







进程的同步与互斥
什么是进程同步?
之前的文章我们有提到过操作系统的四大特性有一个是异步,异步就是进程的执行时间是不可预测,走走停停,以不可预知的速度向前推进的。那么这个异步性会导致一个问题,假设有进程A负责读,进程B负责写,那么由于异步性的存在,进程A可能先B一步到达缓冲区,此时缓冲区无数据,A就会阻塞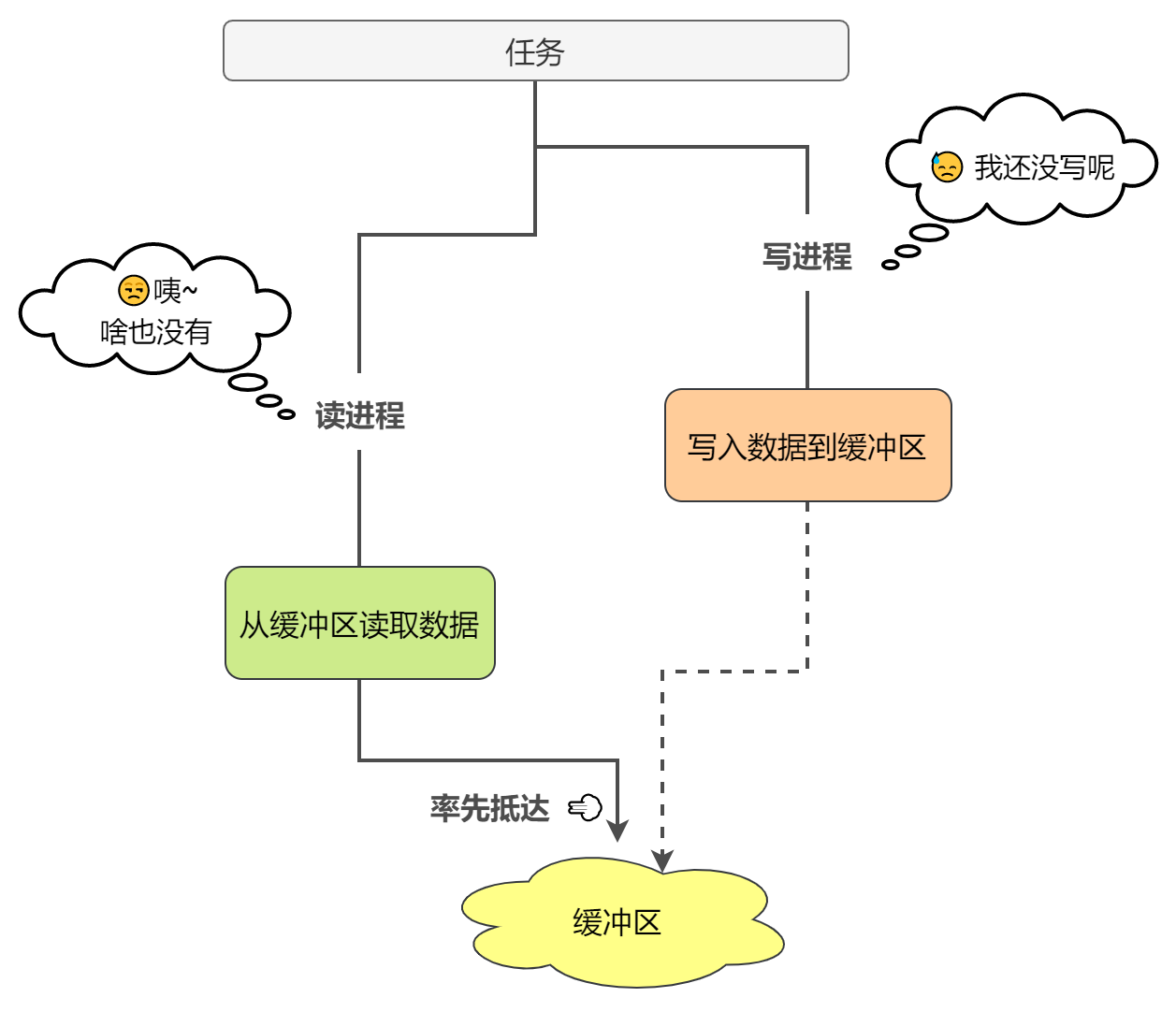
那么这时候我们需要一种机制来保证A一定发生在B之后,这就是进程同步要做的事情了,我们知道系统中的进程是相互作用的,一个进程的执行可能会影响到别的进程,进程同步就是指协调这些完成某个共同任务的并发进程,在某些时刻指定线程的先后执行次序,传递信号或信息。
那么同步和异步的区别就在于:进程是否有序执行
进程同步和进程调度不是一样的,注意不要弄混!
- 进程调度是为了最大程度的使用CPU资源,选用合适的调度算法调度队列中的进程
- 进程同步是为了协调并发进程来完成一个共同任务,指定这些进程的先后顺序
什么是进程互斥?
