







-
分桶表 为什么不能通过load 导数据
3个桶,3个hdfs文件,load 一个文件 -
having 与where 的 区别?
having group by 联用
where 数据过滤
having 可以在聚合条件后的基础上过滤 -
所有的离线数据处理场景都适用hive吗?
并不是所有场景都适合,逻辑简单又要求快速出结果的场景Hive优势更大。但是在业务逻辑非常复杂的情况下还是需要开发MapReduce程序更加直接有效。 -
Hive能作为业务系统的数据库使用吗?
不能。传统数据库要求能够为系统提供实时的增删改查,而Hive不支持行级别的增删改,查询的速度也不比传统关系型数据库,而是胜在吞吐量高,所以不能作为关系型数据库来使用。 -
Hive与传统MR方式处理数据相比能够提高运行效率吗?
Hive的使用中需要将HQL编译为MR来运行,所以在执行效率上要低于直接运行MR程序。但是对于我们来说,由于只需要编写调试HQL,而不用开发调试复杂的MR程序,所以工作效率能够大大提高。 -
Hive为什么不支持行级别的增删改?
Hive不支持行级别的增删改的根本原因在于他的底层HDFS本身不支持。在HDFS中如果对整个文件的某一段或某一行内容进行增删改,势必会影响整个文件在集群中的存放布局。需要对整个集群中的数据进行汇总,重新切块,重新发送数据到每个节点,并备份,这样的情况是得不偿失的。所以HDFS的设计模式使他天生不适合做这个事
Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能(HQL)。
没有集群, 单一节点
OLAP和OLTP的区别
Hive 的架构
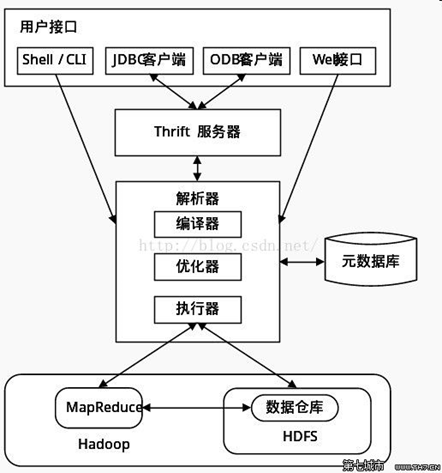
表的各种结构称为元数据
Hive与Hadoop的关系
Hive利用HDFS存储数据,利用MapReduce查询分析数据

2 Hive 安装部署
2.1 derby版hive直接使用
超轻量级的数据库
前提:Hive安装非常简单,解压之后即可直接运行,不需要太多配置,前提是要配置JAVA_HOME和HADOOP_HOME。并且Hadoop要全量启动(五个进程)
解压
cd /opt/softwares
tar -xvzf apache-hive-2.3.6-bin.tar.gz -C ../servers/

修改目录名称
cd ../servers/
mv apache-hive-2.3.6-bin hive-2.3.6
初始化

启动
在hive-2.3.6目录下执行
bin/hive
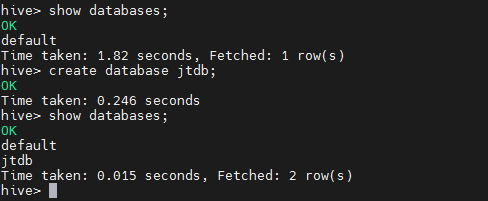
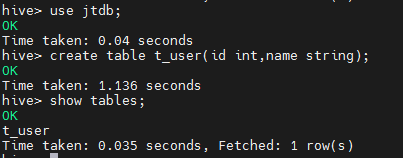
数据库操作 (创建数据库,表,插入数据操作)
create database jtdb;
use jt db;
create table t_user(id int,name string);
insert into table t_user values(1,"zhaoyun");
select * from t_user;
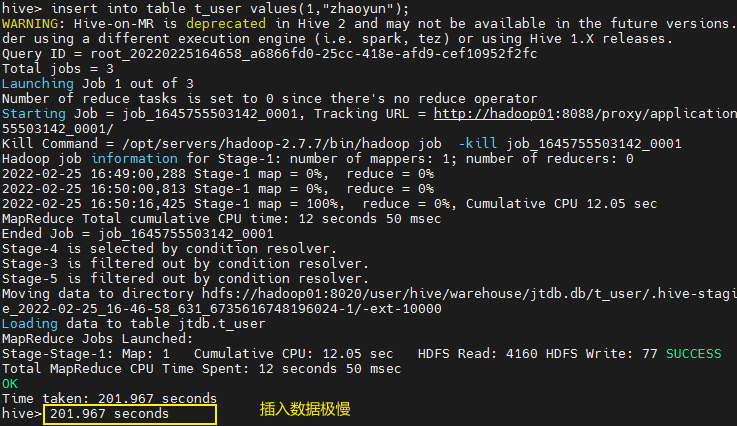
Hive 局限性很大


