






一. 安装
python 的版本需要是 3.7-3.11之间
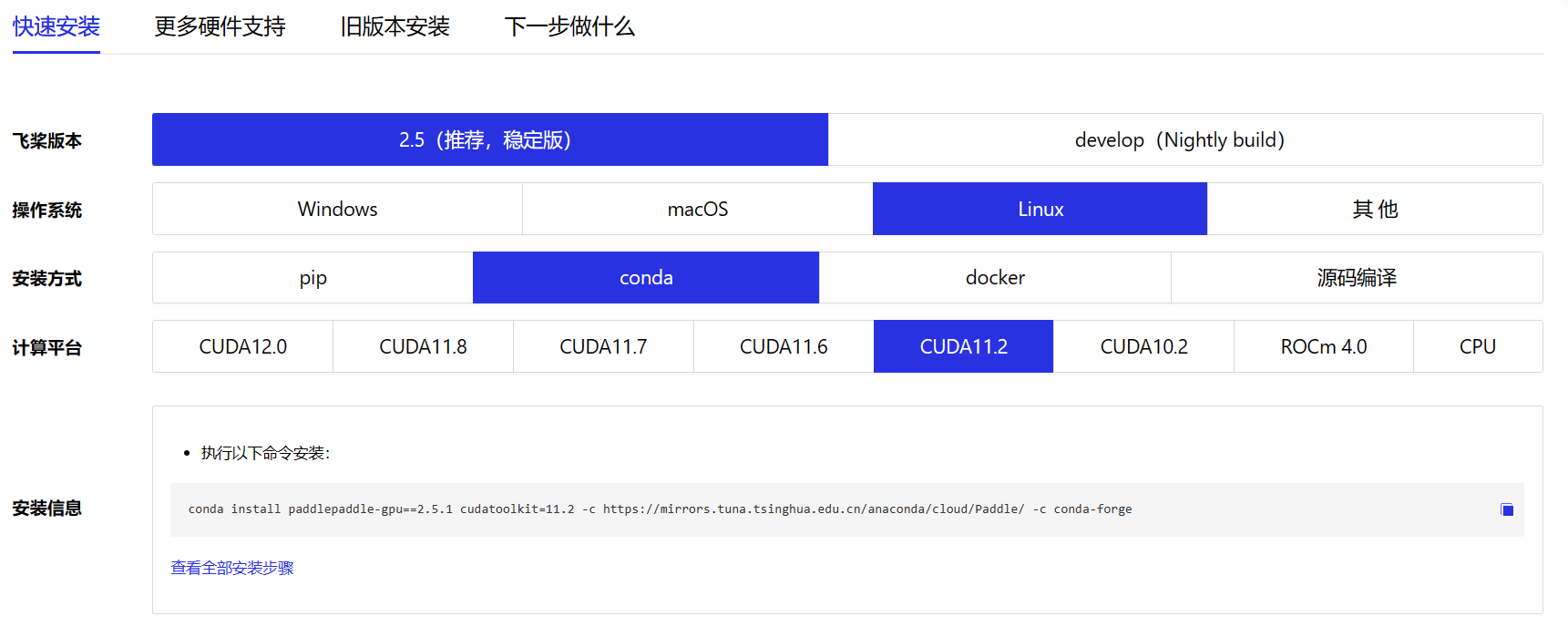
conda install paddlepaddle-gpu==2.5.1 cudatoolkit=11.2 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/ -c conda-forge
安装paddlenlp
在安装的包名称后面加上==可以查看可安装的包版本,比如:
pip install paddlenlp== -i https://pypi.tuna.tsinghua.edu.cn/simple

安装paddlenlp报错

distutils.errors.DistutilsError: Command ‘[‘anaconda3/envs/er/bin/python’, ‘-m’, ‘pip’, ‘–disable-pip-version-check’, ‘wheel’, ‘–no-deps’, ‘-w’, ‘/tmp/tmpjzq2xl09’, ‘–quiet’, ‘setuptools_scm’]’ returned non-zero exit status 1.
