






1.mybatis中一级缓存和二级缓存
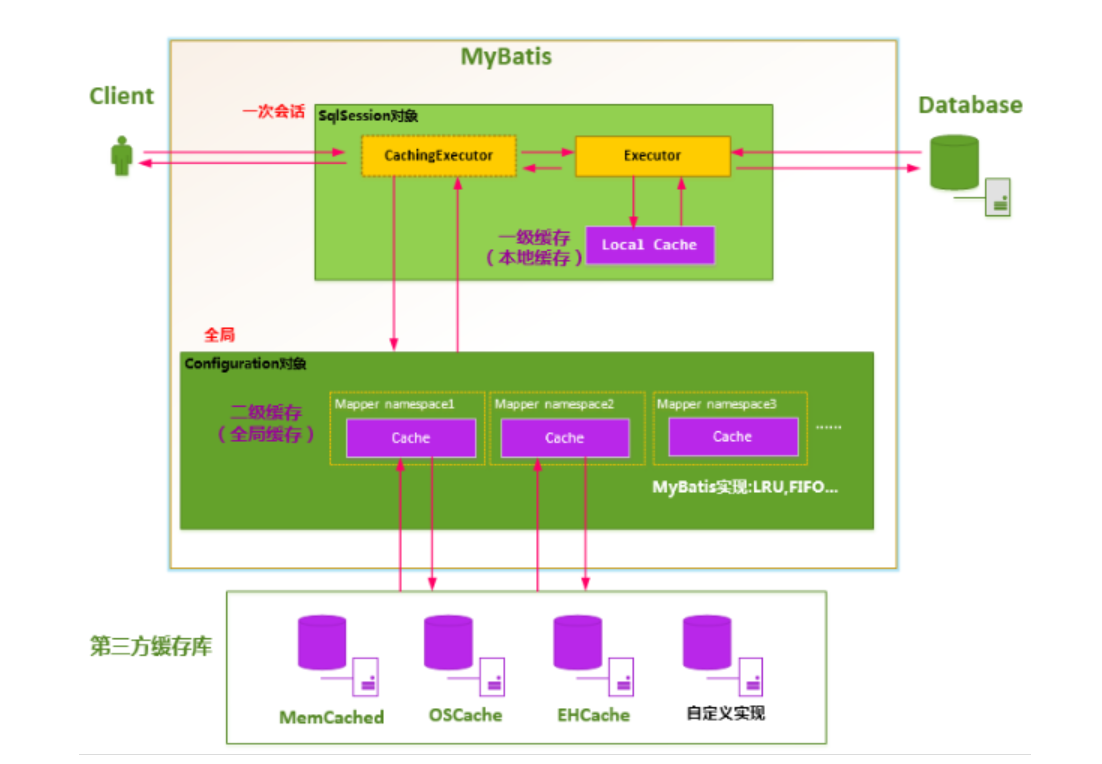
1.一级缓存
一级缓存是SQLSession级别的缓存。在操作数据库时需要构造 SQLSession对象,在对象中有一个(内存区域)数据结构(HashMap)用于存储缓存数据。不同的SQLSession之间的缓存数据区域(HashMap)是互相不影响的。Mybatis的内部缓存使用一个HashMap,key为hashcode+statementId+sql语句,value为查询出来的结果集映射成的java对象。
一级缓存的作用域是同一个SqlSession,在同一个SQLSession中两次执行相同的sql语句,第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次会从缓存中获取数据将不再从数据库查询,从而提高查询效率。当一个SQLSession结束后该SQLSession中的一级缓存也就不存在了。
只有在同一个SqlsSession中,一级缓存才会生效,如果 SqlSession执行insert、update、delete等操作并且执行SQLSession.commit()或者是SQLSession.close()后会清空该SQLSession缓存,一级缓存随之消失。
Mybatis默认开启一级缓存。
代码示例:
@Test
public void testCache1() throws Exception{
SqlSessionsqlSession = sqlSessionFactory.openSession();//创建代理对象
UserMapperuserMapper = sqlSession.getMapper(UserMapper.class);
// 下边查询使用一个SqlSession
// 第一次发起请求,查询id为1的用户
Useruser1 = userMapper.findUserById(1);
System.out.println(user1);
// 如果sqlSession去执行commit操作(执行插入、更新、删除),清空SqlSession中的一级缓存,
// 这样做的目的为了让缓存中存储的是最新的信息,避免脏读。
//更新user1的信息
user1.setUsername("测试用户22");
userMapper.updateUser(user1);
//执行commit操作去清空缓存
sqlSession.commit();
//第二次发起请求,查询id为1的用户
Useruser2 = userMapper.findUserById(1);
System.out.println(user2);
sqlSession.close();
}
如果不commit的错误流程为:
开始执行时,开启事务,创建SqlSession对象
第一次调用mapper的方法findUserById(1)
更新数据
第二次调用mapper的方法findUserById(1),从一级缓存中取数据
aop控制 只要方法结束,sqlSession关闭 sqlsession关闭后就销毁数据结构,清空缓存
Service结束sqlsession关闭
因为上面有commmit操作,所以正确流程:
开始执行时,开启事务,创建SqlSession对象
第一次调用mapper的方法findUserById(1)
更新数据
清空commit
第二次调用mapper的方法findUserById(1),从一级缓存中无数据,从数据库中取数据
aop控制 只要方法结束,sqlSession关闭 sqlsession关闭后就销毁数据结构,清空缓存
Service结束sqlsession关闭
2.二级缓存
二级缓存介绍
二级缓存是mapper级别的缓存,多个SQLSession去操作同一个Mapper的sql语句,多个SqlSession去操作数据库得到数据会存在二级缓存区域,多个SqlSession可以共用二级缓存,二级缓存是多个SqlSession共享的。
mapper有一个二级缓存区域(按namespace分,如果namespace相同则使用同一个相同的二级缓存区),其它mapper也有自己的二级缓存区域(按namespace分)。也是就是说拥有相同的namespace的Mapper共享一个二级缓存
第一次调用mapper下的SQL去查询用户的信息,查询到的信息会存放代该mapper对应的二级缓存区域。 第二次调用namespace下的mapper映射文件中,相同的sql去查询用户信息,会去对应的二级缓存内取结果。
Mybatis默认是没有开启二级缓存的,开启二级缓存的方法也很简单,在mybatis配置文件中进行如下配置:
<!-- 全局配置参数,需要时再设置 -->
<settings>
<!-- 开启二级缓存 默认值为true -->
<setting name="cacheEnabled" value="true"/>
</settings>
在Mapper.xml中开启二级缓存,Mapper.xml下的sql执行完成会存储到它的缓存区域(HashMap)。
下面是开启redis缓存:
<!-- redis配置项 -->
<cache type="org.mybatis.caches.redis.RedisCache" />
...
如何使用二级缓存
public class User implements Serializable {
//Serializable实现序列化,为了将来反序列化
// 二级缓存测试
@Test
public void testCache2() throws Exception {
SqlSessionsqlSession1 = sqlSessionFactory.openSession();
SqlSessionsqlSession2 = sqlSessionFactory.openSession();
SqlSessionsqlSession3 = sqlSessionFactory.openSession();
// 创建代理对象
UserMapperuserMapper1 = sqlSession1.getMapper(UserMapper.class);
// 第一次发起请求,查询id为1的用户
Useruser1 = userMapper1.findUserById(1);
System.out.println(user1);
//这里执行关闭操作,将sqlsession中的数据写到二级缓存区域
sqlSession1.close();
//使用sqlSession3执行commit()操作
UserMapperuserMapper3 = sqlSession3.getMapper(UserMapper.class);
Useruser = userMapper3.findUserById(1);
user.setUsername("张明明");
userMapper3.updateUser(user);
//执行提交,清空UserMapper下边的二级缓存
sqlSession3.commit();
sqlSession3.close();
UserMapperuserMapper2 = sqlSession2.getMapper(UserMapper.class);
// 第二次发起请求,查询id为1的用户
Useruser2 = userMapper2.findUserById(1);
System.out.println(user2);
sqlSession2.close();
}
执行流程:
sqlsession1中使用findUserById(1)
关闭sqlsession1
sqlsession3中使用findUserById(1),从缓存中取出数据
sqlSession3.commit();
sqlSession3.close()
sqlSession2中使用findUserById(1)无法拿到数据(commit刷新二级缓存)
sqlSession2.close()
36.MySQL的内连接、外连接(左外连接、右外连接、全外连接)以及交叉连接
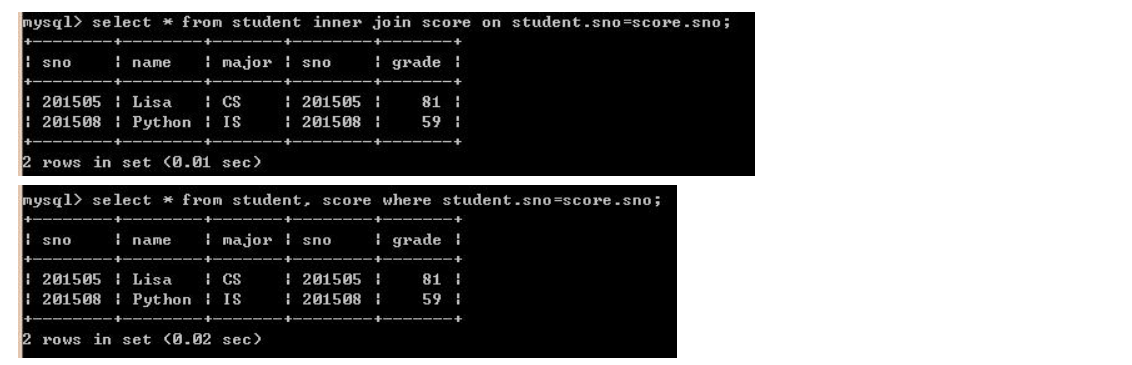
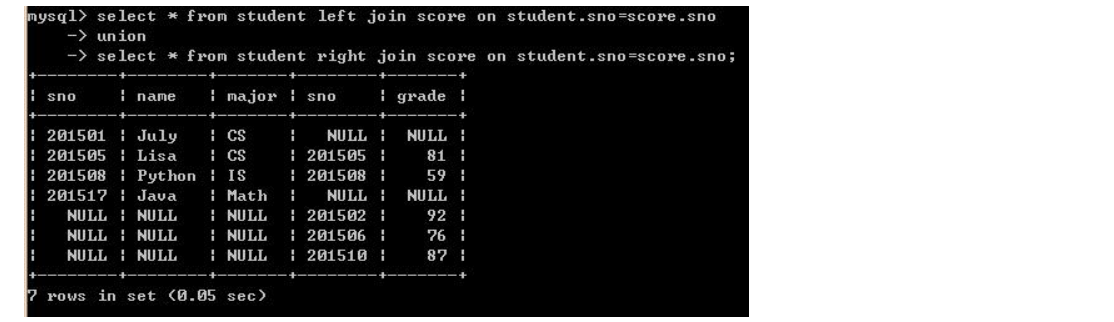
数据库初始表如下:

一、内连接(inner join):结果仅包含符合连接条件的两表中的行。如下:
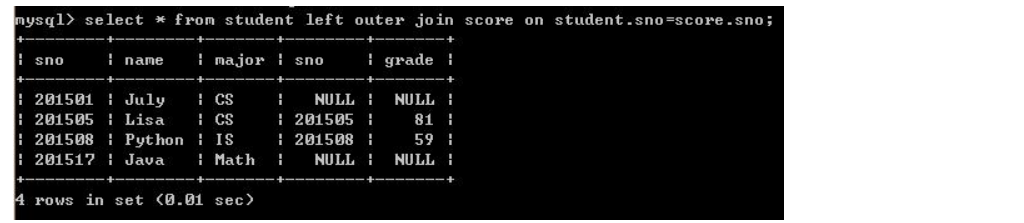
二、外连接(outer join):结果包含符合条件的行,同时包含不符合条件的行(分为左外连接、右外连接和全外连接)
1、左外连接(left [outer join]):左表全部行+右表匹配的行,如果左表中某行 在右表中没有匹配的行,则右表该行显示NULL。如下:
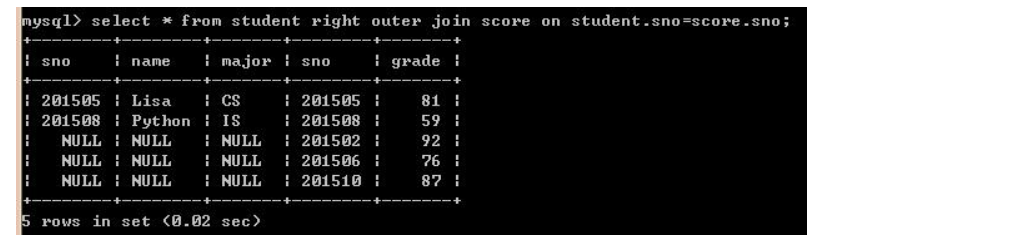
2、右外连接(right [outer join]):和左外连接相反。如下:
3、全外连接(full [outer] join):不管匹配不匹配,全部显示出来,左表在右表没有的显示NULL,右表在左表没有的显示NULL
(MySQL数据库不支持全外连接,因此转换了一种语法,原本写法:select * from student full join score on student.sno=score.sno;)
补充:
-
MySQL实现全外连接可以通过为左外连接 + 右外连接 两者的并集去重后的结果,MySQL的union和union all操作符:将两个结果集合并一个表,比如第一个查询有100条两列,第二个查询结果也为160条两列,故使用union all之后,可以将这两个结果合并成一个,变成260行两列。
-
描述:UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。多个 SELECT 语句会删除重复的数据。
-
MySQL UNION 操作符语法格式:
SELECT expression1, expression2, ... expression_n FROM tables [WHERE conditions] UNION [ALL | DISTINCT] SELECT expression1, expression2, ... expression_n FROM tables [WHERE conditions];参数
- expression1, expression2, … expression_n: 要检索的列。
- tables: 要检索的数据表。
- WHERE conditions: 可选, 检索条件。
- DISTINCT: 可选,删除结果集中重复的数据。默认情况下 UNION 操作符已经删除了重复数据,所以 DISTINCT 修饰符对结果没啥影响。
- ALL: 可选,返回所有结果集,包含重复数据。
- 更多详情可查看链接:
https://blog.csdn.net/helloxiaozhe/article/details/88598003
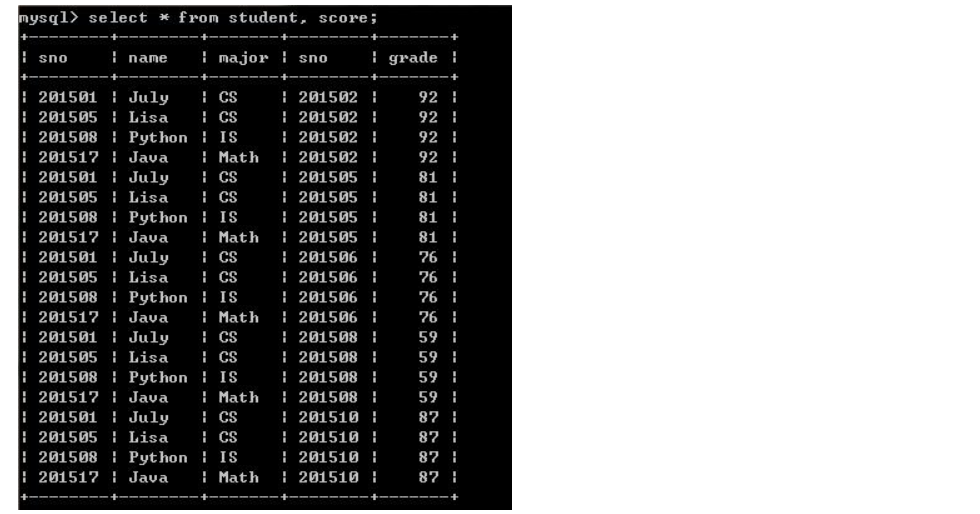
三、交叉连接(cross join):返回左表中所有行与右表中所有行的组合,也称笛卡尔积
————————————————
版权声明:本文为CSDN博主「行者小朱」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u012050154/article/details/52497395
37.MySQL中的事务
一、事务定义
- Transaction
- 事务:一个最小的不可再分的工作单元;通常一个事务对应一个完整的业务(例如银行账户转账业务,该业务就是一个最小的工作单元)
- 一个完整的业务需要批量的DML(insert、update、delete)语句共同联合完成
- 事务只和DML(Data Manipulation Language):数据操纵语句(即增删改查)有关,或者说DML语句才有事务。这个和业务逻辑有关,业务逻辑不同,DML语句的个数不同
二、转账操作理解事务
关于银行账户转账操作,账户转账是一个完整的业务,最小的单元,不可再分————————也就是说银行账户转账是一个事务
以下是银行账户表t_act(账号、余额),进行转账操作
actno balance
1 500
2 100
转账操作
update t_act set balance=400 where actno=1;
update t_act set balance=200 where actno=2;
以上两台DML语句必须同时成功或者同时失败。最小单元不可再分,当第一条DML语句执行成功后,并不能将底层数据库中的第一个账户的数据修改,只是将操作记录了一下;这个记录是在内存中完成的;当第二条DML语句执行成功后,和底层数据库文件中的数据完成同步。若第二条DML语句执行失败,则清空所有的历史操作记录,要完成以上的功能必须借助事务
三、事务四大特征(ACID)
- 原子性**(Atomicity)**:指事务的原子性操作,对数据的修改要么全部执行成功,要么全部失败,实现事务的原子性,是基于日志的
Redo/Undo机制。 - 一致性**(Consistent)**:指执行事务前后的状态要一致,可以理解为数据一致性
- 隔离性**(Isalotion)**:指事务之间相互隔离,不受影响,这个与事务设置的隔离级别有密切的关系。
- 持久性**(Durable)**:指在一个事务提交后,这个事务的状态会被持久化到数据库中,也就是事务提交,对数据的新增、更新将会持久化到数据库中。
总结:原子性、隔离性、持久性都是为了保障一致性而存在的,一致性也是最终的目的。
Redo/Undo机制
- Redo/Undo机制将所有对数据的更新操作都写到日志中。
- Redo log用来记录某数据块被修改后的值,可以用来恢复未写入 data file 的已成功事务更新的数据;Undo log是用来记录数据更新前的值,保证数据更新失败能够回滚。
- 假如数据库在执行的过程中,不小心崩了,可以通过该日志的方式,回滚之前已经执行成功的操作,实现事务的一致性。
- 假如某个时刻数据库崩溃,在崩溃之前有事务A和事务B在执行,事务A已经提交,而事务B还未提交。当数据库重启进行 crash-recovery 时,就会通过Redo log将已经提交事务的更改写到数据文件,而还没有提交的就通过Undo log进行roll back。
四、关于事务的一些术语
- 开启事务:Start Transaction
- 事务结束:End Transaction
- 提交事务:Commit Transaction
- 回滚事务:Rollback Transaction
五、和事务相关的两条重要的SQL语句(TCL)
- commit:提交
- rollback:回滚
六、事务开启的标志?事务结束的标志?
开启标志:
- 任何一条DML语句(insert、update、delete)执行,标志事务的开启
结束标志(提交或者回滚):
- 提交:成功的结束,将所有的DML语句操作历史记录和底层硬盘数据来一次同步
- 回滚:失败的结束,将所有的DML语句操作历史记录全部清空
七、事务与数据库底层数据
在事务进行过程中,未结束之前,DML语句是不会更改底层数据,只是将历史操作记录一下,在内存中完成记录。只有在事务结束的时候,而且是成功的结束的时候,才会修改底层硬盘文件中的数据
八、在MySQL中,事务提交与回滚
在MySQL中,默认情况下,事务是自动提交的,也就是说,只要执行一条DML语句就开启了事务,并且提交了事务,自动提交机制是可以关闭的。如对t_user进行提交和回滚操作,
提交操作(事务成功)
- start transaction
- DML语句
- commit
mysql> start transaction;#手动开启事务
mysql> insert into t_user(name) values('pp');
mysql> commit;#commit之后即可改变底层数据库数据
mysql> select * from t_user;
+----+------+
| id | name |
+----+------+
| 1 | jay |
| 2 | man |
| 3 | pp |
+----+------+
3 rows in set (0.00 sec)
回滚操作(事务失败)
- start transaction
- DML语句
- rollback
mysql> start transaction;
mysql> insert into t_user(name) values('yy');
mysql> rollback;
mysql> select * from t_user;
+----+------+
| id | name |
+----+------+
| 1 | jay |
| 2 | man |
| 3 | pp |
+----+------+
3 rows in set (0.00 sec)
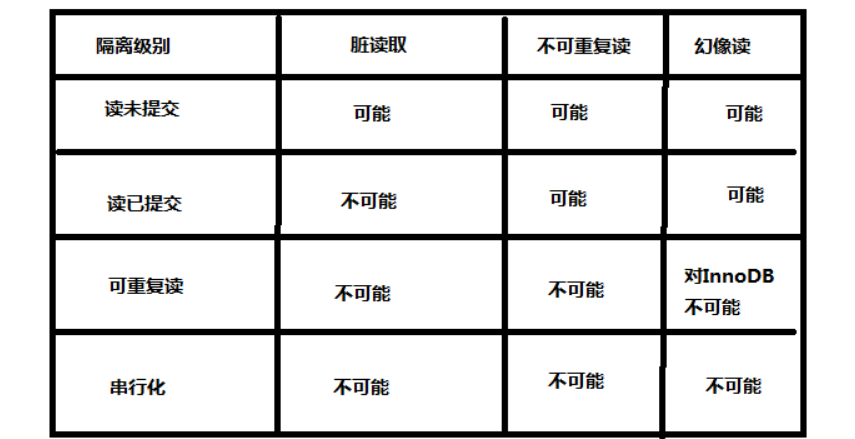
九、事务四大特性之一:隔离性(isolation)
- 事务A和事务B之间具有一定的隔离性
- 隔离性有隔离级别(4个)
- 读未提交:read uncommitted
- 读已提交:read committed
- 可重复读:repeatable read
- 串行化:serializable
1.read uncommitted(读未提交)
- 事务A和事务B,事务A未提交的数据,事务B可以读取到,这里读取到的数据叫做“脏数据”,产生脏读问题
- 这种隔离级别最低,这种级别一般是在理论上存在,数据库隔离级别一般都高于该级别
2、read committed(读已提交)
- 事务A和事务B,事务A提交的数据,事务B才能读取到,这种隔离级别高于读未提交
- 换句话说,对方事务提交之后的数据,我当前事务才能读取到,这种级别可以避免“脏数据”
- 读已提交则解决了脏读,但出现了不可重复读,即在一个事务任意时刻读到的数据可能不一样,可能会受到其它事务对数据修改提交后的影响,一般是对于update的操作。
- Oracle默认隔离级别
3、repeatable read(可重复读)
- 事务A和事务B,事务A提交之后的数据,事务B读取不到
- 这种隔离级别高于读已提交
- 这种隔离级别可以避免”脏读“和“不可重复读取”,达到可重复读取,比如1点和2点读到数据是同一个
- 虽然可以达到可重复读取,但是会导致“幻读”,幻读一般是针对insert操作。例如:第一个事务查询一个User表id=100发现不存在该数据行,这时第二个事务又进来了,新增了一条id=100的数据行并且提交了事务。这时第一个事务新增一条id=100的数据行会报主键冲突,第一个事务再select一下,发现id=100数据行已经存在,这就是幻读。
- MySQL默认级别
4、serializable(串行化)
- 事务A和事务B,事务A在操作数据库时,事务B只能排队等待
- 这种隔离级别很少使用,吞吐量太低,用户体验差
- 这种级别可以避免”脏读“、“不可重复读取”和“幻读”,每一次读取的都是数据库中真实存在数据,事务A与事务B串行,而不并发
十、隔离级别与一致性关系
十一、设置事务隔离级别
1.方式一
- 可以在my.ini文件中使用transaction-isolation选项来设置服务器的缺省事务隔离级别。
- 该选项值可以是:
– READ-UNCOMMITTED
– READ-COMMITTED
– REPEATABLE-READ
– SERIALIZABLE
• 例如:
[mysqld]
transaction-isolation = READ-COMMITTED
2.方式二
- 通过命令动态设置隔离级别
- 隔离级别也可以在运行的服务器中动态设置,应使用
SET TRANSACTION ISOLATION LEVEL语句。 - 其语法模式为:
SET [GLOBAL | SESSION] TRANSACTION ISOLATION LEVEL <isolation-level>
其中的<isolation-level>可以是:
– READ UNCOMMITTED
– READ COMMITTED
– REPEATABLE READ
– SERIALIZABLE
• 例如: SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
十二、隔离级别的作用范围
事务隔离级别的作用范围分为两种:
- 全局级:对所有的会话有效
- 会话级:只对当前的会话有效
十三、设置隔离级别
• 例如,设置会话级隔离级别为READ COMMITTED :
mysql> SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
或:
mysql> SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
• 设置全局级隔离级别为READ COMMITTED :
mysql> SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED;
设置会话的隔离级别,隔离级别由低到高设置依次为:
set session transaction isolation level read uncommitted;
set session transaction isolation level read committed;
set session transaction isolation level repeatable read;
set session transaction isolation level serializable;
设置当前系统的隔离级别,隔离级别由低到高设置依次为:
set global transaction isolation level read uncommitted;
set global transaction isolation level read committed;
set global transaction isolation level repeatable read;
set global transaction isolation level serializable;
十四、查看隔离级别
1、查看当前会话的 隔离级别:
select @@tx_isolation;(MySQL5版本)
select @@transaction_isolation; (MySQL8版本)
2、查看系统的隔离级别:
select @@global.tx_isolation; (MySQL5版本)
select @@global.transaction_isolation; (MySQL8版本)
十五、MySQL默认操作模式为自动提交模式
除非显示的开启一个事务,否则每个查询都被当成一个单独的事务自动执行。可以通脱设置autocommit的值改变默认的提交模式。
- 查看当前提交模式
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
- 关闭自动提交。0代表关闭,1代表开启。
mysql> set autocommit = 0;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | OFF |
+---------------+-------+
- JDBC处理事务
Connection connection = null;
PreparedStatement pstmt = null;
ResultSet resultSet = null;
try {
Class.forName("com.mysql.jdbc.Driver");
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/dbname?characterEncoding=utf-8","username", "password");
connection.setAutoCommit(false);
// others ......
connection.commit();
} catch (Exception e) {
connection.rollback();
} finally {
connection.setAutoCommit(true);
// close connection
}
十六、Mysql的锁机制
- 四大隔离级别越往上,隔离的效果是逐渐增强,但是性能却是越来越差
- 在Mysql中的锁可以分为分享锁/读锁(Shared Locks)、排他锁/写锁(Exclusive Locks) 、间隙锁、行锁(Record Locks)、表锁。
- 共享锁是针对同一份数据,多个读操作可以同时进行,简单来说即读加锁,不能写并且可并行读;
- 排他锁针对写操作,假如当前写操作没有完成,那么它会阻断其它的写锁和读锁,即写加锁,其它读写都阻塞 。
- 而行锁和表锁,是从锁的粒度上进行划分的,行锁锁定当前数据行,锁的粒度小,加锁慢,发生锁冲突的概率小,并发度高,行锁也是MyISAM和InnoDB的区别之一,InnoDB支持行锁并且支持事务 。
- 而表锁则锁的粒度大,加锁快,开销小,但是锁冲突的概率大,并发度低。
- 间隙锁则分为两种:
Gap Locks和Next-Key Locks。Gap Locks会锁住两个索引之间的区间,比如select * from User where id>3 and id<5 for update,就会在区间(3,5)之间加上Gap Locks。 - Next-Key Locks是Gap Locks+Record Locks形成闭区间锁select * from User where id>=3 and id=<5 for update,就会在区间[3,5]之间加上Next-Key Locks。
- 在数据库的增、删、改、查中,只有增、删、改才会加上排它锁,而只是查询并不会加锁,只能通过在select语句后显式加lock in share mode或者for update来加共享锁或者排它锁。
- 在四个隔离级别中加锁肯定是要消耗性能的,而读未提交是没有加任何锁的,所以对于它来说也就是没有隔离的效果,所以它的性能也是最好的。
- 对于串行化加的是一把大锁,读的时候加共享锁,不能写,写的时候,加的是排它锁,阻塞其它事务的写入和读取,若是其它的事务长时间不能写入就会直接报超时,所以它的性能也是最差的,对于它来就没有什么并发性可言。
- 对于读提交和可重复读,他们俩的实现是兼顾解决数据问题,然后又要有一定的并发行,所以在实现上锁机制会比串行化优化很多,提高并发性,所以性能也会比较好。他们俩的底层实现采用的是MVCC(多版本并发控制)方式进行实现。
MVCC(多版本并发控制)
- 在实现MVCC时用到了一致性视图,用于支持读提交和可重复读的实现。
- 在实现可重复读的隔离级别,只需要在事务开始的时候创建一致性视图,也叫做快照,之后的查询里都共用这个一致性视图,后续的事务对数据的更改是对当前事务是不可见的,这样就实现了可重复读。
- 而读提交,每一个语句执行前都会重新计算出一个新的视图,这个也是可重复读和读提交在MVCC实现层面上的区别。
快照(视图)在MVCC底层是怎么工作的?
- 在InnoDB 中每一个事务都有一个自己的事务id,并且是唯一的,递增的 。
- 对于Mysql中的每一个数据行都有可能存在多个版本,在每次事务更新数据的时候,都会生成一个新的数据版本,并且把自己的数据id赋值给当前版本的row trx_id。
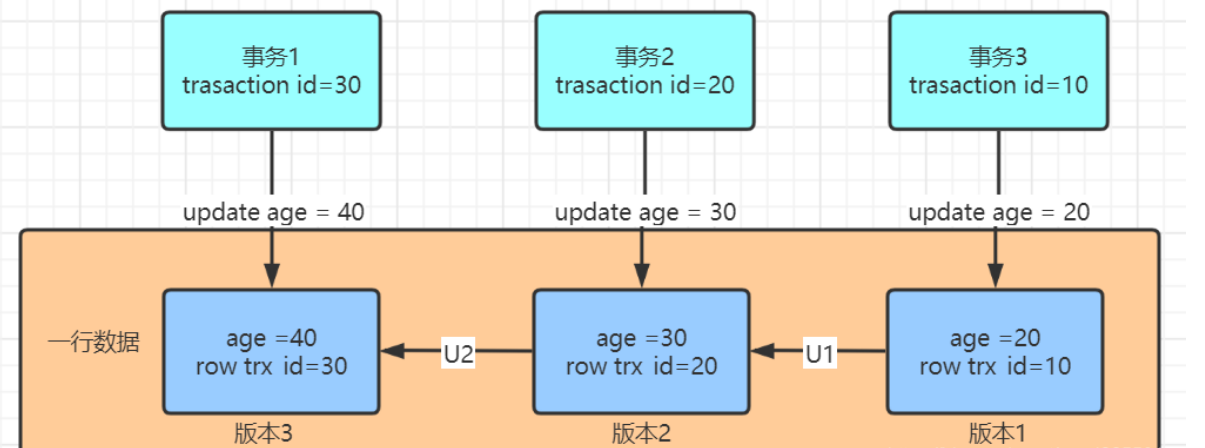
- 如图中所示,假如三个事务更新了同一行数据,那么就会有对应的三个数据版本。
- 实际上版本1、版本2并非实际物理存在的,而图中的U1和U2实际就是undo log,这v1和v2版本是根据当前v3和undo log计算出来的。
对于一个快照来说,它要遵循什么规则?
- 对于一个事务视图来说除了对自己更新的总是可见,另外还有三种情况:版本未提交的,都是不可见的;版本已经提交,但是是在创建视图之后提交的也是不可见的;版本已经提交,若是在创建视图之前提交的是可见的。
假如两个事务执行写操作,又怎么保证并发呢?
- 假如事务1和事务2都要执行update操作,事务1先update数据行的时候,先回获取行锁,锁定数据,当事务2要进行update操作的时候,也会取获取该数据行的行锁,但是已经被事务1占有,事务2只能wait。
- 若是事务1长时间没有释放锁,事务2就会出现超时异常 。(在update的where后的条件是在有索引的情况下)
- 若是没有索引的条件下,就获取所有行,都加上行锁,然后Mysql会再次过滤符合条件的的行并释放锁,只有符合条件的行才会继续持有锁。这样的性能消耗也会比较大。
38.mybatis别名
在MyBatis引用类,可以有3种方式,下面逐一介绍。一般来说使用第3重。
1.方式一
在mapper.xml文件中,比如如下的配置:
</select>
<select id="selById2" resultType="com.susu.pojo.People" parameterType="com.susu.pojo.People">
select * from people where id = #{id}
</select>
可见,参数类型和返回值类型都是com.susu.pojo.People,每次都要写这么长长的一串,并且如果mapper.xml中频繁的应用到com.susu.pojo.People,就会非常麻烦。
2.方式二
MyBatis提供了别名的全局配置。如下,在mybatis.xml这个全局配置文件中,做如下配置:
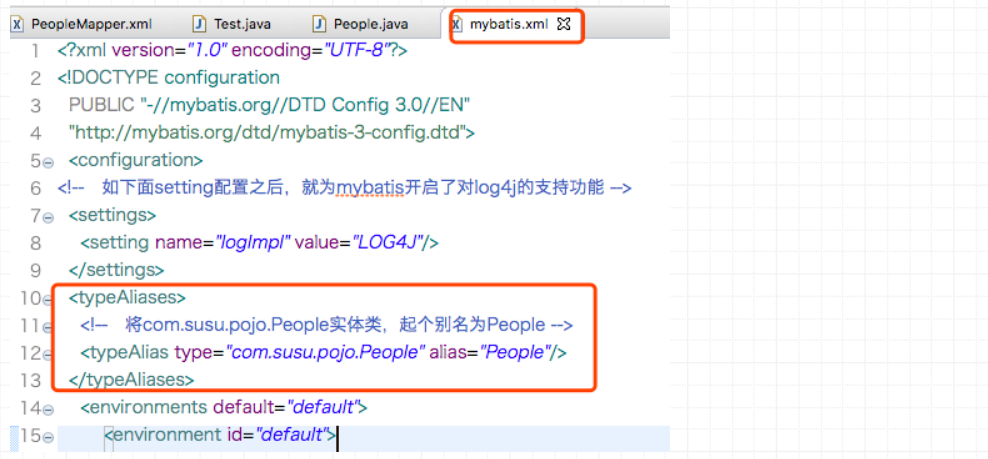
如此,之后再mapper.xml文件中,就可以只要做如下配置即可:
</select>
<select id="selById2" resultType="People" parameterType="People">
select * from people where id = #{id}
</select>
3.方式三
但是上面这种方法,如果项目中有50个实体类,那么mybatis.xml配置文件中就需要写50个像下面这样的配置。
<typeAlias type="com.susu.pojo.People" alias="People"/>
这样同样太麻烦了。因此,可以在mybatis.xml全局配置文件中,做如下配置:
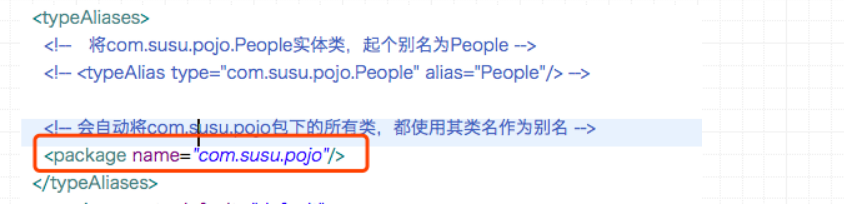
如此一来,当mapper.xml配置文件中,要用到com.susu.pojo.People实体类时,就只要写people就可以了。
4.总结
综上可知,MyBatis别名存在的主要意义就是简化开发。此外,系统还有内置别名:把类型全小写,比如java中Map的别名是map
38.spring
38.spring中的事务

