









中国传媒大学一直是我向往的高校,但是众所周知中国传媒大学研究生录取是十分不透明的,复试参考资料、往年真题、报录比等等都不公开,官网的研究生录取名单是图片形式的,无法直接用网页搜索工具查找数据,但我们可以利用OCR技术提取里面的信息数据。41张图片一张一张OCR是不现实的,我们需要使用百度提供的api批量OCR,再进行正则匹配就能得到想要的数据了。
- 打开百度人工智能网站:百度智能云
登陆之后创建项目,项目信息随便填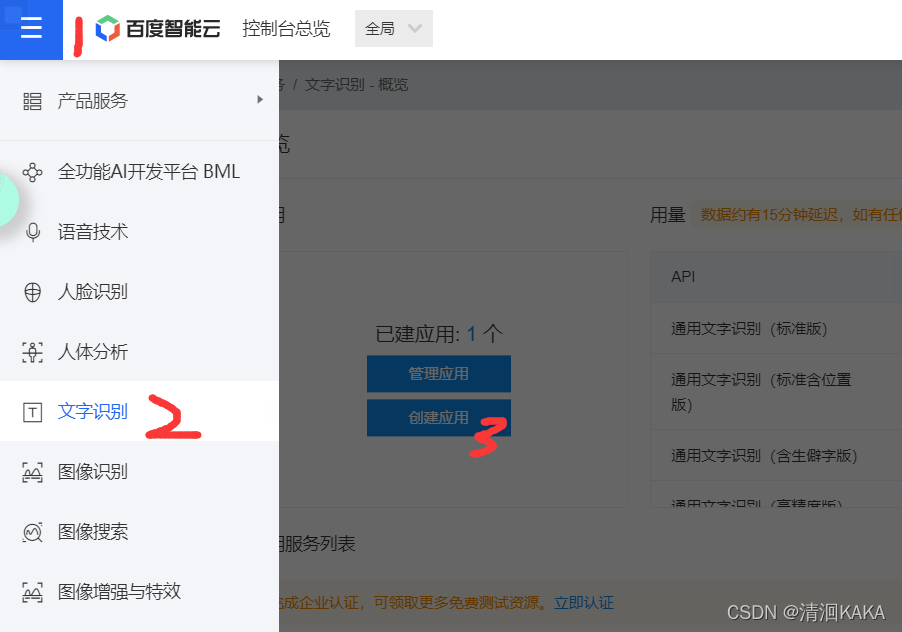
- 领取免费调用额度
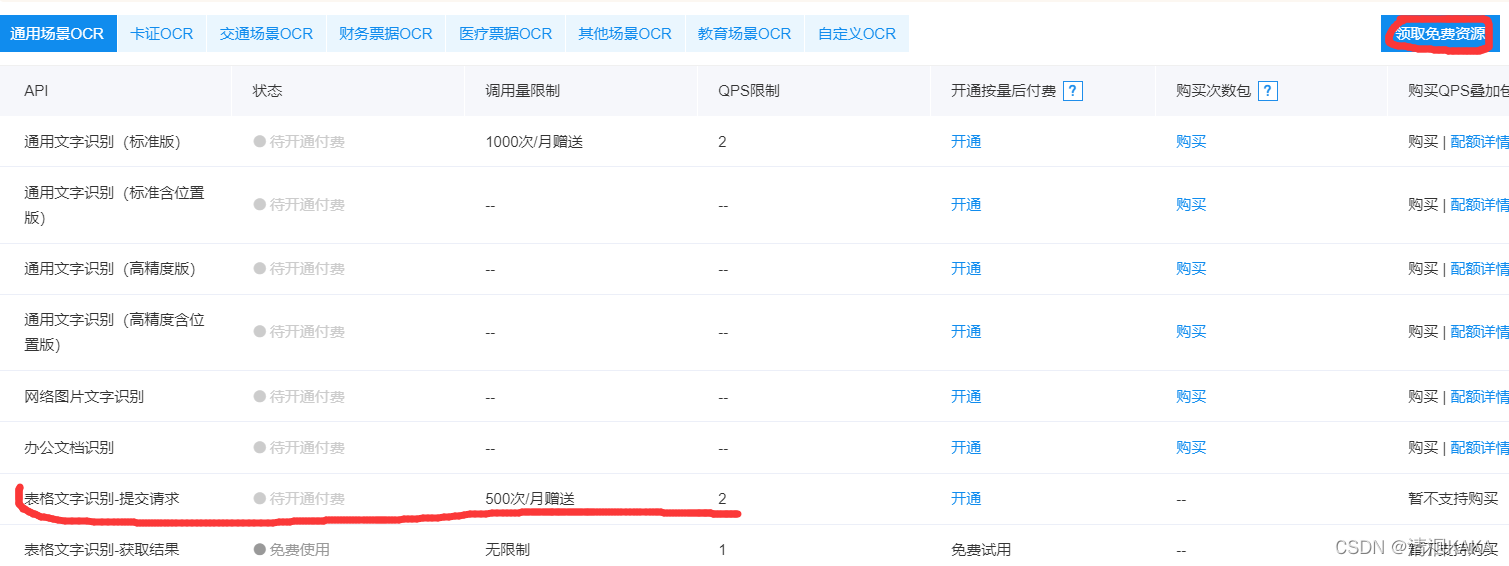
因为录取名单是表格类型的,领取表格文字识别接口就行了,每月有500次 - 记录下百度调用api的信息
| AppID | API Key | Secret Key |
|---|
点击管理应用-保存好这三个值,代码中要用

