







文章目录
前言
我们先提出几个问题?
- 如果现在一个机器数据量很大,一句超出了物理内存的极限,该怎么办?
- 如何对存储的数据进行管理?
- 如何构建集群?
- 如果集群出现故障怎么办?
- 集群如果要扩充新内容,该怎么办?
我们将围绕这几个问题进行解答。
集群的概念
如何获取更⼤的空间? 加机器即可! 所谓 “⼤数据” 的核⼼, 其实就是⼀台机器搞不定了, ⽤多台机器来
搞。
Redis 的集群就是在上述的思路之下, 引⼊多组 Master / Slave , 每⼀组 Master / Slave 存储数据全集的⼀部分, 从⽽构成⼀个更⼤的整体, 称为 Redis 集群 (Cluster).
假定整个数据全集是 1 TB, 引⼊三组 Master / Slave 来存储. 那么每⼀组机器只需要存储整个
数据全集的 1/3 即可.
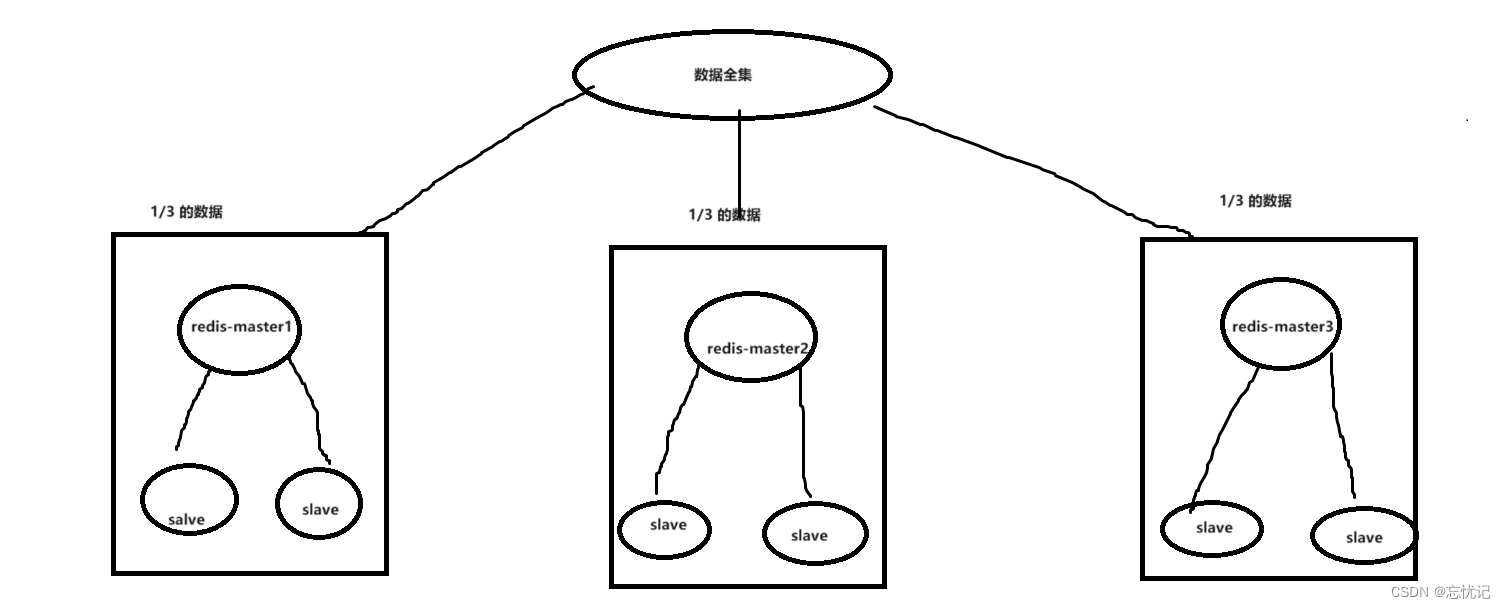
Master1 和 Slave11 和 Slave12 保存的是同样的数据. 占总数据的 1/3
Master2 和 Slave21 和 Slave22 保存的是同样的数据. 占总数据的 1/3
Master3 和 Slave31 和 Slave32 保存的是同样的数据. 占总数据的 1/3
这三组机器存储的数据都是不同的.
每个 Slave 都是对应 Master 的备份(当 Master 挂了, 对应的 Slave 会补位成 Master).
每个红框部分都可以称为是⼀个 分⽚ (Sharding).
如果全量数据进⼀步增加, 只要再增加更多的分⽚, 即可解决.