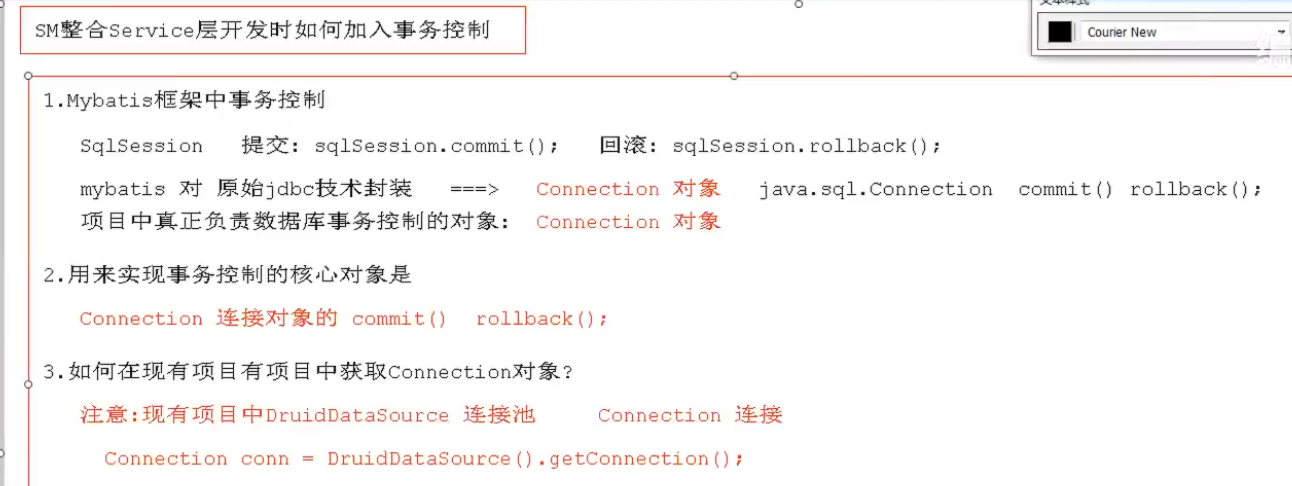

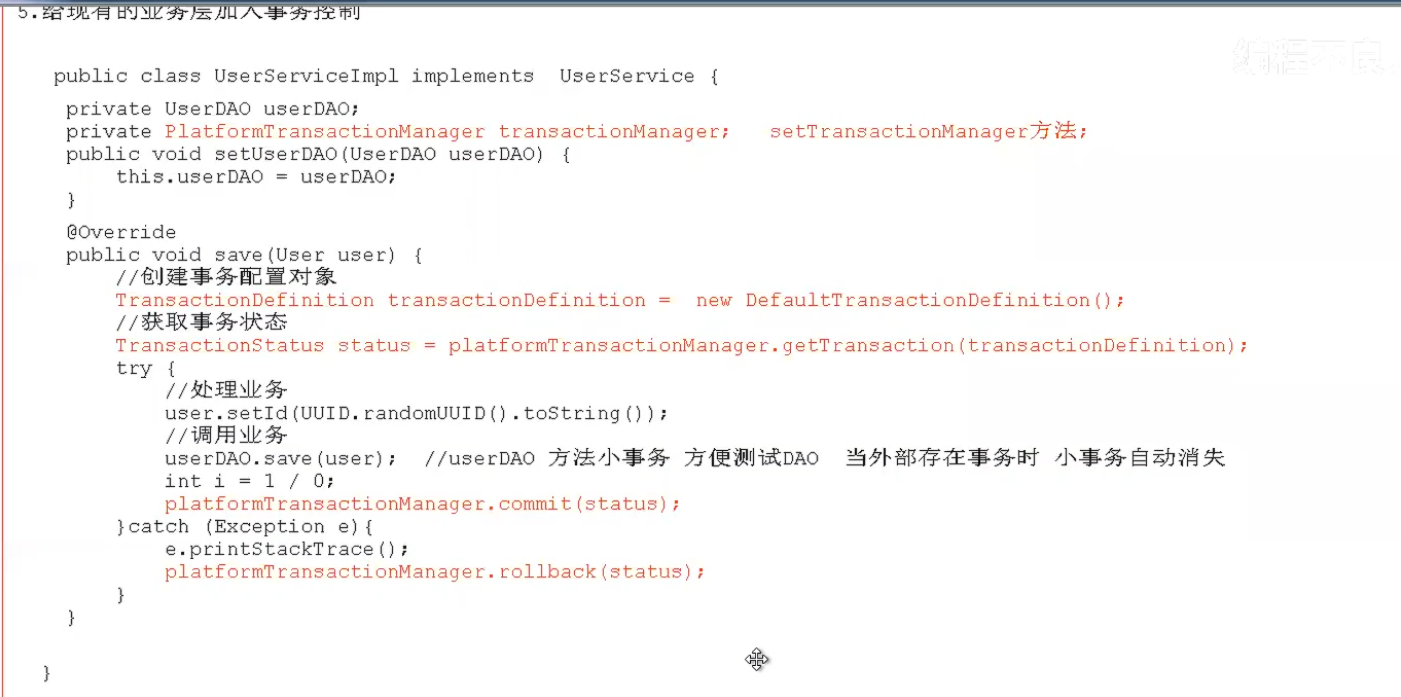
1.事务的传播属性
事务传播:在多个业务层之间相互调用时传递事务的过程,所谓的事务传播即支持链接connection对象的传播,由外层方法把事务传递给内层业务调用的过程就叫事务传播
Spring事务本质是对数据库事务的支持,如果数据库不支持事务(例如MySQL的MyISAM引擎不支持事务),则Spring事务也不会生效。
PROPAGATION:事务的传播属性
REQUIRED:表示需要事务,如果外层没有事务,则开启新的事务;如果外层存在事务,则融入当前事务。spring中默认的属性,一般用于增删改SUPPORTS:表示支持事务,如果外层没有事务,则不会开启新的事务;如果外层存在事务,则融入当前事务,一般用于查询REQUIRED_NEW:表示每次开启新的事务,如果外层存在事务,外层事务挂起;自己开启新的事务执行,执行完成,恢复外层事务继续执行。事务之间互不影响NOT_SUPPORTS:表示不支持事务,如果外层存在事务,外层事务挂起,自己以非事务方式执行,执行完成,恢复外层事务NEVER:表示不能有事务,如果存在事务(外层)则报错MANDATORY:表示强制事务,如果没有事务(外层)则报错NESTED:表示嵌套事务,事务之间可以嵌套执行,目前oracle、mysql还不支持
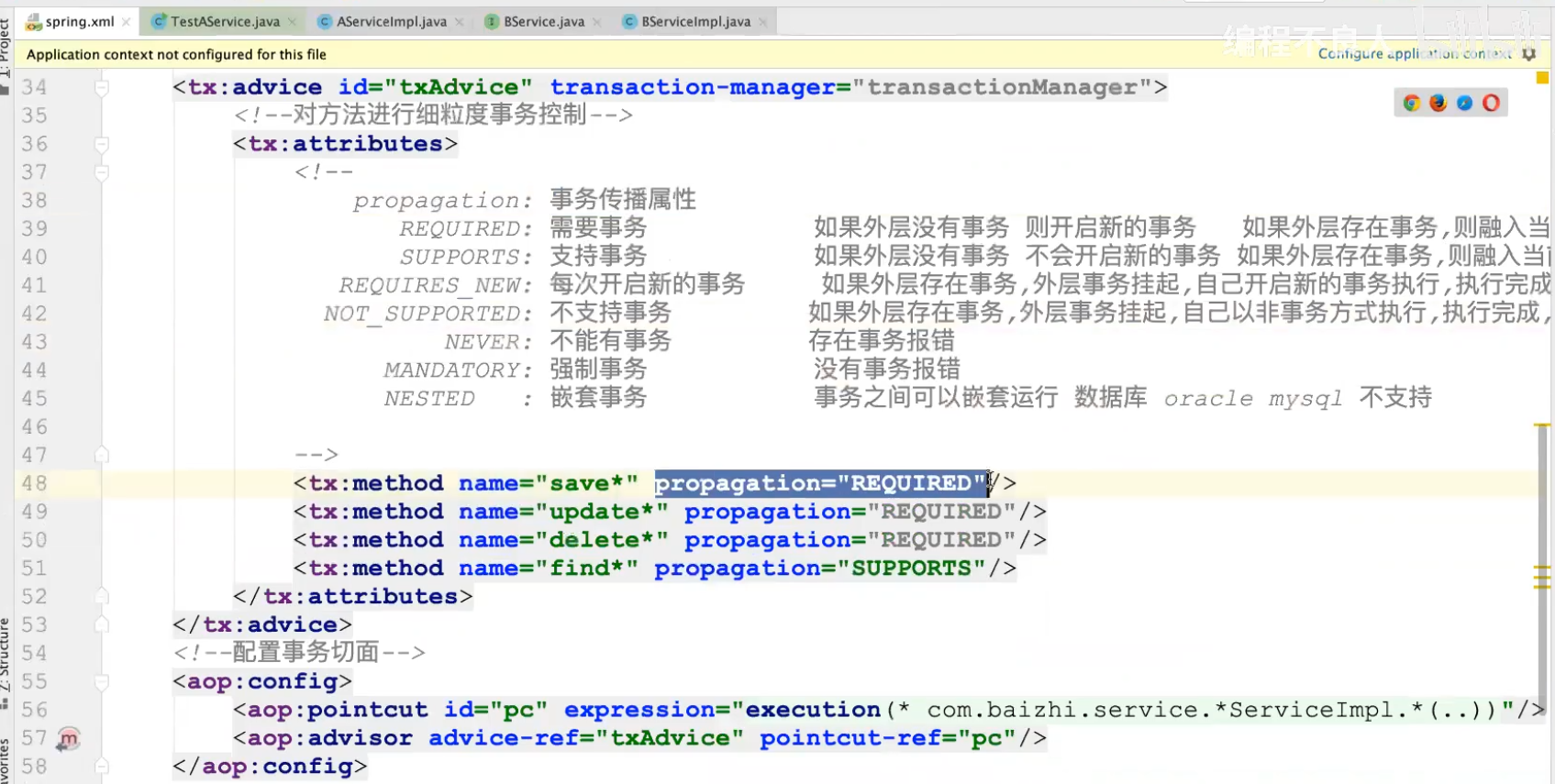
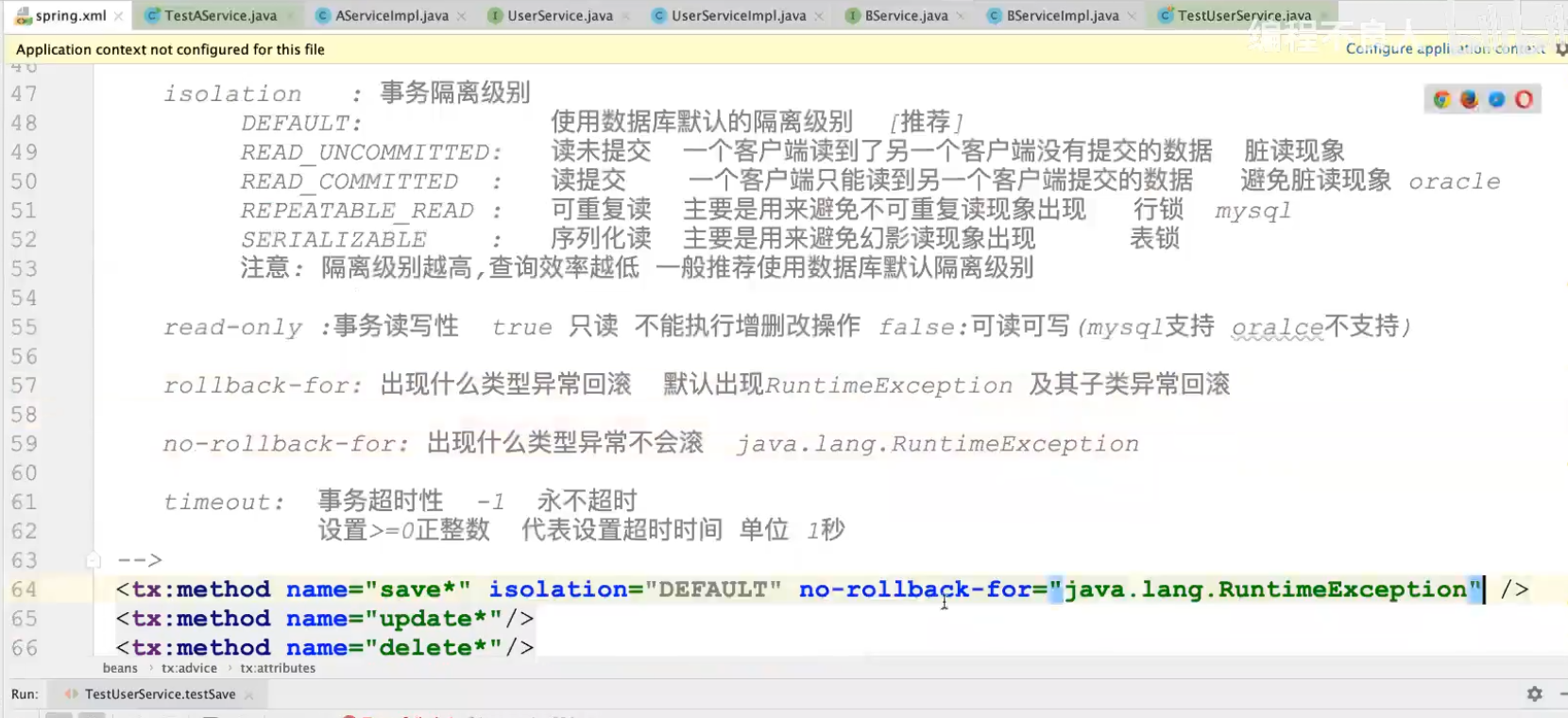
2.事务的隔离级别
isolation:事务隔离级别
- DEFAULT:使用数据库默认的隔离级别,推荐
- READ_UNCOMMITTED:读未提交
- read committed:读已提交
- repeatable read:可重复读
- serializable:串行化
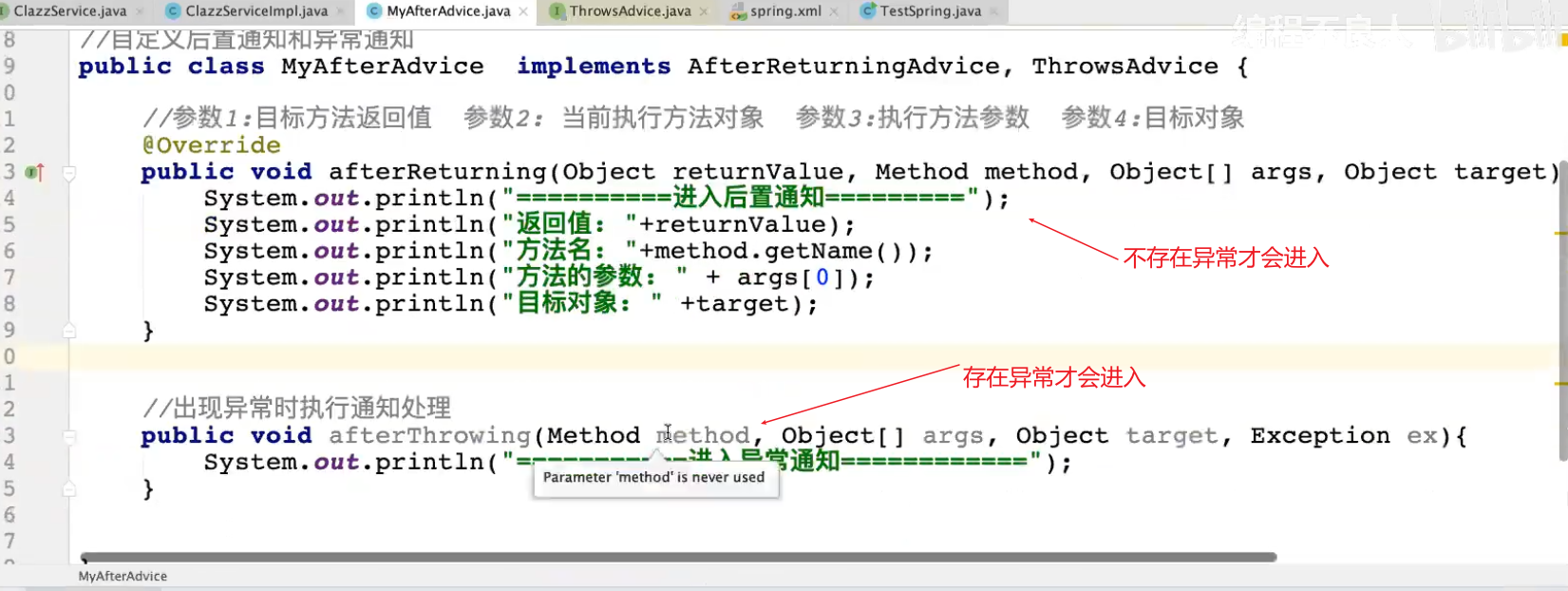
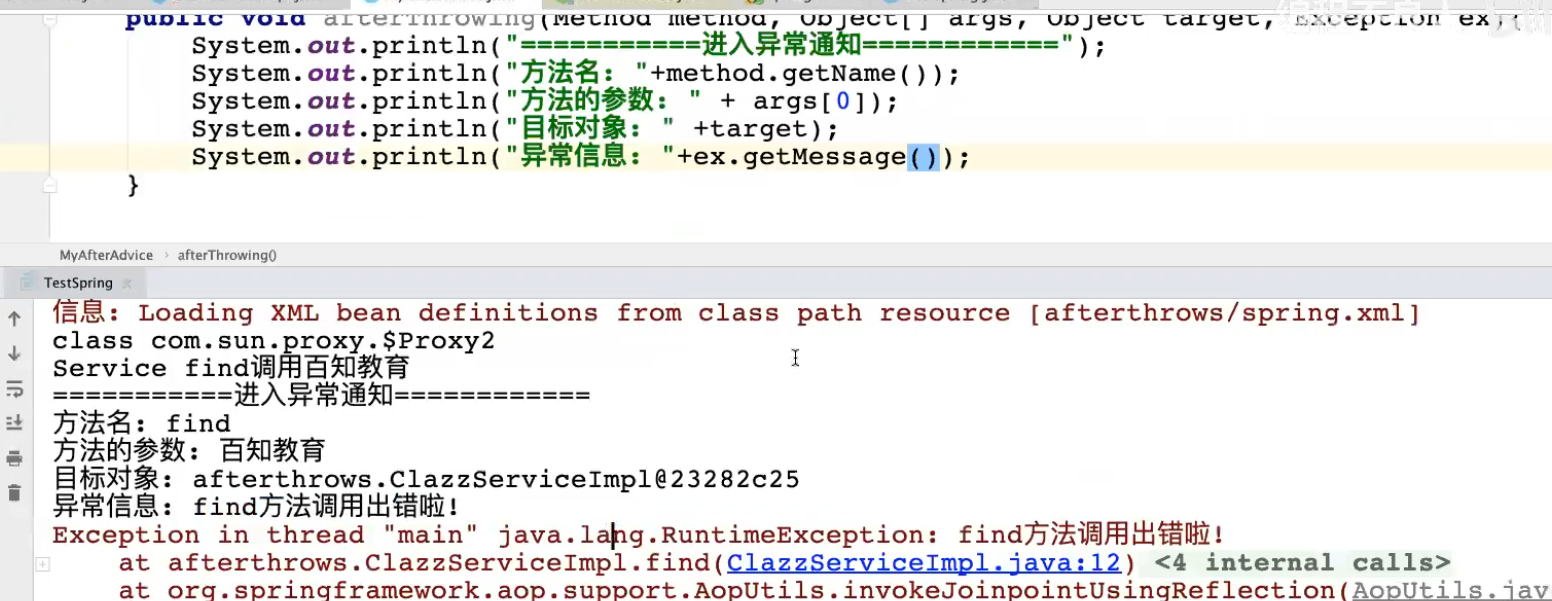
39.AOP机制
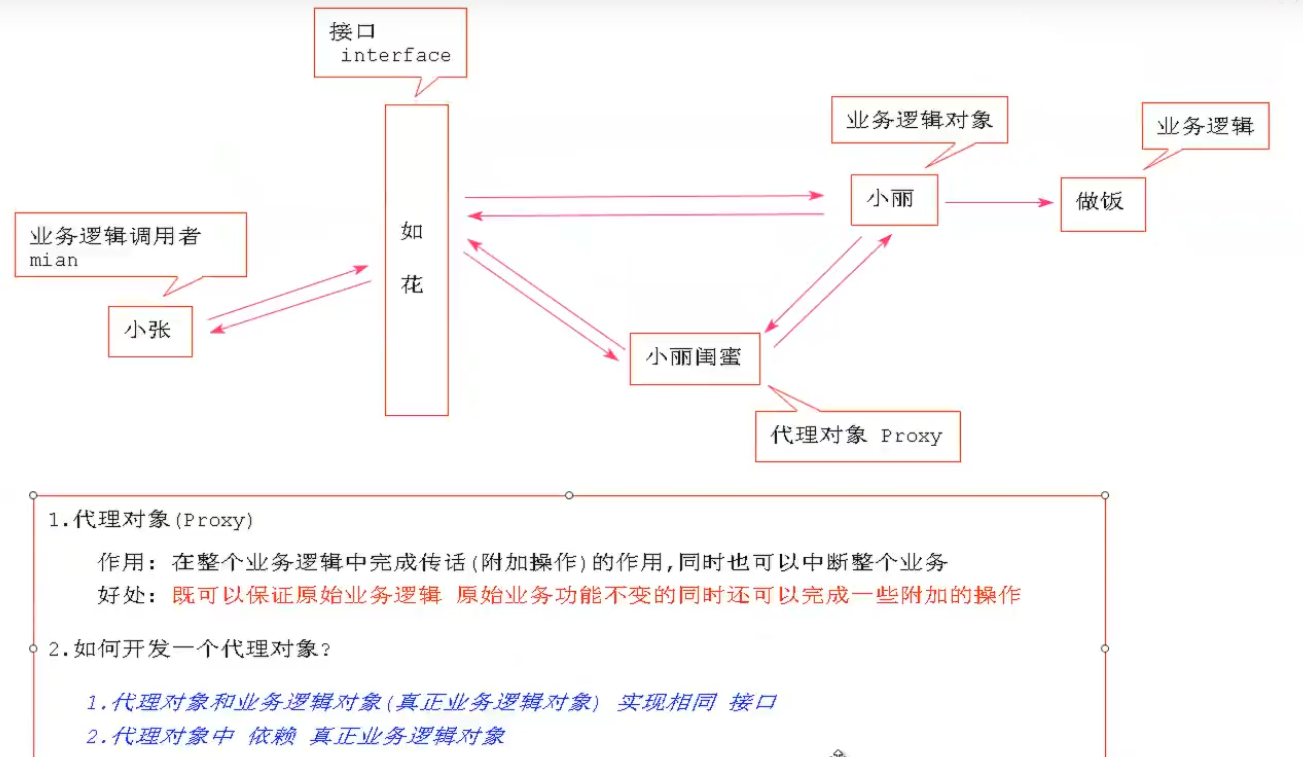
1.静态代理