2.2 基于mysql管理元数据版hive
Hive没有将描述数据库、表、数据之间关系的元数据直接存放在HDFS中,而是存放在了传统的关系型数据库中,这样保证了元数据可以快速的进行增删改查。
Hive原生的将元数据保存在了内置的Derby数据库中。
Derby存在的问题:过于轻量级,性能较低,安全性不高,不适合生产。
这种情况我们是无法忍受的,实际开发中不会使用Derby来做Hive的元数据库。所以我们要将他替换掉。以mysql为例。
检测服务器mysql数据库
mysql
show databases;
配置mysql允许外网访问
grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
flush privileges;
*.*:任意数据库下的任意表

退出mysql
exit;
使用sqlyog连接mysql
修改配置文件hive-site.xml
在conf 下配置
vim hive-site.xml
添加以下内容
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.default.fileformat</name>
<value>TextFile</value>
</property>
<property>
<!--端口改为你自己的端口,这里是连接数据库中hive数据库-->
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<!--连接MySQL的用户名-->
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<!--连接MySQL的密码-->
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
</configuration>
上传mysql驱动
初始化
# 基于mysql初始化元数据
bin/schematool -dbType mysql -initSchema
重复上述创建表的操作。
bin/hive
show databases;
找不到之前创建过的数据库,创建相同名字的数据库和表后,为什么可以查到之前的数据?
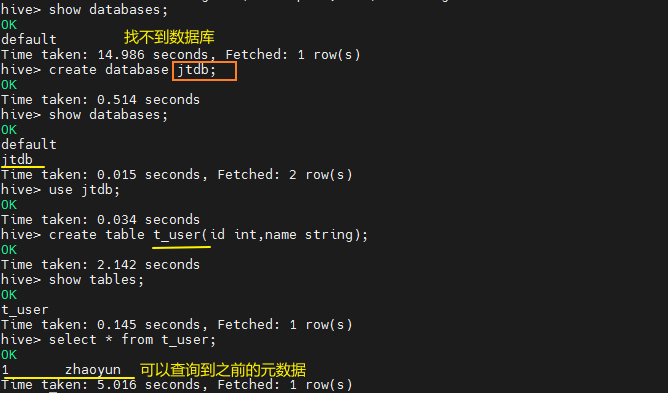


