







第八章--排序 板子
排序算法性能比较

一些小结论
1)除上述之外,折半插入排序算法:
最坏时间复杂度为O(n²),平均时间复杂度O(n²),最好时间复杂度O(nlogn),空间O(1),也是一种稳定的排序算法
(2)可以发现有用到二叉树思想的算法(快、堆、归),其三种情况下的时间复杂度基本都在(除了快速排序在最坏情况下会退化到O(n²))
(3)具有稳定性的算法:合插基冒(在这家店喝茶几毛钱一直是稳定的)
(4)若n较小,可采用直接插入排序或简单选择排序。又由于直接插入排序所需的记录移动次数较简单选择排序的多,因此当记录本身信息量较大时,用简单选择排序较好。
(5)若文件的初始状态已按关键字基本有序,则选用直接插入排序或冒泡排序
(6)若n较大,则应采用时间复杂度为的排序方法:快速排序、堆排序或合并排序。
(7)当待排序的关键字随机分布时,快速排序的平均时间最短,平均性能最优;但当排序的关键字基本有序或基本逆序时,会得到最坏的时间复杂度和最坏的空间复杂度
(8)堆排序所需的辅助空间少于快速排序,并且不会出现快速排序可能出现的最坏情况
(9)若要求排序稳定,并且时间复杂度为,则可选用合并排序
(10)当数据量较大时,可以将合并排序和直接插入排序结合使用,先利用直接插入排序求得较长的有序子文件,然后再使用合并排序两两合并,由于两种方法都是稳定的,因此结合之后也是稳定的。
(11)当n很大,记录的关键字位数较少且可以分解时,采用基数排序较好
(12)当记录本身信息量较大时,为避免耗费大量时间移动记录,可以使用链表作为存储结构(当然,有的排序方法不适用于链表)
1、插入排序
<1>直接插入排序
思路:从第二个元素开始,从左向右依次处理每个元素,,每个元素不断向前寻找自己合适的位置,(以升序为例),和前一个元素比较,如果大于交换继续向前比较,反之停止。

//都是升序排列
#include <iostream>
int item[100000];
int size;
void directInsertSort(int n) {
for (int i = 0; i < n; i++) {
int tmp = item[i];//每次要处理的元素
//开始向前寻找合适的位置
int pos = i-1;//从目标钱一个位置开始
for (; pos >= 0; pos--) {//开始向前找到这个目标书应该在的位置
if (item[i] >= item[pos]) {//比自己大,就继续往前
break;
}
}
for (int j = i - 1; j > pos; j--) {//从i-1到pos+1的数都往后移动一位
item[j + 1] = item[j];
}
item[pos + 1] = tmp;//最后放入目标数
}
}
int main(){
scanf("%d", &size);
for (int i = 0; i < size; i++)
{
scanf("%d", &item[i]);
}
directInsertSort(size);
for (int i = 0; i < size; i++) {
printf("%d ", item[i]);
}
return 0;
}
效率分析:

<2>折半插入排序
真题中出现过,特此整理思路代码

思路:
1、把插入排序的,一项一项向前寻找合适位置的过程优化
2、因为处理第i处,那么从0到i-1之间一定已经满足递增了
3、所以把原本一项一项寻找的过程,改成了利用折半(二分)法,找目标位置
4、写二分法时候,如果在区间内找到了目标,说明这是重复元素,因为这个算法稳定,所以返回后面的一个位置
5、没重复元素,一定是查找失败,在left>right时候,因为right非法,所以目标位置就是right+1(自己举个例子就知道了)
6、因为二分法,是已经排好序得了,所以每次分割有目的性,直达目标,所以一旦停下来,说明已经找到合适位置了
#include <iostream>
#include <string>
#include <stack>
#include <queue>
#include <unordered_map>
#include <vector>
#include <algorithm>
using namespace std;
int findPos(int tar, int left, int right) {
if (left > right) {//左大于右,非法情况,这个这么记忆,如果right==-1,则代表着插到 -1+1=0的位置处
return right + 1;//right位置非法,所以返回right+1
}
int mid = (left + right) / 2;
if (two[mid] == tar) {
return mid + 1;//为了保持稳定性,所以返回当前位置+1
}
else if (two[mid] > tar) {
return findPos(tar, left, mid - 1);//有目的性进行递归深入,只会到终点一次
}
else {
return findPos(tar, mid + 1, right);
}
}
void function_two() {
cin >> n;
for (int i = 0; i < n; i++) {
cin >> two[i];
}
for (int i = 1; i < n; i++) {
int tmp = two[i];
int pos = findPos(tmp, 0, i - 1);//得到插入位置
for (int j = i; j >= pos; j--) {//按照插入位置挪动
two[j] = two[j - 1];
}
two[pos] = tmp;
}
for (int i = 0; i < n; i++) {
cout << two[i] << ' ';
}
return;
}
<3>希尔排序
思路:为了解决直接插入排序,小元素太靠后,而造成的频繁移动问题,所以使用了希尔排序,所以,通过分组(如何分组,看的是增量K),先把小元素往左移,大元素右移,让最后的排序(就相当于对元素整理过后的直接插入)移动次数大幅减少。

