







Tensorflow2.1入门 第六章:循环神经网络
一、循环核
1. 特点
循环核具有“记忆力”,通过不同时刻的参数时间共享,实现了对时间序列的特征提取。
2. 循环核参数及输出
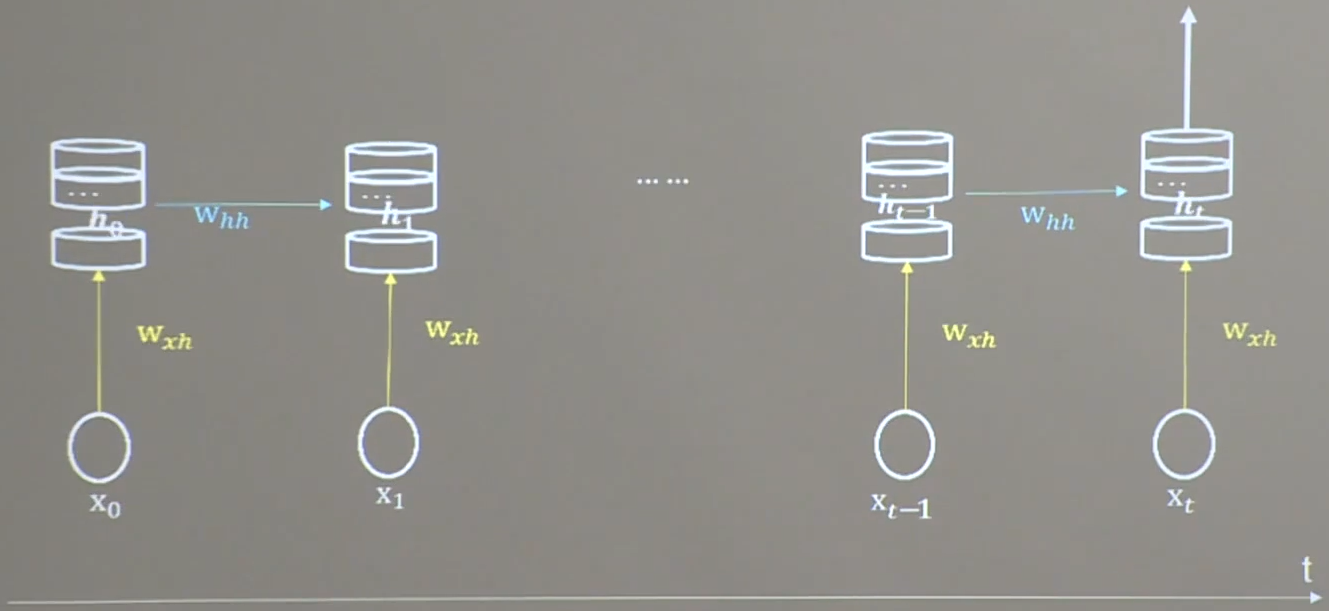
下图为一个循环核。中间的部分为记忆体,记忆体的下面、侧面、上面分别有三组待训练的参数矩阵。可以改变记忆体的个数,来改变记忆容量。当记忆体个数被指定,输入xt、输出yt维度被指定,周围的待训练参数的维度也就被限定了。
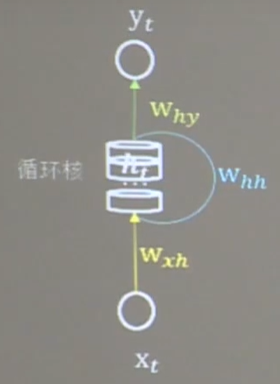
记忆体内存储着每个时刻的状态信息
h
t
h_t
ht,等于当前时刻的输入特征
x
t
x_t
xt乘以参数矩阵
w
h
t
w_{ht}
wht,加上记忆体上一时刻存储的状态信息
h
t
−
1
h_{t-1}
ht−1乘以参数矩阵
w
h
h
w_{hh}
whh,再加上偏置项
b
h
b_h
bh。最后的和再过tanh激活函数即可。
h
t
=
t
a
n
h
(
x
t
∗
w
x
h
+
h
t
−
1
∗
w
h
h
+
b
h
)
h_{t}=tanh(x_{t}*w_{xh}+h_{t-1}*w_{hh}+b_h)
ht=tanh(xt∗wxh+ht−1∗whh+bh)
当前时刻循环和的输出特征
y
t
y_t
yt等于记忆体内存储的状态信息
h
t
h_t
ht乘以矩阵
w
h
y
w_{hy}
why,再加上偏置项
b
y
b_y
by,过softmax激活函数。(即为一层全连接)
y
t
=
s
o
f
t
m
a
x
(
h
t
∗
w
h
y
+
b
y
)
y_{t}=softmax(h_t*w_{hy}+b_y)
yt=softmax(ht∗why+by)
前向传播时:记忆体内存储的信息
h
t
h_t
ht,在每个时刻都被刷新,三个参数矩阵
w
x
h
w_{xh}
wxh、
w
h
h
w_{hh}
whh、
w
h
y
w_{hy}
why自始至终都是固定不变的。
反向传播时:三个参数矩阵
w
x
h
w_{xh}
wxh、
w
h
h
w_{hh}
whh、
w
h
y
w_{hy}
why被梯度下降法更新。
3. 循环核按时间步展开