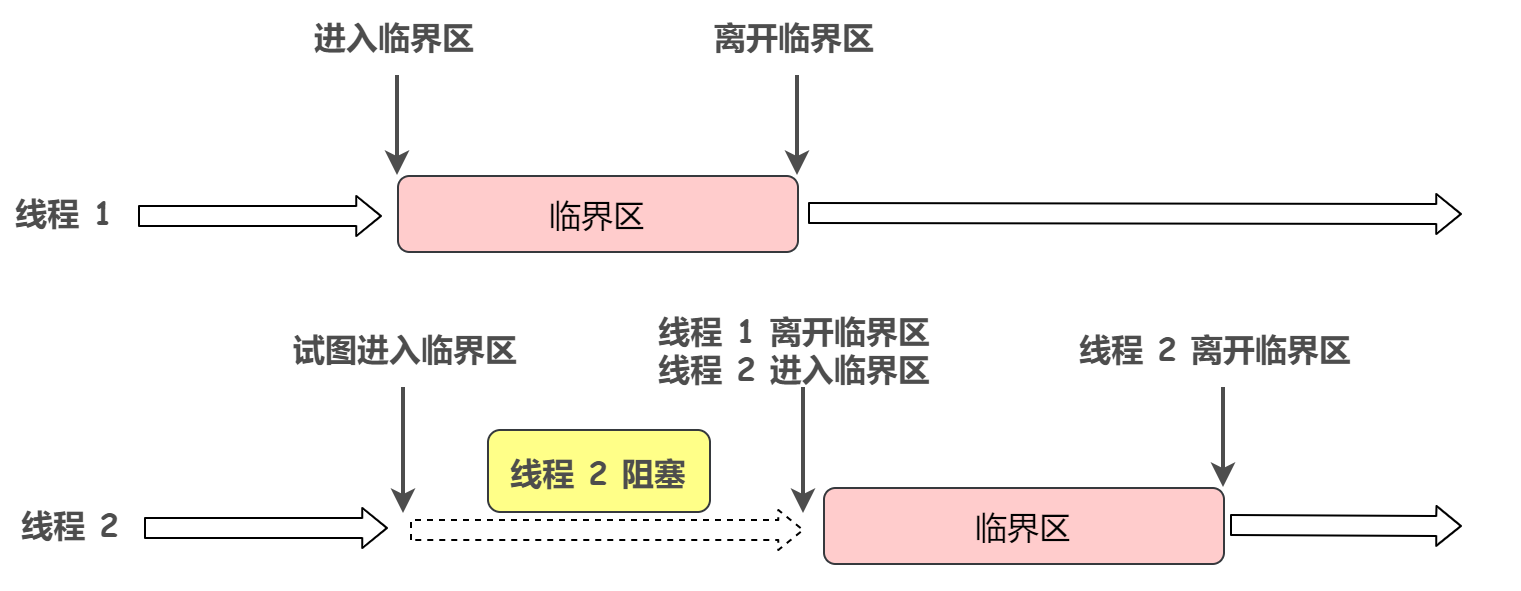
还是举个例子,同时刻你的QQ和微信都有人给你打来语音电话,那么你能在接通qq电话之后再接通微信电话吗?答案是否定的,由于进程间的并发性,我们需要共享一些系统资源,但是有些资源在同一时刻只允许一个进程使用,那么怎么完成这件事,就需要依靠进程互斥了
进程互斥就是协调并发进程使用临界资源的先后次序
进程互斥就是一种特殊的进程同步(临界资源就是在一个时间段内只允许一个进程使用的资源)
 常见的互斥和同步机制
常见的互斥和同步机制
1.信号量和PV操作
2.管程
信号量与PV操作
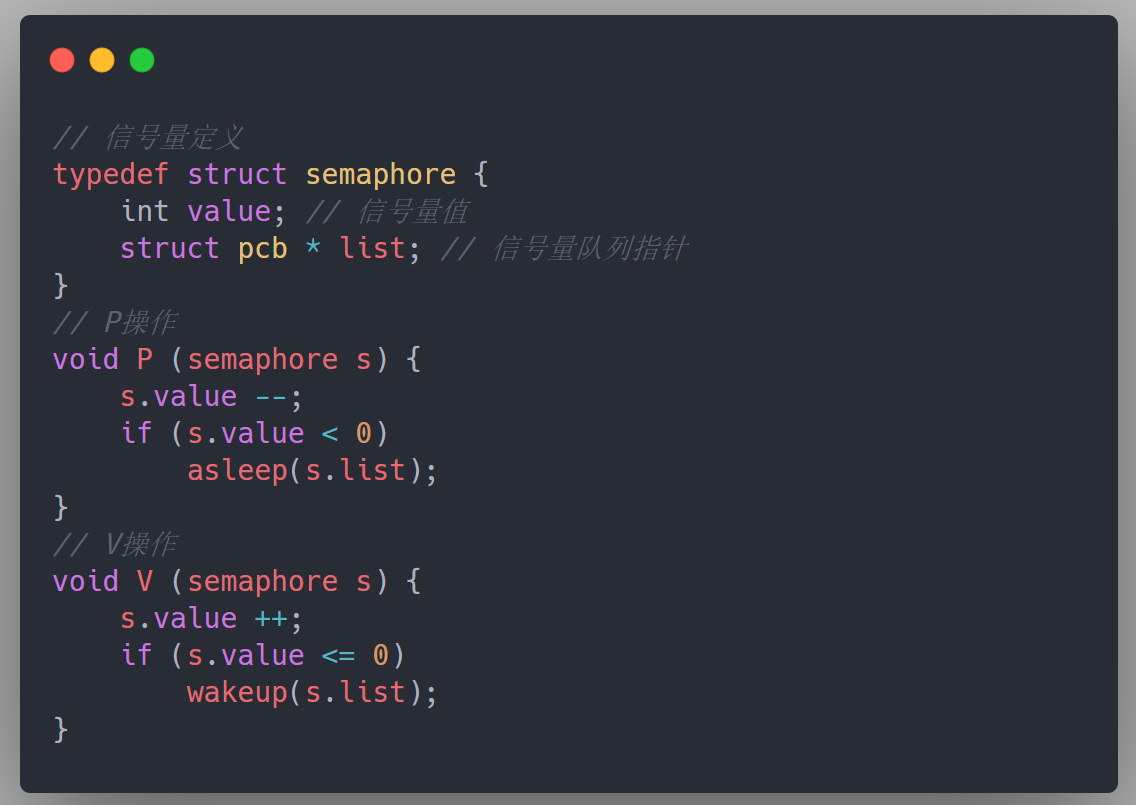
进程通过操作系统提供一对原语来对信号量进行操作,从而很方便的实现进程互斥和进程同步,这一对原语就是PV操作
1.P操作——将信号量减1,表示申请占用一个资源。如果结果小于0,表示无可用资源,执行P操作的进程阻塞,大于0则代表资源充足,继续执行
2.V操作——将信号量加1,表示释放一个资源,如果加完之后信号量的值小于1,代表此时仍有某些阻塞进程在等待该资源,唤醒对应的阻塞进程,令它转换成就绪态
通俗的理解,就是当信号量的值为2时,表示有两个资源可用,当信号量为-2时,代表有两个阻塞进程在等待资源
问:当信号量大于0表示有临界资源可用使用,这时候为什么不唤醒进程?
唤醒进程是从阻塞队列里找到对应进程唤醒,但是信号量大于0时代表有临界资源可供使用,阻塞队列为空,不需要唤醒,正常运行即可
问:当信号量的值为0时表示没有临界资源可用,为什么仍需唤醒进程?
进程执行V操作时会给信号量加1,代表释放1个资源,那么加1之前信号量为-1,代表有1个进程在阻塞队列中等待该资源,所以需要唤醒。
用PV操作实现进程互斥