#include <iostream>
int item[100000];
int size;
class shall_sort {
public:
shall_sort() {
this->n = size;
for (int i = 0; i < n; i++) {
arrays[i] = item[i];
}
}
void shallSort() {
int k = n / 2;//初始规模
while (k >= 1) {//直到k=1作为最后一次移动,整体作为一组,此时小的元素整体在左面,大的在右面,在直接插入效率快很多,之前相当于预处理
//k固定,分组确定了,所以把每个分组中的第二个节点以及往后的节点进行直接插入排序
for (int i = k; i < n; i++) {//0->k-1为各个组的第一个节点,所以从k开始,即第一组第二节点开始,把后面的各个组的每个节点都直接插入到改组正确位置
derectInsert(i, k);//针对每个点(start),在该分组中(pace决定)插入到合适位置
}
k /= 2;//缩小规模
}
}
void Print() {
for (int i = 0; i < n; i++) {
printf("%d ", arrays[i]);
}
}
private:
int arrays[100050];
int n;
//确定pace,一个组当中,从第二个节点开始,每个节点的向前移动寻找本组中合适位置的过程
//和原本的直接插入不一样,每次处理的都是大数组中的一部分,所以需要处理位置,以及每个元素之间间隔(pace)
void derectInsert(int start, int pace) {//参数:本次直接排序起点,以及每次向前的步伐(用于找到本组在他前面的节点)
if (start >= n) {//边界判断
return;
}
int pos = start - pace;//本组中离他最近的节点
while (pos >= 0) {//防止越界
if (arrays[pos] <= arrays[start]) {//因为升序排序,所以发现<=目标的停止
break;
}
int tmp = arrays[start];//反之交换
arrays[start] = arrays[pos];
arrays[pos] = tmp;
start = pos;//更新起点以及上一个元素位置,循环向前
pos = start - pace;
}
}
};
int main(){
scanf("%d", &size);
for (int i = 0; i < size; i++)
{
scanf("%d", &item[i]);
}
shall_sort* ss = new shall_sort();
ss->shallSort();
ss->Print();
return 0;
}
算法性能分析:

2、交换排序
<1>冒泡排序
思路:就是一趟一趟的把两两之间有顺序问题的两个元素进行交换,直到没问题为止

#include <iostream>
int item[100000];
int size;
void bubbleSort(int n) {
//是否会产生交换标志
bool flag = true;
//开始不间断的交换,直到不再产生交换位置
while (flag) {
flag = false;//默认本轮不产生交换
for (int i = 0; i < n - 1; i++) {//相邻的数据两两比较
if (item[i] > item[i + 1]) {//发现可交换(因为是升序且稳定,所以条件是 前>后)
//发生了交换,还得再来一轮
flag = true;
//交换
int tmp = item[i + 1];
item[i + 1] = item[i];
item[i] = tmp;
}
}
}
}
int main(){
scanf("%d", &size);
for (int i = 0; i < size; i++)
{
scanf("%d", &item[i]);
}
bubbleSort(size);
for (int i = 0; i < size; i++) {
printf("%d ", item[i]);
}
return 0;
}
算法性能分析

