






1.组合两个表

思路
我们可以看到题目说明Person表的主键是PersonId,而Address的主键是AddressId,而且Address表里也同样包含PersonId,因此可以得出一个结论,PersonId是Address表的外键,因此我们只需要使用PersonId字段将两个表连接即可
select FirstName, LastName, City, State
from Person left join Address
on Person.PersonId = Address.PersonId;
2.查找第二高的薪水

思路
要查找排名第二高的薪水,首先我们肯定要做的事情——排序
然后排序之后如何取到第二高的数据呢?我们可以把查询结果当成一个排好序的数组,第二高的薪水肯定就是索引1位置处的薪水了,并且我们只选取一条数据,所以可以写出sql语句——limit 1,1
特殊情况
1.只有一条数据的时候,输出null
2.如果有多个人的工资一样,我们还需要去重,所以需要使用distinct salary
select ifnull(
(select distinct salary
from Employee
order by salary desc
limit 1,1),null
)as SecondHighestSalary;
3.超过经理收入的员工

思路
题目仅仅给出了一张表,但是却需要比较经理和员工的工资,那么我们肯定要想到自连接join(不使用left join或者right join是因为有可能有null情况,还需要进行去null操作,而join就不需要),那么可以看作是一张员工表记录了员工和经理的信息(a),还有一张特殊的员工表记录经理的信息(b)
所以可以写出下述sql语句
select a.name from Employee as a
join Employee as b
on a.ManagerId=b.Id
where a.Salary>b.Salary
4.查找重复的电子邮箱

思路
仅仅是需要找出重复的电子邮箱,不需要去重,其实很简单,我们只需要找出哪些邮箱出现的次数大于1即可
group by(Email)——统计每个邮箱出现的次数
having count(Email)>1——找出数量大于1的邮箱
sql语句
select Email from Person
group by (Email)
having count(Email)>1
5.从不订购的客户

思路
题目给出了一张客户信息表和订单表order,要我们找出从来没有订购过的客户,其实就是找出Id不在order表里面的客户,所以我们需要做的事情很简单
sql语句
select a.name as 'Customers' from Customers as a
where a.Id not in
(
select CustomerId from Orders
)
6.删除重复的电子邮箱

思路
在前面我们已经知道如何查找重复的邮箱,那么要删除重复的邮箱其实也很简单,就是使用delete语句删除行记录即可
sql语句
1.
delete p1 from Person as p1
Inner join Person as p2
on p1.email=p2.email && p1.Id>p2.Id
delete p1 from Person p1,Person p2
where p1.email=p2.email
and p1.Id>p2.Id
其实这两种解法(1.内连接Inner Join)或者第二种解法的大概过程都是一样的,就是把Person表复制两份,然后将p1表中的每条记录逐条和p2中的记录比较,这样当遇到email相等但是Id不一致的时候,就可以删除p1中的记录了
7.每个部门工资最高的员工

思路
首先要找出部门工资最高的员工名字,我们一定要找出两个必要信息
1.部门 2.每个部门最高工资是多少
我们查询得到的信息有部门名字,员工名字,最高工资
所以我们必须要对员工表和部门表进行一个连接,使用DepartmentId作为连接字段
sql语句
select
Department,name as 'Department',
Employee.name as 'Employee',
Salary
from Employee
join Department
on Department.Id=Emloyee.DepartmentId
where (Emloyee.DepartmentId,Salary) in
(
select DepartmentId,max(Salary)
from Employee
group by(DepartmentId)
)
--and Department.name is not Null--
注意点
使用join不需要进行null情况的排查,如果是使用left/right join,还需要在where语句后面加一句and Department.name is not Null
8. 第N高的薪水

思路:
这道题目和第二高的薪水的题目很类似,只不过这次我们需要找的是第N高的薪水了,那么我们要找第N高,那么肯定前面有N-1比它更高的薪水
1.由于MySQL里面是按照索引来排序的,所以索引0就是第一高的薪水,那么索引N-1就是第N高的薪水了,但是我们使用Limit语句时是不允许以
limit N-1,1
这种形式书写的,所以我们首先要将N设置为N-1
set N:=N-1;
2.接下来就基本和求第二高薪水的写法一样
select salary
from employee
group by salary
order by salary desc
limit N,1;
整体代码
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
set N:=N-1;
RETURN (
select Salary
from employee
group by (Salary)
order by Salary desc
limit N,1
);
END
9.分数排名

