







Java数据结构类型
Java数据结构包括Enumeration、BitSet、Vector、Stack、Dictionary、
Hashtable、Properties以及java2中引入的Collection共八种类型,
八种类型中包含了接口和类。
该八种类型分别对映:
枚举、位集合、向量、栈、字典、哈希表、属性以及框架-集合框架。
枚举(Enumeration)
其本质上为一个接口,其中定义了一些方法,通过这些方法可以枚举一个对象集合中的所有元素。已逐渐被迭代器所取代,在传统的一些方法中还保留该类型。
其主要方法有:
boolean hasMoreElements( ) : 测试此枚举是否包含更多的元素。
Object nextElement( ) : 如果此枚举对象至少还有一个可提供的元素,则返回此枚举的下一个元素。
演示如下:
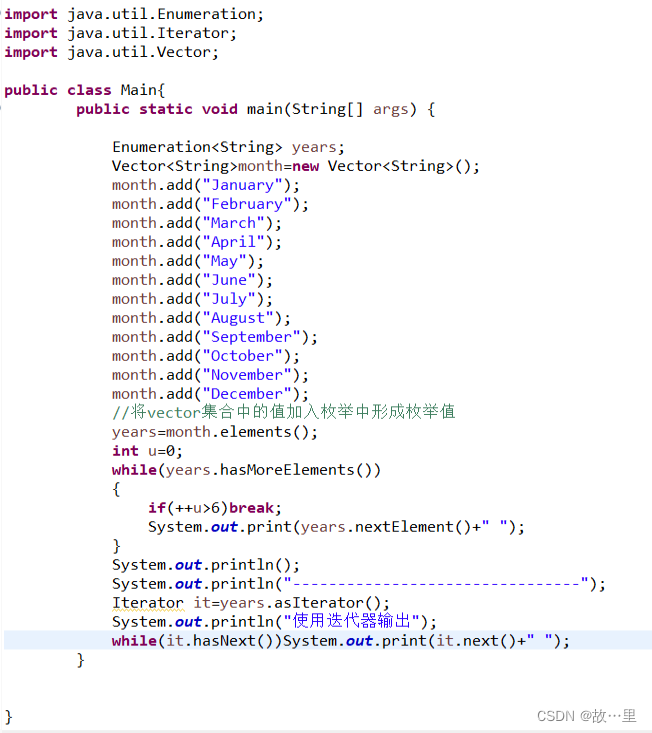
输出为:

注意事项:
Enumeration为接口类,其包括三个方法,nextElem返回值为泛型,其余两个方法中,有一个默认方法。
Enumeration中的默认方法为asIterator,其返回值为Iterator,特别注意的是,返回的元素是未遍历的元素集合,若元素在调用该方法时已经遍历结束,那么Iterator迭代器之中的元素集合为空。
位集合(BitSet)
位集合实现了一组可以单独设置和清除的位或标志。
位集合实现了Cloneable接口的方法。
其构造方式有两种,一种为不含参数的默认方法,另一种为含有整数值参数的构造方法,该整数值是为集合分配的初始大小,并且所有位初始化为0。
在第二种方式中,初始化的集合大小,其为64的整数倍,若设置的大小不是64的整数倍,则大小为大于设置大小的64的整数倍。
void and(BitSet set):位集合的与运算。
将两个bitset类型的位集合每一位进行与运算,只保留两个集合中都存在的数值。若集合中有某个参数与set位集合中不同,则清除。
void andNot(BitSet set):将存在与该集合中的数值都消除,只保留不相交的部分。
在bitset位集合中,空值则表示位false,若有数值存在,则真值为true,其余方法还有:
boolean equals(Object bitSet):将此对象与指定的对象进行比较。
void flip(int index):将指定索引处的位设置为其当前值的补码。
void flip(int startIndex, int endIndex):将指定的 fromIndex(包括)到指定的 toIndex(不包括)范围内的每个位设置为其当前值的补码。
boolean get(int index):返回指定索引处的位值。
boolean intersects(BitSet bitSet):如果指定的 BitSet 中有设置为 true 的位,并且在此 BitSet 中也将其设置为 true,则返回 true。
void or(BitSet bitSet):对此位 set 和位 set 参数执行逻辑或操作。
void xor(BitSet bitSet):对此位 set 和位 set 参数执行逻辑异或操作。
代码演示如下:
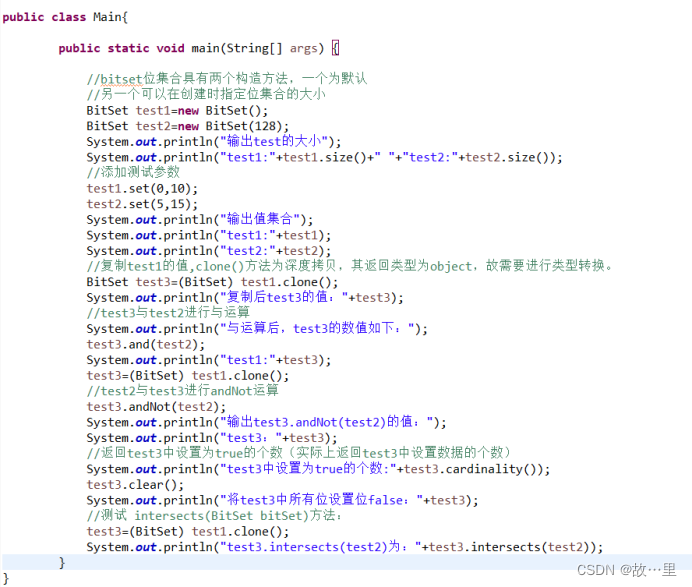
输出为:

