







目录
以下视频地址:[中英字幕]吴恩达机器学习系列课程_哔哩哔哩_bilibili
第四章 (正规方程与梯度下降一样是为了求满足条件的(塞塔o))
4.6正规方程(对于某些线性回归方程给出更好的方法求得参数x(塞塔)的最优值)
6.5 简化代价函数与梯度下降{如何用梯度算法来拟合出逻辑回归的参数(塞塔)}分类的代价函数为凸函数
8.1 神经网络的必要性(神经网络用于非线性假设,庞大的特真值)
8.4 模型展示2(神经网络的假设函数+向量化的实现方法)向前传播
8.3 例:神经网络用于计算XOR,XNOR(异或,以及假异或(当两数异或为真时,取假))
9.1 神经网络代价函数(这里讲解神经网络,在分类问题上面的应用)
9.2让神经网络代价函数最小化的算法---反向传播算法(有点不懂)
9.5 梯度检测(用来计算 反向传播算法的偏导数D是否计算正确)
10.3 模型选择(数据分为训练集,验证集和测试集)和交叉验证集
10.6 学习曲线(建立诊断方差和偏差的学习算法,以样本数量大小m为横轴)
11.3 不对称性分类的误差评估(偏斜类问题用查全率(召回率)和查准率)
11.4 查准率和召回率的权衡(F值:更强调这些值中较低的值,制约查准率和查全率的一方偏向)(偏斜类问题用查全率(召回率)和查准率)
以下视频地址:(强推|双字)2022吴恩达机器学习Deeplearning.ai课程_哔哩哔哩_bilibili
P77学习曲线 见本笔记 10.6 学习曲线(建立诊断方差和偏差的学习算法,以样本数量大小m为横轴)
P86倾斜数据集合误差指标 11.3 不对称性分类的误差评估(偏斜类问题用查全率(召回率)和查准率)
P87查全率和查准率的权衡 F1权衡 参见笔记11.4 查准率和召回率的权衡(F值,制约查准率和查全率的一方偏向)
P91 选择拆分信息增益 (熵的差值:代表降低的不确定性程度)
P95 回归树 (当我们的问题不再是分类问题时,用回归树解决回归问题(一些数字问题,房价))
P110 异常检测算法 -----------(密度估计=P(x))
P118 均值归一化处理 (针对于很少电影数量的评价处理过程,结果为电影评价的均值)
P122 基于内容过滤的深度学习方法(如何求用户和电影相关特征)
自己疑问-----容易错误的点:
关于交叉验证集的疑问?
参考:https://blog.csdn.net/qq_36607894/article/details/106827318
训练集、验证集、测试集
如果给定的样本数据充足,我们通常使用均匀随机抽样的方式将数据集划分成3个部分——训练集、验证集和测试集,这三个集合不能有交集,常见的比例是8:1:1。需要注意的是,通常都会给定训练集和测试集,而不会给验证集。这时候验证集该从哪里得到呢?一般的做法是,从训练集中均匀随机抽样一部分样本作为验证集。
训练集
训练集用来训练模型,即确定模型的权重和偏置这些参数,通常我们称这些参数为学习参数。
验证集
而验证集用于模型的选择,更具体地来说,验证集并不参与学习参数的确定,也就是验证集并没有参与梯度下降的过程。验证集只是为了选择超参数,比如网络层数、网络节点数、迭代次数、学习率这些都叫超参数。比如在k-NN算法中,k值就是一个超参数。所以可以使用验证集来求出误差率最小的k。
测试集
测试集只使用一次,即在训练完成后评价最终的模型时使用。它既不参与学习参数过程,也不参数超参数选择过程,而仅仅使用于模型的评价。
值得注意的是,千万不能在训练过程中使用测试集,而后再用相同的测试集去测试模型。这样做其实是一个cheat,使得模型测试时准确率很高。
一个交叉验证将样本数据集分成两个互补的子集,一个子集用于训练分类器或模型,被称为训练集(training set);另一个子集用于验证训练出的分类器或模型是否有效,被称为测试集(testing set)。测试结果作为分类器或模型的性能指标。而我们的目的是得到高度预测精确度和低的预测误差。为了保证交叉验证结果的稳定性,对一个样本数据集需要多次不同的划分,得到不同的互补子集,进行多次交叉验证。取多次验证的平均值作为验证结果。

第二章
2.1线性回归
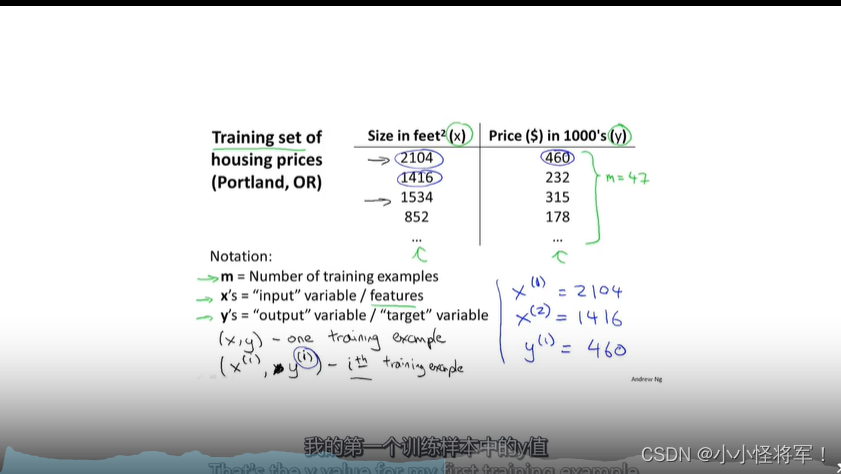
m:表示训练样本数量
x:代表输入数量或者特征
y:预测目标/输出目标
(x,y)训练集中的一个样本 (x^i,y^i)代表训练集中样本的索引 i
2-2代价函数(类似误差一样)

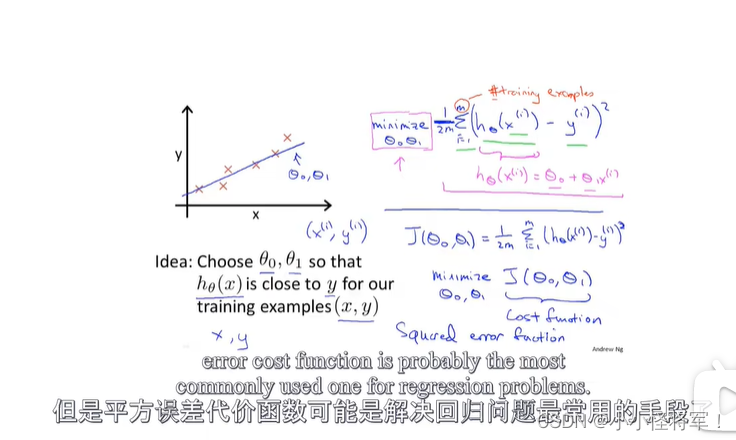
平方误差代价函数是解决回归问题最常用的手段。其中二分之一m其实是数学的一种表达,使其误差显得更小一点
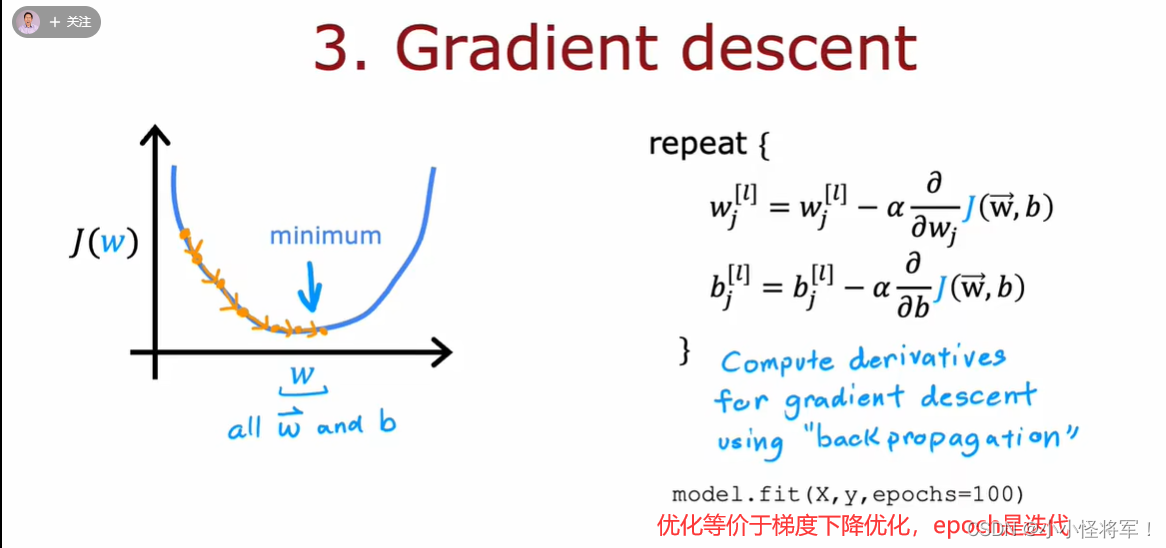
2.5-2.6 梯度下降算法,梯度下降算法理解
用来寻找代价函数J(xo,xi)的最小值,下图为梯度算法要干嘛:

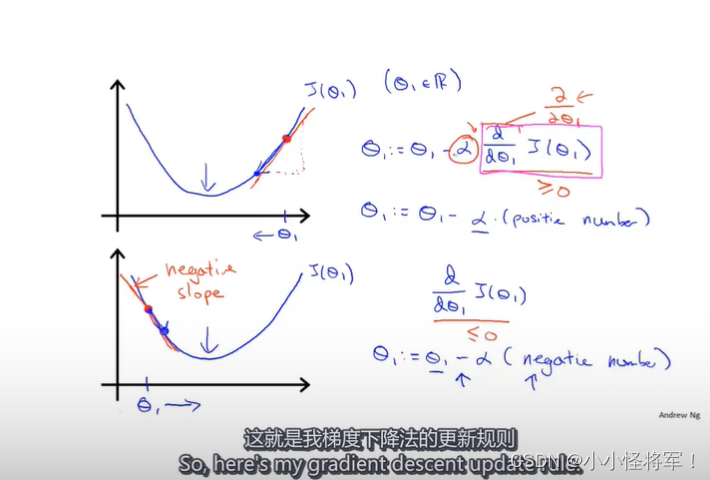
梯度算法背后的数学原理,下图为梯度算法的计算公式及正确的验算步骤:

左侧正确格式算法、右侧错误算法,因为没有同步更新
需要同时更新x1,x0,其中x1:=x2是赋值,x1=x2是判断符号,α是你所迈步子的大小
下图为梯度算法形象图解:

下图为 只有一个参数时候的x1:=重新赋值 (更新值),
下图为α学习率的形象理解:
2.3 线性回归的梯度下降 / Batch梯度下降
下图为梯度算法与线性回归以及代价函数的三者的组合应用,其目的就是为了求得θ1,θ0:
下图为的最后表示,在新版中(θ0表示b\θ1表示w)

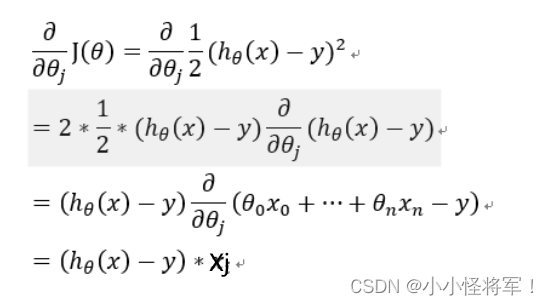
梯度回归的局限性: 可能得到的是局部最优解
线性回归的梯度下降的函数是凸函数,因此没有局部最优解,只有全局最优解
凸函数图像:
第四章 (正规方程与梯度下降一样是为了求满足条件的(塞塔o))
4.1 多变量线性回归假设函数
参照:吴恩达 - 机器学习课程笔记(持续更新)_做一只猫的博客-CSDN博客_吴恩达机器学习课程笔记
4.2 多元(多变量)梯度下降算法
下图为多元梯度(含偏导式子):
m:表示训练样本数量
x:代表输入数量或者特征
y:预测目标/输出目标
(x,y)训练集中的一个样本 (x^i,y^i)代表训练集中样本的索引 i(第i个样本),下角字母表示第几个矩阵中第几个数据

4.3 梯度下降实用技巧1-特征缩放
特征缩放,先看左边的图,如果有两个特征,一个特征是房子大小0-2000,而另一个特征是卧室的数量(1-5),那么画出来的代价函数的图像,就是椭圆状,这种图像经过梯度下降算法,很难收敛,因为(x0,x1)会来回震荡。(查找路径更加直线化,可以尽快找到全局最小)
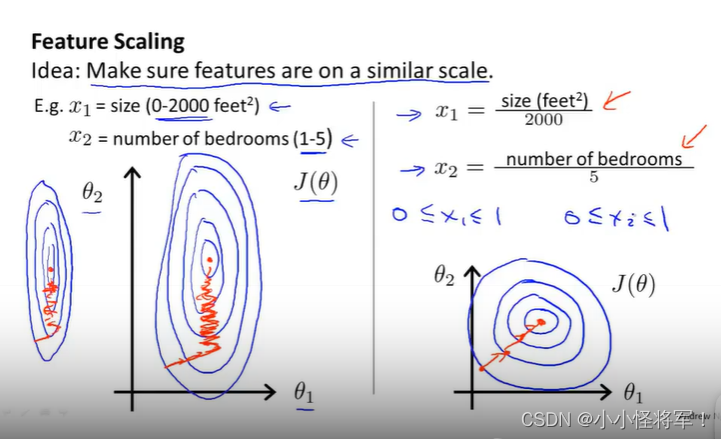
参考: 【机器学习】机器学习笔记(吴恩达)_Bug 挖掘机的博客-CSDN博客_机器学习笔记
注: 使用特征缩放时,有时候会进行均值归一化的操作,使其范围比较接近就可以接受
特征值x1=( x1 -u1) / s1
这里的u1 就是训练数据集当中 x1 的平均值,而 s1 就是 x1的范围,即x1最大值-x1 最小值。 s1 也可以取x1的标准差,不过一般用x1最大值-x1 最小值就行
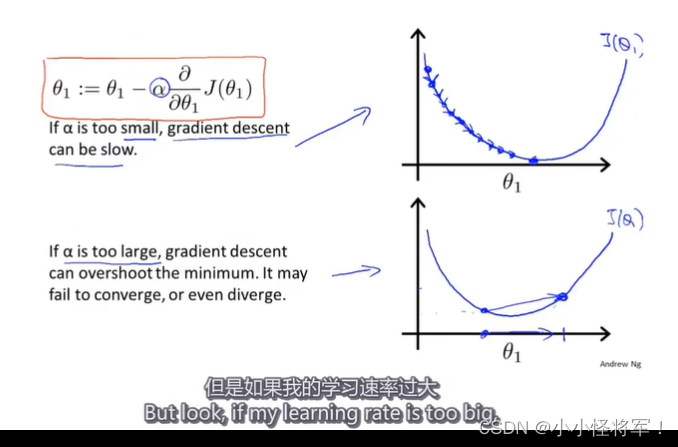
4.4 梯度下降算法实用技巧2 -学习率的选择

在梯度下降算法运行过程中,该图的横轴是迭代次数,而 竖轴是代价函数的最小值,通常情况下,迭代次数越多,代价函数的最小值会依次减小。有一个自动收敛测试,当J(x)小于 10-3 次方时,就认为已经收敛
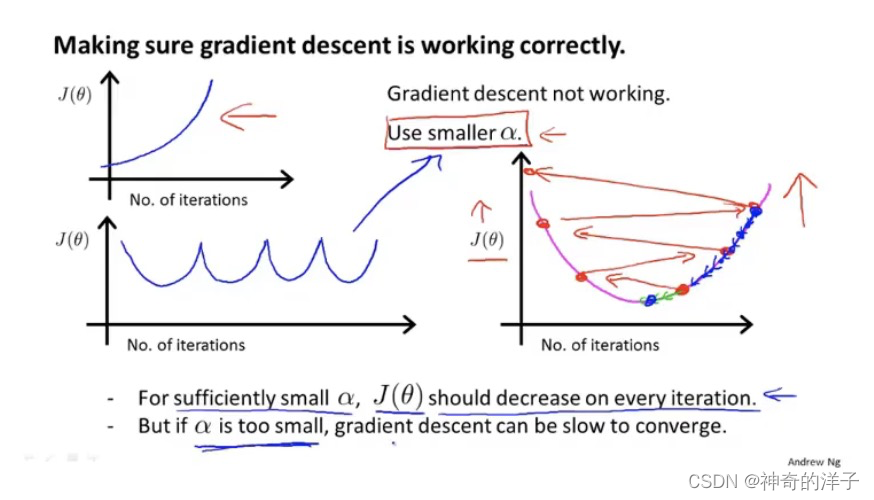
像上图中的三幅图,都要降低学习率a。但是如果学习率a太小的话,收敛就会很慢,那么如何选择合适的学习率呢。(α代表上述箭头的跨度/不发大小)
converge -----收敛 iteration----迭代
先找一个最小的学习率,再找一个最大的学习率,然后取一个最大可能值或比最大值小一些的值,作为学习效率α
4.5 特征与多项式回归
参考:【机器学习】机器学习笔记(吴恩达)_Bug 挖掘机的博客-CSDN博客_机器学习笔记
我们房子的特征,除了宽和高两个特征,还能把两者结合起来,如房子面积作为一个特征,这样有可能更能准确用来预测房子的价格
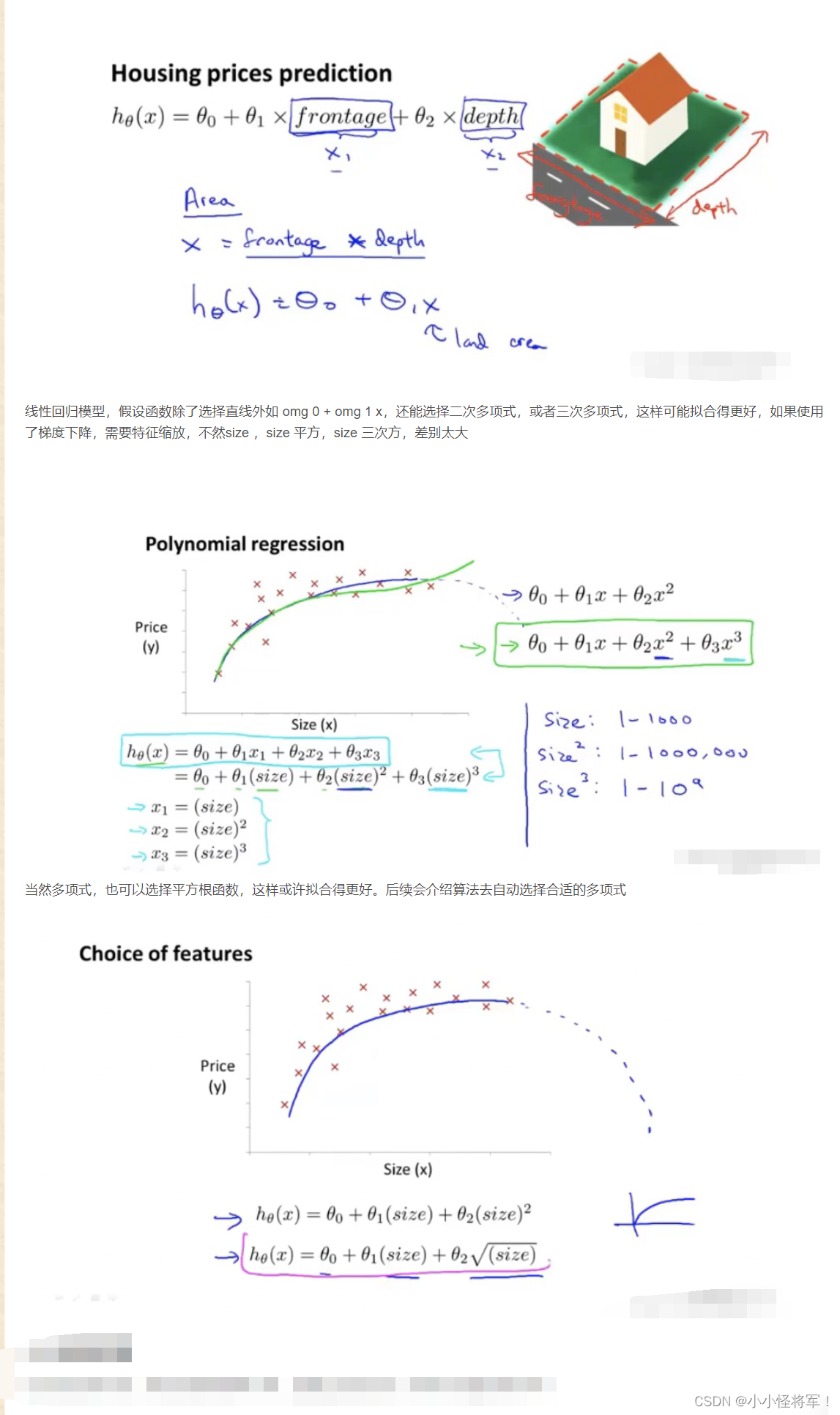
4.6正规方程(对于某些线性回归方程给出更好的方法求得参数x(塞塔)的最优值)
在讲正规方程以前,我们知道使用梯度下降,是通过迭代的方法,使得代价函数不断下降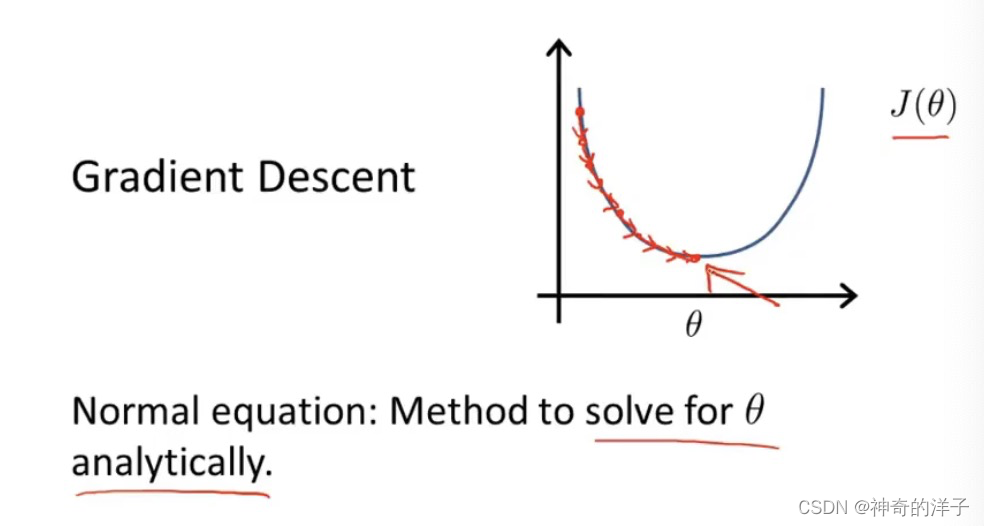
通过求导,或者求所有变量的偏微分/偏导/斜率等于0(类似条件极值),可以获取函数的最小值,但这样实现起来过于复杂,这里我需要知道实现原理即可
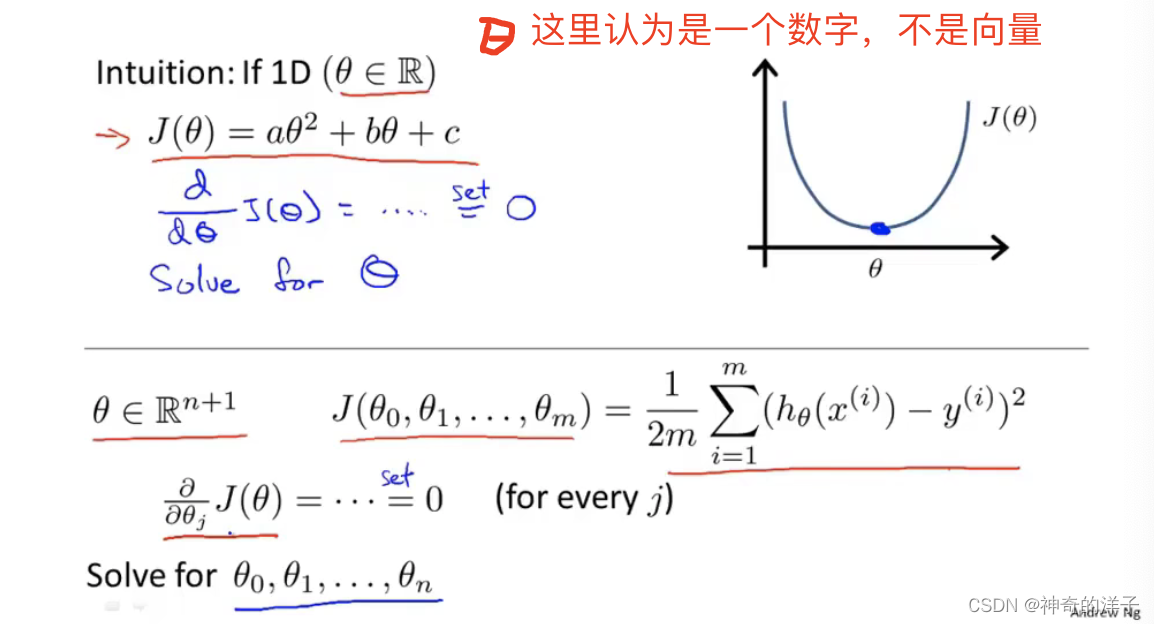
对于下面这个例子,有4个特征,我们构造x0的一列,然后表示出矩阵X和向量y,通过下面这个式子就能直接求出的最小值(正规矩阵避免了一直求导求极值的麻烦,可以一步到位)(就像最小二乘法)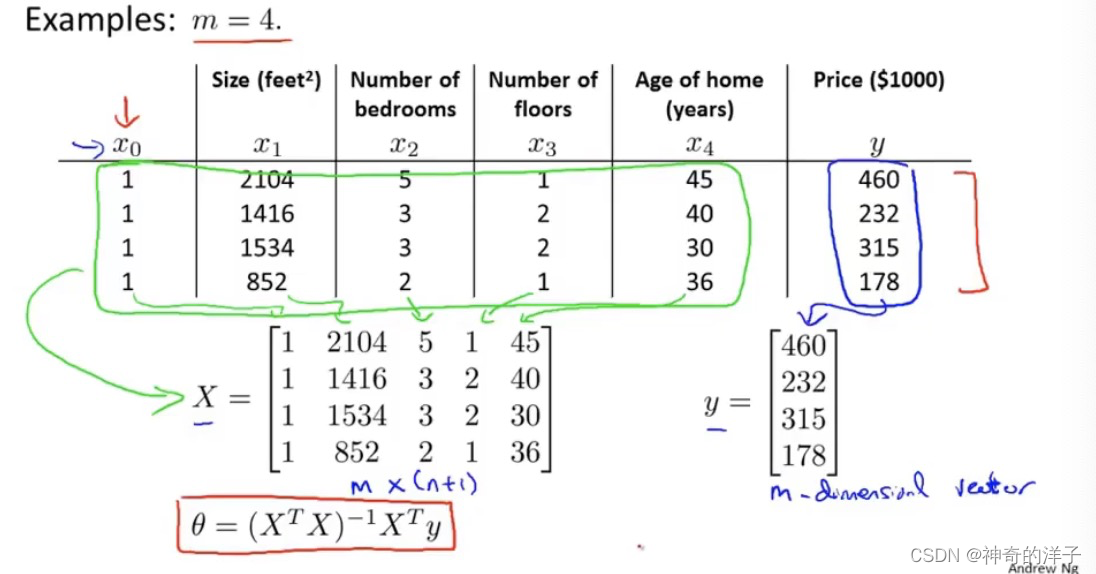
构造正规方程的步骤如下:(这儿构