这是解决方法
报错里面其实提示了,pip语句添加 --use-pep517 参数就可以。
pip install paddlenlp==2.5.0 --use-pep517 -i https://pypi.tuna.tsinghua.edu.cn/simple
二. 使用ERNIE3
下载数据集 中文评论情感分析语料数据集ChnSentiCorp,有可能出现报错:
from paddlenlp.datasets import load_dataset
train_ds, dev_ds, test_ds = load_dataset("chnsenticorp", splits=["train", "dev", "test"])
ModuleNotFoundError: No module named ‘paddle.fluid.layers.utils’
安装paddlenlp最新版本就可以解决了。
使用官网代码进行简单训练
发现没有eval这个模块。可以使用AIstudio启动环境,查看eval.py的代码,将这个文件添加到运行文件同一级目录下就可以了。具体代码如下,可以直接复制。
ModuleNotFoundError: No module named ‘eval’
import paddle
import numpy as np
# 构建验证集evaluate函数
@paddle.no_grad()
def evaluate(model, criterion, metric, data_loader):
model.eval()
metric.reset()
losses = []
for batch in data_loader:
input_ids, token_type_ids, labels = batch['input_ids'], batch['token_type_ids'], batch['labels']
logits = model(input_ids, token_type_ids)
loss = criterion(logits, labels)
losses.append(loss.numpy())
correct = metric.compute(logits, labels)
metric.update(correct)
accu = metric.accumulate()
print("eval loss: %.5f, accuracy: %.5f" % (np.mean(losses), accu))
model.train()
metric.reset()
return accu
三. 创建自己的数据集进行训练
数据格式:
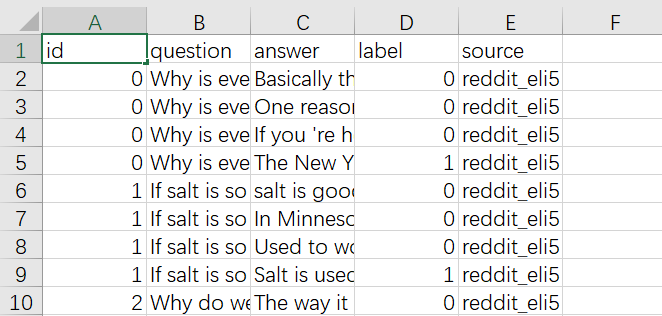
训练:
import paddle
import functools
import pandas as pd
import time
import paddle.nn.functional as F
from paddlenlp.datasets import load_dataset, MapDataset
from paddlenlp.transformers import AutoModelForSequenceClassification, AutoTokenizer
from paddle.io import DataLoader, BatchSampler, Dataset
from paddlenlp.data import DataCollatorWithPadding
num_class = 2
max_seq_length = 512
epochs = 2
model_name = "ernie-3.0-medium-zh"
data_dir = "/home/ernie-3.0/train.csv" # 数据路径
save_dir = "/home/ernie-3.0/1" # 保存路径
# 数据加载类
class MyDataset(Dataset):
"""
步骤一:继承 paddle.io.Dataset 类
"""
def __init__(self, data_dir):
"""
步骤二:实现 __init__ 函数,初始化数据集,将样本和标签映射到列表中
"""
super().__init__()
self.data_list = []
train_df = pd.read_csv(data_dir, usecols=['answer', 'label']) # 读取某两列
for index, item in train_df.iterrows():
dict = {}
dict['text'] = item['answer']
dict['label'] = int(item['label'])
self.data_list.append(dict)
def __getitem__(self, index):
"""
步骤三:实现 __getitem__ 函数,定义指定 index 时如何获取数据,并返回单条数据(样本数据、对应的标签)
"""
return self.data_list[index]
def __len__(self):
"""
步骤四:实现 __len__ 函数,返回数据集的样本总数
"""
return len(self.data_list)
train_ds = MyDataset(data_dir)
train_ds = MapDataset(train_ds) # 转化为 MapDataset 类,才能进行map操作