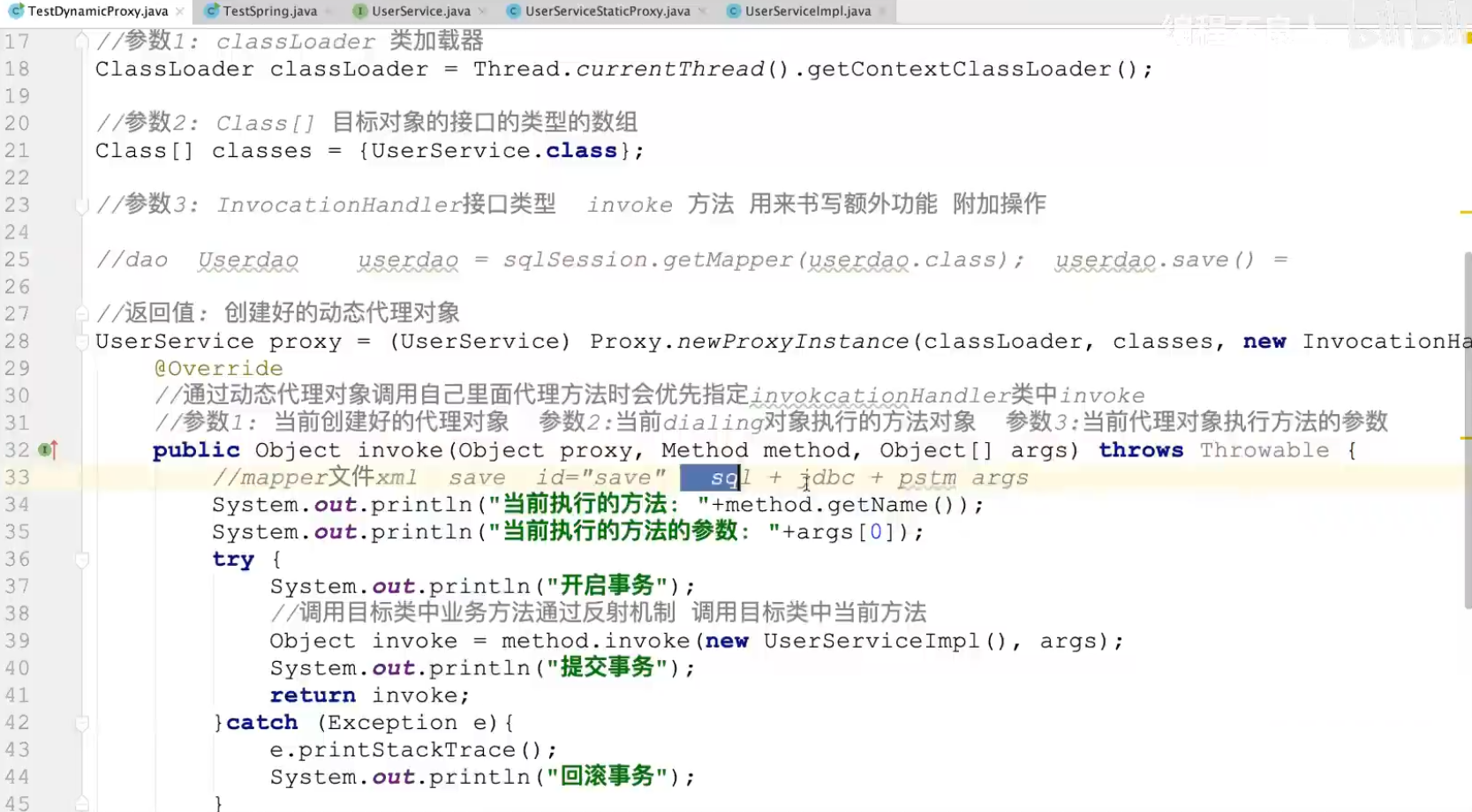
2.动态代码

3.AOP
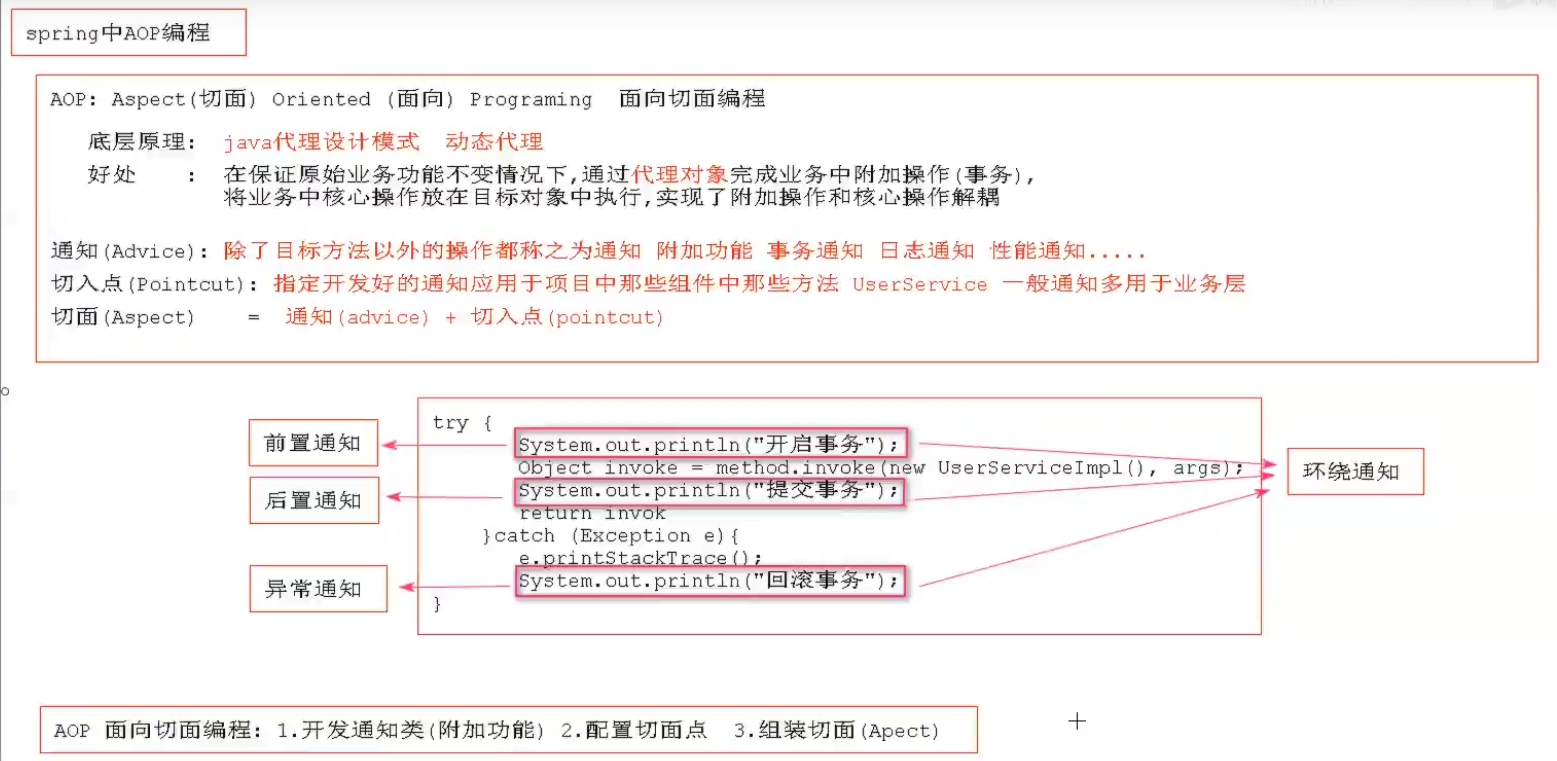
前置通知

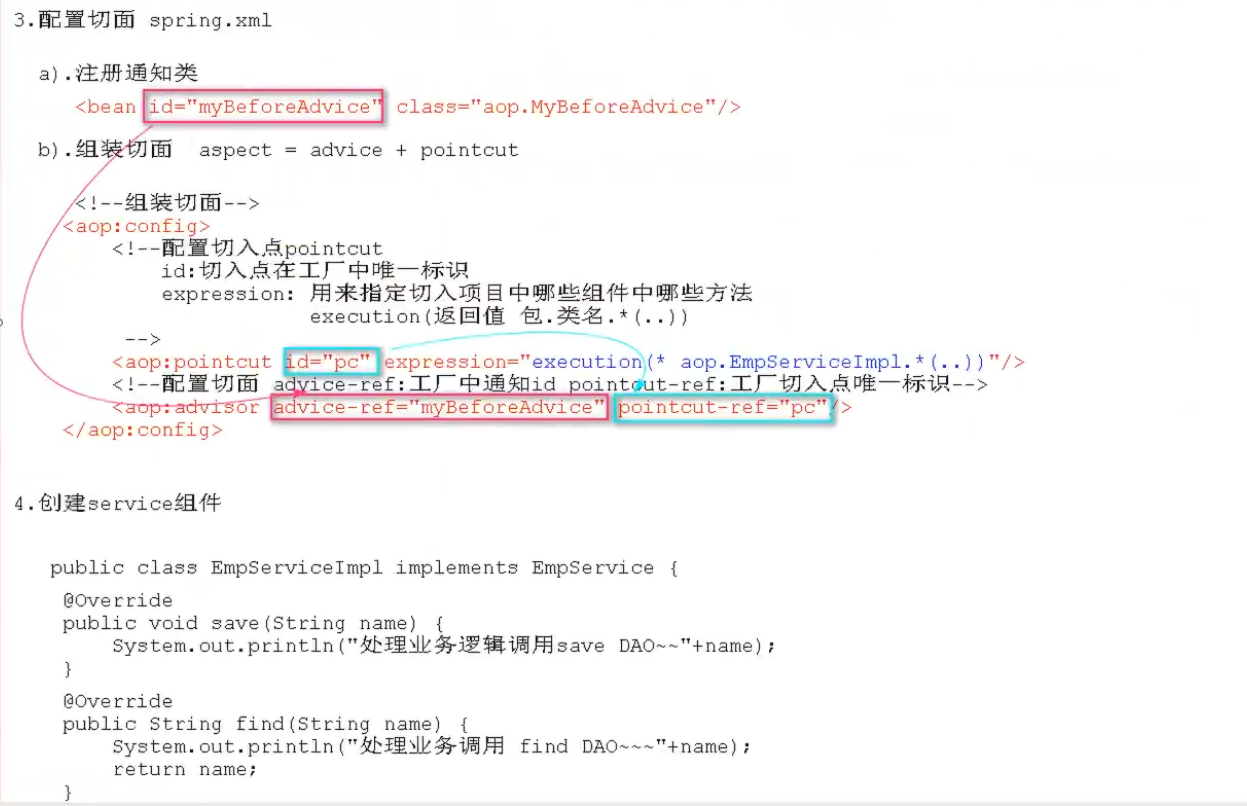

环绕通知


切入点表达式



后置通知
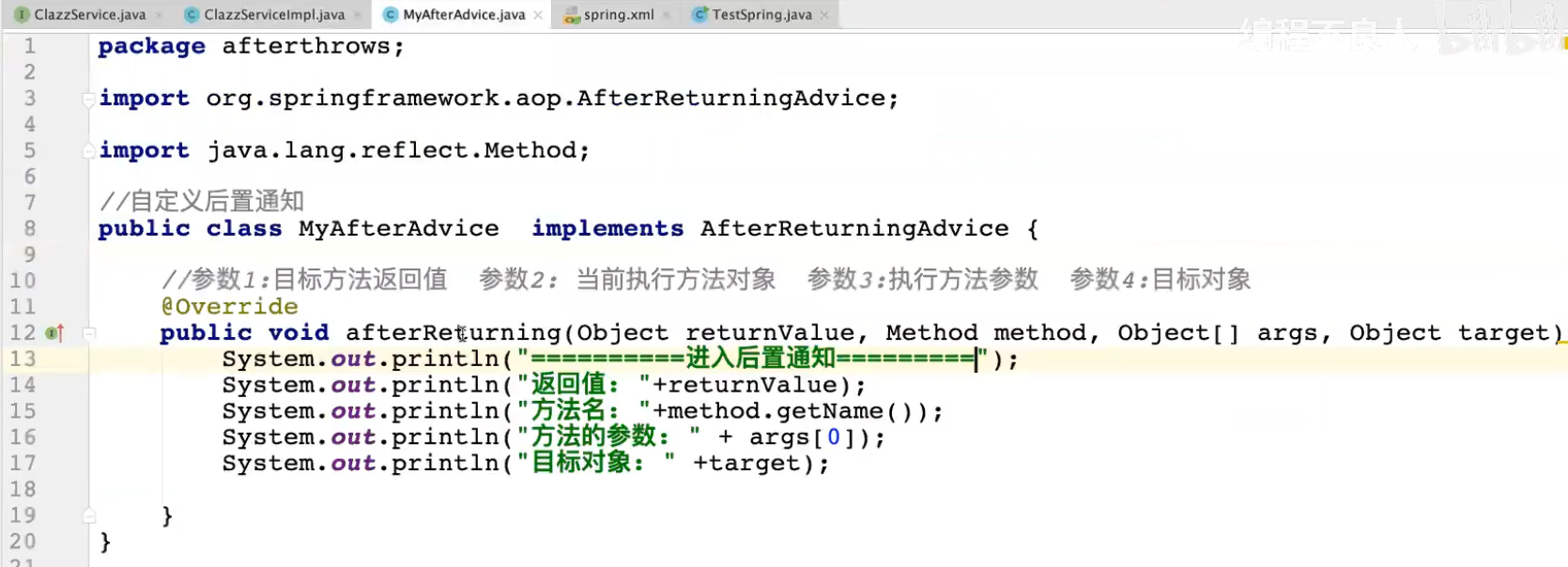
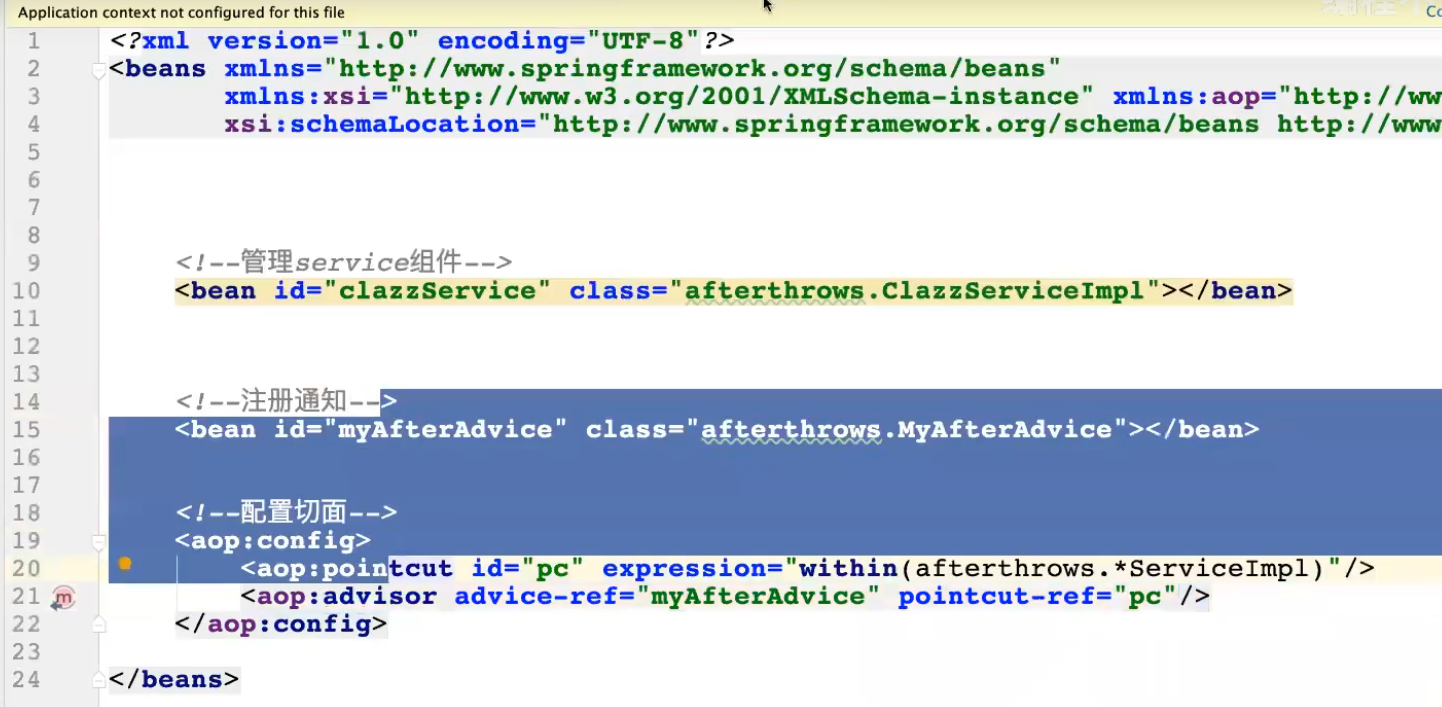
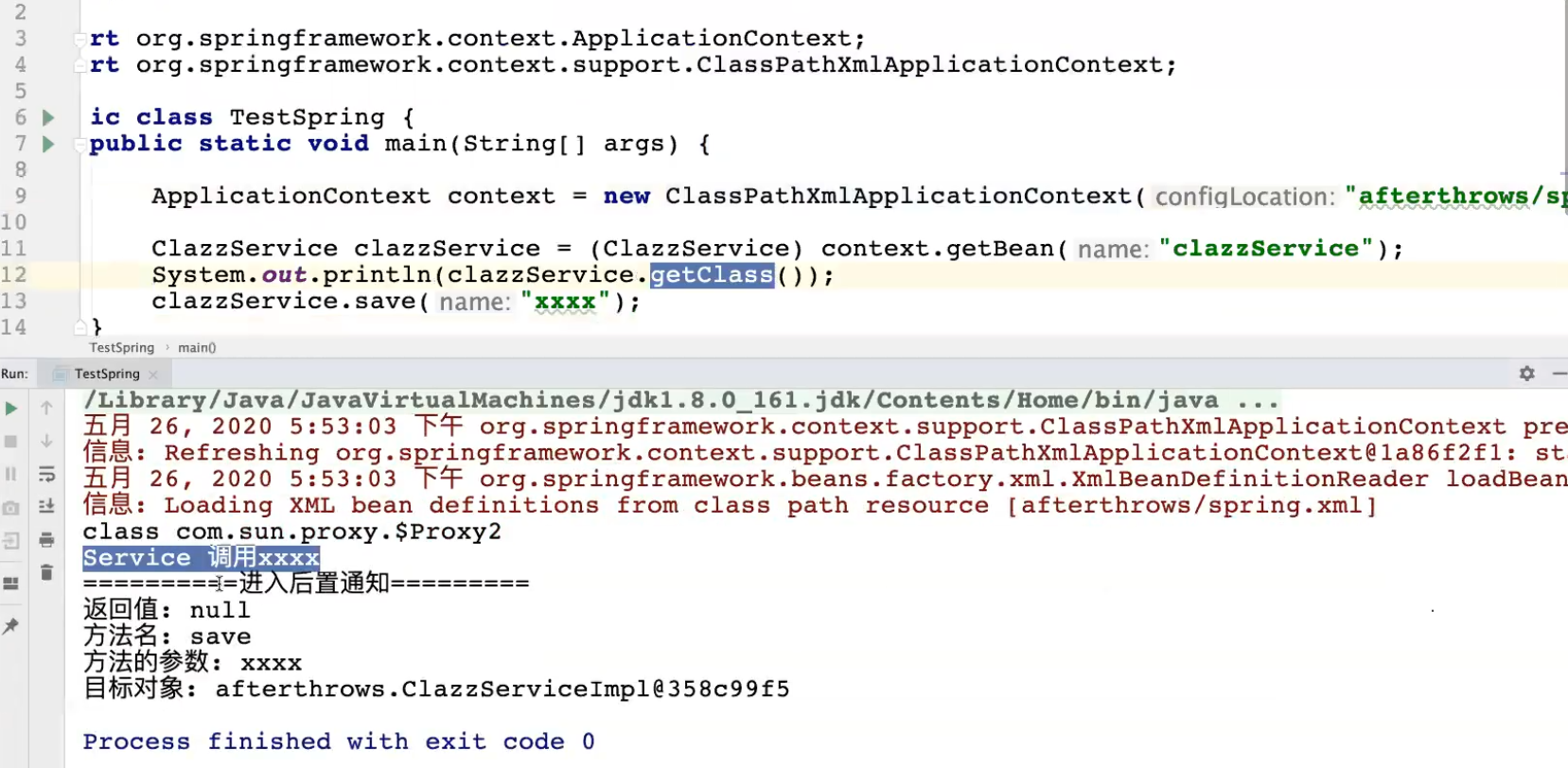
异常通知
40.IOC和DI
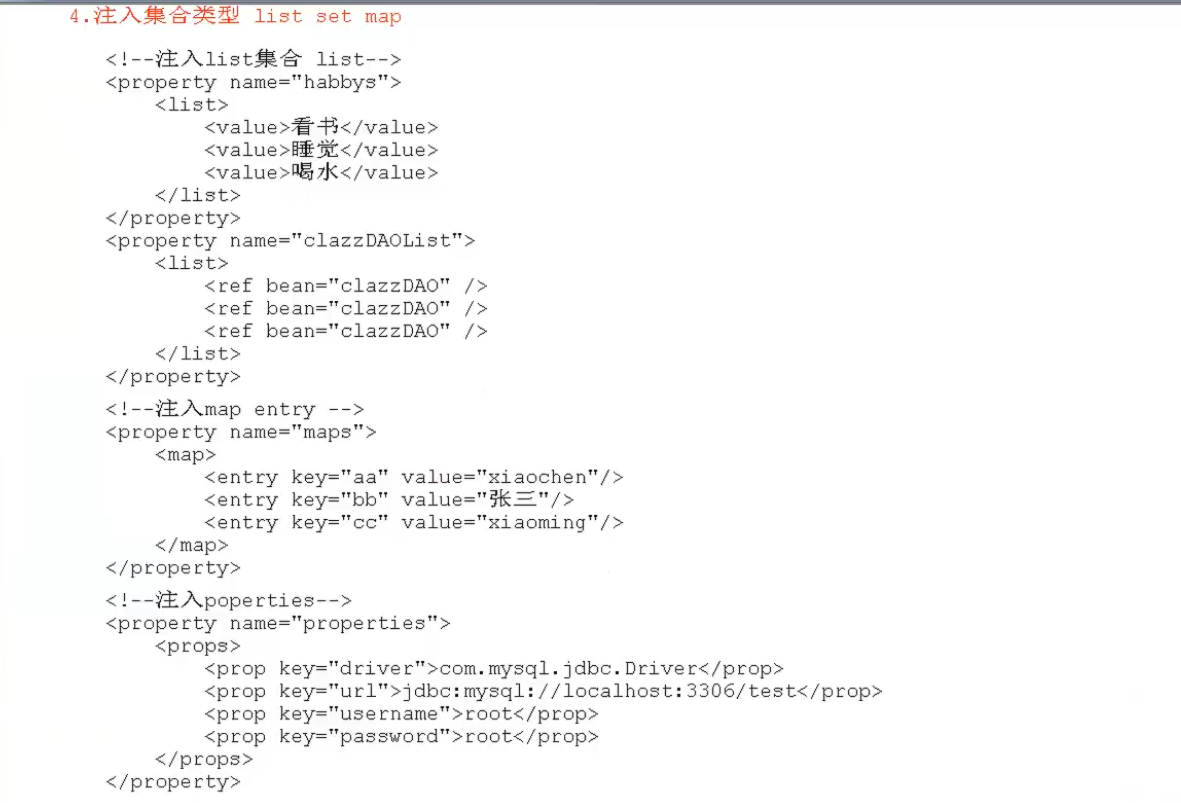
1.spring中的三种注入方式
1.set方式注入


2.构造注入
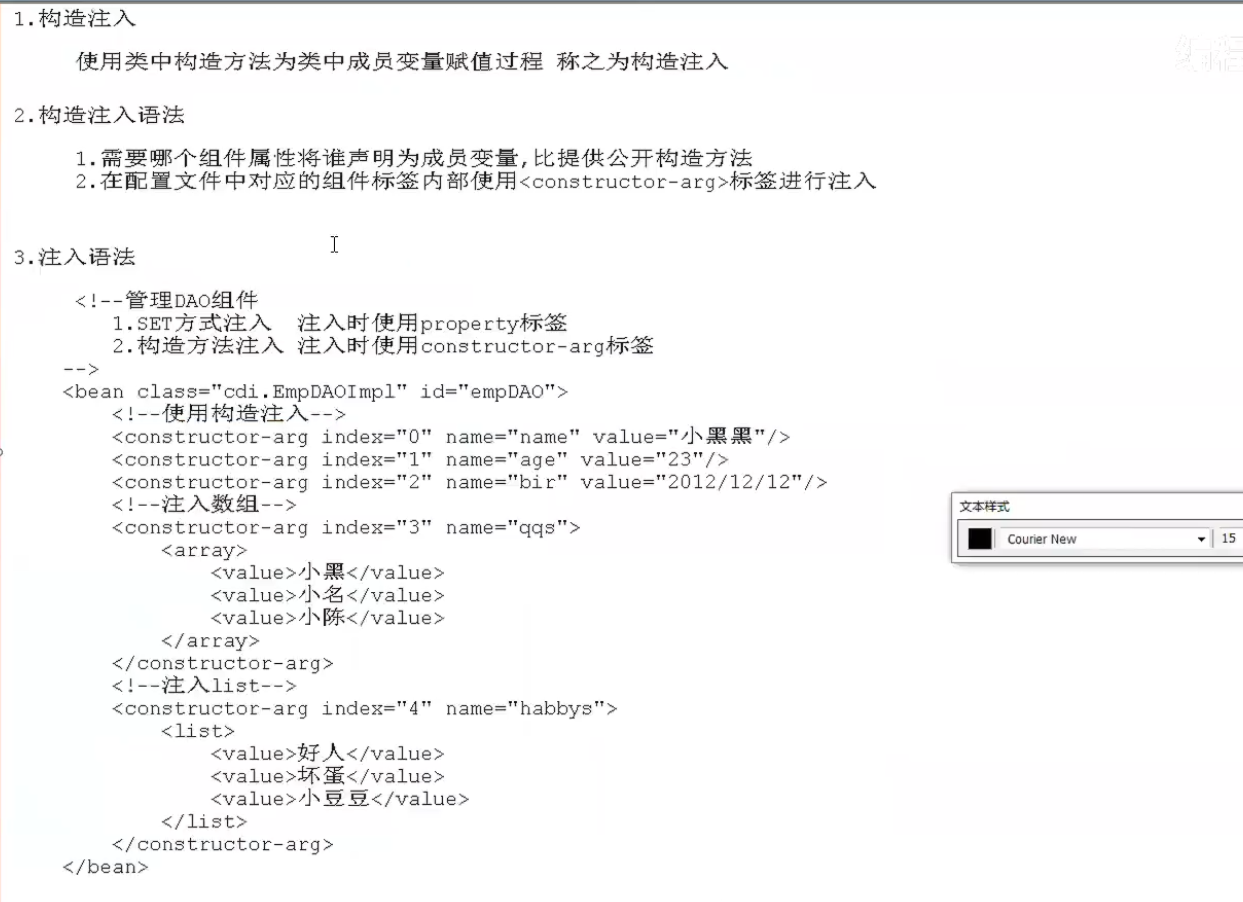
3.自动注入

2.bean的作用域与生命周期
1.bean的作用域
在Spring中,那些组成应用程序的主体及由Spring IoC容器所管理的对象,被称之为bean。简单地讲,bean就是由IoC容器初始化、装配及管理的对象,除此之外,bean就与应用程序中的其他对象没有什么区别了。而bean的定义以及bean相互间的依赖关系将通过配置元数据来描述。
Spring中的bean默认都是单例的,对于Web应用来说,Web容器对于每个用户请求都创建一个单独的Sevlet线程来处理请求,引入Spring框架之后,每个Action都是单例的,那么对于Spring托管的单例Service Bean,Spring的单例是基于BeanFactory也就是Spring容器的,单例Bean在此容器内只有一个,Java的单例是基于JVM,每个JVM内只有一个实例。
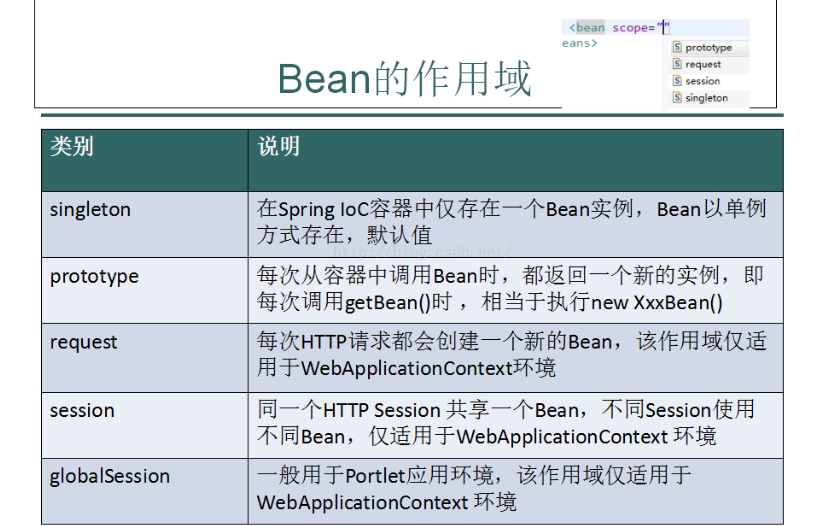
五种作用域中,request、session和global session三种作用域仅在基于web的应用中使用(不必关心你所采用的是什么web应用框架),只能用在基于web的Spring ApplicationContext环境。
(1)当一个bean的作用域为Singleton,那么Spring IoC容器中只会存在一个共享的bean实例,并且所有对bean的请求,只要id与该bean定义相匹配,则只会返回bean的同一实例。Singleton是单例类型,就是在创建起容器时就同时自动创建了一个bean的对象,不管你是否使用,他都存在了,每次获取到的对象都是同一个对象。注意,Singleton作用域是Spring中的缺省作用域。要在XML中将bean定义成singleton,可以这样配置:
<bean id="ServiceImpl" class="cn.csdn.service.ServiceImpl" scope="singleton">
(2)当一个bean的作用域为Prototype,表示一个bean定义对应多个对象实例。Prototype作用域的bean会导致在每次对该bean请求(将其注入到另一个bean中,或者以程序的方式调用容器的getBean()方法)时都会创建一个新的bean实例。Prototype是原型类型,它在我们创建容器的时候并没有实例化,而是当我们获取bean的时候才会去创建一个对象,而且我们每次获取到的对象都不是同一个对象。根据经验,对有状态的bean应该使用prototype作用域,而对无状态的bean则应该使用singleton作用域。在XML中将bean定义成prototype,可以这样配置:
<bean id="account" class="com.foo.DefaultAccount" scope="prototype"/>
<!--或者-->
<bean id="account" class="com.foo.DefaultAccount" singleton="false"/>
(3)当一个bean的作用域为Request,表示在一次HTTP请求中,一个bean定义对应一个实例;即每个HTTP请求都会有各自的bean实例,它们依据某个bean定义创建而成。该作用域仅在基于web的Spring ApplicationContext情形下有效。考虑下面bean定义:
<bean id="loginAction" class=com.foo.LoginAction" scope="request"/>
(4)当一个bean的作用域为Session,表示在一个HTTP Session中,一个bean定义对应一个实例。该作用域仅在基于web的Spring ApplicationContext情形下有效。考虑下面bean定义:
<bean id="userPreferences" class="com.foo.UserPreferences" scope="session"/>
针对某个HTTP Session,Spring容器会根据userPreferences bean定义创建一个全新的userPreferences bean实例,且该userPreferences bean仅在当前HTTP Session内有效。与request作用域一样,可以根据需要放心的更改所创建实例的内部状态,而别的HTTP Session中根据userPreferences创建的实例,将不会看到这些特定于某个HTTP Session的状态变化。当HTTP Session最终被废弃的时候,在该HTTP Session作用域内的bean也会被废弃掉。
(5)当一个bean的作用域为Global Session,表示在一个全局的HTTP Session中,一个bean定义对应一个实例。典型情况下,仅在使用portlet context的时候有效。该作用域仅在基于web的Spring ApplicationContext情形下有效。考虑下面bean定义:
<bean id="user" class="com.foo.Preferences "scope="globalSession"/>
global session作用域类似于标准的HTTP Session作用域,不过仅仅在基于portlet的web应用中才有意义。Portlet规范定义了全局Session的概念,它被所有构成某个portlet web应用的各种不同的portlet所共享。在global session作用域中定义的bean被限定于全局portlet Session的生命周期范围内。
2.bean的生命周期
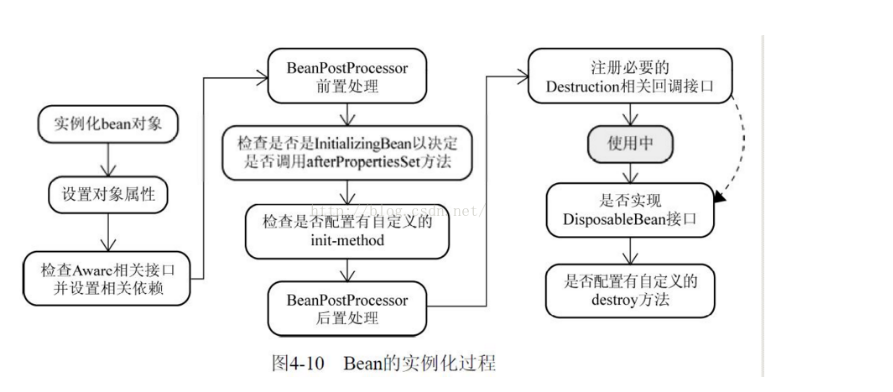
Spring中Bean的实例化过程:
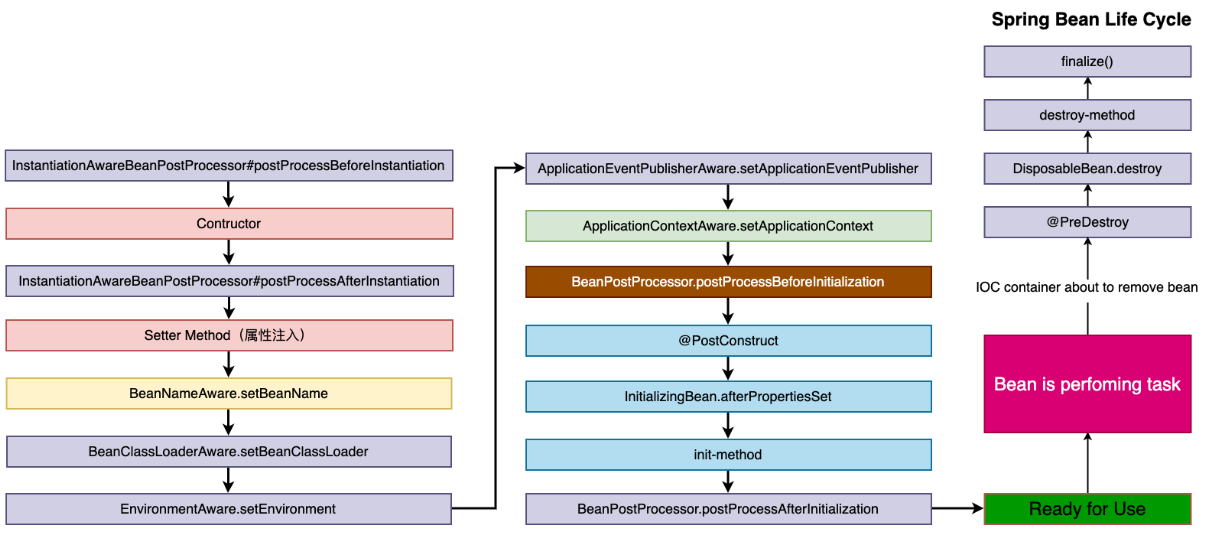
Bean的生命周期:
Bean实例生命周期的执行过程如下:
- Spring对bean进行实例化,默认bean是单例;
- Spring对bean进行依赖注入;
- 如果bean实现了BeanNameAware接口,Spring将bean的名称传给setBeanName()方法;
- 如果bean实现了BeanFactoryAware接口,Spring将调用setBeanFactory()方法,将BeanFactory实例传进来;
- 如果bean实现了ApplicationContextAware接口,它的setApplicationContext()方法将被调用,将应用上下文的引用传入到bean中;
- 如果bean实现了BeanPostProcessor接口,它的postProcessBeforeInitialization()方法将被调用;
- 如果bean中有方法添加了@PostConstruct注解,那么该方法将被调用;
- 如果bean实现了InitializingBean接口,spring将调用它的afterPropertiesSet()接口方法,类似的如果bean使用了init-method属性声明了初始化方法,该方法也会被调用;
- 如果在xml文件中通过标签的init-method元素指定了初始化方法,那么该方法将被调用;
- 如果bean实现了BeanPostProcessor接口,它的postProcessAfterInitialization()接口方法将被调用;
- 此时bean已经准备就绪,可以被应用程序使用了,他们将一直驻留在应用上下文中,直到该应用上下文被销毁;
- 如果bean中有方法添加了@PreDestroy注解,那么该方法将被调用;
- 若bean实现了DisposableBean接口,spring将调用它的distroy()接口方法。同样的,如果bean使用了destroy-method属性声明了销毁方法,则该方法被调用;
这里特别说明一下Aware接口,Spring的依赖注入最大亮点就是所有的Bean对Spring容器的存在是没有意识的。但是在实际项目中,我们有时不可避免的要用到Spring容器本身提供的资源,这时候要让 Bean主动意识到Spring容器的存在,才能调用Spring所提供的资源,这就是Spring的Aware接口,Aware接口是个标记接口,标记这一类接口是用来“感知”属性的,Aware的众多子接口则是表征了具体要“感知”什么属性。例如BeanNameAware接口用于“感知”自己的名称,ApplicationContextAware接口用于“感知”自己所处的上下文。其实Spring的Aware接口是Spring设计为框架内部使用的,在大多数情况下,我们不需要使用任何Aware接口,除非我们真的需要它们,实现了这些接口会使应用层代码耦合到Spring框架代码中。
其实很多时候我们并不会真的去实现上面所描述的那些接口,那么下面我们就除去那些接口,针对bean的单例和非单例来描述下bean的生命周期:
单例管理的对象
当scope=“singleton”,即默认情况下,会在启动容器时(即实例化容器时)时实例化。但我们可以指定Bean节点的lazy-init="true"来延迟初始化bean,这时候,只有在第一次获取bean时才会初始化bean,即第一次请求该bean时才初始化。如下配置:
<bean id="serviceImpl" class="cn.csdn.service.ServiceImpl" lazy-init="true"/>
如果想对所有的默认单例bean都应用延迟初始化,可以在根节点beans设置default-lazy-init属性为true,如下所示:
<beans default-lazy-init="true">
默认情况下,Spring在读取xml文件的时候,就会创建对象。在创建对象的时候先调用构造器,然后调用init-method属性值中所指定的方法。对象在被销毁的时候,会调用destroy-method属性值中所指定的方法(例如调用Container.destroy()方法的时候)。写一个测试类,代码如下:
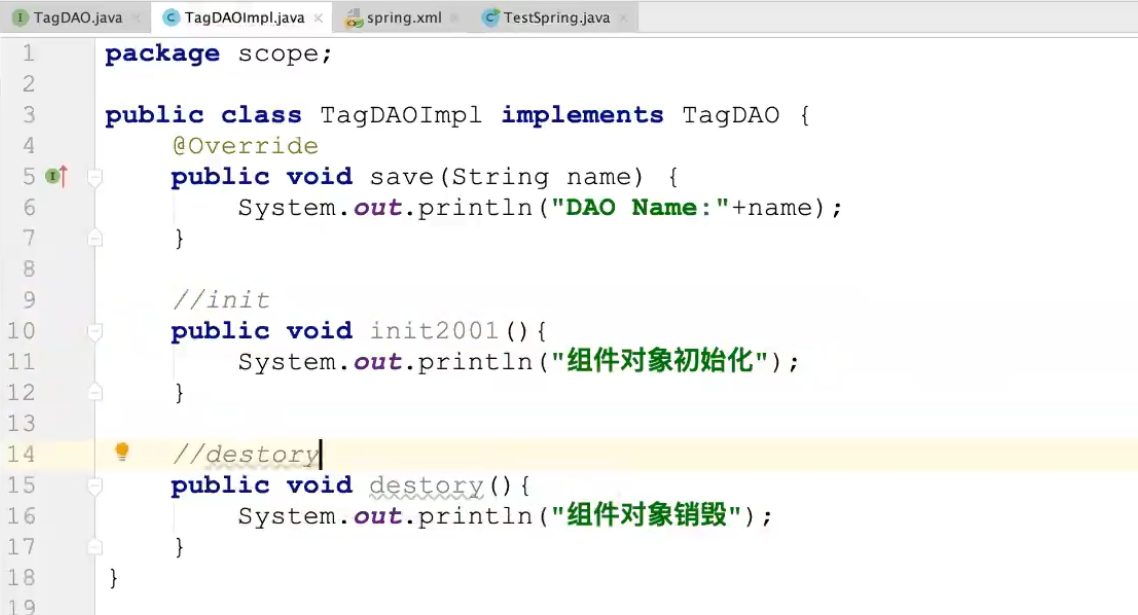
public class LifeBean {
private String name;
public LifeBean(){
System.out.println("LifeBean()构造函数");
}
public String getName() {
return name;
}
public void setName(String name) {
System.out.println("setName()");
this.name = name;
}
public void init(){
System.out.println("this is init of lifeBean");
}
public void destory(){
System.out.println("this is destory of lifeBean " + this);
}
}
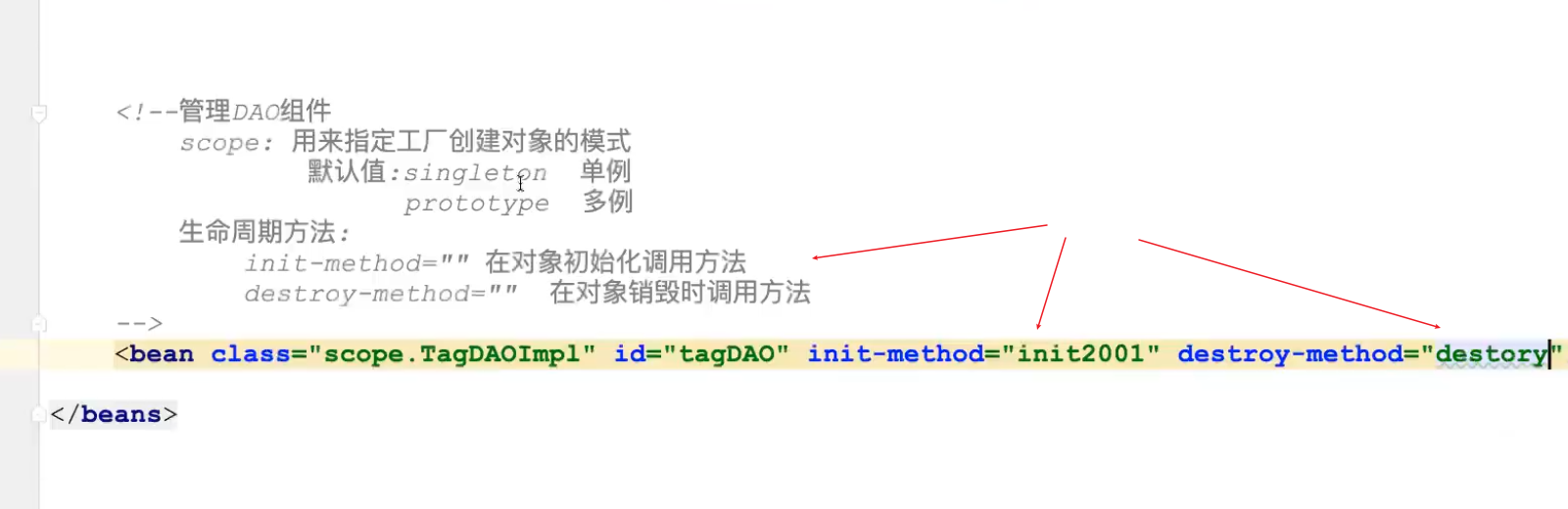
life.xml配置如下:
<bean id="life_singleton" class="com.bean.LifeBean" scope="singleton"
init-method="init" destroy-method="destory" lazy-init="true"/>
测试代码如下:
public class LifeTest {
@Test
public void test() {
AbstractApplicationContext container =
new ClassPathXmlApplicationContext("life.xml");
LifeBean life1 = (LifeBean)container.getBean("life");
System.out.println(life1);
container.close();
}
}
运行结果如下:
LifeBean()构造函数
this is init of lifeBean
com.bean.LifeBean@573f2bb1
……
this is destory of lifeBean com.bean.LifeBean@573f2bb1
非单例管理的对象
当scope="prototype"时,容器也会延迟初始化bean,Spring读取xml文件的时候,并不会立刻创建对象,而是在第一次请求该bean时才初始化(如调用getBean方法时)。在第一次请求每一个prototype的bean时,Spring容器都会调用其构造器创建这个对象,然后调用init-method属性值中所指定的方法。对象销毁的时候,Spring容器不会帮我们调用任何方法,因为是非单例,这个类型的对象有很多个,Spring容器一旦把这个对象交给你之后,就不再管理这个对象了。
为了测试prototype bean的生命周期life.xml配置如下:
<bean id="life_prototype" class="com.bean.LifeBean" scope="prototype" init-method="init" destroy-method="destory"/>
测试程序如下:
public class LifeTest {
@Test
public void test() {
AbstractApplicationContext container = new ClassPathXmlApplicationContext("life.xml");
LifeBean life1 = (LifeBean)container.getBean("life_singleton");
System.out.println(life1);
LifeBean life3 = (LifeBean)container.getBean("life_prototype");
System.out.println(life3);
container.close();
}
}
运行结果如下:
LifeBean()构造函数
this is init of lifeBean
com.bean.LifeBean@573f2bb1
LifeBean()构造函数
this is init of lifeBean
com.bean.LifeBean@5ae9a829
……
this is destory of lifeBean com.bean.LifeBean@573f2bb1
可以发现,对于作用域为prototype的bean,其destroy方法并没有被调用。如果bean的scope设为prototype时,当容器关闭时,destroy方法不会被调用。对于prototype作用域的bean,有一点非常重要,那就是Spring不能对一个prototype bean的整个生命周期负责:容器在初始化、配置、装饰或者是装配完一个prototype实例后,将它交给客户端,随后就对该prototype实例不闻不问了。不管何种作用域,容器都会调用所有对象的初始化生命周期回调方法。但对prototype而言,任何配置好的析构生命周期回调方法都将不会被调用。清除prototype作用域的对象并释放任何prototype bean所持有的昂贵资源,都是客户端代码的职责(让Spring容器释放被prototype作用域bean占用资源的一种可行方式是,通过使用bean的后置处理器,该处理器持有要被清除的bean的引用)。谈及prototype作用域的bean时,在某些方面你可以将Spring容器的角色看作是Java new操作的替代者,任何迟于该时间点的生命周期事宜都得交由客户端来处理。
Spring容器可以管理singleton作用域下bean的生命周期,在此作用域下,Spring能够精确地知道bean何时被创建,何时初始化完成,以及何时被销毁。而对于prototype作用域的bean,Spring只负责创建,当容器创建了bean的实例后,bean的实例就交给了客户端的代码管理,Spring容器将不再跟踪其生命周期,并且不会管理那些被配置成prototype作用域的bean的生命周期。
引申
在学习Spring IoC过程中发现,每次产生ApplicationContext工厂的方式是:
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("applicationContext.xml");
这样产生ApplicationContext就有一个弊端,每次访问加载bean的时候都会产生这个工厂,所以这里需要解决这个问题。
ApplicationContext是一个接口,它继承自BeanFactory接口,除了包含BeanFactory的所有功能之外,在国际化支持、资源访问(如URL和文件)、事件传播等方面进行了良好的支持。
解决问题的方法很简单,在web容器启动的时候将ApplicationContext转移到ServletContext中,因为在web应用中所有的Servlet都共享一个ServletContext对象。那么我们就可以利用ServletContextListener去监听ServletContext事件,当web应用启动的是时候,我们就将ApplicationContext装载到ServletContext中。 Spring容器底层已经为我们想到了这一点,在spring-web-xxx-release.jar包中有一个已经实现了ServletContextListener接口的类ContextLoader,其源码如下:
public class ContextLoaderListener extends ContextLoader implements ServletContextListener {
private ContextLoader contextLoader;
public ContextLoaderListener() {
}
public ContextLoaderListener(WebApplicationContext context) {
super(context);
}
public void contextInitialized(ServletContextEvent event) {
this.contextLoader = createContextLoader();
if (this.contextLoader == null) {
this.contextLoader = this;
}
this.contextLoader.initWebApplicationContext(event.getServletContext());
}
@Deprecated
protected ContextLoader createContextLoader() {
return null;
}
@Deprecated
public ContextLoader getContextLoader() {
return this.contextLoader;
}
public void contextDestroyed(ServletContextEvent event) {
if (this.contextLoader != null) {
this.contextLoader.closeWebApplicationContext(event.getServletContext());
}
ContextCleanupListener.cleanupAttributes(event.getServletContext());
}
}
这里就监听到了servletContext的创建过程, 那么 这个类又是如何将applicationContext装入到serveletContext容器中的呢?
this.contextLoader.initWebApplicationContext(event.getServletContext())方法的具体实现中:
public WebApplicationContext initWebApplicationContext(ServletContext servletContext) {
if (servletContext.getAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE) != null) {
throw new IllegalStateException(
"Cannot initialize context because there is already a root application context present - " +
"check whether you have multiple ContextLoader* definitions in your web.xml!");
}
Log logger = LogFactory.getLog(ContextLoader.class);
servletContext.log("Initializing Spring root WebApplicationContext");
if (logger.isInfoEnabled()) {
logger.info("Root WebApplicationContext: initialization started");
}
long startTime = System.currentTimeMillis();
try {
// Store context in local instance variable, to guarantee that
// it is available on ServletContext shutdown.
if (this.context == null) {
this.context = createWebApplicationContext(servletContext);
}
if (this.context instanceof ConfigurableWebApplicationContext) {
ConfigurableWebApplicationContext cwac = (ConfigurableWebApplicationContext) this.context;
if (!cwac.isActive()) {
// The context has not yet been refreshed -> provide services such as
// setting the parent context, setting the application context id, etc
if (cwac.getParent() == null) {
// The context instance was injected without an explicit parent ->
// determine parent for root web application context, if any.
ApplicationContext parent = loadParentContext(servletContext);
cwac.setParent(parent);
}
configureAndRefreshWebApplicationContext(cwac, servletContext);
}
}
servletContext.setAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE, this.context);
ClassLoader ccl = Thread.currentThread().getContextClassLoader();
if (ccl == ContextLoader.class.getClassLoader()) {
currentContext = this.context;
}
else if (ccl != null) {
currentContextPerThread.put(ccl, this.context);
}
if (logger.isDebugEnabled()) {
logger.debug("Published root WebApplicationContext as ServletContext attribute with name [" +
WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE + "]");
}
if (logger.isInfoEnabled()) {
long elapsedTime = System.currentTimeMillis() - startTime;
logger.info("Root WebApplicationContext: initialization completed in " + elapsedTime + " ms");
}
return this.context;
}
catch (RuntimeException ex) {
logger.error("Context initialization failed", ex);
servletContext.setAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE, ex);
throw ex;
}
catch (Error err) {
logger.error("Context initialization failed", err);
servletContext.setAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE, err);
throw err;
}
}
这里的重点是servletContext.setAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE, this.context),用key:WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE value: this.context的形式将applicationContext装载到servletContext中了。另外从上面的一些注释我们可以看出: WEB-INF/applicationContext.xml, 如果我们项目中的配置文件不是这么一个路径的话 那么我们使用ContextLoaderListener 就会出问题, 所以我们还需要在web.xml中配置我们的applicationContext.xml配置文件的路径。
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:applicationContext.xml</param-value>
</context-param>
剩下的就是在项目中开始使用 servletContext中装载的applicationContext对象了: 那么这里又有一个问题,装载时的key是 WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE,我们在代码中真的要使用这个吗? 其实Spring为我们提供了一个工具类WebApplicationContextUtils,接着我们先看下如何使用,然后再去看下这个工具类的源码:
WebApplicationContext applicationContext = WebApplicationContextUtils.getWebApplicationContext(request.getServletContext());
接着来看下这个工具类的源码:
public static WebApplicationContext getWebApplicationContext(ServletContext sc) {
return getWebApplicationContext(sc, WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE);
}
这里就能很直观清晰地看到 通过key值直接获取到装载到servletContext中的 applicationContext对象了。
ContextLoaderListener监听器的作用就是启动Web容器时,自动装配ApplicationContext的配置信息,因为它实现了ServletContextListener这个接口,在web.xml配置这个监听器,启动容器时,就会默认执行它实现的方法。在ContextLoaderListener中关联了ContextLoader这个类,整个加载配置过程由ContextLoader来完成。
————————————————
版权声明:本文为CSDN博主「GeorgiaStar」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/fuzhongmin05/article/details/73389779