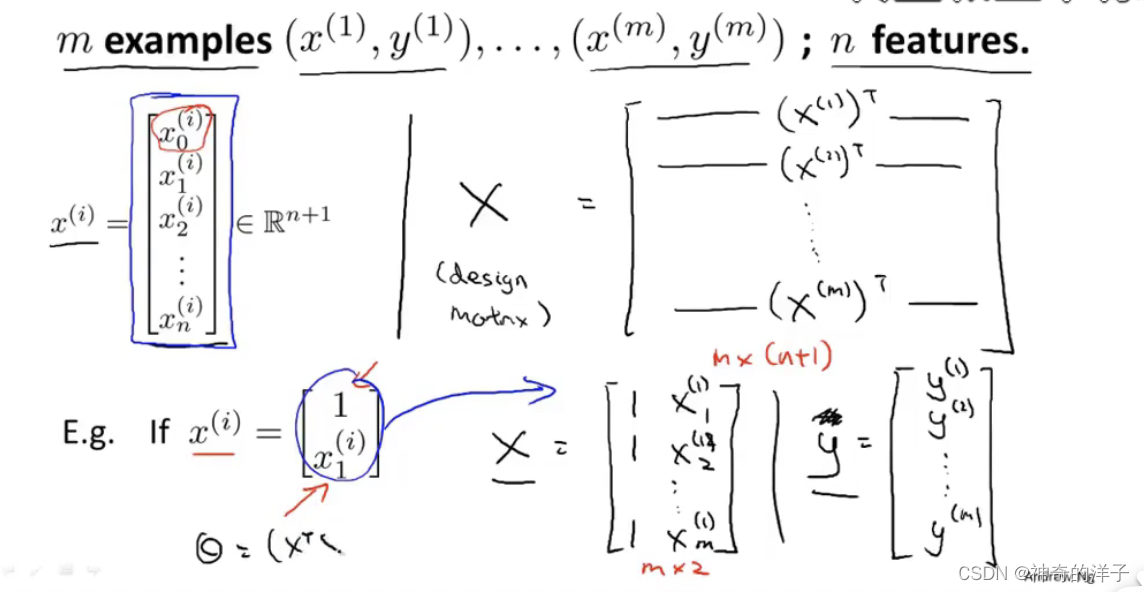
下图中的正规矩阵可以求得最小值代价函数值 minJ(o)
注意:使用正规方程,不用进行特征缩放 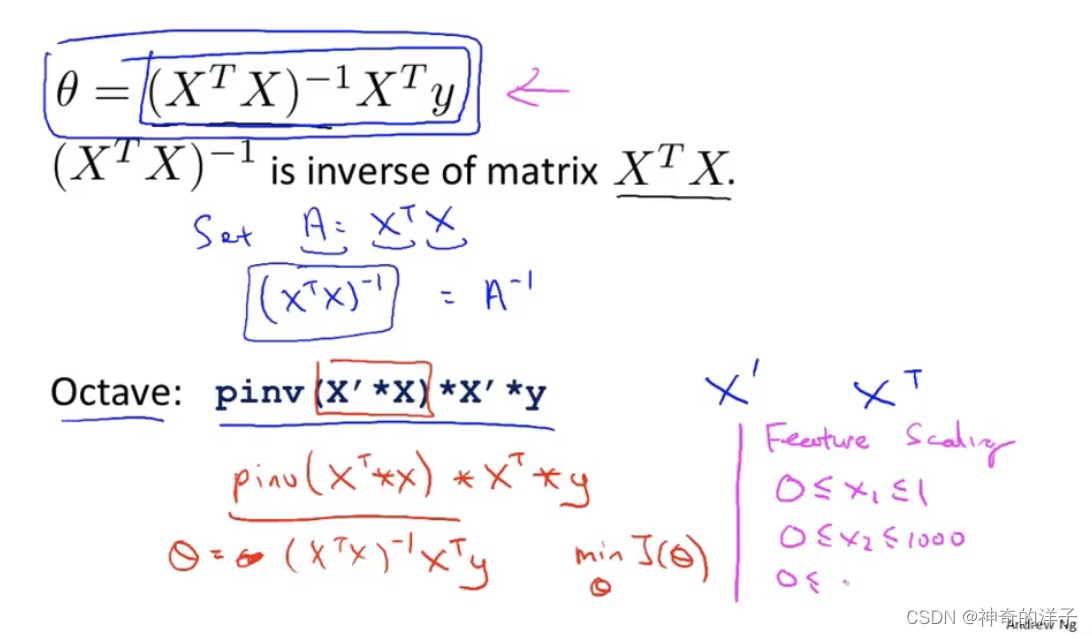
为什么用正规方程就可以解决求θ的多重步骤呢?
参考:详解正规方程(Normal Equation) - 知乎
对比梯度下降和正规方程,一般特征数量 n>10000 对于线性回归模型就可以使用梯度下降
4.6.2 正规方程同梯度下降比较
- 是同级算法
- 梯度下降缺点是需确定α,需要许多次迭代;优点是适用于样本量大(m > 10000)的数据
- 正规方程缺点是不适用于样本量大(m > 10000)的数据,但无需确定α,无需许多次迭代
4.6.3 正规方程与不可逆矩阵(新版中无)
矩阵不可逆的情况很小,导致不可逆可能有以下两个原因:
1、两个及两个以上的特征量呈线性关系,如x1 = 3x2
2、特征量过多。当样本量较小时,无法计算出那么多个偏导来求出结果
实际操作过程中,要删除多余特征,且呈线性关系的多个特征保留一个即可
Octave中的pinv即使面对不可逆矩阵,也能计算出结果,得出来的是伪矩阵
XT.X不可逆的情况下,仍然可以使用Octave 里面的伪逆函数pinv 获取正确的结果
其余解决办法有两个,
(1)一些已经线性相关的特征,如x1=(3.28)平方* x2,这时候可以去掉x2这个特征
(2)如果特征太多(比如=样本m太少,而特征n太多),可以删除一些特征,或者使用正则化方法
第六章 分类问题
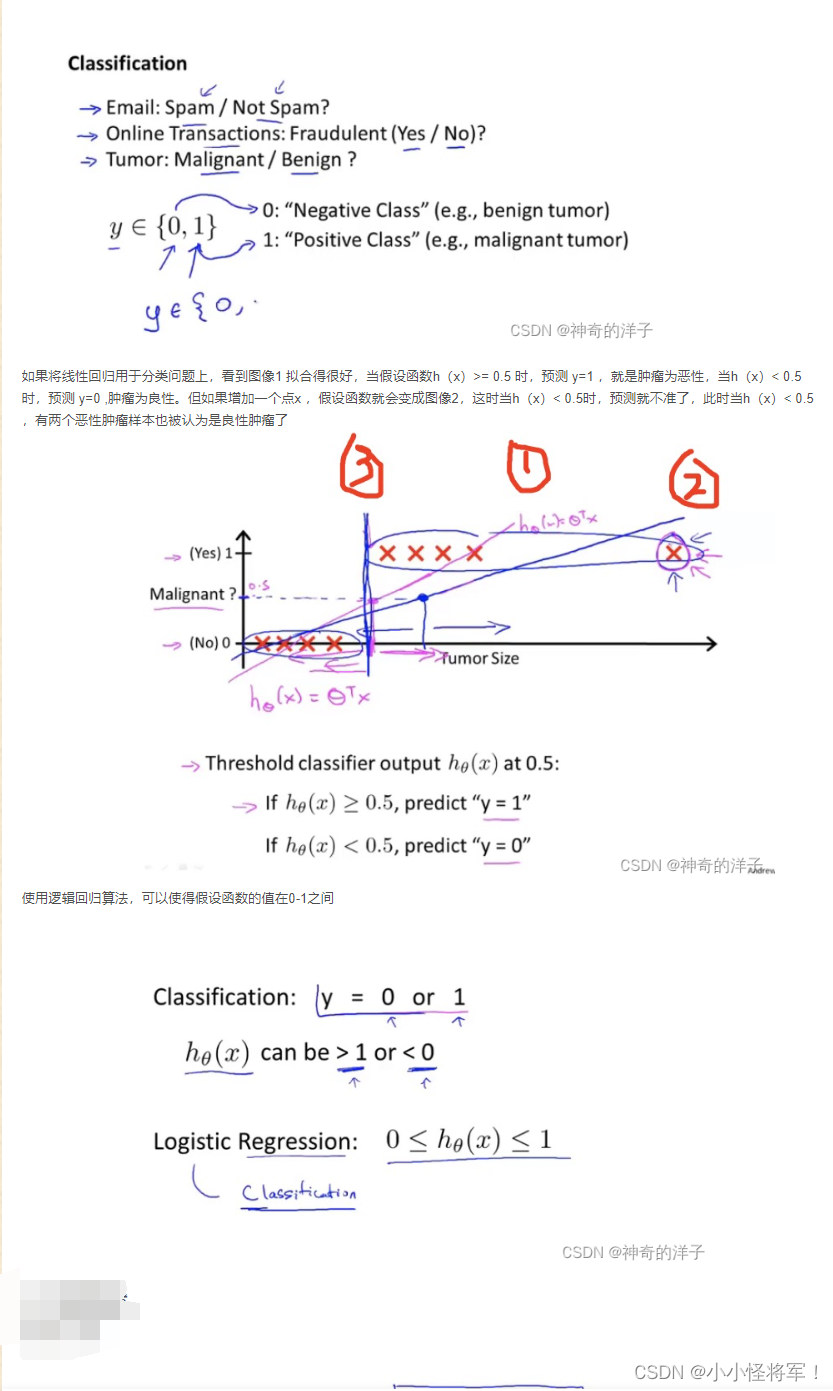
6.1 分类问题
参考:【机器学习】机器学习笔记(吴恩达)_Bug 挖掘机的博客-CSDN博客_机器学习笔记
6.2假设函数
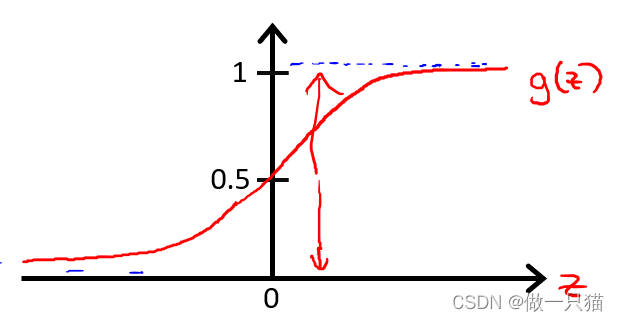
ogistic regression的假设函数值总是在0到1之间
logistic regression模型
线性回归中 hθ(x) = θTx
作一下修改,变成下图形式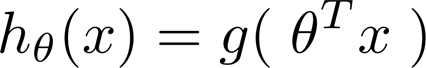
logistic函数 / sigmoid函数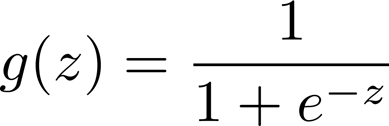
逻辑回归模型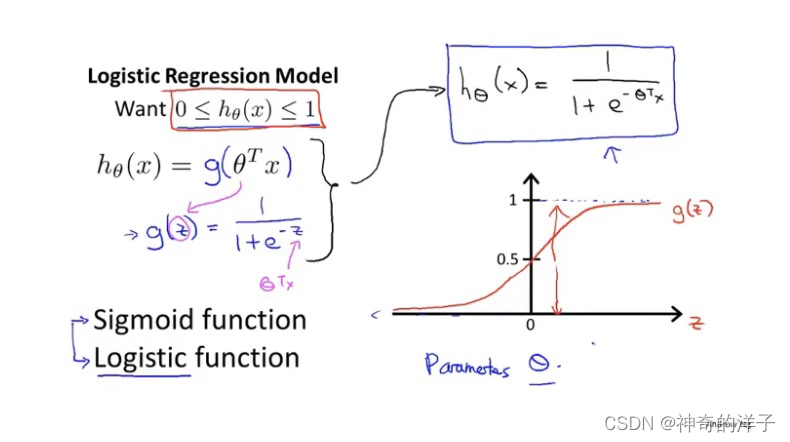
看一个具体的逻辑回归问题(这儿θ为参数,y的取值为0或1,x为某种特征)
Tell patient that 70% chance of tumor being malignanthel)
告诉病人70%的肿瘤有可能是恶性肿瘤
P(y=0| x;θ) 这个公式可以理解成条件概率
6.3决策边界
下图为回归函数我们最后要将其转换为判断什么的图片:

预测 y = 1 if -3 + x1 + x2 ≥ 0,即x1 + x2 ≥ 3
则有下图,中间的洋红色直线即为 决策边界(x1 + x2 = 3)
决策边界所画出的分界线都是假设函数的属性决定于假设本身和其参数的属性(θ的不同取值),非数据集的属性(样本属性),之后的决策边界我们通过训练集来确定参数(θ的值){我们用训练集来拟合参数θ},再来求得准确的决策边界。
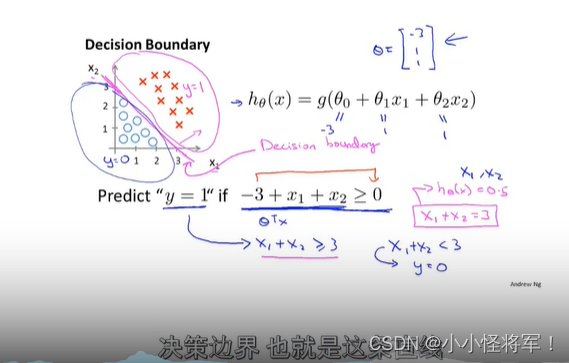

便可以开确定决策边界
6.4分类问题中的代价函数
逻辑回归的代价函数选择:如何选择θ

如果直接使用线性回归的,误差平方作为代价函数,会出现代价函数不是凸函数的情况,会得到局部最优解,影响梯度下降算法寻找全局最小值

下面是逻辑回归的代价函数:(纵轴代表代价函数的值J(0))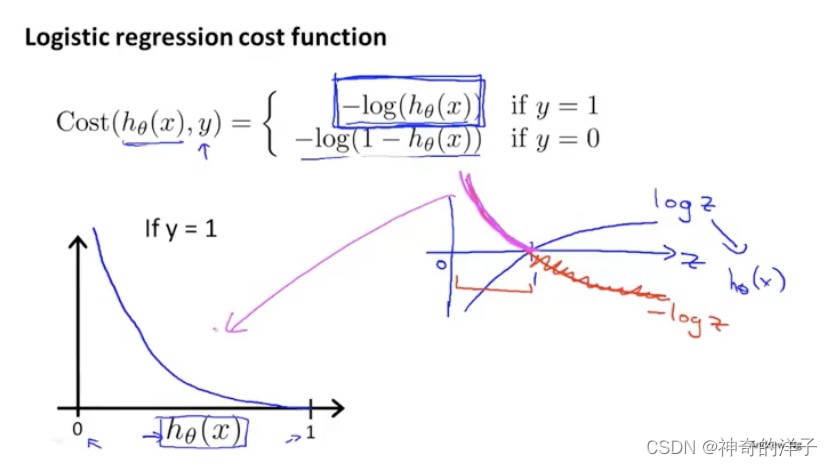
先看下if y=1 的函数图像,如果 y=1 时,h(x)接近为0,这时候认定他是一个恶性肿瘤,这时候代价会很大(因为之前预测是h(x)<0.5 是良性,y=0不是肿瘤)
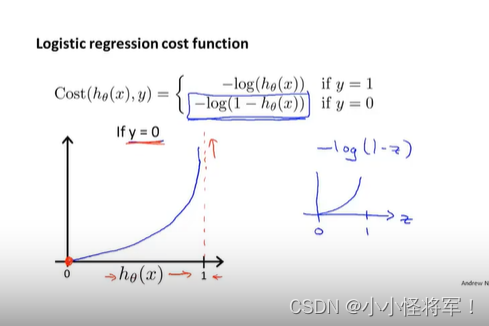
下面是y=0的代价函数,当h(x)=1 时,若还是预测y=0 ,代价会非常高
2. 当y = 0时
if hθ(x) = 0, cost = 0
if hθ(x) = 1, cost = ∞ (预测与实际完全不一致,要花费很大的代价惩罚算法)
6.5 简化代价函数与梯度下降{如何用梯度算法来拟合出逻辑回归的参数(θ)}分类的代价函数为凸函数
求解思路********************************************************************************************先求出h(θ)的值,然后用代价函数J(θ)来得到最优解,其中θ的值来源于:
得到:
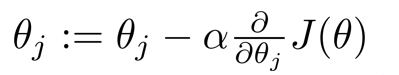
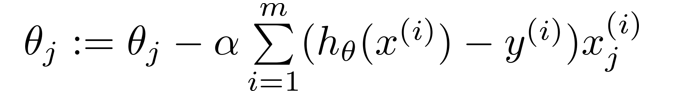
可以将逻辑回归的代价函数进行简化
注意,假设函数的输出值,表示的P(y=1 |x;oumiga即为恶性肿瘤的概率,逻辑回归的代价函数,是根据统计学当中的最大似然估计得出的
下面的图1,少了1/m,网上说也可以归到学习率里面去
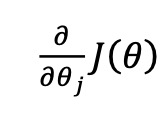
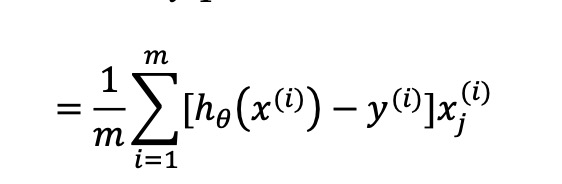
图1

利用梯度下降算法找到代价函数的最小值,表面上看上去与线性回归的梯度下降算法一样,但是这里 的h𝜃(𝑥) = 𝑔(𝜃𝑇𝑋)与线性回归中不同,所以实际上是不一样的。另外,在运行梯度下降算法 之前,进行特征缩放依旧是非常必要的
注意:
- 逻辑回归的代价函数看似与线性回归的代价函数相同,但本质不同。
- 逻辑回归中的hθ(x) = 1 / e-θTx(T是θ的上标)
- 线性回归中的hθ(x) = θTx
6.6 高级优化(比梯度算法更加优化的算法)(新版本无)
梯度下降干些了啥:

右边这个使用octave 的costFunction函数,会有两个返回值,一个是jval,另外一个是gradient
6.7 多元分类:一对多
主要思想:将多个分类选中其中一个作为正类,其他均为负类;在求h(θ)函数,最后选出最大值h(θ)函数,作为样本数据应该归类在哪一类中。

最后需要输入一个x,选择h最大的类别,也即在三个分类器中选择可信度最高,效果最好的
意思就是说:我输入一个x,里面哪个概率大,我就是哪个的分类。
参考:【机器学习】机器学习笔记(吴恩达)_Bug 挖掘机的博客-CSDN博客_机器学习笔记
第七章
7. 1过拟合问题
过拟合的意思:我们拟合的数据需要用高阶多项式来拟合,虽然这个函数能拟合所有数据,这就导致函数过于庞大和变量太多的问题,我们就没有很多的数据来约束它。
泛化:一个假设模型应用到新样本的能力
下面三张图,分别是欠拟合,拟合刚好,和过拟合。
第一个模型是一个线性模型,欠拟合,不能很好地适应我们的训练集;第三个模型是一 个四次方的模型,过于强调拟合原始数据,而丢失了算法的本质:预测新数据。我们可以看 出,若给出一个新的值使之预测,它将表现的很差,是过拟合,虽然能非常好地适应我们的 训练集但在新输入变量进行预测时可能会效果不好;而中间的模型似乎最合适。
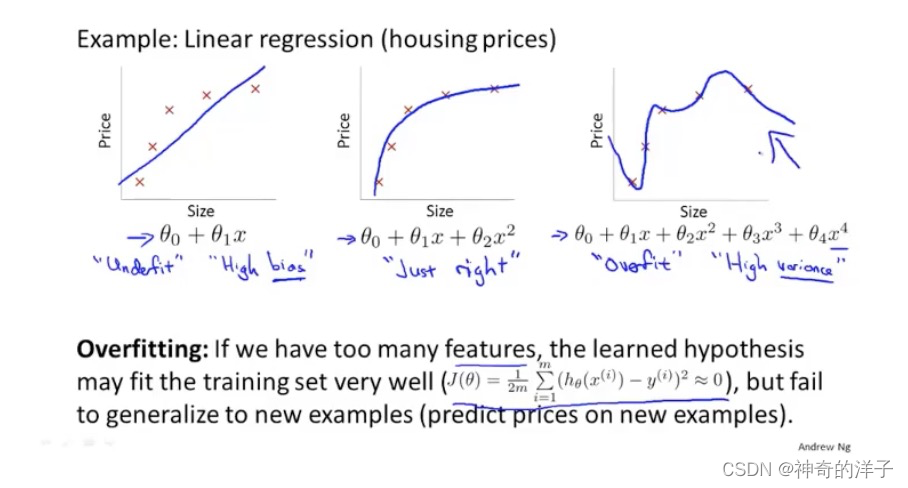
除了线性回归,在逻辑回归当中,也会出现过过拟合的情况
如下面的图1是欠拟合,图3是过拟合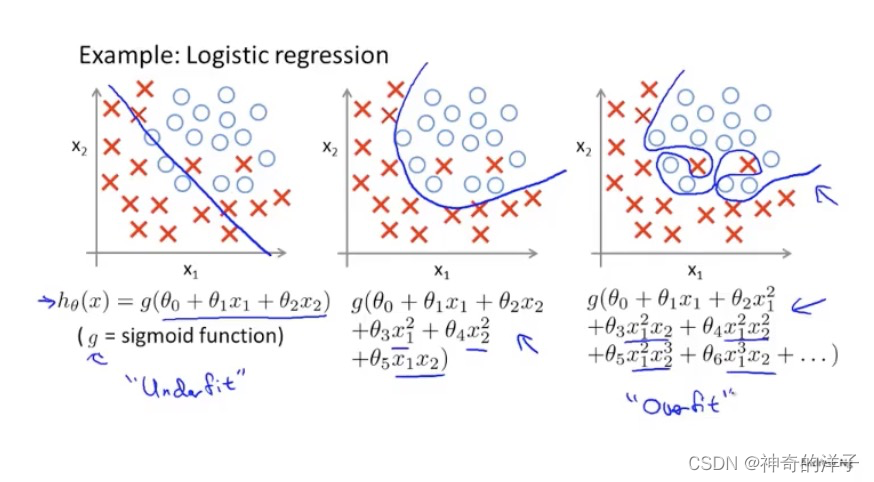
就以多项式理解,𝑥 的次数越高,拟合的越好,但相应的预测的能力就可能变差。并且特征太多,样本太少就有可能出现过拟合的情况,我们也不能随便去掉一些特征。

如果我们发现了过拟合问题,应该如何处理?
1.丢弃一些不能帮助我们正确预测的特征。可以是手工选择保留哪些特征,或者使用一 些模型选择的算法来帮忙(例如 PCA)
2.正则化。 保留所有的特征,但是减少参数的大小(magnitude)。

7.2 代价函数-正则函数引入(正则化相当于减少特征量)
(正则函数:将后面的+项相对于制衡前面对整个代价函数的影响,更加形象的解释是将弯曲的曲线变得更加光滑)
因为根本不知道,要选择哪些θ(w)参数去缩小,所以修改代价函数,通过在其后面新添项(额外的正则化项)来缩小每个参数θ的值。这个额外项作用就是缩小每个高次参数

代价函数如图所示J(θ)
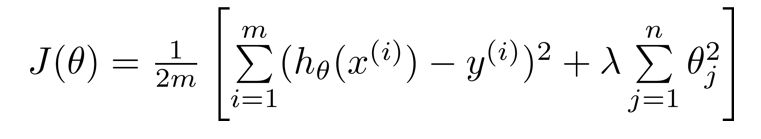
其中
+ 后的一项为正则化项,n是参数个数
λ 为正则化参数(在多重选择部分讲述正则化参数的选择),作用是控制两个不同目标之间的取舍,,将参数θ控制在更小的目标,避免出现过拟合的情况。(后面的+项相对于制衡前面对整个代价函数的影响,更加形象的解释是将弯曲的曲线变得更加光滑)
(1)第一个目标与第一项有关,即我们想要更加拟合数据集。
(2)第二个目标与第二项有关,即我们想要参数θj尽量小,与正则化目标有关
惩罚从θ1到θn,不包括θ0(实操中有无θ0影响不大)
若 λ 设置的过大,即对θ1θ2θ3θ4的惩罚程度过大,导致θ1θ2θ3θ4(w)都接近于0,最后假设模型只剩一个θ0,出现欠拟合情况。
形象理解:λ过大,导致x的系数θ或者说是新版的w参数变小,使x高次项影响减小,只剩下低次多项式!如下图所示

7.3 线性回归的正则化(惩罚对象是1-n,不含有0)
我们之前使用梯度下降法来,去最小化最初的代价函数:下图为之前所学梯度下降

由于正则化是从1到n项,故先将θ0提出来
将第二个式子写成下面这样的形式
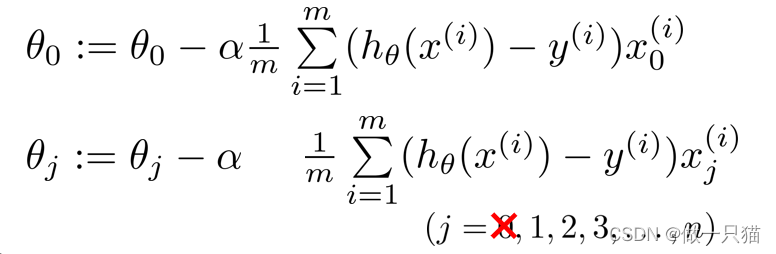
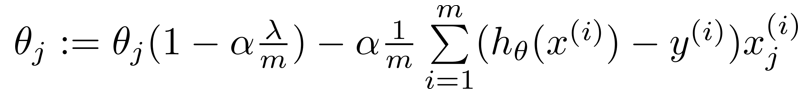

注:正规方程和正则化是两个 不同的定义
正规方程的带入正则化参数后的求代价函数


进而求出J(θ)代数函数最小值。
正规方程对比详见4.6章
7.4 逻辑回归的正则化
在逻辑回归当中,有两个方式来减小代价函数,一种是使用梯度下降,另外一种是更高级的算法(1)共轭梯度法,(2) BFGS(变尺度法) 和 (3)L-BFGS(限制变尺度 101
在逻辑回归当中,使用梯度下降算法,加入正则化后的表达式如下:

(新版吴恩达教学视频中无)结合Octave ,可以使用更高级的算法或者梯度下降算法,减少代价函数值,下面是加入正则化项的方法(此处函数可以不必大懂)
第八章(神经网络部分)
8.1 神经网络的必要性(神经网络用于非线性假设,庞大的特征值)
当特征值只有两个时,我们仍可以用之前学过的算法去解决
但当特征值很多,且含有很多个多次多项式时,用之前的算法就很难解决了
例 汽车识别
计算机识别汽车是靠像素点的亮度值
给定数据集汽车和非汽车的数据,按照之前的方法划分 pixel----像素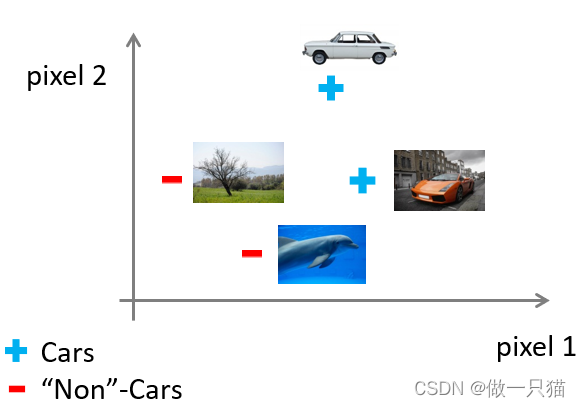
可以看到仅针对50*50像素的灰白图片,就有2500个特征值。当引入rgb时,特征值达到了7500个,如果算上多次多项式,特征值达到了三百万个,显然再继续用之前的算法难以处理这么庞大的数据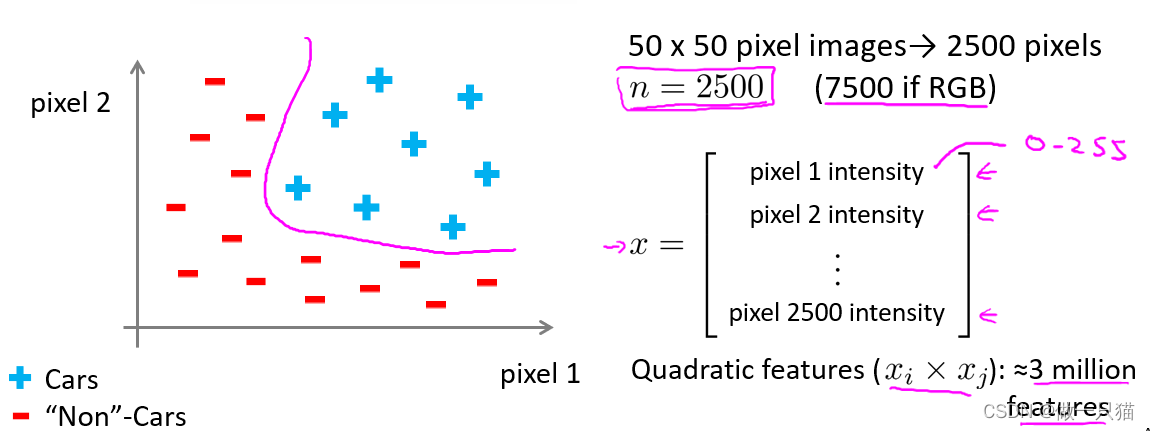
8.3 模型展示I
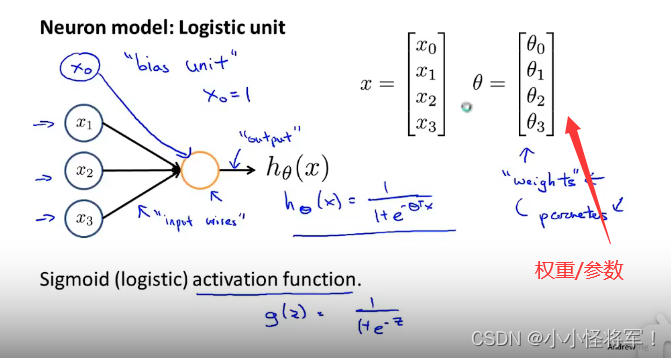
一个带有激活函数的人工神经元,𝜃 为模型的参数,在神经网络里面表示模型的权重
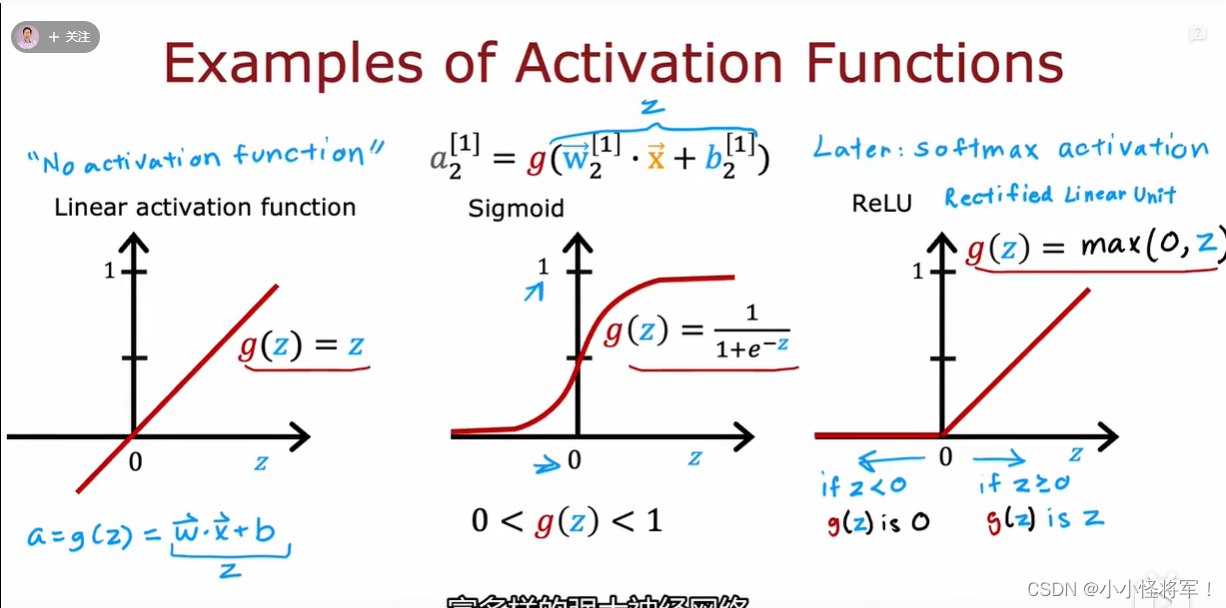
常用激活函数
常用激活函数(激励函数)理解与总结_tyhj_sf的博客-CSDN博客_激活函数
x0=1 可以自己根据需要添加
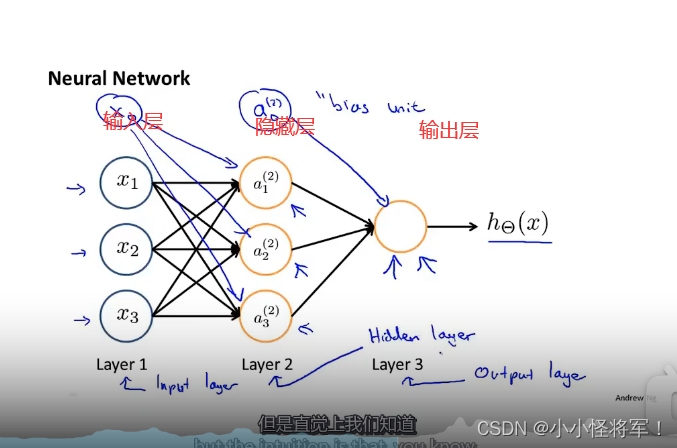
第二层第一个激活项(神经元计算并输出的值)

