







当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法
今日收获:
- 学会了用ASCII作为哈希函数,即
ord(char); - 学会了按位与计算
&; - 学会了用数组原来也可以做哈希表;
- 学会用
divmod(n, 10)函数;
哈希表理论基础
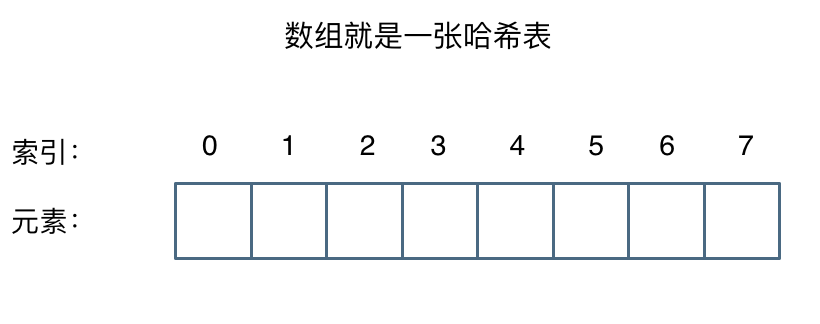
哈希表是根据关键码的值而直接进行访问的数据结构。
哈希表中关键码就是数组的索引下标,然后通过下标直接访问数组中的元素,如下图所示:
一般哈希表都是用来快速判断一个元素是否出现集合里
哈希函数
哈希函数,把学生的姓名直接映射为哈希表上的索引,然后就可以通过查询索引下标快速知道这位同学是否在这所学校里了。
哈希函数如下图所示,通过hashCode把名字转化为数值,一般hashcode是通过特定编码方式,可以将其他数据格式转化为不同的数值,这样就把学生名字映射为哈希表上的索引数字了。

如果hashCode得到的数值大于 哈希表的大小了,也就是大于tableSize了,怎么办呢?
此时为了保证映射出来的索引数值都落在哈希表上,会再次对数值做一个取模的操作,这样我们就保证了学生姓名一定可以映射到哈希表上了。
此时问题又来了,哈希表我们刚刚说过,就是一个数组。
如果学生的数量大于哈希表的大小怎么办,此时就算哈希函数计算的再均匀,也避免不了会有几位学生的名字同时映射到哈希表 同一个索引下标的位置。
哈希碰撞
如图所示,小李和小王都映射到了索引下标 1 的位置,这一现象叫做哈希碰撞。

一般哈希碰撞有两种解决方法, 拉链法和线性探测法。
拉链法
刚刚小李和小王在索引1的位置发生了冲突,发生冲突的元素都被存储在链表中。 这样我们就可以通过索引找到小李和小王了。

线性探测法
使用线性探测法,一定要保证tableSize大于dataSize。 我们需要依靠哈希表中的空位来解决碰撞问题。
例如冲突的位置,放了小李,那么就向下找一个空位放置小王的信息。所以要求tableSize一定要大于dataSize ,要不然哈希表上就没有空置的位置来存放 冲突的数据了。如图所示:

常见的三种哈希结构
当我们想使用哈希法来解决问题的时候,我们一般会选择如下三种数据结构。
- 数组
- set(集合)
- map(映射)
总结
总结一下,当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法。
但是哈希法也是牺牲了空间换取了时间,因为我们要使用额外的数组,set或者是map来存放数据,才能实现快速的查找。
如果在做面试题目的时候遇到需要判断一个元素是否出现过的场景也应该第一时间想到哈希法!