按照时间步展开式,就是把循环核按照时间轴方向展开。可以表示为下图所示。
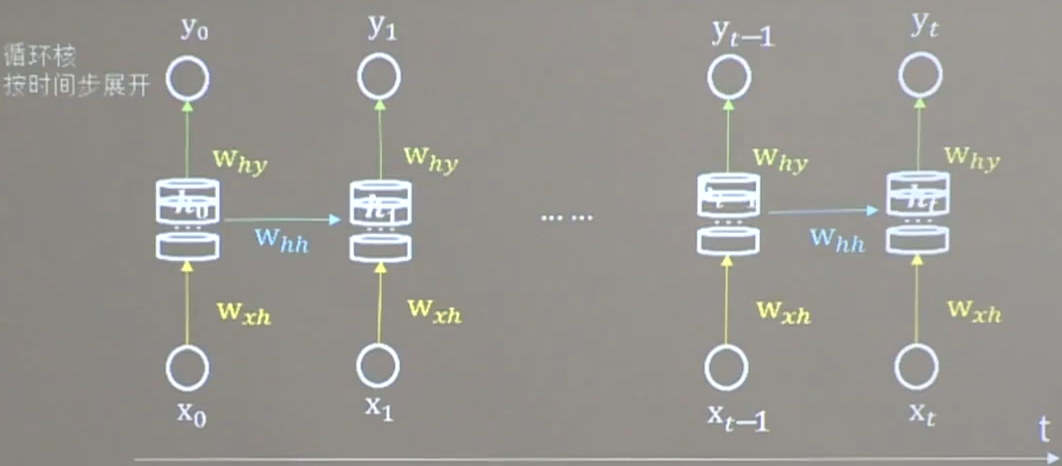
每个时刻记忆体状态信息 h t h_t ht被刷新,记忆体周围的参数矩阵 w x h w_{xh} wxh、 w h h w_{hh} whh、 w h y w_{hy} why是固定不变的。我们要训练优化的,就是这些参数矩阵。训练完成后,使用效果最好的参数矩阵,执行前向传播,输出预测结果。
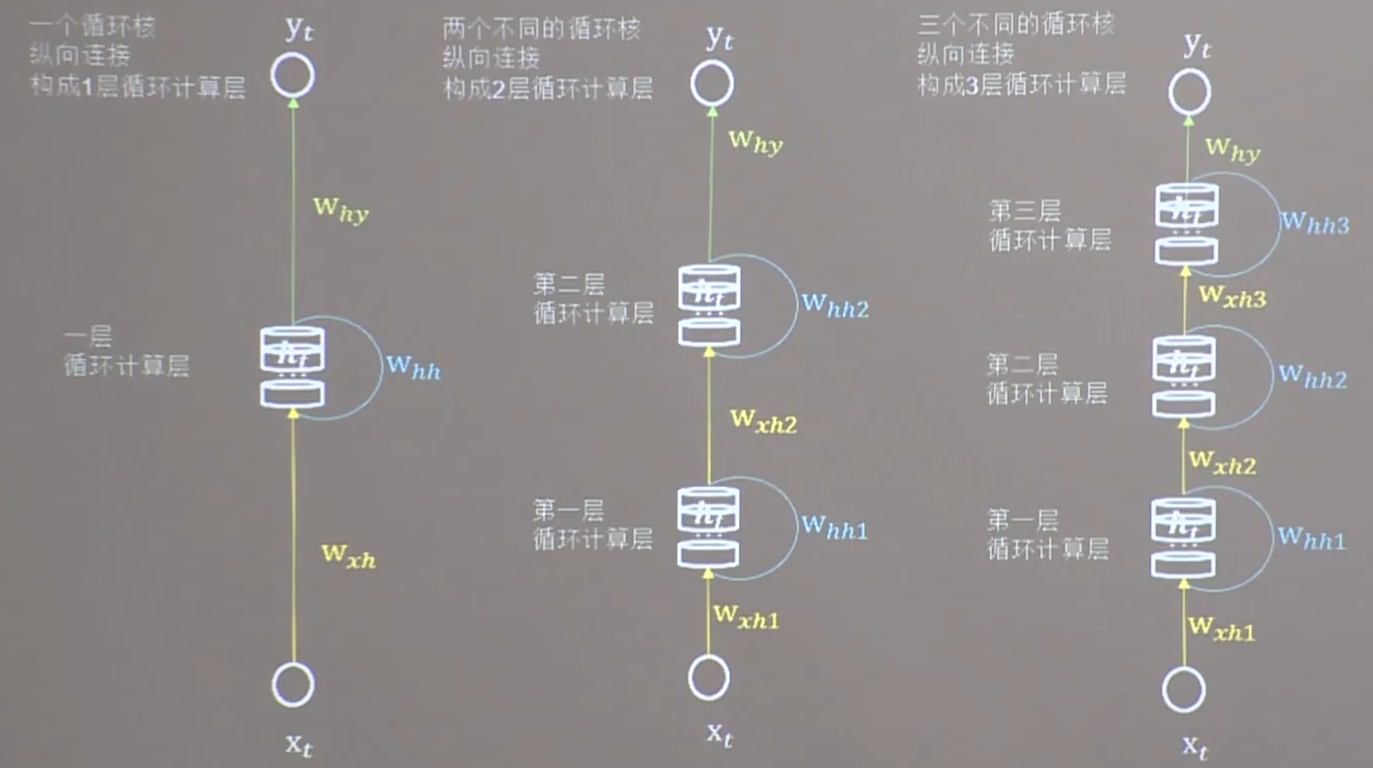
二. 循环计算层
1. 循环计算层
每个循环核构成一层循环计算层,循环计算层的层数是向输出方向增长的。每个循环计算层(循环核)中的记忆体的个数,是根据需求任意指定的。
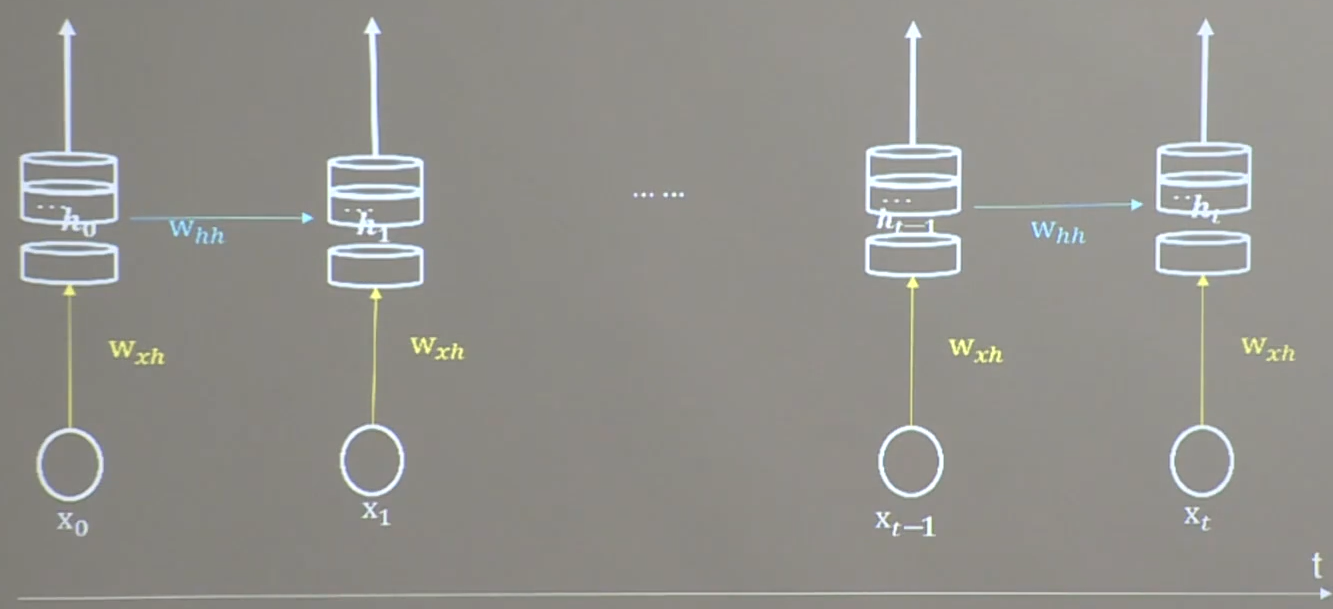
2. 使用Tensorflow描述
tf.keras.layers.SimpleRNN(记忆体个数, activation='激活函数',
return_sequences=是否每个时刻输出ht到下一层,
activation=‘激活函数’(不写默认tanh)
)
其中return_sequences=True表示各时间步输出
h
t
h_t
ht;return_sequences=False表示仅在最后一个时间步输出
h
t
h_t
ht(默认)。一般,最后一层的循环核用False,中间层的循环核用True。
例:SimpleRNN(3, return_sequences=True)
在每一个时间步都输出 h t h_t ht:
仅在最后一个时间步输出 h t h_t ht:
3. 数据维度
输入数据送入RNN时,x_train的数据维度要求是三维的:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]。
例:

三、循环计算过程
本节使用字母预测的例子进行演示。
1. 单一字母预测
目标效果:输入a→输出b,输入b→输出c,输入c→输出d,输入d→输出e,输入e→输出a。
步骤:
(1)用独热码对五个字母进行编码;
| 字母 | 编码 |
|---|---|
| a | 10000 |
| b | 01000 |