数据分片算法
Redis cluster 的核⼼思路是⽤多组机器来存数据的每个部分. 那么接下来的核⼼问题就是, 给定⼀个数据 (⼀个具体的 key), 那么这个数据应该存储在哪个分⽚上? 读取的时候⼜应该去哪个分⽚读取?
接下来,我们来看看。
1.hash 求余
算法原理
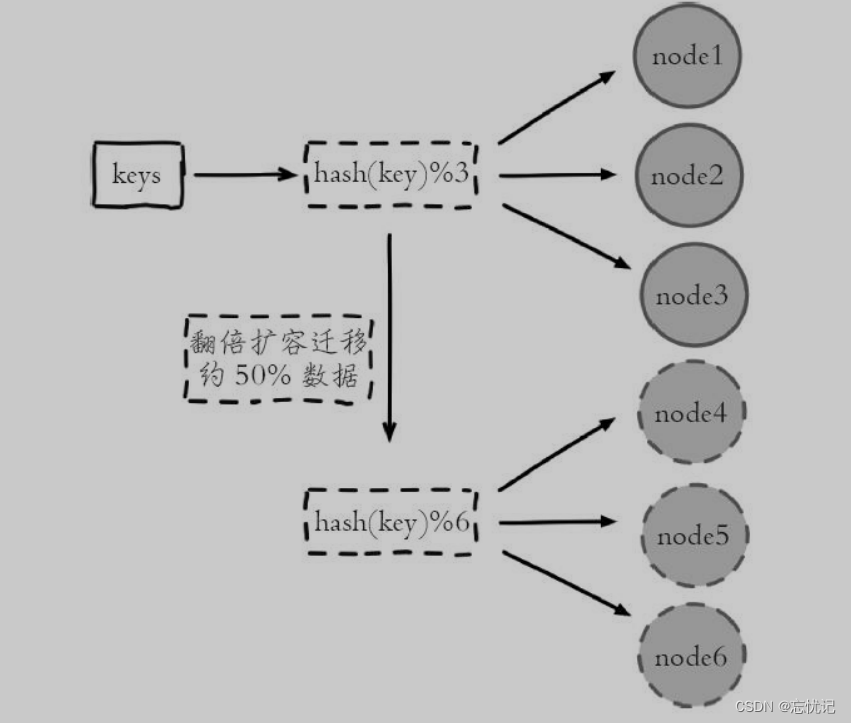
Hash 求余是一种常用的数据分布策略,通常用于将数据均匀分配到多个存储节点。算法的基本思想是使用哈希函数对数据项的键值进行哈希处理,然后取结果的模(即余数),用来决定将数据存储在哪个节点。例如,如果有 N 个节点,可以将哈希值除以 N 并取余数,得到的余数范围在 0 到 N-1 之间,这个余数就代表数据应当存储在哪个节点。
具体的算法发区如下图所示:
存在问题
扩缩容问题:当增加或减少节点时,大部分键值的映射关系会发生改变,需要重新分配,这就引发了大量的数据迁移,对系统的稳定性和性能产生影响。
负载不均衡:如果数据分布不均匀或节点性能各异,简单的 hash 求余可能导致某些节点负载过高,而其他节点则相对空闲。
2.一致性hash算法