1.定义一个信号量为1
2.将对临界资源的访问代码放在PV操作之间

PV操作和阻塞-唤醒原语一样是成对出现的,缺少P就不能保证对临界资源的互斥访问,缺少V就无法释放临界资源,阻塞进程无法唤醒
实现进程同步
我们已经知道进程同步就是协调并发进程按一定次序执行
举例——有两个进程P1,P2并发执行,由于存在异步性,二者的执行时间是不可预测的。假设我们要求P2的代码4要基于P1的代码1和代码2的结果才能继续执行,那么我们就要保证代码4一定要在代码1和2之后执行

进程同步三步走
- 定义一个同步信号量,并初始化为当前可用资源的数量
- 在优先级较高的进程后面执行V操作,代表释放资源
- 在优先级较高的进程前面执行P操作,代表申请占用资源(一般都会阻塞)
生产者消费者模型
下面来运用PV操作解决经典的进程同步和互斥问题——生产者消费者模型
问:系统中有一组生产者进程和一组消费者进程,生产者进程每次生产一个产品放入缓冲区,消费者进程每次从缓冲区中取出一个产品并使用。任何时刻,只能有一个生产者或消费者可以访问缓冲区。
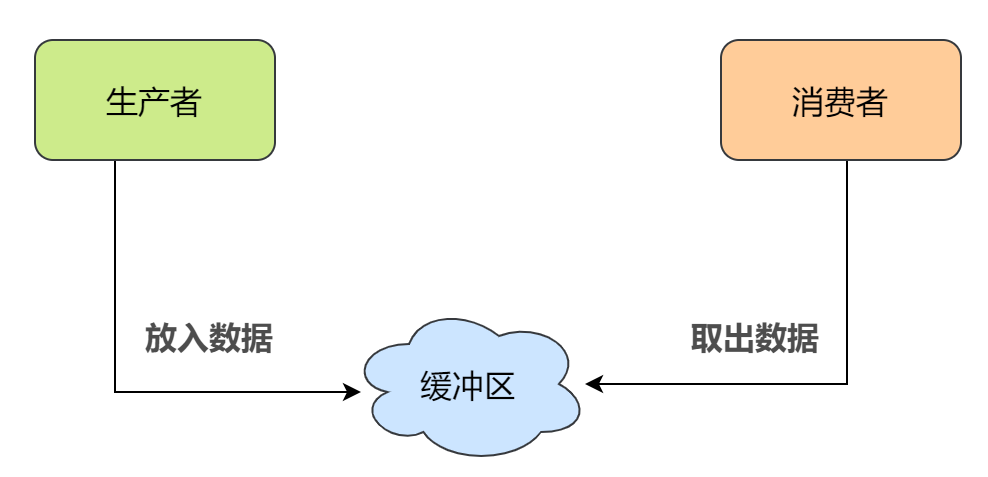
分析:我们知道生产者和消费者共享一个大小为n,初始为0的临界资源——缓冲区,我们提炼一下其中的同步-互斥信息
- 同步关系1:只有缓冲区未装满时(优先级高),生产者才可以把产品放进缓冲区,否则必须等待
- 同步关系2:只有当缓冲区不为空时(优先级高),消费者才能取产品,否则必须等待
- 同步关系3:假设缓冲区为空,那么消费者必须在生产者后面运行
- 互斥关系:同一时间只能有一个进程访问缓冲区

操作系统六大进程通信机制总结
进程通信,就是进程之间的信息交流,实际上,进程的同步和互斥也是一种进程通信(注意同步互斥和通信都有信号量),只不过同步互斥传递的仅仅是信号量,通过修改信号量使进程之间建立联系,但是同步互斥缺少的是传递数据的能力