| c | 00100 |
| d | 00010 |
| e | 00001 |
(2)随机生成参数矩阵 w x h w_{xh} wxh、 w h h w_{hh} whh、 w h y w_{hy} why,记忆体的数量选取三个。
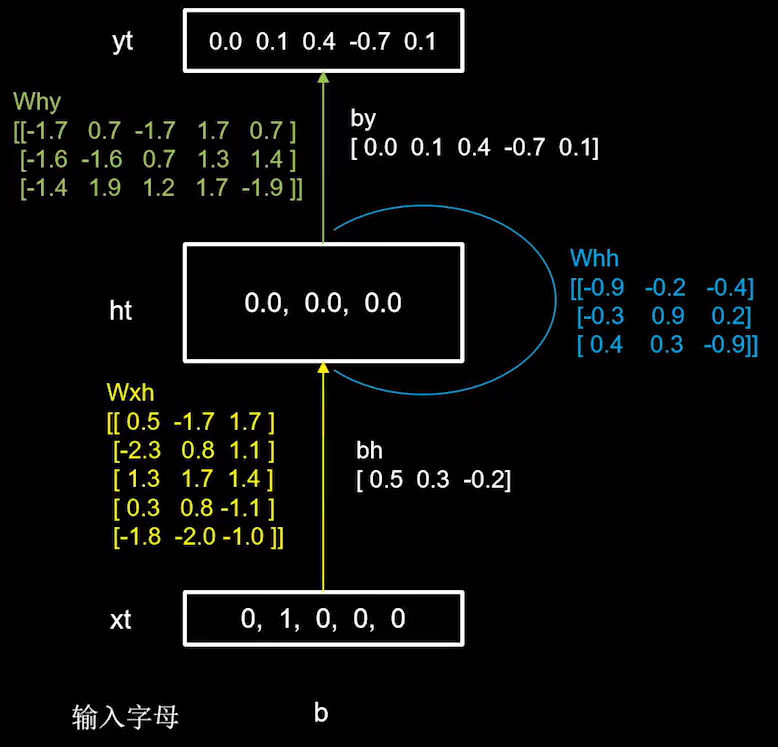
(3)计算输入为b时的
h
t
h_{t}
ht和
y
t
y_{t}
yt
h
t
=
t
a
n
h
(
x
t
∗
w
x
h
+
h
t
−
1
∗
w
h
h
+
b
h
)
h_{t}=tanh(x_{t}*w_{xh}+h_{t-1}*w_{hh}+b_h)
ht=tanh(xt∗wxh+ht−1∗whh+bh)
=
t
a
n
h
(
[
−
2.3
,
0.8
,
1.1
]
+
[
0
,
0
,
0
]
+
[
0.5
,
0.3
,
−
0.2
]
)
=tanh([-2.3, 0.8, 1.1]+[0, 0, 0]+[0.5, 0.3, -0.2])
=tanh([−2.3,0.8,1.1]+[0,0,0]+[0.5,0.3,−0.2])
=
t
a
n
h
(
[
−
1.8
,
1.1
,
0.9
]
)
=
[
−
0.9
,
0.8
,
0.7
]
=tanh([-1.8, 1.1, 0.9])=[-0.9, 0.8, 0.7]
=tanh([−1.8,1.1,0.9])=[−0.9,0.8,0.7]
h t h_{t} ht发生了改变,即脑中的记忆随着新输入的事物而改变了。
y
t
=
s
o
f
t
m
a
x
(
h
t
∗
w
h
y
+
b
y
)
y_{t}=softmax(h_t*w_{hy}+b_y)
yt=softmax(ht∗why+by)
=
s
o
f
t
m
a
x
(
[
−
0.7
,
−
0.6
,
2.9
,
0.7
,
−
0.8
]
+
[
0.0
,
0.1
,
0.4
,
−
0.7
,
0.1
]
)
=softmax([-0.7, -0.6, 2.9, 0.7, -0.8]+[0.0, 0.1, 0.4, -0.7, 0.1])
=softmax([−0.7,−0.6,2.9,0.7,−0.8]+[0.0,0.1,0.4,−0.7,0.1])
=
[
0.02
,