三大排序函数
1、ROW_NUMBER()
排序的数值连续并且不重复,即使两个数据查询出来的数值一样大,但是序号是不同的(1-2-3-4)
select *,row_number() OVER(order by number ) as row_num
from num
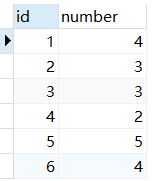
使用row_number()函数
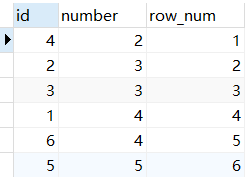
二、rank()
使用rank()函数在查询两个大小相等的数据时,得到的排名是相同的,并且排名会进行累加(1-2-2-4)
select *,rank() OVER(order by number ) as row_num
from num
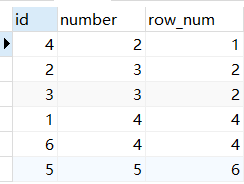
三、dense_rank()
dense_rank()查询大小相等的数据时排名也是一样的,但是和rank()不同的时dense_rank()不会对排名进行累加(1-2-2-3)
select *,dense_rank() OVER(order by number ) as row_num
from num
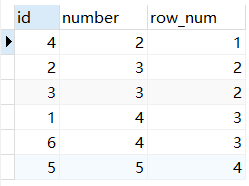
本题目应该使用dense_rank(),代码如下
select Score,dense_rank() over(order by Score desc) as 'rank'
from Scores;
10.查询至少连续出现三次的数字


思路
1)至少连续出现3次,那么这些数字不仅要相等,并且id还得是连续的才行,所以我们使用logs关键字判断三个数字是否连续并且相等
(Tips:这列的Logs不是sql关键字,是要查询表的名称,l1是表别名,将logs在此查询中改名为l1的意思)
假设我们从l1里取Id=1的数字,那么就会从l2中取Id=2的数字,从l3中取Id=3的数字来进行逐条比较,假设是连续4次出现,5次出现也是一样的套路
2)要判断id连续,那么l1表的Id肯定和l2表中的Id-1相等并且l1.Num=l2.Num,表3和表2的判断也是一样的套路
sql语句
select distinct l1.Num as ConsecutiveNums
from
logs l1,
logs l2,
logs l3
where
l1.Id=l2.Id-1
and l1.Num=l2.Num
and l2.Id=l3.Id-1
and l2.Num=l3.Num;
11.部门工资前三高的所有员工


思路
我们首先回顾一下count函数和distinct函数
1)count(字段名) ——返回表中该字段总共有多少条记录
2)DISTINCT 字段名——过滤字段中的重复记录
1.我们要找出前三高的工资,首先就要找到薪水至少不能比3个人低的薪水
select e1.Salary
from Employee as e1
where 3>(
select count(distinct e2.Salary)
from Employee as e2
where e2.Salary>e1.Salary
and e2.DepartmentId=e1.DepartmentId
)
举个例子
e1=e2=[4,5,6,7,8]
1)e1.Salary=4,符合条件的e2.Salary=[5,6,7,8],count(distinct e2.Salary)=4
所以4可以排除——rank=5
2)e1.Salary=5,符合条件的e2.Salary=[6,7,8],count(distinct e2.Salary)=3
所以5也可以排除——rank=4
3)e1.Salary=6,符合条件的e2=[7,8],count(distinct e2.Salary)=2,6符合
4)e1.Salary=7,符合条件的e2=[8],count(distinct e2.Salary)=1,7符合
5)e1.Salary=8,符合条件的e2=[],count(distinct e2.Salary)=0,8符合
所以最后我们查询出来的结果就是[6,7,8]
**2)**但是上述的例子仅仅针对一个部门,但是这道题有两个部门,所以我们还需要把Employee表和Department表连接一下再做查询
整体代码
select d.Name as 'Department',e1.Name as 'Employee',e1.Salary
from
Employee as e1
join
Department as d
on d.Id=e1.DepartmentId
where 3>(
select count(distinct e2.Salary)
from Employee as e2
where e1.Salary<e2.Salary
and e1.DepartmentId=e2.DepartmentId
)
order by Department,Salary desc;
12.上升的温度