补充:二维数组的冒泡排序
1、不要被二维数组给骗了,因为其在电脑中的存储地址是连续的:
*(基地址+该元素前面的元素个数)
就可以访问任意一个二维数组的元素,所以就等效于把二维数组降为一维处理
2、共n^2个元素,最后一个元素表示为 *(基地址+n^2-1),因为要两两交换,所以枚举到 n^2-2
#include <iostream>
#include <string>
#include <stack>
#include <queue>
#include <unordered_map>
#include <vector>
#include <algorithm>
using namespace std;
//第四题
//如果排序之后满足行列都是递增,则必然满足题意,所以本题就是二维数组排序问题。
//一维数组,直接用下标寻址,二维数组用,(基地址+前方元素数)可以模拟出一维寻址效果,进而使用一维的冒泡排序
int four[5][5];
void bubbleSort(int n) {
bool flag = true;
int * base_address = &four[0][0];//基地址
while (flag) {
flag = false;
for (int i = 0; i < n*n - 1; i++) {//枚举间隔数,比如a[0][1],前面有一个元素,间隔数为1,所以(基地址+1)就是它
if (*(base_address + i) > *(base_address + i + 1)) {
flag = true;
int tmp = *(base_address + i);
*(base_address + i) = *(base_address + i + 1);
*(base_address + i + 1) = tmp;
}
}
}
}
int main()
{
int four_n = 5;
for (int i = 0; i < four_n; i++) {
for (int j = 0; j < four_n; j++) {
cin >> four[i][j];
}
}
bubbleSort(four_n);
cout << endl;
for (int i = 0; i < four_n; i++) {
for (int j = 0; j < four_n; j++) {
cout << four[i][j] << ' ';
}
cout << endl;
}
return 0;
}
补充:链表的冒泡排序

像这种题,未规定方法,给链表排序,推荐直接使用冒泡,因为最简单,思路和数组排序最接近
思路:
1、也是用flag控制何时排序全部停止
2、因为涉及交换两个节点,共需要标记四个节点,但是由于但项链表属性,所以只需要标记前三个即可
3、内层循环的话,保证不越界就行,所以让third指针不是nullptr
4、余下和数组版本一致
5、默认有哨兵节点
#include <iostream>
#include <string>
#include <stack>
#include <queue>
#include <unordered_map>
#include <vector>
#include <algorithm>
using namespace std;
typedef struct node {
int data;
node* next;
};
node* function_seven(node* l) {//默认l有哨兵节点
//预处理2000以内所有素数:欸氏筛法
bool primeNum[2000];
for (int i = 2; i < 2000; i++) {
primeNum[i] = true;
}
for (int i = 2; i < 2000; i++) {
if (primeNum[i]) {
for (int j = 2 * i; j < 2000; j += i) {
primeNum[i] = false;
}
}
}
//删除val为素数的节点
node *cur = l->next, *pre = l;
while (cur != nullptr) {
if (primeNum[abs(cur->data)]) {//绝对值是素数就删除,并且删除之后,指针不用动,恰好符合下一次的判定
node *tmp = cur;
cur = cur->next;
pre->next = cur;
tmp->next = nullptr;//删除
free(tmp);
}
else {
pre = cur;
cur = cur->next;
}
}
//开始冒泡排序,按照递减的顺序,整体上和数组冒泡一个写法
bool flag = true;
while (flag) {
flag = false;
//first second third是用来辅助一次遍历过程中交换所用,所以定义在里面
node *first = l, *second = l->next, *third = l->next->next;//交换两个节点,需要标记四个节点的位置,因为链表属性,只需要前三个就行
while (third != nullptr) {
if (second->data < third->data) {//递减排序
flag = true;//标志产生交换
first->next = third;//交换顺序绝对不能变
second->next = third->next;
third->next = second;
}
first = first->next;
second = second->next;
third = third->next;
}
}
return l;
}
<2>快速排序
思路:分而治之,让每个元素左面全小于他,右面全大于他即可
(下图所示是快速排序一次的交换过程,此次交换完事之后,Pivot左面都小于他,右面都大于他,所以继续分化,直到每个元素都具备上述性质即可)

//都是升序排列
#include <iostream>
int item[100000];
int size;
class quick_sort {
public:
quick_sort() {
this->n = size;
for (int i = 0; i < n; i++) {
arrays[i] = item[i];
}
}
//快速排序
void quickSort(int left, int right) {
if (left > right) {//递归退出条件
return;
}
int mid = partition(left, right);//mid左面都小于他,右面都大于他
quickSort(left, mid - 1);//同样的思路继续对左面分治
quickSort(mid + 1, right);//同样的思路继续对右面分治
}
void Print() {
for (int i = 0; i < n; i++){
printf("%d ", arrays[i]);
}
}
private:
int arrays[100050];
int n;
//每次快排内部的划分过程
int partition(int low, int hight) {
int base = arrays[low];//基点
while (low < hight) {
//注意:
//1、基点选在左边界,那就从右面开始找,反之从左面开始找
//2、时刻注意,low<hight,二者一旦相等,意味着这次划分就结束了
while (low < hight&&arrays[hight] >= base) {//hight那边元素必须>=base
hight--;
}
//发现 < base,交换到low那一侧
arrays[low] = arrays[hight];
while (low < hight&&arrays[low] <= base) {//low那边元素必须<=base
low++;
}
//发现 > base, 交换到low那一侧
arrays[hight] = arrays[low];
}
arrays[low] = base;//二者相遇,base左面都小于他,右面都大于他
return low;
}
};
int main(){
scanf("%d", &size);
for (int i = 0; i < size; i++)
{
scanf("%d", &item[i]);
}
quick_sort* qs = new quick_sort();
qs->quickSort(0, size - 1);
qs->Print();
return 0;
}
算法性能分析:

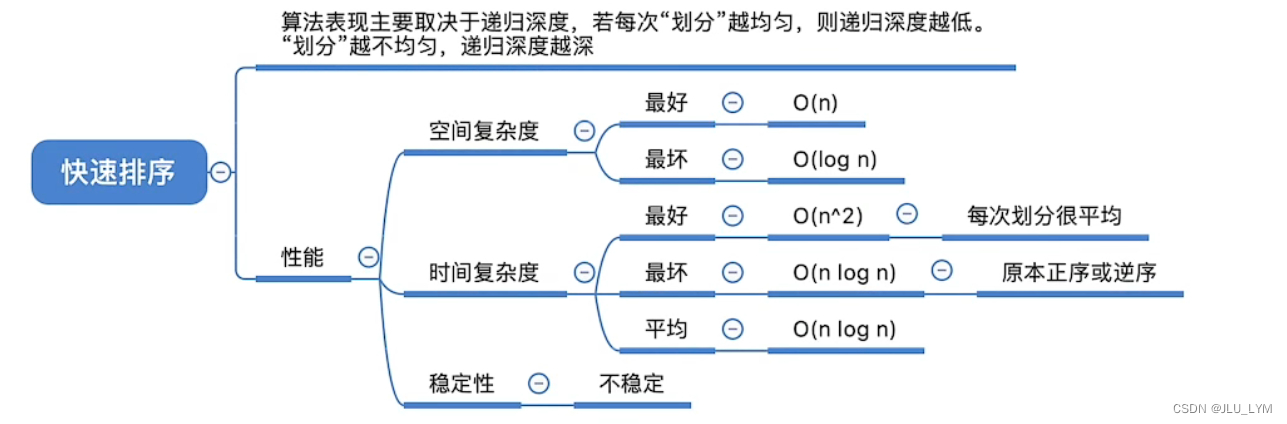
(二图时空复杂度有地方反了,参考一图)
3、选择排序
<1> 堆排序
思路:利用大根堆性质,每次快速在堆顶获得最大值,和此规模下最后一个元素换位置,减小规模,再把堆顶元素下沉(重整堆,这也是删除堆中任何一个位置元素的思路)。
(下图中我们建堆的思路与之不同,我们先把数组输入进来,把每个位置的元素都下沉一遍来建堆)