算法原理
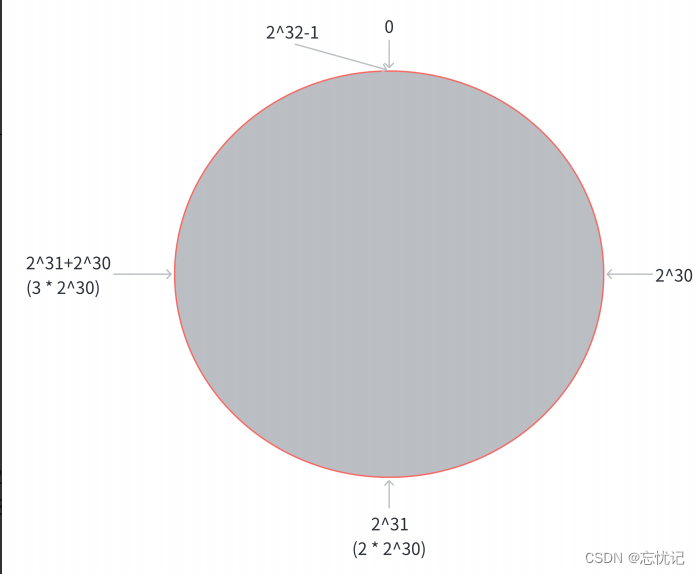
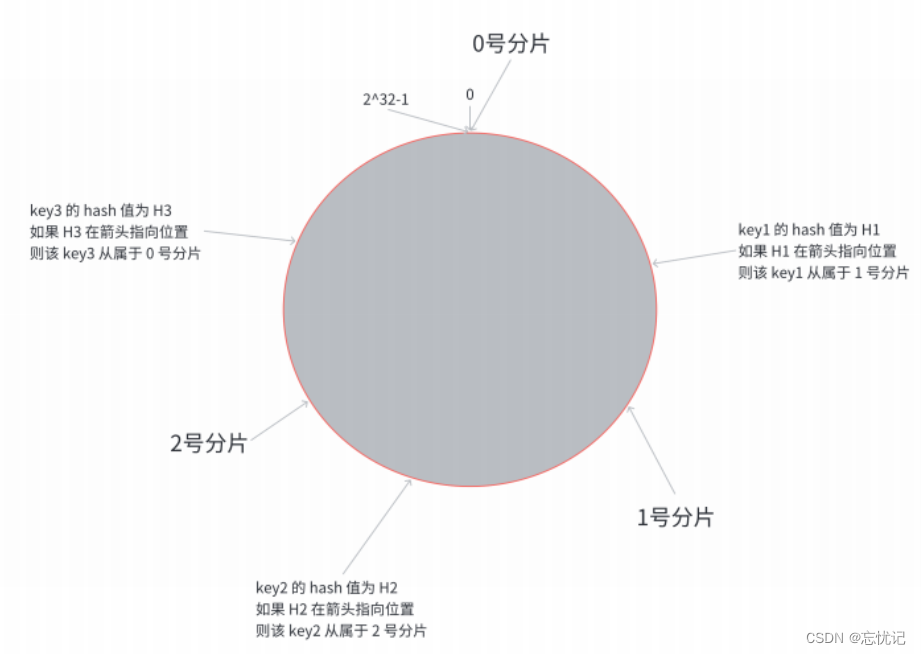
一致性哈希算法是为了解决简单哈希求余中节点增减引起的大量数据迁移问题而提出的。它将整个哈希值空间组织成一个虚拟的圆环,例如使用 0 到 2^32-1 的哈希空间。每个节点在这个环上占据一个哈希值的位置,每个数据项的键也通过哈希函数映射到这个环上的某个点。数据存储在顺时针遇到的第一个节点上。当增加或删除节点时,只有该节点附近的数据需要重新定位,从而大大减少了迁移的数据量。
-
第⼀步, 把 0 -> 2^32-1 这个数据空间, 映射到⼀个圆环上. 数据按照顺时针⽅向增⻓
-
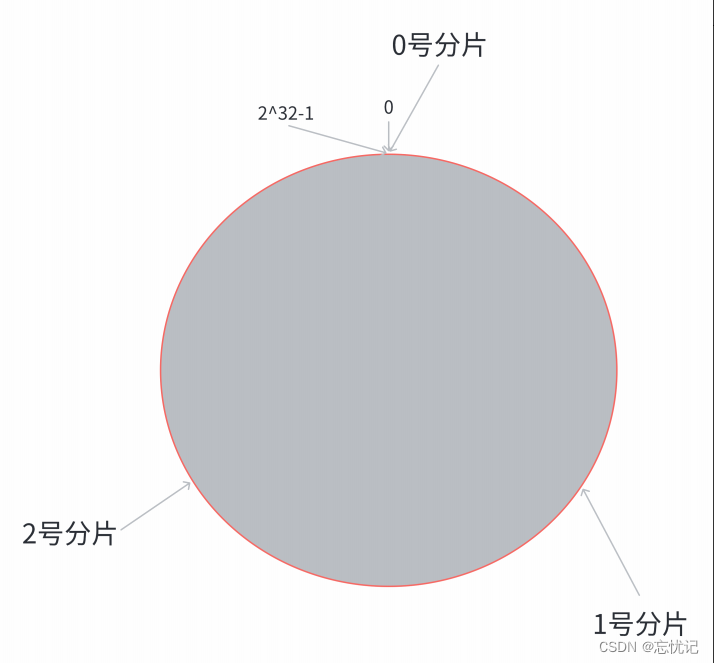
第⼆步, 假设当前存在三个分⽚, 就把分⽚放到圆环的某个位置上
-
第三步:假定有⼀个 key, 计算得到 hash 值 H, 那么这个 key 映射到哪个分⽚呢? 规则很简单, 就是从 H所在位置, 顺时针往下找, 找到的第⼀个分⽚, 即为该 key 所从属的分⽚.