而进程通信就是来解决这个问题的,进程之间需要传递大批量数据的时候,使用进程通信
如果从操作系统层面看,由于每个进程都是相互独立的,一个进程不可以直接访问另一个进程的地址空间,但是内核态的进程是共享的,所以进程通信发生必须通过内核。
进程通信机制总共有6种
- 管道
- 消息队列(也叫消息传递)
- 共享内存
- 信号量和PV操作(同步互斥)
- 信号
- 套接字(socket)
管道
$command1 | command2以上这行代码就是形成了一个管道,“|”就是我们创建的一个匿名管道,这行代码的功能时将前一个命令1的输出,作为命令2的输入,我们可以看出管道中的数据只能单向流动,即半双工通信,如果想实现全双工通信,需要有两个管道
而且注意一点,“|”只能在父子进程中使用,也就是说管道只能用于父子进程之间的通信,而且用完就自动销毁。
那我们如何使用管道实现全双工通信呢
int pipe (int fd[2]);我们使用pipe来创建两个管道,成功返回0,失败返回-1
现在我们创建了一个存储空间为2的文件描述符数组
fd[0]——指向管道的读端
fd[1]——指向管道的写端,其输出是fd[0]的输入
1.父进程创建两个管道
2.父进程fork一个子进程,子进程也会继承父进程的资源,子进程也有哦两个管道
3.父进程关闭管道1的读端和管道2的写端,子进程关闭管道1的写端和管道2的读端,保证管道1只能父进程写,子进程读,管道2只能父进程读,子进程写,这样就实现了全双工通信
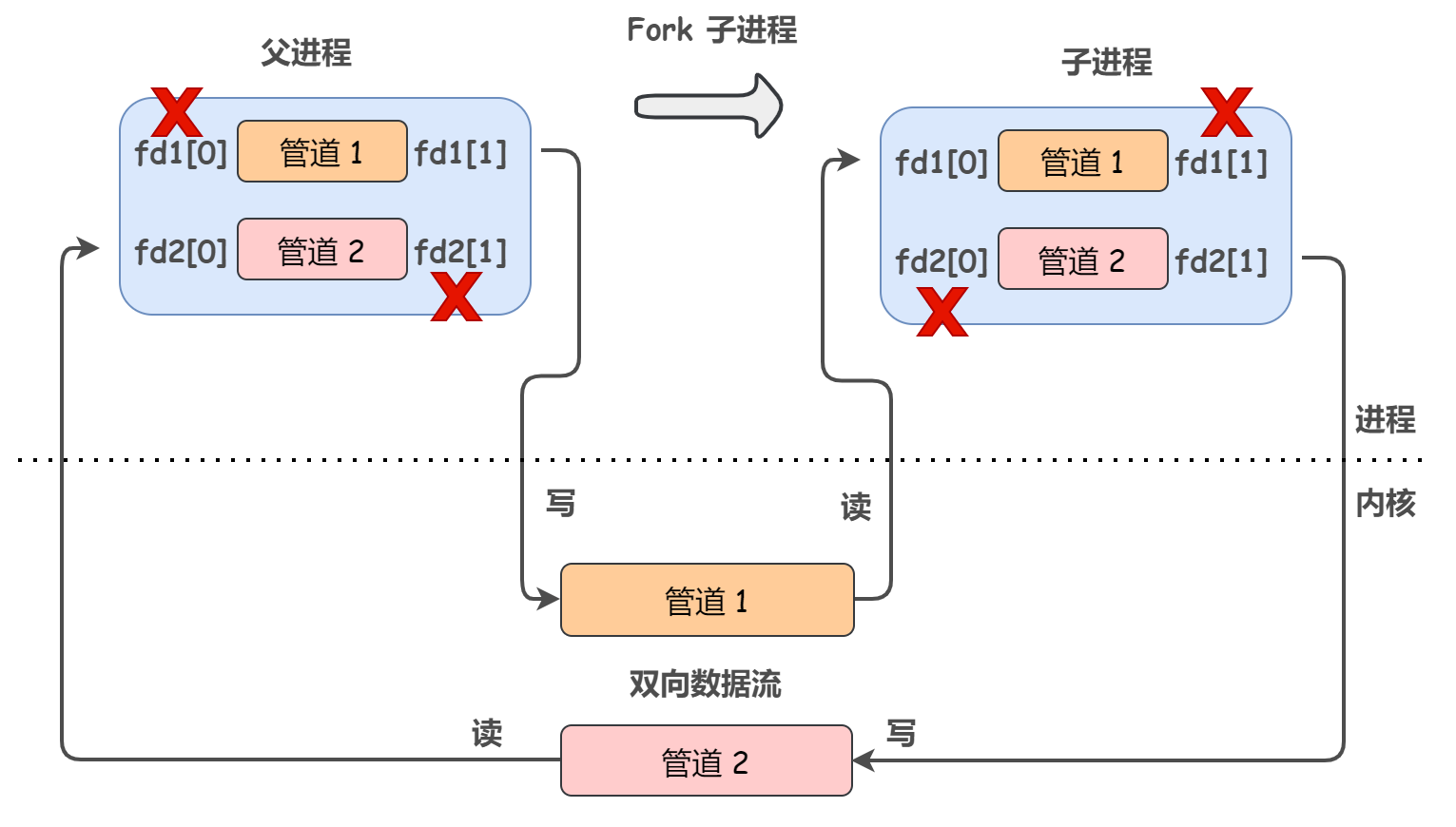
管道的本质其实就是一个内核在内存中开辟的一个缓冲区,这个缓冲区和管道文件相关联,对管道文件的操作,被内核转换成对这块缓冲区的操作。