即第1层有3个单元,第2层有3个单元,则θ(1)是一个 3乘 4 的矩阵。

神经网络:不断的改变θ矩阵,就可通过h(x)得到不同的映射y
8.4 模型展示2(神经网络的假设函数+向量化的实现方法)向前传播
上标代表层数
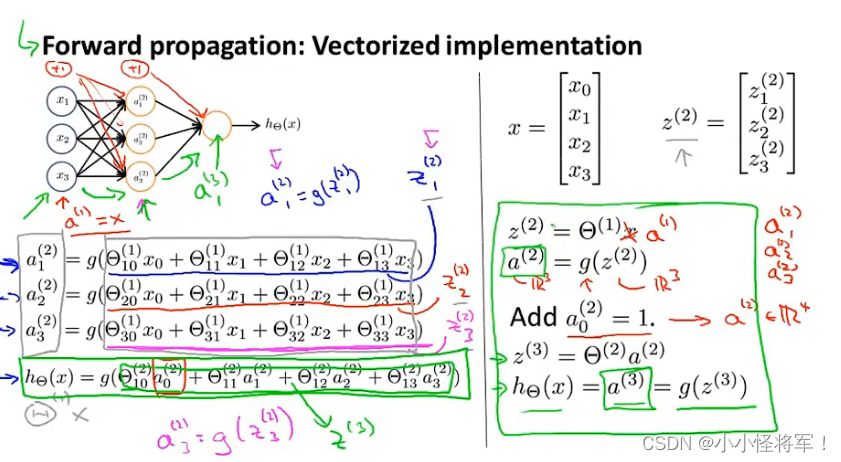

在神经网络当中,根据θ选择不同的参数,可以得到隐藏层更好的特征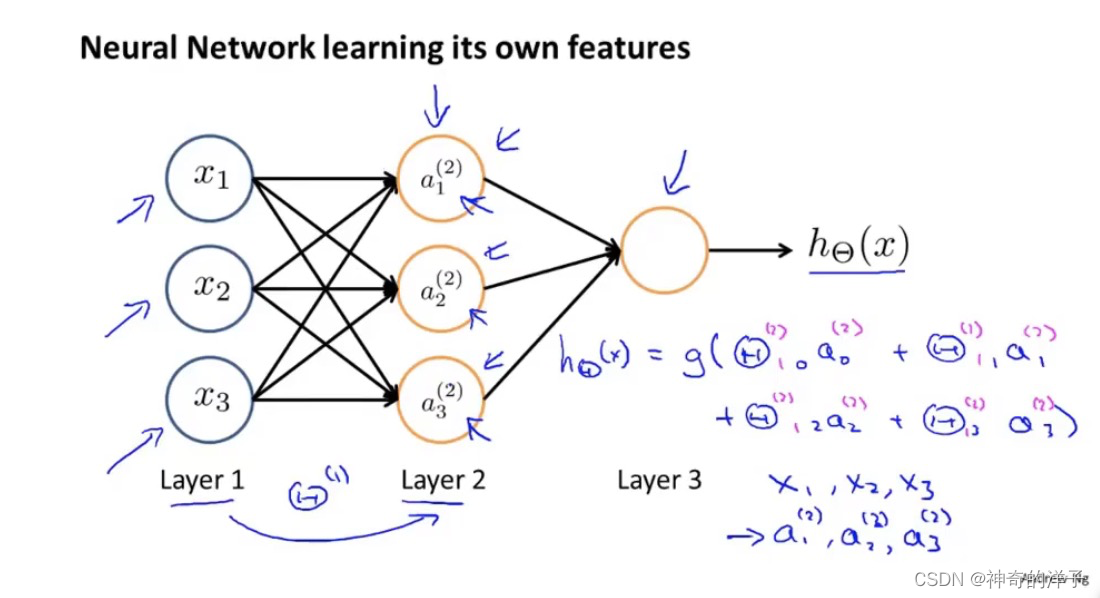
我们可以把𝑎0, 𝑎1, 𝑎2, 𝑎3看成更为高级的特征值,也就是𝑥0, 𝑥1, 𝑥2, 𝑥3的进化体,并且它们 是由 𝑥与θ决定的,因为是梯度下降的,所以𝑎是变化的,并且变得越来越厉害,所以这些更 高级的特征值远比仅仅将 𝑥次方厉害,也能更好的预测新数据。
这就是神经网络相比于逻辑回归和线性回归的优势
根据前向传播的原理,从输入层传递到隐藏层1,再前向传播到隐藏层2,最后到达输出层
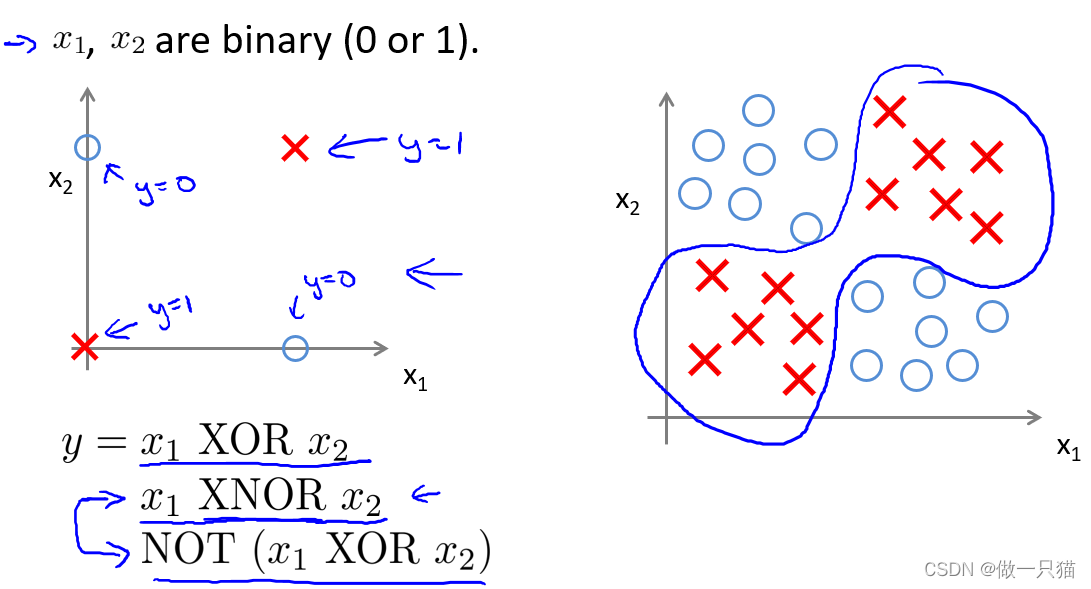
8.3 例:神经网络用于计算XOR,XNOR(异或,以及假异或(当两数异或为真时,取假)新版吴恩达-无)
-
定义两个特征x1,x2,它们的值只能为0或1
-
AND
引入x0,值为1。对权重 / 参数进行赋值,-30、+20、+20
x1 = 0,x2 = 0,hθ(x)结果为0
同理得到另外三组结果
总结果与 x1 AND x2 一致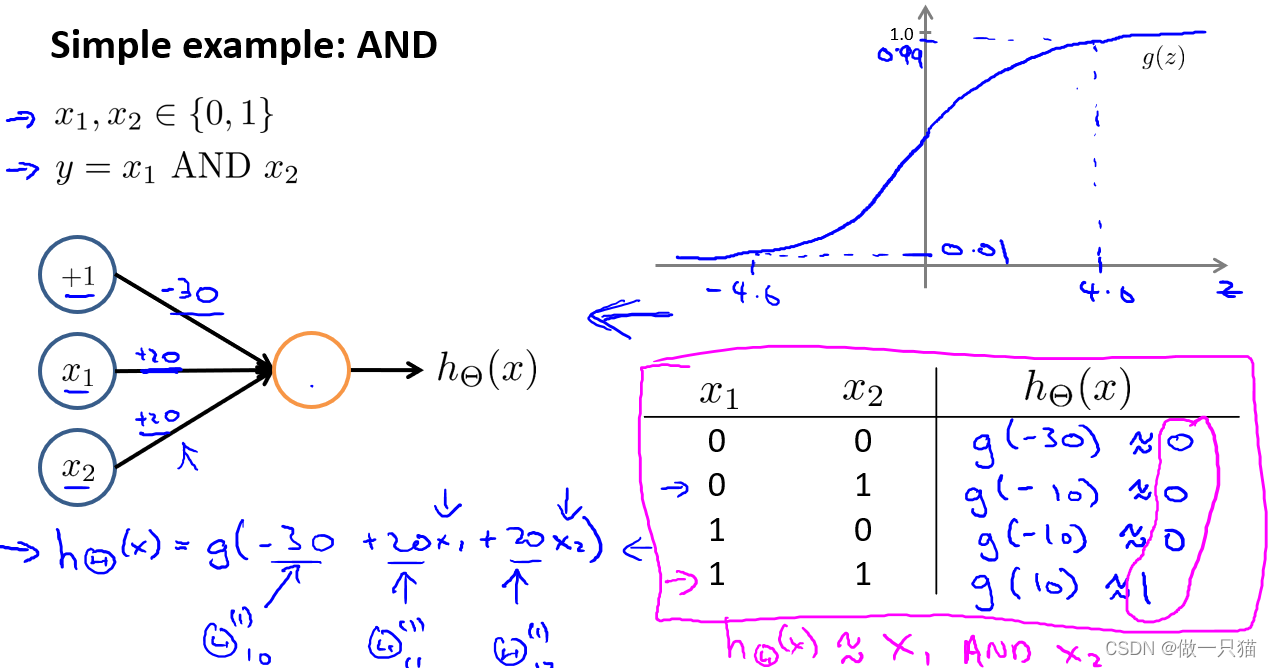
-
OR
与AND同理

(NOT x1)AND(NOT x2)
NOT即结果取反。如果x1输入为1,则输出为0
x1输入0,hθ(x1)输出1;x2输入0,hθ(x2)输出1,再进行AND运算可得最终结果
其他三种情况同理
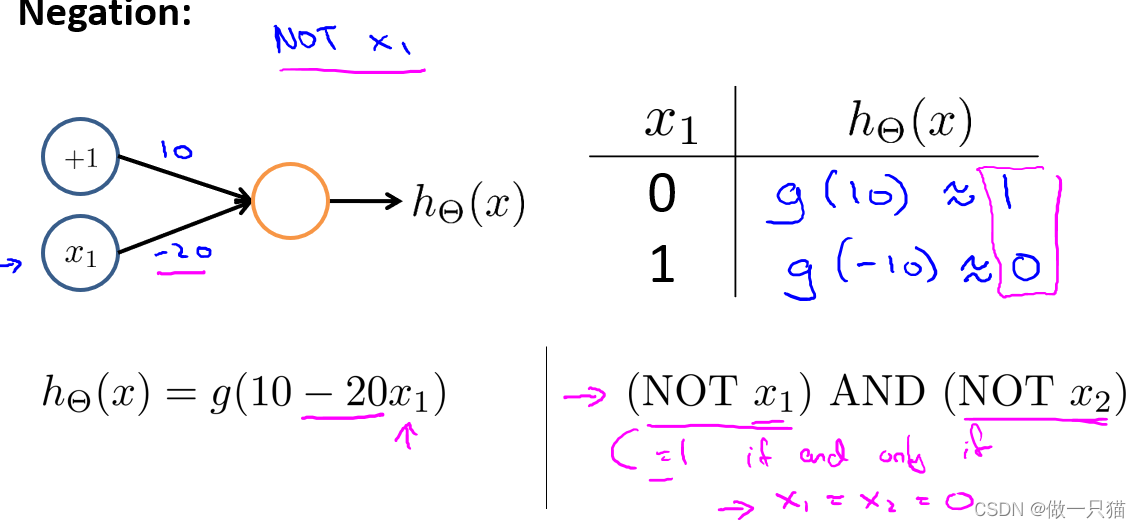
- XNOR
有AND,(NOT x1)AND (NOT x2), OR三个前提
同样在输入层定义x0,x1,x2
在隐藏层中
进行AND运算得到a1(2),进行(NOT x1)AND (NOT x2)运算得到a2(2)
在输出层中
进行OR运算得到a1(3),即为最终结果,每层都是通过计算不断复杂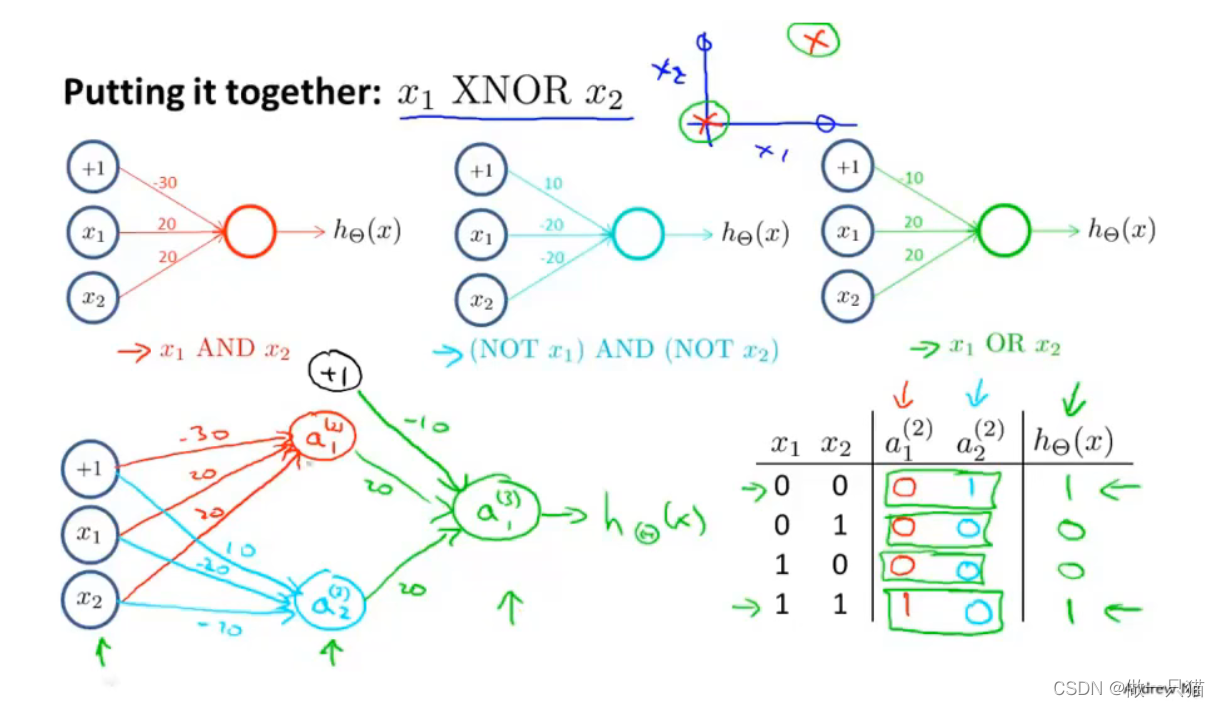
第九章
9.1 神经网络代价函数(这里讲解神经网络,在分类问题上面的应用)
sl表示第L层的单元数,表示神经元的数量(不包含L层的偏差单元)

sl表示输出单元的个数,其中L同样代表最后一层的序号
K为输出层的单元数量,S L 代表输出层(L为最后一层的序号),K 要大于等于3,不然没有必要去使用多分类。对于二分类,h(x)是一个实数。而对于多分类问题,h(x) 是一个K维向量
注意:这里正则化项,不考虑偏置项,所以下面标从1开始
xxxxxxxxxxxxx这儿有点不懂
代价函数
在逻辑回归(含正则项)中,我们有如下代价函数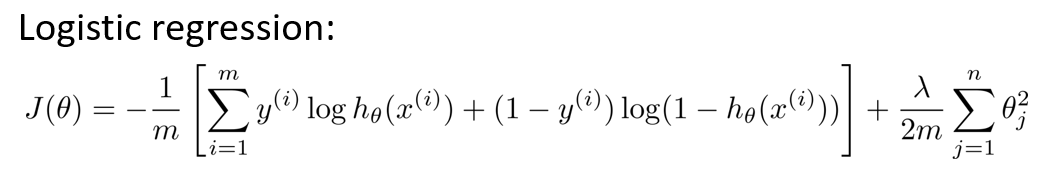
演化到神经网络中,得到如下代价函数(m维 k个输出单元)
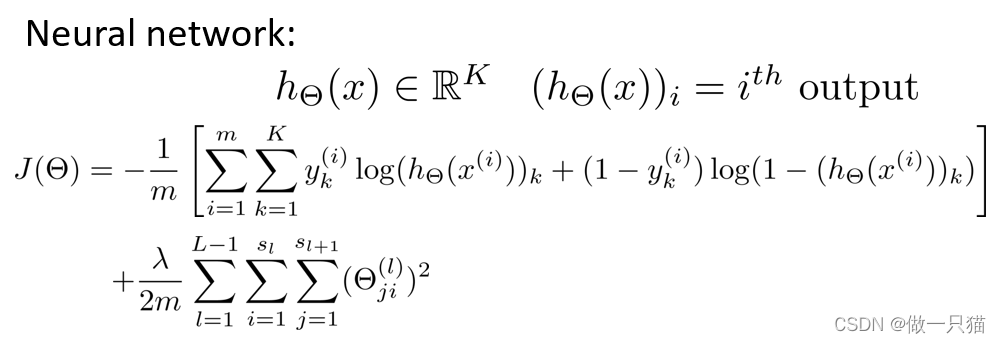
其中
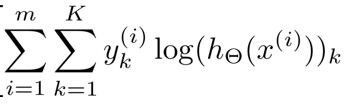
两个连加类似for循环。 (m维 k个输出单元)
这里相当于求k等于从1到4的每一个逻辑回归算法的代价函数,然后按四次输出的顺序,依次把这些代价函数加起来
其次
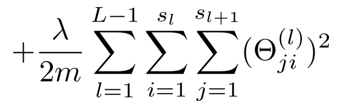
这一项表对所有θji^(l)求和
1 到 L - 1是因为映射是两两之间的
注意 j 和 i没有标错,按照之前的定义,j就是θ向量的行,进而 i 就代表列
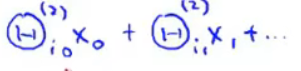
在计算中,不将θi0这一项也进行计算,乘出来的结果有些类似于偏差单元的值,但实际运用中,影响不大
9.2让神经网络代价函数最小化的算法---反向传播算法(有点不懂)(新版无)
δj ^(L)代表了第I层的第j个结点的误差
参考9.2节:【机器学习】机器学习笔记(吴恩达)_Bug 挖掘机的博客-CSDN博客_机器学习笔记
9.3反向传播算法理解(反向传播计算代价函数的导数)(新版无)
参考P52:B站视频重新学习[中英字幕]吴恩达机器学习系列课程_哔哩哔哩_bilibili
9.4 使用技巧:展开参数(矩阵展开为向量)
矩阵转向量,后面用python实现

返回gradient vec梯度向量(从获取参数到获取代价函数到导数值)偏导数D J(theta)代价函数

9.5 梯度检测(用来计算 反向传播算法的偏导数D是否计算正确)
我们之前所学是利用前向传播和后向传播来计算导数,梯度检测用来验证能正确计算代价函数的导数D
双侧差分相比单侧差分会更加准确
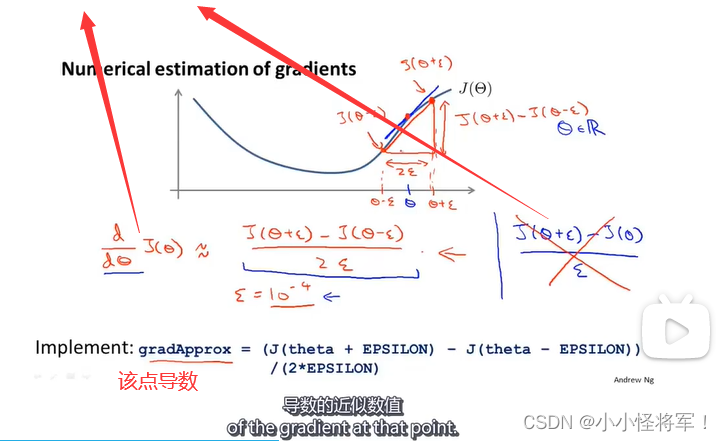
梯度检测: 计算神经网络中所有参数的偏导数

总结:建议使用反向传播来代替梯度检测的导数求导工作

9.6 随机初始化(初始化θ使每个项不再冗余)
任何优化算法都需要一些初始的参数。到目前为止我们都是初始所有参数为 0,这样的 初始方法对于逻辑回归来说是可行的,但是对于神经网络来说是不可行的。如果我们令所有 的初始参数都为 0,这将意味着我们第二层的所有激活单元都会有相同的值。同理,如果我 们初始所有的参数都为一个非 0 的数,结果也是一样的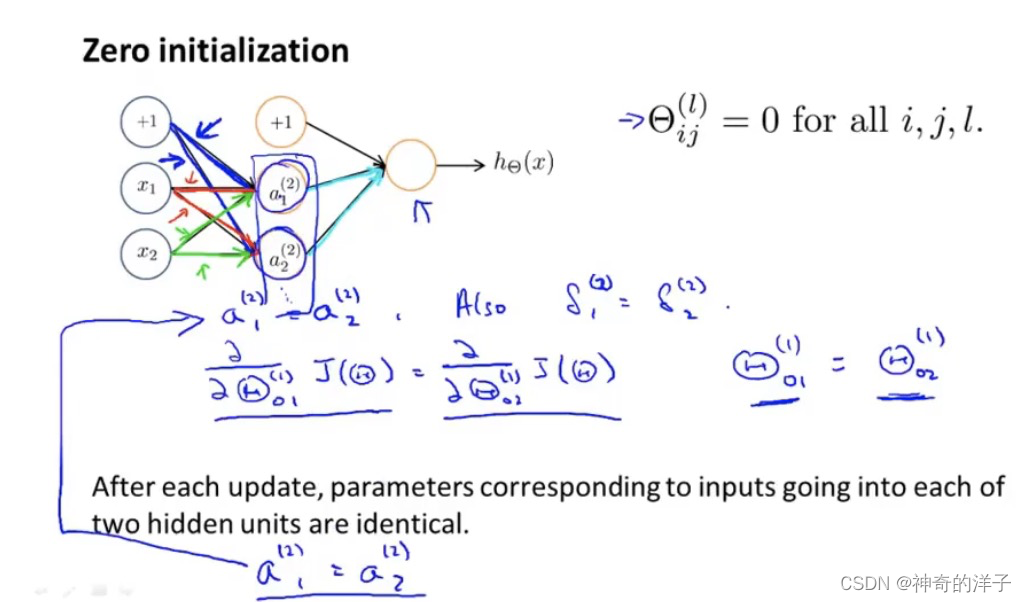

9.7小总结
1.选择神经元之间的连接模式(输入单元隐藏单元,输出单元)
小结一下使用神经网络时的步骤:
- 网络结构:第一件要做的事是选择网络结构,即决定选择多少层以及决定每层分别有多 少个单元。
- 第一层的单元数即我们训练集的特征数量。
- 最后一层的单元数是我们训练集的结果的类的数量。
- 如果隐藏层数大于 1,确保每个隐藏层的单元个数相同,通常情况下隐藏层单元的个数越多越好。
我们真正要决定的是隐藏层的层数和每个中间层的单元数。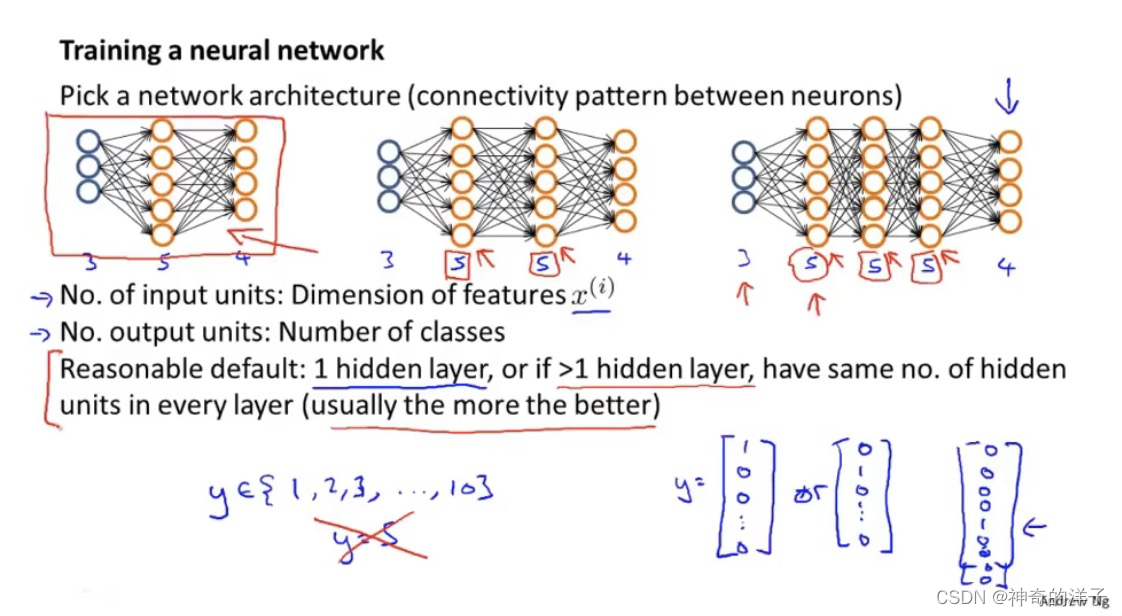
训练神经网络:
- 1.参数的随机初始化
- 利用正向传播方法计算所有的h𝜃 (𝑥)
- 编写计算代价函数 𝐽 的代码
- 利用反向传播方法计算所有偏导数
- 利用数值检验方法检验这些偏导数
- 使用优化算法来最小化代价函数

 反向传播原理:在利用反向传播算法求得代价函数的偏导数后,再利用梯度下降或者更高级的算法求得代价函数最小值,使之求到的H(θ)和实际值y相吻合的很接近
反向传播原理:在利用反向传播算法求得代价函数的偏导数后,再利用梯度下降或者更高级的算法求得代价函数最小值,使之求到的H(θ)和实际值y相吻合的很接近
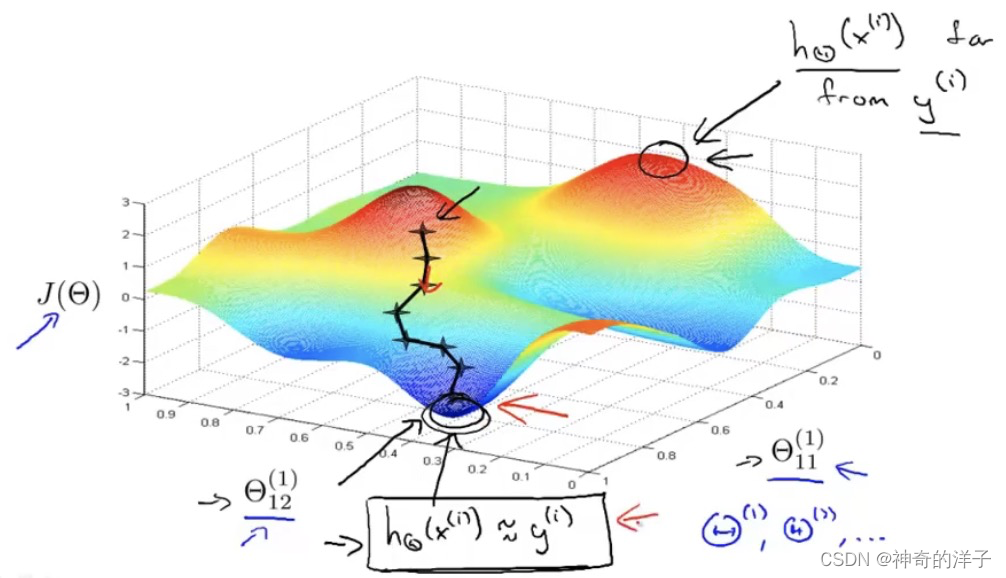
第十章 应用机器学习的建议
10.1 应用机器学习的建议
到目前为止,我们已经学习了许多不同的学习算法,但可能没有完全理解怎样运用它们,因此总是把时间浪费在毫无意义的尝试上。所以我们接下来将学习一些方法去选择一条最正确的道路。
我们将重点关注的是如果我们在开发一个机器学习系统,或者想试着改进一个机器学习系统的性能,我们要如何决定接下来应该选择哪条道路?
为了解释这一问题,我们仍然使用预测房价的学习例子。假设已经完成了正则化线性回归,也就是最小化代价函数的值,但如果假设函数放到一组新的房屋样本上进行测试,发现在预测房价时产生了巨大的误差,我们要如何改进这个算法?

