







一.关系型数据库——MySQL
1.MySQL引擎
MyISAM:主要面向在线分析处理方面的应用。
特点:不支持事务,支持表锁和全文索引。操作速度快。
InnoDB:主要面向在线事务处理方面的应用。
特点:行锁设计,支持外键。
2.SQL 的select 语句完整的执行顺序
from->where->group by->聚集函数->having->计算所有表达式
->select字段->order by ->limit
3.不可重复读和幻读区别:
不可重复读侧重于修改,幻读侧重于增加或删除。
解决:解决不可重复读需要锁住满足条件的行,解决幻读需要锁表。
4.事务的基本要素(ACID)
- 原子性:事务开始后的所有操作,要么全部做完,要么全部不做,不可能停留在中间环节。
- 一致性:事务开始前和结束后,数据库的完整性约束没有被破坏。
- 隔离性:同一时间,只允许一个事务请求同一数据,不同的事物之间彼此没有干扰。
- 持久性:事务完成后,事务对数据库的所有更新将保存到数据库,不能回滚。
5.MySQL事务隔离级别:
读未提交、读提交、可重复读、串行化
6.SQL优化
- 对查询进行优化,应尽量避免全表扫描
- 避免更改索引列的类型
- 避免在索引列上计算
- 尽量避免使用in 和not in
优化方式:如果是连续数值,可以用between代替。
如果是子查询,可以用exists代替。 - 保证单表数据不超过200W,适时分割表
- 当只需要一行数据的时候,使用limit 1
详细的SQL优化参考链接:https://blog.csdn.net/weixin_43842590/article/details/99870538
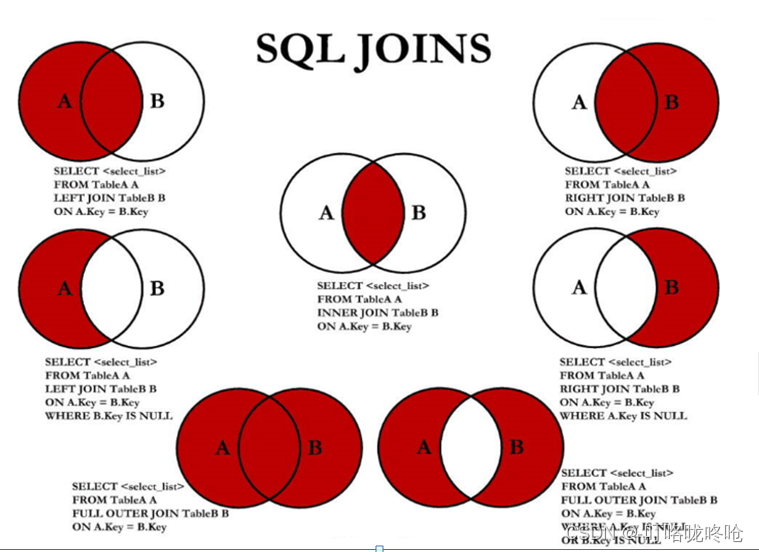
7.7种SQL JOINS的实现方式
7.索引
7.1 是什么?
索引是帮助MySQL高效获取数据的数据结构。本质:索引就是数据结构。
7.2 有什么用?
a. 类似图书馆建数目索引,提高数据检索的效率,降低数据库的IO成本。
b. 通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗。
7.3 怎么用?
- 主键自动建立唯一索引
- 频繁作为查询条件的字段应该创建索引
- 查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
- 查询中统计或者分组字段
7.4 索引的底层是什么?
InnoDB存储引擎是用B+Tree实现其索引结构。
原因:时间复杂度低, 查找、删除、插入操作都可以可以在对数时间内完成。
另外一个重要原因存储在B-Tree中的数据是有序的
7.5 什么情况下索引会失效?
