







今日收获:
- 拿到题目先分析出所有情况,在面试中看到这种题目不要上来就开始写代码,然后就越写越乱。
- 匹配问题都是栈的强项。
- eval是执行字符串中的表达式并返回结果的内置函数。
20. 有效的括号
[力扣题目链接](https://leetcode.cn/problems/implement-queue-using-stacks/)
视频讲解:《代码随想录》算法视频公开课 (opens new window):栈的拿手好戏!| LeetCode:20. 有效的括号
题目如下——
给定一个只包括 ‘(’,‘)’,‘{’,‘}’,‘[’,‘]’ 的字符串,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
- 注意空字符串可被认为是有效字符串。
示例 1:
- 输入: “()”
- 输出: true
示例 2:
- 输入: “()[]{}”
- 输出: true
示例 3:
- 输入: “(]”
- 输出: false
示例 4:
- 输入: “([)]”
- 输出: false
示例 5:
- 输入: “{[]}”
- 输出: true
【思路】
在面试中看到这种题目不要上来就开始写代码,然后就越写越乱。
建议在写代码之前要分析好有哪几种不匹配的情况,如果不在动手之前分析好,写出的代码也会有很多问题。
先来分析一下 这里有三种不匹配的情况,
- 第一种情况,字符串里左方向的括号多余了 ,所以不匹配。
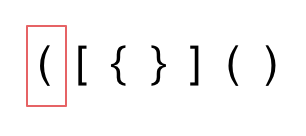
- 第二种情况,括号没有多余,但是 括号的类型没有匹配上。
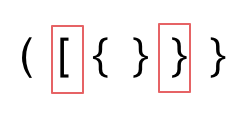
- 第三种情况,字符串里右方向的括号多余了,所以不匹配。
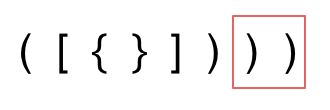
我们的代码只要覆盖了这三种不匹配的情况,就不会出问题,可以看出 动手之前分析好题目的重要性。