- 第一种办法是使用更多的训练样本。但有时候获得更多的训练数据实际上并没有作用。 -----解决高方差
- 第二种方法是尝试选用更少的特征集。如果你有很多特征,我们可以从这些特征中仔细挑选一小部分来防止过拟合。--------解决高方差
- 第三种方式是尝试选用更多的特征,也许目前的特征集,对我们来讲并不是很有帮助。所以我们也许可以从获取更多特征的角度来收集更多的数据,也可以把这个问题扩展为一个很大的项目。-----解决高偏差
- 第四种方式是可以尝试增加多项式特征,比如X1的平方,X2的平方,X1和下的乘积等等。------解决高偏差
- 第五种方式是可以考虑其他方法去减小或增大正则化参数的值。----------解决高偏差(减小)/高方差(增大)
以上这些方法都需要很长的时间,但有一系列简单的方法能让我们事半功倍,排除掉这些方法中的至少一半,从而节省大量不必要花费的时间。这些方法被叫做 “机器学习诊断法” 。
“诊断法” 的意思是:这是一种测试法,你通过执行这种测试,能够深入了解某种算法到底是否有用。这也能告诉我们,要想改进一种算法的效果,去做什么样的尝试才是有意义的。
 、
、
但同时这些诊断法的执行和实现,也需要花费时间,有时候确实需要花很多时间来理解和实现,不过这样做是把时间用在了刀刃上,可以为我们在开发学习算法时节省几个月的时间。
10.2 评估一个假设 (评价你所学习得到的假设)
在之前的学习中我们尝试选择参量来使训练误差最小化,但得到一个非常小的训练误差并不一定是一件好事,它推广到新的训练集上并不一定适用。那么我们该如何判断一个假设函数是否过拟合呢?
对于简单的例子,我们可以对假设函数进行画图,然后观察图形的趋势,但对于像右边这样特征变量不止一个的情况,就很难画图去观察了。所以需要另一种方法来评估(假设函数是否过拟合)。

这里展示十组训练样本,我们将数据分成两部分,第一部分(通常为70%)作为我们的训练集,第二部分(通常为30%)作为我们的测试集。
用Mtest表示测试样本的总数,(x(1)test, y(1)test)就表示第一组测试样本。
要注意的是,在分成两组数据集之前,应该先将数据随机排列再进行分组。



对于逻辑回归,同样我们也要从训练集中学习得到参数θ,再放到Jtest中去。这个目标函数和之前的一样,唯一的区别是这里使用的是Mtest个样本。
还有另一种测试度量可能更便于理解,叫做错误分类,也叫作0/1分类错误。
可以定义一次预测的误差,是关于假设函数和标签y的误差:
(1)误差等于1的情况是,当假设函数h(x)的值大于等于0.5且y的值等于0时;假设函数的值小于0.5,且y的值等于1时;这两种情况都表示假设对样本进行了误判。
(2)其他情况则误差等于0,表示假设能对样本进行正确分类。
然后我们就能用应用错误分类误差(Test error),来定义测试误差,也就是错误分类误差求平均值。
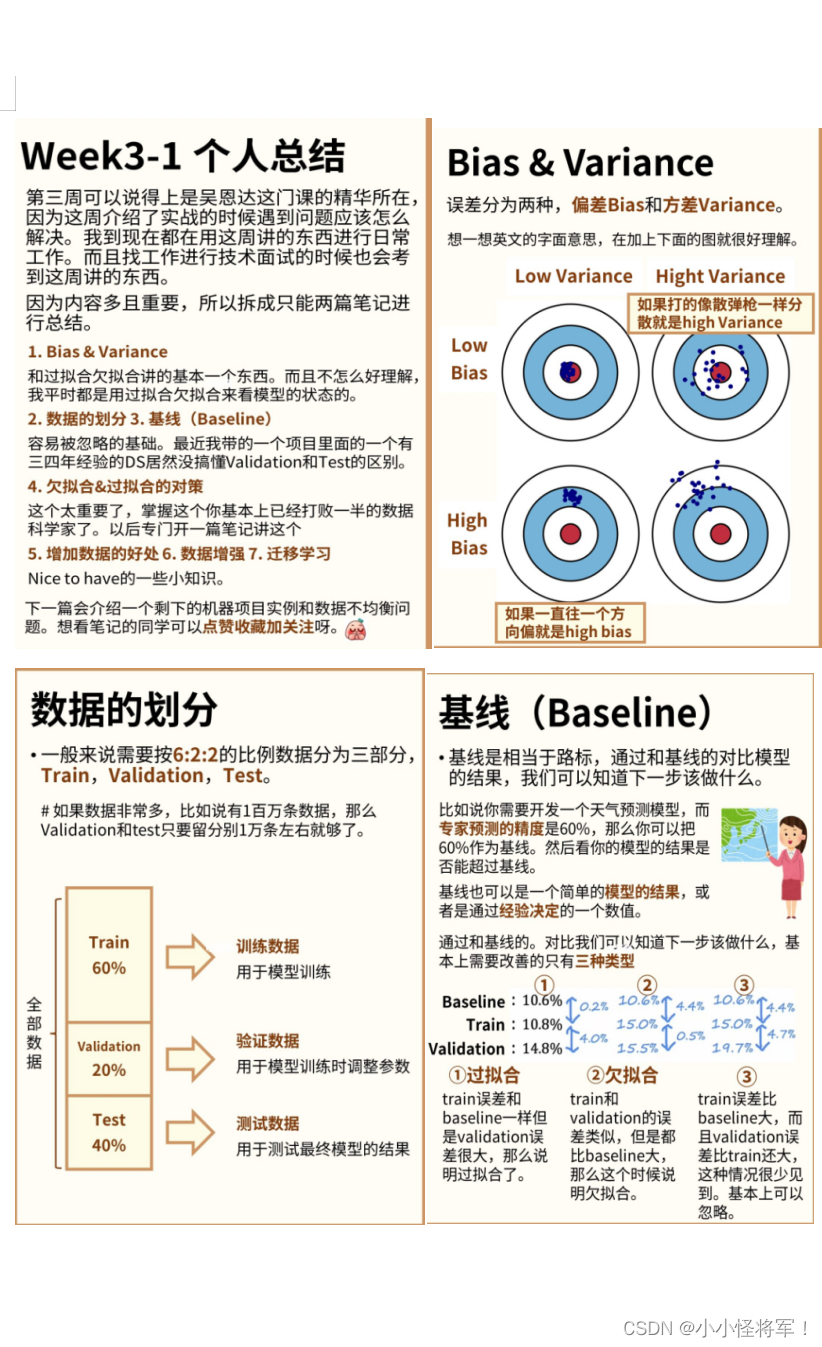
10.3 模型选择(数据分为训练集,验证集和测试集)和交叉验证集
如果我们想要确定对于一个数据集最合适的多项式次数,怎样选用正确的特征来构造学习算法;或者如果我们要选择学习算法中的正则化参数lambda --- λ,要怎么做?这类问题叫做模型选择问题。
说的有点麻烦了,就是一个训练,一个挑选最合适的一个模型,test用来算误差
我们之前提到过拟合问题,用左边这些参数来拟合训练集,就算假设函数在训练集上表现得很好,也不意味着该假设对新样本也有好的泛化能力。所以训练集误差不能用来表示假设对新样本的拟合好坏。而如果参数对某个数据集拟合的很好,那么用同一数据集计算得到的误差,比如训练误差并不能很好地估计出实际的泛化误差(即对该数据集的泛化能力)。如下图:

假设我们要在10个不同次数的二项式模型之间进行选择,用参数d来表示多项式的次数。d=1……d=10。
(1)选择各个模型,分别得到各个参数,为做区别,在参数上加上上标。
(2)用这些参数分别计算得到各个测试集误差。
(3)为从这些模型找到最好一个,应该看哪个模型的测试集误差最小。
(4)假设这里最终选择了五次多项式模型,现在要知道这个模型的泛化能力,可以观察这个模型对测试集的拟合程度,但由于我们拟合了一个参数d,并且选择了一个最好地拟合测试集的参数d的值,因此我们的参数向量θ(5)在测试集上的性能很可能是对泛化误差过于乐观的估计。意思就是说是用测试集拟合得到的参数d,再在测试集上评估假设,所以假设可能对测试集的表现要好过那些其他那些新的测试集中没有的样本。如下图:

为解决模型选择出现的问题,通常会使用以下的方法来评估一个假设:
给定一个数据集,分为三部分,用60%的数据作为训练集,用 20%的数据作为交叉验证集(CV,也叫验证集),用20%的数据作为测试集。
注:交叉验证集中的w、b(01,o2)已经是训练集中梯度下降到比较好的参数了,然后利用这些参数再用交叉验证集再次进行J函数的计算,这样就有更低的代价函数值。
用Mcv来表示验证集的样本总数,同样用(x(i) ,y(i) )来表示第i个验证样本,如下图: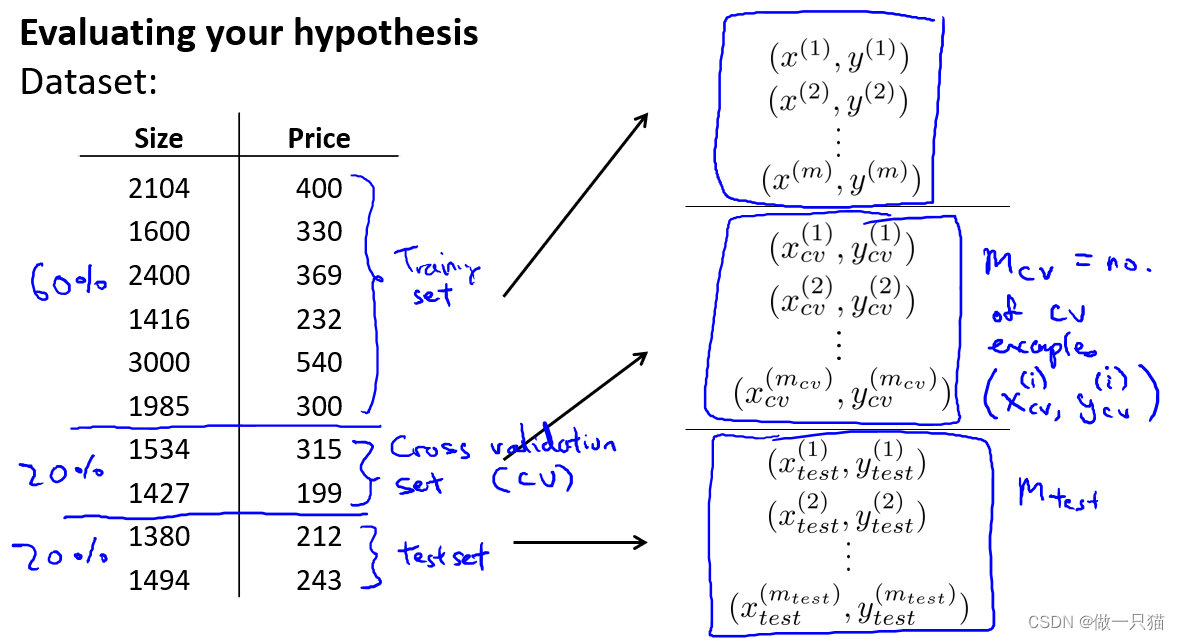
用三个样本分别计算测试误差:下图

下图的模型选择方法:
(1)同样我们用训练集来计算最小代价函数得到各个参数,但这次用验证集来测试。
(2)用计算出的Jcv来观察这些假设模型在交叉验证集上的效果如何。
(3)选择Jcv最小的假设,这里假设选择四次多项式对应的交叉验证误差最小,进而得到d=4
(4)之后就可以用测试集来衡量模型的泛化误差了

10.4 P74 诊断偏差和方差
当我们运行一个学习算法时,如果这个算法的表现不理想,那么多半是出现两种情况:要么是偏差比较大,要么是方差比较大。换句话说,出现的情况要么是欠拟合,要么是过拟合问题。高偏差和高方差的问题基本上来说是欠拟合和过拟合的问题。能判断出现的情况是这两种情况中的哪一种,是一个很有效的指示器,指引着可以改进算法的最有效的方法和途径。
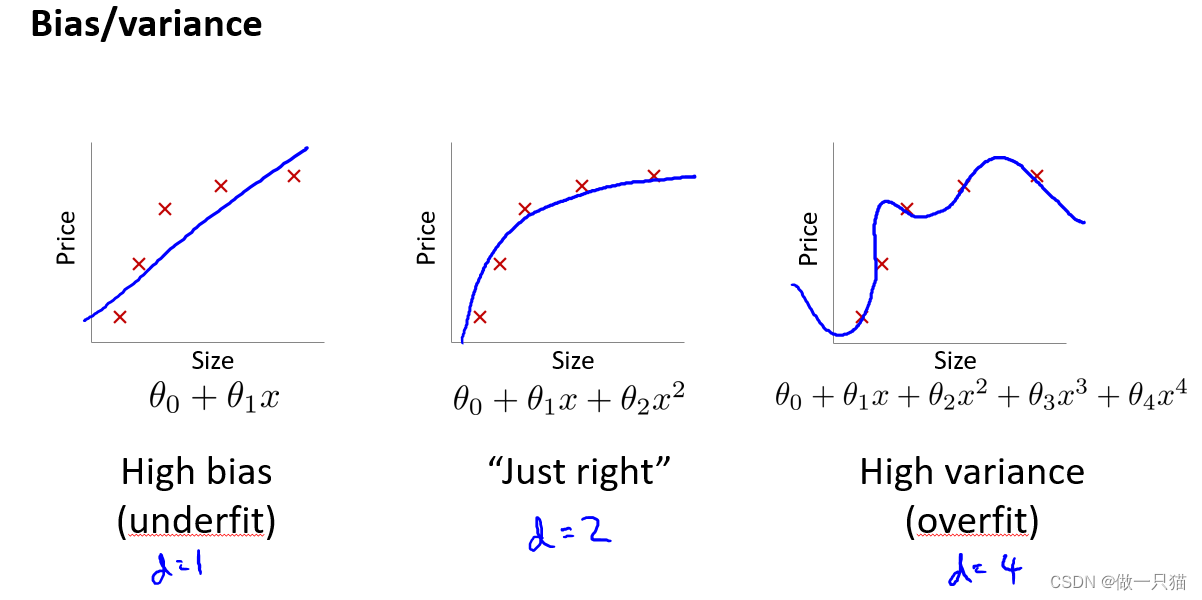
通过之前的学习我们知道,上图左边是欠拟合,右边是过拟合,而中间是刚好拟合,其泛化误差也是最小的。
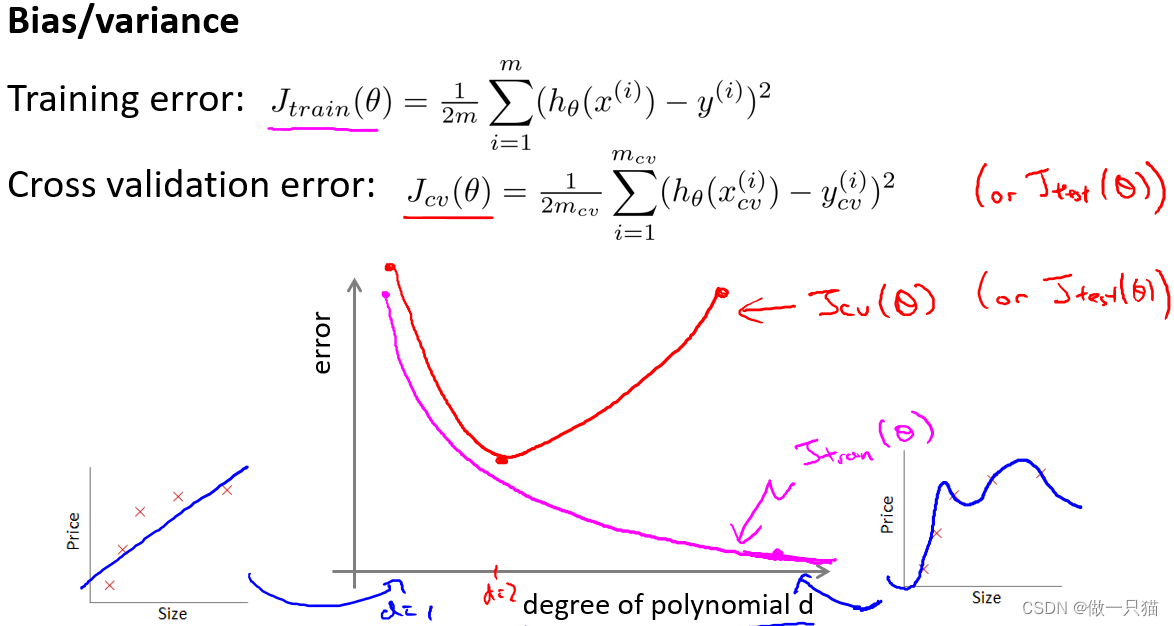
上图的图像,横坐标d代表多项式的次数,左边值为1的时候对应一次函数,右边值为4的时候对应更高的多项式次数。
粉色线Jtrain(θ)代表训练误差,由于次数越高越拟合,所以训练误差是趋于下降的。
红色线Jcv(θ)代表交叉验证误差,d=1时欠拟合,测试误差较高,d=4时过拟合,测试误差较高,而d=2时刚好拟合,测试误差较低。
高偏差:训练误差大,交叉验证误差约等于训练误差,表示模型欠拟合
高方差:训练误差小,但交叉验证误差远远大于训练误差,表示模型过拟合
随着多项式次数d增加,训练误差逐步在减少,而交叉验证误差是先减少后增加
高偏差是因为他欠拟合
高方差是因为它过拟合 下面这张图是重点::::::
高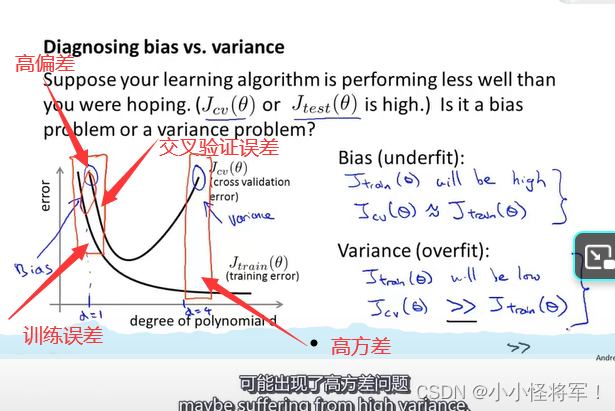
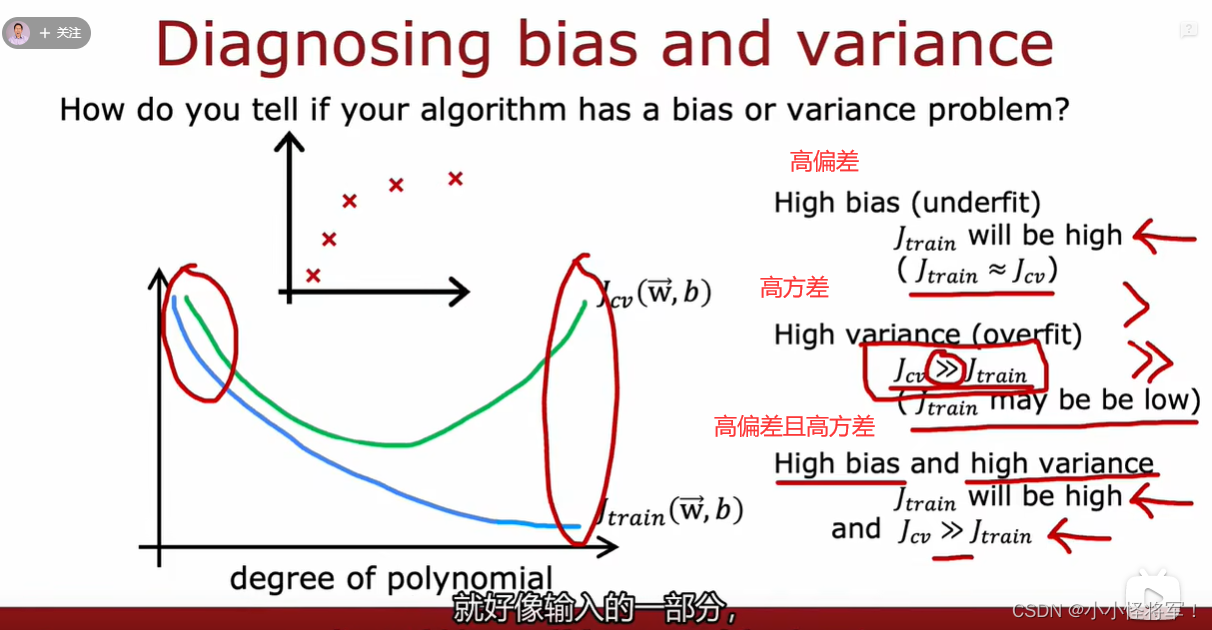
由上面的分析我们可以知道,
d=1时欠拟合,呈现高偏差,此时训练误差和测试误差都很大,且两者接近;
d=4时过拟合,呈现高方差,此时训练误差很大,测试误差很小,测试误差远大于训练误差。
10.5正则化和偏差、方差
在我们在训练模型的过程中,一般会使用一些正则化方法来防止过拟合。但是我们可能 会正则化的程度太高或太小了,即我们在选择 λ 的值时也需要思考与刚才选择多项式模型次 数类似的问题
假设入=1000,则w'(0值)会非常小,w=0,这h函数只剩b,所以是条直线

用交叉验证集来拟合参数θ ,测试集来验证对新样本的泛化能力

λ过大时,出现高偏差
λ过小时,相当于我们没有使用正则项,会过拟合,对训练集很友好,λ小可以代表你可以使用高次项来拟合你的数据
高偏差:训练误差大,交叉验证误差约等于训练误差,表示模型欠拟合
高方差:训练误差小,但交叉验证误差远远大于训练误差,表示模型过拟合
随着多项式次数d增加,训练误差逐步在减少,而交叉验证误差是先减少后增加
注下图训练集分为含正则化参数的代价函数和不含正则化参数的代价函数,交叉验证集合测试集都不含正则化项。
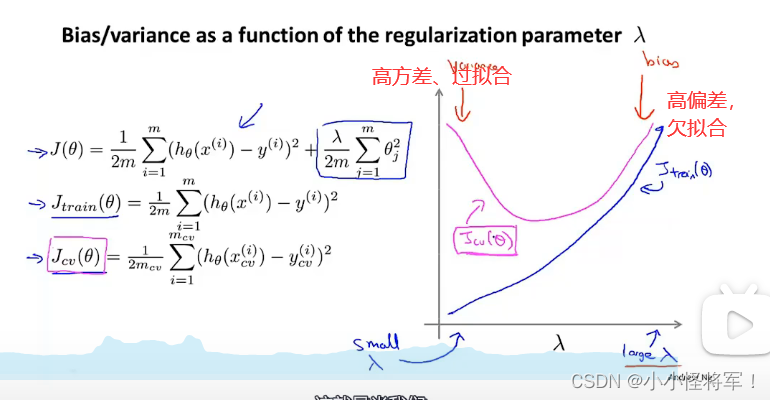
下图为上图更好的理解
10.6 学习曲线(建立诊断方差和偏差的学习算法,以样本数量大小m为横轴)
学习曲线的作用帮助我们来诊断某个学习算法是否处于偏差,方差的问题,或者两者都有
当样本m数量增大时,训练误差会增大,因为很难保证每个点都命中的训练集;而交叉验证误差会变小,因为训练样本多了,数据多了,能更好的拟合假设了,模型的泛化能力(拟合能力)变好。
之前的曲线的横轴是多项式的次数,并不是样本数量

高偏差(欠拟合)的学习曲线如下图
随着样本数增多,训练误差和交叉验证误差都不会改变,出于一个水平线的位置
结论:学习算法对于处于高偏差(欠拟合,λ值过大)的数据,再给再多的数据得到的交叉验证误差和训练误差都不会再改变太多(适应不了再多的数据了),所以当误差随着样本数量增多时,而误差却降不下来,则可以知道你的假设处于高偏差状态
在高偏差下,增加数据到训练集不一定有帮助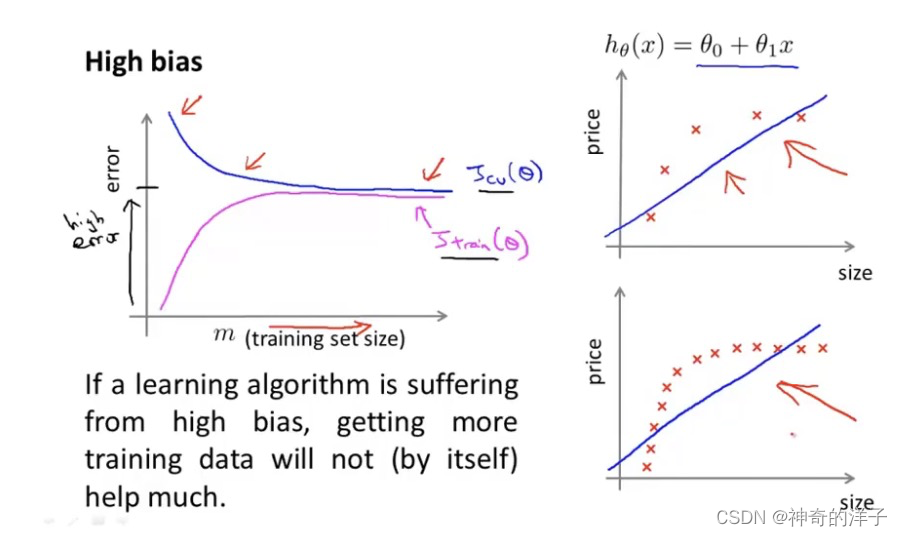
高方差(过拟合)特点:交叉验证误差和训练误差中间有很大的差距
因为我们对假设过拟合,所以交叉验证误差一直将会很大
高方差(过拟合)的话,增加样本数量,训练误差增大,交叉验证误差会减小(增加样本数量对改进算法有帮助仅适用于高方差) 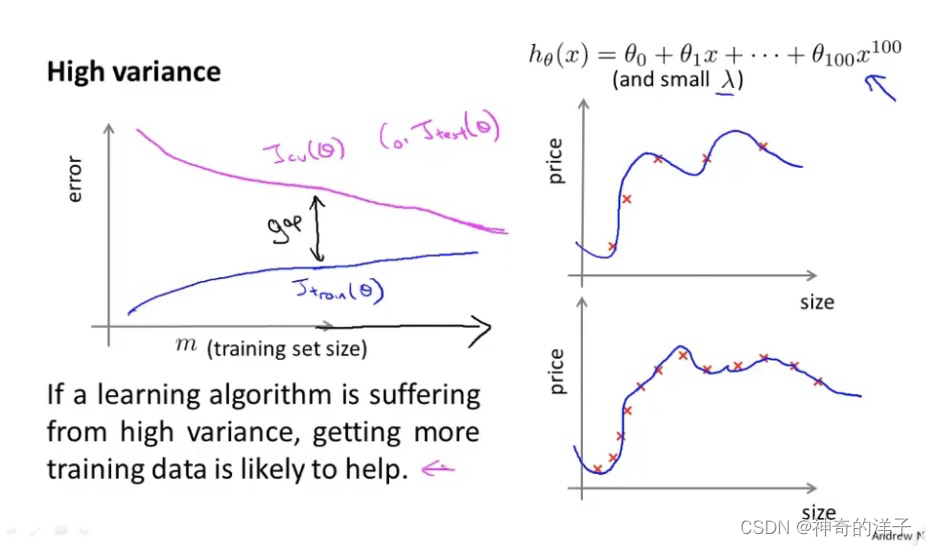
10.7改进学习算法
有了学习曲线,我们可以看出是高偏差还是高方差,然后用下面方法进行修复
高偏差:说明我们的假设太简单,欠拟合,λ值比较大
高方差:说明我们的项数太大,过拟合,λ值比较小
- 获得更多的训练实例(增加样本数量)——解决高方差????(改善模型参数,更侧重于交叉验证集的参数)
- 尝试减少特征的数量——解决高方差
- 尝试增加正则化程度 λ——解决高方差
- 尝试获得更多的特征——解决高偏差
- 尝试增加多项式特征x1*x2——解决高偏差
- 尝试减少正则化程度 λ——解决高偏差
1.使用较小的神经网络,类似于参数较少的情况,容易导致高偏差和欠拟合,但计算代 价较小;使用较大的神经网络,类似于参数较多的情况,容易导致高方差和过拟合,虽然计算 代价比较大,但是可以通过正则化手段来调整而更加适应数据。
2.通常选择较大的神经网络并采用正则化处理会比采用较小的神经网络效果要好。3.对于神经网络中的隐藏层的层数的选择,通常从一层开始逐渐增加层数,为了更好地 作选择,可以把数据分为训练集、交叉验证集和测试集,针对不同隐藏层层数的神经网络训练神经网络, 然后选择交叉验证集代价最小的神经网络