0.02
,
0.91
,
0.03
,
0.02
]
=[0.02, 0.02, 0.91, 0.03, 0.02]
=[0.02,0.02,0.91,0.03,0.02]
即模型认为有91%的可能性输出字母c。
x_train = np.reshape(x_train, (len(x_train), 1, 5))
# 第一个维度是样本个数,第二个维度是时间展开步数,第三个维度是每个时间步输入特征个数
# 因为输入一个字母即得到结果,所以时间展开步数是1;由于独热码长度为5,所以特征个数为5
y_train = np.array(y_train)
model = tf.keras.Sequential([
SimpleRNN(3), # 记忆体个数为3
Dense(5, activation='softmax') # 全连接层实现了yt的计算
])
model.compile(optimizer=tf.keras.optimizers.Adam(0.01),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
p15_rnn_onehot_1pre1.py
2. 连续输入多个字母预测下一个字母
前向传播过程中的每个时刻,参数矩阵都是固定的,而记忆体会在每个时刻被更新。
最终输出通过全连接预测。
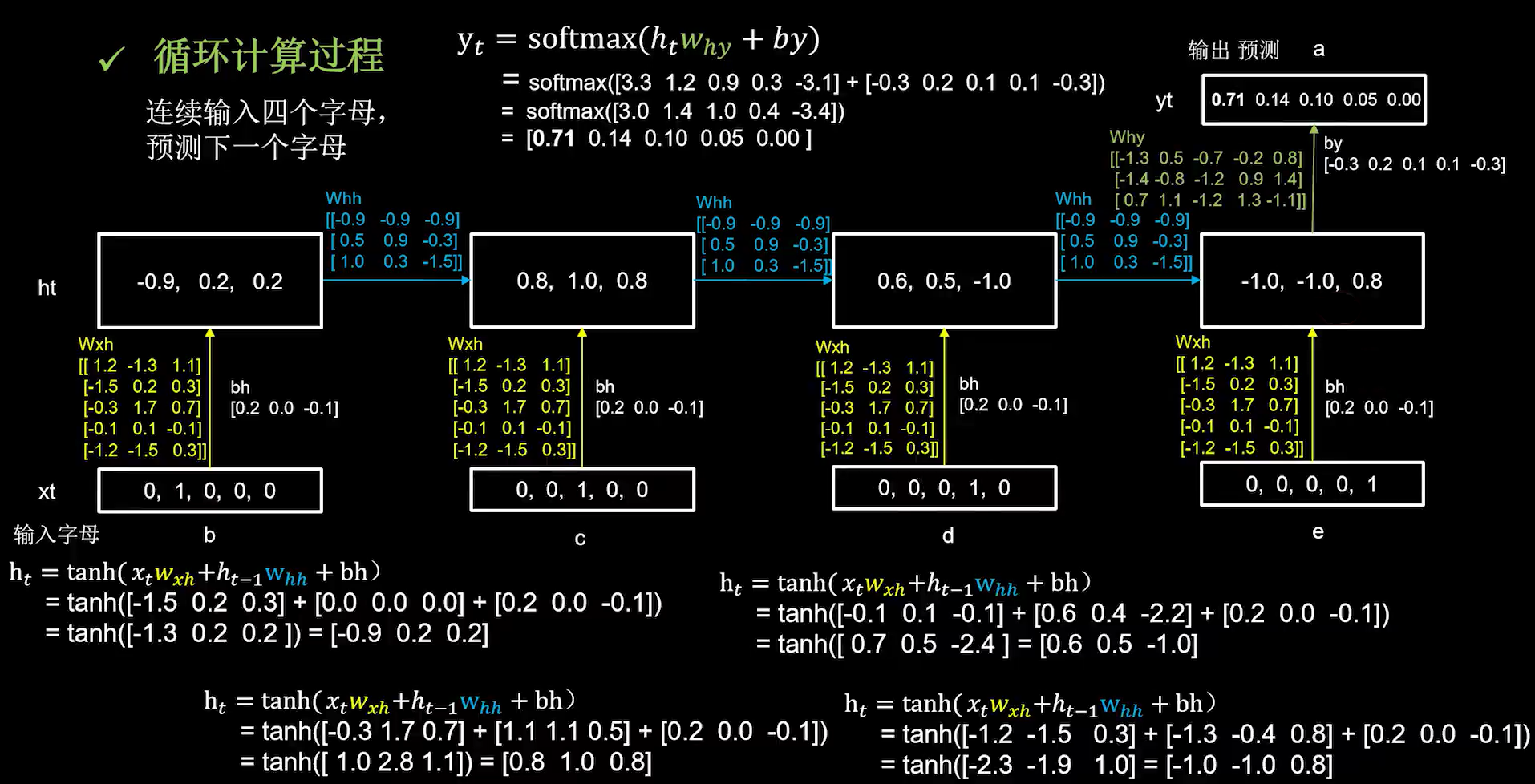
# 使x_train符合SimpleRNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]。
# 此处整个数据集送入,送入样本数为len(x_train);输入4个字母出结果,循环核时间展开步数为4; 表示为独热码有5个输入特征,每个时间步输入特征个数为5
x_train = np.reshape(x_train, (len(x_train), 4, 5))
y_train = np.array(y_train)
model = tf.keras.Sequential([
SimpleRNN(3),
Dense(5, activation='softmax')
])
p21_rnn_onehot_4pre1.py
四、Embedding——一种编码方法