40.spring中复杂对象的创建


41.SpringMVC
引言

运行流程

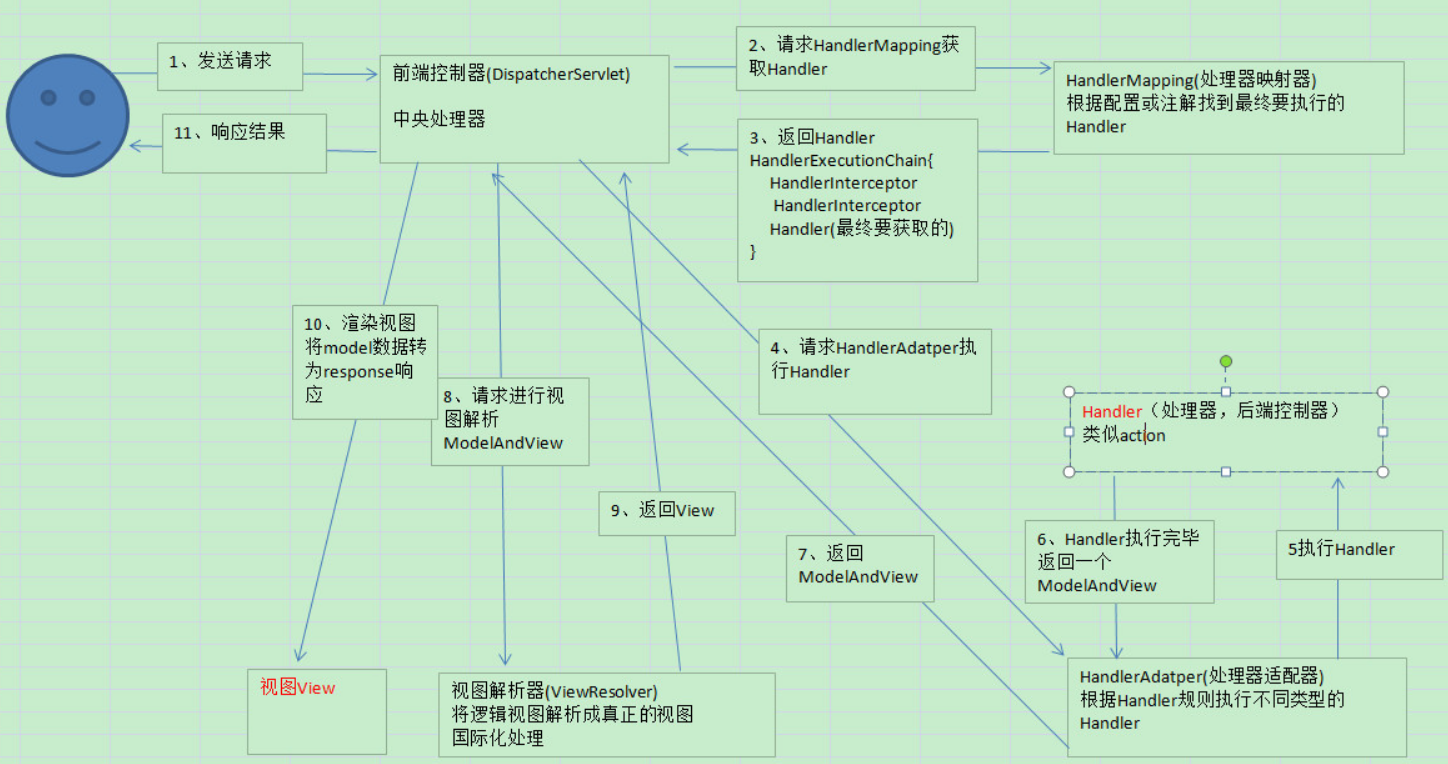
SpringMVC流程
1、 用户发送请求至前端控制器DispatcherServlet。
2、 DispatcherServlet收到请求调用HandlerMapping处理器映射器。
3、 处理器映射器找到具体的处理器(可以根据xml配置、注解进行查找),生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet。
4、 DispatcherServlet调用HandlerAdapter处理器适配器。
5、 HandlerAdapter经过适配调用具体的处理器(Controller,也叫后端控制器)。
6、 Controller执行完成返回ModelAndView。
7、 HandlerAdapter将controller执行结果ModelAndView返回给DispatcherServlet。
8、 DispatcherServlet将ModelAndView传给ViewReslover视图解析器。
9、 ViewReslover解析后返回具体View。
10、DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)。
11、 DispatcherServlet响应用户。
组件说明:
以下组件通常使用框架提供实现:
DispatcherServlet:作为前端控制器,整个流程控制的中心,控制其它组件执行,统一调度,降低组件之间的耦合性,提高每个组件的扩展性。
HandlerMapping:通过扩展处理器映射器实现不同的映射方式,例如:配置文件方式,实现接口方式,注解方式等。
HandlAdapter:通过扩展处理器适配器,支持更多类型的处理器。
ViewResolver:通过扩展视图解析器,支持更多类型的视图解析,例如:jsp、freemarker、pdf、excel等。
组件:
1、前端控制器DispatcherServlet(不需要工程师开发),由框架提供
作用:接收请求,响应结果,相当于转发器,中央处理器。有了dispatcherServlet减少了其它组件之间的耦合度。
用户请求到达前端控制器,它就相当于mvc模式中的c,dispatcherServlet是整个流程控制的中心,由它调用其它组件处理用户的请求,dispatcherServlet的存在降低了组件之间的耦合性。
2、处理器映射器HandlerMapping(不需要工程师开发),由框架提供
作用:根据请求的url查找Handler
HandlerMapping负责根据用户请求找到Handler即处理器,springmvc提供了不同的映射器实现不同的映射方式,例如:配置文件方式,实现接口方式,注解方式等。
3、处理器适配器HandlerAdapter
作用:按照特定规则(HandlerAdapter要求的规则)去执行Handler
通过HandlerAdapter对处理器进行执行,这是适配器模式的应用,通过扩展适配器可以对更多类型的处理器进行执行。
4、处理器Handler(需要工程师开发)
注意:编写Handler时按照HandlerAdapter的要求去做,这样适配器才可以去正确执行Handler
Handler 是继DispatcherServlet前端控制器的后端控制器,在DispatcherServlet的控制下Handler对具体的用户请求进行处理。
由于Handler涉及到具体的用户业务请求,所以一般情况需要工程师根据业务需求开发Handler。
5、视图解析器View resolver(不需要工程师开发),由框架提供
作用:进行视图解析,根据逻辑视图名解析成真正的视图(view)
View Resolver负责将处理结果生成View视图,View Resolver首先根据逻辑视图名解析成物理视图名即具体的页面地址,再生成View视图对象,最后对View进行渲染将处理结果通过页面展示给用户。 springmvc框架提供了很多的View视图类型,包括:jstlView、freemarkerView、pdfView等。
一般情况下需要通过页面标签或页面模版技术将模型数据通过页面展示给用户,需要由工程师根据业务需求开发具体的页面。
6、视图View(需要工程师开发jsp…)
View是一个接口,实现类支持不同的View类型(jsp、freemarker、pdf…)
核心架构的具体流程步骤如下:
1、首先用户发送请求——>DispatcherServlet,前端控制器收到请求后自己不进行处理,而是委托给其他的解析器进行处理,作为统一访问点,进行全局的流程控制;
2、DispatcherServlet——>HandlerMapping, HandlerMapping 将会把请求映射为HandlerExecutionChain 对象(包含一个Handler 处理器(页面控制器)对象、多个HandlerInterceptor 拦截器)对象,通过这种策略模式,很容易添加新的映射策略;
3、DispatcherServlet——>HandlerAdapter,HandlerAdapter 将会把处理器包装为适配器,从而支持多种类型的处理器,即适配器设计模式的应用,从而很容易支持很多类型的处理器;
4、HandlerAdapter——>处理器功能处理方法的调用,HandlerAdapter 将会根据适配的结果调用真正的处理器的功能处理方法,完成功能处理;并返回一个ModelAndView 对象(包含模型数据、逻辑视图名);
5、ModelAndView的逻辑视图名——> ViewResolver, ViewResolver 将把逻辑视图名解析为具体的View,通过这种策略模式,很容易更换其他视图技术;
6、View——>渲染,View会根据传进来的Model模型数据进行渲染,此处的Model实际是一个Map数据结构,因此很容易支持其他视图技术;
7、返回控制权给DispatcherServlet,由DispatcherServlet返回响应给用户,到此一个流程结束。
下边两个组件通常情况下需要开发:
Handler:处理器,即后端控制器用controller表示。
View:视图,即展示给用户的界面,视图中通常需要标签语言展示模型数据。
在讲SpringMVC之前我们先来看一下什么是MVC模式
MVC是一种设计模式
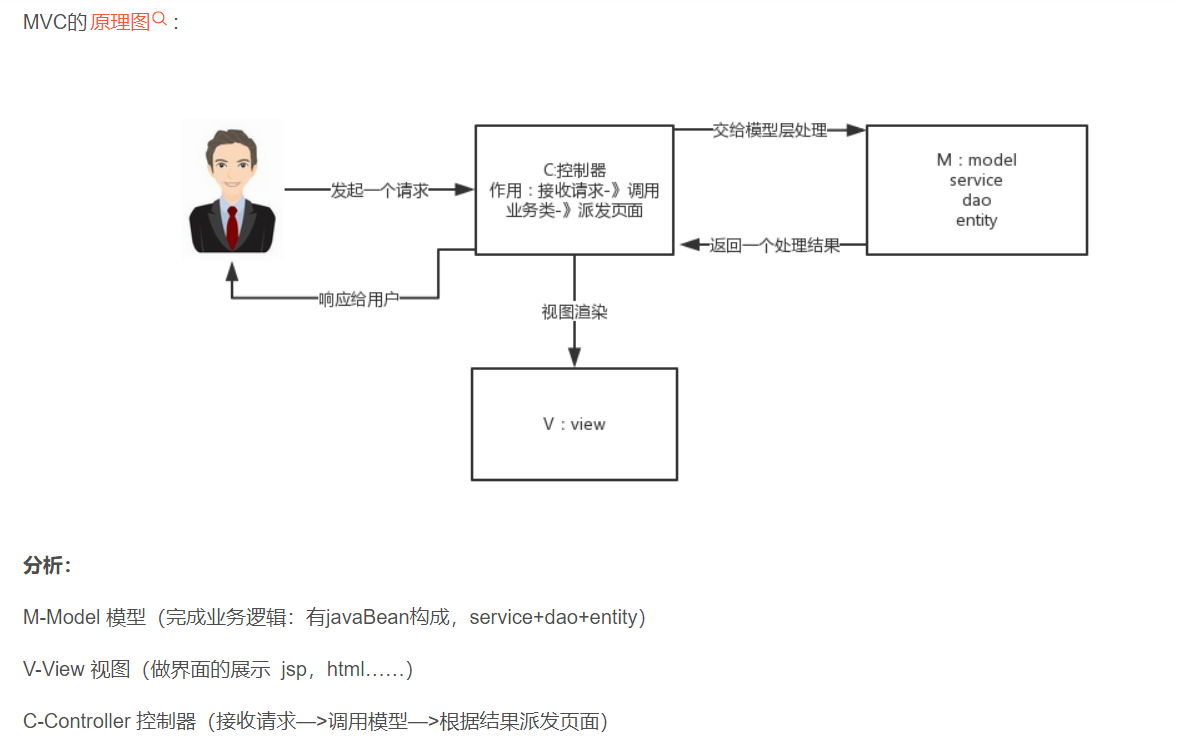
springMVC是什么:
springMVC是一个MVC的开源框架,springMVC=struts2+spring,springMVC就相当于是Struts2加上sring的整合,但是这里有一个疑惑就是,springMVC和spring是什么样的关系呢?这个在百度百科上有一个很好的解释:意思是说,springMVC是spring的一个后续产品,其实就是spring在原有基础上,又提供了web应用的MVC模块,可以简单的把springMVC理解为是spring的一个模块(类似AOP,IOC这样的模块),网络上经常会说springMVC和spring无缝集成,其实springMVC就是spring的一个子模块,所以根本不需要同spring进行整合。
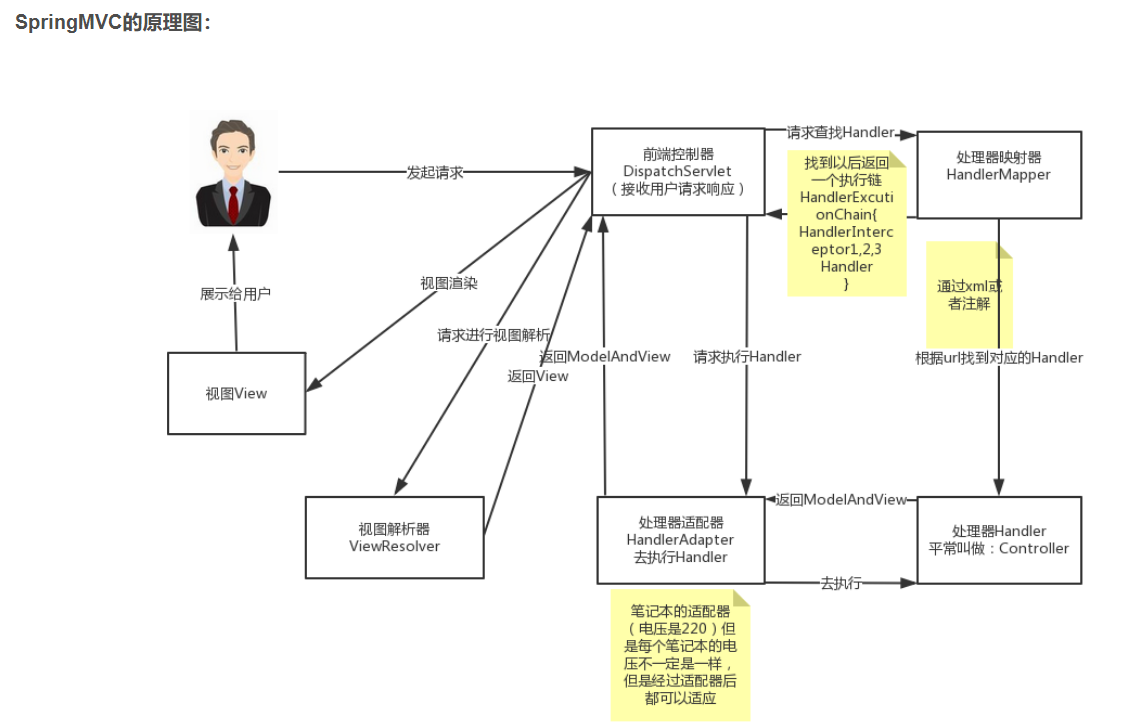
看到这个图大家可能会有很多的疑惑,现在我们来看一下这个图的步骤:(可以对比MVC的原理图进行理解)
第一步:用户发起请求到前端控制器(DispatcherServlet)
第二步:前端控制器请求处理器映射器(HandlerMappering)去查找处理器(Handle):通过xml配置或者注解进行查找
第三步:找到以后处理器映射器(HandlerMappering)像前端控制器返回执行链(HandlerExecutionChain)
第四步:前端控制器(DispatcherServlet)调用处理器适配器(HandlerAdapter)去执行处理器(Handler)
第五步:处理器适配器去执行Handler
第六步:Handler执行完给处理器适配器返回ModelAndView
第七步:处理器适配器向前端控制器返回ModelAndView
第八步:前端控制器请求视图解析器(ViewResolver)去进行视图解析
第九步:视图解析器像前端控制器返回View
第十步:前端控制器对视图进行渲染
第十一步:前端控制器向用户响应结果
看到这些步骤我相信大家很感觉非常的乱,这是正常的,但是这里主要是要大家理解springMVC中的几个组件:
前端控制器(DispatcherServlet):接收请求,响应结果,相当于电脑的CPU。
处理器映射器(HandlerMapping):根据URL去查找处理器
处理器(Handler):(需要程序员去写代码处理逻辑的)
处理器适配器(HandlerAdapter):会把处理器包装成适配器,这样就可以支持多种类型的处理器,类比笔记本的适配器(适配器模式的应用)
视图解析器(ViewResovler):进行视图解析,多返回的字符串,进行处理,可以解析成对应的页面
Model和ModelAndView的区别
1.主要区别
- Model是每次请求中都存在的默认参数,利用其addAttribute()方法即可将服务器的值传递到jsp页面中;
- ModelAndView包含model和view两部分,使用时需要自己实例化,利用ModelMap用来传值,也可以设置view的名称
1)使用Model传值
@RequestMapping(value="/list-books")
private String getAllBooks(Model model){
logger.error("/list-books");
List<Book> books= bookService.getAllBooks();
model.addAttribute("books", books);
return "BookList";
}
在jsp页面利${books}即可取出其中的值
2)使用ModelAndView
1.返回到指定的页面
ModelAndView构造方法可以指定返回的页面名称
- 例:return new ModelAndView(“redirect:/m07.jsp”);
通过setViewName()方法跳转到指定的页面
- 例:mav.setViewName(“hello”);
2.返回参数到指定页面的request作用于中
使用addObject()设置需要返回的值,addObject()有几个不同参数的方法,可以默认和指定返回对象的名字,参数会返回到新页面的request作用域中
ModelAndView 的3种用法
1.ModelAndView的第一种用法,先创建ModelAndView对象,再通过它的方法去设置数据与转发的视图名
- setViewName(String viewName):设置此 ModelAndView 的视图名称, 由 DispatcherServlet 通过 ViewResolver 解析
- addObject(String attributeName, Object attributeValue):通过key/value的方式绑定数据
package com.gxa.spmvc.controller;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.servlet.ModelAndView;
import com.gxa.spmvc.entity.Student;
/**
* SpringMVC的控制器(业务控制器)
* 定义的方法就是一个请求处理的方法
* @author caleb
*
*/
@Controller
@RequestMapping("/user")
public class TestController {
/**
* 利用ModelAndView来转发数据,给前端视图
* @return
*/
@RequestMapping("/m06")
public ModelAndView m06() {
ModelAndView modelAndView = new ModelAndView();
modelAndView.setViewName("m06");
modelAndView.addObject("message", "Hello World, Hello Kitty");
return modelAndView;
}
}
2.ModelAndView的第二种方法,可以直接通过带有参数的构造方法 ModelAndView(String viewName, String attributeName, Object attributeValue) 来返回数据与转发的视图名
package com.gxa.spmvc.controller;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.servlet.ModelAndView;
import com.gxa.spmvc.entity.Student;
/**
* SpringMVC的控制器(业务控制器)
* 定义的方法就是一个请求处理的方法
* @author caleb
*
*/
@Controller
@RequestMapping("/user")
public class TestController {
/**
* 利用ModelAndView来转发数据,给前端视图
* @return
*/
@RequestMapping("/m07")
public ModelAndView m07() {
return new ModelAndView("m07", "message", "Hello World");
}
}
3.ModelAndView的第三种用法,设置重定向
package com.gxa.spmvc.controller;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.servlet.ModelAndView;
import com.gxa.spmvc.entity.Student;
/**
* SpringMVC的控制器(业务控制器)
* 定义的方法就是一个请求处理的方法
* @author caleb
*
*/
@Controller
@RequestMapping("/user")
public class TestController {
/**
* ModelAndView默认转发
* ModelAndView还是可以设置重定向
* 1. 重定向另一个控制器
* 2. 重定向具体的jsp页面
* @param name
* @return
*/
@RequestMapping("/{name}/m07")
public ModelAndView m07(@PathVariable String name) {
if (!"admin".equals(name)) {
return new ModelAndView("redirect:/m07.jsp");
}
return new ModelAndView("m07");
}
}
ModelAndView使用实例
要点:
1.@RequestMapping 注解的使用
2.modelandview 的使用
3.jsp页面request作用域的取值
4.视图解析器配置
ModelAndView 使用代码
package com.dgr.controller;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.servlet.ModelAndView;
@RequestMapping("mvc")
@Controller
public class TestRequestMMapping {
@RequestMapping(value="/testModelAndView")
public ModelAndView testModelAndView(){
ModelAndView mav = new ModelAndView();
mav.setViewName("hello");//跳转新的页面名称
mav.addObject("address", "中国广东省广州市");//传入request作用域参数
return mav;
}
}
跳转前jsp页面链接设置
<a href="mvc/testModelAndView">Test ModelAndView</a>
跳转后jsp页面以及request作用于取值
<title>New Page</title>
</head>
<body>
<h1>ModelAndView 跳转</h1>
<br>
${requestScope.address}
<br>
${address }
<br>
</body>
视图解析器配置

环境搭建


跳转方式

为什么重定向会丢失request域
重定向就是、A访问C的时候 C里写了重定向、 C的走向是先返回A、在由A自动访问重定向的D然后返回到A、这就 是 重定向、
如果没有用到重定向、就是 A访问C的时候 C里没有用到重定向、直接由C自动访问D然后返回A、 这就没有用到重定向、
而request的有效期是在一次的请求响应中有效、 而重定向相当于两次请求响应、 所以在第二次的时候就自动丢失了request对象里的数据
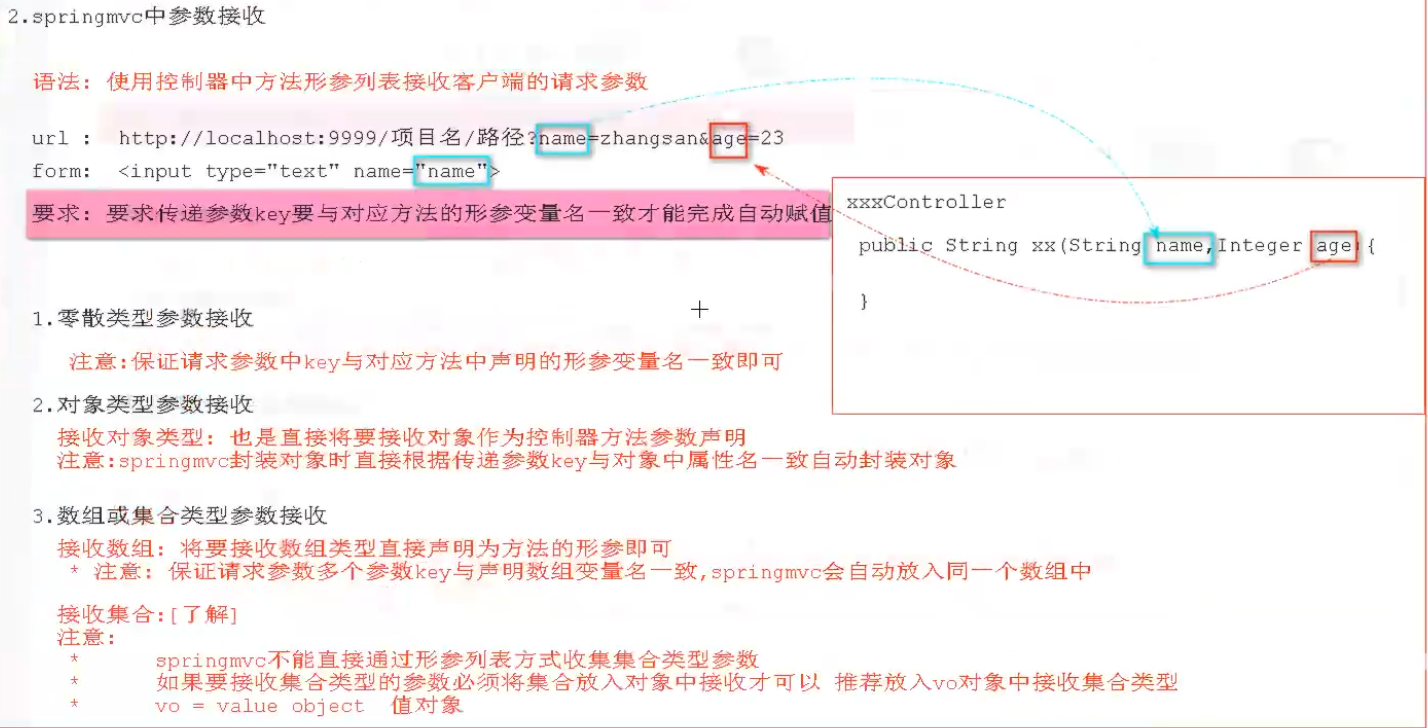
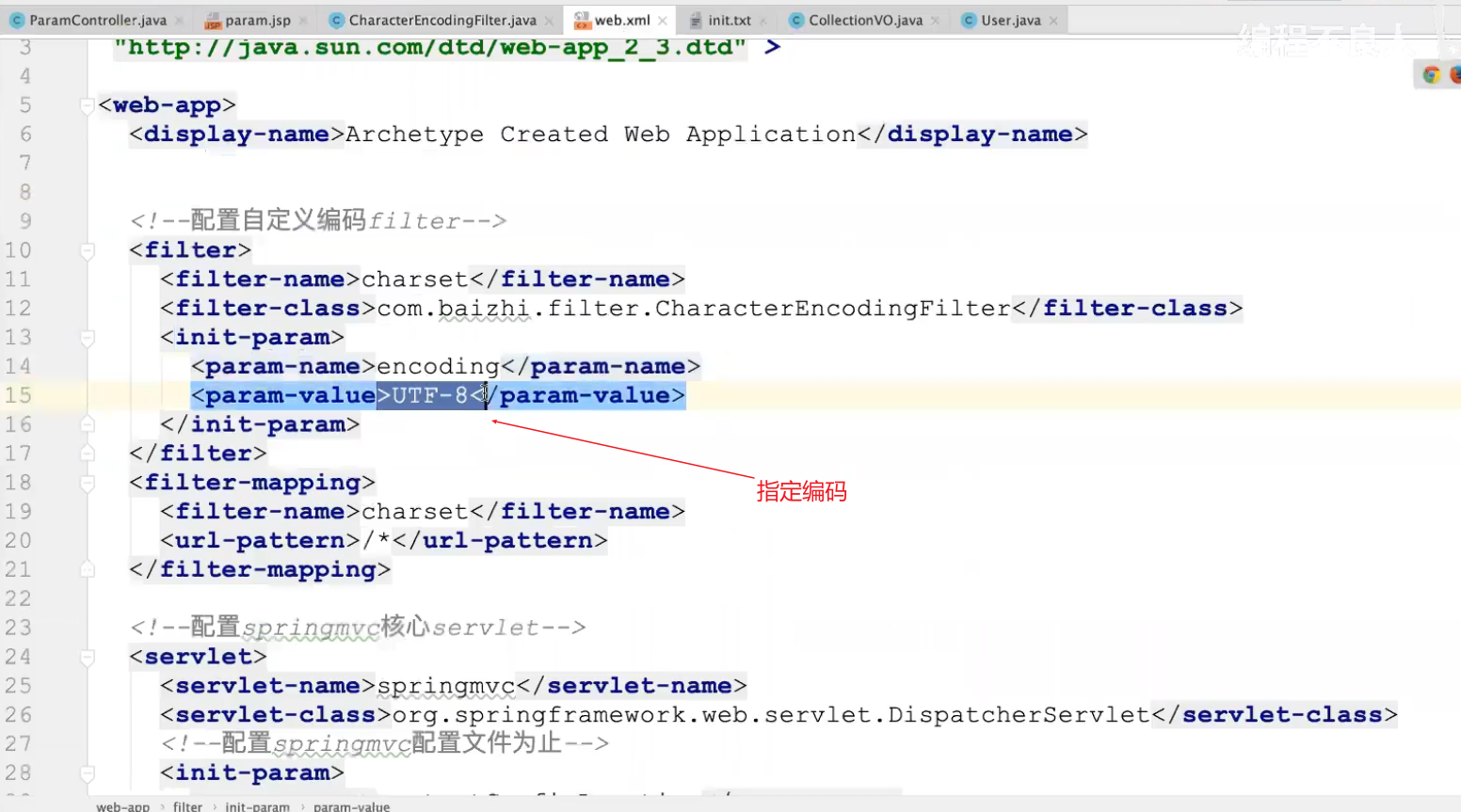
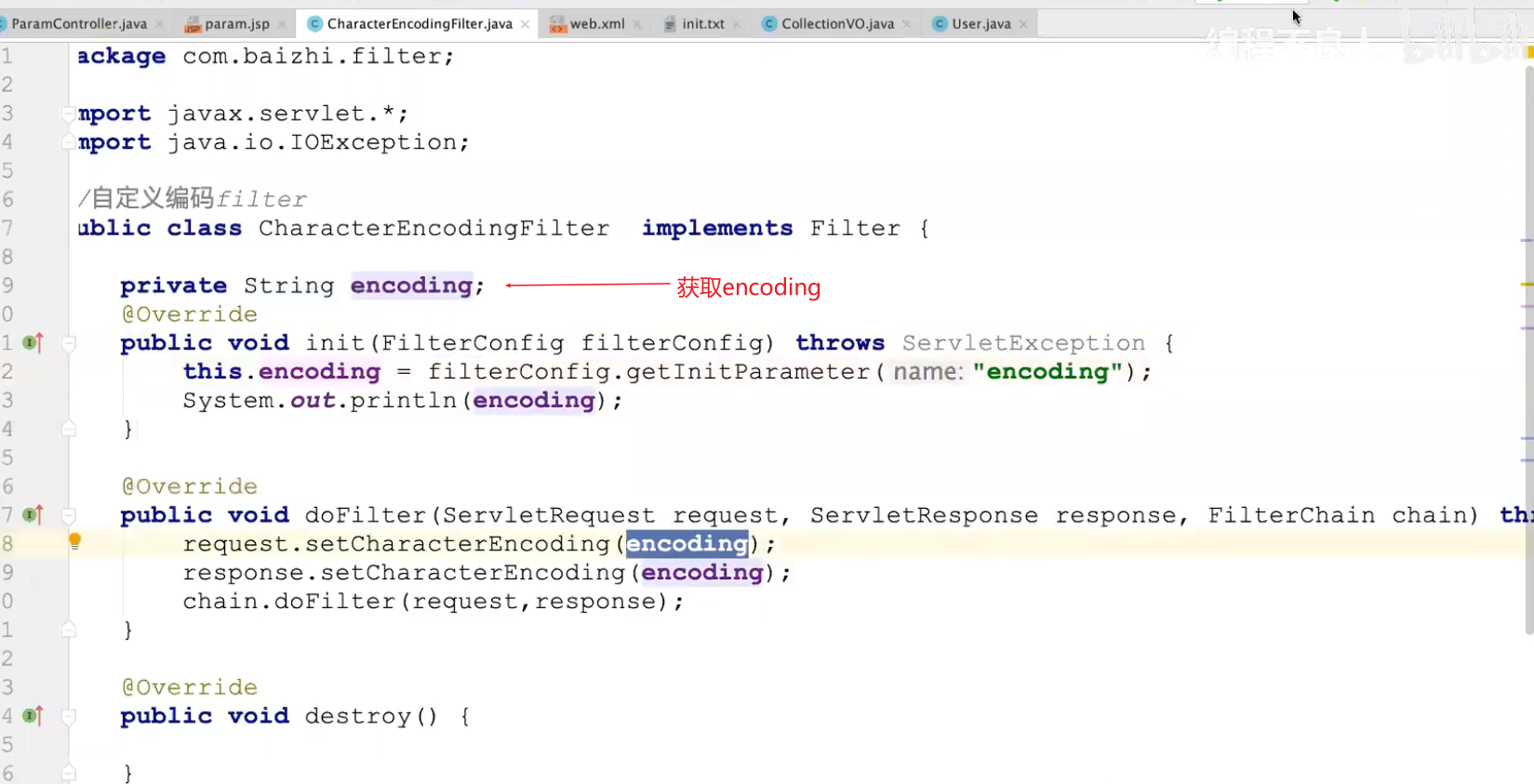
参数接收