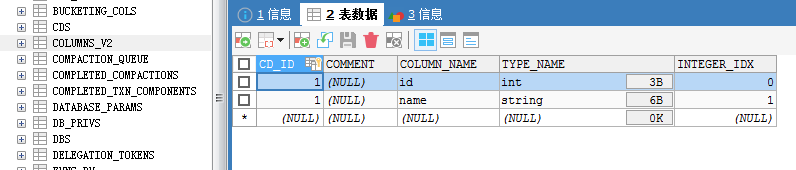
3 创建数据库与创建数据库表
3.1 管理表(内部表)
创建数据库操作
创建数据库
create database if not exists myhive;
use myhive;
说明:hive的表存放位置模式是由hive-site.xml当中的一个属性指定的
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
创建数据库并指定hdfs存储位置
create database myhive2 location '/myhive2';
修改数据库
可以使用alter database 命令来修改数据库的一些属性。但是数据库的元数据信息是不可更改的,包括数据库的名称以及数据库所在的位置
alter database myhive2 set dbproperties('createtime'='20210611');
查看数据库详细信息
查看数据库基本信息
desc database myhive2;
查看数据库更多详细信息
desc database extended myhive2;
删除
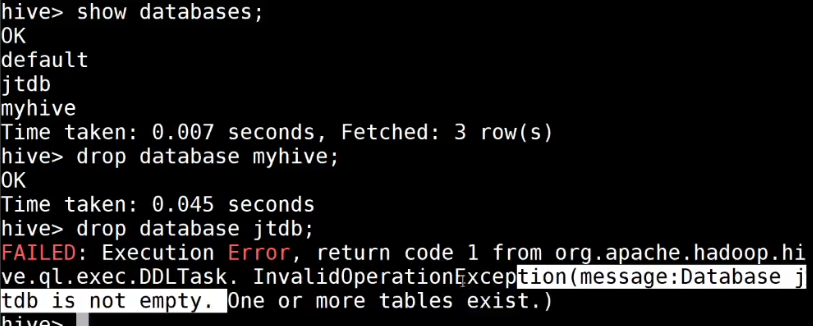
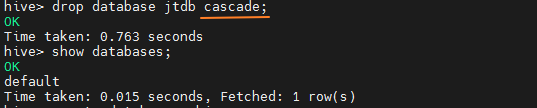

3.2外部表:
外部表说明:
外部表因为是指定其他的hdfs路径的数据加载到表当中来,所以hive表会认为自己不完全独占这份数据,所以删除hive表的时候,数据仍然存放在hdfs当中,不会删掉。
内部表:当删除表的时候,表结构和表数据全部都会删除掉。
外部表:当删除表的时候,认为表的数据会被其他人使用,自己没有独享数据的权利,所以只会删除掉表的结构(元数据),不会删除表的数据。
操作案例
分别创建老师与学生表外部表,并向表中加载数据
create external table teacher (t_id string,t_name string) row format delimited fields terminated by '\t';
create external table student (s_id string,s_name string,s_birth string , s_sex string ) row format delimited fields terminated by '\t';

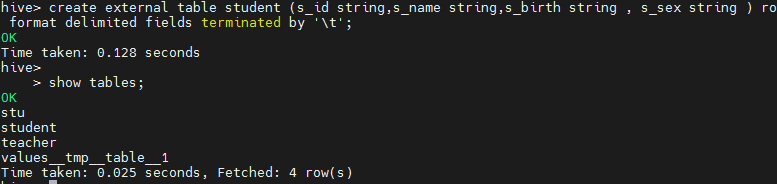
从本地文件系统向表中加载数据
load data local inpath '/opt/data/hivedatas/student.csv' into table student;
加载数据并覆盖已有数据
load data local inpath '/opt/data/hivedatas/student.csv' overwrite into table student;
从hdfs文件系统向表中加载数据(需要提前将数据上传到hdfs文件系统,其实就是一个移动文件的操作)
cd /opt/servers/hivedatas
hdfs dfs -mkdir -p /hivedatas
hdfs dfs -put teacher.csv /hivedatas/
### 数据库操作
hive> load data inpath '/hivedatas/teacher.csv' into table teacher;
如果删掉student表,hdfs的数据仍然存在,并且重新创建表之后,表中就直接存在数据了,因为我们的student表使用的是外部表,drop table之后,表当中的数据依然保留在hdfs上面了。