//都是升序排列
#include <iostream>
int item[100000];
int size;
class heap_sort {//因为升序排列,所以使用大根堆
public:
heap_sort() {
this->n = size;//初始化规模
for (int i = 1; i <= n; i++) {//初始化堆数组
heaps[i] = item[i - 1];
}
//重整堆
for (int i = n; i >= 1; i--) {
Down(i, n);//把堆每个位置处的元素都下沉一次就行
}
}
void heapSort() {
for (int i = n; i >= 1; i--) {//i表示当前处理规模
//每次把当前规模的:堆顶(最大)放到最后(因为是升序排列),进入结果集
int tmp = heaps[1];
heaps[1] = heaps[i];
heaps[i] = tmp;
Down(1, i - 1);//此时规模减一,相当于删除了堆顶,把堆顶元素1重新下沉重整堆即可。
}
}
void print() {
for (int i = 1; i <= n; i++) {
printf("%d ", heaps[i]);
}
}
private:
int heaps[100050];//完全二叉树用数组存储,儿子节点和父亲节点有固定的计算方式,从1开始
int n;//总规模
//封装堆操作--上浮
void Up(int k, int size) {//第几个元素,此时规模是多大
int fa = k >> 1;//父亲节点 / 2
while (fa > 0) {//从零开始存储,边界就是0,不能超过边界
if (heaps[fa] > heaps[k]) {//大根堆,父亲比自己大,停止
break;
}
int tmp = heaps[fa];//交换
heaps[fa] = heaps[k];
heaps[k] = tmp;
k = fa;//准备继续进行之前步骤
fa >>= 1;
}
}
//封装堆操作--下沉
void Down(int k, int size) {
int son = k << 1;//寻找儿子节点 *2
while (son <= size) {//范围
if (son + 1 <= size && heaps[son] < heaps[son + 1]) {//两个儿子,挑大的上来
son++;
}
if (heaps[k] > heaps[son]) {//结束标志,儿子没有比他大的,因为大根堆
break;
}
int tmp = heaps[son];//交换
heaps[son] = heaps[k];
heaps[k] = tmp;
k = son;//准备下一次
son <<= 1;
}
}
};
int main(){
scanf("%d", &size);
for (int i = 0; i < size; i++)
{
scanf("%d", &item[i]);
}
heap_sort* hs = new heap_sort();
hs->heapSort();
hs->print();
return 0;
}
算法性能分析:
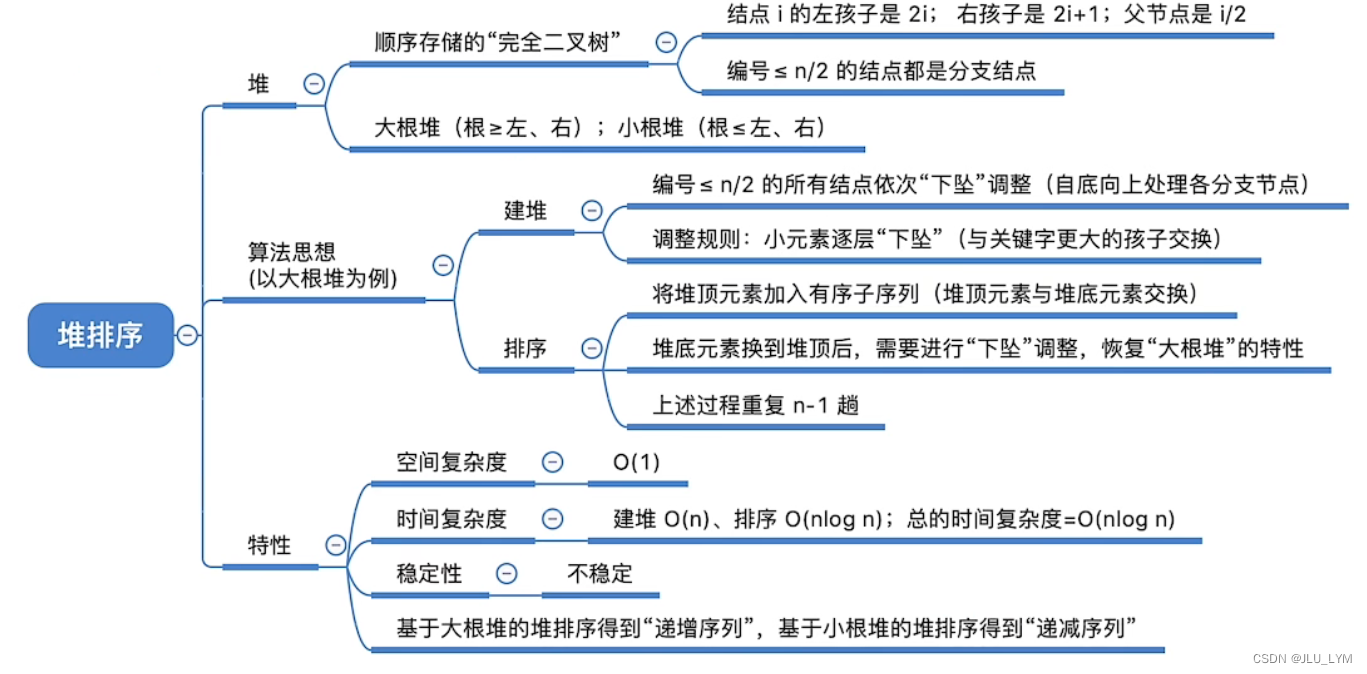
<2> 堆排序灵活应用