11.1 确定执行的优先级(设计复杂学习系统)
为了构建这个分类器算法,我们可以做很多事,例如:收集更多的数据,让我们有更多的垃圾邮件和非垃圾邮件的样本(蜜罐)
基于邮件的路由信息开发一系列复杂的特征
基于邮件的正文信息开发一系列复杂的特征,包括考虑截词的处理
为探测刻意的拼写错误(把 watch 写成 w4tch)开发复杂的算法
我们将在随后的课程中讲误差分析,我会告诉你怎样用一个更加系统性的方法,从一 堆不同的方法中,选取合适的那一个


11.2 误差分析(建议在交叉验证集上做误差分析)
构建一个学习算法的推荐方法为:
从一个简单的能快速实现的算法开始,实现该算法并用交叉验证集数据测试这个算 法
绘制学习曲线,决定是增加更多数据,或者添加更多特征,还是其他选择
进行误差分析:人工检查交叉验证集中我们算法中产生预测误差的实例(
可以用单一的数值指标,即通过某个实数来评估你的学习算法,去算出误差率),看看这些实例是否有某种系统化的趋势
Recommended approach 推荐方法
Start with a simple algorithm that you can implement quickly.lmplement it and test it on your cross-validation data. 从一个简单的算法开始,您可以快速实现它,然后在交叉验证数据上测试它。
Plot learning curves to decide if more data, more features, etc.are likely to help. 绘制学习曲线,以确定是否有更多的数据、更多的特性等可能会有所帮助。
Error analysis: Manually examine the examples (in cross 错误分析:手动检查示例(在交叉中)
validation set) that youralgorithm made errors on.See if youspot any systematic trend in what type of examples it is (验证集)你的算法犯了错误。参见如果你在哪种类型的例子中发现任何系统性的趋势
making errors on. 继续犯错误。

11.3 不对称性分类的误差评估(偏斜类问题用查全率(召回率)和查准率)
正例和负例的比率处于一个极端的情况,叫偏斜类问题,一个样本中的数据比另一个反例样本中的数据多很多,就叫偏斜类问题,比如说99%的病人有癌症,你只有1%的误差在测试集上
对于偏斜类问题,单一的数值指标,即通过某个实数来评估你的学习算法,就不管用了,因为从准确率99.3%,到准确率99.5% 。看似数值提高了,但是实际效果没有什么帮助。所以衍生出另外一种评估度量值,叫查准率和召回率(查全率,西瓜书)
下图为公式介绍:

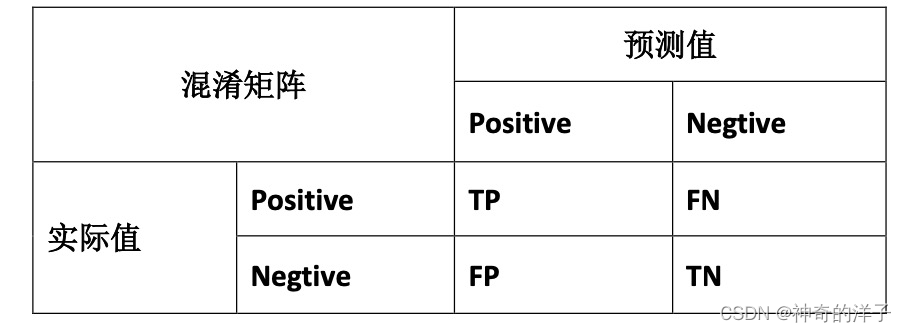
查准率(Precision)和查全率(Recall) 我们将算法预测的结果分成四种情况:
1. 正确肯定(TruePositive,TP):预测为真,实际为真
2. 正确否定(TrueNegative,TN):预测为假,实际为假
3. 错误肯定(FalsePositive,FP):预测为真,实际为假
4. 错误否定(FalseNegative,FN):预测为假,实际为真
则:查准率(在预测的基础上,看真实的预测占到多少)=TP/(TP+FP)。例,在所有我们预测有恶性肿瘤的病人中,实际上有恶性肿 瘤的病人的百分比,越高越好。------------准不准
查全率(召回率)(在实际的基础上我们的预测准不准)=TP/(TP+FN)。例,在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的 病人的百分比,越高越好。-----------全不全
这样,对于我们刚才那个总是预测病人肿瘤为良性的算法,其查全率是 0对于分类问题,查准率和召回率高,这个算法就表现得好
偏斜类问题 用查准率和召回率,比用分类误差或分类准确性好的多
11.4 查准率和召回率的权衡(阀值:更强调这些值中较低的值,制约查准率和查全率的一方偏向)
(偏斜类问题用查全率(召回率)和查准率)
在之前的课程中,我们谈到查准率和召回率,作为遇到偏斜类问题的评估度量值。在 很多应用中,我们希望能够保证查准率和召回率的相对平衡。
1.改变临界值
在这节课中,我将告诉你应该怎么做,同时也向你展示一些查准率和召回率作为算法 评估度量值的更有效的方式。继续沿用刚才预测肿瘤性质的例子。假使,我们的算法输出的 结果在 0-1 之间,我们使用阀值 0.5 来预测真和假。0/1分类的阈值可以取相同的值,不一定要和为1
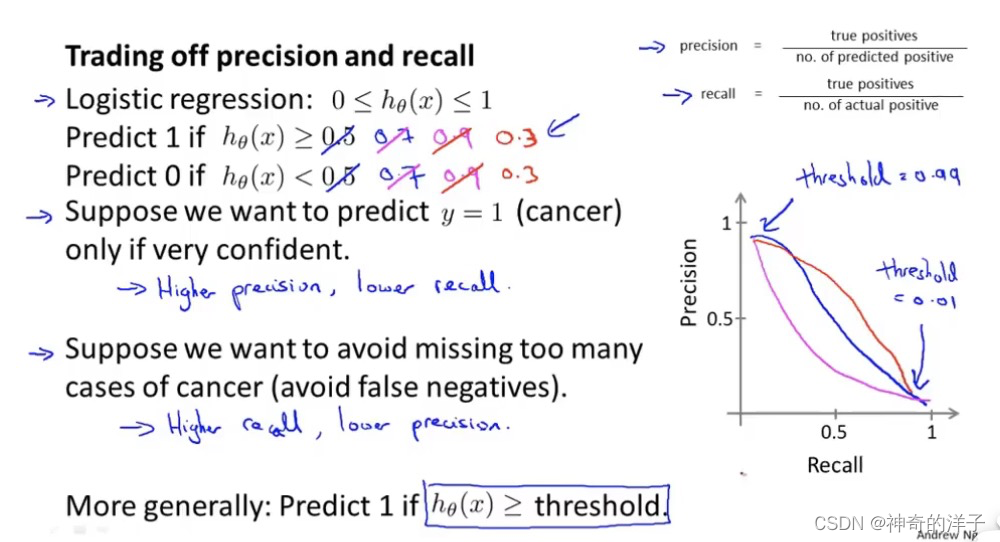
查准率(Precision)=TP/(TP+FP) 例,在所有我们预测有恶性肿瘤的病人中,实际上有恶 性肿瘤的病人的百分比,越高越好。
查全率(Recall)=TP/(TP+FN)例,在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿 瘤的病人的百分比,越高越好。
- 如果我们希望只在非常确信的情况下预测为真(肿瘤为恶性),即我们希望更高的查准率,我们可以使用比 0.5 更大的阀值,如 0.7,0.9(即阙值为0.7,我们才认为他患有肿瘤)。这样做我们会减少错误预测病人为恶 性肿瘤的情况,同时却会增加未能成功预测肿瘤为恶性的情况。即查准率提高而查全率(召回率)降低。 解释:比如:若我们希望选出的西瓜中好瓜尽可能多,即查准率高,则只挑选最优把握的西瓜,算法挑选出来的西瓜(TP+FP)会减少,相对挑选出的西瓜确实是好瓜(TP)也相应减少,但是分母(TP+FP)减少的更快,所以查准率变大;在查全率公式中,分母(所有好瓜的总数)是不会变的,分子(TP)在减小,所以查全率变小。
- 如果我们希望提高查全率,尽可能地让所有有可能是恶性肿瘤的病人都得到进一步地 检查、诊断,我们可以使用比 0.5 更小的阀值,如 0.3。
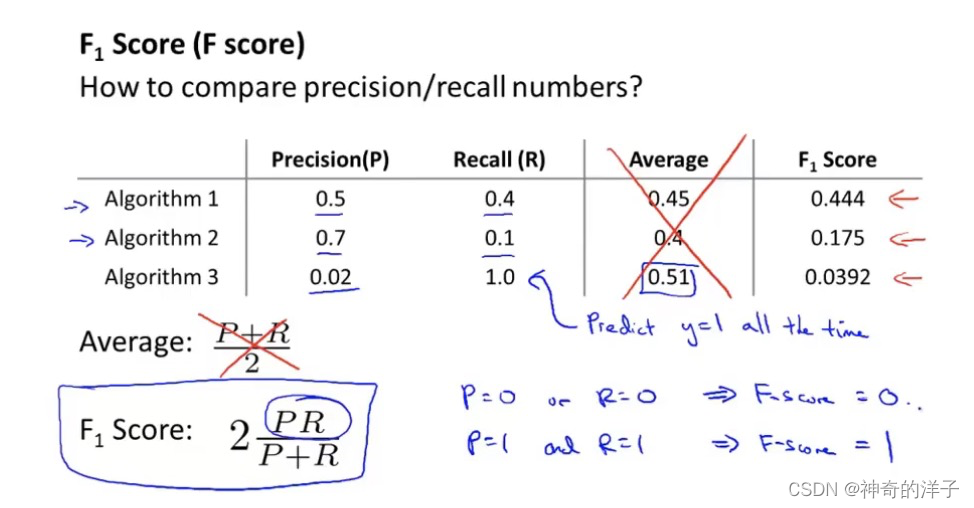
2.用F值来评估衡量查全率和查准率
我们可以将不同阀值情况下,查全率与查准率的关系绘制成图表,曲线的形状根据数 据的不同而不同:
评估查准率和召回率的方法,计算F值,可以用它衡量算法好坏的标准 F值:更强调这些值中较低的值,

11.5 机器学习数据
对数据的要求是要包含足够多的特征,不然白搭。对算法的要求:要包含足够的参数,多参数保证偏差小,大量数据保证方差小,二合一完美。
但是这里有个关键的假设,是特征值含有足够的信息量,有一类很好的假设函数,然后有大量的训练集。

2022新版机器学习补充知识点
P50-P60 为机器学习入门之神经网络基础知识 可以参考笔记:【机器学习】什么是神经网络?如何去搭建神经网络?神经网络的原理是什么?_晓亮.的博客-CSDN博客
P50 TensorFlow中的数据形式



P51搭建一个神经网络


右侧构建神经网络函数优化后结果如下图:

P52 单个网络层上的向前传播
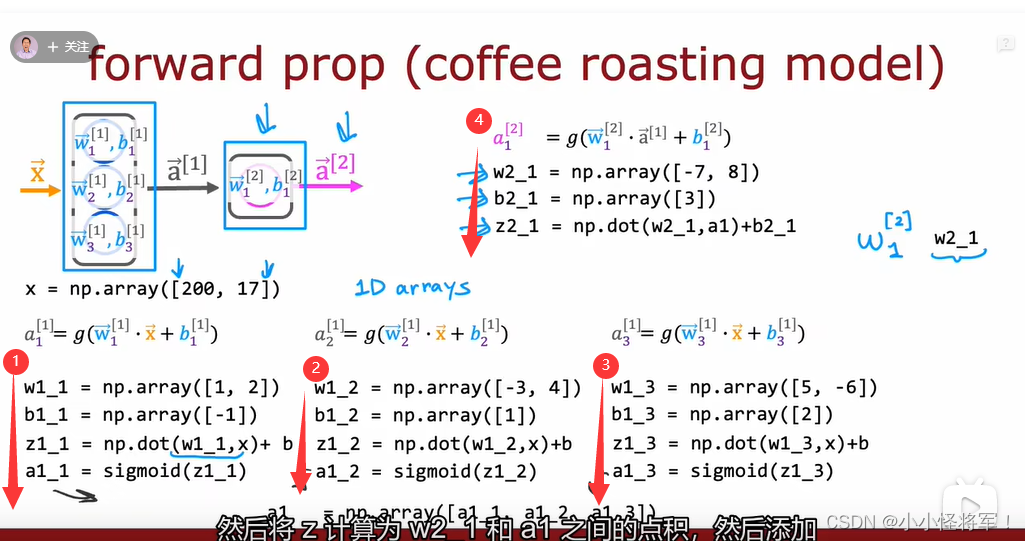
P53 向前传播的一般实现(代码实现)
密集函数的作用就是输出前一层的激活矩阵

shape:
对于矩阵来说:
shape[0]:表示矩阵的行数
shape[1]:表示矩阵的列数
numpy:
X[:,0]是numpy中数组的一种写法,表示对一个二维数组,取该二维数组第一维中的所有数据,第二维中取第0个数据,直观来说,X[:,0]就是取所有行的第0个数据, X[:,1] 就是取所有行的第1个数据。
X[n,:]是取第1维中下标为n的元素的所有值。
X[1,:]即取第一维中下标为1的元素的所有值,输出结果:
X[:, m:n],即取所有数据的第m到n-1列数据,含左不含右
P56 矩阵乘法
参考:带你一次搞懂点积(内积)、叉积(外积)_机器学习Zero的博客-CSDN博客_内积 点积

点积:

P58 矩阵乘法代码

第二周 TensorFlow实现 机器学习入门之神经网络的多分类
(本章P60-P69笔记可以借鉴:【机器学习】神经网络的训练步骤有哪些?神经网络中最常见的激活函数有哪几种?什么是多分类问题?_晓亮.的博客-CSDN博客_神经网络训练的步骤)
P60 模型训练细节

tensorflow中model.fit()用法
model.fit()方法用于执行训练过程model.fit( 训练集的输入特征,训练集的标签,
batch_size, #每一个batch的大小
epochs, #迭代次数
validation_data = (测试集的输入特征,测试集的标签),
validation_split = 从测试集中划分多少比例给训练集,
validation_freq = 测试的epoch间隔数)
1.建立模型
2.定义损失函数(代价函数)

3.优化(x,y为你的训练集)
P61 不同于sigmoid的激活函数
P62 如何选择激活函数


p64 多分类问题

P65 softmax回归模型

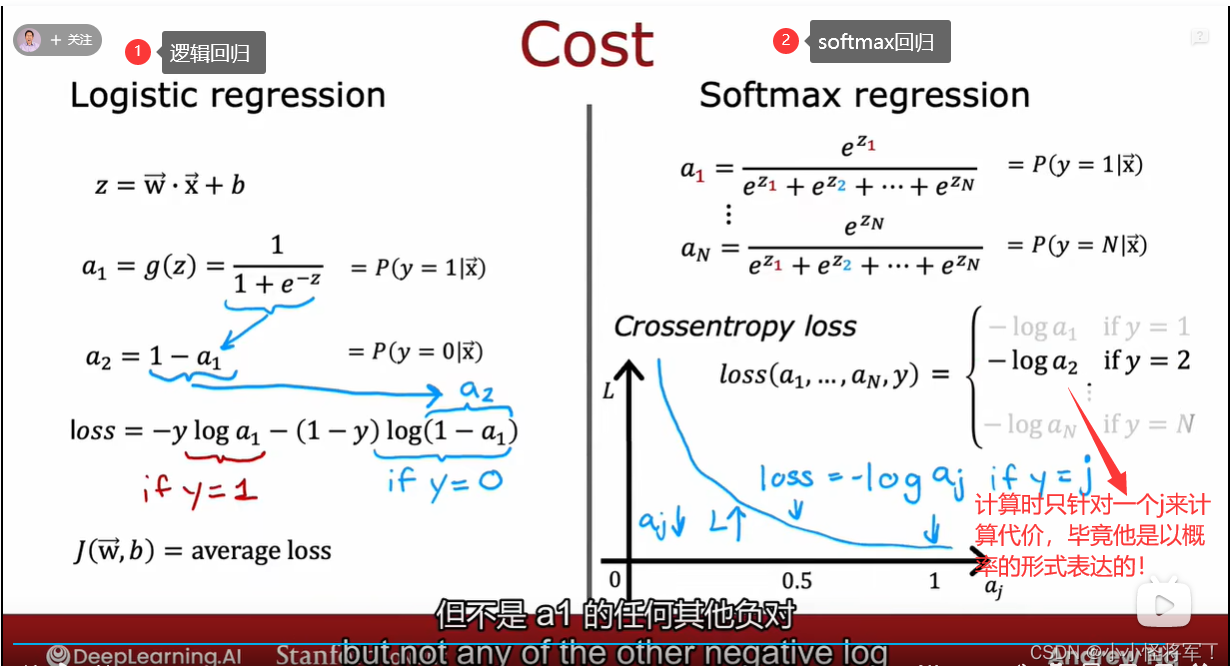
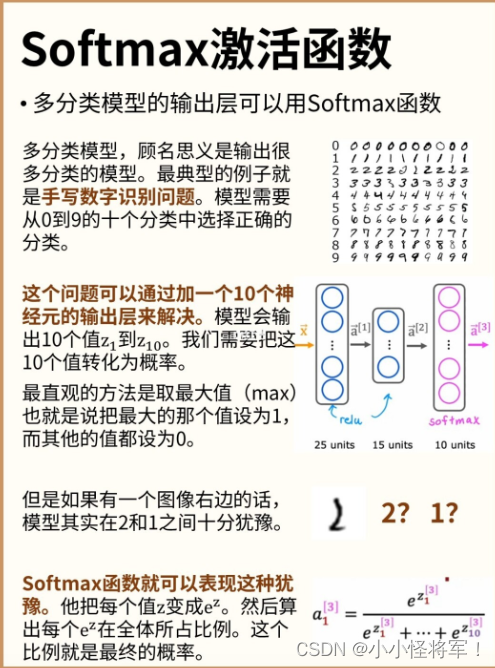
P66 softmax神经网络的输出
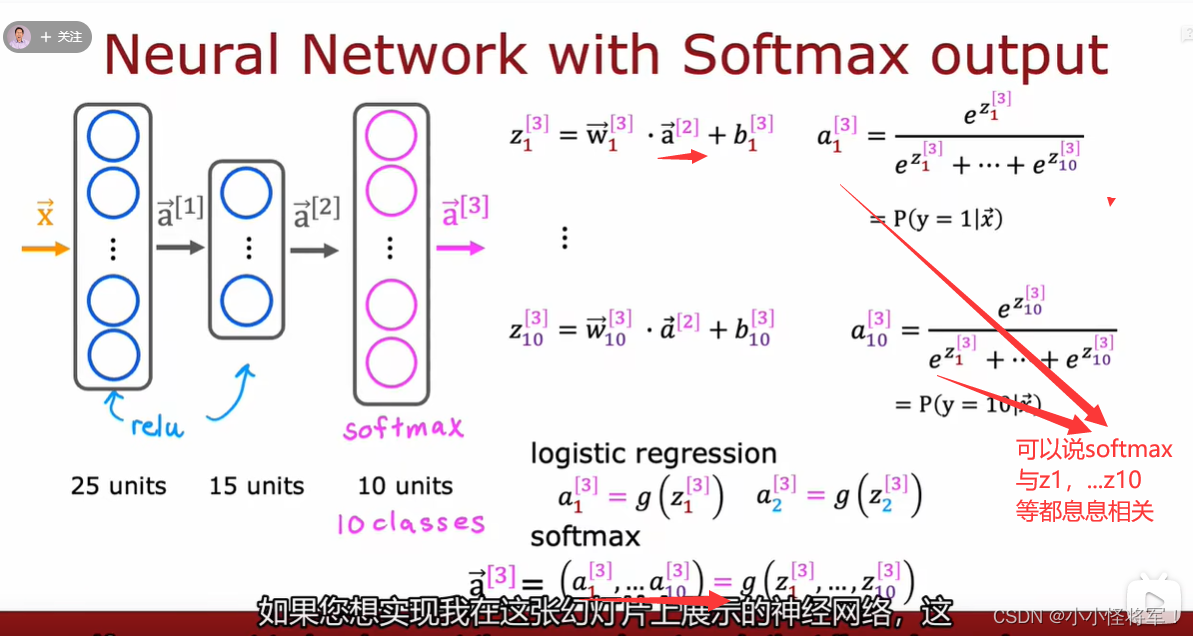

P67 softmax精度的改进

from_logit=True 的解释参照:Keras/TensorFlow 交叉熵损失函数中的 from_logits 参数_杭州的平湖秋月的博客-CSDN博客_from_logits
from_logit=True 的解释:
在 Keras 的二元交叉熵损失函数(tf.keras.losses.BinaryCrossentropy,下面简称为 bce)中,有 from_logits 这个参数。在使用时需要分下面 2 种情况:
1.如果输入给 bce 的是一个 logit 值(值域范围 [-∞, +∞] ),则应该设置 from_logits=True 。
2.如果输入给 bce 的是一个概率值 probability (值域范围 [0, 1] ),则应该设置为 from_logits=False 。实际上,logit 是一个函数,并且它和 sigmoid 互为反函数。sigmoid 会把 logit 值转换为 [0, 1] 之间的概率值,而 logit 则会把概率值转换为 [-∞, +∞] 之间的 logit 值。
P68 多标签分类

P69 高级优化 Adam学习率优化


Adam已经基本上可以用于所有类型的网络并且取得很好的结果,但是由于采用Mini Batch方法,在神经网络学习前期,使用相对大的学习率进行快速逼近最优点,在学习后期则需要采用学习率衰减防止结果在最优点附近不断震荡无法收敛。
机器学习入门之构建机器学习系统一P70-P76
参考笔记:【机器学习】如何去评价一个神经网络模型的好坏?什么是交叉验证数据集?偏差和高差对模型的影响?_晓亮.的博客-CSDN博客_神经网络模型评价
P74 见本笔记10.4节 诊断偏差和方差
P75 见本笔记10.5节 正则化和偏差、方差
P76 制定一个性能评估标准

泛化指对新数据的拟合能力
构建机器学习系统二P77-P83 可以参考:【机器学习】什么是学习曲率?如何解决模型中方差和偏差问题?什么是迁移学习?什么是模型的精确率和召回率?_晓亮.的博客-CSDN博客
P77学习曲线 见本笔记 10.6 学习曲线(建立诊断方差和偏差的学习算法,以样本数量大小m为横轴)
P78决定下一步做什么 见本笔记 10.7改进学习算法
P79方差与偏差 见本笔记 10.7改进学习算法
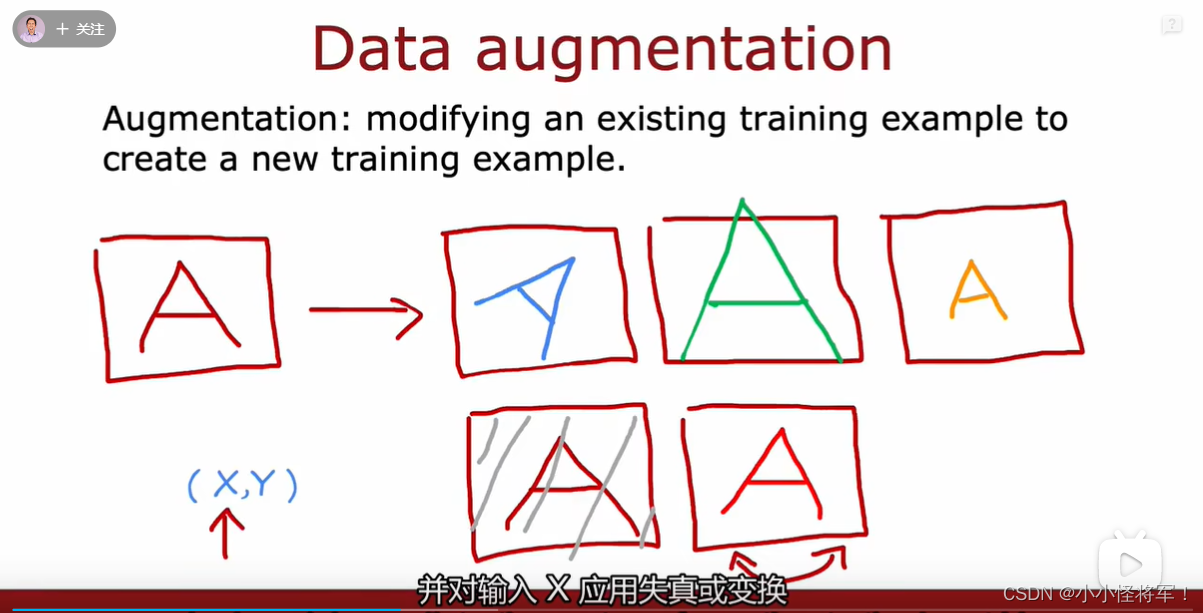
P82添加更多的数据 11.5 机器学习数据
对输入的x应用失真或者变换来得到更多的数据
P83 迁移学习
转移学习总结→
1、下载在大型数据集上预先训练的神经网络参数,输入类型(例如图像、音频、文本)与您的应用程序(或训练您自己的)相同。(预训练)
2.、在您自己的数据上进一步训练(微调)网络。