那么这道题其实就涉及到了对日期的一个操作,要找出比前一天气温还高的日期,我们就需要使用到datediff(date1,date2)函数,返回值是date1-date2

那么我们可以使用自连接,然后找出气温比前一天更高的日期
select w1.idfrom weather w1
join weather w1
on diffdate(w1.RecordDate,w2.RecordDate)=1
where w1.Temperature>w2.Temperature
13.换座位


要做的事情是将相邻的两行记录为一组,调换一下顺序,那么我们要做的其实就两件事情
1.对id为奇数的行记录
1)如果此时的行记录不是最后一行,那么对id+1
2)如果此时的行记录是最后一行,id不变
2.id为偶数的行记录
直接对id-1即可
所以我们可以写出下列sql语句对原表进行一个修改
修改完成之后再以id为标准重新排序,即完成修改
select(
case
when id%2==0 then id-1
when id%2!=0 and id!=(select count(*) from seat) then id+1
else id
end
)as id,student
from seat
order by id;
14.重新格式化部门表


原表有三个字段——id,revenue(工资),month(月份)
我们要将原表修改成新的一张表——id,每月工资(总共有12个月,所以有12个字段记录,没有的数据用null来表示)
操作步骤
根据month为基准选择每个month的revernue作为新的工资字段
注意点
首先每个人只有一个id,所以我们需要根据id来进行分组,但是每个人可能不只有一个月的工资(会出现id相同,工资不同的情况,这是因为不同月份的工资也是不同的),所以我们还需要借助一个联合索引(revenue,month)

此时在第一组数据中group by id得到了三行数据,我们仅仅select id,revenue是不知道该选取哪一个数据的,所以这样的操作在标准SQL中是不允许的,只能通过聚合函数来处理,也就是把一组数据处理成一个单一数据,所以可以这样写:
select id, sum(revenue) as total
from Department
group by id
来表示一个部门的总收入。那么我们要找出一月份的收入,就需要以month作为判断标准了,sql可以这样写
sum(case when month="Jan" then revenue end) as "Jan_revenue",
如果month的值是Jan,那么结果就是revenue,否则忽略。
sql语句
select id,
sum(case when month="Jan" then revenue end) as "Jan_revenue",
sum(case when month="Feb" then revenue end) as "Feb_revenue",
sum(case when month="Mar" then revenue end) as "Mar_revenue",
sum(case when month="Apr" then revenue end) as "Apr_revenue",
sum(case when month="May" then revenue end) as "May_revenue",
sum(case when month="Jun" then revenue end) as "Jun_revenue",
sum(case when month="Jul" then revenue end) as "Jul_revenue",
sum(case when month="Aug" then revenue end) as "Aug_revenue",
sum(case when month="Sep" then revenue end) as "Sep_revenue",
sum(case when month="Oct" then revenue end) as "Oct_revenue",
sum(case when month="Nov" then revenue end) as "Nov_revenue",
sum(case when month="Dec" then revenue end) as "Dec_revenue"
from Department
group by(id)
15.有5个或更多学生选择的课程

操作步骤
1.使用group by class 将表按照课程进行一个分组
2.having count(distinct student)>=5找出分组后数据量大于等于5的课程,使用distinct是为了对学生去重,如果出现一样的学生选了同一门课那么我们需要筛除掉(这个不严谨,使用id会更好,因为名字也有可能一样)
sql语句
select class
from courses
group by class
having count(distinct student)>=5;
15.大的国家

(这道题目很简单,就是加两个条件筛选一下即可)
1.普通做法
select w.name,w.population,w.area
from World as w
where w.area>3000000 or w.population>25000000
在数据量很大的时候,因为使用了or,导致不会走索引,所以我们可以使用union连接子查询,这种做法可以利用到索引,在大数据量的时候会更快
2.Union子查询
select name, population, area
from World
where area>3000000
Union
select name, population, area
from World
where population>25000000














 872
872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