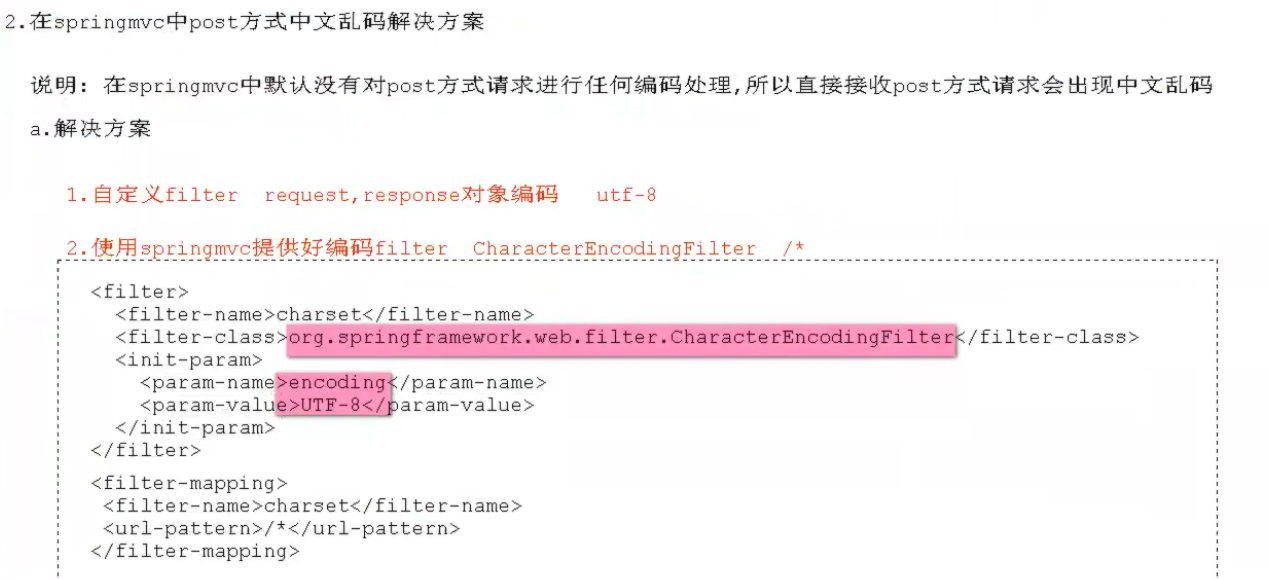
post方式出现中文乱码

数据传递机制
静态资源拦截问题

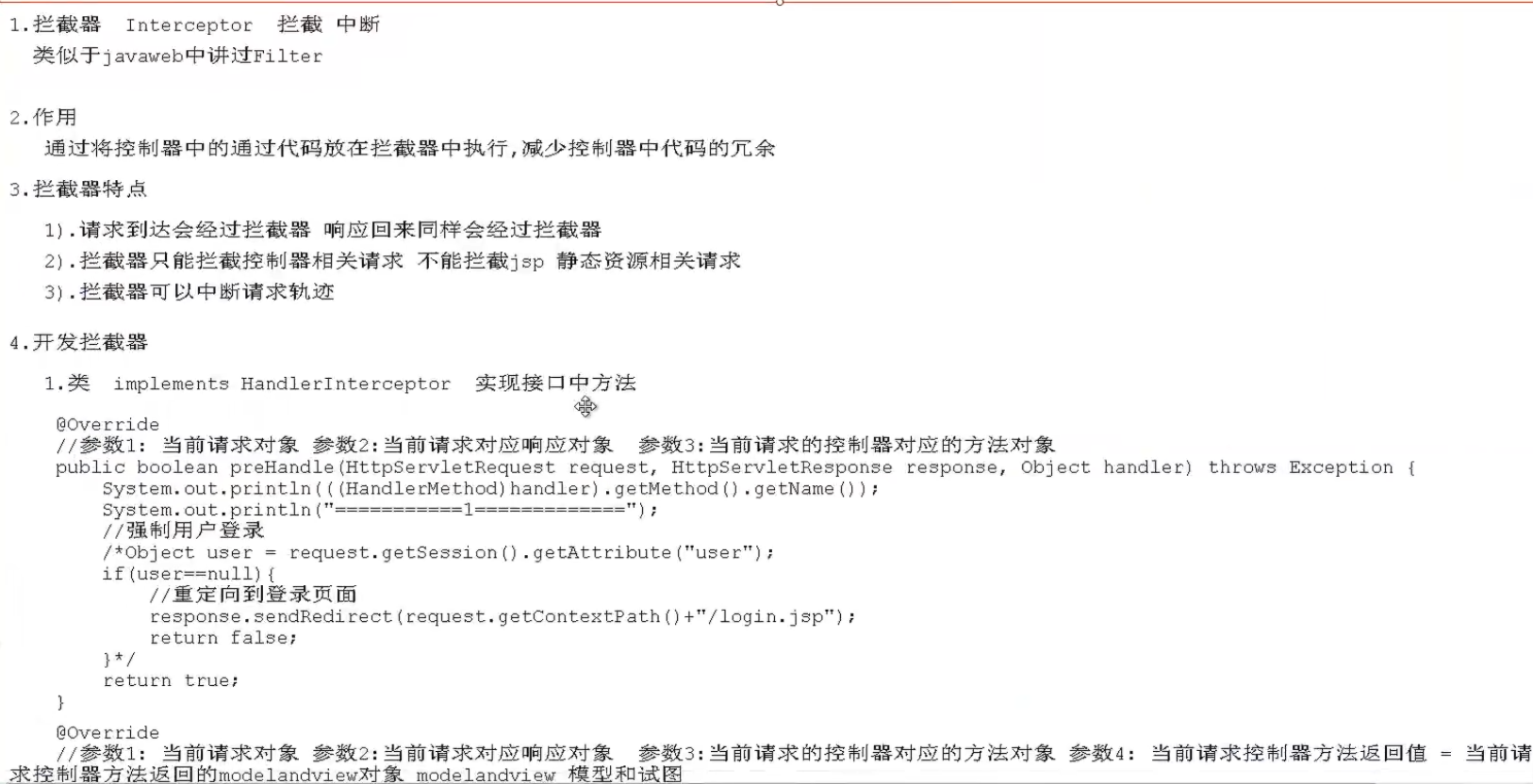
拦截器
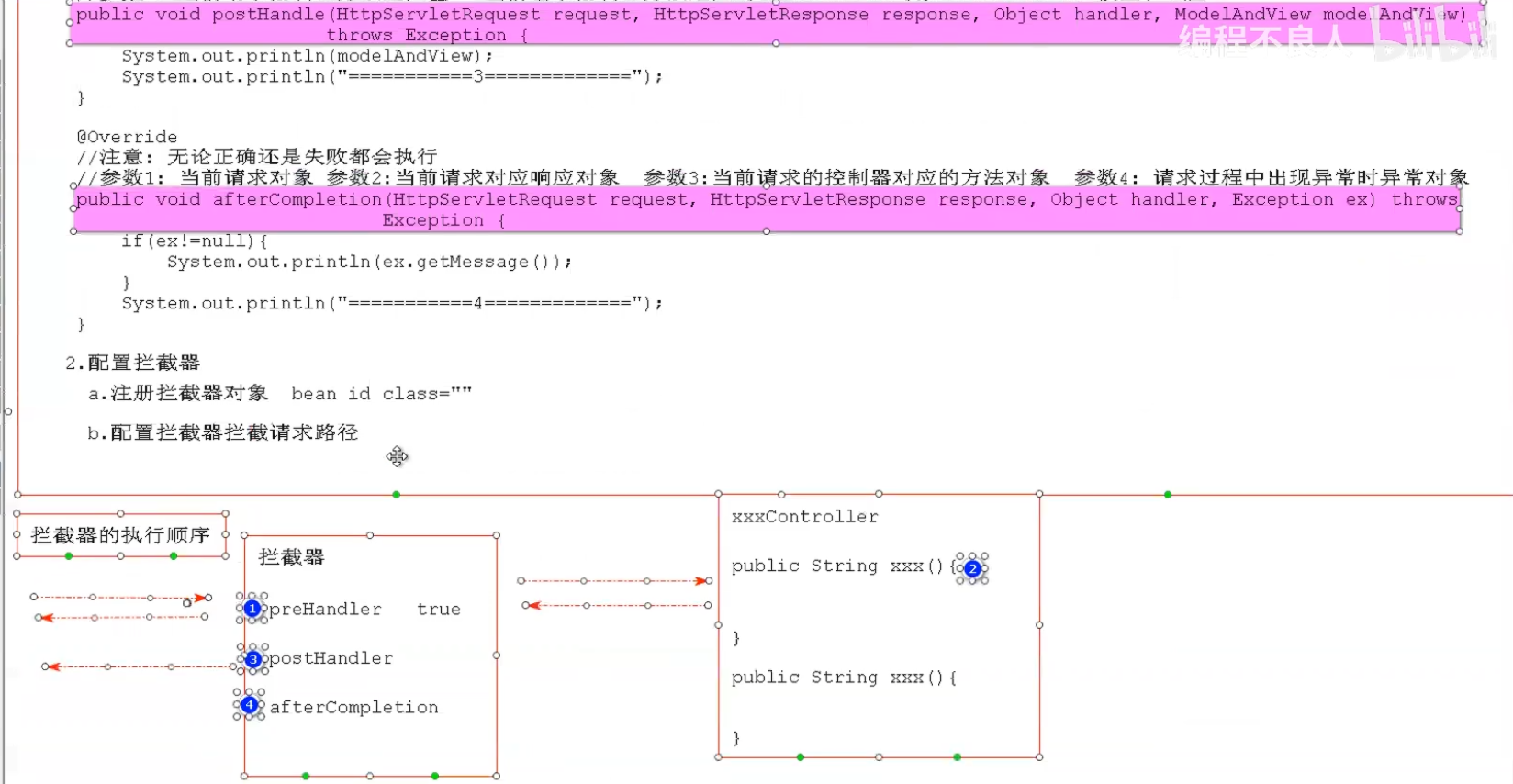
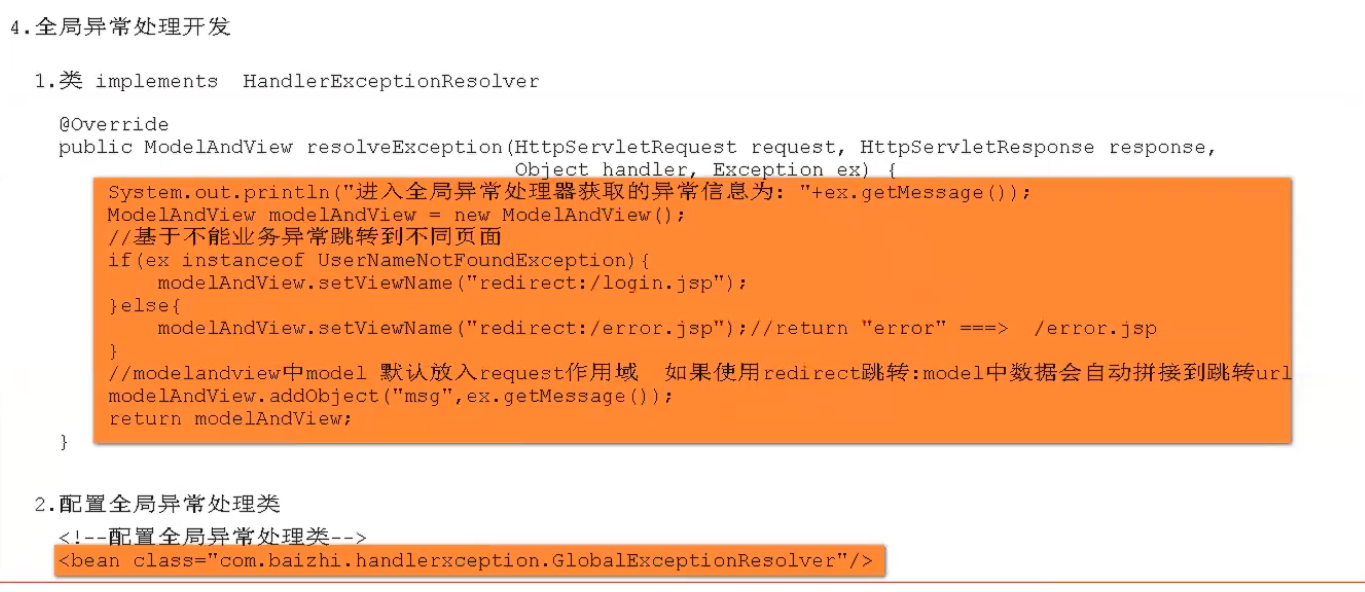
全局异常处理

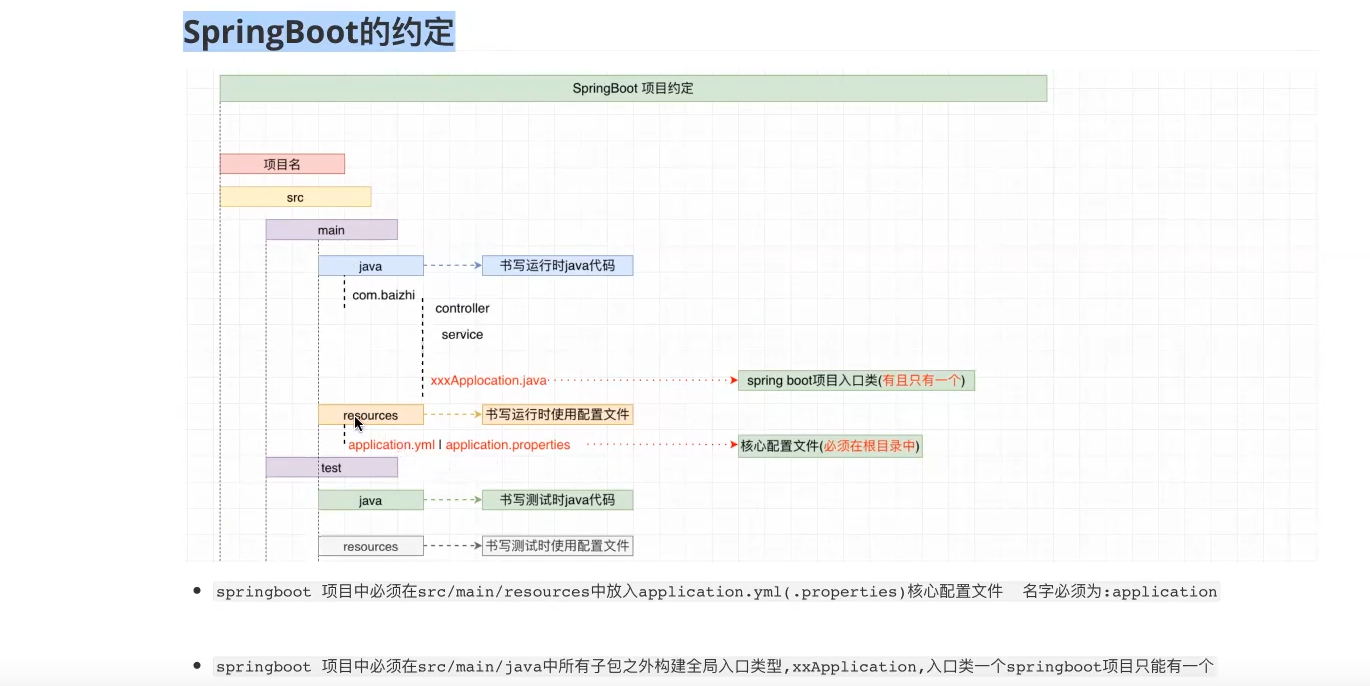
42.springboot
引言
传统的ssm:
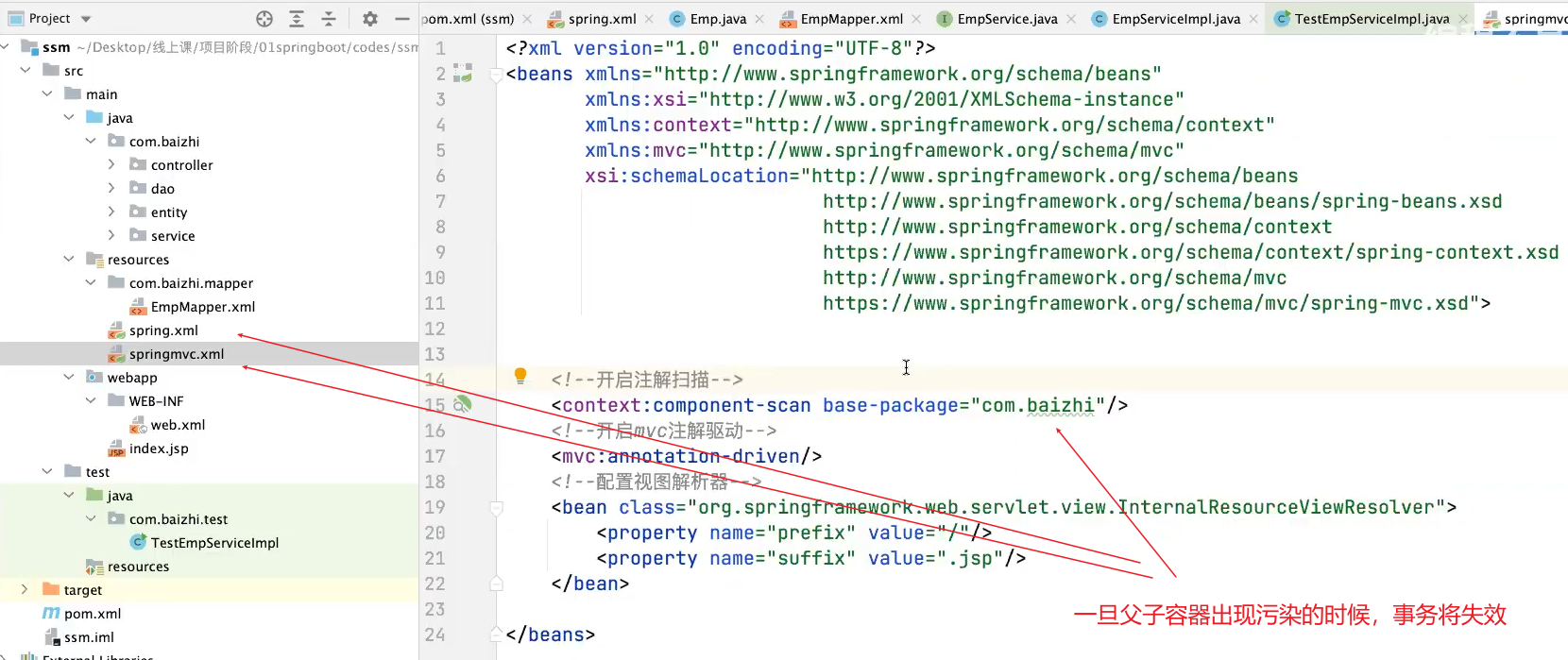
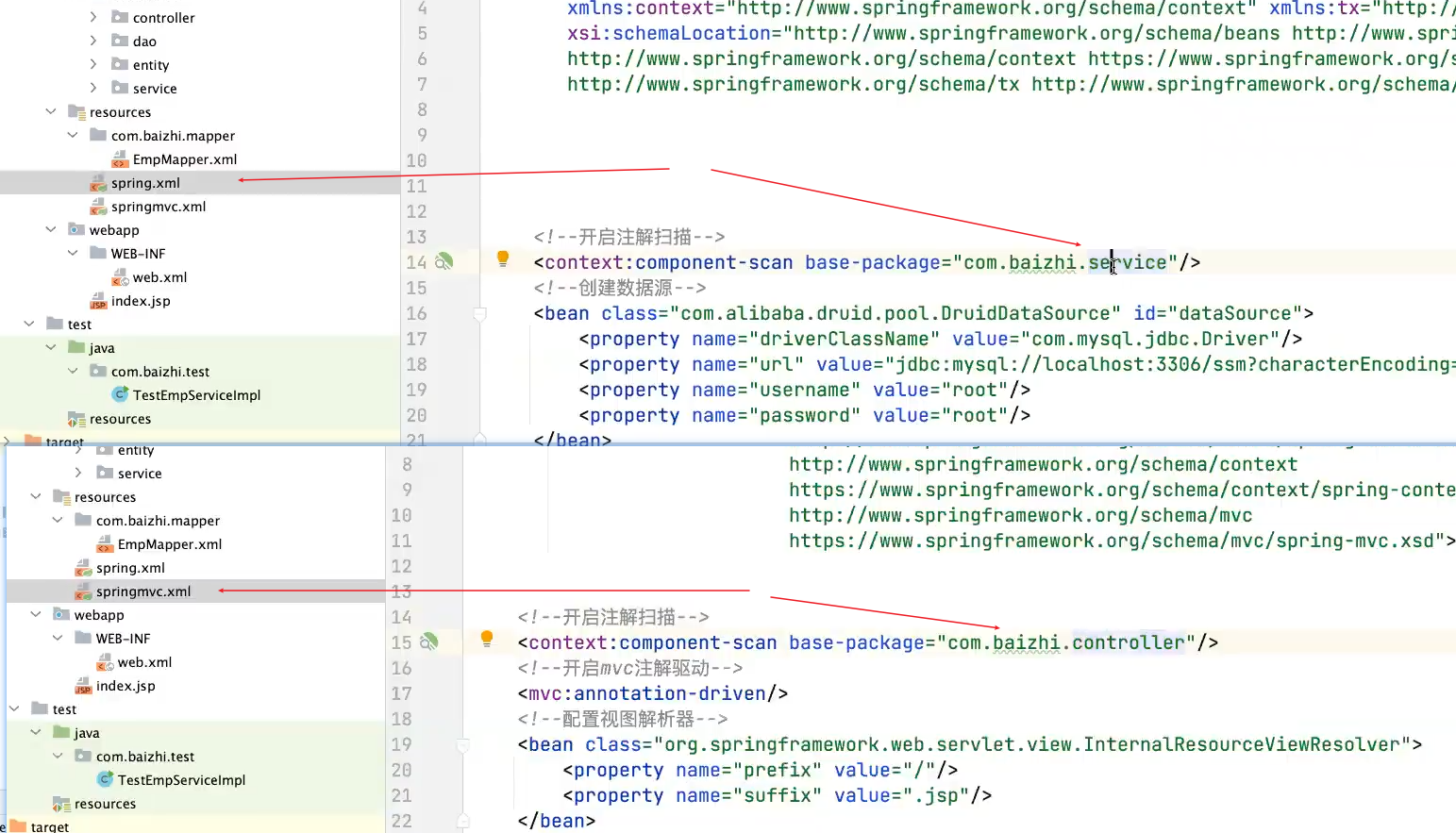
spring和springMVC互相扫描自己的包才不会使事务失效

相关注解

元注解
jdk1.5之后出现的,源码样例
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
public @interface MthCache {
String key();
}
@Target 注解
功能:指明了修饰的这个注解的使用范围,即被描述的注解可以用在哪里。
ElementType的取值包含以下几种:
- TYPE:类,接口或者枚举
- FIELD:域,包含枚举常量
- METHOD:方法
- PARAMETER:参数
- CONSTRUCTOR:构造方法
- LOCAL_VARIABLE:局部变量
- ANNOTATION_TYPE:注解类型
- PACKAGE:包
@Retention 注解
功能:指明修饰的注解的生存周期,即会保留到哪个阶段。
RetentionPolicy的取值包含以下三种:
- SOURCE:源码级别保留,编译后即丢弃。
- CLASS:编译级别保留,编译后的class文件中存在,在jvm运行时丢弃,这是默认值。
- RUNTIME: 运行级别保留,编译后的class文件中存在,在jvm运行时保留,可以被反射调用。
@Documented 注解
功能:指明修饰的注解,可以被例如javadoc此类的工具文档化,只负责标记,没有成员取值。
@Inherited注解
功能:允许子类继承父类中的注解。
注意!:
@interface意思是声明一个注解,方法名对应参数名,返回值类型对应参数类型。
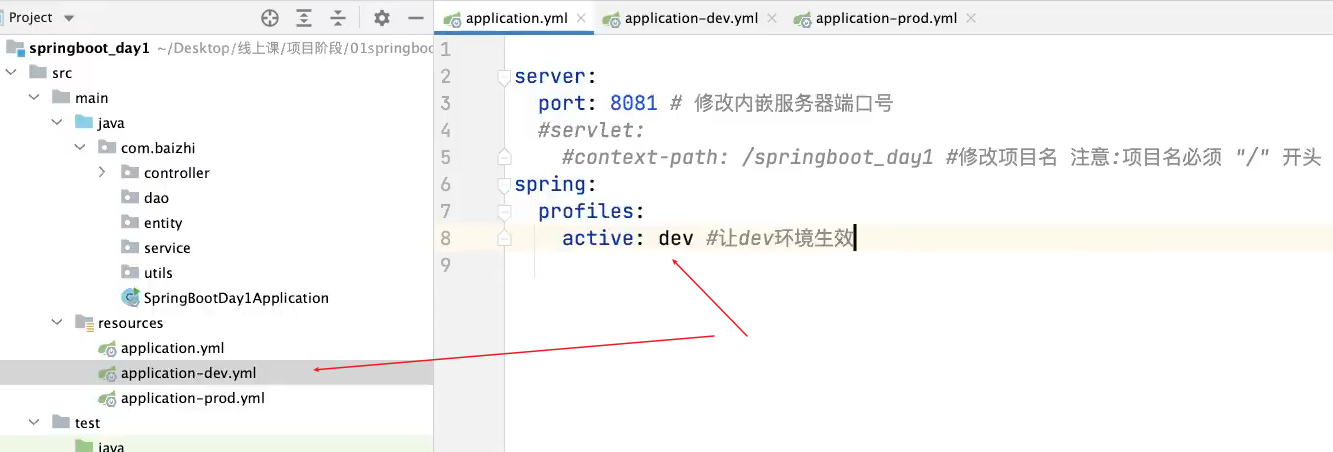
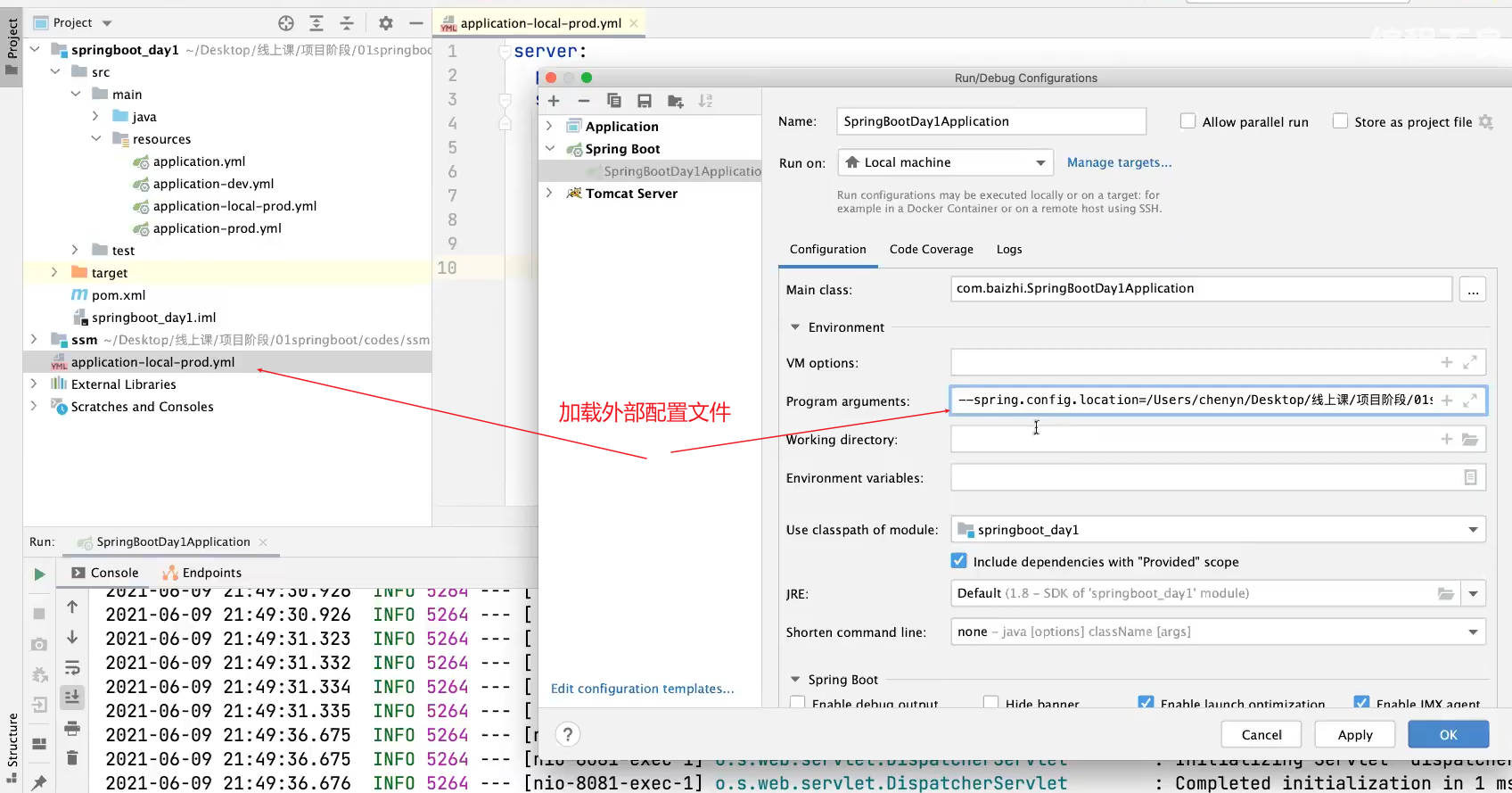
配置文件拆分和加载外部配置
管理对象的创建
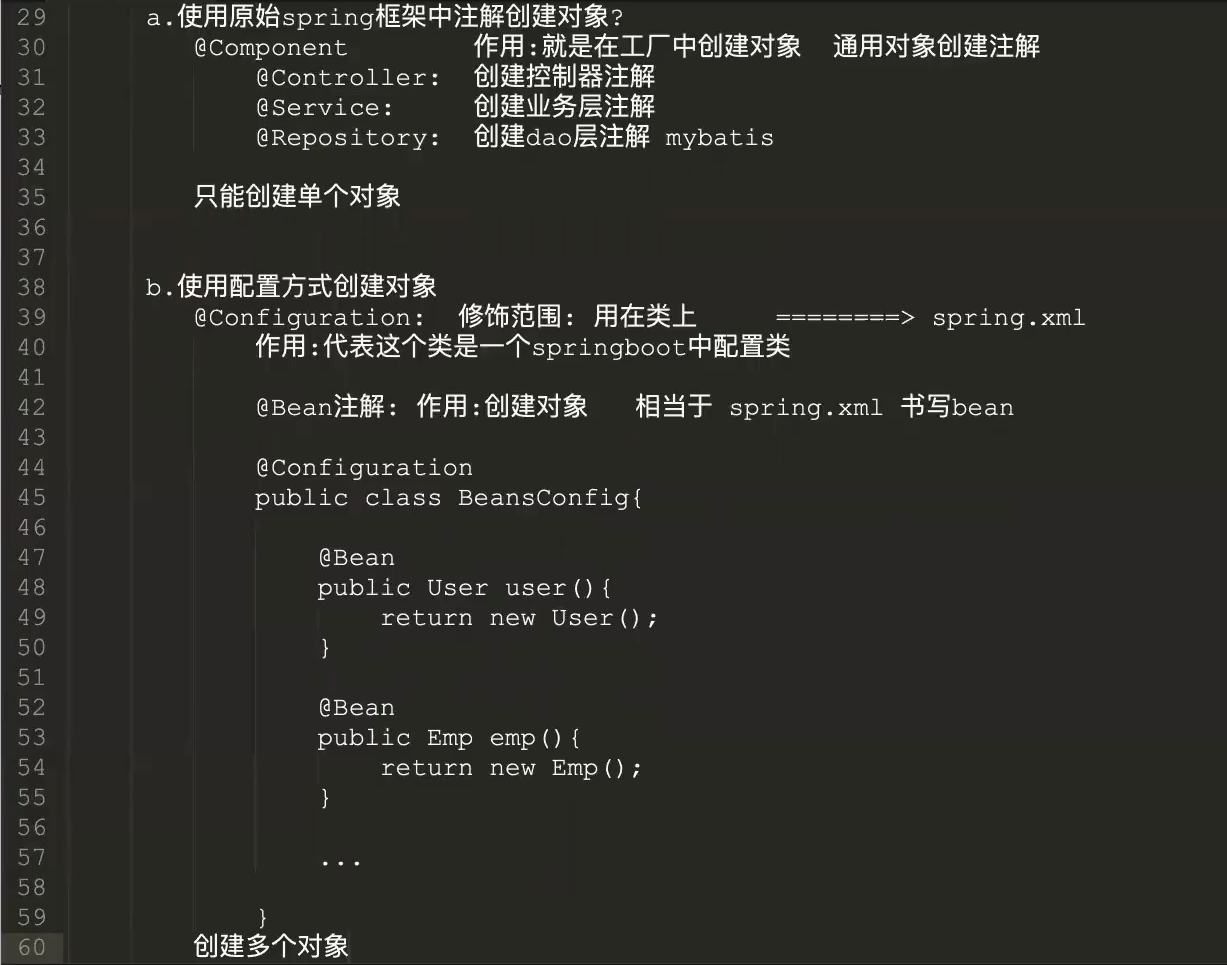
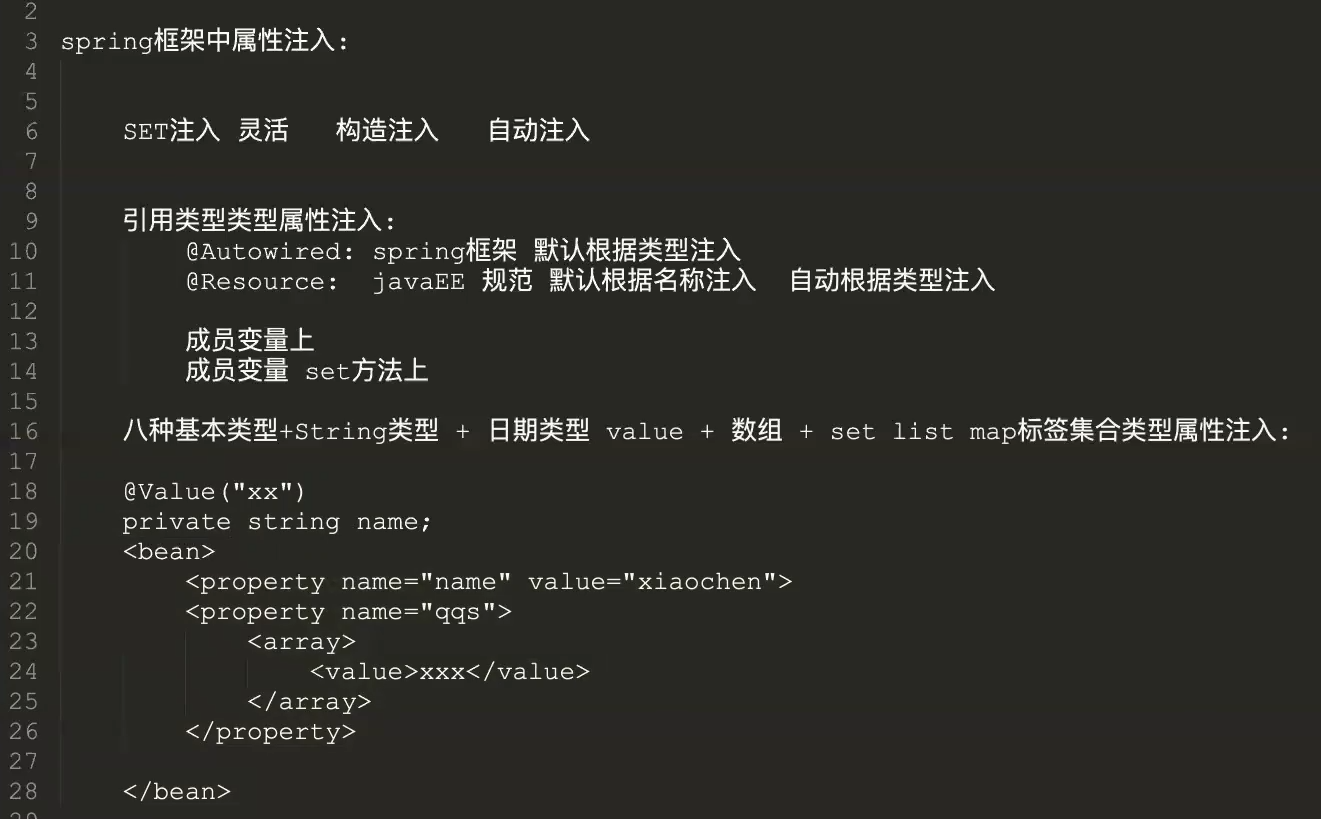
属性注入