有名管道
匿名管道由于没有名字,只能用于父子进程之间的通信,为了克服这个缺点,提出了有名管道,也称作FIFO,因为数据是先进先出的传输形式。
所谓的有名管道就是提供一个路径名与之相关联,这样即使不是父子进程,只要可以访问该路径,就可以实现相互通信
使用Linux命令来创建有名管道——mkfifo
$ mkfifo myPipemyPipe就是我们创建的管道名字,接下来可以写入数据
$ echo "first pipe" > myPipe执行完上述命令你会发现它就停止了,这是因为我们只是完成了数据的写入,我们写入了数据,不可缺少的肯定是读取数据了
$ cat < myPipe执行完这条命令,就会返回myPipe里的数据,然后退出
消息队列
我们可以看出,管道这种通信方式虽然很简单,但致命的缺点就是效率太低,不适合进程间频繁的交换数据,而且管道只能传输无格式的字节流。为此提出了消息队列。
比如说进程A要给进程B发送消息,只要把数据放在对应的消息队列之后返回即可,不需要得到B的响应,进程B在需要的时候自行去消息队列读取数据即可,反过来也是一样
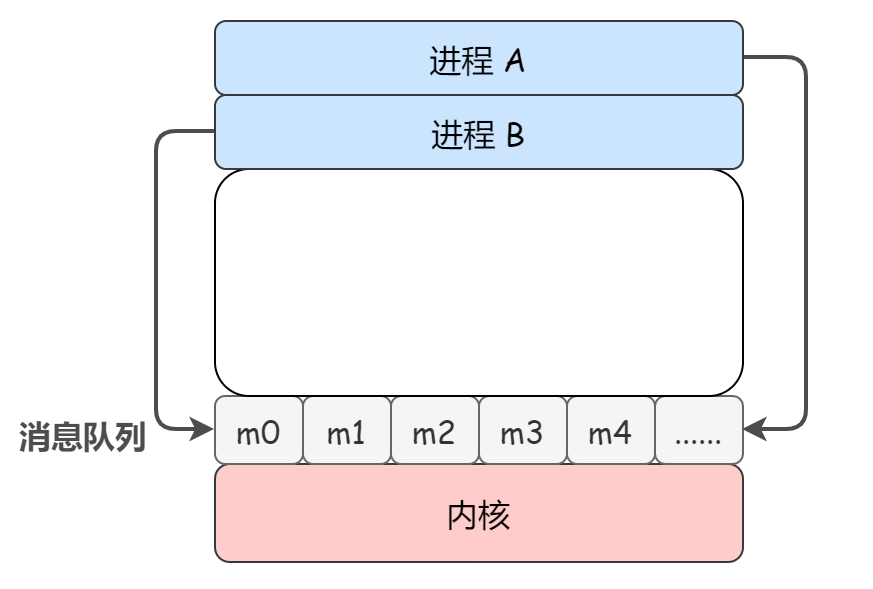
(感觉和进程队列有点像,运行进程释放CPU之后,CPU会去就绪队列里挑选优先级最高的进程转换成运行态)
消息队列的本质就是存放在内存中的消息的链表,消息本质上是用户自己定义的数据结构。如果某个进程从消息队列读取了一个消息,这个消息就会从消息队列中删除
消息队列的生命周期——随内核,如果没有释放消息队列或者关闭操作系统,消息队列一直存在,而管道的生命周期随进程的创建而建立,进程销毁而销毁