242.有效的字母异位词
视频讲解:《代码随想录》算法视频公开课 (opens new window):学透哈希表,数组使用有技巧!Leetcode:242.有效的字母异位词
状态:用哈希字典直接AC了,抵消时要删掉元素
题目如下——
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
示例 1: 输入: s = “anagram”, t = “nagaram” 输出: true
示例 2: 输入: s = “rat”, t = “car” 输出: false
说明: 你可以假设字符串只包含小写字母。
【思路】
数组其实就是一个简单哈希表,而且这道题目中字符串只有小写字符,那么就可以定义一个数组,来记录字符串s里字符出现的次数。
需要定义一个多大的数组呢,定一个数组叫做record,大小为26 就可以了,初始化为0,因为字符a到字符z的ASCII也是26个连续的数值。
需要把字符映射到数组也就是哈希表的索引下标上,因为字符a到字符z的ASCII是26个连续的数值,所以字符a映射为下标0,相应的字符z映射为下标25。
再遍历 字符串s的时候,只需要将 s[i] - ‘a’ 所在的元素做+1 操作即可,并不需要记住字符a的ASCII,只要求出一个相对数值就可以了。 这样就将字符串s中字符出现的次数,统计出来了。
那看一下如何检查字符串t中是否出现了这些字符,同样在遍历字符串t的时候,对t中出现的字符映射哈希表索引上的数值再做-1的操作。
最后检查一下,record数组如果有的元素不为零0,说明字符串s和t一定是谁多了字符或者谁少了字符,return false。
【代码实现】
(哈希数组)用ord获取字符的ASCII码-》天然的哈希函数
class Solution:
def isAnagram(self, s: str, t: str) -> bool:
record = [0] * 26
for i in s:
#并不需要记住字符a的ASCII,只要求出一个相对数值就可以了
record[ord(i) - ord("a")] += 1
for i in t:
record[ord(i) - ord("a")] -= 1
for i in range(26):
if record[i] != 0:
#record数组如果有的元素不为零0,说明字符串s和t 一定是谁多了字符或者谁少了字符。
return False
return True
(哈希字典)为零时删除
class Solution:
def isAnagram(self, s: str, t: str) -> bool:
hashmap = {}
for i in s:
hashmap[i] = hashmap.get(i, 0) + 1
for i in t:
if i in hashmap:
hashmap[i] -= 1
if hashmap[i] < 0:
return False
if hashmap[i] == 0:
del hashmap[i]
else:
return False
return True if len(hashmap) == 0 else False
class Solution:
def isAnagram(self, s: str, t: str) -> bool:
if len(s) != len(t):
return False
hashmap = {}
for c in s:
if c in hashmap:
hashmap[c] += 1
else:
hashmap[c] = 1
for c in t:
if c in hashmap and hashmap[c] > 0:
hashmap[c] -= 1
else:
return False
for count in hashmap.values():
if count != 0:
return False
return True
(Counter)没有用哈希,直接调用Counter
class Solution(object):
def isAnagram(self, s: str, t: str) -> bool:
from collections import Counter
a_count = Counter(s)
b_count = Counter(t)
return a_count == b_count
【相关题目】
349. 两个数组的交集
视频讲解:《代码随想录》算法视频公开课 (opens new window):学透哈希表,数组使用有技巧!Leetcode:242.有效的字母异位词 (opens new window)
题目如下——
题意:给定两个数组,编写一个函数来计算它们的交集。
说明: 输出结果中的每个元素一定是唯一的。 我们可以不考虑输出结果的顺序。

【思路】
注意题目特意说明:输出结果中的每个元素一定是唯一的,也就是说输出的结果的去重的, 同时可以不考虑输出结果的顺序.
但是要注意,使用数组来做哈希的题目,是因为题目都限制了数值的大小。
而这道题目没有限制数值的大小,就无法使用数组来做哈希表了。
而且如果哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费。->因为数组需要进行初始化。
为什么有时候不直接set()而是用数组?
因为直接使用set 不仅占用空间比数组大,而且速度要比数组慢,set把数值映射到key上都要做hash计算的。
【代码实现】
(字典+集合)先用字典存第一个数组,再用集合存第二个数组,相同的就删掉
class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
# 使用哈希表存储一个数组中的所有元素
table = {}
for num in nums1:
table[num] = table.get(num, 0) + 1
# 使用集合存储结果
res = set()
for num in nums2:
if num in table:
res.add(num)
del table[num]
return list(res)
(数组)直接遍历
class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
count1 = [0] * 1001
count2 = [0] * 1001
result = []
for i in range(len(nums1)):
count1[nums1[i]] += 1
for j in range(len(nums2)):
count2[nums2[j]] += 1
for k in range(1001):
if count1[k] * count2[k] > 0: # 相当于一种按位与运算
result.append(k)
return result
(集合)两个集合:按位与计算&
class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
return list(set(nums1) & set(nums2))
class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
hashmap1 = set(nums1)
hashmap2 = set(nums2)
res = []
for i in hashmap1:
if i in hashmap2:
res.append(i)
return res
202. 快乐数
题目如下——
编写一个算法来判断一个数 n 是不是快乐数。
「快乐数」定义为:对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和,然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。如果 可以变为 1,那么这个数就是快乐数。
如果 n 是快乐数就返回 True ;不是,则返回 False 。
示例:
输入:19
输出:true
解释:
1^2 + 9^2 = 82
8^2 + 2^2 = 68
6^2 + 8^2 = 100
1^2 + 0^2 + 0^2 = 1
【思路】
思路一:哈希判断是否循环出现
!这不是一道数学问题!