删除 student 表
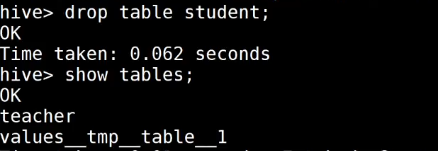
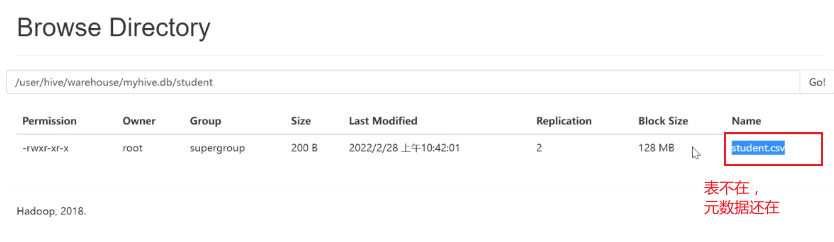
再次创建
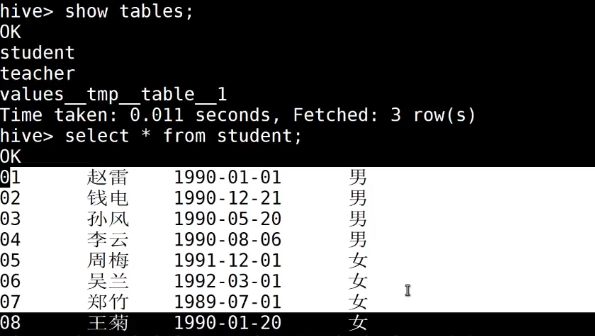
3.3 分区表
分的文件目录
即可以创建内部又可以创建外部表
在大数据中,最常用的一种思想就是分治,我们可以把大的文件切割划分成一个个的小的文件,这样每次操作一个小的文件就会很容易了,同样的道理,在hive当中也是支持这种思想的,就是我们可以把大的数据,按照每天,或者每小时进行切分成一个个的小的文件,这样去操作小的文件就会容易得多了
create table score(s_id string,c_id string, s_score int) partitioned by (month string) row format delimited fields terminated by '\t';
partitioned by -指定分区的字段
多个分区写多个字段
create table score2 (s_id string,c_id string, s_score int) partitioned by (year string,month string,day string) row format delimited fields terminated by '\t';
加载数据到分区表中
load data local inpath '/opt/data/hivedatas/score.csv' into table score partition (month='202202');
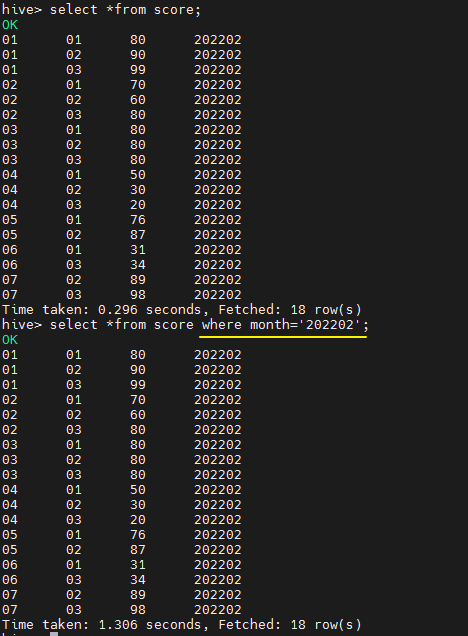

一个数据加载到多个分区
加载数据到分区表中
load data local inpath '/opt/data/hivedatas/score.csv' into table score2 partition(year='2022',month='02',day='28');
partition
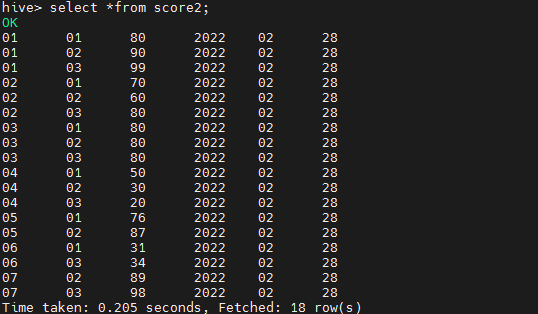