1.like查询以%开头
2.组合索引要遵循最左匹配原则
3.如果mysql使用全表扫描比使用索引快,则不使用索引
4.如果列类型是字符串,一定要在条件中将数据使用引号引起来,否则不使用索引
5.如果条件中有or,即使其中有条件带索引也不会使用
要想使用or,又想条件带索引,只能在or条件中的每个列都加上索引
二.非关系型数据库——Redis
介绍:Redis本质上是一个Key-value类型的内存数据库,它的性能非常出色,每秒可以处理10万次读写操作,是已知最快的Key-value数据库,支持保存多种数据结构。缺点是数据库容量受到物理内存的限制,不能用作海量数据的高性能读写。
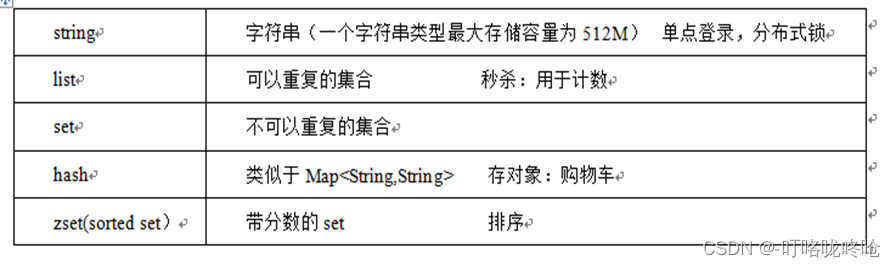
1.常用数据类型
2.Redis提供了哪几种持久化方式,在工作中是怎么配置的?
2.1 RDB持久化:
在指定的时间间隔内将内存中的数据集快照写入磁盘,它恢复时是将快照文件直接读到内存里。存储的文件小,速度快,但是安全性低。
优点:
适合大规模的数据恢复
对数据完整性和一致性要求不高更适合使用
节省磁盘空间
恢复速度快
缺点:
在备份周期在一定间隔时间做一次备份,所以如果Redis意外down掉的话,就会丢失最后一次快照后的所有修改。
2.2 AOF持久化:
以日志形式记录每个写操作,只许追加文件但不可以改写文件,默认不开启。存储的文件大,速度慢,安全性高。
优势:
备份机制更稳健,丢失数据概率更低。
可读的日志文本,通过操作AOF稳健,可以处理误操作。
劣势:
比起RDB占用更多的磁盘空间。
恢复备份速度要慢。
每次读写都同步的话,有一定的性能压力。
2.3 总结:
AOF和RDB同时开启:默认取AOF的数据。
总结:官方推荐两个都启用。
如果对数据不敏感,可以选单独用RDB。
不建议单独用 AOF,因为可能会出现Bug。
如果只是做纯内存缓存,可以都不用。
3.Redis的功能
1.缓存
2.发布订阅
3.分布式锁(解决高并发)
4.消息队列
4.为什么用Redis做缓存
1.速度快,是基于内存的。
2.支持多种数据类型。
3.支持多种事务,如果在入队时报错,都不会执行;在非入队时报错,成功的就会成功执行。
4.不仅可以用来做缓存,还支持分布式锁、消息队列等功能。
5.Redis为什么查询速度快
1.完全基于内存
2.数据结构简单
3.采用单线程,避免了不必要的上下文切换,也就不存在多线程切换的消耗。
4.使用到了多路IO复用(非阻塞IO)
6.如何保持Redis和MySQL数据的一致性
延迟双删:事务A进来会先查Redis缓存,没查到会清空缓存,再去MySQL数据库查询,查询完的数据会自动存到Redis中,此时需要延时一会儿,再进行清空缓存,此时事务B进来查询到的就是最新的数据。
7.缓存中出现的三个问题
7.1 缓存击穿
缓存某一个热点key失效,如果存在高并发,直接访问数据库,会导致数据库压力过大。
解决:将数据库中所有的查询条件,放布隆过滤器中。当一个查询请求来临的时候,先经过布隆过滤器 进行查询,如果请求存在这个条件中,那么继续执行,如果不在,直接丢弃。
7.2 缓存穿透
用户查询数据库中一个根本不存在的数据,查了无法缓存。
解决:将null放到缓存中,再设置一个相对较短的过期时间。
7.3 缓存雪崩
缓存中所有key失效,如果存在高并发,会导致数据库崩溃。
解决:缓存中的key,过期时间不要设置为统一时间。
如果缓存雪崩服务器崩了?
服务熔断。当某个服务不可用或者响应时间太长,会进行服务降级,然后熔断该节点微服务调用。
如何提前发现雪崩? 设置一个阈值,如果接近或超过这个阈值,具体情况具体处理
三.Redis和MySQL的区别
1.MySQL是关系型数据库,Redis是非关系型数据库。
2. MySQL是基于磁盘的,用于持久化的方式将数据存到硬盘中,读写数据没有Redis快,但不受容量限制,性价比高。
3.Redis是基于内存的,将使用比较频繁的数据存到缓存中,读写速度快,也可以做持久化,但是内存空间有限,当数据量超过内存时,需要扩充内存,但内存价格高















 7261
7261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