但是消息队列也不是完美的,消息队列仅在数据量较小的时候很有用,举个例子,当用户进程写入数据到消息队列时,会发生从用户态拷贝数据到内核态的消息队列里,当用户读取数据时,又要从内核里拷贝数据到用户态,如果数据交换频繁,就要在内核态和用户态之间频繁切换,进程上下文切换太多就会造成系统开销太大。
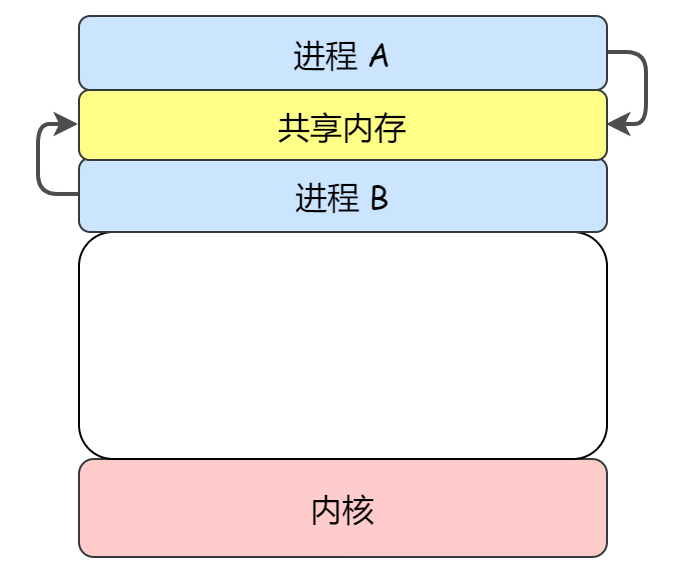
共享内存
为了解决消息队列无法胜任大数据量交换,那么此时又提出了共享内存,顾名思义,共享内存就是允许不相干的进程将同一段物理内存连接到他们各自的内存空间里,使得这些进程可以访问同一个物理内存,这个物理内存就是共享内存。如果有某个进程向共享内存中写入某个数据,同一时间共享内存里的所有其他进程都会受到影响。
我们来解释一下共享内存的原理——每个进程都有自己的PCB和逻辑地址空间,并且都有一个页表,记录着逻辑地址映射的对应物理地址,并且受CPU的mmu管理。两个不同的进程通过页表映射到同一区域的物理地址,这个区域就是共享内存。
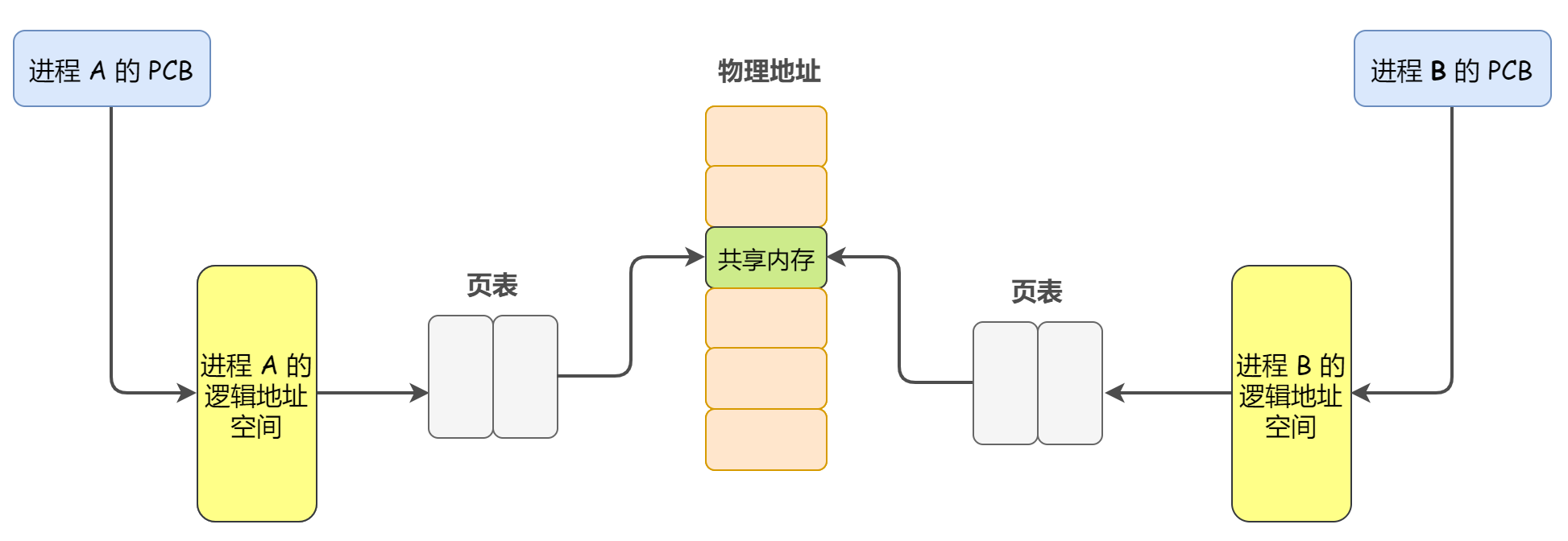
不同于消息队列频繁的系统调用和上下文切换,共享内存机制仅在初次建立共享内存时需要系统调用,一旦建立完成,所有的访问都会视作常规访问,无需借助内核。共享内存时最快的进程通信方式。
信号量和PV操作
但是基于多核CPU的研究发现,多核CPU的消息队列的性能其实比共享内存更好,因为消息队列无需避免冲突,而共享内存机制却有可能发生冲突,也就是说如果多个进程同时修改一个共享内存,先来的进程写的内容可能被后面的进程覆盖
那么其实这就是进程的同步和互斥的内容,因为我们要保证共享内存不发生冲突,就要实现进程的同步(进程按一定次序先后对共享内存进程操作),所以信号量和PV操作其实是一种对进程通信的保护机制,并不是用来传输进程之间通信的数据的,但是由于他们涉及到了信号量的传输,所以也将其归为进程通信,称为低级通信。
