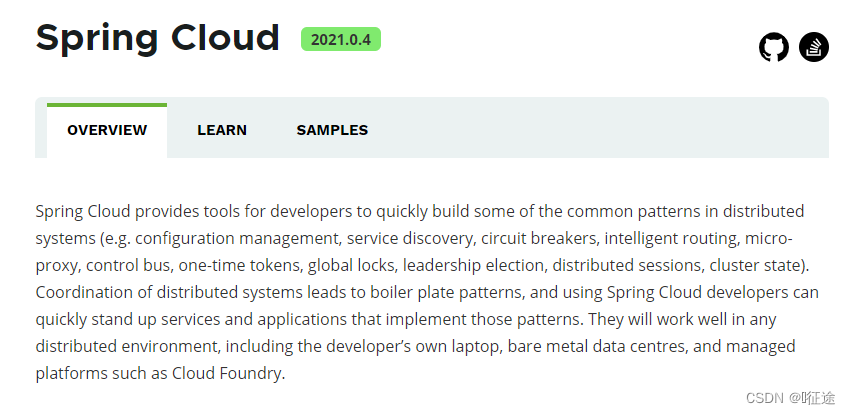
Spring Cloud 规范及实现意图要解决的问题其实就是微服务架构实施过程中存在的一些问题,比如微服务架构中的服务注册发现问题、网络问题(比如熔断场景)、统一认证安全授权问题、负载均衡问题、链路追踪等问题。
- Distributed/versioned configuration (分布式/版本化配置)
- Service registration and discovery (服务注册和发现)
- Routing (智能路由)
- Service-to-service calls (服务调用)
- Load balancing (负载均衡)
- Circuit Breakers (熔断器)
- Global locks (全局锁)
- Leadership election and cluster state ( 选举与集群状态管理)
- Distributed messaging (分布式消息传递平台)
3 Spring Cloud 架构
如前所述,Spring Cloud是一个微服务相关规范,这个规范意图为搭建微服务架构提供一站式服务,采用组件(框架)化机制定义一系列组件,各类组件针对性的处理微服务中的特定问题,这些组件共同来构成Spring Cloud微服务技术栈
3.1 Spring Cloud 核心组件
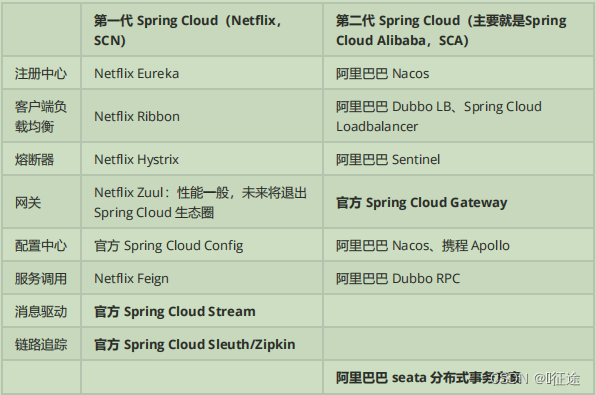
Spring Cloud 生态圈中的组件,按照发展可以分为第一代 Spring Cloud组件和第二代 SpringCloud组件。
3.2 Spring Cloud 体系结构(组件协同工作机制)

Spring Cloud中的各组件协同工作,才能够支持一个完整的微服务架构。
- 注册中心负责服务的注册与发现,很好将各服务连接起来
- API网关负责转发所有外来的请求
- 断路器负责监控服务之间的调用情况,连续多次失败进行熔断保护
- 配置中心提供了统一的配置信息管理服务,可以实时的通知各个服务获取最新的配置信息
3.3 Spring Cloud 与 Dubbo 对比
Dubbo是阿里巴巴公司开源的一个高性能优秀的服务框架,基于RPC调用,对于目前使用率较高的Spring Cloud Netflix来说,它是基于HTTP的,所以效率上没有Dubbo高,问题在于Dubbo体系的组件不全,不能够提供一站式解决方案,比如服务注册与发现需要借助于Zookeeper等实现,而SpringCloud Netflix则是真正的提供了一站式服务化解决方案,且有Spring大家族背景。
前些年,Dubbo使用率高于SpringCloud,但目前Spring Cloud在服务化/微服务解决方案中已经有了非常好的发展趋势。
3.4 Spring Cloud 与 Spring Boot 的关系