1、这种题就不要拘泥于传统的堆排序模型,那样的话复杂度会稳定在O(nlogn)在极大的数据量面前,复杂度还是太高
3、堆本质上还是一棵二叉树,所以我们不要让二叉树生长的太大,也是不好的,这样每次调整都会很慢很慢
2、这种题明确地指出了,我就要这100万人中的前二十,所以,我们只需要维护20个名额就行,这样,二叉树最多就5层,每次调整最多五次,常数级别的调整,大幅缩短了调整所耗费的时间。
4、综上所述,我们维护一个20个元素的 “ 小根堆 ”,每次新元素,如果比栈顶元素大,那么就完全可能是前二十中的一员,入堆,如果小于堆顶,就意味着,小于前二十中最小的元素(堆顶表示堆中最小的元素),一定不是答案
5、这样,时间复杂度就降低到了O(n)。
注:以上过程,可以更形象地理解为,我拿一个20个元素的过滤器,把所有元素扫一遍,把大的富集进来
4、合并排序
<1>二路归并排序
思路:逐层划分至只有一个元素,在逐层合并(所以后根遍历法)。因为是升序序列,所以每次从两个队头里面找最小
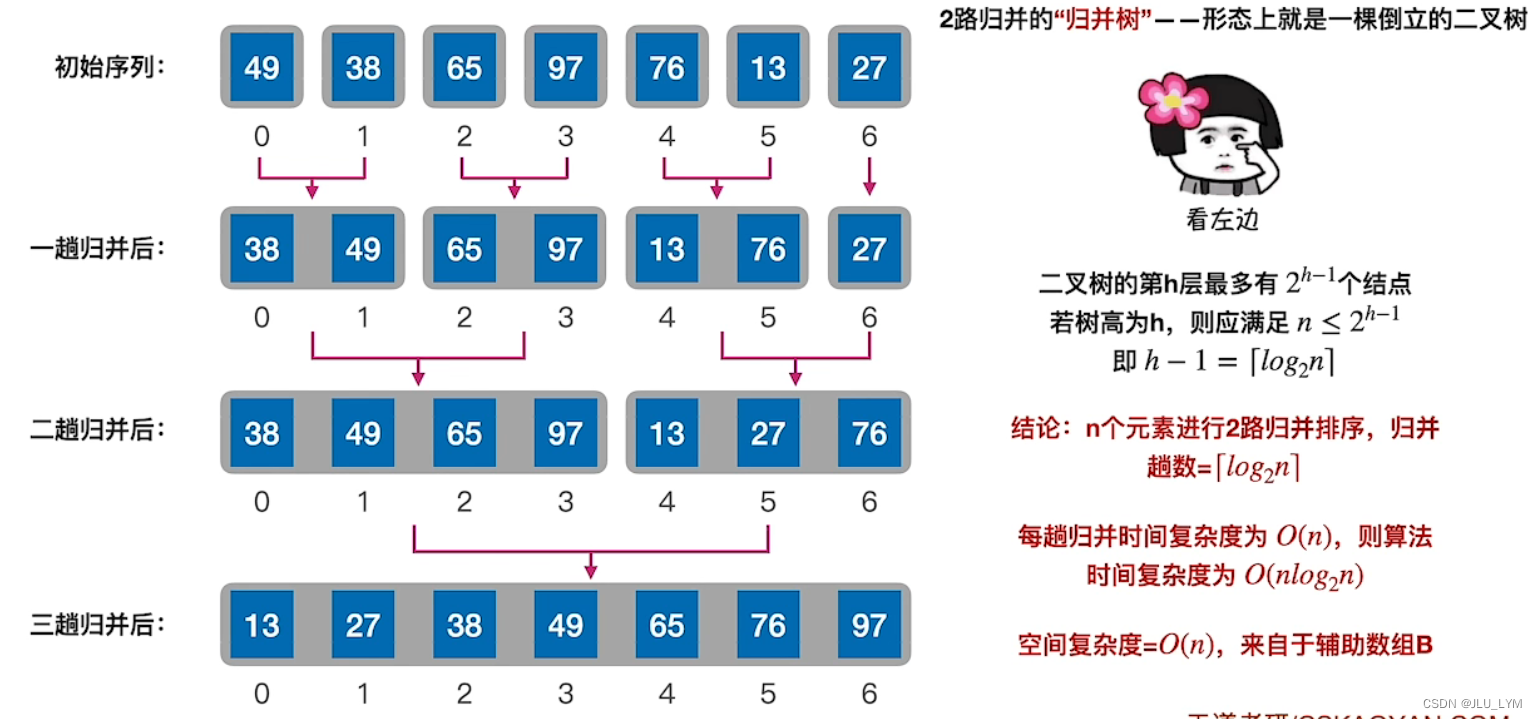