独热码:数据量大、过于系数,映射之间是独立的,没有表现出关联性。
Embedding:是一种单词编码方法,用低维向量实现了编码。这种编码通过神经网络训练优化,能表达出单词间的相关性。
tf.keras.layers.Embedding(词汇表大小,编码维度)
编码维度就是用几个数字表达一个单词。
例:
对1-100进行编码,每个自然数用三个数字表示,用Embedding层表示就是
tf.keras.layers.Embedding(100,3)
Embedding层对于输入数据维度要求是二维的:[送入样本数,循环核时间展开步数]。
model = tf.keras.Sequential([
Embedding(5, 2),
SimpleRNN(3),
Dense(5, activation='softmax')
])
p27_rnn_embedding_1pre1.py
p27_rnn_embedding_4pre1.py
五、用RNN实现股票预测
SH600519.csv是用tushare下载的贵州茅台的日k线数据,仅使用其C列数据(开盘价)。使用前60天连续的开盘价来预测第61天的开盘价。
# 使x_train符合RNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]。
# 此处整个数据集送入,送入样本数为x_train.shape[0]即2066组数据;输入60个开盘价,预测出第61天的开盘价,循环核时间展开步数为60; 每个时间步送入的特征是某一天的开盘价,只有1个数据,故每个时间步输入特征个数为1
x_train = np.reshape(x_train, (x_train.shape[0], 60, 1))
# 测试集:csv表格中后300天数据
# 利用for循环,遍历整个测试集,提取测试集中连续60天的开盘价作为输入特征x_train,第61天的数据作为标签,for循环共构建300-60=240组数据。
for i in range(60, len(test_set)):
x_test.append(test_set[i - 60:i, 0])
y_test.append(test_set[i, 0])