存在问题
- 数据倾斜问题:如果节点较少,或者哈希函数的映射不够均匀,仍然可能出现数据分布不均的问题。
- 环的管理:随着节点的频繁增减,环的管理和数据的重新定位可能会变得复杂。
3.哈希槽分区算法 (Redis 使用)
算法原理
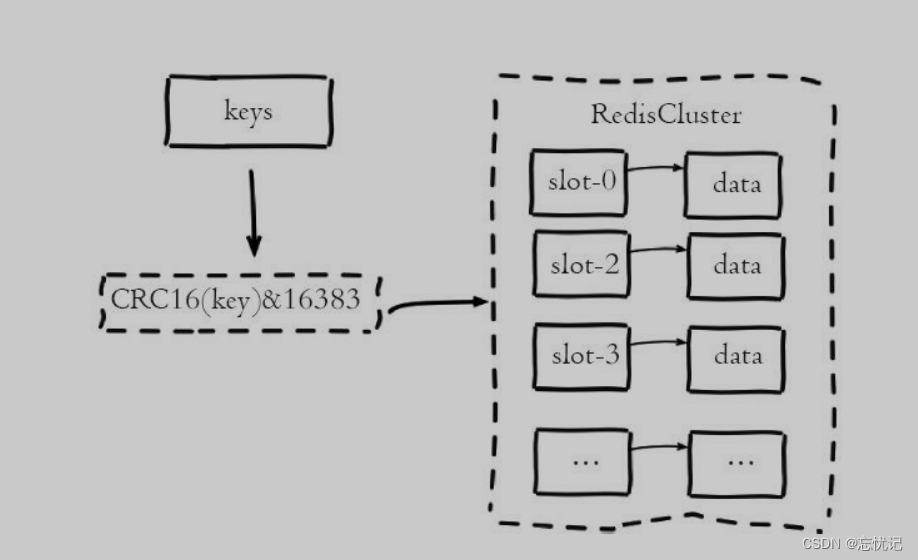
Redis 的集群使用了一种称为 “哈希槽” 的技术来分配和管理键空间。在 Redis 集群中,存在 16384 个哈希槽,每个键通过哈希函数被映射到这 16384 个槽中的一个。每个集群节点负责一部分哈希槽,例如在一个三个节点的集群中,每个节点可能负责大约 5461 个槽。当需要查找一个键时,先计算这个键的哈希槽,然后直接转到负责该槽的节点。
Redis Cluser采用虚拟槽分区,所有的键根据哈希函数映射到0~16383整
数槽内,计算公式:slot=CRC16(key)&16383。每一个节点负责维护一部
分槽以及槽所映射的键值数据.
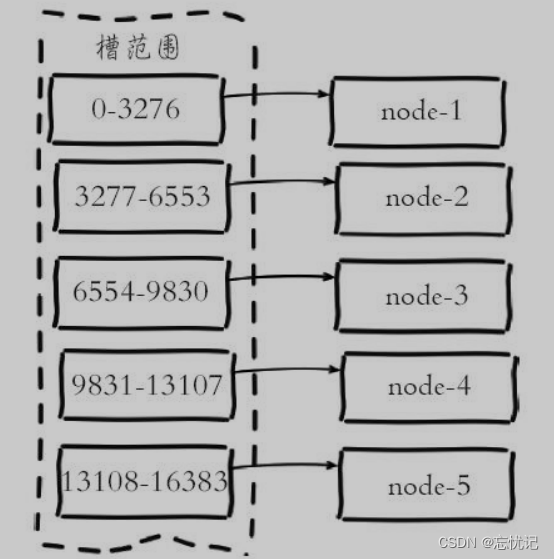
使用CRC16(key)&16383将键映射到槽上
搭建环境集群环境
拓扑结构图
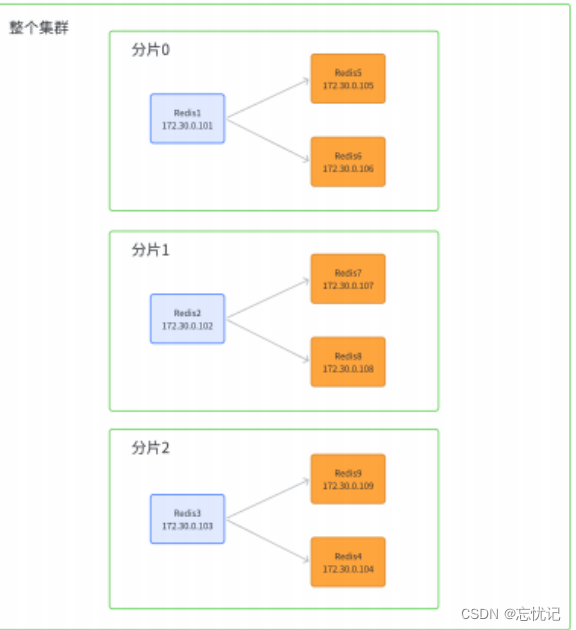
此处我们先创建出 11 个 redis 节点. 其中前 9 个⽤来演⽰集群的搭建.
