








第一章 大模型简介
1.大语言模型 LLM 理论简介
| 开源地址 | 是否可使用 | |
|---|---|---|
| ChatGPT 使用地址 | ||
| Claude 使用地址 | ||
| PaLM 官方地址 | ||
| Gemini 使用地址 | ||
| 文心一言使用地址 | ||
| 星火大模型使用地址 | ||
| LLaMA 官方地址 | LLaMA 开源地址 | |
| 通义千问使用地址 | 通义千问开源地址 | |
| ChatGLM 使用地址 | ChatGLM 开源地址 | |
| 百川使用地址 | 百川开源地址 |
2.检索增强生成 RAG 简介
新的模型架构:检索增强生成(RAG, Retrieval-Augmented Generation):
整合了从庞大知识库中检索到的相关信息,并以此为基础,指导大型语言模型生成更为精准的答案,从而显著提升了回答的准确性与深度。
RAG 是一个完整的系统,其工作流程可以简单地分为数据处理、检索、增强和生成四个阶段:
| 阶段 | ||
|---|---|---|
| 数据处理阶段 | 对原始数据进行清洗和处理。 将处理后的数据转化为检索模型可以使用的格式。 将处理后的数据存储在对应的数据库中。 | |
| 检索阶段 | 将用户的问题输入到检索系统中,从数据库中检索相关信息。 | |
| 增强阶段 | 对检索到的信息进行处理和增强,以便生成模型可以更好地理解和使用。 | |
| 生成阶段 | 将增强后的信息输入到生成模型中,生成模型根据这些信息生成答案。 |

在提升大语言模型效果中,RAG 和 微调(Finetune)是两种主流的方法。
微调: 通过在特定数据集上进一步训练大语言模型,来提升模型在特定任务上的表现。
3.LangChain
LangChain 框架:帮助开发者们快速构建基于大型语言模型的端到端应用程序或工作流程。

LangChain 框架是一个开源工具,充分利用了大型语言模型的强大能力,以便开发各种下游应用。它的目标是为各种大型语言模型应用提供通用接口,从而简化应用程序的开发流程。具体来说,LangChain 框架可以实现数据感知和环境互动,也就是说,它能够让语言模型与其他数据来源连接,并且允许语言模型与其所处的环境进行互动。
每个椭圆形代表了 LangChain 的一个模块`,例如数据收集模块或预处理模块。`每个矩形代表了一个数据状态
| 模块表示 | |
|---|---|
| 每个椭圆形代表了 LangChain 的一个模块 | 例如数据收集模块或预处理模块 |
每个矩形代表了一个数据状态 | 例如原始数据或预处理后的数据 |