(这部分具体内容相信看过进程同步与互斥的应该就不用过多赘述了。。。)
信号
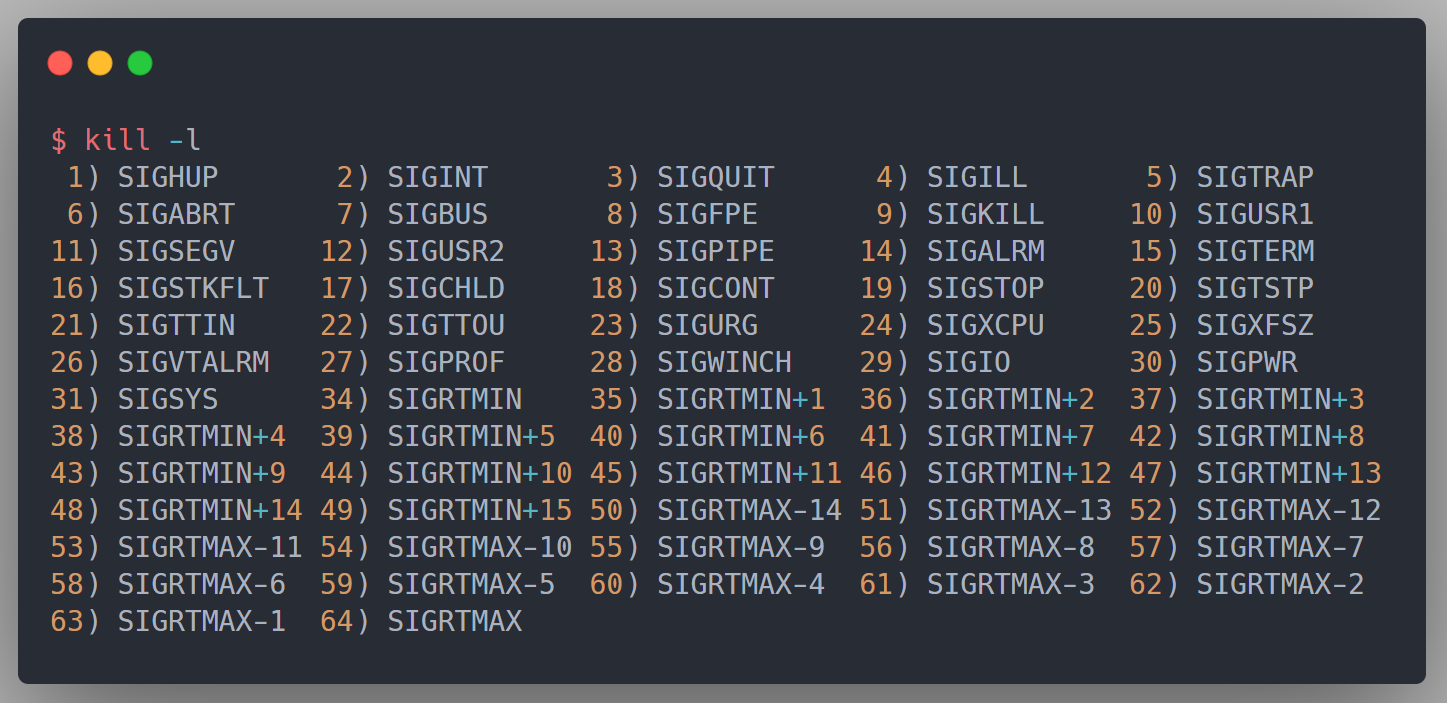
信号和信号量虽然仅一字之差,但是却是完全不一样的两个东西,信号是进程通信机制中唯一的异步通信机制,它可以在任何时候发送信号给某个进程,通过发送指定信号来通知进程某个异步时间的发送,以迫使进程执行信号处理程序,信号处理完毕之后,被中断程序恢复执行(感觉和中断差不多),用户,内核和进程都可以生成和发送信号
信号来源有硬件来源和软件来源,硬件来源一般就是键盘或者别的I/O设备输入,软件来源就是我们的cmd命令窗口输入kill -9 1111,表示给pid 1111的进程发送sigkill信号,立即结束该进程。Linux查看信号的命令为
Socket(套接字)
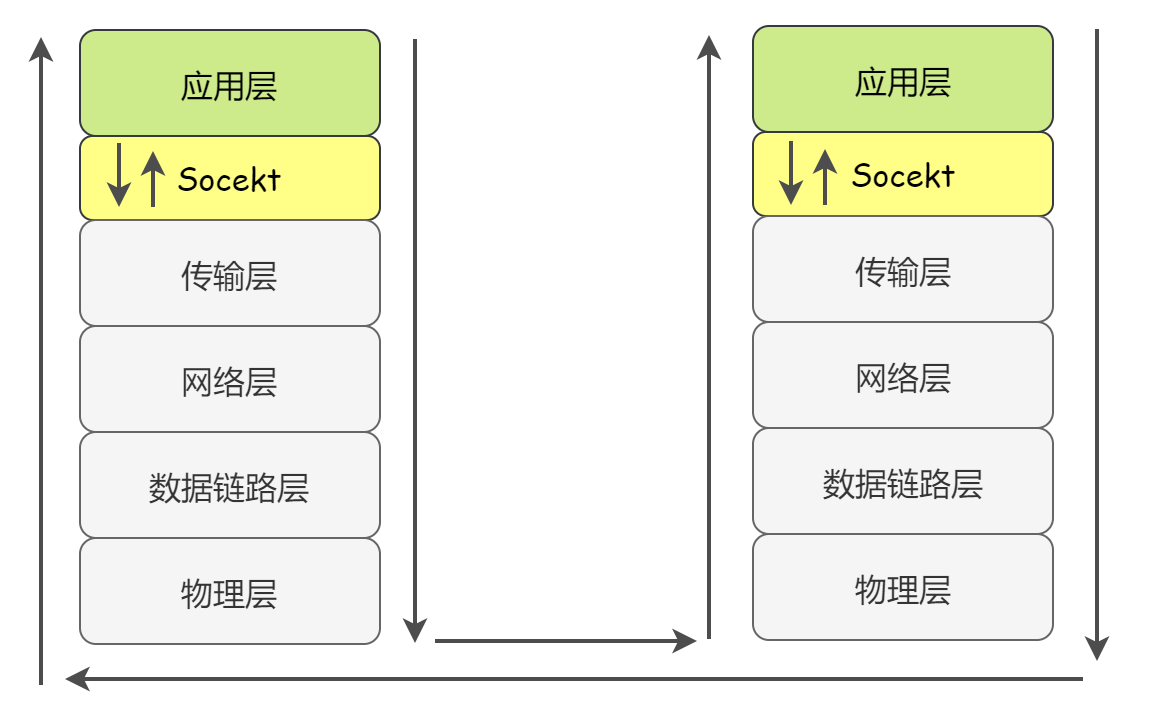
以上介绍的方法都是基于一台主机上的进程通信,那我们要实现跨主机通信该怎么办呢,这就是socket通信的任务了
从计算机网络层面来说,Socket 套接字是网络通信的基石,是支持 TCP/IP 协议的网络通信的基本操作单元。它是网络通信过程中端点的抽象表示,包含进行网络通信必须的五种信息:连接使用的协议,本地主机的 IP 地址,本地进程的协议端口,远地主机的 IP 地址,远地进程的协议端口。
socket的本质是编程接口(API),是应用层与TCP/IP协议族之间通信的中间软件抽象层,它对TCP/IP协议进行了封装,把复杂的TCP/IP协议族封装在socket接口后,对用户来说,只需要调用简单的挨批就可以实现socket通信。
总结