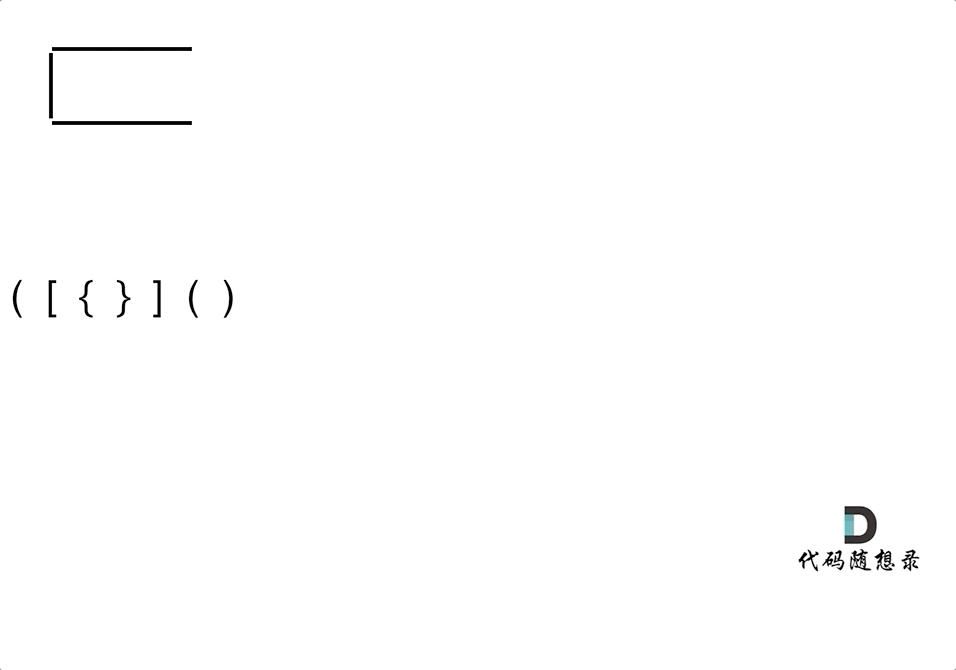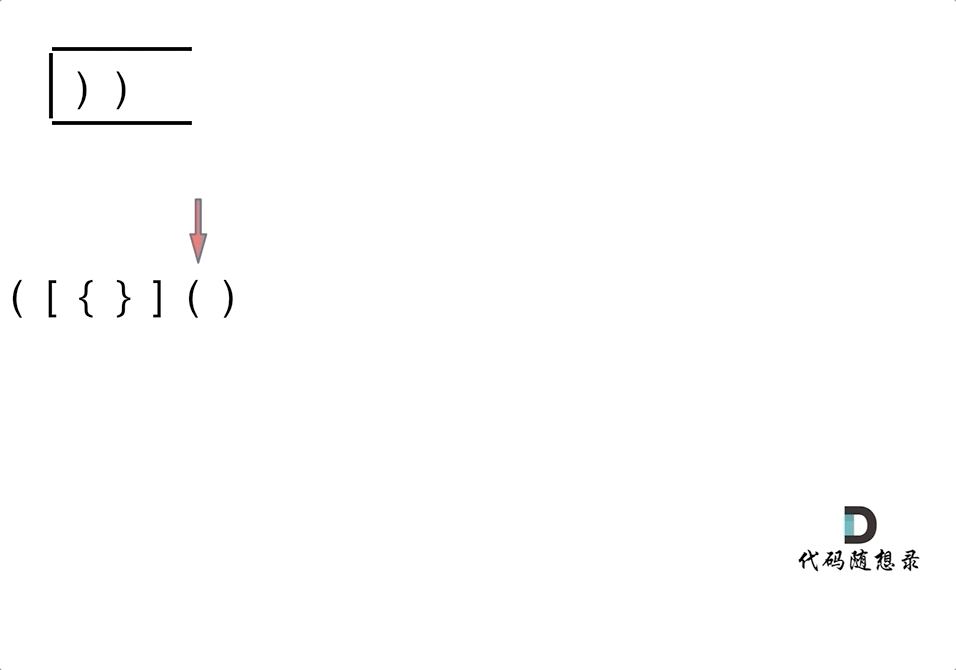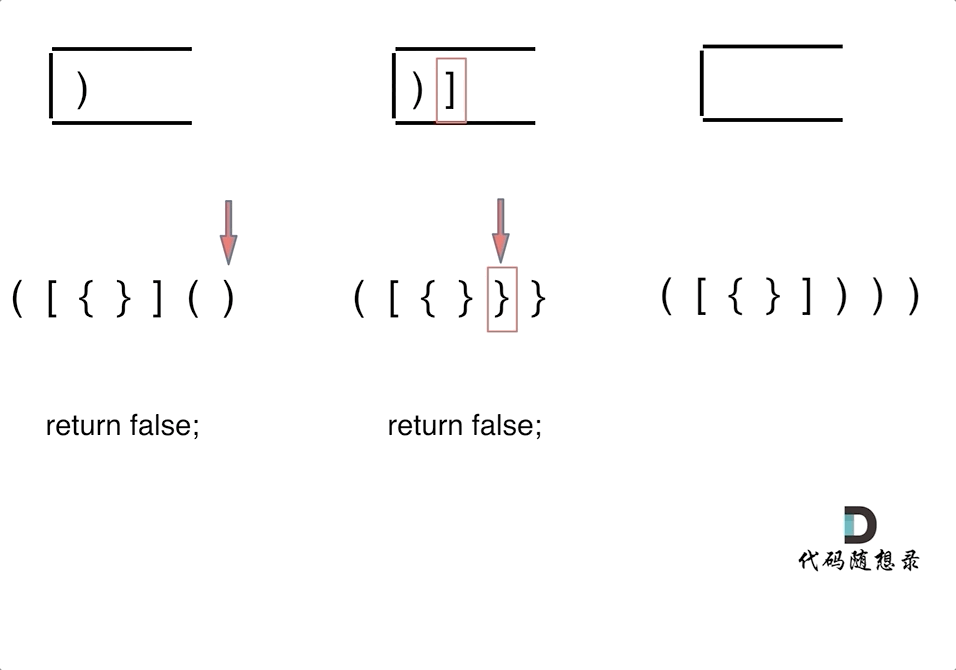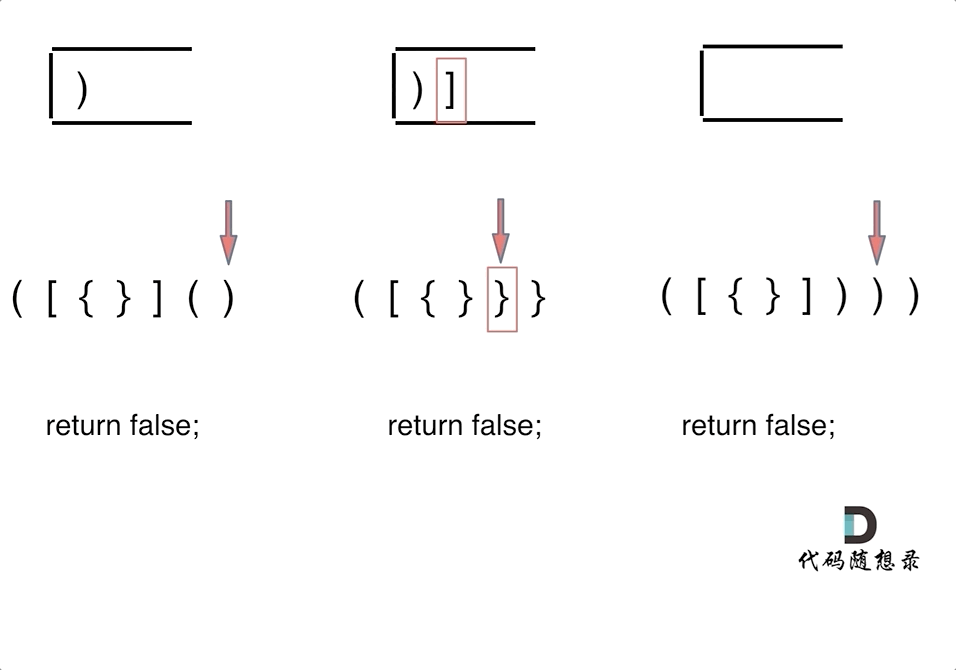
第一种情况:已经遍历完了字符串,但是栈不为空,说明有相应的左括号没有右括号来匹配,所以return false
第二种情况:遍历字符串匹配的过程中,发现栈里没有要匹配的字符。所以return false
第三种情况:遍历字符串匹配的过程中,栈已经为空了,没有匹配的字符了,说明右括号没有找到对应的左括号return false
那么什么时候说明左括号和右括号全都匹配了呢,就是字符串遍历完之后,栈是空的,就说明全都匹配了。
分析完之后,代码其实就比较好写了,
但还有一些技巧,在匹配左括号的时候,右括号先入栈,就只需要比较当前元素和栈顶相不相等就可以了,比左括号先入栈代码实现要简单的多了!
【代码实现】
(栈)每次只加入右边括号
class Solution:
def isValid(self, s: str) -> bool:
stack = []
for item in s:
if item == '(':
stack.append(')')
elif item == '[':
stack.append(']')
elif item == '{':
stack.append('}')
elif not stack or stack[-1] != item:
return False
else:
stack.pop()
return True if not stack else False
(栈)全部存进去,然后每次比较
class Solution:
def isValid(self, s: str) -> bool:
stack = []
for i in s:
if i in ["{", "(", "["]:
stack.append(i)
elif i == "}":
if len(stack) == 0 or stack[-1] != "{":
return False