Spring Cloud 只是利用了Spring Boot 的特点,让我们能够快速的实现微服务组件开发,否则不使用Spring Boot的话,我们在使用Spring Cloud时,每一个组件的相关Jar包都需要我们自己导入配置以及需要开发人员考虑兼容性等各种情况。所以Spring Boot是我们快速把Spring Cloud微服务技术应用起来的一种方式。
第一代 Spring Cloud 核心组件
1 Eureka服务注册中心
常用的服务注册中心:Eureka、Nacos、Zookeeper、Consul
1.1 关于服务注册中心
注意:服务注册中心本质上是为了解耦服务提供者和服务消费者。
服务消费者 → 服务提供者
服务消费者 → 服务注册中心 → 服务提供者
对于任何一个微服务,原则上都应存在或者支持多个提供者(比如商品微服务部署多个实例),这是由微服务的分布式属性决定的。
更进一步,为了支持弹性扩、缩容特性,一个微服务的提供者的数量和分布往往是动态变化的,也是无法预先确定的。因此,原本在单体应用阶段常用的静态LB机制就不再适用了,需要引入额外的组件来管理微服务提供者的注册与发现,而这个组件就是服务注册中心。
1.1.1 注册中心实现原理
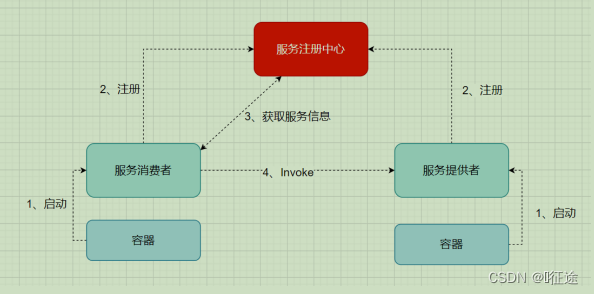
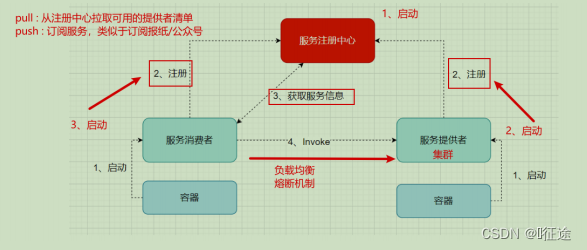
分布式微服务架构中,服务注册中心用于存储服务提供者地址信息、服务发布相关的属性信息,消费者通过主动查询和被动通知的方式获取服务提供者的地址信息,而不再需要通过硬编码方式得到提供者的地址信息。消费者只需要知道当前系统发布了那些服务,而不需要知道服务具体存在于什么位置,这就是透明化路由。
-
服务提供者启动
-
服务提供者将相关服务信息主动注册到注册中心
-
服务消费者获取服务注册信息:
- pull模式:服务消费者可以主动拉取可用的服务提供者清单
- push模式:服务消费者订阅服务(当服务提供者有变化时,注册中心也会主动推送更新后的服务清单给消费者
-
服务消费者直接调用服务提供者
另外,注册中心也需要完成服务提供者的健康监控,当发现服务提供者失效时需要及时剔除;
1.2 服务注册中心组件 Eureka
服务注册中心的一般原理、对比了主流的服务注册中心方案,目光聚焦Eureka。
-
Eureka 基础架构
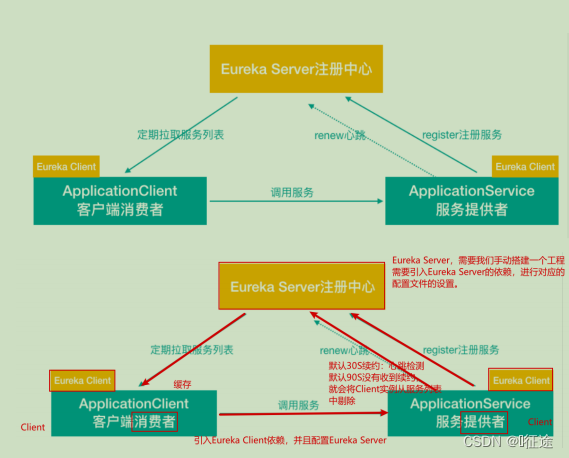
-
Eureka 交互流程及原理
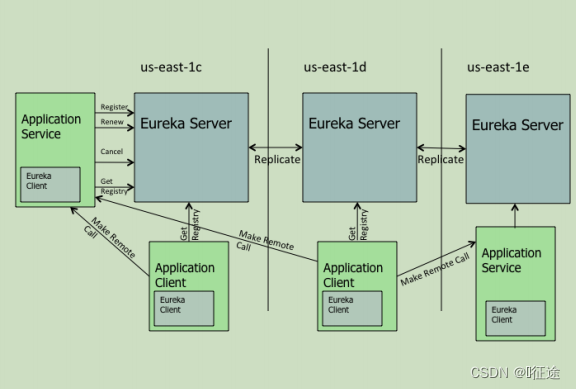
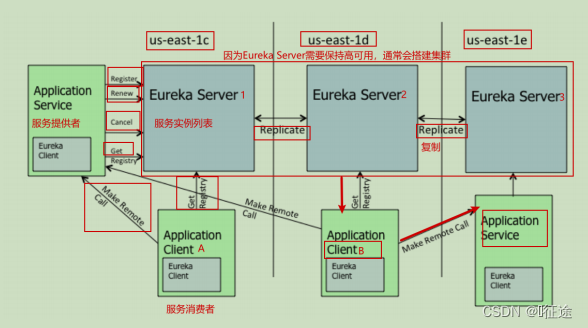
Eureka 包含两个组件:Eureka Server 和 Eureka Client,Eureka Client是一个Java客户端,用于简化与Eureka Server的交互;Eureka Server提供服务发现的能力,各个微服务启动时,会通过EurekaClient向Eureka Server 进行注册自己的信息(例如网络信息),Eureka Server会存储该服务的信息; -