P71-83总结:
基线一般指人为的判断

P86倾斜数据集合误差指标 11.3 不对称性分类的误差评估(偏斜类问题用查全率(召回率)和查准率)
P87查全率和查准率的权衡 F1权衡 参见笔记11.4 查准率和召回率的权衡(F值,制约查准率和查全率的一方偏向)
P88- P101 决策树部分参考:【机器学习】什么是学习曲率?如何解决模型中方差和偏差问题?什么是迁移学习?什么是模型的精确率和召回率?_晓亮.的博客-CSDN博客
P88决策树型
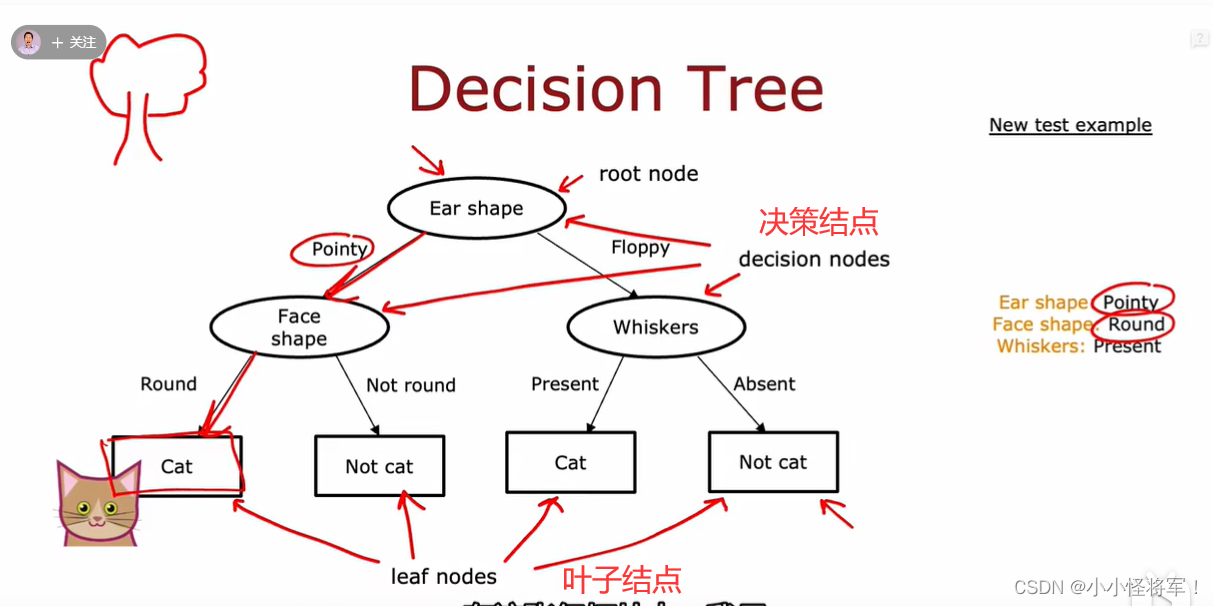
P89 决策树模型
你什么时候停止分裂?
- 当一个节点100%是一个类时
- 当拆分一个节点时,将导致树超过最大深度
- 当纯度分数的改善低于一个阈值
- 当节点中的示例数量低于阈值时

P90纯度 决定如何拆分结点 测量结点中杂质的方式
熵是衡量一组数据是否纯不纯的方式
我们一般会使用熵来衡量一组示例的纯度
先来看一下熵的定义:熵就是衡量一组数据是否不纯的指标。
例如给定一个例子,有3只猫、3只狗。我们如果将p_1定义为猫样本的比例,也就是标签为1占的比例
这个例子中p_1=3/6
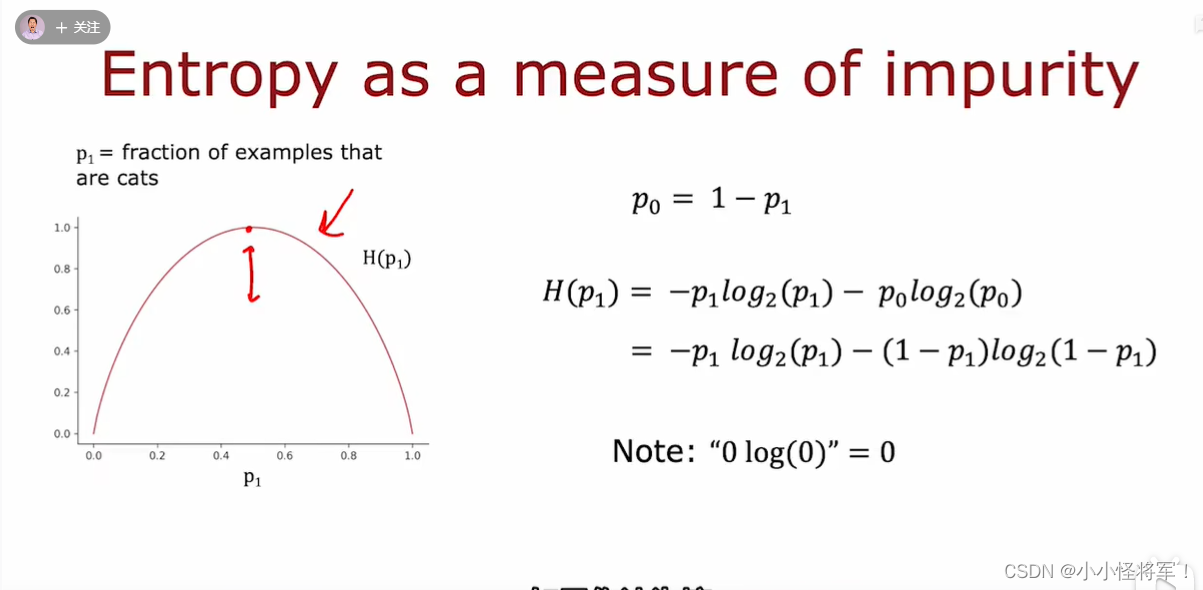
我们将建立如图所示的函数来表示熵,熵函数通常表示为H,这里横轴为p_1值,纵轴为熵的值

下图为熵的计算公式
这里p_1 = 0.5 时,熵的值H(p_1)=1
如果我们的数据集里全是猫,或都不是猫时,熵的值为0
可以看见图中下面一个例子,有5只猫和1只狗,此时正例p_1 = 5/6 = 0.8333 ,熵的值H(p_1)大约为0.65
下面来看看熵H(p_1)的实际方程
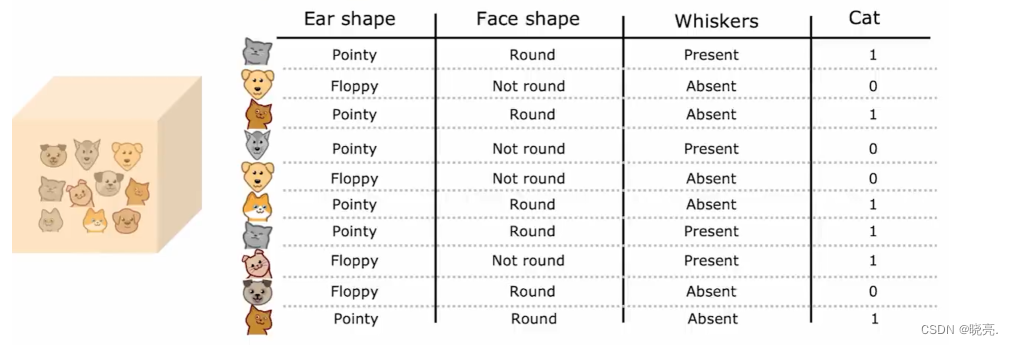
P91 选择拆分信息增益 (熵的差值:代表降低的不确定性程度)
在构建决策树时,我们将决定在节点上拆分什么样的特征取决于 选择什么样的特征可以最大程度的减小熵,或最大化纯度。
在决策树学习中,熵的减少称为信息增益,下面我们来看看如何来计算信息增益,来决定要在决策树上每个支点上选择什么特征进行拆分。
以在根节点选择什么特征来进行拆分为例,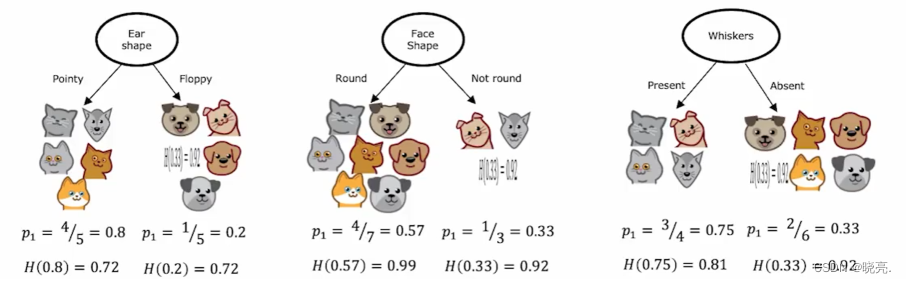
如图,如果以耳朵是尖还是软的为特征,拆分结果左边5个中有4个是猫,右边5个中有1个是猫,概率分别为0.8和0.2. 如果应用熵公式,那么左边的杂质是熵0.72,右边的熵也是0.72。
如果以 脸是圆的和不是圆的 为特征,拆分结果左边7个中有4个是猫,右边3个中有1个是猫,概率分别为0.57和0.33. 如果应用熵公式,那么左边的杂质是熵0.99,右边的熵也是0.92,所以左右节点的杂质程度比前一个要高得多。
如果以 有没有胡须 为特征,拆分结果左边4个中有3个是猫,右边6个中有2个是猫,概率分别为0.75和0.33. 如果应用熵公式,那么左边的杂质是熵0.81,右边的熵也是0.92.
我们需要做的就是对比这3个特征,找出哪一个特征在根节点使用的效果最好。
事实证明可以对这些计算出来的熵值进行加权平均,然后在做比较。
还从头开始,第一个,我们10个例子中有5个去了左分支,5个去了右分支,那么我们就可以直接计算加权平均值,如图,依次类推,其他的特征计算也是一样的。3个加权平均值最小的哪个就是我们需要的那个特征。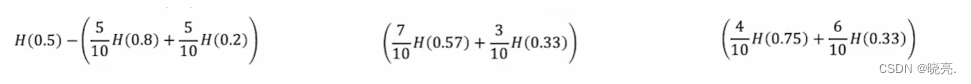
但是这样并不准确,在构建决策树的方式中,我们实际上要对这些公式在决策数构建中遵循惯例,除了计算这个加权平均熵,我们需要将计算熵的减少与我们没有进行分裂的情况相比较。
我们回到上面的例子,没有进行分裂时,10个中有5只猫,p_1=0.5, 根节点的熵实际上等于1,这时纯度最高,H(0.5)=1我们实际上用于拆分的公式如图
信息增益------------越大您的子集的纯度越高

计算出来的0.28、0.03、0.12这些被称为信息增益。它衡量的是熵的减少。
随这决策树的不断分裂,经过不断的拆分,我们最终会得到较低的熵值.这两个值之间的差异,就是熵的减少
为什么我们要计算熵的减少而不仅仅是左右分支的熵呢?
因为决定何时停止或不停止分裂的标准之一,如果熵的减少太小,则需要进一步拆分。
在这种情况下,我们可以选择熵减少的较多的结果进行拆分,因为一直拆分会有过度拟合的风险。
信息增益的一般公式如下:
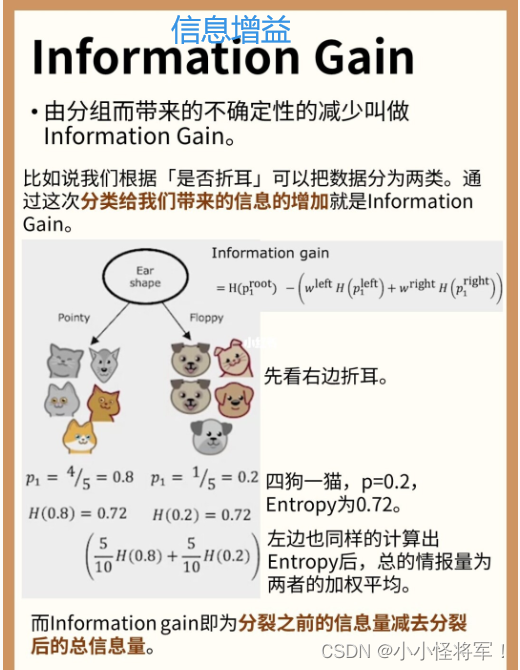
注意:::::
信息增益中的Pk的分母是当前当前样本集合中的样本数量
H(Pk)前面的权重的分母是父节点中样本集合中的样本数量


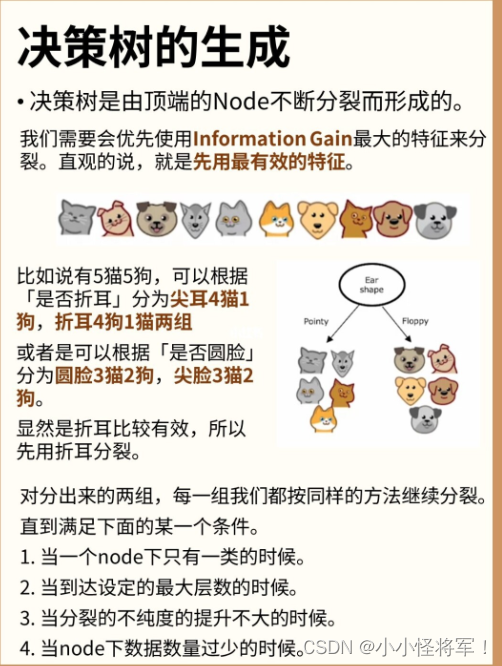
P92 整合 (如何进行决策树学习)

在每一次的拆分前,选择特征信息增益高的进行拆分
p93 独热编码 one-hot
特征值有两个以上的离散值:比如说一个耳朵有折耳,立耳,耷拉耳三种值一样,但我们其中只能有一个为 1 其他同一个特征的其他的值只能为0 ,,,这样我说这是one-hot编码
1 什么是one-hot
在目前学习的特征中都是只有两个离散值的,像猫的脸是圆的或者不是圆的、有胡须或没有胡须等。
如果特征可以采用两个以上的离散值呢?我们可以使用one-hot 编码解决这种特征。
还是以猫狗分类为例,猫的耳朵有3种类型了,尖的、软的或椭圆形的。
初始特征仍然是一个分类值特征,但它可以采用3个可能的值,如果在决策树支点使用这个特征,那么我们就会创建3个子分支。这里有一种处理特征不同的方式,使用one-hot 编码,将这一个特征,变成3个特征。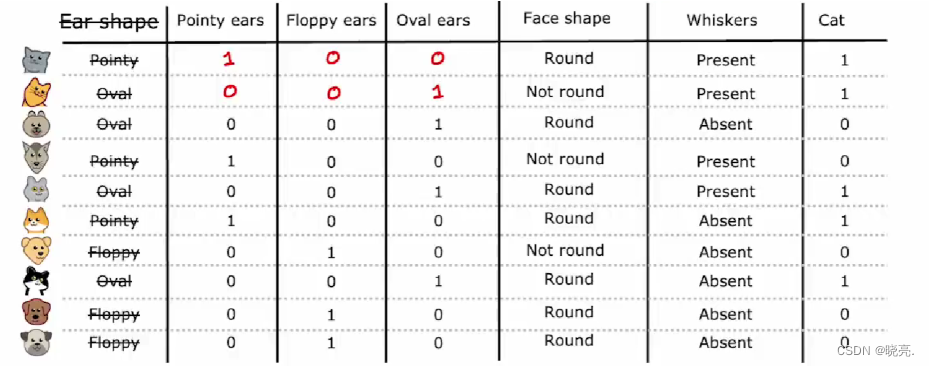
如图,使用one-hot 编码,我们将创建3个新的特征,分别是耳朵是尖的、耳朵是松软的、耳朵是椭圆的。
对于第一个示例,我们之前说耳朵形状是尖尖的,现在我们说这种动物耳朵是尖的值为1、耳朵是松软的值为0、耳朵是椭圆的值为0,以此类推,其他的示例也这样写。
我们现在就是构建了3个新特征,而不是1个特征取3个可能的值,每个特征都可以取两个可能的值0或1。
更详细一点,如果一个分类特征可以取k个可能的值,我们可以创建k个二进制特征(可以取的可能值为0或1)来实现.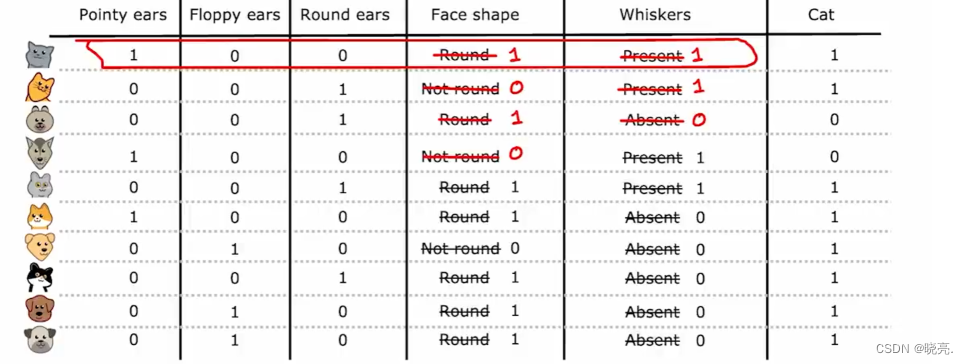
在之前的例子中,我们训练决策树使用one-hot 编码来进行建模 0/1编码分类特征也适用于训练神经网络。
如果我们将脸型和胡须的特征也用0或1 来表示,这样我们就有3个可能的耳朵形状值,1个可能的脸型值和1个可能的胡须值 这5个特征列表。
这5个特征列表可以输入到新网络或者逻辑回归中,来训练猫分类器。
所以one-hot编码时一种不仅仅适用于决策树学习的技术,它允许我们使用0或1对分类特征进行编码,一边它可以作为输入馈送到神经网络,也可以将数字作为输入。可以用于新的网络或线性回归或逻辑回归训练。
P94 连续有价值的功能 00------连续值特征-----one-hot独热编码的应用
我们现在已经会使用一些离散的特征了。
让我们来看看如何修改决策树,使其可以使用连续值的特征(可以是任意数字的特征,不仅仅是0或1)。
如果我们给猫狗分类的例子加了一个重量特征,它是一个连续值的特征,那我们怎么分割这个重量特征呢?
我们可以根据重量是否大于或对于某个值,比如说数字8,然后我们画一条直线,将例子分裂,计算两边的信息增益,选出信息增益最大的一个。
我们一般会尝试x 轴上的多个值,一种惯例是根据权重或根据该特征的值对所有示例进行排序,并取所有训练排序列表之间的中点值,以此处作为阈值考虑值的示例。
如果我们有10个训练示例,我们将针对此阈值测试9个不同的可能值,然后尝试选择可以为我们提供最高信息增益的那个值,它就是连续值的特征。
这里,我们当值为9时,信息增益最大为0.61,假设算法选择这个特征来分割,我们最终会得到两个子集,
然后可以使用递归构建额外的决策树,这两个子集就用来构建树的其他部分。
P95 回归树 (当我们的问题不再是分类问题时,用回归树解决回归问题(一些数字问题,房价)*************没懂ing)
我们目前只学习了作为分类算法的决策树, 如果我们有一个回归问题,我们如何使用决策树来预测数字。
其实决策树可以泛化处理回归问题。
假设我们要使用下图中的3个特征来预测猫或狗的重量(之前是用重量来判别猫狗,这次反过来),来看看怎么使用决策树进行预测数字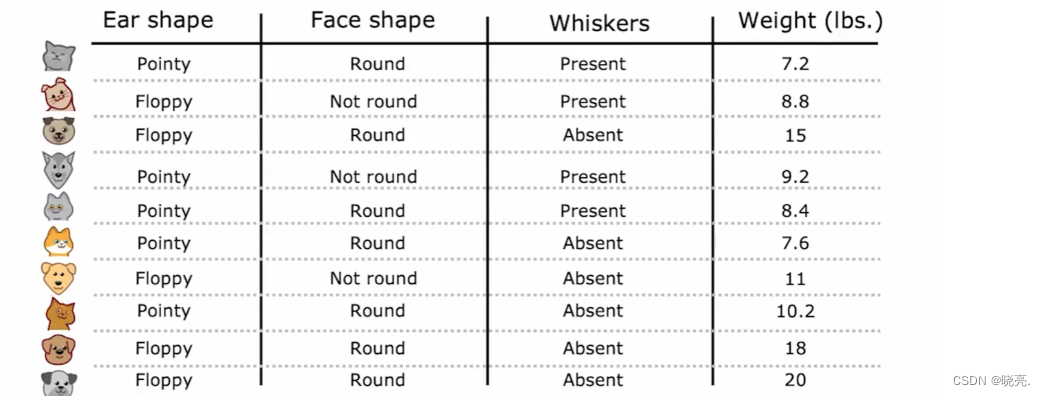
与前面不同,这里我们不是预测动物是猫还是狗,我们的输出目标是一个数字。
首先,我们还是要构建一个决策树,我们将动物分好类了,如何输出权重呢?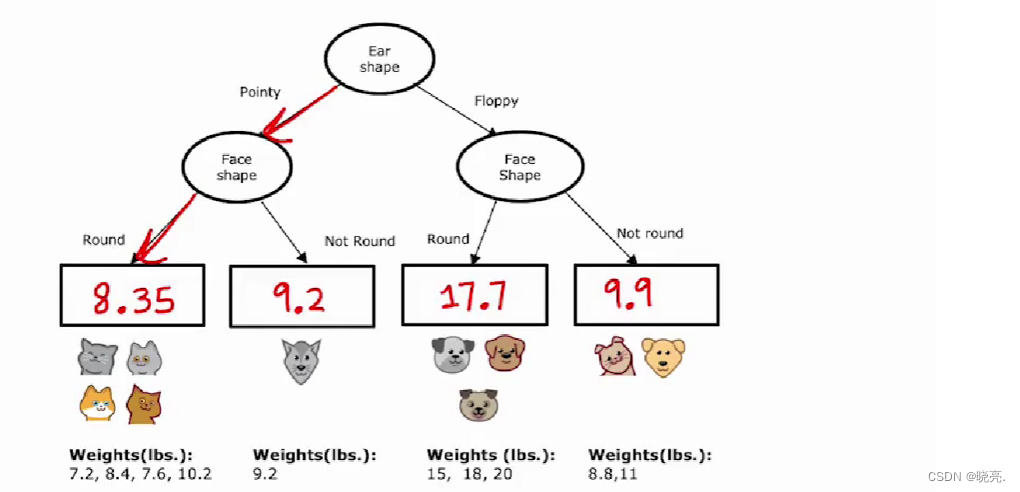
如上图,输入示例,并跟随决策节点,一直到叶节点,如何预测该值(图中红色部分),我们是取每个叶节点示例的权重的平均值作为输出值。这种决策树称为回归树。
让我们回推,来看看每个节点是如何确定所用的特征的。