查看分区
show partitions score;
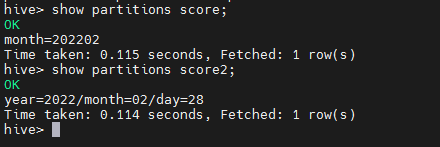
添加分区
alter table score add partition(month='202201');
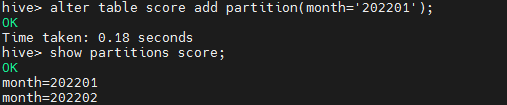
添加多个分区
alter table score add partition(month='202203') partition(month = '202204');
删除分区
alter table score drop partition(month = '202201');
内部表,外部表,分区表的区别?
分区 : 按文件
3.4 分桶表
用途:采样,以偏概全
将数据按照指定的字段进行分成多个桶中去,说白了就是将数据按照字段进行划分,可以将数据按照字段划分到多个文件当中去
开启hive的桶表功能
set hive.enforce.bucketing=true;
设置reduce的个数
set mapreduce.job.reduces=3;
创建桶表
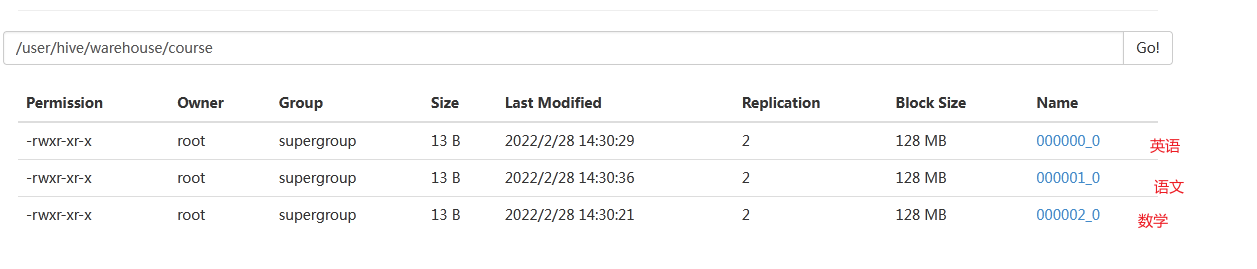
create table course (c_id string,c_name string,t_id string) clustered by(c_id) into 3 buckets row format delimited fields terminated by '\t';
clustered by(c_id) :按照c_id 分
into 3 buckets :分到3个桶
为什么不能通过load 导
3个桶,3个hdfs文件,load 一个文件
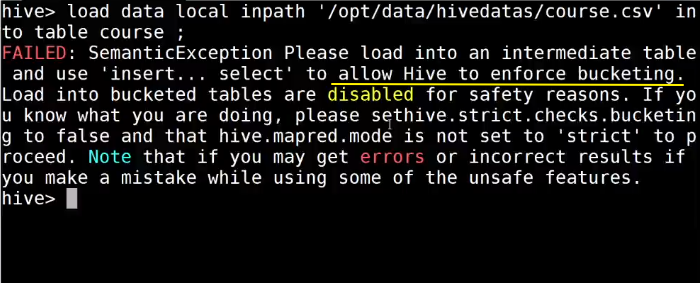
桶表的数据加载,由于桶表的数据加载通过hdfs dfs -put文件或者通过load data均不好使,只能通过insert overwrite
创建普通表,并通过insert overwrite的方式将普通表的数据通过查询的方式加载到桶表当中去
创建普通表:
create table course_common (c_id string,c_name string,t_id string) row format delimited fields terminated by '\t';
普通表中加载数据
load data local inpath '/opt/data/hivedatas/course.csv' into table course_common;
通过insert overwrite给桶表中加载数据
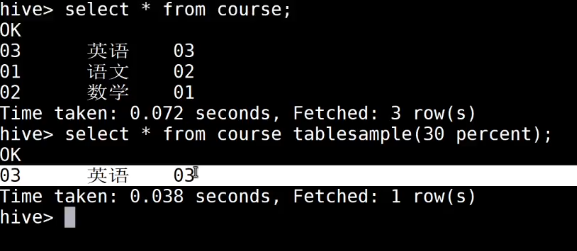
insert overwrite table course select * from course_common cluster by(c_id);















 4782
4782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