图中us-east-1c、us-east-1d,us-east-1e代表不同的区也就是不同的机房
-
图中每一个Eureka Server都是一个集群
-
图中Application Service作为服务提供者向Eureka Server中注册服务,Eureka Server接受到注册事件会在集群和分区中进行数据同步,Application Client作为消费端(服务消费者)可以从EurekaServer中获取到服务注册信息,进行服务调用
-
微服务启动后,会周期性地向Eureka Server发送心跳(默认周期为30秒,默认Eureka Server90S会将还没有续约的给剔除)以续约自己的信息
-
Eureka Server在一定时间内没有接收到某个微服务节点的心跳,Eureka Server将会注销该微服务节点(默认90秒)
-
每个Eureka Server同时也是Eureka Client,多个Eureka Server之间通过复制的方式完成服务注册列表的同步
-
Eureka Client会缓存Eureka Server中的信息。即使所有的Eureka Server节点都宕掉,服务消费者依然可以使用缓存中的信息找到服务提供者
Eureka通过心跳检测、健康检查和客户端缓存等机制,提高系统的灵活性、可伸缩性和高可用性。
2 Ribbon负载均衡
2.1 关于服务注册中心
负载均衡一般分为服务器端负载均衡和客户端负载均衡
所谓服务器端负载均衡,比如Nginx、F5这些,请求到达服务器之后由这些负载均衡器根据一定的算法将请求路由到目标服务器处理。
所谓客户端负载均衡,比如我们要说的Ribbon,服务消费者客户端会有一个服务器地址列表,调用方在请求前通过一定的负载均衡算法选择一个服务器进行访问,负载均衡算法的执行是在请求客户端进行。
Ribbon是Netflix发布的负载均衡器。Eureka一般配合Ribbon进行使用,Ribbon利用从Eureka中读取到服务信息,在调用服务提供者提供的服务时,会根据一定的算法进行负载。
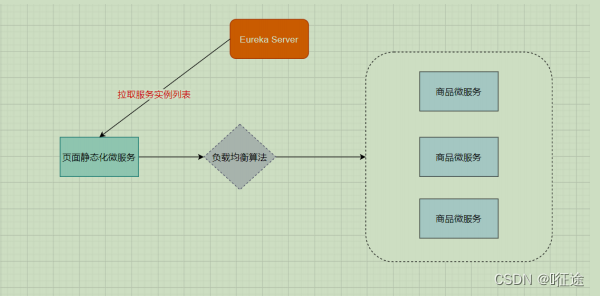
2.3 Ribbon负载均衡策略
Ribbon内置了多种负载均衡策略,内部负责复杂均衡的顶级接口为 com.netflix.loadbalancer.IRule ,接口简介:
package com.netflix.loadbalancer;
/**
* Interface that defines a "Rule" for a LoadBalancer. A Rule can be thought of
* as a Strategy for loadbalacing. Well known loadbalancing strategies include
* Round Robin, Response Time based etc.