# 测试集变array并reshape为符合RNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]
x_test, y_test = np.array(x_test), np.array(y_test)
x_test = np.reshape(x_test, (x_test.shape[0], 60, 1))
model = tf.keras.Sequential([
SimpleRNN(80, return_sequences=True),
Dropout(0.2),
SimpleRNN(100),
Dropout(0.2),
Dense(1)
])
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss='mean_squared_error') # 损失函数用均方误差
# 该应用只观测loss数值,不观测准确率,所以删去metrics选项,一会在每个epoch迭代显示时只显示loss值
p38_rnn_stock.py
六、LSTM
传统循环网络RNN可以通过记忆体实现短期记忆进行连续数据的预测。但是当连续数据的序列变长时,会使展开时间步过长,在反向传播更新参数时,梯度要按照时间步连续相乘,会导致梯度消失。长短记忆网络就是用来避免这一问题的。
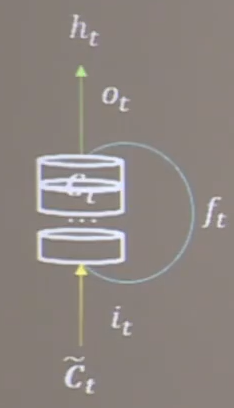
长短记忆网络中引入了三个门限:输入门 i t i_t it,遗忘门 f t f_t ft,输出门 o t o_t ot。引入了表征长期记忆的细胞态 C t C_t Ct和等待长期记忆的候选态 C t ~ \tilde{C_t} Ct~。
三个门限都是当前时刻的输入特征 x t x_t xt和上个时刻的短期记忆 h t − 1 h_{t-1} ht−1的函数。 W i W_i Wi、 W f W_f Wf、 W o W_o Wo三者都是待训练的参数矩阵, b i b_i bi、 b f b_f bf、 b o b_o bo时代训练偏置项。它们都经过sigmoid激活函数,使门限的范围在0到1之间。
细胞态表示长期记忆等于上个时刻的长期记忆乘以遗忘门,加上当前时刻归纳出的新知识乘以输入门;记忆体表示短期记忆,属于长期记忆的一部分,是细胞态过tanh激活函数乘以输出门的结果;候选态表示归纳出的待存入细胞态的新知识,是当前时刻的输入特征 x t x_t xt和上个时刻的短期记忆 h t − 1 h_{t-1} ht−1的函数。