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_classes=num_class)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 数据预处理函数,利用分词器将文本转化为整数序列
def preprocess_function(examples, tokenizer, max_seq_length, is_test=False):
result = tokenizer(text=examples["text"], max_seq_len=max_seq_length)
if not is_test:
result["labels"] = examples["label"]
return result
trans_func = functools.partial(preprocess_function, tokenizer=tokenizer, max_seq_length=max_seq_length)
train_ds = train_ds.map(trans_func)
# collate_fn函数构造,将不同长度序列充到批中数据的最大长度,再将数据堆叠
collate_fn = DataCollatorWithPadding(tokenizer)
# 定义BatchSampler,选择批大小和是否随机乱序,进行DataLoader
train_batch_sampler = BatchSampler(train_ds, batch_size=32, shuffle=True)
train_data_loader = DataLoader(dataset=train_ds, batch_sampler=train_batch_sampler, collate_fn=collate_fn)
# Adam优化器、交叉熵损失函数、accuracy评价指标
optimizer = paddle.optimizer.AdamW(learning_rate=5e-5, parameters=model.parameters())
criterion = paddle.nn.loss.CrossEntropyLoss()
metric = paddle.metric.Accuracy()
global_step = 0 # 迭代次数
tic_train = time.time()
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, token_type_ids, labels = batch['input_ids'], batch['token_type_ids'], batch['labels']
# 计算模型输出、损失函数值、分类概率值、准确率
logits = model(input_ids, token_type_ids)
loss = criterion(logits, labels)
probs = F.softmax(logits, axis=1)
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
# 每迭代10次,打印损失函数值、准确率、计算速度
global_step += 1
if global_step % 10 == 0:
print(
"global step %d, epoch: %d, batch: %d, loss: %.5f, accu: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss, acc,
10 / (time.time() - tic_train)))
tic_train = time.time()
# 反向梯度回传,更新参数
loss.backward()
optimizer.step()
optimizer.clear_grad()
model.save_pretrained(save_dir)
tokenizer.save_pretrained(save_dir)
运行过程:

测试:
import paddle
import functools
import pandas as pd
import paddle.nn.functional as F
from paddlenlp.datasets import load_dataset, MapDataset
from paddlenlp.transformers import AutoModelForSequenceClassification, AutoTokenizer
from paddle.io import DataLoader, BatchSampler, Dataset
from paddlenlp.data import DataCollatorWithPadding
from sklearn.metrics import f1_score, accuracy_score
from sklearn.metrics import classification_report, roc_auc_score
num_class = 2
max_seq_length = 512
model_name = "ernie-3.0-medium-zh"
data_dir = "/home/ernie-3.0/test.csv"
params_path = '/home/ernie-3.0/1/model_state.pdparams'
# 数据加载类
class MyDataset(Dataset):