LangChain 的核心组件
LangChian 作为一个大语言模型开发框架,可以将 LLM 模型(对话模型、embedding 模型等)、向量数据库、交互层 Prompt、外部知识、外部代理工具整合到一起,进而可以自由构建 LLM 应用。
LangChain 主要由以下 6 个核心组件组成: (在开发过程中,可以根据自身需求灵活地进行组合。)
- 模型输入/输出(Model I/O):与语言模型交互的接口
- 数据连接(Data connection):与特定应用程序的数据进行交互的接口
- 链(Chains):将组件组合实现端到端应用。比如后续我们会将搭建
检索问答链来完成检索问答。 - 记忆(Memory):用于链的多次运行之间持久化应用程序状态;
- 代理(Agents):扩展模型的推理能力。用于复杂的应用的调用序列;
- 回调(Callbacks):扩展模型的推理能力。用于复杂的应用的调用序列;
LangChain 的生态
- LangChain Community: 专注于第三方集成,极大地丰富了 LangChain 的生态系统,使得开发者可以更容易地构建复杂和强大的应用程序,同时也促进了社区的合作和共享。
- LangChain Core: LangChain 框架的核心库、核心组件,提供了基础抽象和 LangChain 表达式语言(LCEL),提供基础架构和工具,用于构建、运行和与 LLM 交互的应用程序,为 LangChain 应用程序的开发提供了坚实的基础。我们后续会用到的处理文档、格式化 prompt、输出解析等都来自这个库。
- LangChain CLI: 命令行工具,使开发者能够通过终端与 LangChain 框架交互,执行项目初始化、测试、部署等任务。提高开发效率,让开发者能够通过简单的命令来管理整个应用程序的生命周期。
- LangServe: 部署服务,用于将 LangChain 应用程序部署到云端,提供可扩展、高可用的托管解决方案,并带有监控和日志功能。简化部署流程,让开发者可以专注于应用程序的开发,而不必担心底层的基础设施和运维工作。
- LangSmith: 开发者平台,专注于 LangChain 应用程序的开发、调试和测试,提供可视化界面和性能分析工具,旨在帮助开发者提高应用程序的质量,确保它们在部署前达到预期的性能和稳定性标准。
4.开发 LLM 应用的整体流程
| 大模型开发 | 以大语言模型为功能核心、通过大语言模型的强大理解能力和生成能力、结合特殊的数据或业务逻辑来提供独特功能的应用(更多为工程问题) |
| 将大模型作为一个调用工具,通过 Prompt Engineering、数据工程、业务逻辑分解等手段来充分发挥大模型能力,适配应用任务。要掌握使用大模型的实践技巧 | |
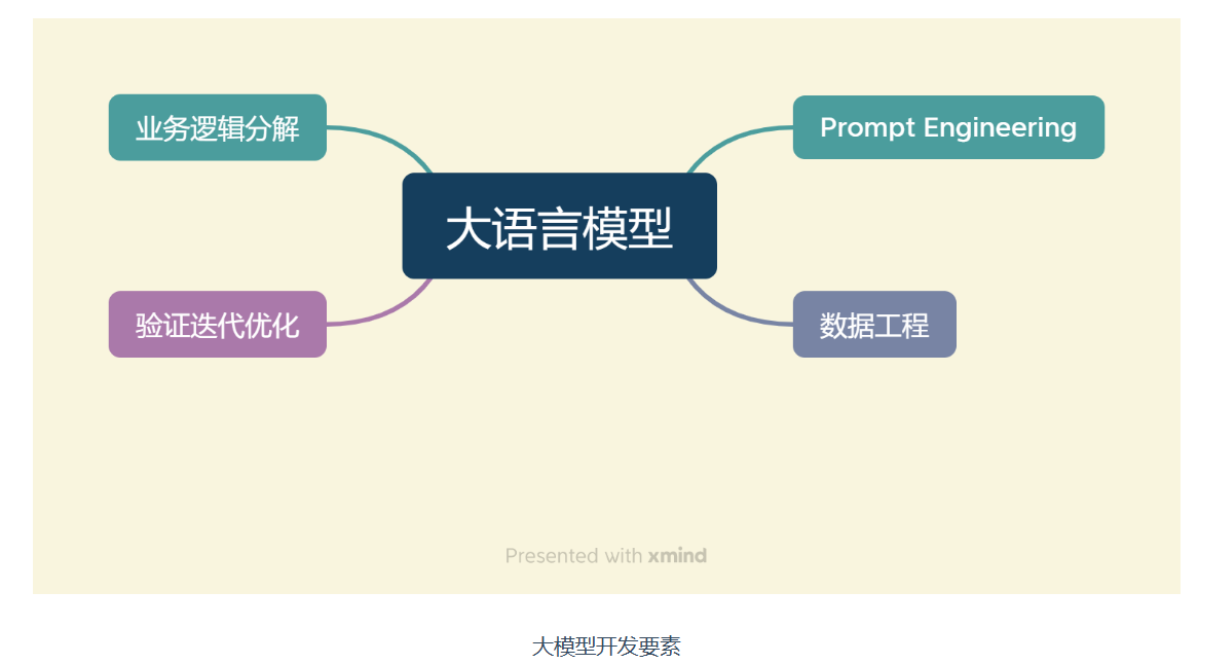 | |
大语言模型的两个核心能力:指令遵循与文本生成。 |
传统的 AI 开发:将业务逻辑依次拆解 —>构造训练数据与验证数据 —> 每一个子业务训练优化模型 —> 形成模型链路解决业务。大模型开发:用 Prompt Engineering 来替代子模型的训练调优 —> 通过 Prompt 链路组合来实现业务逻辑 —> 用一个通用大模型 + 若干业务 Prompt 来解决任务。(更简单、轻松、低成本的 Prompt 设计调优)
在评估思路上,大模型开发与传统 AI 开发的差异。
-
传统 AI 开发:需要首先构造训练集、测试集、验证集。训练集 训练模型 测试集 调优模型 验证集 验证模型效果来实现性能的评估 -
大模型开发:从实际业务需求出发构造小批量验证集,设计合理 Prompt 来满足验证集效果。然后,不断收集当下 Prompt 的 Bad Case 并加入到验证集中,针对性优化 Prompt,最后实现较好的泛化效果。