首先看根节点,我们分别看看3个特征的分类结果,那么怎么确定使用哪一个特征呢?
让我们一个个的看,一般我们会先计算左边分裂的方差,然后计算右边分类的方差;再写出左右分支数量的占比;如何计算加权平均方差,如上图。
这个和我们在决定使用什么分割时使用的加权平均熵的作用非常相似。然后我们继续对其他的特征计算这个加权平均方差。在回归树中,选择拆分的一个好办法时只选择最低的加权平均方差值。类似于我们计算信息增益(其实就是熵的减少),所以我们也可以进一步计算方差的减少,拿根节点的方差20.51 (怎么来的????)减去其他的,如图。
结果如图,第一个结果的方差减少的最多,所以它就是我们需要的特征。
总结计算方法
- 首先收集各个被分配下来样本的权重,通过对这些权重计算方差,得到variance方差。
- 在这些方差前面加上wleft,Wright 权重;
- 最后通过计算跟结点方差与权重处理后的子节点方差的差,选取合适的分支特征。
*使用多个决策树P96-P99
P96 使用多个决策树
为什么要使用树集合:单个决策树的缺点之一是该决策树可能对数据中的微小变化高度敏感,为了解决这个问题,我们通常构建多个决策树,称之为树集合。
来举例说明,如下图,我们之前在根节点处使用的特征是耳朵的形状,它具有最高的信息增益。
如果我们将数据集中的一个狗改成猫呢?在这个根节点的使用的特征就会改变为是否有胡须,因为这个特征现在具有最高信息增益。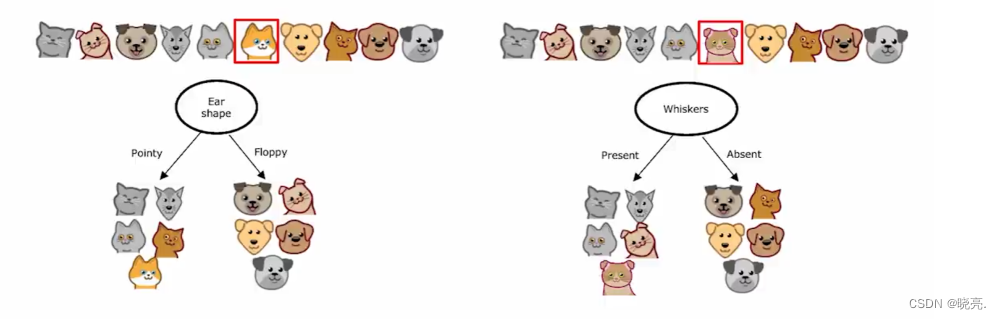
这就是为什么说 单个决策树可能对数据中的微小变化高度敏感,
改变一个训练示例就会使得算法有所改变,显然这个算法不那么稳定。
所以我们通常会训练多个决策树来解决这个问题,也就是训练一个树集合。
当我们有一个树集合,那么每一个决策树都可能是一种对猫或不是猫进行分类的合理方法。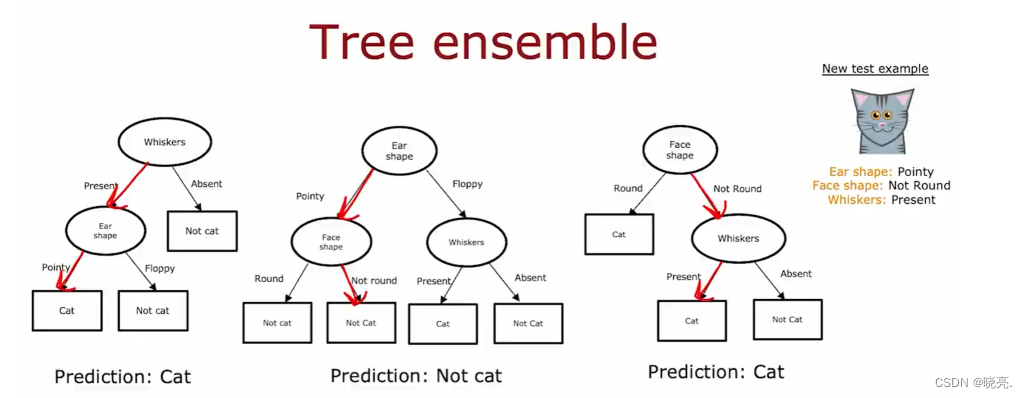
如果我们有一个新的示例想要进行预测,那我们要做的就是在新示例上运行所有的决策树(图中是3个)
让它们共同决定哪个是最终预测结果,3个决策树都对新示例进行了预测,其中2个预测是猫,一个不是,3个决策树“投票”,结果是猫的可能性较大,所以预测结果就是猫。
P97有放回抽样 ----(构建树的集合)
为了构建树集合,我们需要一种技术,称为有放回抽样。
如果有10个训练示例放在一个箱子里,每次取样都是随机拿出一个样本,再放回,再随机拿出一个样本,直到我们拿到10个样本,这其中可能有重复的,这个训练集也可能不包括10个原始的训练示例。这就是带有替换程序的抽样的一部分。
带放回抽样,可以让我们构建一个新的训练集,这是构建树集合的关键。
P98 随机森林
随机森林的目的就是要通过大量的基础树模型找到最稳定可靠的结果,最终的预测结果由全部树模型共同决定。采用二重随机,每次随机采用不同特征进行建树。将所有的树模型组合在一起。在分类任务中,求众数就是最终的分类结果;在回归任务中,直接求平均值即可。
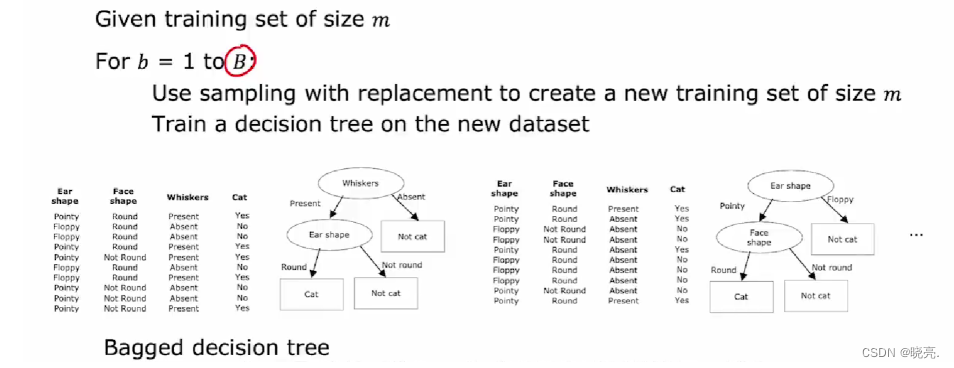
如上图,如果我们有一个训练集大小为m,我们将使用带放回抽样,创建一个大小为M的新训练集(有些是重复的没有关系)。
然后在新的数据集上训练决策树,这样我们就会得到一个决策树。
然后在使用带放回抽样来生成另一个训练集M,在这个新的数据集上训练决策树,我们会得到另一个决策树。
以此类推,构建出多个决策树(B个,在64-228左右),比如说我们构建了100棵不同的树组成的集合,然后当你试图做出预测时,让这些树共同决定预测结果。事实证明,当训练的决策树太多时,远大于100,它实际上不会取得更好的效果,反而会减慢计算速度,而不会显著提高整体算法。
对这个算法进行更改,尝试随机化每个节点处的特征选择,这可能导致树集合预测的更准确。
具体做法就是:如果我们有n个特征可以选择,我们会创建一个含有k个特征的随机子集。
当我们在节点要选择特征进行拆分时,我们会在子集k中随机选择一个信息增益最高的特征进行拆分。
如果n很大时,几十或几百时,k值一般会取n的平方根。
P100何时使用决策树
决策树、树集合与神经网络是非常强大、非常有效的学习算法。
决策树阐述:
决策树或树集合通常用于表格数据,也称为结构化数据。像房价预测,有房子大小、房间数等多个特征。决策树或树集合一个优点是它们的训练数据非常快。小型决策树我们可以解释的,可以了解它是如何做出决策的。如果我们决定使用决策树或树集合,那就有很大可能使用XGBoost 算法来处理大多数应用程序。
神经网络阐述:
神经网络可以处理非结构化数据任务,像图像、视频、音频和文本等。对于神经网络,与决策树和树集合相比较,它适用于所有类型的数据,包括表格或结构化数据以及非结构化数据,包括结构化和非结构化组件的混合数据也可以处理。神经网络通常用于处理非结构化数据任务,像图像、视频、音频和文本等。对于表格结构化数据,神经网络和决策树都可以解决,而在非结构化数据任务,像图像、视频、音频和文本等问题中,神经网络还是首选。
二者相对比:
缺点:是神经网络可能比决策树慢。
优点:是神经网络可以和迁移学习一起使用,这点非常重要,因为对于许多应用程序,我们只有一小部分数据集,可以使用迁移学习并进行预训练一个更大的数据集。可以将多个神经网络串联起来,构建一个更大的机器学习系统。因为神经网络输入x后 将输出y计算为平滑或连续的函数,即使我们有很多不同的模型,都可以使用梯度下降同时训练它们。对于决策树,一次只能训练一颗决策树。
结论:如果我们正在构建一个由多个机器学习模型协同工作的系统,串联起来训练多个神经网络可能更容易,而不是使用决策树。
第二大部分 无监督学习
P102 什么是聚类
前言:
聚类( clustering )是一种典型的“无监督学习”,是把物理对象或抽象对象的集合分组为由彼此类似的对象组成的多个类的分析过程。K-means 算法是就是比较经典的聚类算法,使用较多,本文主要讲解了什么是K-means 算法及其原理。
聚类 clustering
聚类算法着眼于数据点的数量 和自动查找彼此相关 或相似的数据点。聚类算法是一种无监督的学习算法。回想一下我们之前学的用于二元分类的监督学习。如下图:
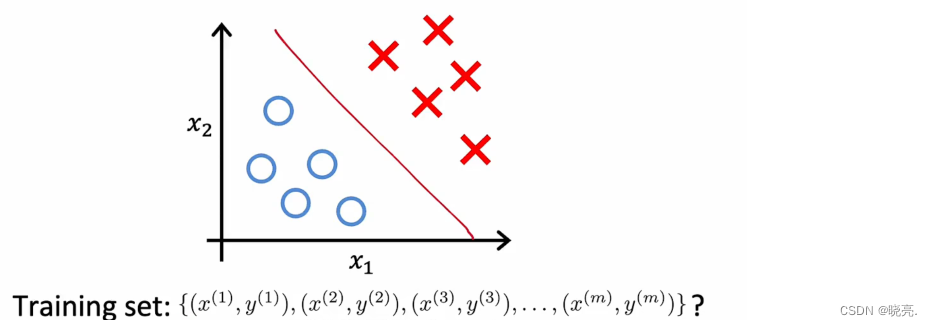
给定一个具有特征x_1 和x_2 的数据集,通过监督学习,我们有一个训练集,输入特征x 以及标签y 。我们可以绘制出数据集并拟合逻辑回归算法 或用一个神经网络来学习这样的决策边界。在监督学习中,数据集既包括输入x,也包括目标输出y 。
上面讲的是监督学习,现在来看看无监督学习unspervised learning,无监督学习中,给定的数据集,只有x ,而没有标签y 。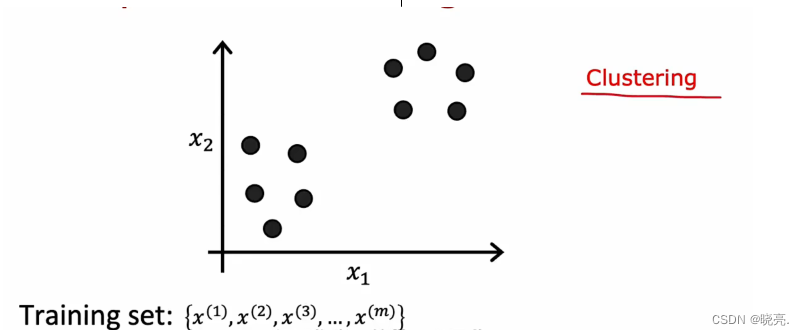
我们要求算法找出有关数据的相关联的内容。
聚类算法clustering 就是一种无监督学习的算法,它会找到数据的一种特定类型的结构。给定像上图这样未标记的数据集(只有x), 算法就可能会找到有关数据的特定结构,它会查看数据,并尝试查看是否可以将其分组为集群,表示彼此相似的点组,可能会将数据分为两类。
应用:聚类算法的应用有很多,像把类似的新闻文章放在一起,将学习者进行分类等。聚类也被应用于分析DNA 数据。
P103 K-means直观理解
P104 K-means 聚类算法公式
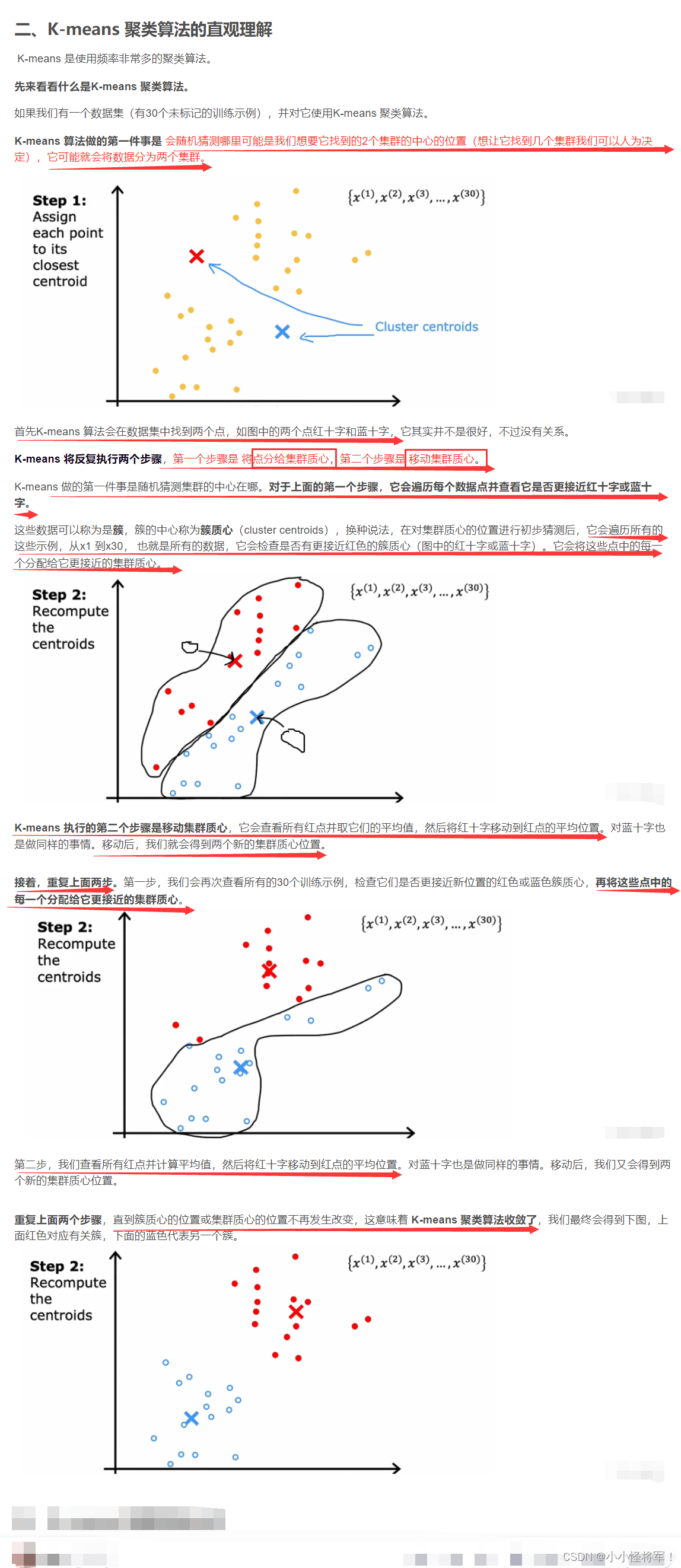
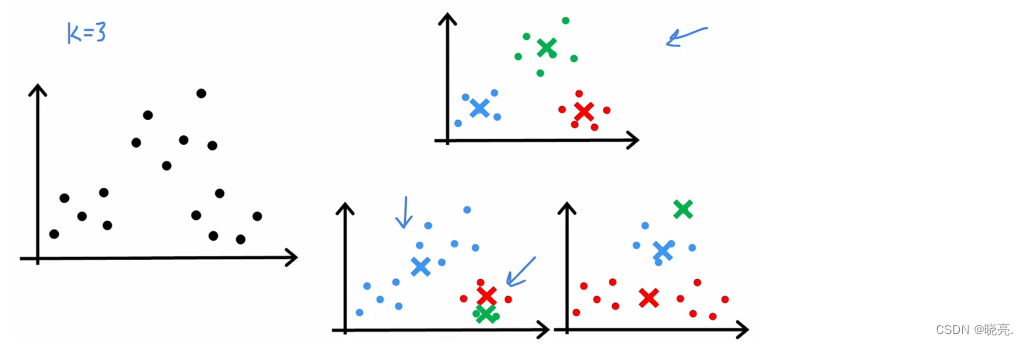
我们现在知道了 K-means 聚类算法就是干两件事。
第一件事,初始化K 个簇质心,μ1,μ2一直到μK。(相当于前面所的随机选择的红十字和蓝十字)前面的例子中分为两个簇质心,也就是红十字和蓝十字,那就可以用μ1,μ2来表示了。(假设红十字是μ1,蓝十字是μ2)
注意:μ1,μ2具有与训练示例相同的维度。我们的30个训练示例中,都是两个数的列表,或者说是二维向量,因为对于每个训练示例,我们有两个特征X1、X2。其中μ1,μ2也是二维向量(表示其中包含两个数字的向量,若训练示例中是三个特征xyz,则u1,u2簇质心也是包含三个特征)。
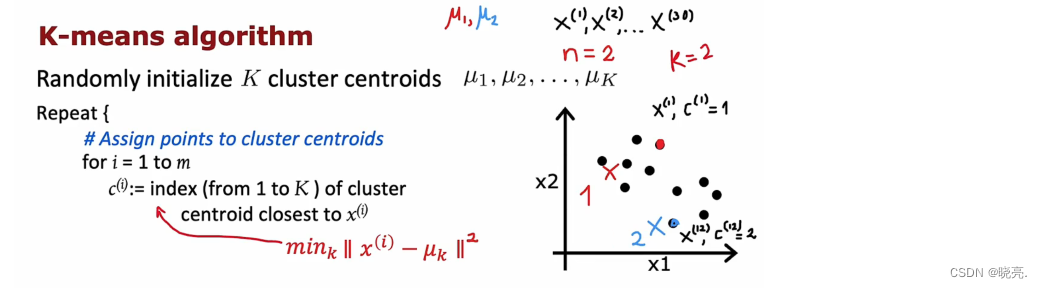
******* C_i是距离u1或者u2质心最近的点的索引值。
第二件事, K-means 将重复上面提到的 两个步骤 将点分给集群质心,再移动集群质心。
1 、 将点分给集群质心,对每个训练数据根据离 簇质心 的距离进行分类(红色或蓝色)。每个训练数据点x 与质心μ 的距离,也被称为L2 范数。我们想要的就是找到这个最小化这个距离 K 。然后将最小化的K值设置为图中的C_i, 其实这个距离 更方便的是写成平方距离,最小化平方距离与最小化的簇质心是相同的。
2、移动集群质心,计算所有红点的平均值,水平轴平均值、垂直轴平均值,两条的交点就是更新后红色簇质心的位置。对蓝色的簇质心也是相同的操作。
- for i= 1 to m 是指将m个特征点中选最小距离的点分配给簇点
- for k= 1 to k 是将已分配出来的点 累加起来进行计算 中心点,然后将质点移动过去 u1是个质点
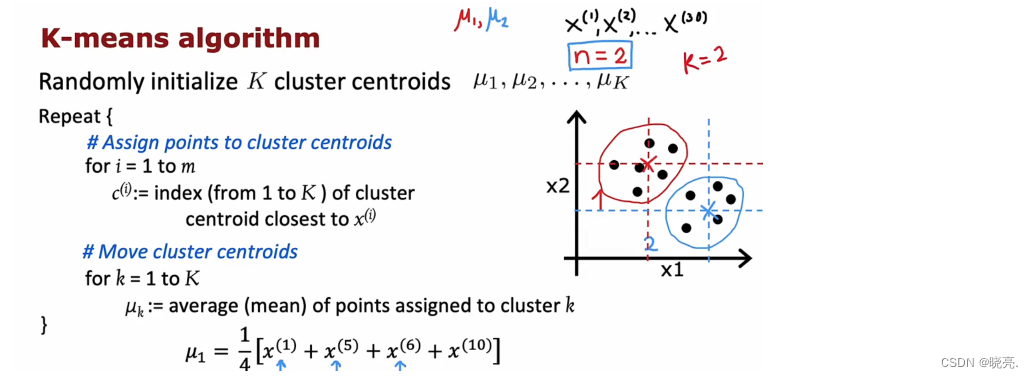
如果第一个红色集群已经分配了训练示例x1,x5, x6, x10 ,计算平均值的公式如上图所示。(这里我们有两个特征,所以我们的μ 中有两个数字也就是二维向量,如果我们有n 个特征,那么我们的μ 就有n 个数,是n 维向量。)
出现特殊情况的解决方法:
1.如果示例出现极端情况,训练后,一个集群里面有0个训练示例,那么算法会在第二步计算0 的平均值。这种情况我们一般会直接取消该集群,最终会得到K-1 个簇(这是常见做法)
2.如果需要K个簇,那么一个方法就是重新初始化该集群的质心,使得它在下一轮的循环中得到一些训练示例。
除了上面说的,K-means算法也可以很好的处理集群没有很好分离的数据集。比如说将一堆连着的数据进行分类(比如说x轴身高和y轴体重的关系)。
P105 K-means 聚类算法的优化目标(失真函数J)
首先先了解一些变量代表什么:
Ci --------------------------簇划分为( C 1 , C 2 , . . . C k )
μi --------------------------是簇 Ci 的均值向量, 有时也称为质心
μ_ci -------------------------是指已经分配训练示例xi 的集群质心的位置。

上面就是 K-means算法的代价函数,我们需要的就是最小化的平方距离,也就是最小化代价函数。这里的代价函数它也叫做失真函数 distortion。
下面我们来进一步的学习这个失真函数 J
K-means的第一部分表示将训练数据点分配给集群质心的位置,也就是改变c1,c2…cm 来降低失真函数 J。 具体来讲,就是让每个数据点选择离自己最近的一个聚类中心。像图中的黑点,它就会选择红十字。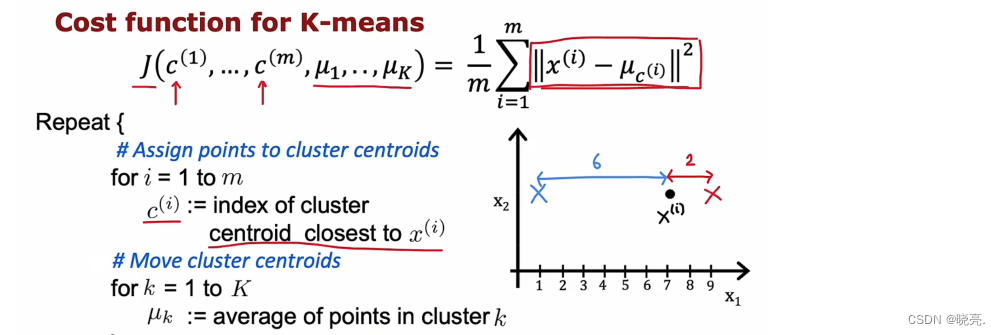
第二部分就是移动集群质心位置。K 中的每一步都在设置值c_i 和 μ_k 来试图降低代价函数。
P106 初始化 k-means---------选择随机位置作为集群质心*******没看懂
K-means 聚类算法的第一步就是选择随机位置作为集群质心。
为了选择集群质心,最常见的方法是随机选择k 个训练样例。这与前面提到的有些不同,前面是随机选择初始的集群质心,现在是随机选择训练样例。
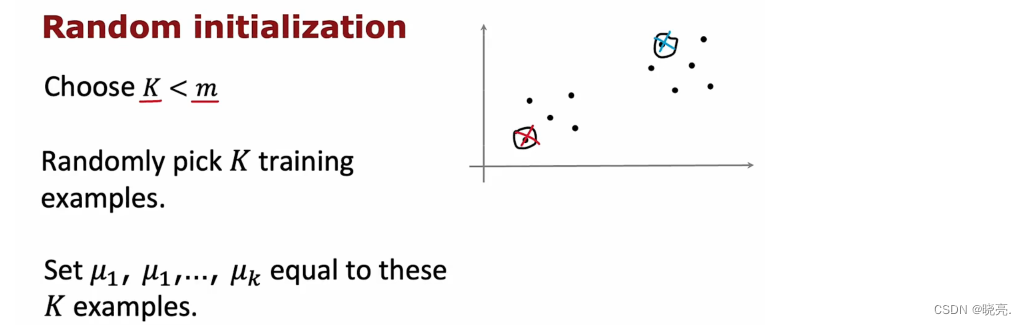
通常情况下,我们会在m个样本中选择K个(K<m)来作为初始化的聚类中心。但是,如上图所示,不同的初始化有可能引起不同的聚类结果,能达到全局最优(global optimal)固然是好的,但是,往往得到的是局部最优。
选择的是随机选择训练样例作为初始的集群质心 虽然比 随机选择任意点作为初始的集群质心要好。但是,这一会出一些问题,如图,它可能出现局部最优值。(这次我们不是随机选择质心,而是随机选择 训练样本)
这种效果不好的情况,我们就要运行多次,来找到最佳的局部最优值,如图中的3种,我们可以选择最上面的那个来为我们提供代价函数 J 的最低值。
将上面思想写成算法
假设我们想使用100 个随机初始化 K-means, 那就会随机初始化运行100次,
首先随机选择一个示例位置作为初始的集群质心,计算代价函数,运行100次,选择最小的代价函数值。(一般这个次数在50-1000这个范围都合理的)
这就是为什么我们一般会使用多个初始化,因为会计算出多个最小化代价函数,可以为集群质心找到更好的选择。
P107 选择聚类数量K (选多少个集群呢)
K-means 算法需要k 作为其输入之一,也就是我们希望它找到的集群数量。
如何来选择k 的值呢,有人提出使用elbow 方法,也就是肘部方法,他的意思就是将代价函数看成是集群数量的函数,看看曲线是否有弯曲,如图,k = 3 是个转折点,k 大于3,代价函数就下降的很慢了,所以就选择k= 3,因为形状看起来很像肘部,所以就被称为肘部算法了。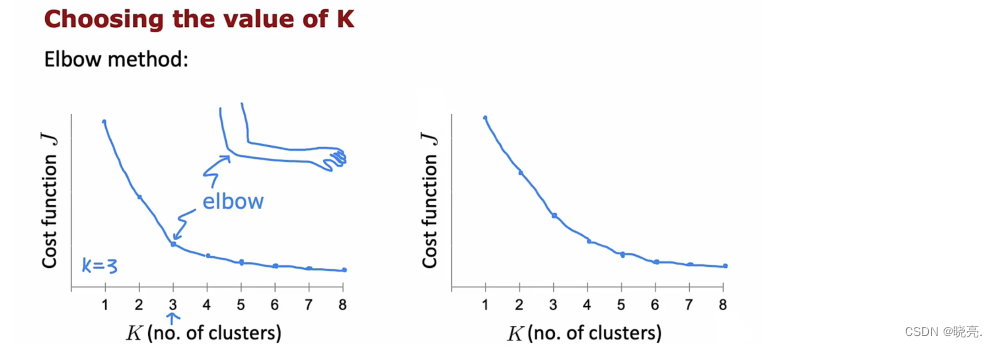
但是这种方法有局限性,如果代价函数下降平滑,就像右边的图,我们就找不到任何的肘点了。
注意:使用k 来最小化J 也是不行的,因为代价函数J 的值会随着k 越多而越小的,所以这种方法不可取。
那么我们该如何选择需要多少个聚类数量K 呢?
下图为服装衣服的尺寸大小选择
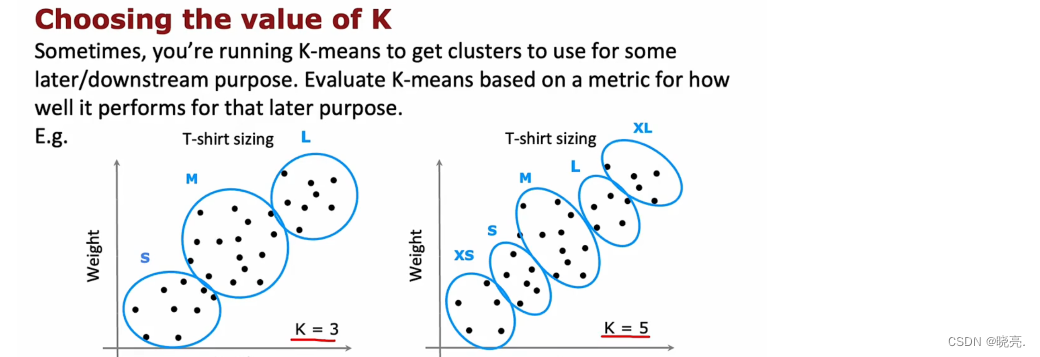
如图中的例子,我们可能会纠结K = 3 还是5,一般情况,我们会运行这两种情况,权衡各种因素,来选择使用哪个。
k-means 的应用很广泛,它还可以使用在图片压缩方面。
第二个无监督学习 异常
P108 发现异常事件
异常检测算法 finding unusual events 也是比较常用的 无监督算法
异常检测算法查看为标记的正常事件数据集,从而学会检测,如果发现异常事件会发出危险信号。
以检测飞机发动机质量为例,我们可以计算飞机发动机的许多不同的特征,
假设特征x1 测量发动机产生的热量,特征x2 测量发动机震动强度等…我们这里就以这两个特征为例,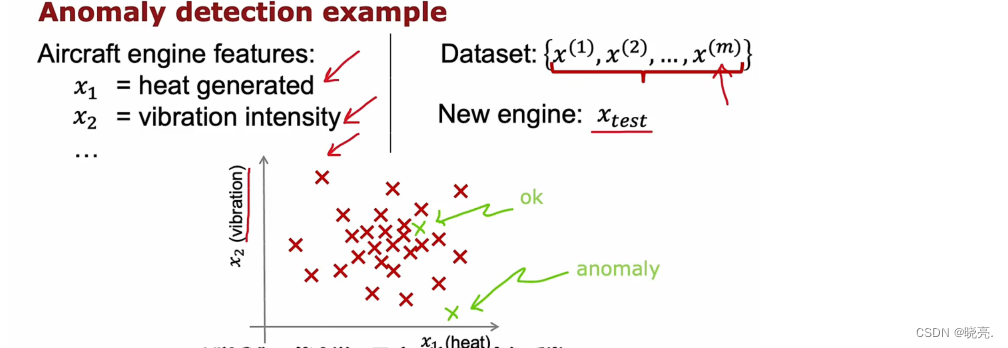
如图,如果新生产的发动机在两个特征图上数据比较密集的地方,我们通常会觉得它没有问题,如果它在比较偏的位置,如图中下边的点,我们会觉得这个可能会有问题,从而再检查一下这个发动机。
2 我们怎么可以使用算法来处理这个问题呢?
执行异常检测最常见的方法是通过一种称为密度估计的技术,
这也就意味着,当我们得到 一个含有m 个样本的训练集时,我们要做的第一件事就是为x 的概率建立一个模型 P(x)。换句话说,也就是学习算法将尝试找出具有高概率和哪些值在数据集中出现的可能性较小(概率较低)的数据。
如上图所示,数据越密集的地方概率也就越大。
我们已经建立了一个概率模型P(X) ,当获得新的测试示例 Xtest时,我们要做的就是计算Xtest 的概率,如果Xtest的概率小于 ε epsilon(我们设置的某个阈值),我们就可以将 Xtest 标记为异常anomaly; 如果Xtest的概率大于 ε epsilon(我们设置的某个阈值),我们就可以将 Xtest 标记为正常。
P109 高斯正态分布
在应用异常检测时,我们需要使用高斯分布 Gaussian distribution,也称为正态分布 normal distribution. 也叫做钟形分布 bell-shaped distribution 。
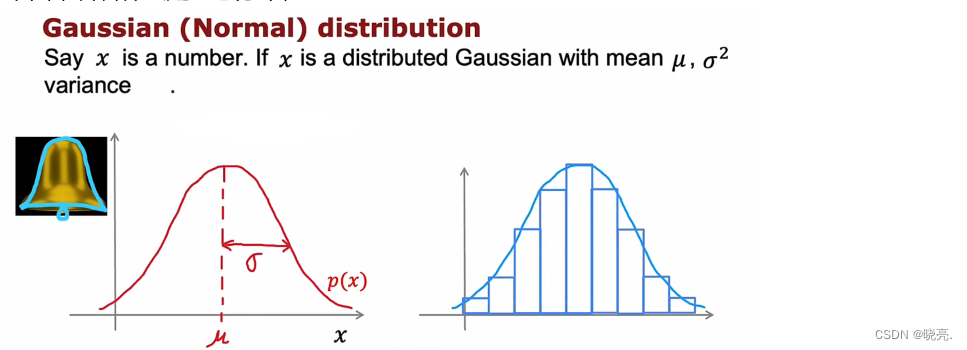
如果x 是一个随机数,有时称为随机变量,使用正态分布来表示x,如图曲线的最高点由x的均值 μ决定,该曲线的标准偏差或宽度由该方差参数σ 决定( sigma)。σ被称为标准差和平方差,这条曲线就显示了P(x) , 因为看起来像钟,所以也叫钟形分布。
下面,就是正态分布的公式:
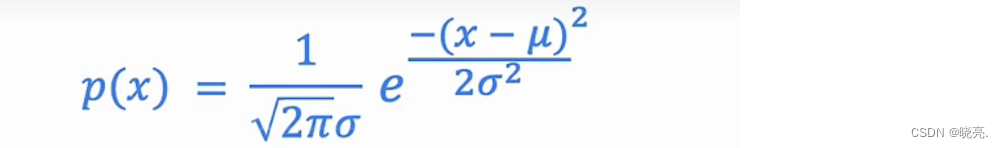
来看看改变μ 和σ会对正态分布有什么影响。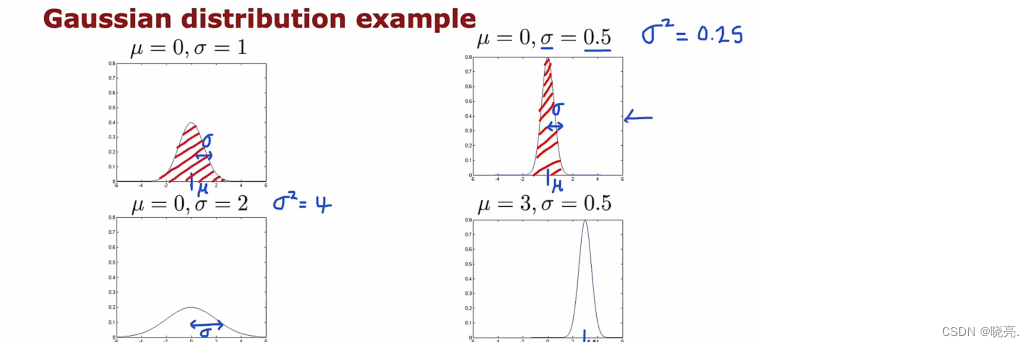
可以看见,正态分布的图是由μ和σ着两个参数决定的,μ表示中间点,σ表示曲线的宽度,由于概率之和为1,所以σ越小,曲线会变高,保持面积不变。
当我们将正态分布应用在异常检测时,我们要做的也就是计算平均参数 μ和 方差参数σ平方,计算 σ平方 时,除以m 或 m-1 结果都不会有太大的区别,所以我们用的时候,直接除以m 也是可以的。 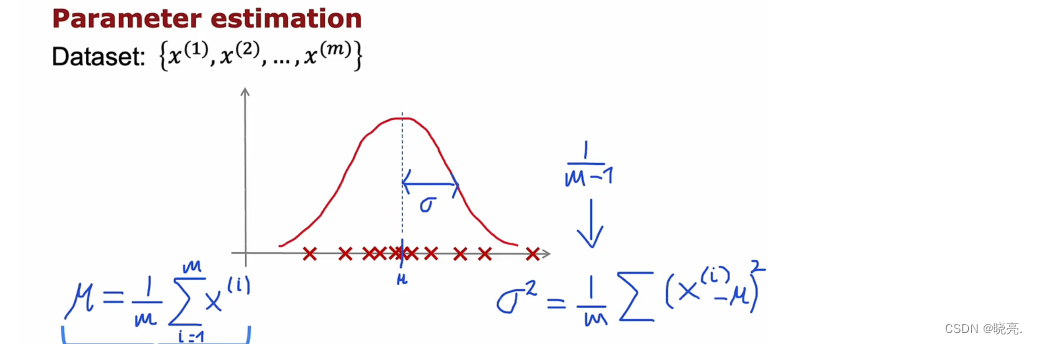
P110 异常检测算法 -----------(密度估计=P(x)各种概率相乘)
我们知道了可以将正态分布应用在异常检测中,但是只是单个特征,如果我们有多个特征呢,怎么将正态分布应用在异常检测中。
如果我们有 m 个训练示例,如果我们有多个特征,那么每个示例都是一个向量。在飞机发动机的例子中,我们有两个特征,因此每个示例都是一个二维向量。但实际上使用的使用的时候可能是多个特征,如果有n 个特征,那么示例就是n 维向量。
有了数据集,我们想做的是密度估计,这意味着我们将建立一个模型来估计P(x) 概率。
我们的P(x) 模型将如图所示,X 是一个 特征向量,那么它的概率P(x) 就等于每一个特征的概率相乘。为什么要将每个特征的概率相乘?这是计算它们同时发生的概率,图中有个例子,如果飞机发动机发热的概率是1/10 , 震动的概率为1/20 ,那么这个发动机既发热又震动的概率就为1/200.
有了上面的基础,我们来看看什么是异常检测算法。
第一步是选择,我们认为可能是异常示例的特征 x_i;
第二步, 在提出要使用的特征后,我们将计算参数μ1到μn,σ1平方到σn平方,用于数据集中的n 个特征。
第三步,当有一个新的例子的时候,计算P(x) 并查看它的大小。使用我们设置的阈epsilon ε,进行比较。如果小于阈值,则标记为异常。
在这个过程中,每一个特征xj 都在拟合高斯分布,只要有一个特征的概率非常小,那么一乘,它对应的概率P(xj) 也会非常小。
异常检测在算法中所作的是一种系统化的方法来衡量这个新示例 x。具有任何差异大或差异小的特征。让我们来看一下这在1个示例中的实际意义。
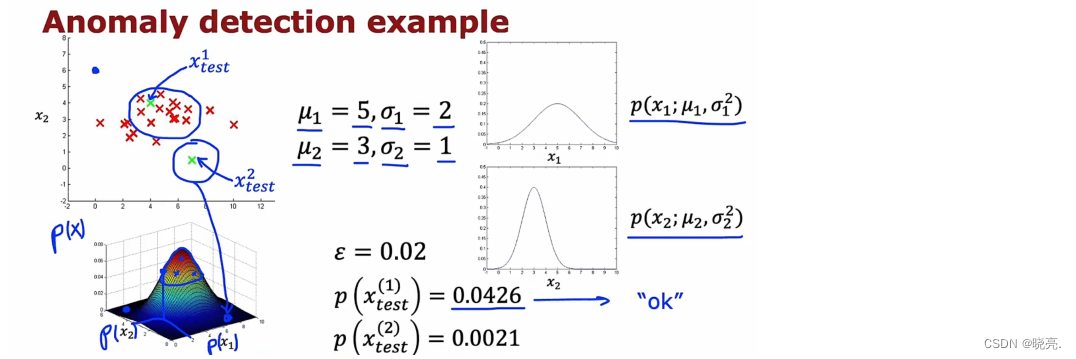
如图,x1 的取值范围比 x2 要大得多,如果我们要计算特征x1 的两个参数,我们最终会得到如图所示的参数。计算出两个特征的概率,相乘后会得到一个3维的图,其中高度就是两者的乘积。
如果给了两个测试数据,ε设置为0.02,那么结果如图,很明显第一个测试数据正常,第二个异常。