*
* @author stonse
* *
*/
public interface IRule{
/*
* choose one alive server from lb.allServers or
* lb.upServers according to key
*
* @return choosen Server object. NULL is returned if none
* server is available
*/
public Server choose(Object key);
public void setLoadBalancer(ILoadBalancer lb);
public ILoadBalancer getLoadBalancer();
}
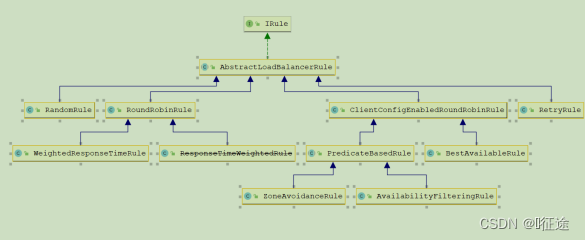
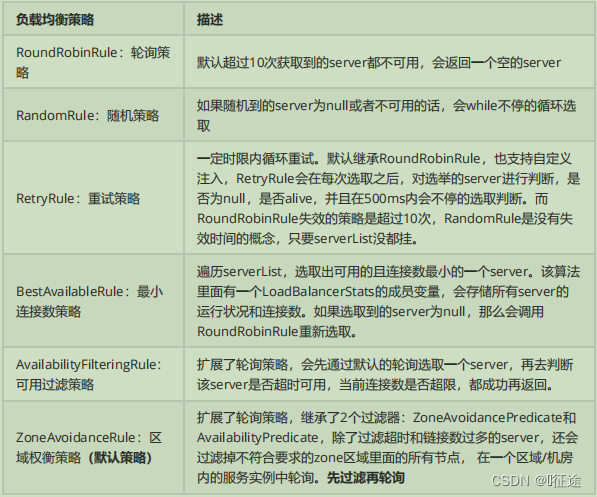
3 Hystrix熔断器
属于一种容错机制
3.1 微服务中的雪崩效应
当山坡积雪内部的内聚力抗拒不了它所受到的重力拉引时,便向下滑动,引起大量雪体崩塌,人们把这种自然现象称作雪崩。
微服务中,一个请求可能需要多个微服务接口才能实现,会形成复杂的调用链路。
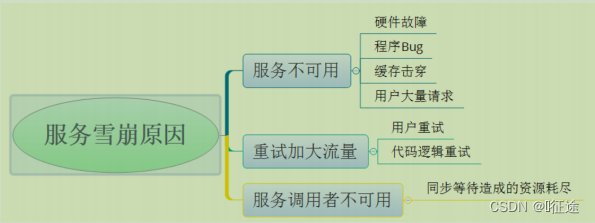
服务雪崩效应: 是一种因“服务提供者的不可用”(原因)导致“服务调用者不可用”(结果),并将不可用逐渐放大的现象。
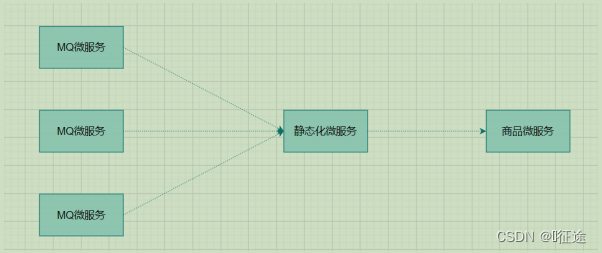
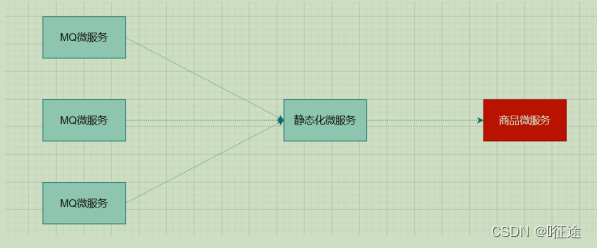
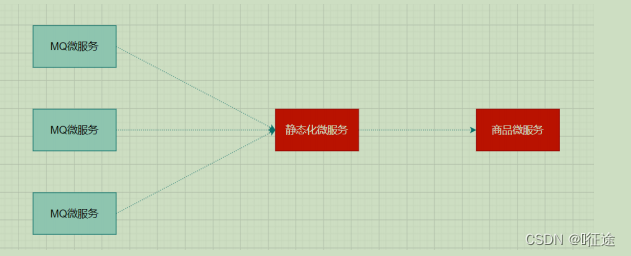
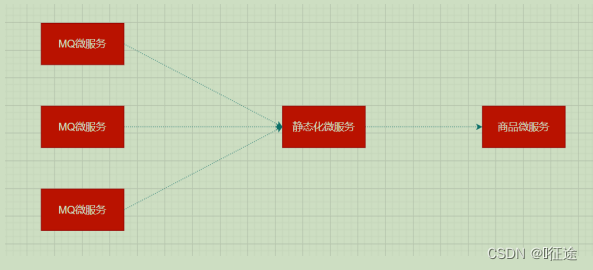
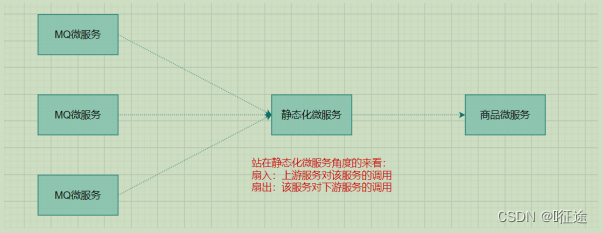
扇入: 代表着该微服务被调用的次数,扇入大,说明该模块复用性好
扇出: 该微服务调用其他微服务的个数,扇出大,说明业务逻辑复杂
扇入大是一个好事,扇出大不一定是好事