- 最简单的通信方式是管道,管道的本质是存放在内存中的特殊的文件,就是在内存中开辟了一个缓冲区,与管道文件相关联,对管道文件的操作,被操作系统转换成了对内存中的缓冲区的操作。管道又分为匿名和有名管道,匿名管道只允许父子进程之间的通信,有名管道则无限制
- 为了解决管道效率低下,不适合进程频繁的通信且只能传输无格式字节流,提出了消息队列机制, 消息队列的本质是存放在内存中的消息的链表,消息的本质是用户自定义的数据结构,进程从消息队列中读取某个消息,这个消息就从消息队列中删除
- 消息队列虽然可以频繁交换数据,但是数据量过大时,系统的开销也很大,所以提出了共享内存机制,共享内存就是两个进程不同的逻辑地址映射到同一区域的物理地址,这个区域就是我们的共享内存。用户进程向共享内存写入数据,这个改动会立即影响到可以访问这个共享内存的所有进程,而且对于共享内存来说,仅在初次建立共享内存的时候才需要系统调用,后面的所有访问都当做常规访问,不需要内核参与。
- 共享内存虽然速度快,开销小,但是在多核CPU系统里,有可能会出现进程冲突问题,先访问的进程写入的数据可能被后面的进程所覆盖,这时就需要引入信号量和PV操作保证进程通信的安全
- 信号和信号量是完全不同的两个概念,信号是进程通信唯一的异步通信机制,它可以在任意时刻发送信号给某个进程。通过发送信号来通知某个异步事件的发送,迫使进程执行信号处理程序,处理完毕后进程才能恢复执行。(用户,内核,进程都可以发送信号)
- 以上5种都是同主机的进程通信,要实现跨主机通信,需要借助socket,它本质是一个API接口,将TCP/IP协议封装在socket接口下,用户只需要简单的调用就可以实现跨主机进程通信。















 1662
1662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