后两个⽤来演⽰集群扩容.
创建目录和配置
[root@VM-16-7-centos redis]# mkdir redis-cluster
[root@VM-16-7-centos redis]# cd redis-cluster/
[root@VM-16-7-centos redis-cluster]# ls
[root@VM-16-7-centos redis-cluster]# touch docker-compose.yml
[root@VM-16-7-centos redis-cluster]# touch generate.sh
补充docker-compose和generate.sh 文件
generate.sh
for port in $(seq 1 9); \
do \
mkdir -p redis${port}/
touch redis${port}/redis.conf
cat << EOF > redis${port}/redis.conf
port 6379
bind 0.0.0.0
protected-mode no
appendonly yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 172.30.0.10${port}
cluster-announce-port 6379
cluster-announce-bus-port 16379
EOF
done
# 注意 cluster-announce-ip 的值有变化.
for port in $(seq 10 11); \
do \
mkdir -p redis${port}/
touch redis${port}/redis.conf
cat << EOF > redis${port}/redis.conf
port 6379
bind 0.0.0.0
protected-mode no
appendonly yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 172.30.0.1${port}
cluster-announce-port 6379
cluster-announce-bus-port 16379
EOF
done
docker-compose.yml
version: '3.7'
networks:
mynet:
ipam:
config:
- subnet: 172.30.0.0/24
services:
redis1:
image: 'redis:5.0.9'
container_name: redis1
restart: always
volumes:
- ./redis1/:/etc/redis/
ports:
- 6371:6379
- 16371:16379
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.101
redis2:
image: 'redis:5.0.9'
container_name: redis2
restart: always
volumes:
- ./redis2/:/etc/redis/
ports:
- 6372:6379
- 16372:16379
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.102
redis3:
image: 'redis:5.0.9'
container_name: redis3
restart: always
volumes:
- ./redis3/:/etc/redis/
ports:
- 6373:6379
- 16373:16379
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.103
redis4:
image: 'redis:5.0.9'
container_name: redis4
restart: always
volumes:
- ./redis4/:/etc/redis/
ports:
- 6374:6379
- 16374:16379
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.104
redis5:
image: 'redis:5.0.9'
container_name: redis5
restart: always
volumes:
- ./redis5/:/etc/redis/
ports:
- 6375:6379
- 16375:16379
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.105
redis6:
image: 'redis:5.0.9'
container_name: redis6
restart: always
volumes:
- ./redis6/:/etc/redis/
ports:
- 6376:6379
- 16376:16379
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.106
redis7:
image: 'redis:5.0.9'
container_name: redis7
restart: always
volumes:
- ./redis7/:/etc/redis/
ports:
- 6377:6379
- 16377:16379
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.107
redis8:
image: 'redis:5.0.9'
container_name: redis8
restart: always
volumes:
- ./redis8/:/etc/redis/
ports:
- 6378:6379
- 16378:16379
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv5_address: 172.30.0.108
redis9:
image: 'redis:5.0.9'
container_name: redis9
restart: always
volumes:
- ./redis9/:/etc/redis/
ports:
- 6379:6379
- 16379:16379
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.109
redis10:
image: 'redis:5.0.9'
container_name: redis10
restart: always
volumes:
- ./redis10/:/etc/redis/
ports:
- 6380:6379
- 16380:16379
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.110
redis11:
image: 'redis:5.0.9'
container_name: redis11
restart: always
volumes:
- ./redis11/:/etc/redis/
ports:
- 6381:6379
- 16381:16379
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.111
启动容器
docker-compose up -d
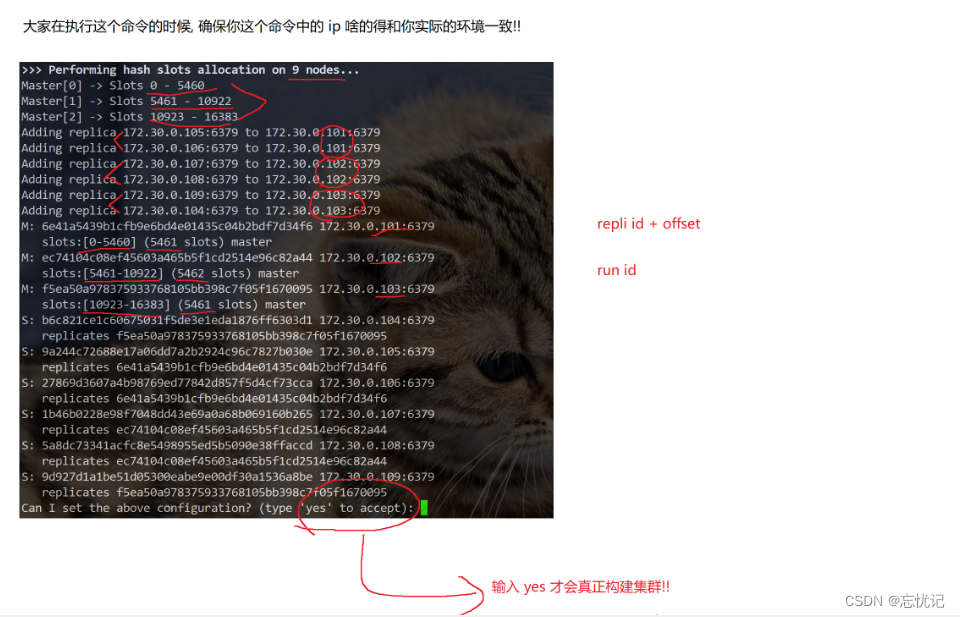
把上述的redis节点构建成集群
redis-cli --cluster create 172.30.0.101:6379 172.30.0.102:6379
172.30.0.103:6379 172.30.0.104:6379 172.30.0.105:6379 172.30.0.106:6379 172.30.0.107:6379 172.30.0.108:6379 172.30.0.109:6379 --cluster-replicas 2
- –cluster create 表⽰建⽴集群. 后⾯填写每个节点的 ip 和地址.
- –cluster-replicas 2 表示 每个主节点需要两个从节点备份.
执行之后, 容器之间会进⾏加入集群操作
使用集群
使用cluster nodes 查看集群信息

假设主节点宕机
查看当前节点。
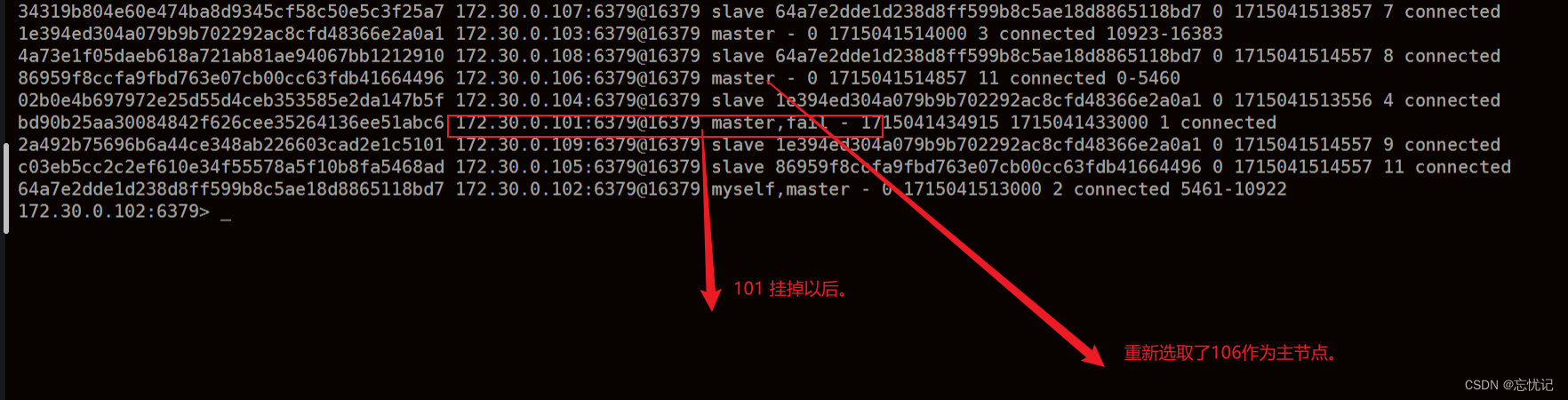
⼿动停⽌⼀个 master 节点, 观察效果.