{ 输 入 门 ( 门 限 ) : i t = σ ( W i ∗ [ h t − 1 , x t ] + b i ) 遗 忘 门 ( 门 限 ) : f t = σ ( W f ∗ [ h t − 1 , x t ] + b f ) 输 出 门 ( 门 限 ) : o t = σ ( W o ∗ [ h t − 1 , x t ] + b o ) 细 胞 态 ( 长 期 记 忆 ) : C t = f t ∗ C t − 1 + i t ∗ C t ~ 记 忆 体 ( 短 期 记 忆 ) : h t = o t ∗ t a n h ( C t ) 候 选 态 ( 归 纳 出 的 新 知 识 ) : C t ~ = t a n h ( W c ∗ [ h t − 1 , x t ] + b c ) \left\{ \begin{aligned} 输入门(门限):i_t=\sigma(W_i*[h_{t-1},x_t]+b_i) \\ 遗忘门(门限):f_t=\sigma(W_f*[h_{t-1},x_t]+b_f) \\ 输出门(门限):o_t=\sigma(W_o*[h_{t-1},x_t]+b_o) \\ 细胞态(长期记忆):C_t=f_t*C_{t-1}+i_t* \tilde{C_t}\\ 记忆体(短期记忆):h_t=o_t*tanh(C_{t})\\ 候选态(归纳出的新知识):\tilde{C_t}=tanh(W_c*[h_{t-1},x_t]+b_c)\\ \end{aligned} \right. ⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧输入门(门限):it=σ(Wi∗[ht−1,xt]+bi)遗忘门(门限):ft=σ(Wf∗[ht−1,xt]+bf)输出门(门限):ot=σ(Wo∗[ht−1,xt]+bo)细胞态(长期记忆):Ct=ft∗Ct−1+it∗Ct~记忆体(短期记忆):ht=ot∗tanh(Ct)候选态(归纳出的新知识):Ct~=tanh(Wc∗[ht−1,xt]+bc)