//都是升序排列
#include <iostream>
int item[100000];
int size;
class merge_sort {
public:
merge_sort() {
this->n = size;
for (int i = 0; i < n; i++) {
arrays[i] = item[i];
}
}
//归并排序
void mergeSort(int left, int right) {
if (left >= right) {//退出条件
return;
}
int mid = (left + right) / 2;
//因为归并是要把元素先打散成逐个的,再逐一合并,所以后根遍历法
mergeSort(left, mid);
mergeSort(mid + 1, right);
merge(left, mid, right);
}
void Print() {
for (int i = 0; i < n; i++) {
printf("%d ", arrays[i]);
}
}
private:
int arrays[100050];
int n;
//合并过程
void merge(int left, int mid, int right) {
int point = left;//指向原数组指针,指示下一个元素插入位置
int l = left;//左面子序列指针
int r = mid + 1;//右面子序列指针
int tmp[100050];//临时数组,用于记录当前子序列,帮助实现归并
for (int i = left; i <= right; i++) {//初始化
tmp[i] = arrays[i];
}
while (l <= mid && r <= right) {//两个小的子序列,每次比队头,因为是升序,所以谁小谁上
if (tmp[l] <= tmp[r]) {
arrays[point++] = tmp[l++];
}
else {
arrays[point++] = tmp[r++];
}
}
while (l <= mid) {//把剩下元素补齐
arrays[point++] = tmp[l++];
}
while (r <= right) {//把剩下元素补齐
arrays[point++] = tmp[r++];
}
}
};
int main(){
scanf("%d", &size);
for (int i = 0; i < size; i++)
{
scanf("%d", &item[i]);
}
merge_sort* ms = new merge_sort();
ms->mergeSort(0, size - 1);
ms->Print();
return 0;
}
算法性能分析:

<2>链表法的归并排序
总体思想:链表和数组有本质不同,链表无法像数组一样随机存取,所以不能用其指针移动表示的方法,但是链表由于是链式结构,拆分很方便,所以使用归并排序最本质的思路,拆分法,不断拆分出子链(结尾用nullptr标识),最后合并也是拿两条子链不断合并成一个完整的,也并未多余开出空间(因为串糖葫芦法)
#include <iostream>
#include <string>
#include <stack>
#include <queue>
#include <unordered_map>
#include <vector>
#include <algorithm>
using namespace std;
typedef struct node {//按照教材来,这里使用typedef
int val;
node* next;
}node;
//以left和right开头的小链表,结尾是nullptr
node* merge(node* left, node* right) {//这个函数就是把这两个链表串糖葫芦穿起来
//标识新的串的头部,哨兵节点,作为临时节点,最后去掉
node* head = new node(); //串糖葫芦的头
node* tail = head;//用于加入节点,串糖葫芦的线
//left right作为标识节点不可动
node *p1 = left, *p2 = right;//作用于其上的指示指针
//合并的思想和数组一致,方法为串糖葫芦
while (p1 != nullptr&&p2 != nullptr) {
if (p1->val <= p2->val) {//p1为目标
tail->next = p1;
tail = p1;
p1 = p1->next;
}
else {//p2为目标
tail->next = p2;
tail = p2;
p2 = p2->next;
}
}
while (p1 != nullptr) {
tail->next = p1;
tail = p1;
p1 = p1->next;
}
while (p2 != nullptr) {
tail->next = p2;
tail = p2;
p2 = p2->next;
}
tail->next = nullptr;//必须处理结尾,必须明确指向空
return head->next;//去掉哨兵
}
//递归函数,思想和数组版本的一致
//出口判定,不要她是空,在之前就退出
//中点判定,快慢指针法
//分划思想,同数组,也是后根遍历
node* mergesort(node* cur) {
//出口
if (cur->next == nullptr) {//只有自己一个的时候出口
return cur;
}
//准备快慢指针找中间节点
node *slow = cur, *fast = cur;
//用于标识中间节点位置,方便拆分字串(他作为左字串的末尾,fast作为右子串的末尾,cur作为左字串开头,slow作为右子串开头)
node *lefttail = slow;
while (fast != nullptr&&fast->next != nullptr) {
lefttail = slow;
slow = slow->next;
fast = fast->next->next;
}
lefttail->next = nullptr;
//后跟法
node* left = mergesort(cur);
node*right = mergesort(slow);
return merge(left, right);//把串好的串返回去
}
int main()
{
int a[7] = { 49, 38, 65, 97, 76, 13, 27 };
int n = 7;
node* head = (node*)malloc(sizeof(node));
node* tail = head;
for (int i = 0; i < n; i++)
{
node* tmp = (node*)malloc(sizeof(node));
tmp->val = a[i];
tail->next = tmp;
tail = tmp;
}
tail->next = NULL;
printf("排序前:\n");
for (node* it = head->next; it != NULL; it = it->next)
{
printf("%d ", it->val);
}printf("\n\n");
head->next = mergesort(head->next);
printf("排序后:\n");
for (node* it = head->next; it != NULL; it = it->next)
{
printf("%d ", it->val);
}
return 0;
}
5、基数排序
算法流程(注:基数排序关键字比较次数为0)