stack.pop()
elif i == ")":
if len(stack) == 0 or stack[-1] != "(":
return False
stack.pop()
elif i == "]":
if len(stack) == 0 or stack[-1] != "[":
return False
stack.pop()
return len(stack) == 0
(字典)和每次只加入右边的栈的思路差不多
class Solution:
def isValid(self, s: str) -> bool:
stack = []
mapping = {
'(': ')',
'[': ']',
'{': '}'
}
for item in s:
if item in mapping.keys():
stack.append(mapping[item])
elif not stack or stack[-1] != item:
return False
else:
stack.pop()
return True if not stack else False
1047. 删除字符串中的所有相邻重复项
视频讲解:《代码随想录》算法视频公开课 (opens new window):栈的好戏还要继续!| LeetCode:1047. 删除字符串中的所有相邻重复项
题目如下——
给出由小写字母组成的字符串 S,重复项删除操作会选择两个相邻且相同的字母,并删除它们。
在 S 上反复执行重复项删除操作,直到无法继续删除。
在完成所有重复项删除操作后返回最终的字符串。答案保证唯一。
示例:
- 输入:“abbaca”
- 输出:“ca”
- 解释:例如,在 “abbaca” 中,我们可以删除 “bb” 由于两字母相邻且相同,这是此时唯一可以执行删除操作的重复项。之后我们得到字符串 “aaca”,其中又只有 “aa” 可以执行重复项删除操作,所以最后的字符串为 “ca”。
提示:
- 1 <= S.length <= 20000
- S 仅由小写英文字母组成。
【思路】
那么栈里应该放的是什么元素呢?