-
在Python中安装库:baidu-aip
这个库anaconda里没有,需要用pip install baidu-aip -
将图片批量重命名
用图片下载器下载好官网:中传研招网 的图片后,批量重命名,能加序号后缀,方便编程 -
用Python批量OCR识别表格,并导出为Excel
# 从相应的aip导入AipOcr模块
from aip import AipOcr
import time
import urllib.request
#根据url下载文件
# 输入凭证
APP_ID = "xxx"
API_Key = "xxx"
Secret_Key = "xxx" #xxx为你之前记录下的信息
aipOcr = AipOcr(APP_ID, API_Key, Secret_Key)
# 输入资源
filePath = r"D:\360极速浏览器下载\拟录取名单"
for i in range(1, 42):
filePath1 = filePath + "\\yan (" + str(i) +").png"
image = open(filePath1, "rb").read()
table = aipOcr.tableRecognitionAsync(image)
# 调用表格识别模块识别图片
request_id = table['result'][0]['request_id']
#获取表格处理结果
result = aipOcr.getTableRecognitionResult(request_id)
# 若处理状态是“已完成”,获取下载地址
while result['result']['ret_msg'] != '已完成':
time.sleep(4) # 暂停4秒再刷新
result = aipOcr.getTableRecognitionResult(request_id)
download_url = result['result']['result_data']
#print(download_url)
# 根据图片名字命名表格名称
xls_name = filePath1.split(".")[0] + ".xls"
# 导出excel文件
urllib.request.urlretrieve(download_url,xls_name)
#转到R
这里导出Excel最好是使用urllib库,不要直接使用requests库,格式可能会不兼容。运行完会得到每张图片所对应的表格
OCR表格大概长这样: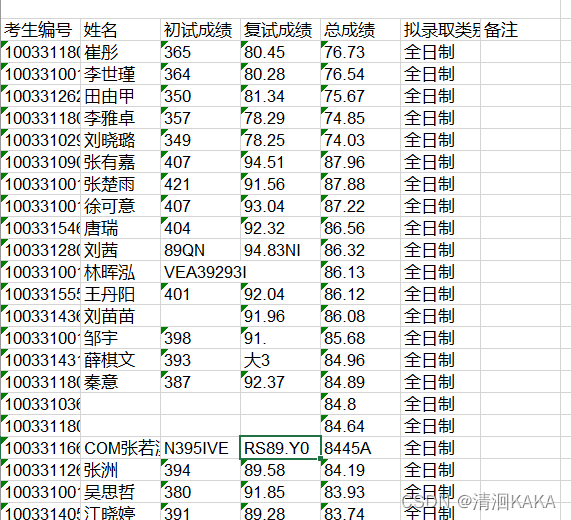
因为图片中央有中传的大LOGO,所以中间部分数据识别会不准,这很正常,但不必找原图修改,因为考生编号仍然还是完整的,大部分数据不会被筛选到,一个个修改会很浪费时间,完善方法见下。
- 用R语言合并数据,导出到Excel
library(readxl)
# 设置工作空间
setwd('D:/360极速浏览器下载/拟录取名单/')
# 读取该工作空间下的所有文件名
filenames <- dir()
# 通过正则,获取所有xls结尾的文件名
filenames2 <- grep('.xls', filenames, value = TRUE)
# 初始化数据框,用于后面的数据合并
data3 <- data.frame()
#通过循环完成数据合并
for (i in filenames2){
# 构造数据路径
path <- paste0('D:/360极速浏览器下载/拟录取名单/',i)
# 读取并合并数据
data2 <- read_xls(path = path,sheet='body',skip=1,col_names = TRUE)
data2$index <- i
data3 <- rbind(data3,data2)
}
write.csv(data3, file="D:/录取名单.csv",row.names = FALSE)
这里我新增了一列index,用来指明数据来自哪一张图片,方便当我们最终筛选的数据有问题时再检查图片。
关于为什么要突然换到R语言处理,这是因为R语言做数据预处理比python更方便,另外OCR的结果可能会导致表格出现错位等,合并时会报错列数不匹配,用R语言可以设置断点方便查找哪一个表格有问题。其次作为一名数据分析师用R语言和python结合使用很常见。最后,
一定程度上防止某些考研机构做一些抄袭等不良商业行为。
得到的录取总名单如下: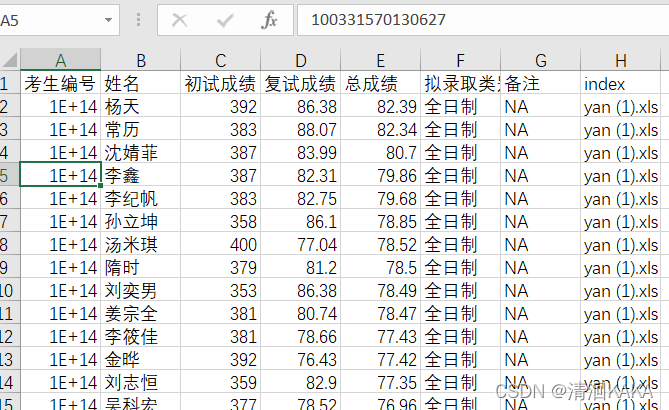
- 最后回到python,用正则匹配获取数据并导出
import re
import pandas as pd
with open(r'D:\录取名单.csv', encoding="gbk") as file:
data = pd.read_csv(file)
pat = "^10033[0-9]{4}07"
c=data['考生编号'].astype(str).apply(lambda x:re.match(pat,x))
d=data.loc[c.notnull(),:]
d.to_csv(r'D:\学院录取名单.csv', index=False, encoding="gbk")
10033是中传编号,07是学院号,但是具体是哪个学院并不知道,而且从往年数据分析,这个学院号每年都会变化的,所以还是适合等今年录取名单公布了再根据自己的编号来比对
- 最后,其实还有一些详细的数据分析还没做,等我先准备复试考上了再说,如果没考上的话,那这篇文章就到这里了

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