tf.keras.layers.LSTM(记忆体个数, return_sequences=是否返回输出)
p47_LSTM_stock.py
七、GRU
在2014年,Cho等人简化了LSTM结构,提出了GRU网络。GRU使记忆体
h
t
h_t
ht融合了长期记忆和短期记忆,即
h
t
h_t
ht包含了过去信息
h
t
−
1
h_{t-1}
ht−1和现在信息
h
t
~
\tilde{h_t}
ht~;现在信息
h
t
~
\tilde{h_t}
ht~是过去信息
h
t
−
1
h_{t-1}
ht−1过重置门与当前输入共同决定。两个门限的取值范围也被sigmoid激活函数控制在了0-1之间。
{
更
新
门
:
i
t
=
σ
(
W
i
∗
[
h
t
−
1
,
x
t
]
+
b
i
)
重
置
门
:
f
t
=
σ
(
W
f
∗
[
h
t
−
1
,
x
t
]
+
b
f
)
记
忆
体
:
h
t
=
o
t
∗
t
a
n
h
(
C
t
)
候
选
隐
藏
层
:
C
t
~
=
t
a
n
h
(
W
c
∗
[
h
t
−
1
,
x
t
]
+
b
c
)
\left\{ \begin{aligned} 更新门:i_t=\sigma(W_i*[h_{t-1},x_t]+b_i) \\ 重置门:f_t=\sigma(W_f*[h_{t-1},x_t]+b_f) \\ 记忆体:h_t=o_t*tanh(C_{t})\\ 候选隐藏层:\tilde{C_t}=tanh(W_c*[h_{t-1},x_t]+b_c)\\ \end{aligned} \right.
⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧更新门:it=σ(Wi∗[ht−1,xt]+bi)重置门:ft=σ(Wf∗[ht−1,xt]+bf)记忆体:ht=ot∗tanh(Ct)候选隐藏层:Ct~=tanh(Wc∗[ht−1,xt]+bc)
tf.keras.layers.GRU(记忆体个数, return_sequences=是否返回输出)
p56_GRU_stock.py
















 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









