







springboot依赖注入的方式
Bean的注入通常使用@Autowired注解,该注解用于bean的field、setter方法以及构造方法上,显式地声明依赖。
在最新的文档中注入方式有两大类:
基于构造函数的依赖注入(推荐使用)
基于setter的依赖注入
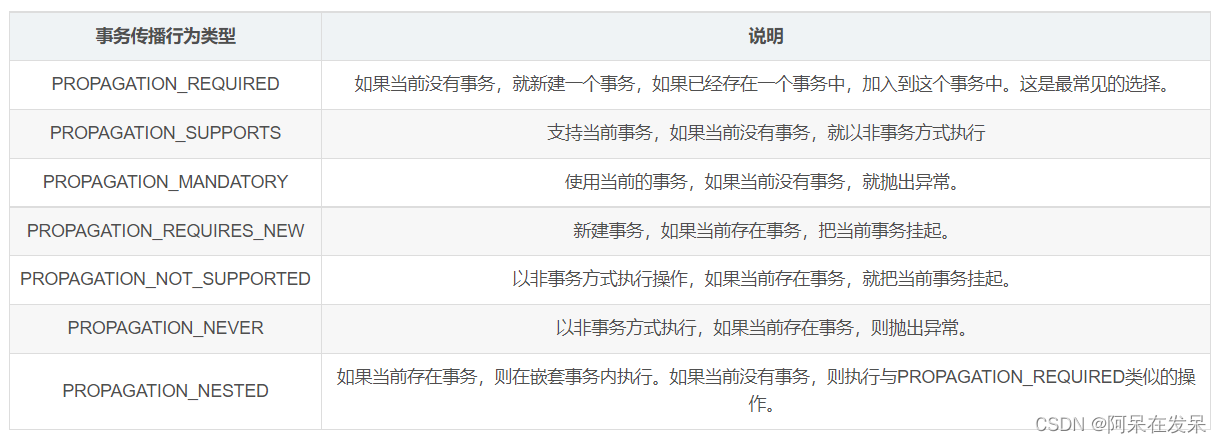
springboot事务传播机制
springboot的优缺点
优点:快速创建独立运行的Spring应用以及与主流框架集成
1.1. 使用嵌入式的Servlet容器,应用最终可以打成Jar包的形式独立运行。
1.2. 版本仲裁中心和不同的场景启动器为Spring Boot应用开发管理这不同的框架和版本依赖。
1.3. 约定大于配置,Spring Boot为开发者导入项目所使用的框架设置好了默认配置。
1.4. Java Config代替了原有难以管理的SpringXML配置。
1.5. 提供了准生产环境的运行时的应用监控。
1.6. 与云计算的天然集成,Spring Cloud相关框架技术。
缺点:Spring Boot的最大优点就是为开发者屏蔽了底层框架的复杂性。这样恰好是其缺点。Spring Boot降低了入门门槛,但是其封装使后期学习曲线陡峭。所以如果需要熟练的掌握该框架,必须了解其底层原理。依赖太多。
springboot自动装配原理
SpringBoot启动的时候会通过@EnableAutoConfiguration注解找到META- INF/spring.factories配置文件中的所有自动配置类,并对其进行加载,而这些自动配置类都是以AutoConf iguration结尾来命名的,它实际上就是一个JavaConfig形式的Spring容器配置类,它能通过以Properties结尾命名的类中取得在全局配置文件中配置的属性如: server .port,而XxxxProperties类是通 过@Confi gurationProperties注解与全局配置文件中对应的属性进行绑定的。
springboot如何配置redis
1.导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2.配置连接
编写yml
redis:
#数据库索引
database: 0
host: 127.0.0.1
port: 6379
password:
jedis:
pool:
#最大连接数
max-active: 8
#最大阻塞等待时间(负数表示没限制)
max-wait: -1
#最大空闲
max-idle: 8
#最小空闲
min-idle: 0
#连接超时时间
timeout: 10000
3.编写配置类
import org.springframework.cache.annotation.CachingConfigurerSupport;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
@EnableCaching
public class RedisConfig extends CachingConfigurerSupport {
@Bean(name = "redisTemplate")
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory){
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
//参照StringRedisTemplate内部实现指定序列化器
redisTemplate.setConnectionFactory(redisConnectionFactory);
redisTemplate.setKeySerializer(keySerializer());
redisTemplate.setHashKeySerializer(keySerializer());
redisTemplate.setValueSerializer(valueSerializer());
redisTemplate.setHashValueSerializer(valueSerializer());
return redisTemplate;
}
private RedisSerializer<String> keySerializer(){
return new StringRedisSerializer();
}
//使用Jackson序列化器
private RedisSerializer<Object> valueSerializer(){
return new GenericJackson2JsonRedisSerializer();
}
}
java线程的启动
1.继承Thread
2.通过runnable接口
3.通过Callable和Future创建线程
4.使用异步框架 CompletableFuture
5.线程池
thread.start()和run()有什么区别
start()
用 start方法来启动线程,是真正实现了多线程, 通过调用Thread类的start()方法来启动一个线程,这时此线程处于就绪(可运行)状态,并没有运行,一旦得到cpu时间片,就开始执行run()方法。但要注意的是,此时无需等待run()方法执行完毕,即可继续执行下面的代码。所以run()方法并没有实现多线程。