P111 开发和评估异常检测系统
如何评估算法呢?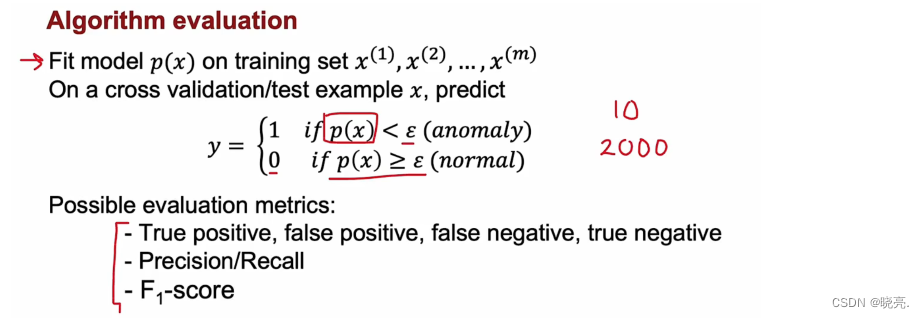
我们将首先在训练集上拟合P(x) 模型 ,然后在交叉验证数据集上和测试数据集上进行预测。
设置阈值epsilon,如果小于ε 则输出1,表示异常;如果大于ε 则输出0,表示正常。
然后来评估算法的精确性,评估的方法也是统计预测的准确性,使用精确率、召回率、F1-score 等之前学过的方法。11.4 查准率和召回率的权衡(F值:更强调这些值中较低的值,制约查准率和查全率的一方偏向)
注意:1 这里评估的数据集没有标签,所以还是无监督学习。
2 交叉验证集和测试集中应该都含有异常值,正常情况下交叉验证集和测试集都需要的,但是如果数据较少时,异常值很少,那么我们会只要应该交叉验证集来进行测试。
P112 异常检测与监督学习对比
 什么情况下,能让我们把某个学习问题当做是一个异常检测,或者是一个监督学习的问题?
什么情况下,能让我们把某个学习问题当做是一个异常检测,或者是一个监督学习的问题?
对于一个学习问题,如果正样本的数量很少,甚至有时候是0,也就是说出现了太多没见过的不同的异常类型,那么对于这些问题,通常应该使用的算法就是异常检测算法;而如果正负样本数量都很多的话,则可以使用监督学习算法。例如,如果网络有很多诈骗用户,则可以变为监督学习;如果只有少量诈骗用户,则为异常检测。
P113 异常检测中的特征选择
在构建异常检测算法时,选择一个好的特征非常重要。
在监督学习中,如果我们没有一个完全正确的特征也是可以的。但是在没有标记的数据中学习异常检测,异常检测算法将会更难找出想要忽略的特征。所以仔细选择特征对异常检测非常重要。
可以帮助异常检测算法的一个步骤是,尝试确保您为其提供的特征尽可能多的是高斯特征,或者说接近高斯分布如果特征不是高斯特征,我们有时也可以更改它使其变的像高斯特征。
下面来具体看看。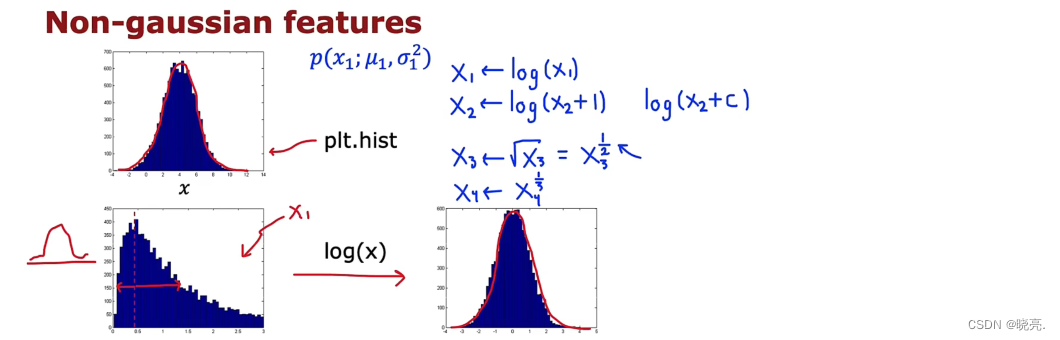
如果我们有一个特征X ,我们需要的是像高斯分布的特征,如果它不是这样时,首先考虑是否需要使用它,如果要使用,我们可以对其进行运算,如图左下角的特征,对它进行运算log(x) 可以得到右边的特征,它看起来符合高斯分布了,使用更改后的模型,更有可能很好地拟合数据。
除了使用log(x) , 也可以对其做一些其他变化,例如log(x + 1) 等,让变化后的特征符合高斯分布。
特征选择:
1、总结一下,如果我们构建异常检测系统时,可以提前看一下特征,如果通过绘制plot( plt.hist() ) 图,如果看起来不像高斯分布,我们可以对其进行转换,尽量的让它更像高斯分布。
2、除了确保我们的数据近似高斯之外,如果我们训练了异常检测算法后,在验证数据集上效果不佳,我们还可以执行错误分析过程以进行异常检测,换句话说,就是可以在出错的时候尝试查看算法在哪些方面做的不好,然后尝试提出改进。
在异常检测中,我们想要P(x) 很大,对于正常示例X ,概率大于阈值ε;对于异常示例X ,概率小于阈值ε。
3、我们还可以通过将一些相关的特征进行组合,来获得一些新的更好的特征(异常数据的该特征值异常地大或小),例如,在检测数据中心的计算机状况的例子中,我们有四个特征:x1:内存使用量; x2:磁盘的容量;x3:CPU的负载程度;x4:网络流量,我们可以用CPU负载与网络通信量的比例作为一个新的特征x5,如果该值异常地大,便有可能意味着该服务器是陷入了一些问题中,算法便可以捕捉到这一异常值。
第三部分 推荐系统
p115 推荐系统的特征使用
1 什么是推荐系统算法
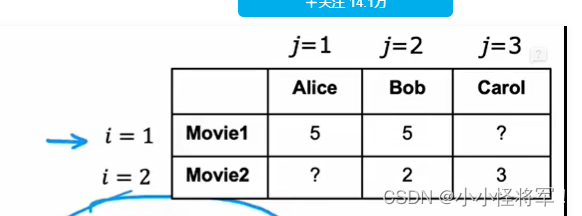
当我们进行网上购物时,网站会根据我们浏览的物品,从而给我们推荐我们可能想要购买的物品,这个就是推荐系统。让我们来看看如何开发一个推荐系统,以推荐电影为例。
我们有一个数据集,4个用户对 5部电影的评价,我们有电影的两个特征,浪漫电影和动作片,放入表格,如下图。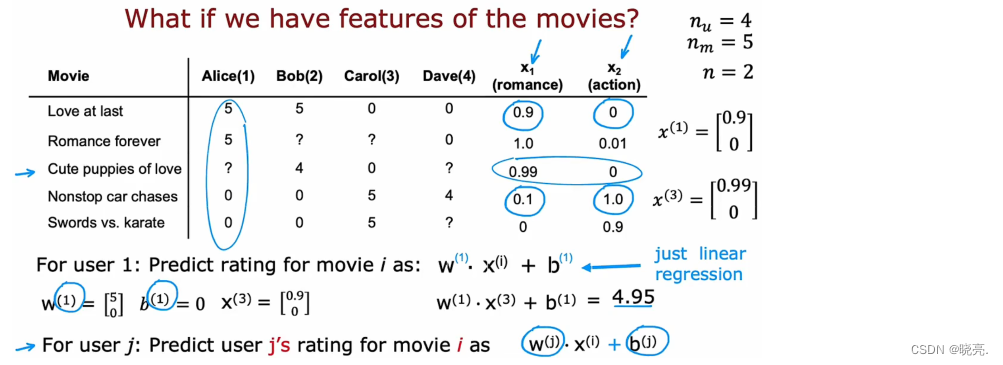
- 使用n_u 表示用户数, m_u 表示电影数,n 表示有几个特征。则 n_u = 4, m_u = 5, n = 2.
如果我们想预测用户1 Alice 对第三部电影的评分,结果如图,可以写出一个很像线性回归的公式。将各个参数带入,得出的结果是0.49,这就是算法预测的结果。可以将这个公式进行推广,用户J 对电影 i的评价,公式如图下角。
电影 i是X(i) 的函数(i代表第几部电影),X(i) 是电影 i的特征。
注意,这个公式看起来很像线性回归,但是对于4个用户来说,它们会有4个不同的公式。
2 如何为这个算法计算代价函数
- r(i,j) 表示用户j 是否对电影 i进行评分,如果评分了 值为1,没有评分值为0. ------布尔值
- y(i, j ) 表示 用户j 对电影 i给出的评分
- w(j),b(j) 是作为用户j 的独有参数
- X(i) 作为电影i的特征向量
- 预测的评分公式就是 w(j)*X(i) + b(j)
- m(j) 表示用户j 评分的电影数量(用户j评价了3部电影)
我们要做的就是在给定数据的情况下学习参数w(j)、b(j)
使用代价函数可以写成均方误差标准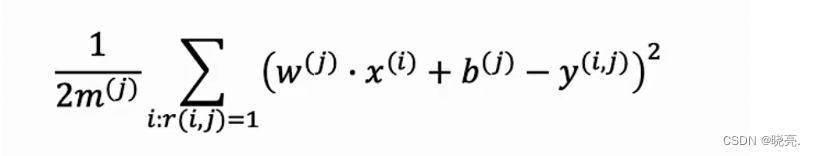
注意这个公式,因为用户没有给所有的电影进行评分,所以我们计算的 代价 只对用户j实际进行行评分的电影i进行求和(做出评分的人求和),且当r(I,j) = 1 时 ,对i的值求和。最后使用1/2*m(j) 进行归一化。
这个就是计算参数w(j)、b(j) 的公式了,为了防止过拟合,我们还会加上 正则化参数lambda 项,如下图。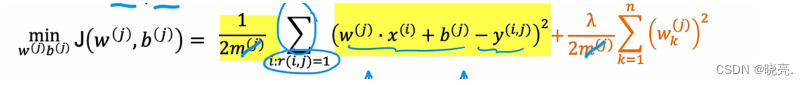
其中的m(j )项可以消去,对求参数也不会有任何影响。
学习所有用户的参数公式:
总的来说代价函数为下图所示:
P116 协同过滤算法(难)***********************不懂
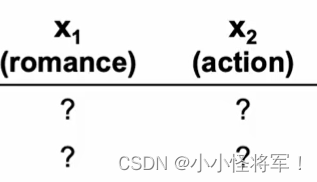
有了计算参数w,b的代价函数,但是这个公式是需要特征Xi的。每部电影都有特征(浪漫,科幻),但是如果我们没有特征怎么来计算这些参数呢?
回到先前的例子,我们不知道特征的值是多少,假设我们知道参数的值w(j)、b(j),那么就可以使用公式来计算特征的值了。Xi为电影的特征值!X^1代表电影1的特征值, X^2代表电影2的特征值,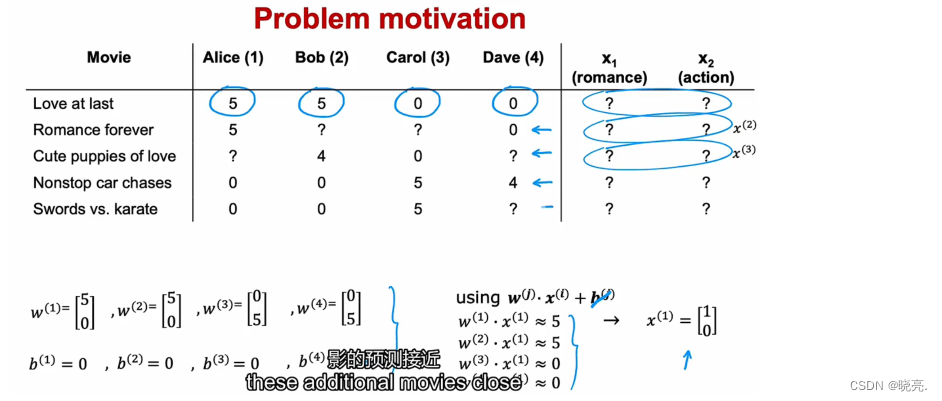
这里为了方便,将b(j)都设置为0,可以看见,带入公式,我们可以算出特征值。
为此,我们可以创建一个代价函数来学习特征值X。
注意,可以这样做是因为,在协同过滤中,同一个项目有多个用户来评价同一部电影。我们有4个用户的参数,允许我们去尝试猜测特征的值。而线性回归中这样做是不行的,因为线性回归我们只有一组参数,也就是相当于一个用户的参数,我们没有足够的信息来计算特征的值。
n_m 部电影 电影 i k~n 电影的特征值 (x_k)^i代表电影i 的特征
所以,只要给定参数,我们可以利用参数构建代价函数来学习特征的值,如上图。
注意,上面求特征的值的代价函数可以使用 的前提是 需要我们提前给定参数w和b 的,那这些参数怎么来呢?
我们可以将特征x也看成参数,将w(j)、b(j)、x(i) 3个参数放在一起求,具体做法就是将两个代价函数相结合,如图,这就是协调过滤算法!!!!!
- 第一个函数是对所有人的w,b的代价函数的学习 使用n_u 表示用户数
- 第二个函数用户j对m个电影的特征值的代价函数的学习 使用n_m表示电影数
- (第一个函数和第二个函数分别用不同的累加方法来求wb和x的)
- 第三个函数是通过对 电影i和 用户j的总和,来学习w\b\x的总体样本函数
注: k~n代表特征值或参数w,

有了代价函数了,那么如何最小化代价函数来求得合适的参数呢?我们可以使用梯度下降来计算。
与线性回归的梯度下降类似,我们可以写出梯度下降的公式。
小结:
我们得出的平均值称为协同过滤,协同过滤就是指,因为多个用户合作,评价了同一部电影,我们可以借此来猜测适合电影的特征,而这又反过来允许我们预测用户对 尚未评价的同一部电影 进行评价。
协同过滤就是从多个用户那收集数据,用户之间的这种协作可以帮助我们预测未来甚至其他用户的评分。
P116 二进制标签
推荐系统或协同过滤算法的许多重要应用都涉及二进制标签。
我们知道二进制标签相当于二分类问题,如何使用泛化方法,将模型从线性回归到逻辑回归,再进行预测。
在前面的预测用户对电影评分的例子中,我们使用的模型很像线性回归,这里我们要处理逻辑回归中的二分类问题,所以我们的预测模型也要做出改变。
有了模型后,为了构建这个算法,我们还必须改变平方误差来改变代价函数,使得代价函数更适合逻辑回归模型的二进制标签的代价函数。
根据我们前面使用的代价函数,可以写出二进制标签的代价函数,如图(其中代价函数是用户和电影i 的求和)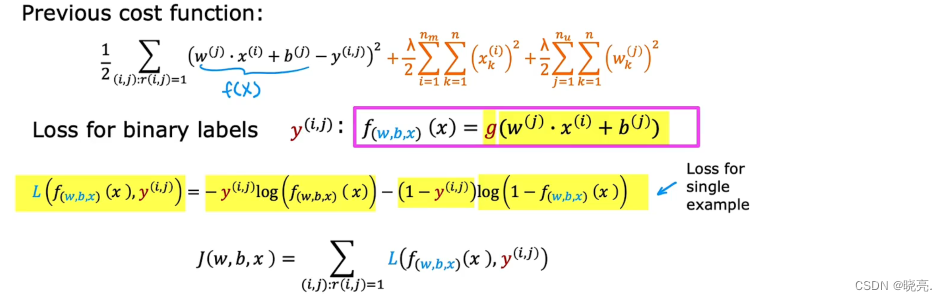
图中黄色部分的损失函数也被称为二元交叉熵损失函数。
P118 均值归一化处理 (针对于很少电影数量的评价处理过程,结果为电影评价的均值)

如果我们在这个数据上训练一个协调过滤算法,通过代价函数我们得到参数的值,对于第五个人Eve ,我们的到的参数可以是 w=[0,0],b(5)=0。
因为他没有给任何电影评分,使用参数w,b 不影响代价函数中的第一项,在这个平方误差代价函数中,我们希望代价函数的值尽可能的小,所以也就是希望参数w 的值尽可能的小,最后参数w 会取到0,参数b 的值我们并没有进行规定,也可以默认它的值为0。
均值归一化干了啥???
如果我们使用计算出来的参数值来预测评分,那么w*x+b ,最终5部电影的评分都是0;使用均值归一化可以避免这种情况。
为了描述什么是均值归一化,我们将数据写成矩阵的形式。
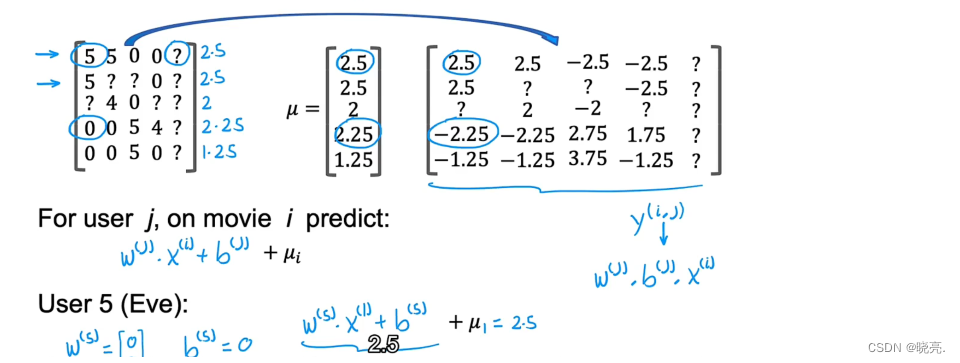
在这里,我们计算每一行的均值,然后写成一个列向量μ,表示每部电影的平均收视率,
然后将每个评分减去评分的平均值,随后使用均值归一化后的值进行预测,
为了避免预测结果出现负值,我们就可以在后面加上μ_i
有了这些铺垫,我们再来看均值归一化后的数据对第五个用户Eve,对5部电影的预测,预测结果不是0了,而是评分均值了,很明显这样的评分比0评分是要好的。
事实证明,通过将不同电影评分的均值归一化为0,优化算法推荐的系统也会运行得更快一点。它对于没有评价电影和评价电影数量很少的用户表现更好,预测结果也更合理。
这里我们使用的是对矩阵的每一行标准化为均值为0,对于不同的问题,我们也可以对矩阵的列进行标准化。
比如对于一部没有人看过的电影,想对其进行预测评分,那么对矩阵的列进行标准化效果是比较好的。
P119 利用TensorFlow 来实现协同过滤算法
参照链接:【机器学习】使用tensorflow 实现协同过滤算法_晓亮.的博客-CSDN博客
P120 寻找相关特征
我们学习了每个项目I 的特征x^(i), 它很难明确的学习到各个特征,比如说x1学习到这个电影是否是动作片,x2学习到这个电影是否是美国片等,这些是很难的。
我们将学到的特征,统称为 x1、x2…… 等 ,表示关于这部电影的某些特征,
虽然学习不到哪些准确的特征,但是找到的这些特征都是与这部电影相关的。
给定项目i的特征x^(i),如果我们想找到其它项目,比如说与电影i相关的其他电影,那么我们可以做的就是尝试找到项目k的x^(k), 类似于x^(i)。
计算x^(k),与 x^(i)的平方距离,如果计算出来的距离值小的话,那就是相关的特征。
如果我们发现不只是一部电影x^(k) 与 x^(i)之间的距离最小,比如说找到了5个相关的项目,那么如果用户在找某个电影Ii时,我们就可以将这几个相似的电影k推荐给他。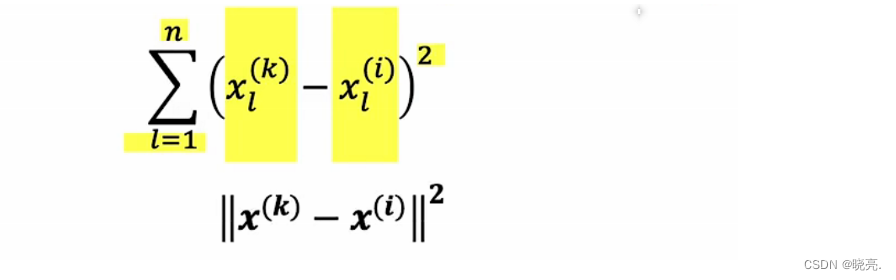
基于内容的过滤系统----------------
P121 协同过滤与基于内容过滤对比
| 协同过滤 | 基于内容过滤 |
|---|---|
| 对于协同过滤,一般时我们根据用户给出的评分,算法会根据用户的评分,给用户推荐新的东西。(对于缺少信息的时候,比如一个用户只对很少电影进行评分,该给他推荐什么电影;或者有一部新电影没有人评分过,该向哪些用户推荐它。对于这些问题,使用协同过滤可能会出现预测不准的情况。) | 对于基于内容过滤,它是基于内容的过滤需要来决定向我们推荐什么东西的算法,它会根据用户的特征给用户推荐东西。 换句话说,它需要每个用户都有一些特征,以及每个项目的一些特征,它使用这些特征来尝试决定哪些项目和用户可能是很好的匹配。 |
使用基于内容过滤算法,它仍然有用户对某些项目进行评分的数据,所以它会像协同过滤一样,使用r(i ,j)表示用户j是否对项目i进行评分;y(i,j)用户j对项目i的评分是多少。不同的是基于内容过滤算法可以很好的利用用户和项目的特征来进行匹配。比如用户有年龄、性别、国家等特征;电影有上映年份、类型、平均评分等特征。
用户特征和电影特征的大小可能有很大差别,那么我们如何将用户和项目的特征进行匹配呢?
基于内容过滤算法中,我们可以利用算法来学习匹配用户和项目,这里是用户和电影。
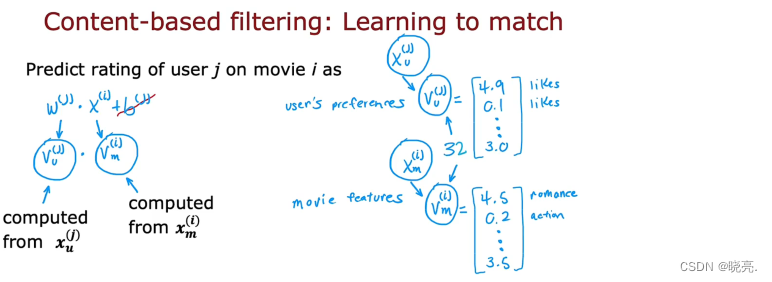
下面是预测用户 j 对电影 i 的评分:
- m表示电影,i表示电影中的其中一个
- u代表用户,j代表人群中的一个人
- v_u(j) 其中u代表用户,j是其中一人
- v_u(j)、v_m(i)是计算出来的数字列表,从X_u(j),X_m(i)
基于内容过滤算法的预测公式不需要b(j) , 这并不会影响算法的性能。
然后将w(j) 改为了v_u(j) 表示用户 ;将 x(i) 改为了 v_m(i) 表示电影中的项目。其中 v_u(j)、v_m(i) 向量都是根据用户的特征和电影的特征计算过来的(下节内容讲如何得到v_u(j)、v_m(i)两个向量)。
前面说了用户特征和电影特征大小可能有很大差别,于是我们将用户特征和电影特征转换计算处理成v_u(j)、v_m(i) 这两个向量具有相同的维度,然后进行点乘。
P122 基于内容过滤的深度学习方法(如何求用户和电影相关特征)
基于内容的过滤算法就是使用深度学习
回到前面,我们有用户的许多特征年龄、性别、国家等x_u, 我们要利用这些特征计算向量v_u
我们有电影的许多特征上映年份、类型等x_m, 我们要利用这些特征计算向量v_m
我们怎么去计算v_u 和 v_m 呢?---------------------------- 可以使用神经网络。
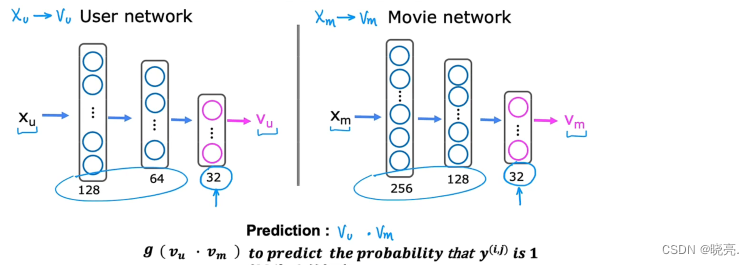
我们现在是对电影评分进行预测,如果有二进制标签,标签y对用户来说是是否喜欢一个项目,我们也可以修改算法来输出,使用sigmiod 函数来进行预测y(i,j)为1 的概率。
这个网络模型每一层都有一组神经网络参数,如何去训练用户网络和电影网络的这些参数?
我们可以构造一个代价函数J, 它非常类似于协同过滤中的代价函数,
有了这个代价函数就可以使用梯度下降或者一些其他的优化算的来调整所有的参数,来使得代价函数尽可能的小,如果想要对这个模型进行正则化,我们也可以添加神经网络正则化项,来使得所有的参数都很小。
在我们有了这个模型后,还可以使用它来寻找类似的物品,这类似于协同过滤特征,帮助找到类似的项目。
例如我们想找到其他类似的电影该怎么做?
向量v_m(i) 描述了电影 i,如果要找到类似的电影,可以寻找其他电影的k的向量,然后计算平方距离。
当平方差较小时,说明两者较为相近。使用这个方法可以找到与给定项目相似的项目。
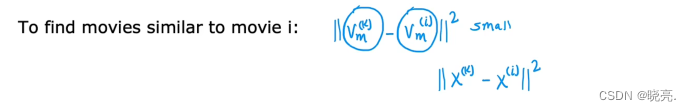
P123 从大型目录中推荐(选看)
















 141
141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