docker stop redis1
重新启动redis1,再来看看效果。
doker start redis1

故障转移的具体处理流程
故障判定
集群中每个节点都会定期向其他节点发送ping消息,接收节点回复pong消息作为响应。如果在cluster-node-timeout时间内通信一直失败,则发送节点会认为接收节点存在故障,把接收节点标记为主观下线(pfail)状态。具体的过程如图所示:
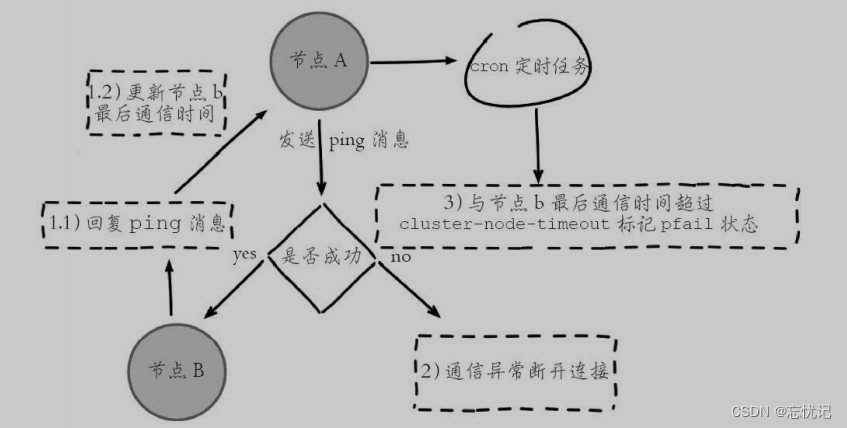
- 节点 A 给 节点 B 发送 ping 包, B 就会给 A 返回⼀个 pong 包. ping 和 pong 除了 message type属性之外, 其他部分都是⼀样的. 这⾥包含了集群的配置信息(该节点的id, 该节点从属于哪个分⽚,是主节点还是从节点, 从属于谁, 持有哪些 slots 的位图…).
- 每个节点, 每秒钟, 都会给⼀些随机的节点发起 ping 包, ⽽不是全发⼀遍. 这样设定是为了避免在节点很多的时候, ⼼跳包也⾮常多(⽐如有 9 个节点, 如果全发, 就是 9 * 8 有 72 组⼼跳了, ⽽且这是按照 N^2 这样的级别增⻓的).
- 当节点 A 给节点 B 发起 ping 包, B 不能如期回应的时候, 此时 A 就会尝试重置和 B 的 tcp 连接, 看能否连接成功. 如果仍然连接失败, A 就会把 B 设为 PFAIL 状态(相当于主观下线).
- A 判定 B 为 PFAIL 之后, 会通过 redis 内置的 Gossip 协议, 和其他节点进⾏沟通, 向其他节点确认 B的状态. (每个节点都会维护⼀个⾃⼰的 “下线列表”, 由于视⻆不同, 每个节点的下线列表也不⼀定相同).
- 此时 A 发现其他很多节点, 也认为 B 为 PFAIL, 并且数⽬超过总集群个数的⼀半, 那么 A 就会把 B 标记成 FAIL (相当于客观下线), 并且把这个消息同步给其他节点(其他节点收到之后, 也会把 B 标记成FAIL).
⾄此, B 就彻底被判定为故障节点了。
故障迁移
所谓故障迁移就是保证集群的可用性,如果下线节点是持有槽的主节点则需要在它的从节点中选出一个替换它,从而保证集群的高可用。下线主节点的所有从节点承担故障恢复的义务,当从节点通过内部定时任务发现自身复制的主节点进入客观下线时,将会触发故障恢复流程。
故障恢复流程如下:
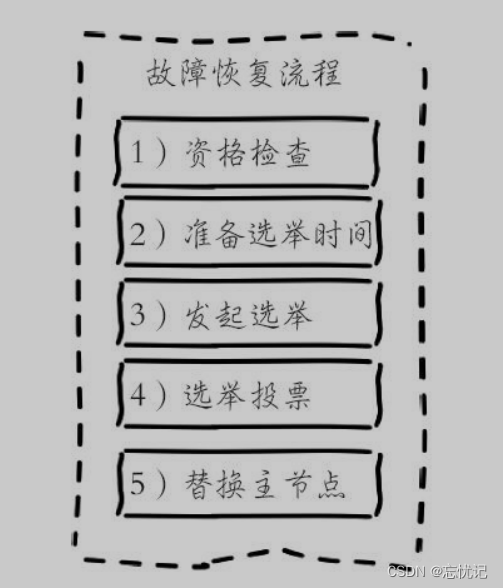
- 从节点判定⾃⼰是否具有参选资格. 如果从节点和主节点已经太久没通信(此时认为从节点的数据和主节点差异太⼤了), 时间超过阈值, 就失去竞选资格.