题目中说了会 无限循环,那么也就是说求和的过程中,sum会重复出现,这对解题很重要!
当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法了。
所以这道题目使用哈希法,来判断这个sum是否重复出现,如果重复了就是return false, 否则一直找到sum为1为止。
判断sum是否重复出现就可以使用集合。
还有一个难点就是求和的过程,如果对取数值各个位上的单数操作不熟悉的话,做这道题也会比较艰难。
思路二:快慢指针法(见代码实现)
Floyd的龟兔赛跑算法。这个算法通常用于检测循环,而快乐数的问题本质上也是一个循环检测问题:一个数不断替换为其每个位置上的数字的平方和,最终要么进入1的循环(即成为快乐数),要么进入其他数字的循环。
【代码实现】
(哈希集合法)先定义一个get_sum函数,用到divmod函数
class Solution:
def isHappy(self, n: int) -> bool:
record = set()
while True:
n = self.get_sum(n)
if n == 1:
return True
# 如果中间结果重复出现,说明陷入死循环了,该数不是快乐数
if n in record:
return False
else:
record.add(n)
def get_sum(self,n: int) -> int:
new_num = 0
while n:
n, r = divmod(n, 10)
new_num += r ** 2
return new_num
(哈希集合法)用到str()和int()的到总和
class Solution:
def isHappy(self, n: int) -> bool:
record = set()
while n not in record:
record.add(n)
new_num = 0 # 每次都要重制一遍
n_str = str(n)
for i in n_str:
new_num += int(i) ** 2 # 计算总和
if new_num == 1:
return True
else:
n = new_num
return False
(数组)和上一个基本相同
class Solution:
def isHappy(self, n: int) -> bool:
record = []
while n not in record:
record.append(n)
new_num = 0
n_str = str(n)
for i in n_str:
new_num += int(i) ** 2
if new_num == 1:
return True
else: n = new_num
return False
(快慢指针)Floyd的龟兔赛跑算法
这个算法通常用于检测循环,而快乐数的问题本质上也是一个循环检测问题:一个数不断替换为其每个位置上的数字的平方和,最终要么进入1的循环(即成为快乐数),要么进入其他数字的循环。
class Solution:
def isHappy(self, n: int) -> bool:
def get_next(num):
total_sum = 0
while num > 0:
digit = num % 10 # 个位
total_sum += digit ** 2
num //= 10 # num除以10
return total_sum
slow = n
fast = get_next(n)
while slow != fast:
if fast == 1:
return True
slow = get_next(slow)
fast = get_next(get_next(fast))
return slow == 1
1. 两数之和
视频讲解:《代码随想录》算法视频公开课 (opens new window):梦开始的地方,Leetcode:1.两数之和
题目如下:
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
【思路】
首先再强调一下 什么时候使用哈希法,当我们需要查询一个元素是否出现过,或者一个元素是否在集合里的时候,就要第一时间想到哈希法。
本题呢,我就需要一个集合来存放我们遍历过的元素,然后在遍历数组的时候去询问这个集合,某元素是否遍历过,也就是 是否出现在这个集合。
那么我们就应该想到使用哈希法了。
因为本题,我们不仅要知道元素有没有遍历过,还要知道这个元素对应的下标,需要使用 key value结构来存放,key来存元素,value来存下标,那么使用map正合适。
再来看一下使用数组和set来做哈希法的局限。
- 数组的大小是受限制的,而且如果元素很少,而哈希值太大会造成内存空间的浪费。
- set是一个集合,里面放的元素只能是一个key,而两数之和这道题目,不仅要判断y是否存在而且还要记录y的下标位置,因为要返回x 和 y的下标。所以set 也不能用。
接下来需要明确两点:
- map用来做什么
- map中key和value分别表示什么
map目的用来存放我们访问过的元素,因为遍历数组的时候,需要记录我们之前遍历过哪些元素和对应的下标,这样才能找到与当前元素相匹配的(也就是相加等于target)
接下来是map中key和value分别表示什么。
这道题 我们需要 给出一个元素,判断这个元素是否出现过,如果出现过,返回这个元素的下标。
那么判断元素是否出现,这个元素就要作为key,所以数组中的元素作为key,有key对应的就是value,value用来存下标。
所以 map中的存储结构为 {key:数据元素,value:数组元素对应的下标}。
在遍历数组的时候,只需要向map去查询是否有和目前遍历元素匹配的数值,如果有,就找到的匹配对,如果没有,就把目前遍历的元素放进map中,因为map存放的就是我们访问过的元素。
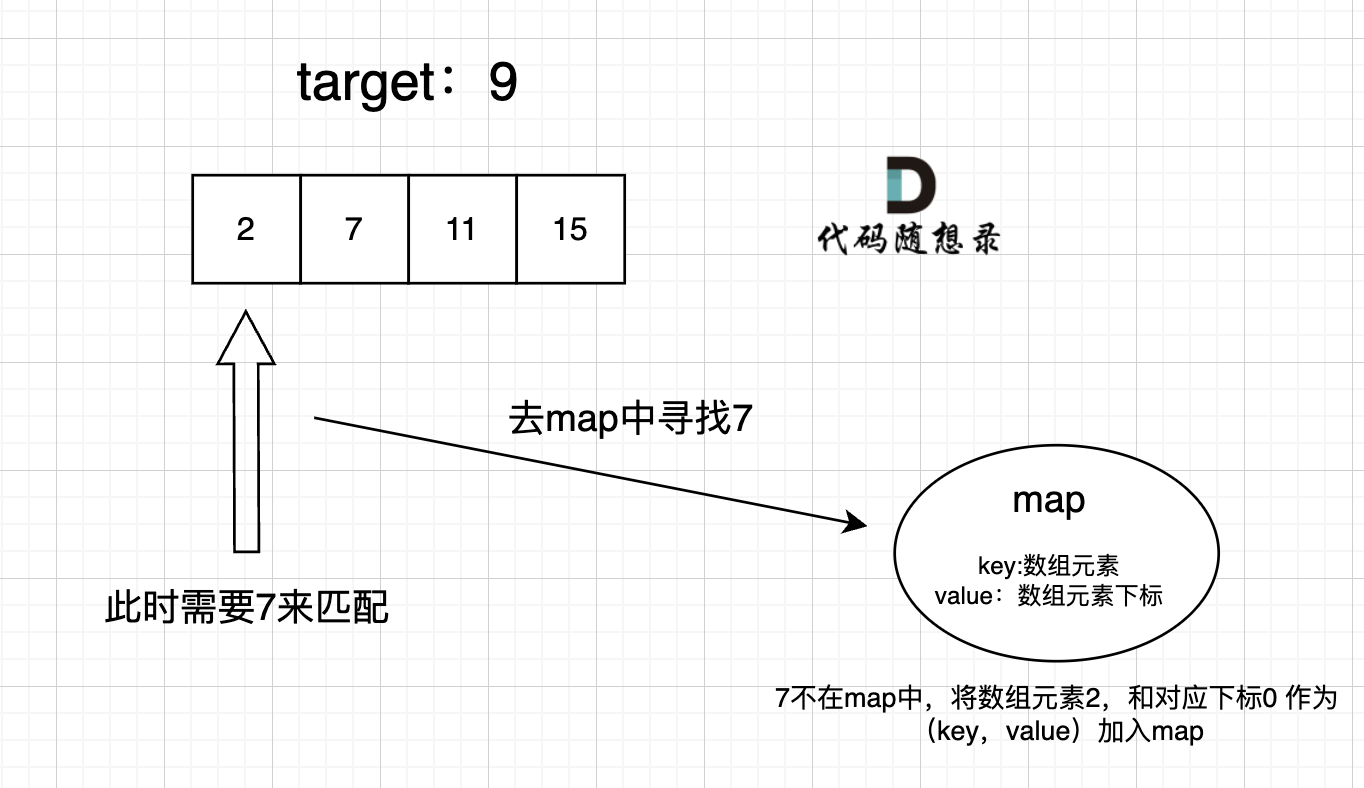
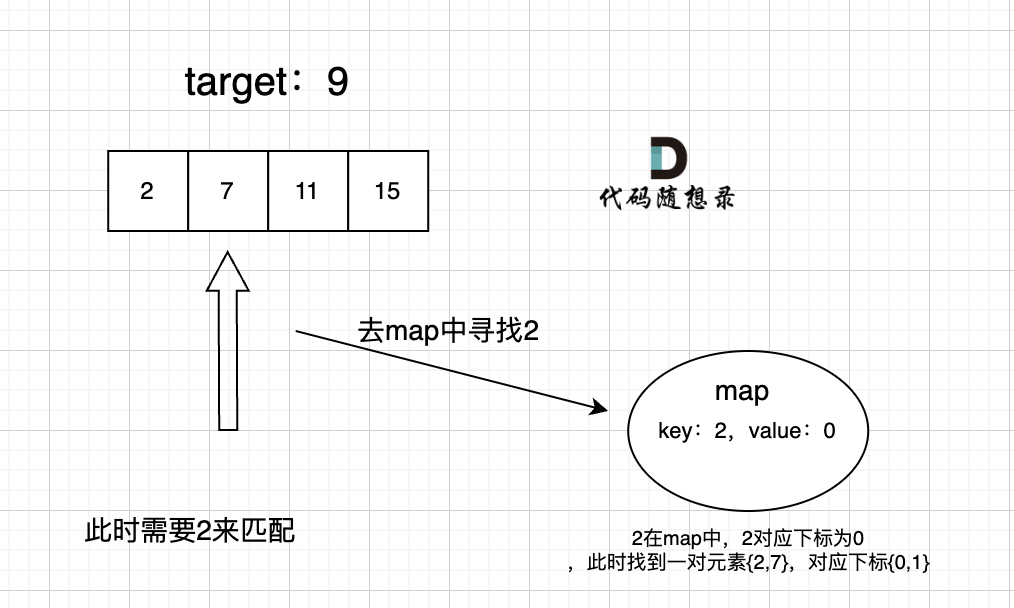
【代码实现】
(字典)哈希表
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
records = dict()
for index, value in enumerate(nums):
if target - value in records: # 遍历当前元素,并在map中寻找是否有匹配的key
return [records[target- value], index]