大模型开发的一般流程
将大模型开发分解为以下几个流程:
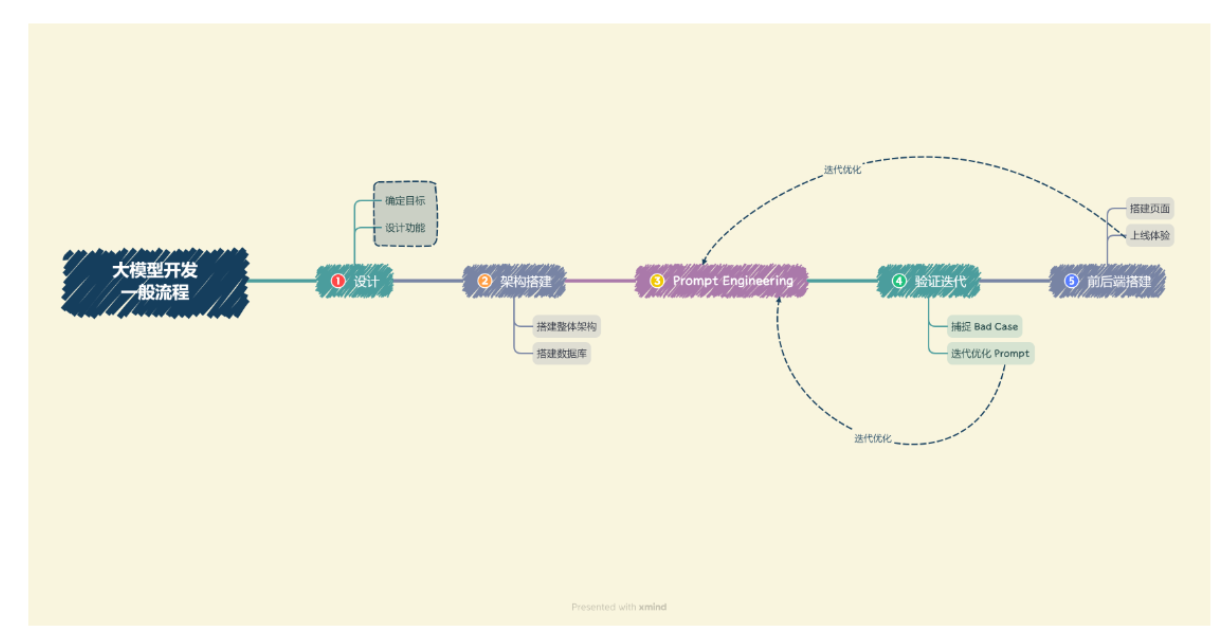
-
确定目标。在进行开发前,我们首先需要确定开发的目标。
(对于个体开发者或小型开发团队而言,一般应先设定最小化目标,从构建一个 MVP(最小可行性产品)开始,逐步进行完善和优化。)
-
设计功能。在确定开发目标后,需要设计本应用所要提供的功能,以及每一个功能的大体实现逻辑。
-
搭建整体架构。目前,绝大部分大模型应用都是采用的特定数据库 + Prompt + 通用大模型的架构。
(一般来说,推荐基于 LangChain 框架进行开发。LangChain 提供了 Chain、Tool 等架构的实现,我们可以基于 LangChain 进行个性化定制,实现从用户输入到数据库再到大模型最后输出的整体架构连接。)
-
搭建数据库。个性化大模型应用需要有个性化数据库进行支撑。
(由于大模型应用需要进行向量语义检索,一般使用诸如 Chroma 的向量数据库。在该步骤中,收集数据并进行预处理,再向量化存储到数据库中。数据预处理一般包括从多种格式向纯文本的转化,例如 PDF、MarkDown、HTML、音视频等,以及对错误数据、异常数据、脏数据进行清洗。完成预处理后,需要进行切片、向量化构建出个性化数据库。)
-
Prompt Engineerin:逐步迭代构建优质的 Prompt Engineering 来提升应用性能。
(明确 Prompt 设计的一般原则及技巧,构建出一个来源于实际业务的小型验证集,基于小型验证集设计满足基本要求、具备基本能力的 Prompt。)
-
验证迭代。验证迭代在大模型开发中,一般指通过不断发现 Bad Case 并针对性改进 Prompt Engineering 来提升系统效果、应对边界情况。
(在完成后,应该进行实际业务测试,探讨边界情况,找到 Bad Case,并针对性分析 Prompt 存在的问题,从而不断迭代优化,直到达到一个较为稳定、可以基本实现目标的 Prompt 版本。)
-
前后端搭建。完成 Prompt Engineering 及其迭代优化之后,我们就完成了应用的核心功能,可以充分发挥大语言模型的强大能力。(接下来我们需要搭建前后端,设计产品页面,我们可以采用 Gradio 和 Streamlit,可以帮助个体开发者迅速搭建可视化页面实现 Demo 上线。)
-
体验优化。在完成前后端搭建之后,应用就可以上线体验了。
(接下来就需要进行长期的用户体验跟踪,记录 Bad Case 与用户负反馈,再针对性进行优化即可。)
总结
学习了一下大模型的基本概念和流程,以及如何构建大模型,但感觉还欠缺一下实践,希望通过下面的学习能更加深入的理解上文的构造流程。
学习出自datawhale: https://datawhalechina.github.io/llm-universe/#/















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