在微服务架构中,一个应用可能会有多个微服务组成,微服务之间的数据交互通过远程过程调用完成。这就带来一个问题,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其它的微服务,这就是所谓的“扇出”。如果扇出的链路上某个微服务的调用响应时间过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,所谓的“雪崩效应”。
如图中所示,最下游商品微服务响应时间过长,大量请求阻塞,大量线程不会释放,会导致服务器资源耗尽,最终导致上游服务甚至整个系统瘫痪。
形成原因:
服务雪崩的过程可以分为三个阶段:
- 服务提供者不可用
- 重试加大请求流量
- 服务调用者不可用
服务雪崩的每个阶段都可能由不同的原因造成:
3.2 雪崩效应解决方案
从可用性可靠性着想,为防止系统的整体缓慢甚至崩溃,采用的技术手段;
下面,我们介绍三种技术手段应对微服务中的雪崩效应,这三种手段都是从系统可用性、可靠性角度出发,尽量防止系统整体缓慢甚至瘫痪。
服务熔断
熔断机制是应对雪崩效应的一种微服务链路保护机制。我们在各种场景下都会接触到熔断这两个字。高压电路中,如果某个地方的电压过高,熔断器就会熔断,对电路进行保护。股票交易中,如果股票指数过高,也会采用熔断机制,暂停股票的交易。同样,在微服务架构中,熔断机制也是起着类似的作用。当扇出链路的某个微服务不可用或者响应时间太长时,熔断该节点微服务的调用,进行服务的降级,快速返回错误的响应信息。当检测到该节点微服务调用响应正常后,恢复调用链路。
注意:
- 服务熔断重点在“断”,切断对下游服务的调用
- 服务熔断和服务降级往往是一起使用的,Hystrix就是这样
服务降级
通俗讲就是整体资源不够用了,先将一些不关紧的服务停掉(调用我的时候,给你返回一个预留的值,也叫做兜底数据),待渡过难关高峰过去,再把那些服务打开。
服务降级一般是从整体考虑,就是当某个服务熔断之后,服务器将不再被调用,此刻客户端可以自己准备一个本地的fallback回调,返回一个缺省值,这样做,虽然服务水平下降,但好歹可用,比直接挂掉要强。
服务限流:
服务降级是当服务出问题或者影响到核心流程的性能时,暂时将服务屏蔽掉,待高峰或者问题解决后再打开;但是有些场景并不能用服务降级来解决,比如秒杀业务这样的核心功能,这个时候可以结合服务限流来限制这些场景的并发/请求量限流措施也很多,比如
- 限制总并发数(比如数据库连接池、线程池)
- 限制瞬时并发数(如nginx限制瞬时并发连接数)