records[value] = index # 如果没找到匹配对,就把访问过的元素和下标加入到map中
return []
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
dict = {}
for i in range(len(nums)):
if target - nums[i] not in dict:
dict[nums[i]] = i
else:
return [dict[target-nums[i]], i]
(集合)存储看到的数字
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
# 创建一个集合来存储我们目前看到的数字
seen = set()
for i, num in enumerate(nums):
complement = target - num
if complement in seen:
return [nums.index(complement), i]
seen.add(num)
(双指针)左右指针向中间移动
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
# 对输入列表进行排序
nums_sorted = sorted(nums)
# 使用双指针
left = 0
right = len(nums_sorted) - 1
while left < right:
current_sum = nums_sorted[left] + nums_sorted[right]
if current_sum == target:
# 如果和等于目标数,则返回两个数的下标
left_index = nums.index(nums_sorted[left])
right_index = nums.index(nums_sorted[right])
if left_index == right_index:
right_index = nums[left_index+1:].index(nums_sorted[right]) + left_index + 1
return [left_index, right_index]
elif current_sum < target:
# 如果总和小于目标,则将左侧指针向右移动
left += 1
else:
# 如果总和大于目标值,则将右指针向左移动
right -= 1
(暴力法)两个for循环嵌套
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
for i in range(len(nums)):
for j in range(i+1, len(nums)):
if nums[i] + nums[j] == target:
return [i,j]
【总结】
本题其实有四个重点:
- 为什么会想到用哈希表
- 哈希表为什么用map
- 本题map是用来存什么的
- map中的key和value用来存什么的
把这四点想清楚了,本题才算是理解透彻了。















 409
409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