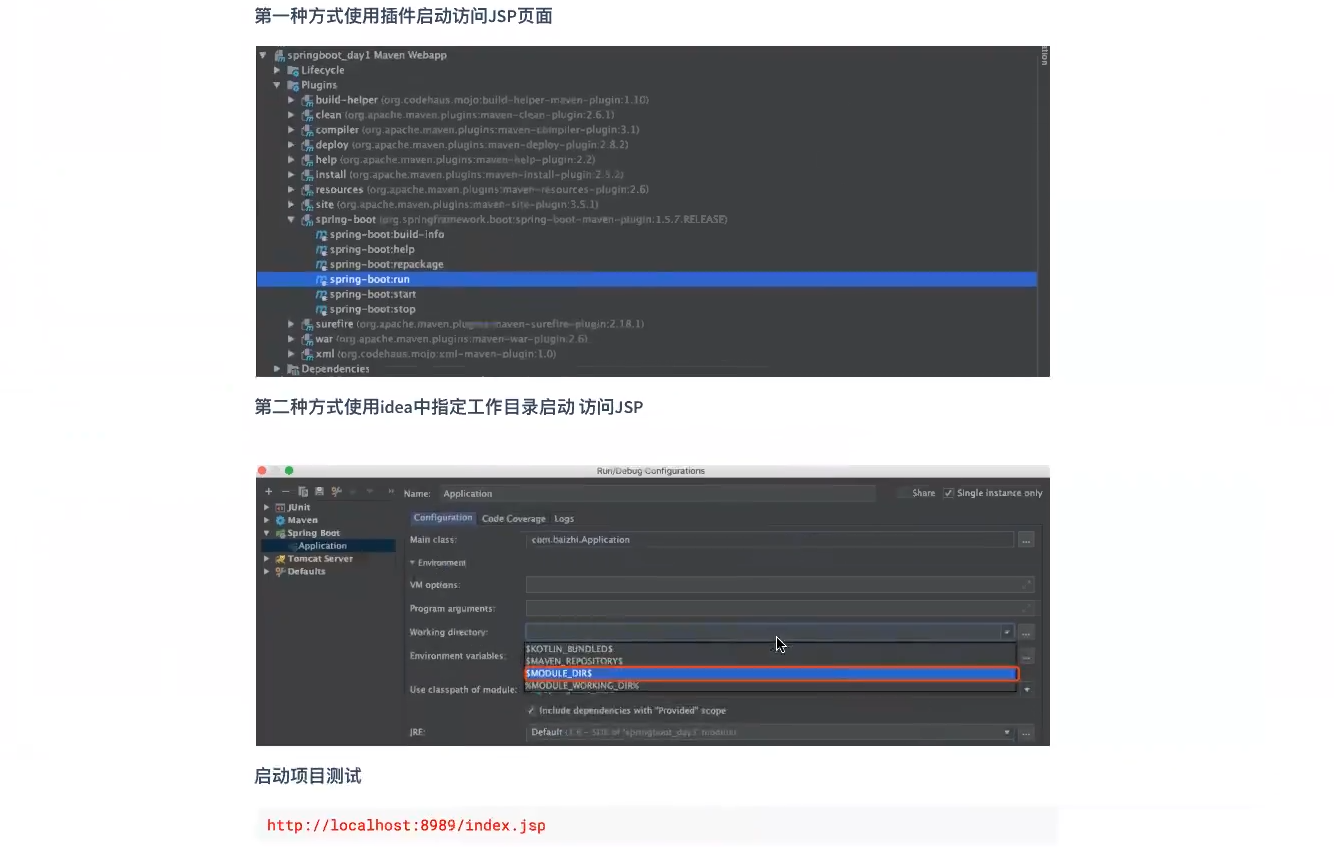
集成jsp

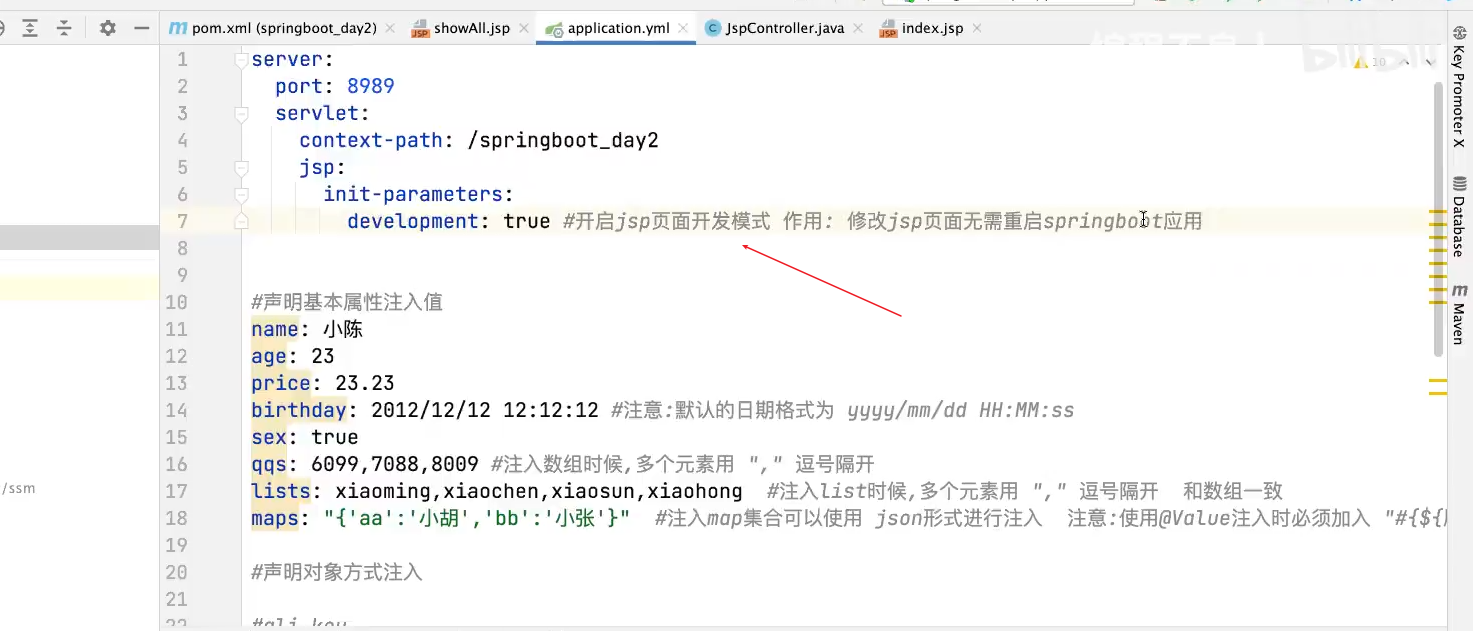
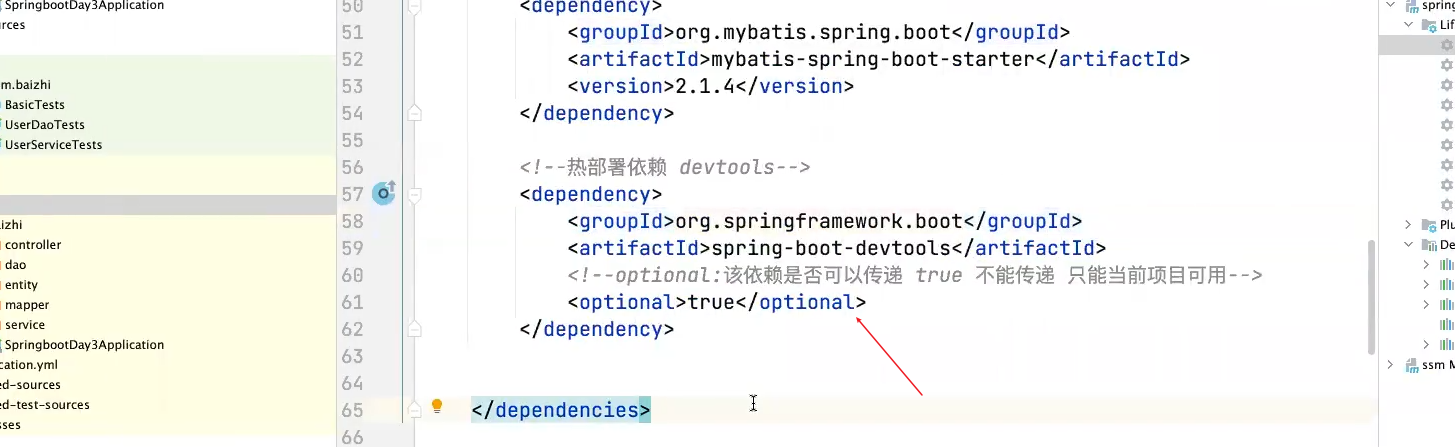
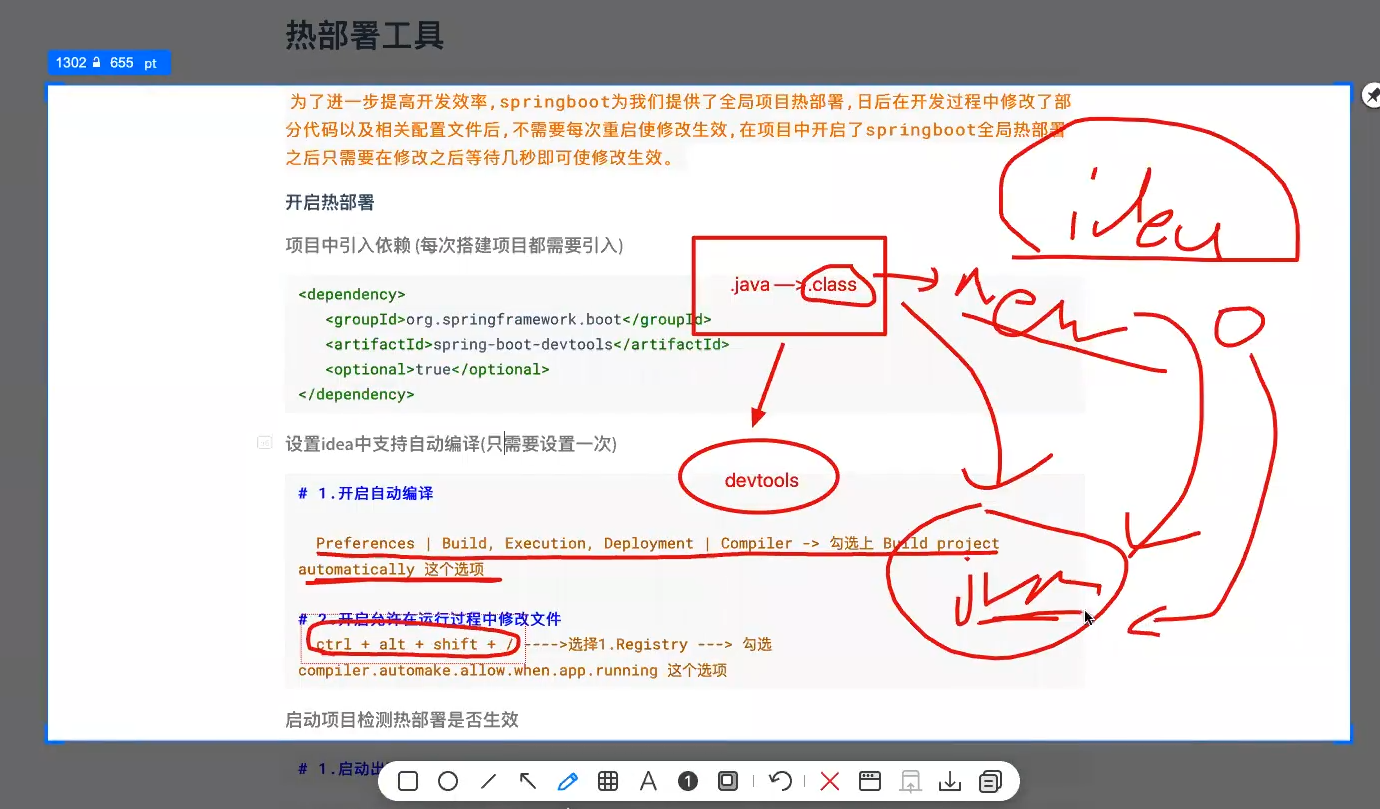
热部署
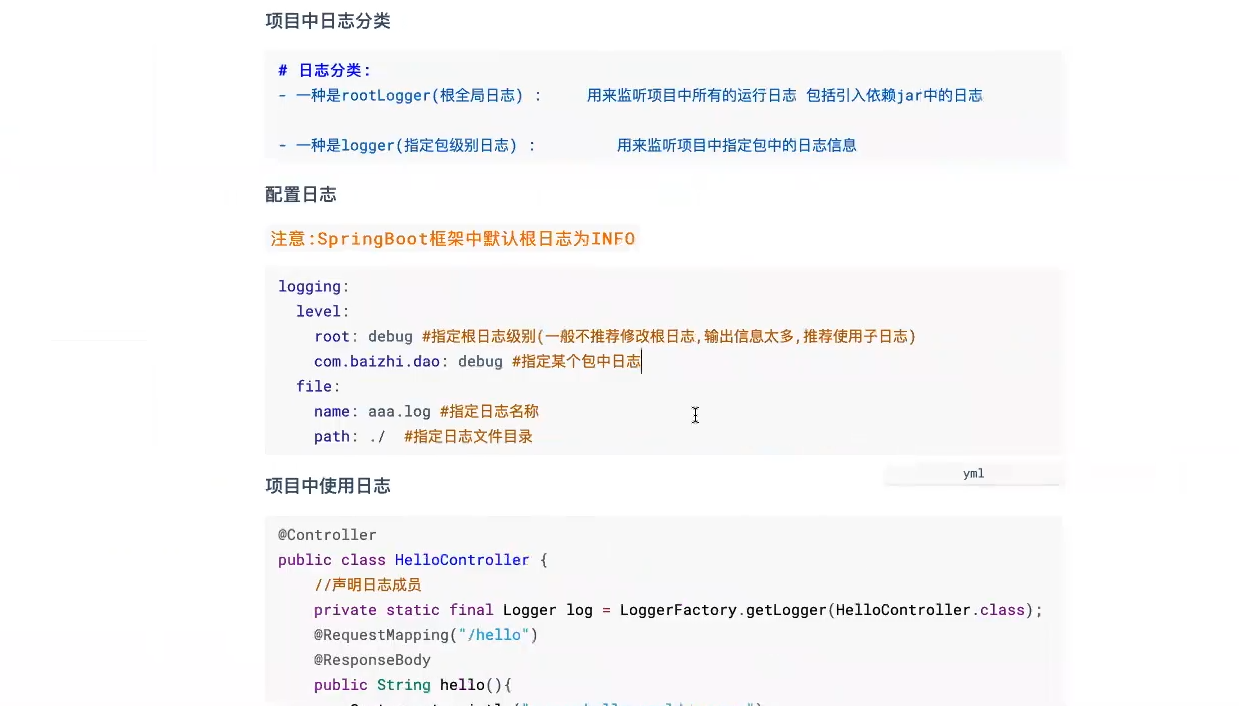
日志

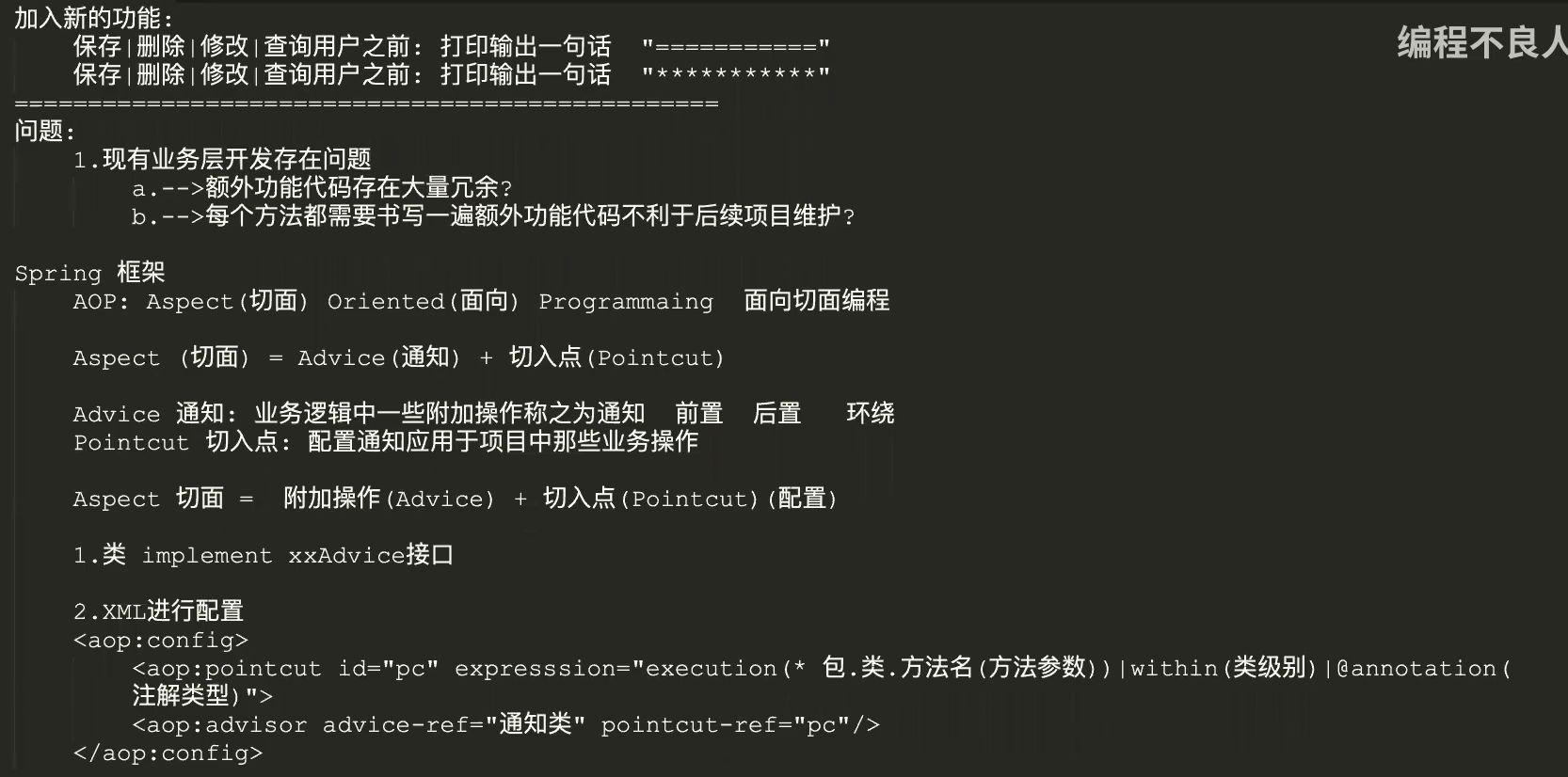
aop

拦截器
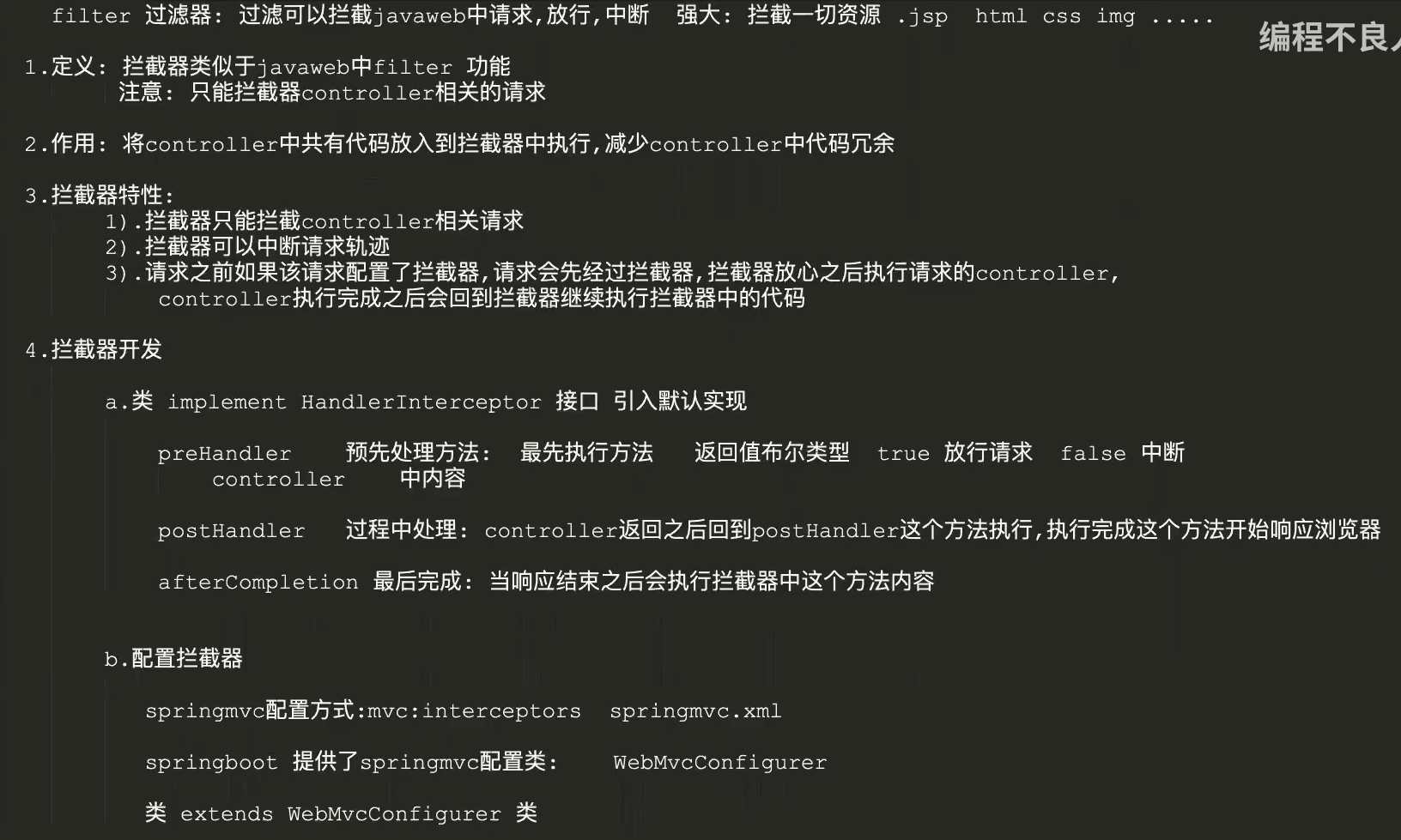
自定义拦截器
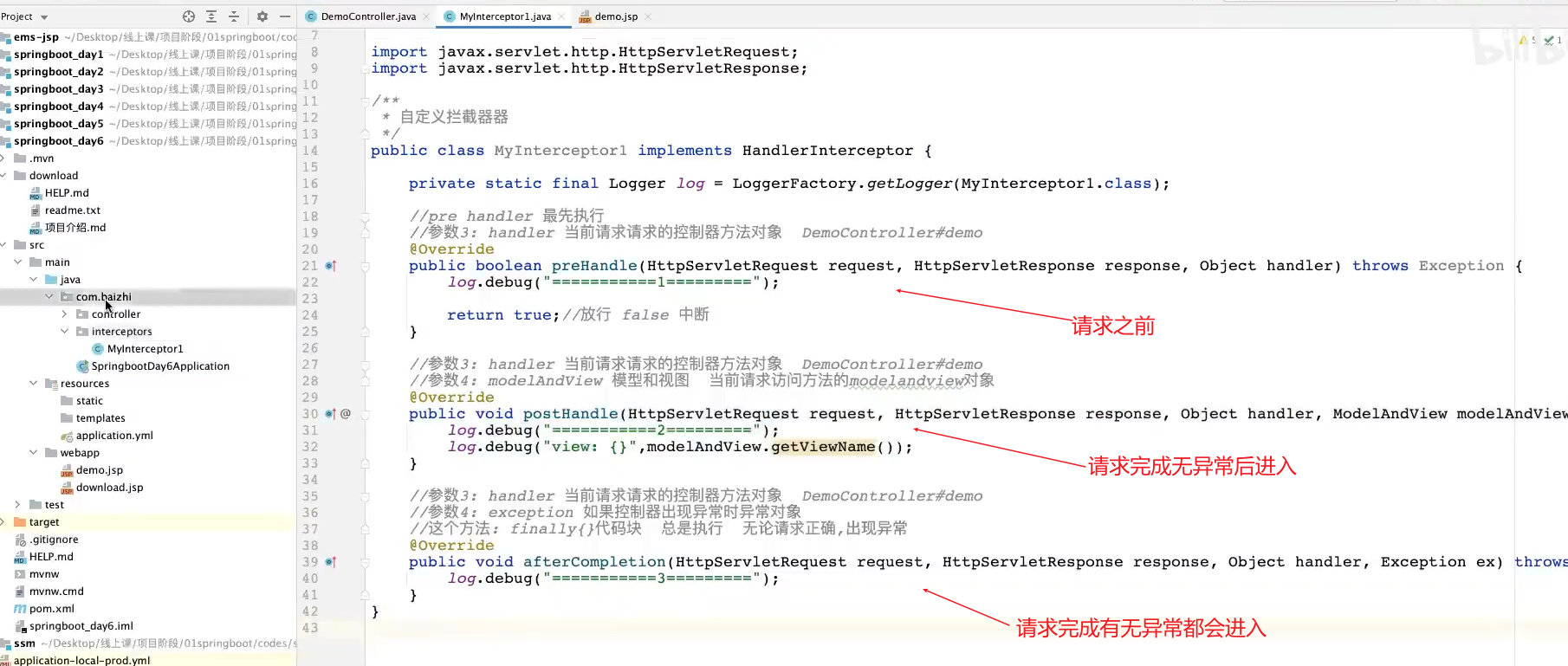
注册拦截器,
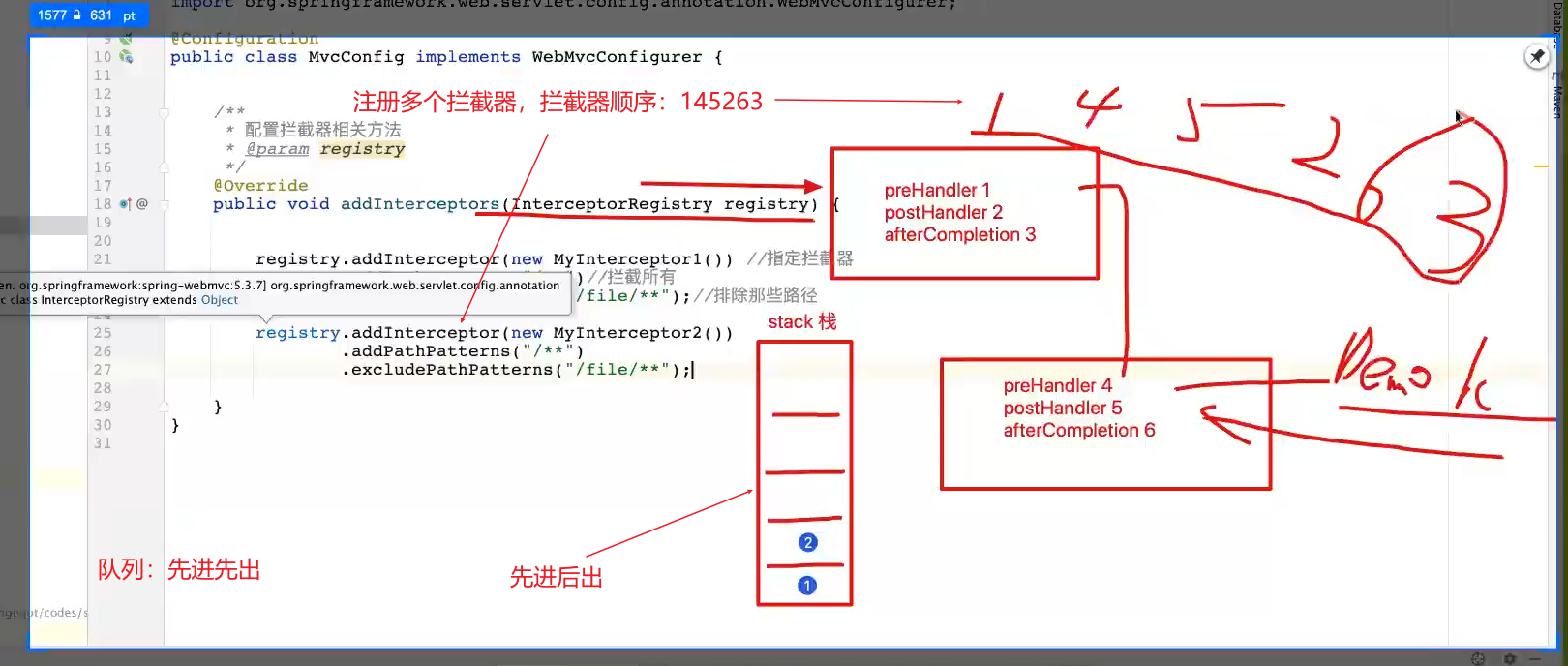
指定拦截器执行顺序