"""
步骤一:继承 paddle.io.Dataset 类
"""
def __init__(self, data_dir):
"""
步骤二:实现 __init__ 函数,初始化数据集,将样本和标签映射到列表中
"""
super().__init__()
self.data_list = []
test_df = pd.read_csv(data_dir, usecols=['answer', 'label']) # 读取某两列
for index, item in test_df.iterrows():
dict = {}
dict['text'] = item['answer']
dict['label'] = int(item['label'])
self.data_list.append(dict)
def __getitem__(self, index):
"""
步骤三:实现 __getitem__ 函数,定义指定 index 时如何获取数据,并返回单条数据(样本数据、对应的标签)
"""
return self.data_list[index]
def __len__(self):
"""
步骤四:实现 __len__ 函数,返回数据集的样本总数
"""
return len(self.data_list)
test_ds = MyDataset(data_dir)
test_ds = MapDataset(test_ds)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_classes=num_class)
tokenizer = AutoTokenizer.from_pretrained(model_name)
state_dict = paddle.load(params_path)
model.set_dict(state_dict)
# 数据预处理函数,利用分词器将文本转化为整数序列
def preprocess_function(examples, tokenizer, max_seq_length, is_test=False):
result = tokenizer(text=examples["text"], max_seq_len=max_seq_length)
if not is_test:
result["labels"] = examples["label"]
return result
trans_func_test = functools.partial(preprocess_function, tokenizer=tokenizer, max_seq_length=max_seq_length, is_test=True)
test_ds_trans = test_ds.map(trans_func_test)
# 进行采样组batch
collate_fn_test = DataCollatorWithPadding(tokenizer)
test_batch_sampler = BatchSampler(test_ds_trans, batch_size=5, shuffle=False)
test_data_loader = DataLoader(dataset=test_ds_trans, batch_sampler=test_batch_sampler, collate_fn=collate_fn_test)
results = []
model.eval()
for batch in test_data_loader:
input_ids, token_type_ids = batch['input_ids'], batch['token_type_ids']
logits = model(batch['input_ids'], batch['token_type_ids'])
probs = F.softmax(logits, axis=-1)
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
preds = [i for i in idx]
results.extend(preds)
test_df = pd.read_csv(data_dir, usecols=['answer', 'label'])
targets = []
for index, item in test_df.iterrows():
label = int(item['label'])
targets.append(label)
print("accuracy_score ", accuracy_score(targets, results))
print("roc_auc_score ", roc_auc_score(targets, results))
print(classification_report(targets, results))
ERNIE3版本
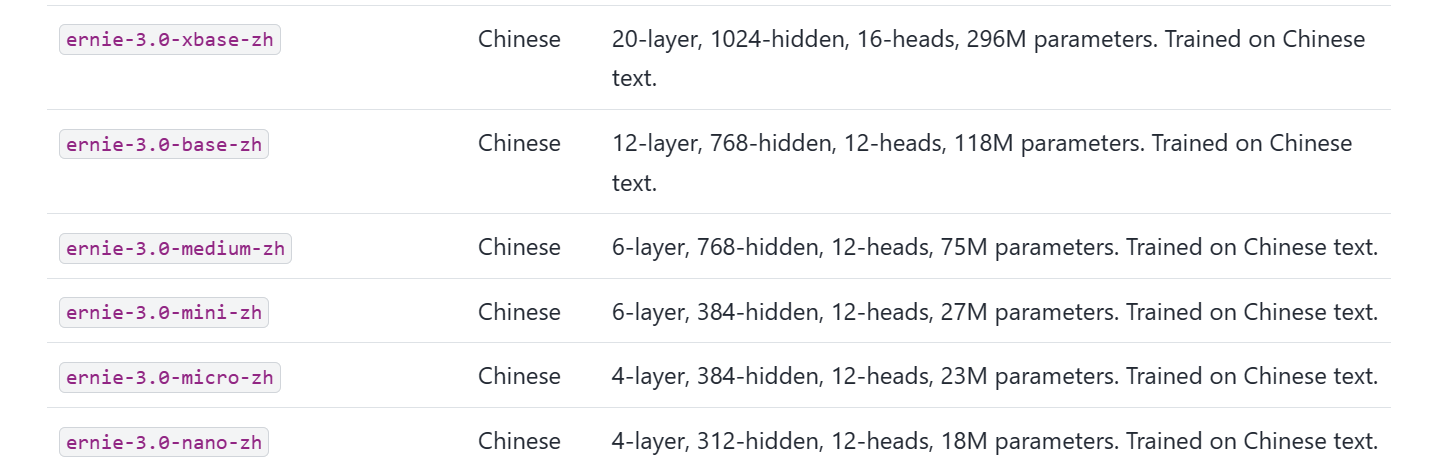
试了试xbase和base版本,都会显示
OSError: Can’t load the model for ‘ernie-3.0-base-zh’. If you were trying to load it from ‘https://paddlenlp.bj.bcebos.com’















 1941
1941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