- 具有资格的节点, ⽐如 C 和 D, 就会先休眠⼀定时间. 休眠时间 = 500ms 基础时间 + [0, 500ms] 随机
时间 + 排名 * 1000ms. offset 的值越⼤, 则排名越靠前(越⼩). - ⽐如 C 的休眠时间到了, C 就会给其他所有集群中的节点, 进⾏拉票操作. 但是只有主节点才有投票资格.
- 主节点就会把⾃⼰的票投给 C (每个主节点只有 1 票). 当 C 收到的票数超过主节点数⽬的⼀半, C 就会晋升成主节点. (C ⾃⼰负责执⾏ slaveof no one, 并且让 D 执⾏ slaveof C).
- 同时, C 还会把⾃⼰成为主节点的消息, 同步给其他集群的节点. ⼤家也都会更新⾃⼰保存的集群结构信息.
集群扩容
上⾯已经把 redis1 - redis9 重新构成了集群. 接下来把 redis10 和 redis11 也加⼊集群.
这里我们以110为master,111 为slave ,相当于把数据分片从3->4.
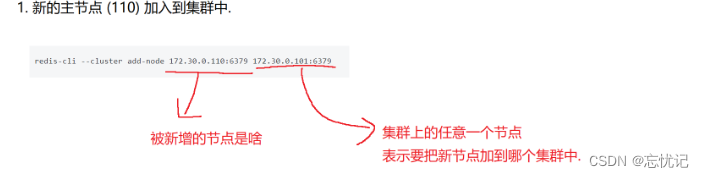
- 将新的节点110 加入集群中
redis-cli --cluster add-node 172.30.0.110:6379 172.30.0.101:6379
add-node 后的第⼀组地址是新节点的地址. 第⼆组地址是集群中的任意节点地址.

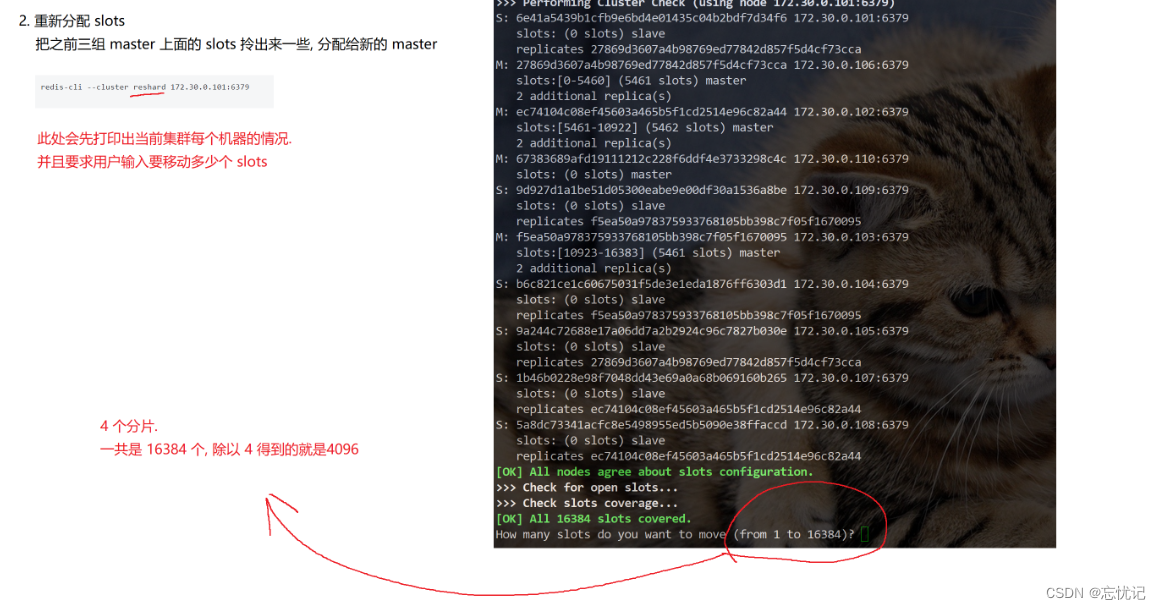
- 重新分配 slots
redis-cli --cluster reshard 172.30.0.101:6379
执行命令以后,你会遇到的操作。
这时候会让你输入分片内容

- 给新的主节点添加从节点
redis-cli --cluster add-node 172.30.0.111:6379 172.30.0.101:6379 --cluster-slave --cluster-master-id 7c2a7cd67ee35561280e0be8ddf2c50ae64b01e0
进入redis一个节点,查看集群状态,这个时候就能看到110的节点就有分片。
















 8266
8266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