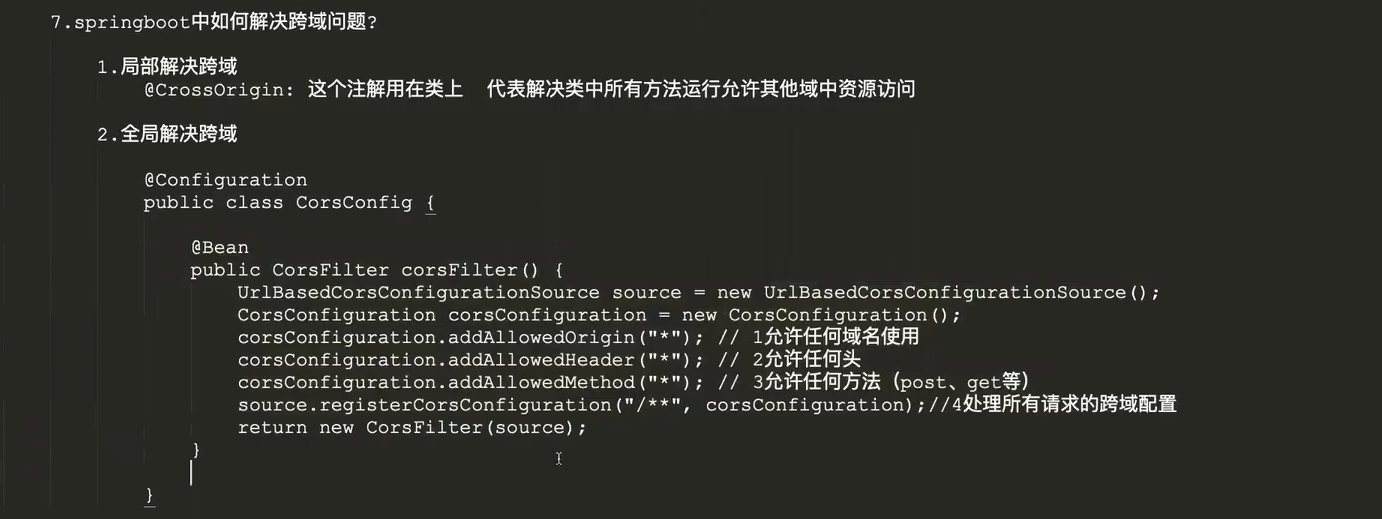
CORS&同源策略
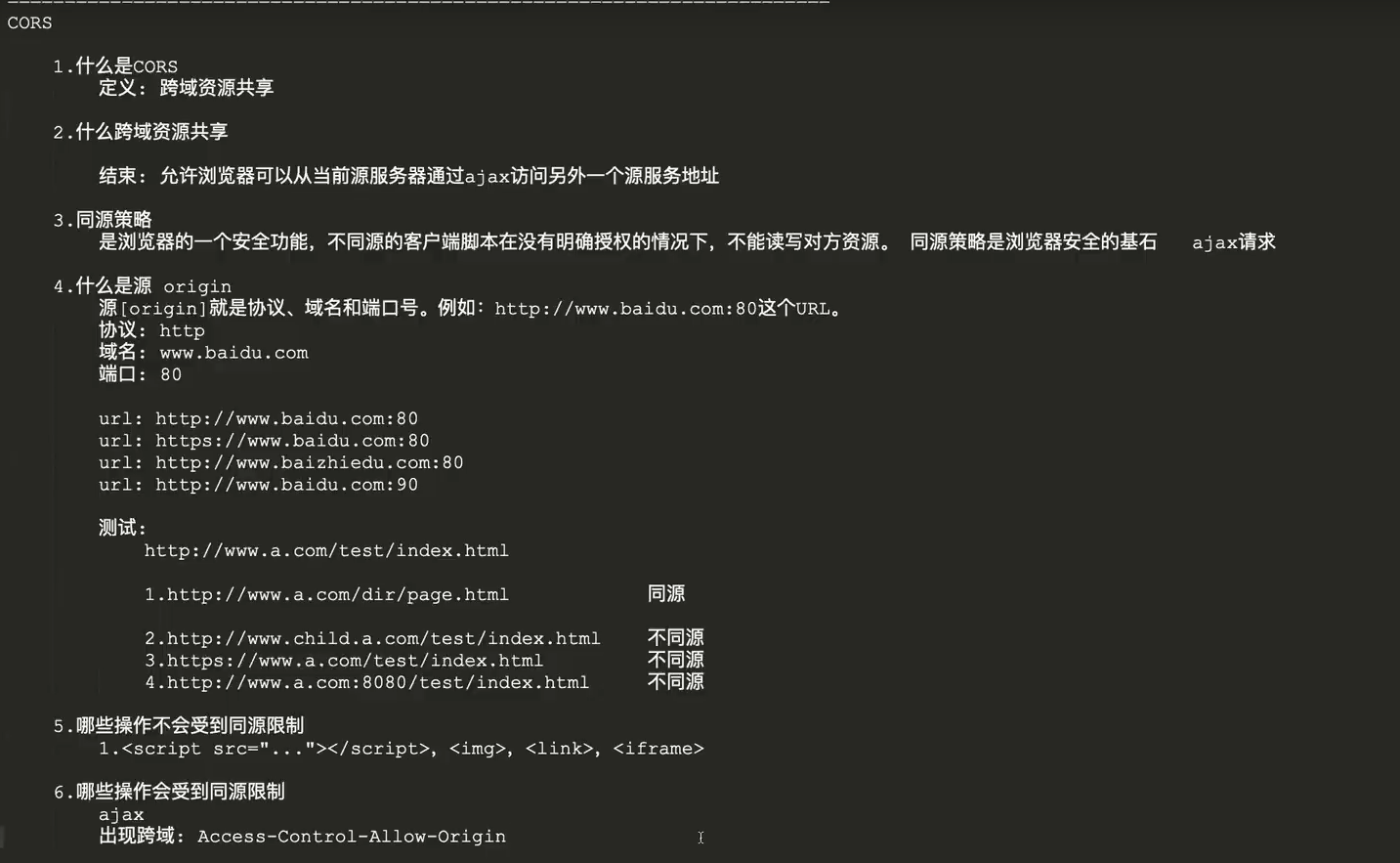
43.网络安全中常见的攻击方式
1.客户端攻击
XSS攻击
XSS攻击即跨站点脚本攻击(Cross Site Script),为不和层叠样式表(Cascading Style Sheets, CSS)的缩写混淆,故将跨站脚本攻击缩写为XSS。
它允许恶意web用户将代码植入到提供给其它用户使用的页面中。
| 类型 | 解释 |
|---|---|
| 反射型XSS攻击 | 简单说,就是要用户去点击,点了我才执行响应的命令。这种类型的XSS攻击是最常见的。 |
| 持久型XSS攻击 | 服务端已经接收了,并且存入数据库,当用户访问这个页面时,这段XSS代码会自己触发,不需要由客户端去手动触发操作。 |
| DOM XSS | 简单理解,DOM XSS就是出现在JavaScript代码中的漏洞。 |
防御方式:对输入的数据做过滤处理。
CSRF攻击
CSRF(Cross Site Request Forgeries),意为跨网站请求伪造,也有写为XSRF。攻击者通过跨站请求,以合法用户的身份进行非法操作,如转账交易、发表评论等。CSRF的主要手法是利用跨站请求,在用户不知情的情况下,以用户的身份伪造请求。其核心是利用了浏览器Cookie或服务器Session策略,盗取用户身份。
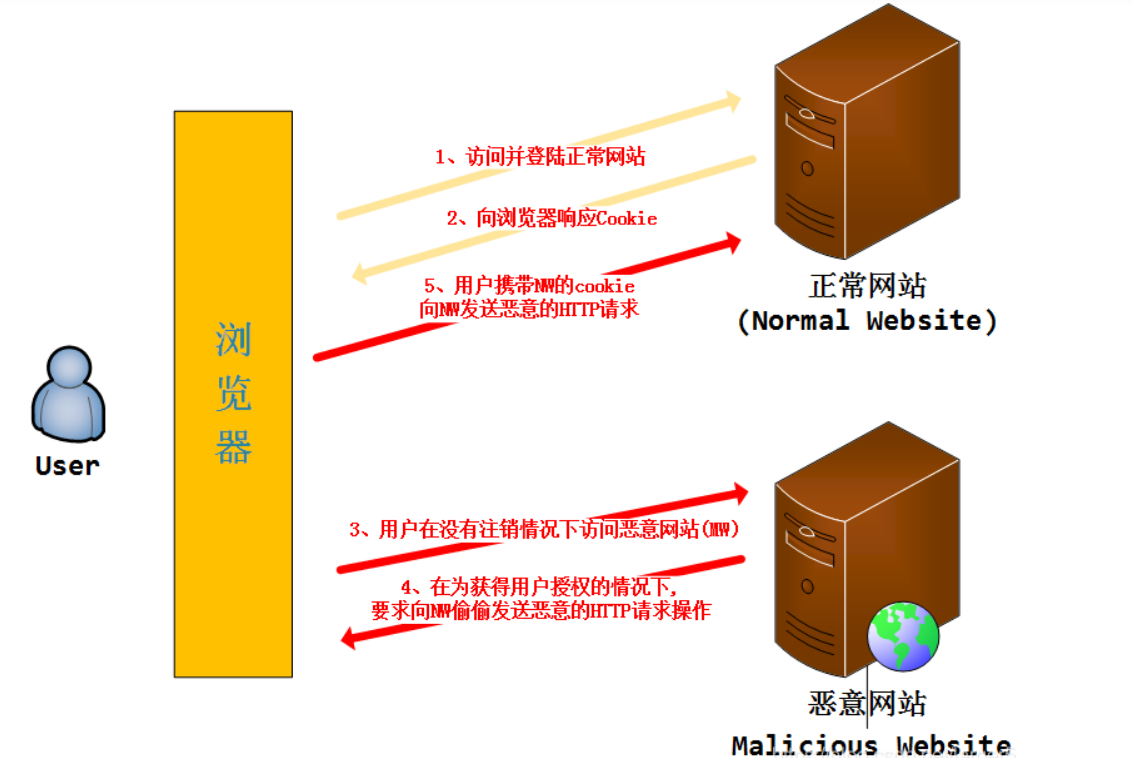
CSRF为什么能够攻击成功?其本质原因是重要操作的所有参数都是可以被攻击者猜测到的。
| 防御方式 | 具体操作 |
|---|---|
| header 加 Token | 表单Token通过在请求参数中增加随机数的办法来阻止攻击者获得所有请求参数(✔) |
| 验证码 | 暴力防御方式,用户体验差 |
| 请求地址验证 | ip校验 |
Spring Security、Struts2等Java框架都已经内置提供了CSRF的防御机制。
2.服务端攻击
SQL注入
攻击者在HTTP请求中注入恶意SQL命令(如:drop table users;),服务器用请求参数构造数据库SQL命令时,恶意SQL被一起构造,并在数据库中执行。
防御方式
- 使用预处理 PreparedStatement而不用Statement。
- 使用正则表达式过滤掉字符中的特殊字符。
目前许多数据访问层框架,如IBatis,Hibernate等,都实现SQL预编译和参数绑定,攻击者的恶意SQL会被当做SQL的参数,而不是SQL命令被执行。
DDOS攻击
首先说说DOS攻击,正如我们所知,当客户端向服务器发送IP请求时,二则和之间要经历TCP的三次握手才会建立连接,DOS攻击就是通过发送大量的虚假IP请求,这时服务器回复确认包后却一直等不到客户的确认,服务器就会一直重发,超时,重发,超时…DOS攻击成功
DoS 是 Denial of Service 的简称,即拒绝服务,造成 DoS 的攻击行为被称为 DoS 攻击,其目的是使计算机或网络无法提供正常的服务。
| 防御方式 | 具体操作 |
|---|---|
| 验证码 | 暴力防御方式,用户体验差 |
| 限制请求频率 | Yahoo算法,根据IP地址和Cookie等信息,可以计算客户端的请求频率并进行拦截。 |
概念
- 分布式拒绝服务攻击(Distributed Denial of Service),相比较于DOS就是不只一个攻击者,而是大量的攻击者发出大量的虚假IP请求,杀伤力远大于DOS。简单说就是发送大量请求是使服务器瘫痪。
- DDos攻击是在DOS攻击基础上的,可以通俗理解,dos是单挑,而ddos是群殴,因为现代技术的发展,dos攻击的杀伤力降低,所以出现了DDOS,攻击者借助公共网络,将大数量的计算机设备联合起来,向一个或多个目标进行攻击。
案例
- SYN Flood ,简单说一下tcp三次握手,客户端先服务器发出请求,请求建立连接,然后服务器返回一个报文,表明请求以被接受,然后客户端也会返回一个报文,最后建立连接。那么如果有这么一种情况,攻击者伪造ip地址,发出报文给服务器请求连接,这个时候服务器接受到了,根据tcp三次握手的规则,服务器也要回应一个报文,可是这个ip是伪造的,报文回应给谁呢,第二次握手出现错误,第三次自然也就不能顺利进行了,这个时候服务器收不到第三次握手时客户端发出的报文,又再重复第二次握手的操作。如果攻击者伪造了大量的ip地址并发出请求,这个时候服务器将维护一个非常大的半连接等待列表,占用了大量的资源,最后服务器瘫痪。
- CC攻击,在应用层http协议上发起攻击,模拟正常用户发送大量请求直到该网站拒绝服务为止。
被攻击的原因
- 服务器带宽不足,不能挡住攻击者的攻击流量
预防
- 最直接的方法增加带宽。但是攻击者用各地的电脑进行攻击,他的带宽不会耗费很多钱,但对于服务器来说,带宽非常昂贵。
- 云服务提供商有自己的一套完整DDoS解决方案,并且能提供丰富的带宽资源
3.补充:什么是带宽?
在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。对于带宽的概念,比较形象的一个比喻是高速公路。单位时间内能够在线路上传送的数据量,常用的单位是bps(bit per second)。计算机网络的带宽是指网络可通过的最高数据率,即每秒多少比特。
一般来说,带宽是以 bit(比特)表示,而电信,联通,移动等运营商在推广的时候往往忽略了这个单位。
正常换算情况如下:
1Mbit=128KB
2Mbit=256KB
(以此类推)
而换算后的速度才是您真实上网的速度,也就是说,如果你从你的运营商开通的带宽是10M,那么代入计算公式,以上面换算的1M来计量则为:
(1M=1024K)
1M/128K=1024/128=8
10/8=1.25M
也就是说你如果开通10M带宽,可以达到最高1.25M的速度一般来说,一台计算机观看电影,玩游戏等,4M带宽足够。
以下哔哩哔哩链接:https://space.bilibili.com/397020648/video?tid=0&page=4&keyword=&order=pubdate
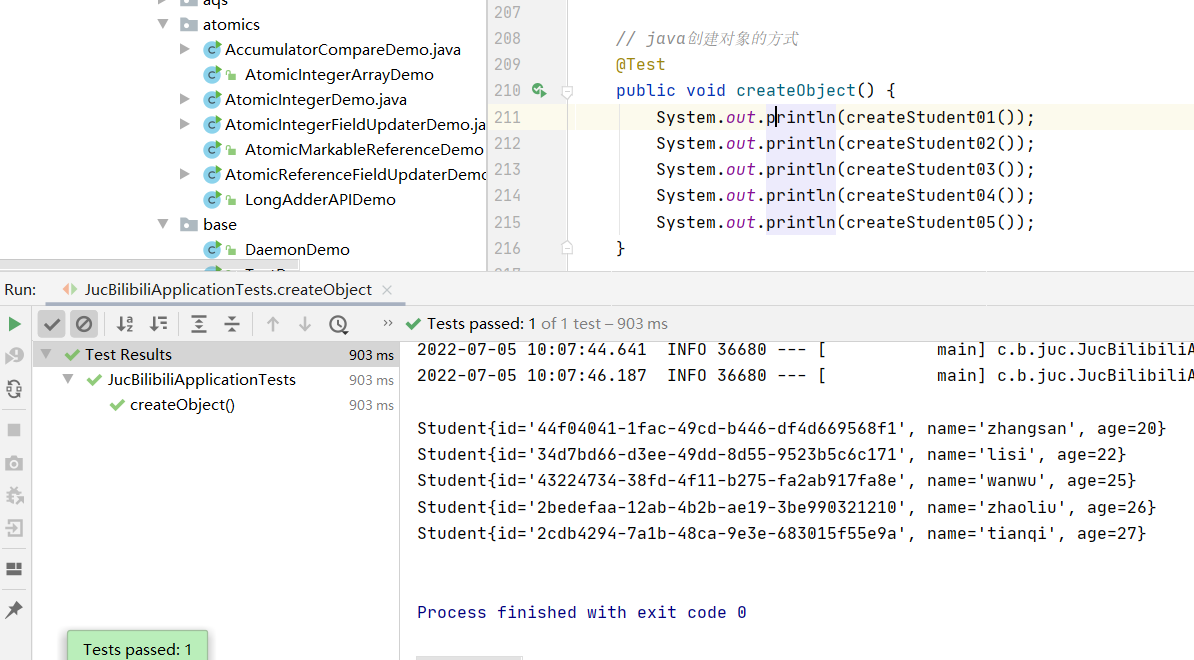
Java创建对象的5种方式
// java创建对象的5种方式
@Test
public void createObject() {
System.out.println(createStudent01());
System.out.println(createStudent02());
System.out.println(createStudent03());
System.out.println(createStudent04());
System.out.println(createStudent05());
}
// 1.通过new xxx()调用构造方法创建对象
private Student createStudent01() {
return new Student(UUID.randomUUID().toString(), "zhangsan", 20);
}
// 2.通过反射,调用xxx.getClass().newInstance()创建对象
private Student createStudent02() {
try {
// 得到一个空的对象
Student student = Student.class.newInstance();
student.setId(UUID.randomUUID().toString());
student.setName("lisi");
student.setAge(22);
return student;
} catch (InstantiationException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
return null;
}
// 3.通过反射,调用construct.newInstance()创建对象
private Student createStudent03() {
// 获取Student类对应的class字节码对象
Class<Student> studentClass = Student.class;
Constructor<Student> constructor = null;
try {
// 获取Student类中有参构造方法
constructor = studentClass.getConstructor(String.class, String.class, Integer.class);
} catch (NoSuchMethodException e) {
e.printStackTrace();
}
Student wanwu = null;
try {
// 创建对象
wanwu = constructor.newInstance(UUID.randomUUID().toString(), "wanwu", 25);
} catch (InstantiationException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
return wanwu;
}
// 4.通过xxx.clone()克隆方式创建(需要实现Cloneable接口,重写clone方法)
public Student createStudent04(){
Student student = new Student(UUID.randomUUID().toString(), "zhaoliu", 26);
try {
Student clone = (Student)student.clone();
return clone;
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return null;
}
// 5.通过序列化,反序列化创建对象(需要实现Serializable接口)
public Student createStudent05(){
Student student = new Student(UUID.randomUUID().toString(), "tianqi", 27);
try {
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("E:\\student.txt"));
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("E:\\student.txt"));
// 调用输出流将student对象序列化到E:\student.txt
objectOutputStream.writeObject(student);
// 从E:\student.txt文件中反序列化出student对象
Student object = (Student)objectInputStream.readObject();
return object;
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
return null;
}
static class Student implements Serializable, Cloneable {
private String id;
private String name;
private Integer age;
public Student() {
}
public Student(String id, String name, Integer age) {
this.id = id;
this.name = name;
this.age = age;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"id='" + id + '\'' +
", name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
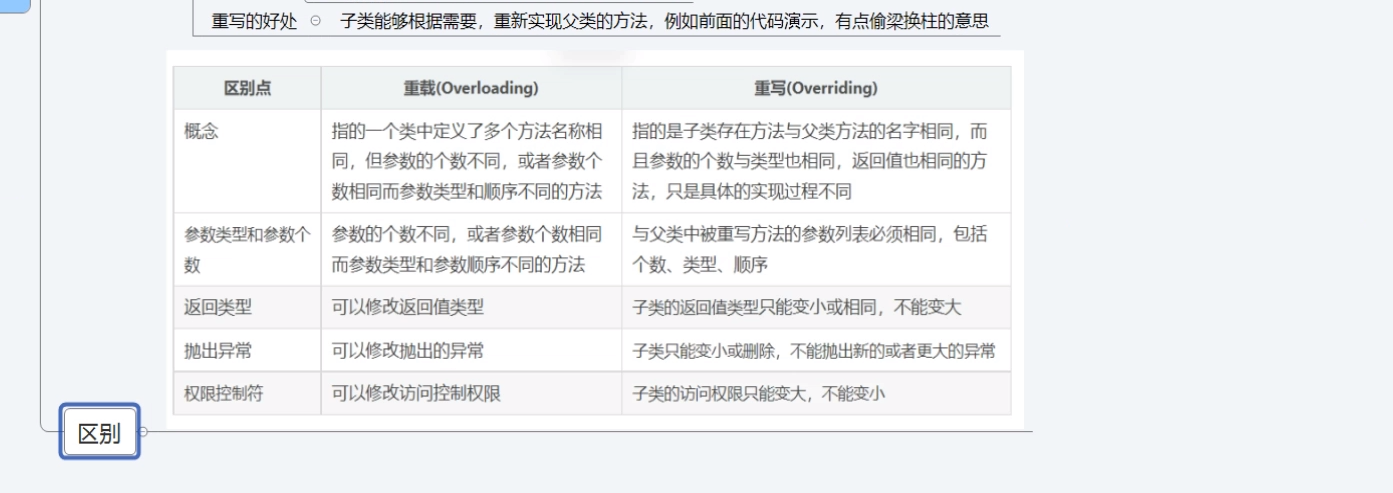
方法重载和重写的区别
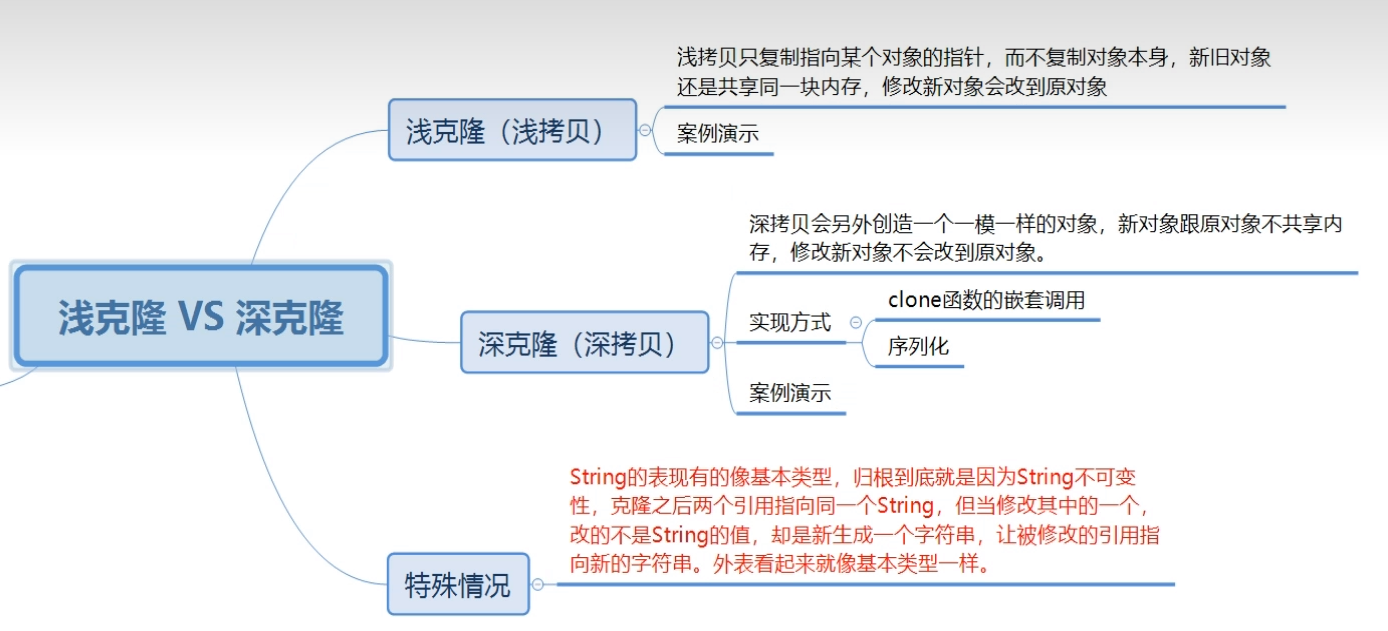
深拷贝与浅拷贝
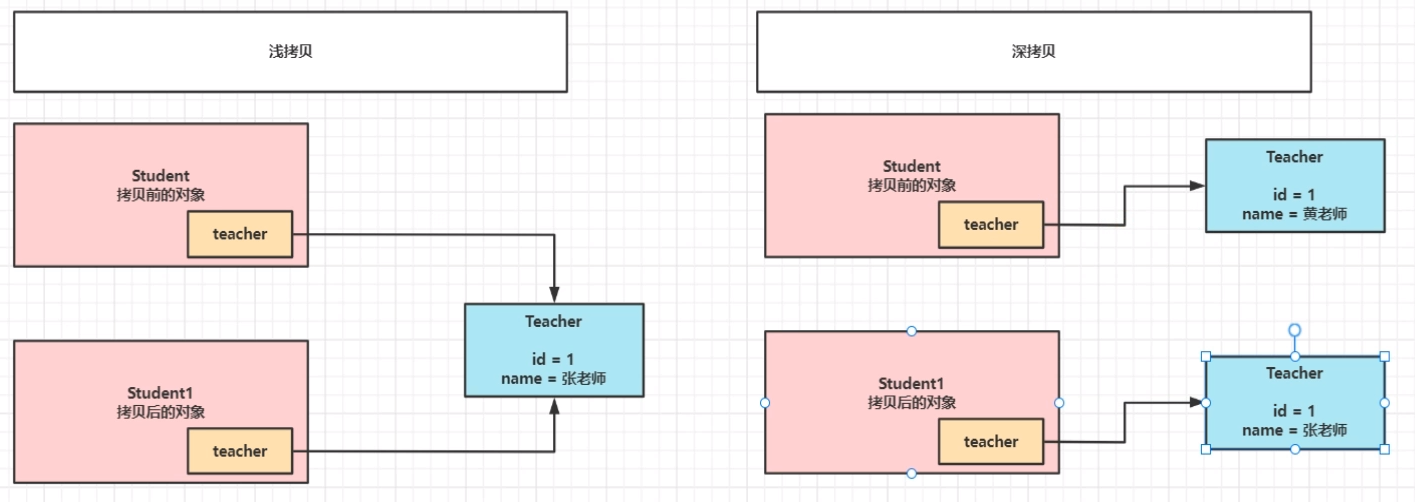
浅拷贝:
teacher:
package com.bilibili.juc.clone;
public class Teacher {
private Integer pkid;
private String name;
public Teacher() {
}
public Teacher(Integer pkid, String name) {
this.pkid = pkid;
this.name = name;
}
public Integer getPkid() {
return pkid;
}
public void setPkid(Integer pkid) {
this.pkid = pkid;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Teacher{" +
"pkid=" + pkid +
", name='" + name + '\'' +
'}';
}
}
student:
package com.bilibili.juc.clone;
public class Student implements Cloneable{
private double weight;
private Integer pkid;
private String name;
// 持有一个教师对象的引用
private Teacher teacher;
public Student(double weight, Integer pkid, String name, Teacher teacher) {
this.weight = weight;
this.pkid = pkid;
this.name = name;
this.teacher = teacher;
}
public double getWeight() {
return weight;
}
public void setWeight(double weight) {
this.weight = weight;
}
public Integer getPkid() {
return pkid;
}
public void setPkid(Integer pkid) {
this.pkid = pkid;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Teacher getTeacher() {
return teacher;
}
public void setTeacher(Teacher teacher) {
this.teacher = teacher;
}
@Override
public String toString() {
return "Student{" +
"weight=" + weight +
", pkid=" + pkid +
", name='" + name + '\'' +
", teacher=" + teacher +
'}';
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
测试:
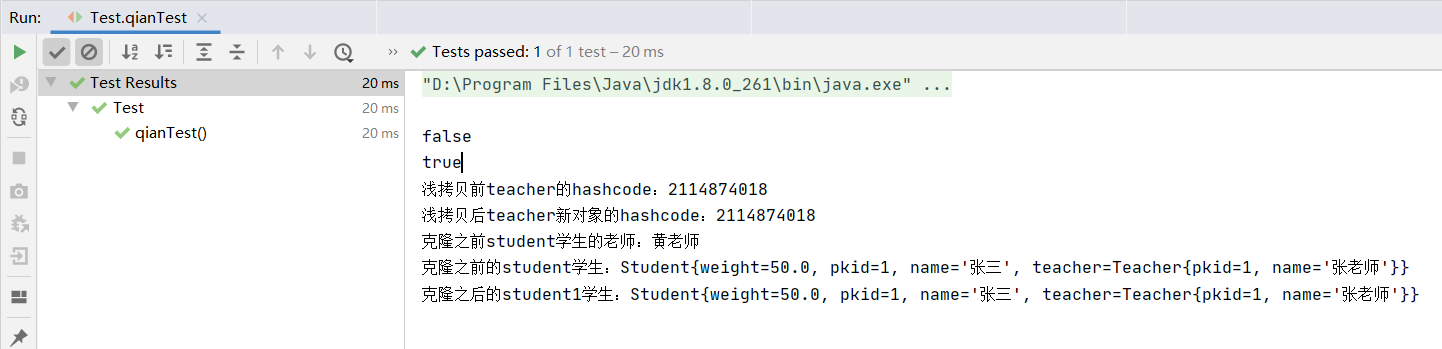
// 浅拷贝演示
@org.junit.jupiter.api.Test
public void qianTest() throws CloneNotSupportedException {
Teacher teacher = new Teacher(1, "黄老师");
// 浅拷贝之前的对象
Student student = new Student(50.00, 1, "张三", teacher);
// 浅拷贝之后的对象
Student student1 = (Student) student.clone();
System.out.println(student == student1);
System.out.println(student.getTeacher() == student1.getTeacher());
System.out.println("浅拷贝前teacher的hashcode:" + student.getTeacher().hashCode());
System.out.println("浅拷贝后teacher新对象的hashcode:" + student1.getTeacher().hashCode());
System.out.println("克隆之前student学生的老师:" + student.getTeacher().getName());
// 将克隆后的对象student1的老师姓名改为张老师,导致旧student的老师姓名也被修改
student1.getTeacher().setName("张老师");
System.out.println("克隆之前的student学生:" + student);
System.out.println("克隆之后的student1学生:" + student1);
}
深拷贝
teacher2:
package com.bilibili.juc.clone;
public class Teacher2 implements Cloneable{
private Integer pkid;
private String name;
public Teacher2() {
}
public Teacher2(Integer pkid, String name) {
this.pkid = pkid;
this.name = name;
}
public Integer getPkid() {
return pkid;
}
public void setPkid(Integer pkid) {
this.pkid = pkid;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Teacher{" +
"pkid=" + pkid +
", name='" + name + '\'' +
'}';
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
student2:
package com.bilibili.juc.clone;
public class Student2 implements Cloneable{
private double weight;
private Integer pkid;
private String name;
// 持有一个教师对象的引用
private Teacher2 teacher;
public Student2(double weight, Integer pkid, String name, Teacher2 teacher) {
this.weight = weight;
this.pkid = pkid;
this.name = name;
this.teacher = teacher;
}
public double getWeight() {
return weight;
}
public void setWeight(double weight) {
this.weight = weight;
}
public Integer getPkid() {
return pkid;
}
public void setPkid(Integer pkid) {
this.pkid = pkid;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Teacher2 getTeacher() {
return teacher;
}
public void setTeacher(Teacher2 teacher) {
this.teacher = teacher;
}
@Override
public String toString() {
return "Student{" +
"weight=" + weight +
", pkid=" + pkid +
", name='" + name + '\'' +
", teacher=" + teacher +
'}';
}
@Override
protected Object clone() throws CloneNotSupportedException {
Student2 student = null;
student = (Student2) super.clone();
// 拷贝teacher对象
student.teacher = (Teacher2)this.teacher.clone();
return student;
}
}
测试:
// 深拷贝演示
@org.junit.jupiter.api.Test
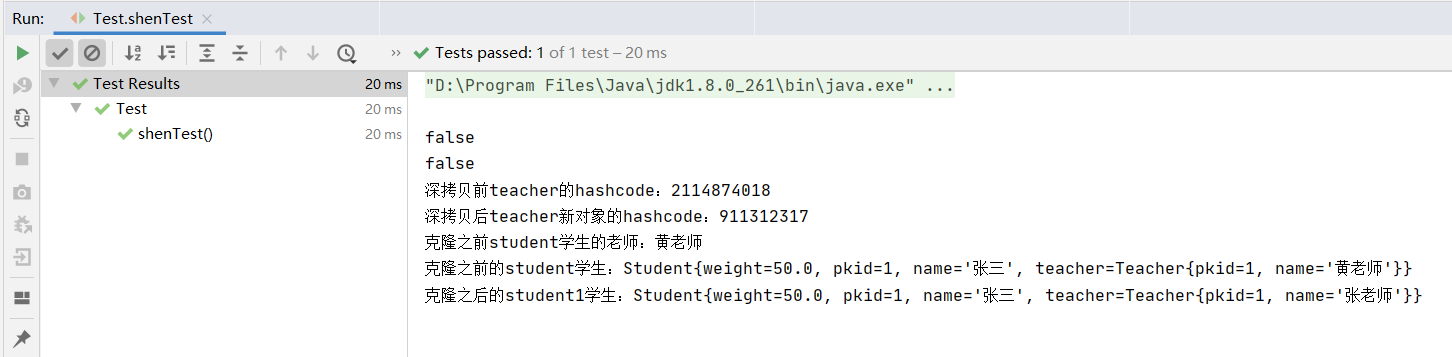
public void shenTest() throws CloneNotSupportedException {
Teacher2 teacher = new Teacher2(1, "黄老师");
// 深拷贝之前的对象
Student2 student = new Student2(50.00, 1, "张三", teacher);
// 深拷贝之后的对象
Student2 student1 = (Student2) student.clone();
System.out.println(student == student1);
System.out.println(student.getTeacher() == student1.getTeacher());
System.out.println("深拷贝前teacher的hashcode:" + student.getTeacher().hashCode());
System.out.println("深拷贝后teacher新对象的hashcode:" + student1.getTeacher().hashCode());
System.out.println("克隆之前student学生的老师:" + student.getTeacher().getName());
// 将克隆后的对象student1的老师姓名改为张老师,因为是深拷贝,旧student的老师姓名不会被修改
student1.getTeacher().setName("张老师");
System.out.println("克隆之前的student学生:" + student);
System.out.println("克隆之后的student1学生:" + student1);
}
通过序列化实现深拷贝
teacher3:
package com.bilibili.juc.clone;
import java.io.Serializable;
public class Teacher3 implements Serializable {
private Integer pkid;
private String name;
public Teacher3() {
}
public Teacher3(Integer pkid, String name) {
this.pkid = pkid;
this.name = name;
}
public Integer getPkid() {
return pkid;
}
public void setPkid(Integer pkid) {
this.pkid = pkid;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Teacher{" +
"pkid=" + pkid +
", name='" + name + '\'' +
'}';
}
}
student3:
package com.bilibili.juc.clone;
import java.io.*;
/*
* @author: TangYong
* @since: 2022/7/5 10:22
*/
public class Student3 implements Serializable {
private double weight;
private Integer pkid;
private String name;
// 持有一个教师对象的引用
private Teacher3 teacher;
public Student3(double weight, Integer pkid, String name, Teacher3 teacher) {
this.weight = weight;
this.pkid = pkid;
this.name = name;
this.teacher = teacher;
}
public double getWeight() {
return weight;
}
public void setWeight(double weight) {
this.weight = weight;
}
public Integer getPkid() {
return pkid;
}
public void setPkid(Integer pkid) {
this.pkid = pkid;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Teacher3 getTeacher() {
return teacher;
}
public void setTeacher(Teacher3 teacher) {
this.teacher = teacher;
}
@Override
public String toString() {
return "Student{" +
"weight=" + weight +
", pkid=" + pkid +
", name='" + name + '\'' +
", teacher=" + teacher +
'}';
}
// 通过序列化实现深拷贝
public Student3 deepCloneBySerializable() {
Student3 student = null;
ByteArrayOutputStream byteArrayOutputStream = null;
ObjectOutputStream objectOutputStream = null;
ByteArrayInputStream byteArrayInputStream = null;
ObjectInputStream objectInputStream = null;
try {
byteArrayOutputStream = new ByteArrayOutputStream();
objectOutputStream = new ObjectOutputStream(byteArrayOutputStream);//对象序列化
objectOutputStream.writeObject(this);
byteArrayInputStream = new ByteArrayInputStream(byteArrayOutputStream.toByteArray());
objectInputStream = new ObjectInputStream(byteArrayInputStream);
//对象的反序列化
student = (Student3) objectInputStream.readObject();
return student;
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
} finally {
if (null != objectInputStream) {
try {
objectInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (null != byteArrayInputStream) {
try {
byteArrayInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (null != objectOutputStream) {
try {
objectOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (null != byteArrayOutputStream) {
try {
byteArrayOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return null;
}
}
测试:
// 深拷贝演示-通过序列化
@org.junit.jupiter.api.Test
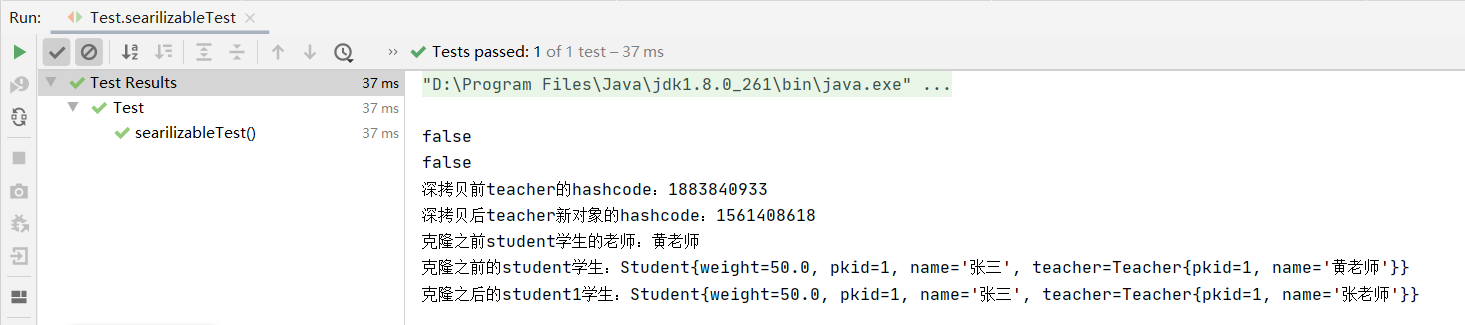
public void searilizableTest() throws CloneNotSupportedException {
Teacher3 teacher = new Teacher3(1, "黄老师");
// 深拷贝之前的对象
Student3 student = new Student3(50.00, 1, "张三", teacher);
// 深拷贝之后的对象
Student3 student1 = (Student3) student.deepCloneBySerializable();
System.out.println(student == student1);
System.out.println(student.getTeacher() == student1.getTeacher());
System.out.println("深拷贝前teacher的hashcode:" + student.getTeacher().hashCode());
System.out.println("深拷贝后teacher新对象的hashcode:" + student1.getTeacher().hashCode());
System.out.println("克隆之前student学生的老师:" + student.getTeacher().getName());
// 将克隆后的对象student1的老师姓名改为张老师,因为是深拷贝,旧student的老师姓名不会被修改
student1.getTeacher().setName("张老师");
System.out.println("克隆之前的student学生:" + student);
System.out.println("克隆之后的student1学生:" + student1);
}
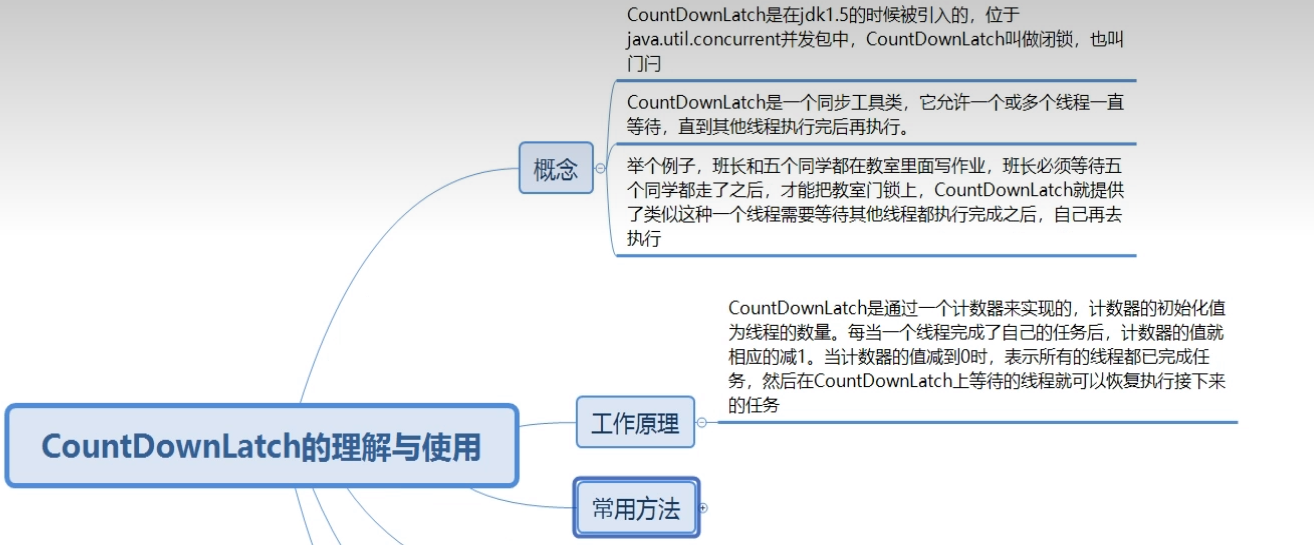
CountDownLatch的使用