- 限制时间窗口内的平均速率(如Guava的RateLimiter、nginx的limit_req模块,限制每秒的平均速率)
- 限制远程接口调用速率、限制MQ的消费速率等
3.3 Hystrix简介

[来自官网] Hystrix(豪猪),宣言“defend your application”是由Netflix开源的一个延迟和容错库,用于隔离访问远程系统、服务或者第三方库,防止级联失败,从而提升系统的可用性与容错性。Hystrix主 要通过以下几点实现延迟和容错。
- 包裹请求:使用HystrixCommand包裹对依赖的调用逻辑。 页面静态化微服务方法
(@HystrixCommand 添加Hystrix控制) - 跳闸机制:当某服务的错误率超过一定的阈值时,Hystrix可以跳闸,停止请求该服务一段时间。
- 资源隔离:Hystrix为每个依赖都维护了一个小型的线程池(舱壁模式)。如果该线程池已满, 发往该依赖的请求就被立即拒绝,而不是排队等待,从而加速失败判定。
- 监控:Hystrix可以近乎实时地监控运行指标和配置的变化,例如成功、失败、超时、以及被拒绝的请求等。
- 回退机制:当请求失败、超时、被拒绝,或当断路器打开时,执行回退逻辑。回退逻辑由开发人员自行提供,例如返回一个缺省值。
- 自我修复:断路器打开一段时间后,会自动进入“半开”状态(探测服务是否可用,如还是不可用,再次退回打开状态)。
3.4 Hystrix舱壁模式
即:线程池隔离策略
如果不进行任何设置,所有熔断方法使用一个Hystrix线程池(10个线程),那么这样的话会导致问题,这个问题并不是扇出链路微服务不可用导致的,而是我们的线程机制导致的,如果方法A的请求把10个线程都用了,方法2请求处理的时候压根都没法去访问B,因为没有线程可用,并不是B服务不可用。
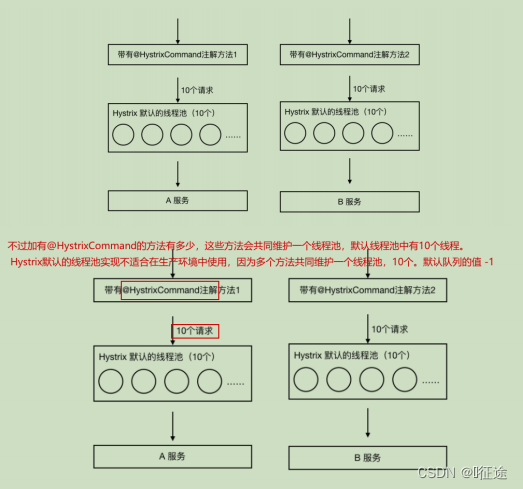
为了避免问题服务请求过多导致正常服务无法访问,Hystrix 不是采用增加线程数,而是单独的为每一个控制方法创建一个线程池的方式,这种模式叫做“舱壁模式",也是线程隔离的手段。















 170
170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