向量(vector)
Vector为一个类,其使用与数组极为相似,可通过下标进行索引。
其优势为创建对象时不需要设置大小,可根据需要,大小动态变化。
Vector具有同步访问的特点,包含许多传统的方法。
其一般用于事先不知道数组的大小,或者只需要一个可以改变大小的数组的情景即可。
Vector类有四种构造方法,分别为:
- 无参构造(Vector()):默认的大小为10;
- 含有一个参数(Vector(int size)):创建指定大小的向量;
- 含有两个参数(Vector(int size,int incr)):创建指定大小的向量,同时设置一个增量值,使向量每次以incr的大小增加空间。
- 包含集合的构造(Vector(Collection c)):创建一个包含集合c元素的向量。
Vector常用的方法有:
Void add(object c):将元素c添加到向量中。
Void add(int index,object element):在指定位置,添加元素。
Boolean addAll(collection c):将集合c中的所有元素,按照迭代器返回的顺序,添加到此向量的末尾。
void addElement(Object obj) :将指定的组件添加到此向量的末尾,将其大小增加 1。
int capacity() :返回此向量的当前容量。
void clear() :从此向量中移除所有元素。
Object clone() :返回向量的一个副本。
boolean contains(Object elem) :如果此向量包含指定的元素,则返回 true。
boolean containsAll(Collection c) :如果此向量包含指定 Collection 中的所有元素,则返回 true。
void copyInto(Object[] anArray) :将此向量的组件复制到指定的数组中。
Object elementAt(int index) :返回指定索引处的组件。
Enumeration elements() :返回此向量的组件的枚举。
void ensureCapacity(int minCapacity) :增加此向量的容量(如有必要),以确保其至少能够保存最小容量参数指定的组件数。
boolean equals(Object o) :比较指定对象与此向量的相等性。
int indexOf(Object elem) :返回此向量中第一次出现的指定元素的索引,如果此向量不包含该元素,则返回 -1。
int indexOf(Object elem, int index) :返回此向量中第一次出现的指定元素的索引,从 index 处正向搜索,如果未找到该元素,则返回 -1。
void insertElementAt(Object obj, int index) :将指定对象作为此向量中的组件插入到指定的 index 处。
Object lastElement() :返回此向量的最后一个组件。
int lastIndexOf(Object elem) :返回此向量中最后一次出现的指定元素的索引;如果此向量不包含该元素,则返回 -1。
Object remove(int index) : 移除此向量中指定位置的元素。
boolean remove(Object o) :移除此向量中指定元素的第一个匹配项,如果向量不包含该元素,则元素保持不变。
boolean removeAll(Collection c) :从此向量中移除包含在指定 Collection 中的所有元素。
部分方法演示如下:
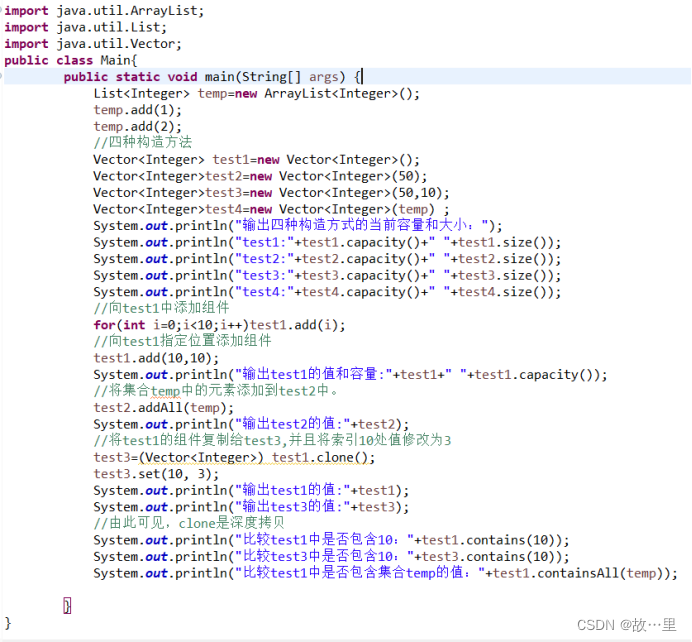
输出结果为:

栈(stack)
栈实现了栈内元素先进后出,后进先出的顺序。
栈类似于对象垂直放置的数组。
Stack继承了vector类,是vector类的一个子类,故stack具有vector类的所有方法,
同时,stack类还定义了自己的一些方法。
Stack只有一个默认的无参构造方法,其实质是系统的储存器为所创建的对象分配一个堆栈。
其自定义的主要方法如下:
boolean empty() :测试堆栈是否为空。
Object peek( ):查看堆栈顶部的对象,但不从堆栈中移除它。
Object pop( ):移除堆栈顶部的对象,并作为此函数的值返回该对象。
Object push(Object element):把项压入堆栈顶部。
int search(Object element):返回对象在堆栈中的位置,以 1 为基数。
实际演示如下:
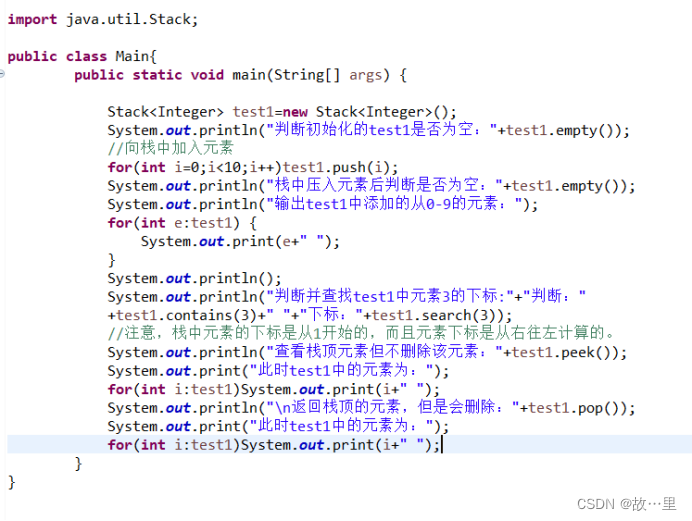
输出结果如下:

字典类(dictionary)
字典类是一个抽象类,它定义了一个键映射到值的数据结构。
字典类实际已经不符合需求而被Map所取代。
字典类中定义的抽象方法如下:
Enumeration elements( ):返回此 dictionary 中值的枚举。
Object get(Object key):返回此 dictionary 中该键所映射到的值。
boolean isEmpty( ):测试此 dictionary 是否不存在从键到值的映射。
Enumeration keys( ):返回此 dictionary 中的键的枚举。
Object put(Object key, Object value):将指定 key 映射到此 dictionary 中指定 value。
Object remove(Object key):从此 dictionary 中移除 key (及其相应的 value)。
int size( ):返回此 dictionary 中条目(不同键)的数量。
注意:
Hashtable<K,V>类继承了dictionary类,并且实现了Map<K,V>, Cloneable, java.io.Serializable三个接口。
实际演示如下:
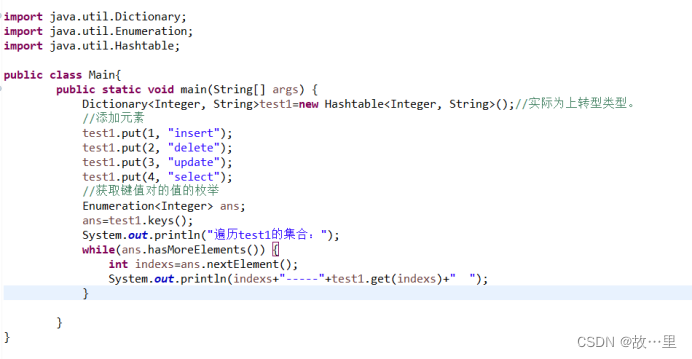
输出为:
哈希表(Hashtable)
Hashtable是原始java.util的一部分,其是dictionary类的具体实现。
Java2中实现了Map接口,现在被加入到集合框架之中,和hashmap类很相似,但是他支持同步。(哈希表的键是经过哈希函数变换后得到的散列码)
其构造方式有四种,分别为:
1.无参构造:Hashtable()
2.初始化哈希表的大小:Hashtable(int size);
3.初始化哈希表的大小,并且使用fillRation填充指定比例,填充比例介于0.0-1.0之间:Hashtable(int size,float fillRation);
4.使用map集合中的元素作为初始元素构造哈希表:Hashtable(Map M)。
其方法的部分演示如下:

输出结果为:

其余方法有:
Enumeration elements( ):返回此哈希表中的值的枚举。
boolean isEmpty( ):测试此哈希表是否没有键映射到值。
Enumeration keys( ):返回此哈希表中的键的枚举。
void rehash( ):增加此哈希表的容量并在内部对其进行重组,以便更有效地容纳和访问其元素。
String toString( ):返回此 Hashtable 对象的字符串表示形式,其形式为 ASCII 字符 ", " (逗号加空格)分隔开的、括在括号中的一组条目。
Object clone( ):创建此哈希表的浅表副本。
属性(Properties)
Properties 继承于 Hashtable.Properties 类表示了一个持久的属性集.属性列表中每个键及其对应值都是一个字符串。
Properties默认拥有一个实例变量:Properties defaults;该对象为默认持有一个属性列表。
其有两种构造方法:
- 无参构造:Properties();
- 设置默认值的构造方法:Properties(Properties propDefault)。
两种构造方法属性列表都为空。
Properties继承于hashtable,故拥有所有hashtable所定义的方法。除此之外
其余一些方法有:
String getProperty(String key):用指定的键在此属性列表中搜索属性。
String getProperty(String key, String defaultProperty):用指定的键在属性列表中搜索属性。
void list(PrintStream streamOut):将属性列表输出到指定的输出流。
void list(PrintWriter streamOut):将属性列表输出到指定的输出流。
PrintWriter,与PrintStream相似,实现了PrintStream中的所有 print 方法。PrintStream打印的所有字符都使用平台的默认字符编码转换为字节。在需要写入字符而不是写入字节的情况下,应该使用 PrintWriter类。
void load(InputStream streamIn) throws IOException:从输入流中读取属性列表(键和元素对)。
Enumeration propertyNames( ):按简单的面向行的格式从输入字符流中读取属性列表(键和元素对)
Object setProperty(String key, String value):调用 Hashtable 的方法 put。
void store(OutputStream streamOut, String description):以适合使用 load(InputStream)方法加载到 Properties 表中的格式,将此 Properties 表中的属性列表(键和元素对)写入输出流。
实际代码演示如下:
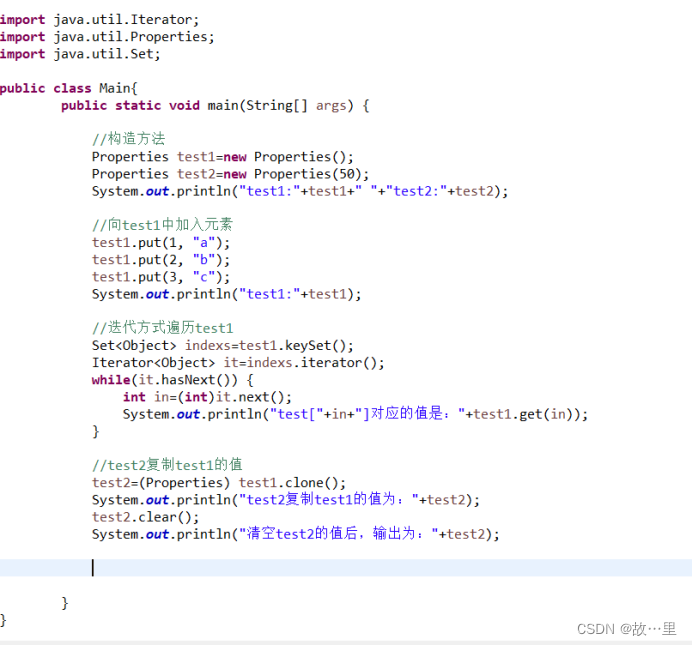
输出结果为:
















 263
263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