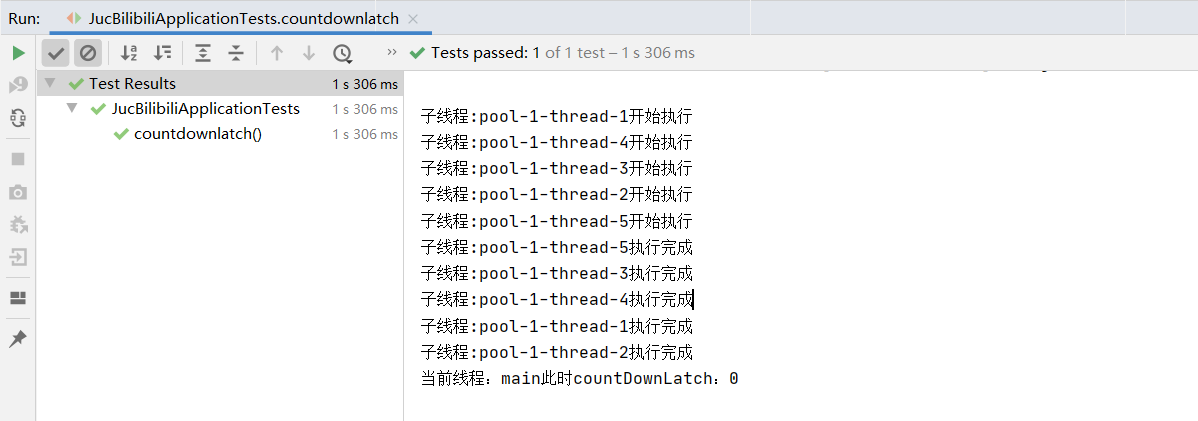
@Test
public void countdownlatch(){
final int THREAD_NUM = 5;
// 创建固定线程数的线程池
ExecutorService executorService = Executors.newFixedThreadPool(THREAD_NUM);
// 如果有n个子线程,我们就指定CountDownLatch的计数器为n
final CountDownLatch countDownLatch = new CountDownLatch(THREAD_NUM);
// 提交任务到线程池
for (int i = 0; i< THREAD_NUM; i++) {
executorService.execute(() -> {
try {
//模拟每个线程处理业务,耗时一秒钟
System.out.println("子线程:" +Thread.currentThread() . getName() + "开始执行");
//模拟每个线程处理业务,耗时一秒钟
TimeUnit.SECONDS.sleep( 1);
System. out.println("子线程:" +Thread.currentThread().getName() +"执行完成");
//当前线程调用此方法,则计数减一
countDownLatch.countDown();
}catch (InterruptedException e){
e.printStackTrace();
}
});
}
// 阻塞当前线程(此处为main线程),直到计数器的值为0,main线程才开始处理
try {
countDownLatch.await();
System.out.println("当前线程:" + Thread.currentThread().getName() + "此时countDownLatch:" + countDownLatch.getCount());
} catch (InterruptedException e) {
e.printStackTrace();
}
// 销毁线程池
executorService.shutdown();
}
String s = new String(“abc”)创建了几个对象
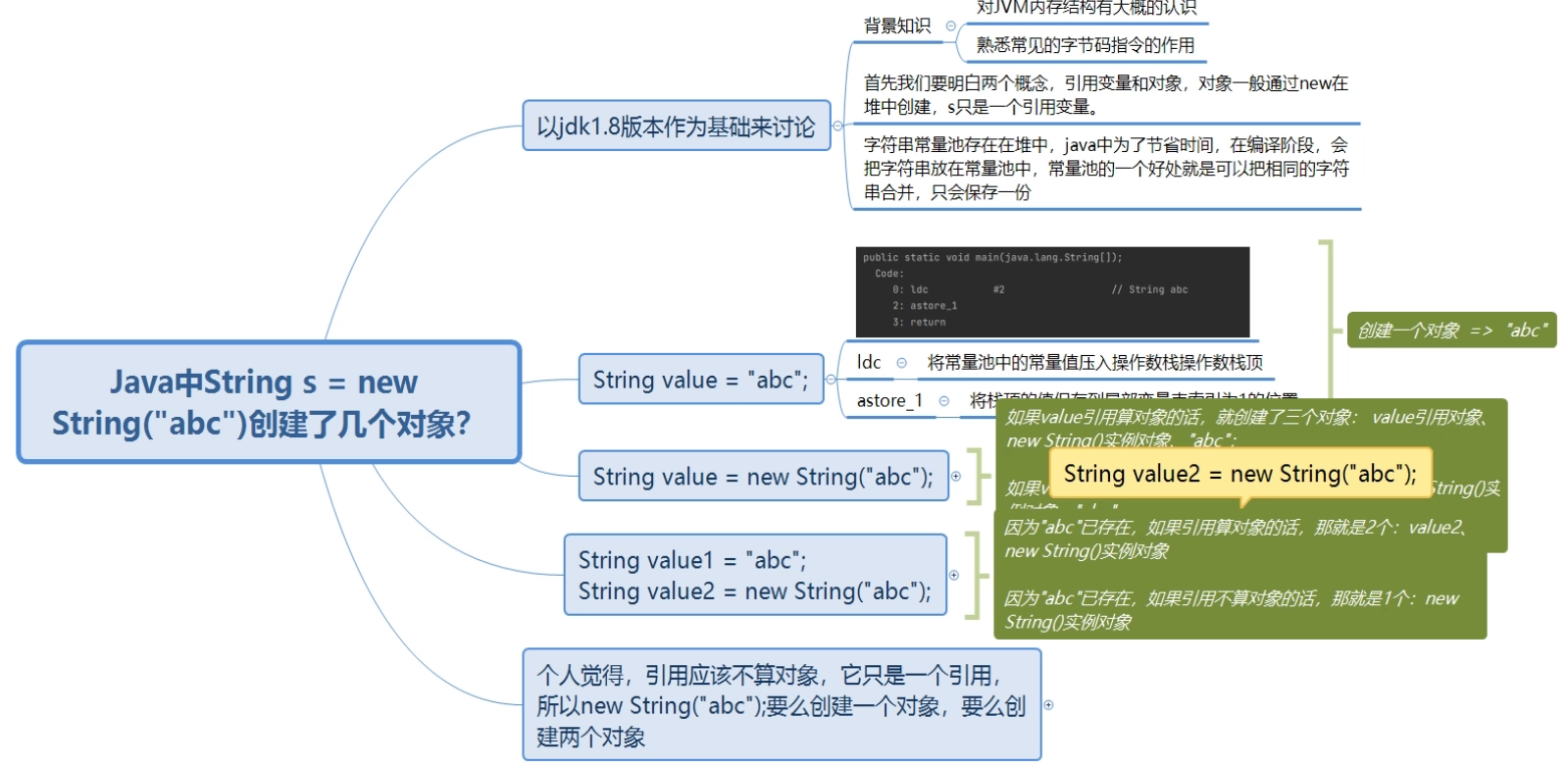
public class NewString {
public static void main(String[] args) {
// 在方法执行过程中,根据字节码指令,往栈里写入数据或提取数据,即入栈/出栈。某些字节码指令把值压入操作数栈,其余指令将操作数取出栈。
// 1.在字符串常量池中创建了一个“abc”的字符串常量
// 2.把字符串常量“abc”的值压入到操作数栈中
// 3.把栈中的元素存入到局部变量表索引为1的位置
// 4.方法返回
String abc = "abc";
}
}

public class NewString {
public static void main(String[] args) {
// 1.创建一个新的实例
// 2.复制栈中的元素并把复制的值压入到操作数栈中
// 3.在字符串常量池中创建了一个“abc”的字符串常量
// 4.把字符串常量“abc”的值压入到操作数栈中
// 5.调用String构造方法,
// 6.把栈中的元素存入到局部变量表索引为1的位置
// 7.方法返回
String abc = new String("abc");
}
}
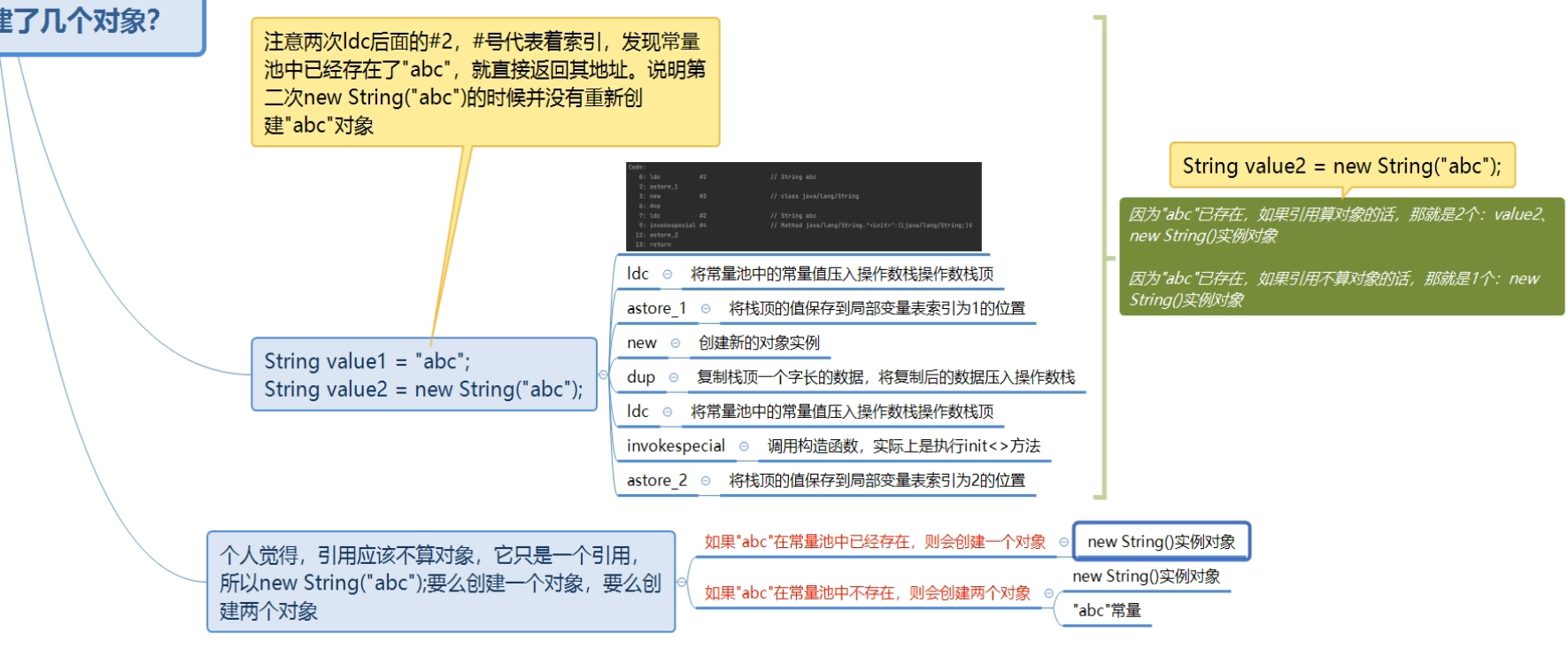
public class NewString {
public static void main(String[] args) {
// 1.在字符串常量池中创建了一个“abc”的字符串常量
// 2.把栈中的元素存入到局部变量表索引为1的位置
// 3.创建一个新的实例
// 4.复制栈中的元素并把复制的值压入到操作数栈中
// 5.由于之前已经创建了“abc”字符串常量池,即“abc”已经在字符串常量池中存在,直接获取#2(abc在字符串常量池中)的地址
// 6.调用String构造方法
// 7.把栈中的元素存入到局部变量表索引为2的位置
// 8.方法返回
String ABC = "abc";
String abc = new String("abc");
}
}

Java获得类对象以及反射的学习

Student:
package com.bilibili.juc;
public class Student implements Cloneable{
private Double weight;
private Integer pkid;
private String name;
public Student() {
}
public Student(Double weight){
this.weight = weight;
}
private Student(Double weight, Integer pkid, String name) {
this.weight = weight;
this.pkid = pkid;
this.name = name;
}
public void study(){
System.out.println("我是学生,我要学习");
}
private void eat(){
System.out.println("我是学生,我要吃饭");
}
private String happy(String style){
return "我是学生,我要玩" + style;
}
public double getWeight() {
return weight;
}
public void setWeight(Double weight) {
this.weight = weight;
}
public Integer getPkid() {
return pkid;
}
public void setPkid(Integer pkid) {
this.pkid = pkid;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Student{" +
"weight=" + weight +
", pkid=" + pkid +
", name='" + name + '\'' +
'}';
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
测试:
/**
* 反射的学习
* https://blog.csdn.net/weixin_60475929/article/details/122653101
*/
@Test
public void testString() throws ClassNotFoundException, NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException, NoSuchFieldException {
// 1.通过类名.class获取类对象
Class<com.bilibili.juc.Student> studentClass = com.bilibili.juc.Student.class;
// 输出:studentClass:class com.bilibili.juc.Student
System.out.println("studentClass:" + studentClass);
// 2.通过实例对象.getClass()获取类对象
com.bilibili.juc.Student student = new com.bilibili.juc.Student();
Class<? extends com.bilibili.juc.Student> aClass = student.getClass();
// 输出:aClass:class com.bilibili.juc.Student
System.out.println("aClass:" + aClass);
// 3.通过Class.forName("类的全限定类名")获取类对象
Class<?> classForName = Class.forName("com.bilibili.juc.Student");
// 输出:classForName:class com.bilibili.juc.Student
System.out.println("classForName:" + classForName);
// 获取到类对象后,就可以获取到类对应的构造方法、属性以及方法,用于创建对象或方法调用
/*
Class类中获取构造器的方法,获取构造器的作用:依旧是初始或一个对象返回
方法 说明
Constructor<?>[ ] getconstructors() 返回所有构造器对象的数组(只能拿public的)
Constructor<?>[] getDeclaredConstructors() 返回所有构造器对象的数组,存在就能拿到
constructor<T> getconstructor(class<?>... parameterTypes) 返回单个构造器对象(只能拿public的)
Constructor<T> getDeclaredConstructor(Class<?>... parameterTypes) 返回单个构造器对象,存在就能拿到
* */
// 提取类中的全部构造器对象(public)
Constructor<?>[] constructors = classForName.getConstructors();
// 遍历构造器
for (Constructor constructor : constructors) {
// 名称 + 参数
System.out.println("getConstructors:" + constructor.getName()+"=====>"+constructor.getParameterCount());
/**
* 输出:
* getConstructors:com.bilibili.juc.Student=====>0
* getConstructors:com.bilibili.juc.Student=====>1
*/
}
// 获取全部的构造器,无所谓权限是否可及
Constructor[] construct1 = classForName.getDeclaredConstructors();
for (Constructor constructor : construct1) {
System.out.println("getDeclaredConstructors:" + constructor.getName()+"====>"+constructor.getParameterCount());
/**
* 输出:
* getDeclaredConstructors:com.bilibili.juc.Student====>0
* getDeclaredConstructors:com.bilibili.juc.Student====>3
* getDeclaredConstructors:com.bilibili.juc.Student====>1
*/
}
// 获取某个构造器对象(按照参数定位无参构造器 只能拿public修饰某个构造器)
Constructor cons = classForName.getConstructor(Double.class);
// 名称 + 参数,输出:Double.class:com.bilibili.juc.Student=====>1
System.out.println("Double.class:" + cons.getName()+"=====>"+cons.getParameterCount());
// 获取某个构造器,无所谓权限是否可及
Constructor conss = classForName.getDeclaredConstructor(Double.class, Integer.class, String.class);
// 名称 + 参数,输出:getDeclaredConstructor:com.bilibili.juc.Student=====>3
System.out.println("getDeclaredConstructor:" + conss.getName()+"=====>"+conss.getParameterCount());
System.out.println("-----------------------------------------");
/* Constructor类中用于创建对象的方法:
* 符号 说明
T newlnstance(Object... initargs) 根据指定的构造器创建对象
public void setAccessible(boolean flag) 设置为true,表示取消访问检查,进行暴力反射
* */
Constructor<?> declaredConstructor = classForName.getDeclaredConstructor(Double.class, Integer.class, String.class);
// 暴力反射,因为这个有三个参数的构造是私有的
declaredConstructor.setAccessible(true);
com.bilibili.juc.Student newInstance = (com.bilibili.juc.Student)declaredConstructor.newInstance(50.00, 25, "张三");
// 输出:newInstance:Student{weight=50.0, pkid=25, name='张三'}
System.out.println("newInstance:" + newInstance);
System.out.println("-------------------------------------");
/*
* class类中用于获取成员变量的方法
* 方法 说明
Field[] getFields() 返回所有成员变量对象的数组(只能拿public的)
Field[]getDeclaredFields() 返回所有成员变量对象的数组,存在就能拿到
Field getField(String name) 返回单个成员变量对象(只能拿public的)
Field getDeclaredField(String name) 返回单个成员变量对象,存在就能拿到
* */
Field[] declaredFields = classForName.getDeclaredFields();
for (Field declaredField : declaredFields) {
// getAnnotatedType:返回一个 AnnotatedType 对象,该对象表示使用类型来指定由该字段对象表示的字段的类型
// 通过其 getType() 方法,我们可以获取到对应的字段类型
System.out.println("getDeclaredFields:" + declaredField.getName()+"====>" + declaredField.getAnnotatedType().getType());
/**
* 输出:
* getDeclaredFields:weight====>class java.lang.Double
* getDeclaredFields:pkid====>class java.lang.Integer
* getDeclaredFields:name====>class java.lang.String
*/
}
// 根据名称定位某个成员变量
Field name = classForName.getDeclaredField("name");
// 输出:getDeclaredField:name====>class java.lang.String
System.out.println("getDeclaredField:" + name.getName()+"====>" + name.getAnnotatedType().getType());
/*
* 获取成员变量的作用依然是在某个对象中取值、赋值,Field类中用于取值、赋值的方法
符号 说明
void set(Object obj, Object value): 赋值
Object get(Objectiobj) 获取值
* */
// 暴力打开权限,因为name属性是private的
name.setAccessible(true);
// 赋值
com.bilibili.juc.Student s = new com.bilibili.juc.Student();
name.set(s, "zhangshan");// s.setName("zhangsan")
// 输出:s:Student{weight=null, pkid=null, name='zhangshan'}
System.out.println("s:" + s);
String getName = (String)name.get(s);
// 输出:getName:zhangshan
System.out.println("getName:" + getName);
System.out.println("----------------------------------");
/*
* Class类中用于获取成员方法的方法
方法 说明
Method[ ] getMethods() 返回所有成员方法对象的数组(只能拿public的)
Method[ ] getDeclaredMethods() 返回所有成员方法对象的数组,存在就能拿到
Method getMethod(String name,class<?>... parameterTypes) 返回单个成员方法对象((只能拿public的), parameterTypes:参数类型
Method getDeclaredMethod(String name,Class<?>... parameterTypes)返回单个成员方法对象,存在就能拿到, parameterTypes:参数类型
* */
// 提取所有方法,包括私有的
Method[] declaredMethods = classForName.getDeclaredMethods();
for (Method declaredMethod : declaredMethods) {
System.out.println("方法名:" + declaredMethod.getName() + ",返回值类型:" + declaredMethod.getReturnType() + ",参数个数:" + declaredMethod.getParameterCount());
/**
* 输出:
* 方法名:study,返回值类型:void,参数个数:0
* 方法名:eat,返回值类型:void,参数个数:0
* 方法名:happy,返回值类型:class java.lang.String,参数个数:1
* 方法名:getWeight,返回值类型:double,参数个数:0
* 方法名:setWeight,返回值类型:void,参数个数:1
* 方法名:setPkid,返回值类型:void,参数个数:1
* 方法名:getPkid,返回值类型:class java.lang.Integer,参数个数:0
* 方法名:toString,返回值类型:class java.lang.String,参数个数:0
* 方法名:clone,返回值类型:class java.lang.Object,参数个数:0
* 方法名:getName,返回值类型:class java.lang.String,参数个数:0
* 方法名:setName,返回值类型:void,参数个数:1
*/
}
/*
* 获取成员方法的作用依然是在某个对象中进行执行此方法,Method类中用于触发执行的方法
符号 说明
Object invoke(0bject obj,object.. . args) 运行方法
参数一:用obj对象调用该方法
参数二:调用方法的传递的参数(如果没有就不写)
返回值:方法的返回值(如果没有就不写)
* */
Method eat = classForName.getDeclaredMethod("eat");
Method happy = classForName.getDeclaredMethod("happy", String.class);
eat.setAccessible(true); // 打开暴力反射
happy.setAccessible(true); // 打开暴力反射
com.bilibili.juc.Student student1 = new com.bilibili.juc.Student();
Object invoke_eat = eat.invoke(student1);
// 如果方法是没有返回结果的,那么返回的为null
/**
* 输出:
* 我是学生,我要吃饭
* invoke_eat:null
*/
System.out.println("invoke_eat:" + invoke_eat);
Object invoke_happy = happy.invoke(student1, "游戏");
// 输出:invoke_happy:我是学生,我要玩游戏
System.out.println("invoke_happy:" + invoke_happy);
/*
* 反射的作用:绕过编程阶段为集合添加元素,
* 反射是作用在运行时的技术,此时集合的泛型将不能产生约束了,此时是可以为集合存入其他任意类型的元素的
* 泛型只是在编译阶段可以约束集合只能操作某种数据类型,在编译成Class文件进入运行阶段的时候,
* 其真实类型都是ArrayList了,泛型相当于被擦除了。
* */
ArrayList<Integer> list1 = new ArrayList<>();
list1.add(120);
// list1.add("加入数据");
Class c = list1.getClass();
Method add = c.getDeclaredMethod("add", Object.class);
boolean rs = (boolean)add.invoke(list1, "加入数据");
// 输出:list1:[120, 加入数据]
System.out.println("list1:" + list1);
// 输出:rs:true
System.out.println("rs:" + rs);
/*
* 1.反射为何可以给约定了泛型的集合存入其他类型的元素?
编译成Class文件进入运行阶段的时候,泛型会自动擦除。
反射是作用在运行时的技术,此时已经不存在泛型了。
* */
/*
* 结论:反射的作用?
可以在运行时得到一个类的全部成分然后操作。
可以破坏封装性。(很突出)
也可以破坏泛型的约束性。(很突出)
更重要的用途是适合:做Java高级框架
* */
}
案例:利用反射存储任意对象

/*
分析
①定义一个方法,可以接收任意类的对象。
②每次收到一个对象后,需要解析这个对象的全部成员变量名称。
③这个对象可能是任意的,那么怎么样才可以知道这个对象的全部成员变量名称呢?
④使用反射获取对象的Class类对象,然后获取全部成员变量信息。
⑤遍历成员变量信息,然后提取本成员变量在对象中的具体值
⑥存入成员变量名称和值到文件中去即可。
* */
@Test
public void fansheTest(){
com.bilibili.juc.Student student = new com.bilibili.juc.Student(50.00);
save(student);
}
// 保存任意类型的对象
public static void save(Object obj){
try {
// 使用FileOutputStream时,如果文件不存在,会自动创建文件。 但是,如果文件夹不存在,就会报错"系统找不到指定的路径
PrintStream ps = new PrintStream(new FileOutputStream("D:\\test\\fanshe.txt",true));
// 1.提取对象的全部成员变量:只有反射可以解决
Class c = obj.getClass();
// c.getSimpleName()获取当前类名,c.getName获取全限名:包名+类名
ps.println("========>"+c.getSimpleName()+"======<");
// 2.提取全部成员变量
Field[] f = c.getDeclaredFields();
// 3.获取成员变量的信息
for (Field field : f) {
String name = field.getName();
field.setAccessible(true);
// 提取本成员变量在obj对象中的值(取值)
String value = field.get(obj) + "";
ps.println(name+"="+value);
}
ps.close();
} catch (Exception e) {
e.printStackTrace();
}
}
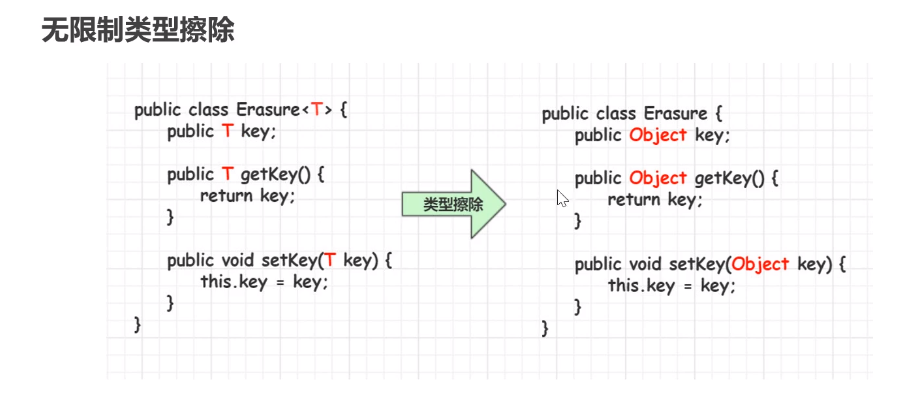
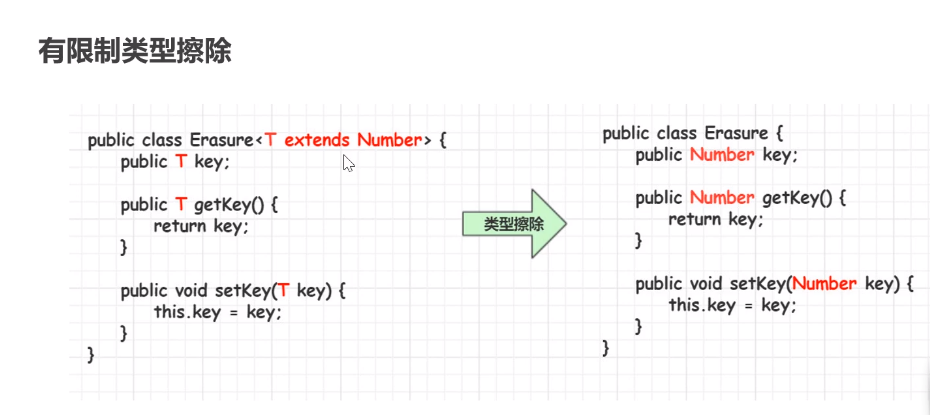
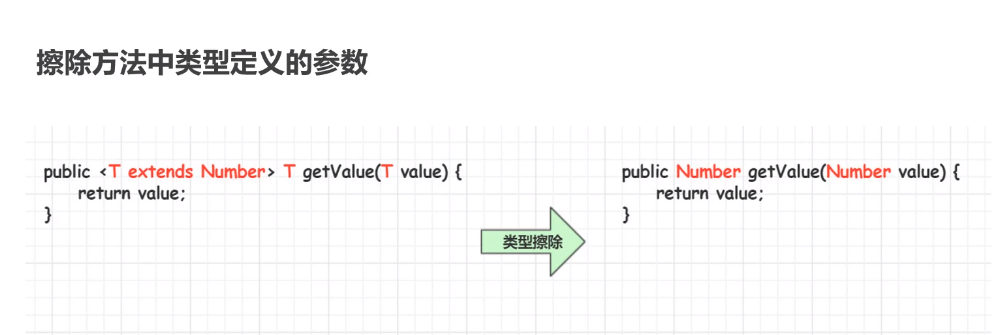
泛型类型擦除
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