run()
run()方法只是类的一个普通方法而已,如果直接调用Run方法,程序中依然只有主线程这一个线程,其程序执行路径还是只有一条,还是要顺序执行,还是要等待run方法体执行完毕后才可继续执行下面的代码。
区别
1、线程中的start()方法和run()方法的主要区别在于,当程序调用start()方法,将会创建一个新线程去执行run()方法中的代码。但是如果直接调用run()方法的话,会直接在当前线程中执行run()中的代码,注意,这里不会创建新线程。这样run()就像一个普通方法一样。
2、另外当一个线程启动之后,不能重复调用start(),否则会报IllegalStateException异常。但是可以重复调用run()方法。
总结起来就是run()就是一个普通的方法,而start()会创建一个新线程去执行run()的代码。
说一说java常用集合
Collection 接口的接口 对象的集合(单列集合)
├——-List 接口:元素按进入先后有序保存,可重复
│—————-├ LinkedList 接口实现类,双向链表, 插入删除, 没有同步, 线程不安全
│—————-├ ArrayList 接口实现类,数组,随机访问,异步, 线程不安全
│—————-└ Vector 接口实现类 数组,线程同步, 线程安全(类方法有很多sychronized进行修饰)
│ ———————-└ Stack 是Vector类的实现类
└——-Set 接口: 仅接收一次,不可重复,并做内部排序
├—————-└HashSet 使用hash表(数组)存储元素
│————————└ LinkedHashSet 链表维护元素的插入次序,内部通过LinkedHashMap来实现
└ —————-TreeSet 底层实现为二叉树,元素排好序
Map 接口 键值对的集合 (双列集合)
├———Hashtable 接口实现类, 同步, 线程安全,数组+列表
├———HashMap 接口实现类 ,没有同步, 线程不安全,可以null为key(聊了聊hashmap底层
│—————–├ LinkedHashMap 双向链表和哈希表实现
│—————–└ WeakHashMap
└ ——–TreeMap 红黑树对所有的key进行排序、
说一说有哪些线程安全的集合类
Vector
Vector 是 jdk1.0 的古老集合类,该类对大部分方法都加上了 synchronized 关键字,用来保证线程安全。
CopyOnWriteArrayList
CopyOnWrite 容器即写时复制的容器。往一个容器添加元素的时候,不直接往当前容器Object添加。
而是先将当前容器 Object[] 进行复制,复制一个新的容器 Object[] newElement 并往其中里添加元素,添加完元素之后,再将原容器的引用指向新的容器 setArray(new Element) 。
这样做的好处是可以对 CopyOnWrite 容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite 容器也是一种读写分离的思想,读和写不同的容器。
ConcurrentHashMap
mysql索引的优缺点
一、索引的优点
1)创建索引可以大幅提高系统性能,帮助用户提高查询的速度;
2)通过索引的唯一性,可以保证数据库表中的每一行数据的唯一性;
3)可以加速表与表之间的链接;
4)降低查询中分组和排序的时间。
二、索引的缺点
1)索引的存储需要占用磁盘空间;
2)当数据的量非常巨大时,索引的创建和维护所耗费的时间也是相当大的;
mysql的优化
mybatis #{}和${}的区别
#相当于对数据 加上 双引号,$相当于直接显示数据。
1、#对传入的参数视为字符串,也就是它会预编译,select * from user where name = #{name},比如我传一个csdn,那么传过来就是 select * from user where name = ‘csdn’;
2、$ 将不会将传入的值进行预编译,select * from user where name=${name},比如我传一个csdn,那么传过来就是 select * from user where name=csdn;
3、#的优势就在于它能很大程度的防止sql注入,而$ 则不行。比如:用户进行一个登录操作,后台sql验证式样的:select * from user where username=#{name} and password = #{pwd},如果前台传来的用户名是“wang”,密码是 “1 or 1=1”,用#的方式就不会出现sql注入,而如果换成$方式,sql语句就变成了 select * from user where username=wang and password = 1 or 1=1。这样的话就形成了sql注入。
4、MyBatis排序时使用order by 动态参数时需要注意,用$而不是#
模糊查询中的%和_的区别
%的作用,代表任意长度(长度可以为0)的字符串例如a%b表示以a开头,以b结尾的任意长度的字符串
_(下横线)的作用:代表任意单个字符















 186
186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