我们在删除相邻重复项的时候,其实就是要知道当前遍历的这个元素,我们在前一位是不是遍历过一样数值的元素,那么如何记录前面遍历过的元素呢?
所以就是用栈来存放,那么栈的目的,就是存放遍历过的元素,当遍历当前的这个元素的时候,去栈里看一下我们是不是遍历过相同数值的相邻元素。
然后再去做对应的消除操作。 如动画所示:

从栈中弹出剩余元素,此时是字符串ac,因为从栈里弹出的元素是倒序的,所以再对字符串进行反转一下,就得到了最终的结果。
题外话
这道题目就像是我们玩过的游戏对对碰,如果相同的元素挨在一起就要消除。
可能我们在玩游戏的时候感觉理所当然应该消除,但程序又怎么知道该如何消除呢,特别是消除之后又有新的元素可能挨在一起。
此时游戏的后端逻辑就可以用一个栈来实现(我没有实际考察对对碰或者爱消除游戏的代码实现,仅从原理上进行推断)。
游戏开发可能使用栈结构,编程语言的一些功能实现也会使用栈结构,实现函数递归调用就需要栈,但不是每种编程语言都支持递归,例如:
递归的实现就是:每一次递归调用都会把函数的局部变量、参数值和返回地址等压入调用栈中,然后递归返回的时候,从栈顶弹出上一次递归的各项参数,所以这就是递归为什么可以返回上一层位置的原因。
相信大家应该遇到过一种错误就是栈溢出,系统输出的异常是Segmentation fault(当然不是所有的Segmentation fault 都是栈溢出导致的) ,如果你使用了递归,就要想一想是不是无限递归了,那么系统调用栈就会溢出。
而且在企业项目开发中,尽量不要使用递归!在项目比较大的时候,由于参数多,全局变量等等,使用递归很容易判断不充分return的条件,非常容易无限递归(或者递归层级过深),造成栈溢出错误(这种问题还不好排查!)
【代码实现】
(栈)取栈尾的每次popleft出来就加到后面去
class Solution:
def removeDuplicates(self, s: str) -> str:
res = list()
for item in s:
if res and res[-1] == item:
res.pop()
else:
res.append(item)
return "".join(res) # 字符串拼接
(双指针)如果不用栈的备选方法
class Solution:
def removeDuplicates(self, s: str) -> str:
res = list(s)
slow = fast = 0
length = len(res)
while fast < length:
# 如果一样直接换,不一样会把后面的填在slow的位置
res[slow] = res[fast]
# 如果发现和前一个一样,就退一格指针
if slow > 0 and res[slow] == res[slow - 1]:
slow -= 1
else:
slow += 1
fast += 1
return ''.join(res[0: slow])
150. 逆波兰表达式求值
视频讲解:《代码随想录》算法视频公开课 (opens new window):栈的最后表演! | LeetCode:150. 逆波兰表达式求值
题目如下——
根据 逆波兰表示法,求表达式的值。
有效的运算符包括 + , - , * , / 。每个运算对象可以是整数,也可以是另一个逆波兰表达式。
说明:
整数除法只保留整数部分。 给定逆波兰表达式总是有效的。换句话说,表达式总会得出有效数值且不存在除数为 0 的情况。
示例 1:
- 输入: [“2”, “1”, “+”, “3”, " * "]
- 输出: 9
- 解释: 该算式转化为常见的中缀算术表达式为:((2 + 1) * 3) = 9
示例 2:
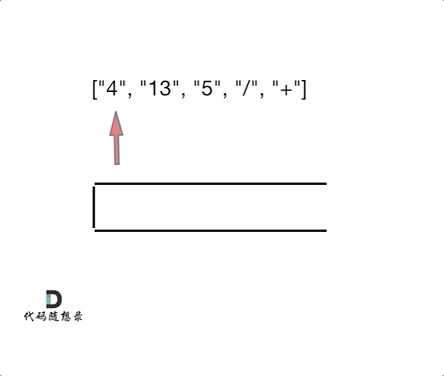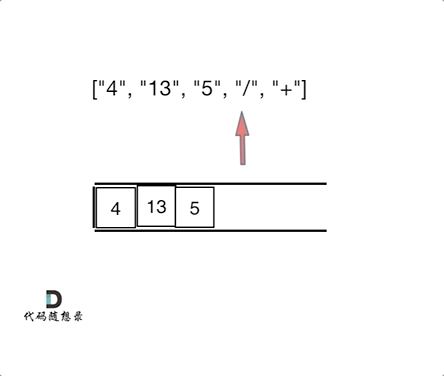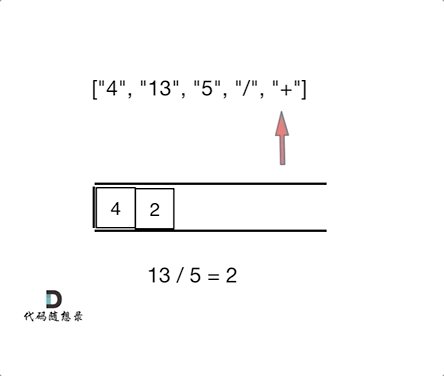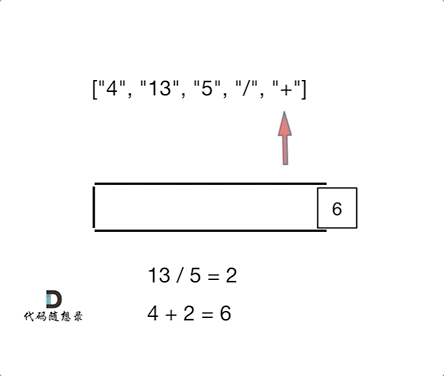
- 输入: [“4”, “13”, “5”, “/”, “+”]
- 输出: 6
- 解释: 该算式转化为常见的中缀算术表达式为:(4 + (13 / 5)) = 6
示例 3:
输入: [“10”, “6”, “9”, “3”, “+”, “-11”, " * ", “/”, " * ", “17”, “+”, “5”, “+”]
输出: 22
解释:该算式转化为常见的中缀算术表达式为:
((10 * (6 / ((9 + 3) * -11))) + 17) + 5
= ((10 * (6 / (12 * -11))) + 17) + 5
= ((10 * (6 / -132)) + 17) + 5
= ((10 * 0) + 17) + 5
= (0 + 17) + 5
= 17 + 5
= 22
【思路】
之前提到,栈与递归之间在某种程度上是可以转换的! 这一点我们在后续讲解二叉树的时候,会更详细的讲解到。
递归的实现就是:每一次递归调用都会把函数的局部变量、参数值和返回地址等压入调用栈中,然后递归返回的时候,从栈顶弹出上一次递归的各项参数,所以这就是递归为什么可以返回上一层位置的原因。
那么来看一下本题,其实逆波兰表达式相当于是二叉树中的后序遍历。 大家可以把运算符作为中间节点,按照后序遍历的规则画出一个二叉树。
但我们没有必要从二叉树的角度去解决这个问题,只要知道逆波兰表达式是用后序遍历的方式把二叉树序列化了,就可以了。
这一题用栈的思路还是可以像之前那样,一个对对碰游戏(两个数字+一个运算符)。
【代码实现】
(栈+字典)引入add/sub/mul运算符和map
from operator import add, sub, mul
class Solution:
op_map = {'+': add, '-': sub, '*': mul, '/': lambda x, y: int(x / y)}
def evalRPN(self, tokens: List[str]) -> int:
stack = []
for token in tokens:
if token not in {'+', '-', '*', '/'}:
stack.append(int(token))
else:
op2 = stack.pop()
op1 = stack.pop()
stack.append(self.op_map[token](op1, op2)) # 第一个出来的在运算符后面
return stack.pop()
(栈)用eval,可能速度较慢
class Solution:
def evalRPN(self, tokens: List[str]) -> int:
stack = []
for item in tokens:
if item not in {"+", "-", "*", "/"}:
stack.append(item)
else:
first_num, second_num = stack.pop(), stack.pop()
stack.append(
int(eval(f'{second_num} {item} {first_num}')) # 第一个出来的在运算符后面
)
return int(stack.pop()) # 如果一开始只有一个数,那么会是字符串形式的
(栈但暴力)不太建议,还是以上的集成式一点的写法好一些
class Solution:
def evalRPN(self, tokens: List[str]) -> int:
stack = []
ans = 0
for item in tokens:
if item == '+':
tmp = int(stack.pop()) + int(stack.pop())
stack.append(tmp)
elif item == '-':
tmp = - int(stack.pop()) + int(stack.pop())
stack.append(tmp)
elif item == '*':
tmp = int(stack.pop()) * int(stack.pop())
stack.append(tmp)
elif item == '/':
s1 = stack.pop()
s2 = stack.pop()
tmp = int(s2) / int(s1)
stack.append(tmp)
else:
stack.append(item)
return int(stack.pop())















 834
834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