基数排序的操作为:

效率分析(吉大教材上计算时间复杂度时不考虑基数r,只算O(nd)):

基数排序不只是用于排序若干个数字,其思想也可以用于其他信息的排序
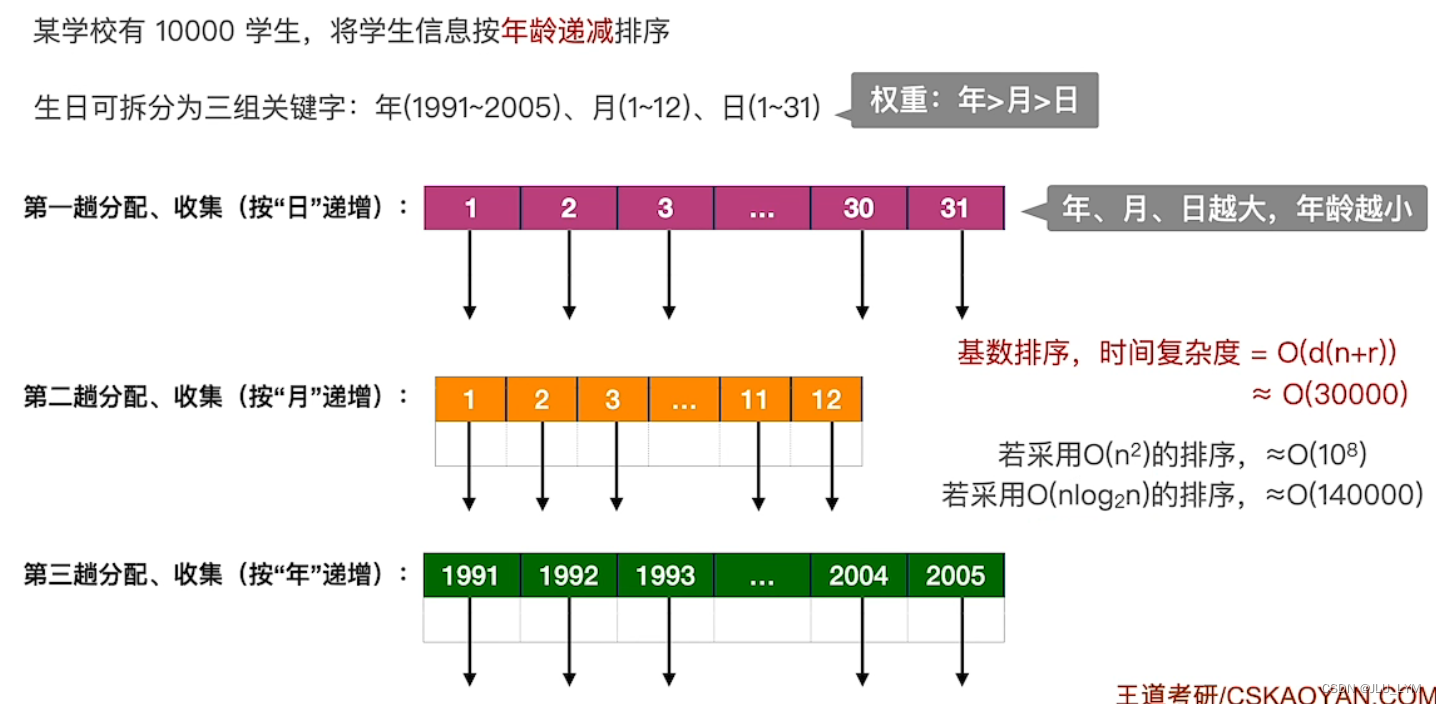
基数排序的适用情况:


6、计数排序
多次在专硕真题之中,以程序填空的形式出现,特此记录

count数组记录前面有几个比它大的(从1到n)
步骤:
1、初始化,count数组全置为1
2、从n开始,枚举n-1次,到2
3、针对每个i,都要向前看,谁更大,谁的count数组+1
<1>Kj>Ki,马上给count[J]++
<2>反之 ,马上给count[I]++

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











